操作系统-内存管理-ZONE 和 page (半原创)
半原创, 原创的linux不知道是多少, 我自己学习用到的版本是 v5.19.17
前言
文章很多内容来自一步一图带你深入理解 Linux 物理内存管理 ,半原创,本文为个人学习总结
我们上一篇--操作系统-内存管理-NUMA1(半原创) 介绍了 NUMA 后, 知道了node 节点统筹这多个zone, 而 zone 下一级则是多个 pages .下面让我们继续学习关于 zone 的知识 .
zone 相关知识
回顾
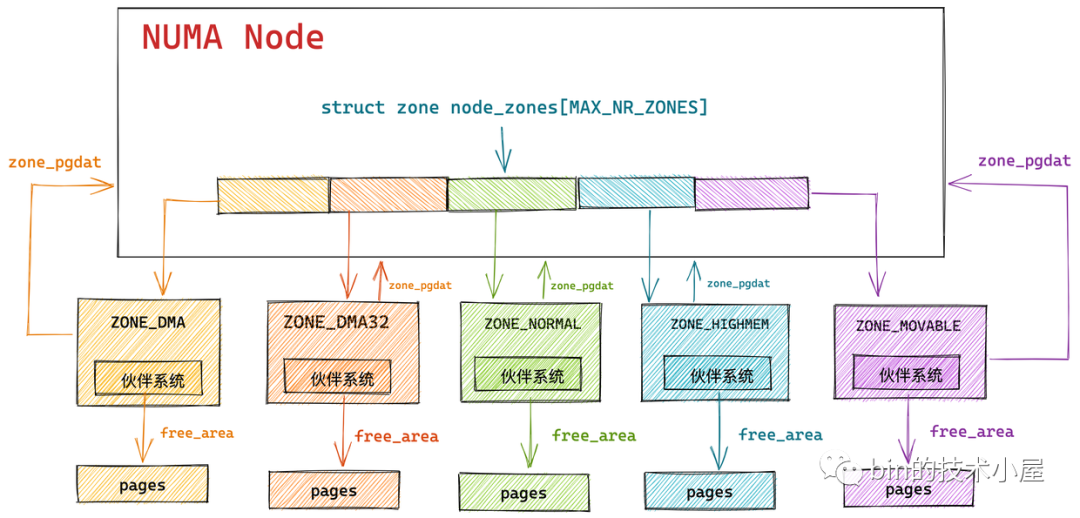
总概图
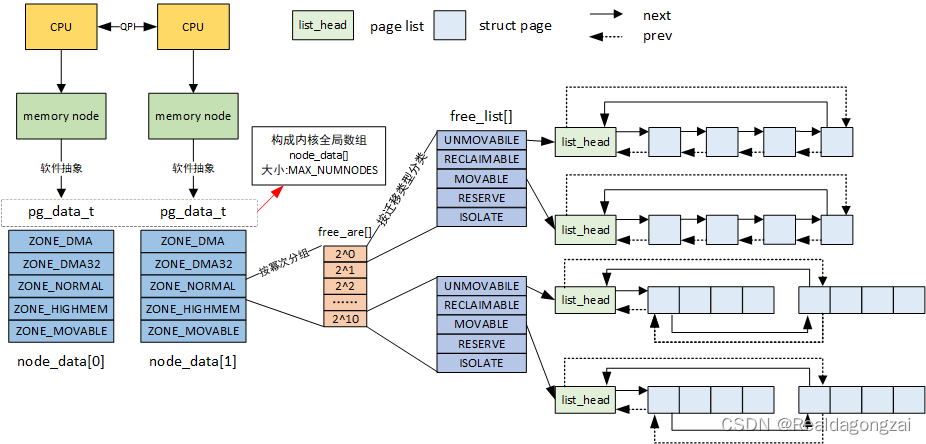
可以看到到了zone 这个层次以后 , 有个 free_area , free_area 就是空闲的page ,它进一步 进行细分, 主要是两个维度
- 大小
- 迁移类型
zone 结构
zone 定义位于文件\linux-5.19.17\include\linux\mmzone.h
struct zone 结构介绍
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long _watermark[NR_WMARK];
unsigned long watermark_boost;
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
struct per_cpu_pages __percpu *per_cpu_pageset;
struct per_cpu_zonestat __percpu *per_cpu_zonestats;
/*
* the high and batch values are copied to individual pagesets for
* faster access
*/
int pageset_high;
int pageset_batch;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* present_early_pages is present pages existing within the zone
* located on memory available since early boot, excluding hotplugged
* memory.
