七月份抄题
206. 反转链表 7/2
思路一:我们可以申请两个指针,第一个指针叫 pre,最初是指向 null 的。第二个指针 cur 指向 head,然后不断遍历 cur。每次迭代到 cur,都将 cur 的 next 指向 pre,然后 pre 和 cur 前进一位。都迭代完了(cur 变成 null 了),pre 就是最后一个节点了。
代码实现
class Solution {
public ListNode reverseList(ListNode head) {
//申请节点,pre和 cur,pre指向null
ListNode pre = null;
ListNode cur = head;
ListNode tmp = null;
while(cur!=null) {
//记录当前节点的下一个节点
tmp = cur.next;
//然后将当前节点指向pre
cur.next = pre;
//pre和cur节点都前进一位
pre = cur;
cur = tmp;
}
return pre;
}
}
思路二:递归的两个条件:
终止条件是当前节点或者下一个节点==null
在函数内部,改变节点的指向,也就是 head 的下一个节点指向 head 递归函数那句
head.next.next = head。
代码实现
class Solution {
public ListNode reverseList(ListNode head) {
//递归终止条件是当前为空,或者下一个节点为空
if(head==null || head.next==null) {
return head;
}
//这里的cur就是最后一个节点
ListNode cur = reverseList(head.next);
//这里请配合动画演示理解
//如果链表是 1->2->3->4->5,那么此时的cur就是5
//而head是4,head的下一个是5,下下一个是空
//所以head.next.next 就是5->4
head.next.next = head;
//防止链表循环,需要将head.next设置为空
head.next = null;
//每层递归函数都返回cur,也就是最后一个节点
return cur;
}
}
146.LRU缓存机制 7/4
https://leetcode-cn.com/problems/lru-cache/solution/lru-ce-lue-xiang-jie-he-shi-xian-by-labuladong/
解题过程:分析上面的操作过程,要让 put 和 get 方法的时间复杂度为 O(1),我们可以总结出 cache 这个数据结构必要的条件:查找快,插入快,删除快,有顺序之分。
因为显然 cache 必须有顺序之分,以区分最近使用的和久未使用的数据;而且我们要在 cache 中查找键是否已存在;如果容量满了要删除最后一个数据;每次访问还要把数据插入到队头。
那么,什么数据结构同时符合上述条件呢?哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。
为什么必须要用双向链表
因为我们需要删除操作。删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持直接查找前驱,保证操作的时间复杂度 O(1)。
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
/**
- Your LRUCache object will be instantiated and called as such:
- LRUCache obj = new LRUCache(capacity);
- int param_1 = obj.get(key);
- obj.put(key,value);
作者:labuladong
链接:https://leetcode-cn.com/problems/lru-cache/solution/lru-ce-lue-xiang-jie-he-shi-xian-by-labuladong/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
*/
4. 寻找两个正序数组的中位数
思路一:开始的思路是写一个循环,然后里边判断是否到了中位数的位置,到了就返回结果,但这里对偶数和奇数的分类会很麻烦。当其中一个数组遍历完后,出了 for 循环对边界的判断也会分几种情况。
返回中位数的话,奇数需要最后一次遍历的结果就可以了,偶数需要最后一次和上一次遍历的结果。
用两个变量 left 和 right,right 保存当前循环的结果,在每次循环前将 right 的值赋给 left。
代码实现
class Solution {
public double findMedianSortedArrays(int[] A, int[] B) {
int m = A.length;
int n = B.length;
int len = m + n;
int left = -1, right = -1;
int aStart = 0, bStart = 0;
for (int i = 0; i <= len / 2; i++) {
left = right; //right 保存当前循环的结果,在每次循环前将 right 的值赋给 left
if (aStart < m && (bStart >= n || A[aStart] < B[bStart])) {
right = A[aStart++];
} else {
right = B[bStart++];
}
}
if ((len & 1) == 0)
return (left + right) / 2.0;
else
return right;
}
}
思路二:题目是求中位数,其实就是求第 k 小数的一种特殊情况。
10. 正则表达式匹配
思路:1.定义状态
- 定义动态数组dp[m][n],(n为字符串p的长度+1,m为字符串s的长度+1),
Q:思考为什么要 +1呢?
A:因为我们还要处理空字符串的情况,比如说p为空,s为空时什么情况;或者p为空,s不为空时什么情况? - 那么dp[m][n]的含义是:p的前[n-1]个字符能否匹配s的前[m-1]个字符
Q:思考为什么是n-1和m-1?