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* cma pages is present pages that are assigned for CMA use
* (MIGRATE_CMA).
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*/
atomic_long_t managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
#if defined(CONFIG_MEMORY_HOTPLUG)
unsigned long present_early_pages;
#endif
#ifdef CONFIG_CMA
unsigned long cma_pages;
#endif
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[ASYNC_AND_SYNC];
unsigned long compact_init_migrate_pfn;
unsigned long compact_init_free_pfn;
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
* compact_order_failed is the minimum compaction failed order.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_event[NR_VM_NUMA_EVENT_ITEMS];
} ____cacheline_internodealigned_in_smp;
enum pgdat_flags {
PGDAT_DIRTY, /* reclaim scanning has recently found
* many dirty file pages at the tail
* of the LRU.
*/
PGDAT_WRITEBACK, /* reclaim scanning has recently found
* many pages under writeback
*/
PGDAT_RECLAIM_LOCKED, /* prevents concurrent reclaim */
};
enum zone_flags {
ZONE_BOOSTED_WATERMARK, /* zone recently boosted watermarks.
* Cleared when kswapd is woken.
*/
ZONE_RECLAIM_ACTIVE, /* kswapd may be scanning the zone. */
};
zone 结构也不复杂, 包含了一些水位线(后面会介绍 , 内存分配的时候用到的) , free_area (就是自己管理的空闲页) , 高速缓存的冷热页 这些, 有一点需要注意的是 , 我们上篇文章操作系统-内存管理-NUMA1(半原创) , zone分类型, 有一个枚举类 ,enum zone_type , 包括 ZONE_DMA , ZONE_NORMAL 等等, 但是奇怪的是并没有一个字段引用在 struct zone 中. 例如我们java , 会有这样一个字段 ,例如以下的例子 :
class shoes{
SHOES_TYPE type ;
float price;
}
enum SHOES_TYPE{
A,B,C,D
}
初始化 zone 的逻辑比较长 ,可以看一下
// 文件位置 : \mm\page_alloc.c
void __init free_area_init(unsigned long *max_zone_pfn)
{
...
for_each_node(nid) {
pg_data_t *pgdat;
if (!node_online(nid)) {
pr_info("Initializing node %d as memoryless\n", nid);
/* Allocator not initialized yet */
pgdat = arch_alloc_nodedata(nid);
if (!pgdat) {
pr_err("Cannot allocate %zuB for node %d.\n",
sizeof(*pgdat), nid);
continue;
}
arch_refresh_nodedata(nid, pgdat);
free_area_init_memoryless_node(nid);
/*
* We do not want to confuse userspace by sysfs
* files/directories for node without any memory
* attached to it, so this node is not marked as
* N_MEMORY and not marked online so that no sysfs
* hierarchy will be created via register_one_node for
* it. The pgdat will get fully initialized by
* hotadd_init_pgdat() when memory is hotplugged into
* this node.