A:因为动态数组里面加了一列和一行空字符串的匹配情况,故需要-1才能对应相应的字符串!比如说dp[1][1]是看s[0]和p[0]能否匹配
因此,创建好的dp数组应该如下图所示:
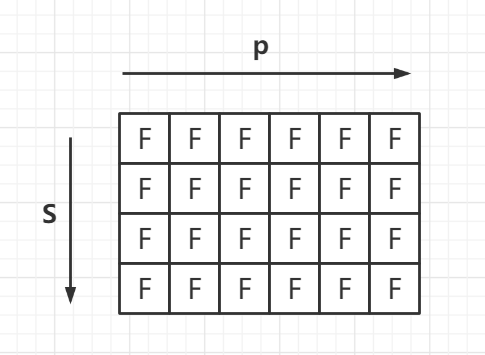
.确定动态转移方程
说明: 为了区别dp数组与字符串索引的区别(因为相差1),我们设i=r-1,j=c-1(r为dp里面的行索引,c为dp里面的列索引)
56. 合并区间
思路:直觉上,只需要对所有的区间按照左端点升序排序,然后遍历。
- 如果当前遍历到的区间的左端点 > 结果集中最后一个区间的右端点,说明它们没有交集,此时把区间添加到结果集;
- 如果当前遍历到的区间的左端点 <= 结果集中最后一个区间的右端点,说明它们有交集,此时产生合并操作,即:对结果集中最后一个区间的右端点更新(取两个区间的最大值)。
数组与List之间的相互转换、
https://blog.csdn.net/qq_39181839/article/details/110501568
代码实现:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Stack;
public class Solution {
public int[][] merge(int[][] intervals) {
int len = intervals.length;
if (len < 2) {
return intervals;
}
// 按照起点排序
Arrays.sort(intervals, Comparator.comparingInt(o -> o[0]));
// 也可以使用 Stack,因为我们只关心结果集的最后一个区间
List<int[]> res = new ArrayList<>();
res.add(intervals[0]);
for (int i = 1; i < len; i++) {
int[] curInterval = intervals[i];
// 每次新遍历到的列表与当前结果集中的最后一个区间的末尾端点进行比较
int[] peek = res.get(res.size() - 1);
if (curInterval[0] > peek[1]) {
res.add(curInterval);
} else {
// 注意,这里应该取最大
peek[1] = Math.max(curInterval[1], peek[1]);
}
}
return res.toArray(new int[res.size()][]);
}
public static void main(String[] args) {
Solution solution = new Solution();
int[][] intervals = {{1, 3}, {2, 6}, {8, 10}, {15, 18}};
int[][] res = solution.merge(intervals);
for (int i = 0; i < res.length; i++) {
System.out.println(Arrays.toString(res[i]));
}
}
}
240. 搜索二维矩阵 II
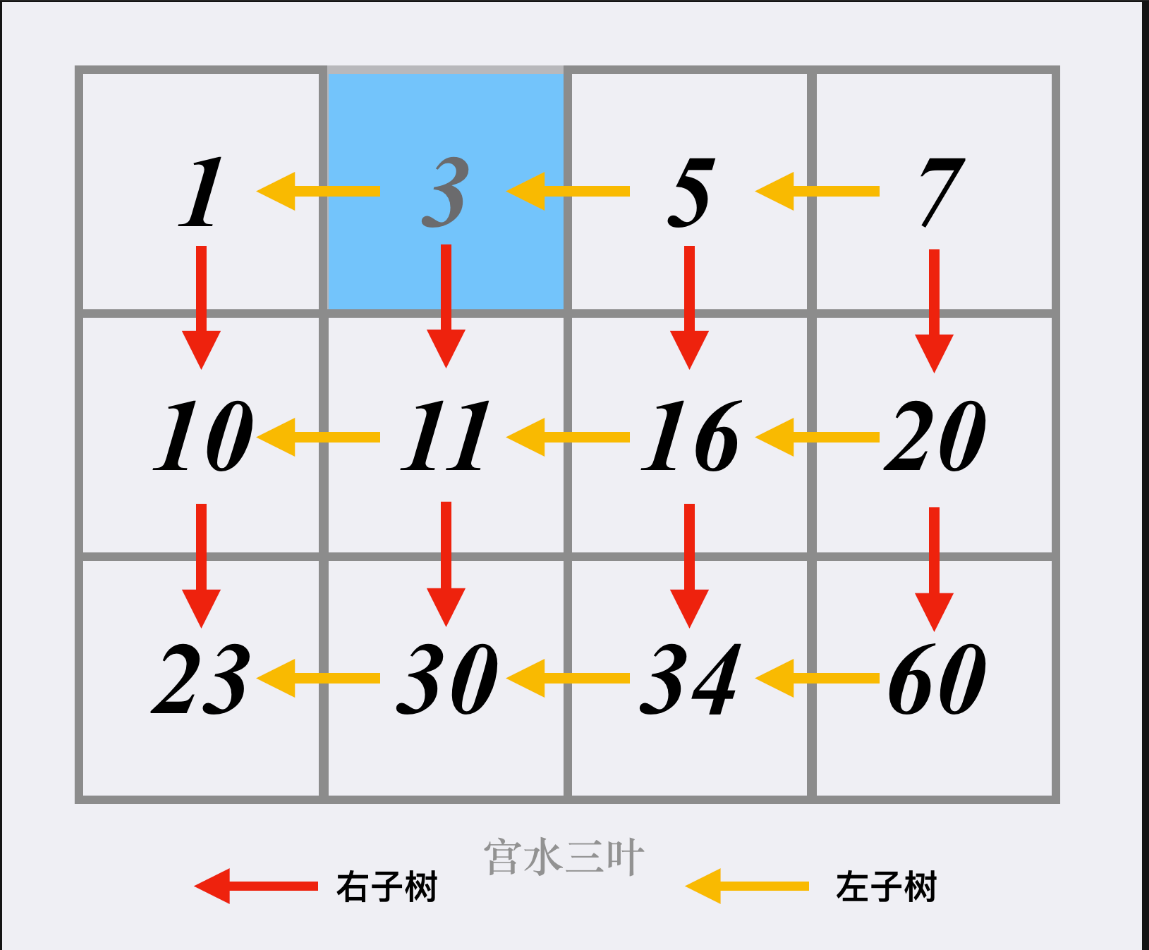
题解:在这张图中,将右上角的数类比为二叉搜索树的根结点,然后
- 每个节点左边数为左节点,满足条件:小于父节点
- 每个节点下边数为右节点,满足条件:大于父节点
- 当前节点大于目标值,搜索当前节点的左子树,也就是当前位置的左侧格子
- 当前节点小于目标值,搜索当前节点的右子树,也就是当前位置的右侧格子
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
int row = matrix.length;
if(row < 1){
return false;
}
int colums = matrix[0].length;
if(matrix[row - 1][colums - 1] < target || matrix[0][0] > target){
return false;
}
// 右上角根节点开始查找 && 可能能找到 (target 在首尾范围内,但不一定有值等同与 targrt)
for(int i = 0, j = colums-1; i < row && j >= 0;) { //三个循环体都可以省略,但是分号不可以省略!全省略后无限循环,永不跳出
if(matrix[i][j] == target){
return true;
}
else if(matrix[i][j] > target){
j--;
}
else if(matrix[i][j] < target){
i++;
}