*/
continue;
}
// node 在线的情况走以下逻辑
pgdat = NODE_DATA(nid);
// (重要) 初始化方法
free_area_init_node(nid);
/* Any memory on that node */
if (pgdat->node_present_pages)
node_set_state(nid, N_MEMORY);
check_for_memory(pgdat, nid);
}
memmap_init();
}
// 文件位置 : \mm\page_alloc.c
static void __init free_area_init_node(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->kswapd_highest_zoneidx);
get_pfn_range_for_nid(nid, &start_pfn, &end_pfn);
pgdat->node_id = nid;
pgdat->node_start_pfn = start_pfn;
pgdat->per_cpu_nodestats = NULL;
if (start_pfn != end_pfn) {
pr_info("Initmem setup node %d [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
end_pfn ? ((u64)end_pfn << PAGE_SHIFT) - 1 : 0);
} else {
pr_info("Initmem setup node %d as memoryless\n", nid);
}
calculate_node_totalpages(pgdat, start_pfn, end_pfn);
alloc_node_mem_map(pgdat);
pgdat_set_deferred_range(pgdat);
free_area_init_core(pgdat);
}
// 文件位置 : \mm\page_alloc.c
static void __init free_area_init_core(struct pglist_data *pgdat)
{
enum zone_type j;
int nid = pgdat->node_id;
pgdat_init_internals(pgdat);
pgdat->per_cpu_nodestats = &boot_nodestats;
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, freesize, memmap_pages;
size = zone->spanned_pages;
freesize = zone->present_pages;
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, freesize);
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
pr_debug(" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
pr_warn(" %s zone: %lu memmap pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
pr_debug(" %s zone: %lu pages reserved\n", zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone_init_internals(zone, j, nid, freesize);
if (!size)
continue;
set_pageblock_order();
setup_usemap(zone);
init_currently_empty_zone(zone, zone->zone_start_pfn, size);
}
}
static void __meminit zone_init_internals(struct zone *zone, enum zone_type idx, int nid,
unsigned long remaining_pages)
{
atomic_long_set(&zone->managed_pages, remaining_pages);
zone_set_nid(zone, nid);
zone->name = zone_names[idx];
zone->zone_pgdat = NODE_DATA(nid);
spin_lock_init(&zone->lock);
zone_seqlock_init(zone);
zone_pcp_init(zone);
}
可以看到MAX_NR_ZONES这个数字对应这 enum zone_type , 然后所有的 zone 都放在了
zone 列表被 node 节点持有的代码
typedef struct pglist_data {
// (重要) 该节点下所有 zone
struct zone node_zones[MAX_NR_ZONES];
}
这个结构之下 ,所以取的时候就可以这样拿 :
for (z = 0; z < MAX_NR_ZONES; z++)
zone_init_internals(&pgdat->node_zones[z], z, nid, 0);
这样的话 zone 就不用直接关联 zone_type 了. 特别灵活 ,我发现后面 page 和 pfn 也是这样设计的, 不需要强关联
page
union 结构
page 这个抽象内存块的节奏肯定是给多个模块使用, 于是不能避免得就会多了很多个字段,但是有些字段却是使用不到的 ,为了节省空间,c中使用了 union , 而 union 结构在 C 语言中被用于同一块内存根据不同场景保存不同类型数据的一种方式。内核之所以在 struct page 结构中使用 union,是因为一个物理内存页面在内核中的使用场景和使用方式是多种多样的。在这多种场景下,利用 union 尽最大可能使 struct page 的内存占用保持在一个较低的水平。
page 的结构如下图, 可以看到有两个 union ,还有几个字段
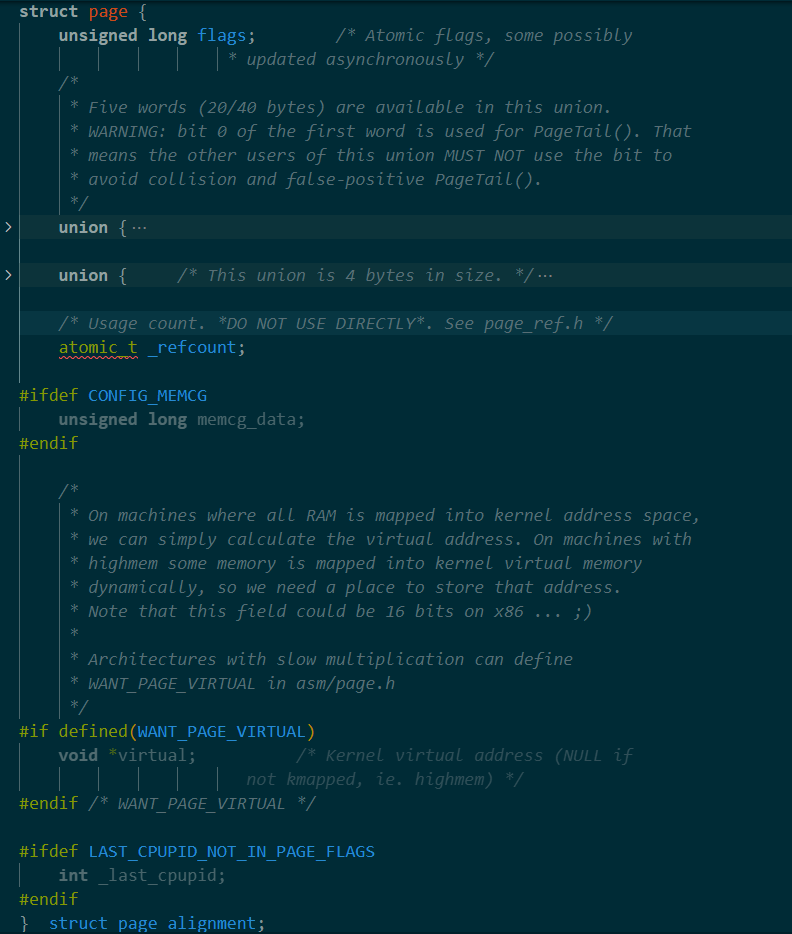
话不多说赶紧看代码 :
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/*
* Five words (20/40 bytes) are available in this union.
* WARNING: bit 0 of the first word is used for PageTail(). That
* means the other users of this union MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
struct { /* Page cache and anonymous pages 页缓存和匿名页 */
/**
* @lru: Pageout list, eg. active_list protected by
* lruvec->lru_lock. Sometimes used as a generic list
* by the page owner.
*/
union {
struct list_head lru;
/* Or, for the Unevictable "LRU list" slot */
struct {
/* Always even, to negate PageTail */
void *__filler;
/* Count page's or folio's mlocks */
unsigned int mlock_count;
};
};
/* See page-flags.h for PAGE_MAPPING_FLAGS (重要) */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
};
struct { /* page_pool used by netstack */
/**
* @pp_magic: magic value to avoid recycling non
* page_pool allocated pages.
*/
unsigned long pp_magic;
struct page_pool *pp;
unsigned long _pp_mapping_pad;
unsigned long dma_addr;
union {
/**
* dma_addr_upper: might require a 64-bit
* value on 32-bit architectures.
*/
unsigned long dma_addr_upper;
/**
* For frag page support, not supported in
* 32-bit architectures with 64-bit DMA.
*/
atomic_long_t pp_frag_count;
};
};
struct { /* Tail pages of compound page */
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
atomic_t compound_pincount;
#ifdef CONFIG_64BIT
unsigned int compound_nr; /* 1 << compound_order */
#endif
};
struct { /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head */
unsigned long _compound_pad_2;
/* For both global and memcg */
struct list_head deferred_list;
};
struct { /* Page table pages */
unsigned long _pt_pad_1; /* compound_head */
pgtable_t pmd_huge_pte; /* protected by page->ptl */
unsigned long _pt_pad_2; /* mapping */
union {
struct mm_struct *pt_mm; /* x86 pgds only */
atomic_t pt_frag_refcount; /* powerpc */
};
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
};
struct { /* ZONE_DEVICE pages */
/** @pgmap: Points to the hosting device page map. */
struct dev_pagemap *pgmap;
void *zone_device_data;
/*
* ZONE_DEVICE private pages are counted as being
* mapped so the next 3 words hold the mapping, index,
* and private fields from the source anonymous or
* page cache page while the page is migrated to device
* private memory.
* ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also
* use the mapping, index, and private fields when
* pmem backed DAX files are mapped.