}
return false;
}
}
25. K 个一组翻转链表 7/21 15:01

ListNode list=new ListNode() 、 ListNode list=new ListNode(0) 与 ListNode list=null
ListNode list=new ListNode() //初始化一个节点,无值,不提倡此种写法。
ListNode list=new ListNode(0) //初始化一个节点值为0的节点,最常用最正规写法
ListNode list=null //为空,什么都没有,一般不这么写;
代码实现
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
if (head == null || head.next == null){
return head;
}
//定义一个假的节点。
ListNode dummy=new ListNode(0);
//假节点的next指向head。
// dummy->1->2->3->4->5
dummy.next=head;
//初始化pre和end都指向dummy。pre指每次要翻转的链表的头结点的上一个节点。end指每次要翻转的链表的尾节点
ListNode pre=dummy;
ListNode end=dummy;
while(end.next!=null){
//循环k次,找到需要翻转的链表的结尾,这里每次循环要判断end是否等于空,因为如果为空,end.next会报空指针异常。
//dummy->1->2->3->4->5 若k为2,循环2次,end指向2
for(int i=0;i<k&&end != null;i++){
end=end.next;
}
//如果end==null,即需要翻转的链表的节点数小于k,不执行翻转。
if(end==null){
break;
}
//先记录下end.next,方便后面链接链表
ListNode next=end.next;
//然后断开链表
end.next=null;
//记录下要翻转链表的头节点
ListNode start=pre.next;
//翻转链表,pre.next指向翻转后的链表。1->2 变成2->1。 dummy->2->1
pre.next=reverse(start);
//翻转后头节点变到最后。通过.next把断开的链表重新链接。
start.next=next;
//将pre换成下次要翻转的链表的头结点的上一个节点。即start
pre=start;
//翻转结束,将end置为下次要翻转的链表的头结点的上一个节点。即start
end=start;
}
return dummy.next;
}
//206. 反转链表:双指针
// 例子: head: 1->2->3->4
public ListNode reverse(ListNode head) {
//单链表为空或只有一个节点,直接返回原单链表
if (head == null || head.next == null){
return head;
}
//前一个节点指针
ListNode preNode = null;
//当前节点指针
ListNode curNode = head;
//下一个节点指针
ListNode nextNode = null;
while (curNode != null){
nextNode = curNode.next;//nextNode 指向下一个节点,保存当前节点后面的链表。
curNode.next=preNode;//将当前节点next域指向前一个节点 null<-1<-2<-3<-4
preNode = curNode;//preNode 指针向后移动。preNode指向当前节点。
curNode = nextNode;//curNode指针向后移动。下一个节点变成当前节点
}
return preNode;
}
}
关于反转链表中的指针指代说明
//206. 反转链表:双指针
// 例子: head: 1->2->3->4
public ListNode reverse(ListNode head) {
//单链表为空或只有一个节点,直接返回原单链表
if (head == null || head.next == null){
return head;
}
//前一个节点指针
ListNode preNode = null;
//当前节点指针
ListNode curNode = head;
//下一个节点指针
ListNode nextNode = null;
while (curNode != null){
nextNode = curNode.next;//nextNode 指向下一个节点,保存当前节点后面的链表。