*/
};
/** @rcu_head: You can use this to free a page by RCU. */
struct rcu_head rcu_head;
};
union { /* This union is 4 bytes in size. */
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
};
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
#ifdef CONFIG_MEMCG
unsigned long memcg_data;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
} _struct_page_alignment;
并不复杂 , 很清晰 ,包括页缓存和匿名页 ,复合页 ,回收相关属性LRU , 页表等 , 其中
struct page {
// 如果 page 为文件页的话,低位为0,指向 page 所在的 page cache
// 如果 page 为匿名页的话,低位为1,指向其对应虚拟地址空间的匿名映射区 anon_vma
struct address_space *mapping;
// 如果 page 为文件页的话,index 为 page 在 page cache 中的索引
// 如果 page 为匿名页的话,表示匿名页在对应进程虚拟内存区域 VMA 中的偏移
pgoff_t index;
}
第一种使用方式是内核直接分配使用一整页的物理内存,在《5.2 物理内存区域中的水位线》小节中我们提到,内核中的物理内存页有两种类型,分别用于不同的场景:
-
一种是匿名页,匿名页背后并没有一个磁盘中的文件作为数据来源,匿名页中的数据都是通过进程运行过程中产生的,匿名页直接和进程虚拟地址空间建立映射供进程使用。
-
另外一种是文件页,文件页中的数据来自于磁盘中的文件,文件页需要先关联一个磁盘中的文件,然后再和进程虚拟地址空间建立映射供进程使用,使得进程可以通过操作虚拟内存实现对文件的操作,这就是我们常说的内存文件映射。
页高速缓存在内核中的结构体就是这个 struct address_space。它被文件的 inode 所持有。
我们常说的 page cache 结构就是 struct address_space .
pfn 和 page
参考资料中, 有一段关于 pfn 的描述 ,下面我们介绍一下它和page 的关系
在前边的文章中,笔者曾多次提到内核是以页为基本单位对物理内存进行管理的,通过将物理内存划分为一页一页的内存块,每页大小为 4K。一页大小的内存块在内核中用 struct page 结构体来进行管理,struct page 中封装了每页内存块的状态信息,比如:组织结构,使用信息,统计信息,以及与其他结构的关联映射信息等。
而为了快速索引到具体的物理内存页,内核为每个物理页 struct page 结构体定义了一个索引编号:PFN(Page Frame Number)。PFN 与 struct page 是一一对应的关系。
内核提供了两个宏来完成 PFN 与 物理页结构体 struct page 之间的相互转换。它们分别是 page_to_pfn 与 pfn_to_page。
内核中如何组织管理这些物理内存页 struct page 的方式我们称之为做物理内存模型,不同的物理内存模型,应对的场景以及 page_to_pfn 与 pfn_to_page 的计算逻辑都是不一样的。
这里有问题 ,我在linux-v5.19.17 中 struct page 中并没有发现 PFN 的定义 , 只有 page_to_pfn 和 pfn_to_page 两个函数 :
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
int __sec = page_to_section(__pg); \
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
})
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})
pfn 其实就是 page 的唯一标识 , 可以通过pfn 找到对应的页 ,找到对应的物理地址 , 例如 :
#define page_to_pa(page) (page_to_pfn(page) << PAGE_SHIFT)
也是说通过pfn 可以找到关于 page , linux 中利用 pfn ,提供了很多便捷的方法 .
下面介绍 page 相关的属性
page 和 内存的回收&内存的分配
内容太多, 下一章进行介绍
page 和 复合页
什么是复合页 , 巨型大页就是通过两个或者多个物理上连续的内存页 page 组装成的一个比普通内存页 page 更大的页,好处多多 :
- 缺页中断的情况就会相对减少,由于减少了缺页中断所以性能会更高
- 巨型页比普通页要大,所以巨型页需要的页表项要比普通页要少,页表项里保存了虚拟内存地址与物理内存地址的映射关系,当 CPU 访问内存的时候需要频繁通过 MMU 访问页表项获取物理内存地址,由于要频繁访问,所以页表项一般会缓存在 TLB 中,因为巨型页需要的页表项较少,所以节约了 TLB 的空间同时降低了 TLB 缓存 MISS 的概率,从而加速了内存访问
- 当一个内存占用很大的进程(比如 Redis)通过 fork 系统调用创建子进程的时候,会拷贝父进程的相关资源,其中就包括父进程的页表,由于巨型页使用的页表项少,所以拷贝的时候性能会提升不少
复合页结构

相关代码
struct page {
...
// 首页 page 中的 flags 会被设置为 PG_head 表示复合页的第一页
unsigned long flags;
// 其余尾页会通过该字段指向首页
unsigned long compound_head;
// 用于释放复合页的析构函数,保存在首页中
unsigned char compound_dtor;
// 该复合页有多少个 page 组成,order 还是分配阶的概念,首页中保存
// 本例中的 order = 2 表示由 4 个普通页组成
unsigned char compound_order;
// 该复合页被多少个进程使用,内存页反向映射的概念,首页中保存
atomic_t compound_mapcount;
// 复合页使用计数,首页中保存
atomic_t compound_pincount;
...
}
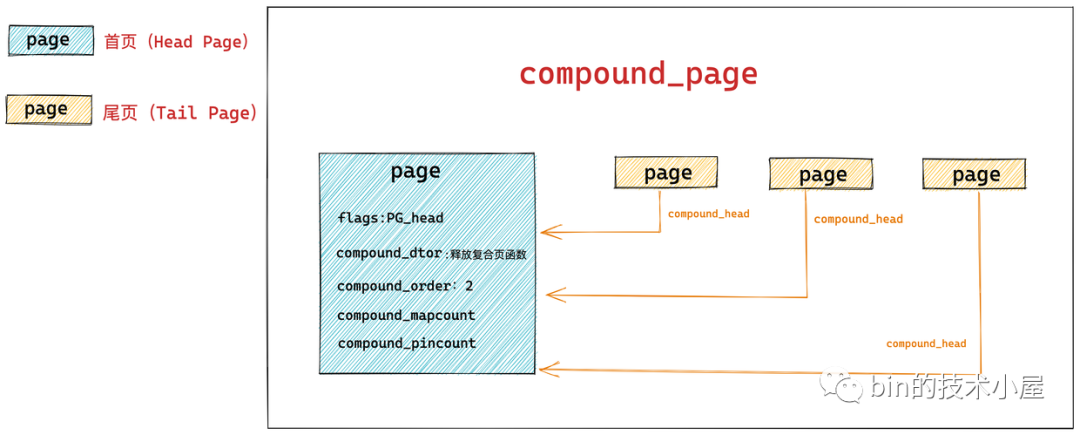
首页对应的 struct page 结构里的 flags 会被设置为 PG_head,表示这是复合页的第一页。
另外首页中还保存关于复合页的一些额外信息,比如用于释放复合页的析构函数会保存在首页 struct page 结构里的 compound_dtor 字段中,复合页的分配阶 order 会保存在首页中的 compound_order 中,以及用于指示复合页的引用计数 compound_pincount,以及复合页的反向映射个数(该复合页被多少个进程的页表所映射)compound_mapcount 均在首页中保存。
复合页中的所有尾页都会通过其对应的 struct page 结构中的 compound_head 指向首页,这样通过首页和尾页就组装成了一个完整的复合页 compound_page 。
其他
内存热插拔
内存的热拔插分为
- 物理内存热拔插
- 逻辑内存热拔插
物理内存热拔插
并非所有的物理页都可以迁移,因为迁移意味着物理内存地址的变化,而内存的热插拔应该对进程来说是透明的,所以这些迁移后的物理页映射的虚拟内存地址是不能变化的。
这一点在进程的用户空间是没有问题的,因为进程在用户空间访问内存都是根据虚拟内存地址通过页表找到对应的物理内存地址,这些迁移之后的物理页,虽然物理内存地址发生变化,但是内核通过修改相应页表中虚拟内存地址与物理内存地址之间的映射关系,可以保证虚拟内存地址不会改变。
但是在内核态的虚拟地址空间中,有一段直接映射区,在这段虚拟内存区域中虚拟地址与物理地址是直接映射的关系,虚拟内存地直接减去一个固定的偏移量(0xC000 0000 ) 就得到了物理内存地址。
直接映射区中的物理页的虚拟地址会随着物理内存地址变动而变动, 因此这部分物理页是无法轻易迁移的,然而不可迁移的页会导致内存无法被拔除,因为无法妥善安置被拔出内存中已经为进程分配的物理页。那么内核是如何解决这个头疼的问题呢?