curNode.next=preNode; //该处表明:curNode.next节点 与 preNode节点同时指向preNode节点所在的地址,并不是curNode.next指向preNode
preNode = curNode; //preNode 指针向后移动。preNode指向当前节点。
curNode = nextNode;//curNode指针向后移动。下一个节点变成当前节点
}
return preNode;
}
curNode.next=preNode; //该处表明:curNode.next节点 与 preNode节点同时指向preNode节点所在的地址,并不是curNode.next指向preNode
preNode = curNode; //preNode 指针向后移动。preNode指向当前节点。
103. 二叉树的锯齿形层序遍历 7/21 16:10
题解:
https://leetcode-cn.com/problems/binary-tree-zigzag-level-order-traversal/solution/bfshe-dfsliang-chong-jie-jue-fang-shi-by-184y/
数据结构-树
https://mp.weixin.qq.com/s?__biz=MzU0ODMyNDk0Mw==&mid=2247487028&idx=1&sn=e06a0cd5760e62890e60e43a279a472b&chksm=fb419d14cc36140257eb220aaeac182287b10c3cab5c803ebd54013ee3fc120d693067c2e960&token=2095441666&lang=zh_CN#rd
list集合 add(int index, E element) 方法的妙用
https://blog.csdn.net/weixin_43558205/article/details/114380535
add(int index, E element):将指定的元素插入此列表中的指定位置(可选操作)。 将当前在该位置的元素(如果有)和任何后续元素右移(将其索引添加一个)
参数:
index-要插入指定元素的索引
element–要插入的元素
当你插入的元素的位置已经有元素的话,会将此位置已经存在的和后面的全部往后移动
如果你需要将数据每次插入到最前面,那么就可以add(0,element);
代码实现
public class Solution {
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if (root == null)
return res;
//创建队列,保存节点
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);//先把节点加入到队列中
boolean leftToRight = true;//第一步先从左边开始打印
while (!queue.isEmpty()) {
//记录每层节点的值
List<Integer> level = new ArrayList<>();
//统计这一层有多少个节点
int count = queue.size();
//遍历这一层的所有节点,把他们全部从队列中移出来,顺便
//把他们的值加入到集合level中,接着再把他们的子节点(如果有)
//加入到队列中
for (int i = 0; i < count; i++) { //一个i对应一个节点
//poll移除队列头部元素(队列在头部移除,尾部添加)
TreeNode node = queue.poll();
//判断是从左往右打印还是从右往左打印。
if (leftToRight) {
//如果从左边打印,直接把访问的节点值加入到列表level的末尾即可
level.add(node.val);
} else {
//如果是从右边开始打印,每次要把访问的节点值
//加入到列表的最前面
level.add(0, node.val);
}
//左右子节点如果不为空会被加入到队列中
if (node.left != null)
queue.add(node.left);
if (node.right != null)
queue.add(node.right);
}
//把这一层的节点值加入到集合res中
res.add(level);
//改变下次访问的方向
leftToRight = !leftToRight;
}
return res;
}
}
链表中节点与指针的区别 ???
代码区别
// 定义一个新链表的头节点
ListNode head = new ListNode(-1);
// 定义一个指针
ListNode prev = head;
// 定义一个指针
ListNode prev = null;
prev = head;
实质区别 ????