既然是这些不可迁移的物理页导致内存无法拔出,那么我们可以把内存分一下类,将内存按照物理页是否可迁移,划分为不可迁移页,可回收页,可迁移页。
大家这里需要记住一点,内核会将物理内存按照页面是否可迁移的特性进行分类,笔者后面在介绍内核如何避免内存碎片的时候还会在提到
然后在这些可能会被拔出的内存中只分配那些可迁移的内存页,这些信息会在内存初始化的时候被设置,这样一来那些不可迁移的页就不会包含在可能会拔出的内存中,当我们需要将这块内存热拔出时, 因为里边的内存页全部是可迁移的, 从而使内存可以被拔除。
我们在上一篇文章中可有看到 zone 对应的有个状态, 其中就有上线 和下线的状态 .
物理内存区域中的冷热页
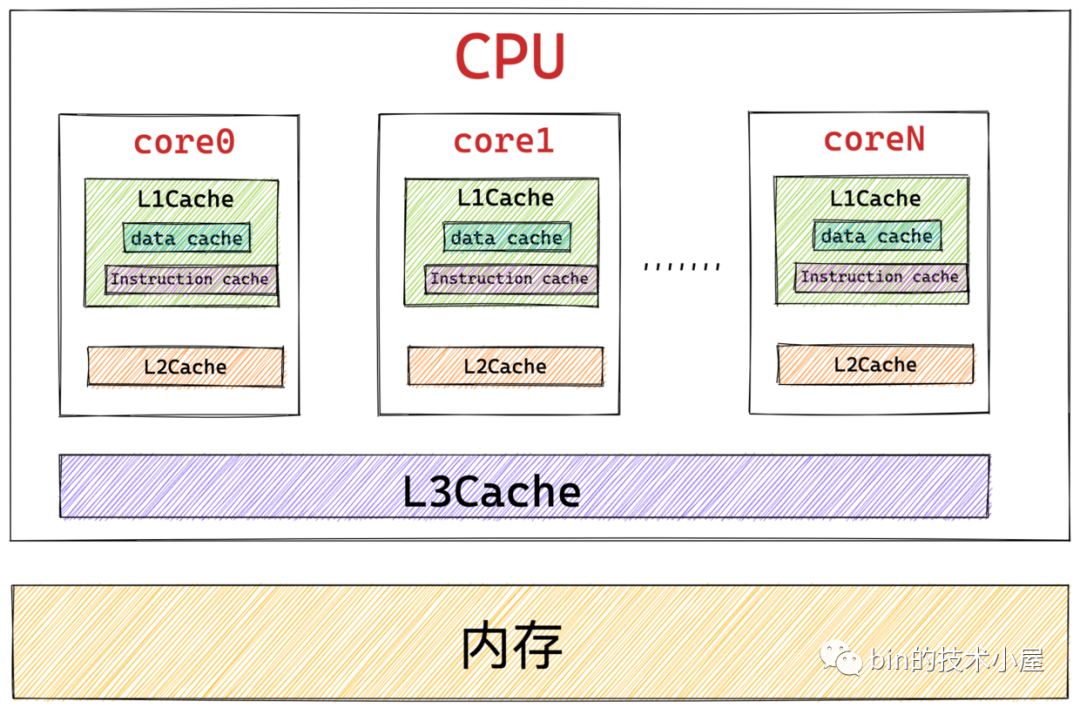
从这个层级上看 , 内存和core之间还有一层缓存--"cache" , 内核中会管理位于加载进 CPU 高速缓存中的物理内存页 ,它的位置位于struct zone结构下
struct zone {
struct per_cpu_pageset pageset[NR_CPUS];
}
物理内存区域中的预留内存
为什么要预留内存 , 有两个原因 :
- 紧急内存分配
- 防止给高层内存区域挤压
第一个原因来自参考文章的解释 :
内核中关于内存分配的场景无外乎有两种方式:
1. 当进程请求内核分配内存时,如果此时内存比较充裕,那么进程的请求会被立刻满足,如果此时内存已经比较紧张,内核就需要将一部分不经常使用的内存进行回收,从而腾出一部分内存满足进 程的内存分配的请求,在这个回收内存的过程中,进程会一直阻塞等待。
2. 另一种内存分配场景,进程是不允许阻塞的,内存分配的请求必须马上得到满足,比如执行中断处理程序或者执行持有自旋锁等临界区内的代码时,进程就不允许睡眠,因为中断程序无法被重新 调度。这时就需要内核提前为这些核心操作预留一部分内存,当内存紧张时,可以使用这部分预留的内存给这些操作分配。
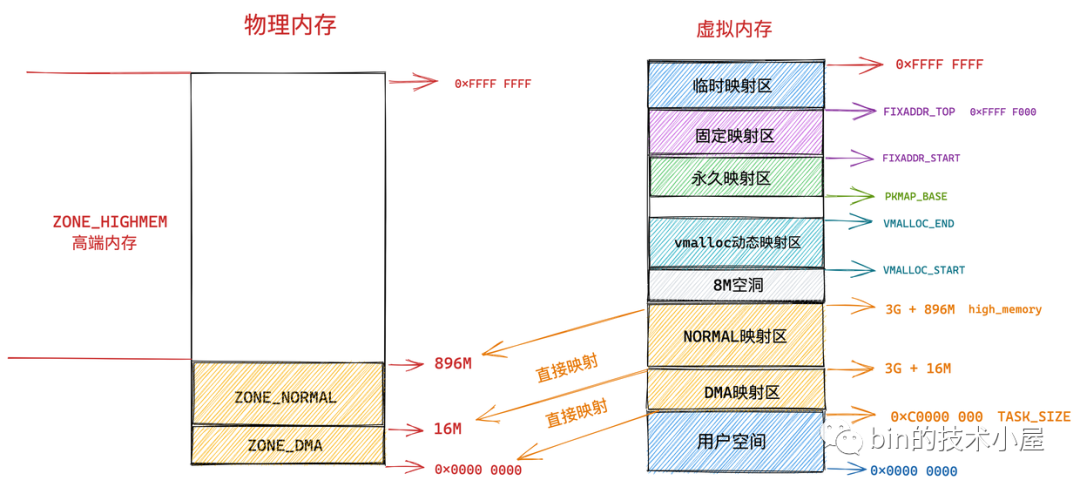
第二个原因是
一些用于特定功能的物理内存必须从特定的内存区域中进行分配,比如外设的 DMA 控制器就必须从 ZONE_DMA 或者 ZONE_DMA32 中分配内存。
但是一些用于常规用途的物理内存则可以从多个物理内存区域中进行分配,当 ZONE_HIGHMEM 区域中的内存不足时,内核可以从 ZONE_NORMAL 进行内存分配,ZONE_NORMAL 区域内存不足时可以进一步降级到 ZONE_DMA 区域进行分配。
而低位内存区域中的内存总是宝贵的,内核肯定希望这些用于常规用途的物理内存从常规内存区域中进行分配,这样能够节省 ZONE_DMA 区域中的物理内存保证 DMA 操作的内存使用需求,但是如果内存很紧张了,高位内存区域中的物理内存不够用了,那么内核就会去占用挤压其他内存区域中的物理内存从而满足内存分配的需求。
但是内核又不会允许高位内存区域对低位内存区域的无限制挤压占用,因为毕竟低位内存区域有它特定的用途,所以每个内存区域会给自己预留一定的内存,防止被高位内存区域挤压占用。而每个内存区域为自己预留的这部分内存就存储在 lowmem_reserve 数组中。
可以使用
cat /proc/sys/vm/lowmem_reserve_ratio
进行查看
参考资料
-
https://linux-kernel-labs.github.io/refs/heads/master/so2/lec7-memory-management.html (重要, 知识点笔记)
-
https://www.kernel.org/doc/html/v5.0/core-api/memory-allocation.html (重要)
-
https://www.kernel.org/doc/gorman/ (这是一本书来的 , 很有用的一本书)
-
https://www.kernel.org/doc/ (这个网站真的是学习内核的一个非常好的网站)
-
Linux 物理内存管理涉及的三大结构体之struct page(非常重要 ,写的非常好)
-
https://github.com/MintCN/linux-insides-zh/tree/master/Booting (重要)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号