节点实际是不动的,在内存中实际存在。有实际值
指针是指向节点的地址值,可以变动
237. 7/22 15:00
class Solution {
public void deleteNode(ListNode node) {
//借刀杀人
node.val = node.next.val;
node.next = node.next.next; //被删除的节点没有索引指向,会被垃圾回收器回收。单链表中没有被指向的节点会被删除,不用管该节点指向谁(即 不用刻意断开)
}
}
1.因为是单链表,所以我们必须先找到需要删除节点的前一个节点
2.temp.next=temp.next.next
3.被删除的节点没有索引指向,会被垃圾回收器回收
108. 将有序数组转换为二叉搜索树 7/22
BST的中序遍历是升序的,因此本题等同于根据中序遍历的序列恢复二叉搜索树。
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return dfs(nums, 0, nums.length - 1);
}
private TreeNode dfs(int[] nums, int lo, int hi) {
if (lo > hi) {
return null;
}
// 以升序数组的中间元素作为根节点 root。
int mid = lo + (hi - lo) / 2;
TreeNode root = new TreeNode(nums[mid]);
// 递归的构建 root 的左子树与右子树。
root.left = dfs(nums, lo, mid - 1);
root.right = dfs(nums, mid + 1, hi);
return root;
}
}
461. 汉明距离 7/23 10:54
https://blog.csdn.net/qq_27007509/article/details/112246576
Integer.bitCount()方法
bitCount(int i) 函数,实现统计一个数的二进制位有多少个 1
Jdk1.8 源码如下
public static int bitCount(int i) {
// HD, Figure 5-2
i = i - ((i >>> 1) & 0x55555555);
i = (i & 0x33333333) + ((i >>> 2) & 0x33333333);
i = (i + (i >>> 4)) & 0x0f0f0f0f;
i = i + (i >>> 8);
i = i + (i >>> 16);
return i & 0x3f;
}
876. 链表的中间结点 7/23 18:05
思路:快慢指针
/**
两个中间结点的时候,返回第二个中间结点
快指针可以前进的条件是:当前快指针和当前快指针的下一个结点都非空。
*/
class Solution {
public ListNode middleNode(ListNode head) {
if (head == null) {
return null;
}
ListNode slow = head;
ListNode fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
return slow;
}
}
169. 多数元素 7/23 20:20
/**
投票算法证明:
如果候选人不是maj 则 maj,会和其他非候选人一起反对 会反对候选人,所以候选人一定会下台(maj==0时发生换届选举)
如果候选人是maj , 则maj 会支持自己,其他候选人会反对,同样因为maj 票数超过一半,所以maj 一定会成功当选
*/
class Solution {
public int majorityElement(int[] nums) {
int count = 0;
Integer candidate = null;
for (int num : nums) {
if (count == 0) {
candidate = num;
}
count += (num == candidate) ? 1 : -1;
}
return candidate;
}
}
283. 移动零 7/23 21:12
我们创建两个指针i和j,第一次遍历的时候指针j用来记录当前有多少非0元素。即遍历的时候每遇到一个非0元素就将其往数组左边挪,第一次遍历完后,j指针的下标就指向了最后一个非0元素下标。
第二次遍历的时候,起始位置就从j开始到结束,将剩下的这段区域内的元素全部置为0。
class Solution {
public void moveZeroes(int[] nums) {
if(nums==null) {
return;
}
//第一次遍历的时候,把所有的非零赶到左边
int j = 0;
for(int i=0;i<nums.length;++i) {
if(nums[i]!=0) {
nums[j] = nums[i];
j++; //
}
}
//非0元素统计完了,剩下的都是0了
//所以第二次遍历把末尾的元素都赋为0即可
for(int i=j;i<nums.length;++i) {
nums[i] = 0;
}
}
}
121. 买卖股票的最佳时机 2021/7/31 23:25
代码实现
class Solution {
public int maxProfit(int[] prices) {
int len = prices.length;
// 特殊判断
if (len < 2) {
return 0;
}
int[][] dp = new int[len][2];
// dp[i][0] 下标为 i 这天结束的时候,不持股,手上拥有的现金数
// dp[i][1] 下标为 i 这天结束的时候,持股,手上拥有的现金数
// 初始化:不持股显然为 0,持股就需要减去第 1 天(下标为 0)的股价
dp[0][0] = 0;
dp[0][1] = -prices[0];
// 从第 2 天开始遍历
for (int i = 1; i < len; i++) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
dp[i][1] = Math.max(dp[i - 1][1], -prices[i]);
}
return dp[len - 1][0];
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号