操作系统-内存管理-NUMA1(半原创)
注意 :
0. Linux , NUMA 结构管理一个NUMA 节点称之为 node
1. 在 NUMA 内存架构下,每个物理内存区域都是属于一个特定的 NUMA 节点,NUMA 节点中包含了一个或者多个 CPU,NUMA 节点中的每个内存区域会关联到一个特定的 CPU 上
2. NUMA 也可以访问到另外NUMA 下的内存 ,只是距离远了, 性能方面肯定不如本地内存好
3. node 对下是 zone ,对上是多个CPU
前言
文章很多内容来自一步一图带你深入理解 Linux 物理内存管理 ,半原创,本文为个人学习总结
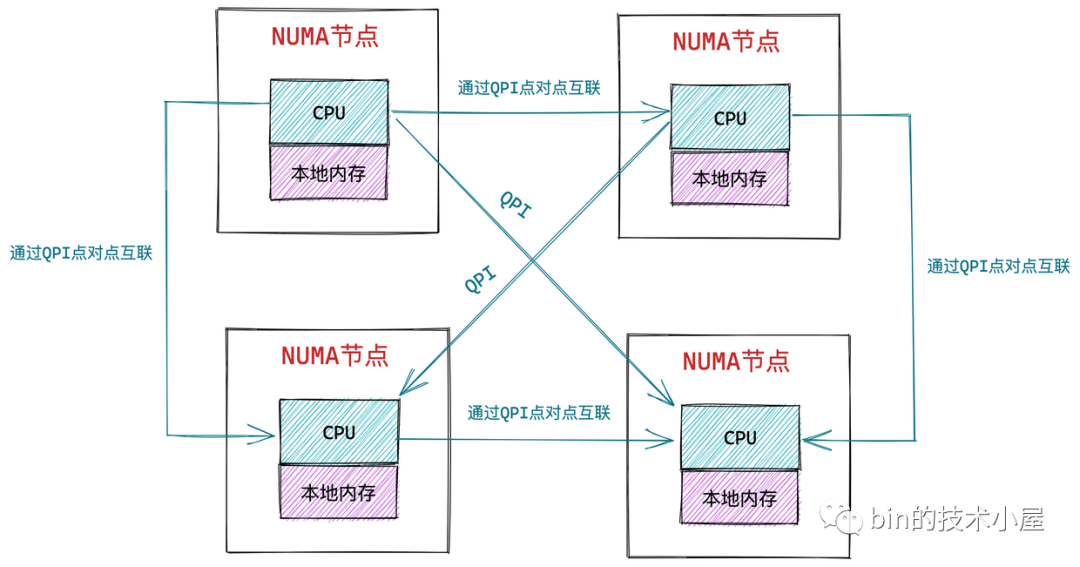
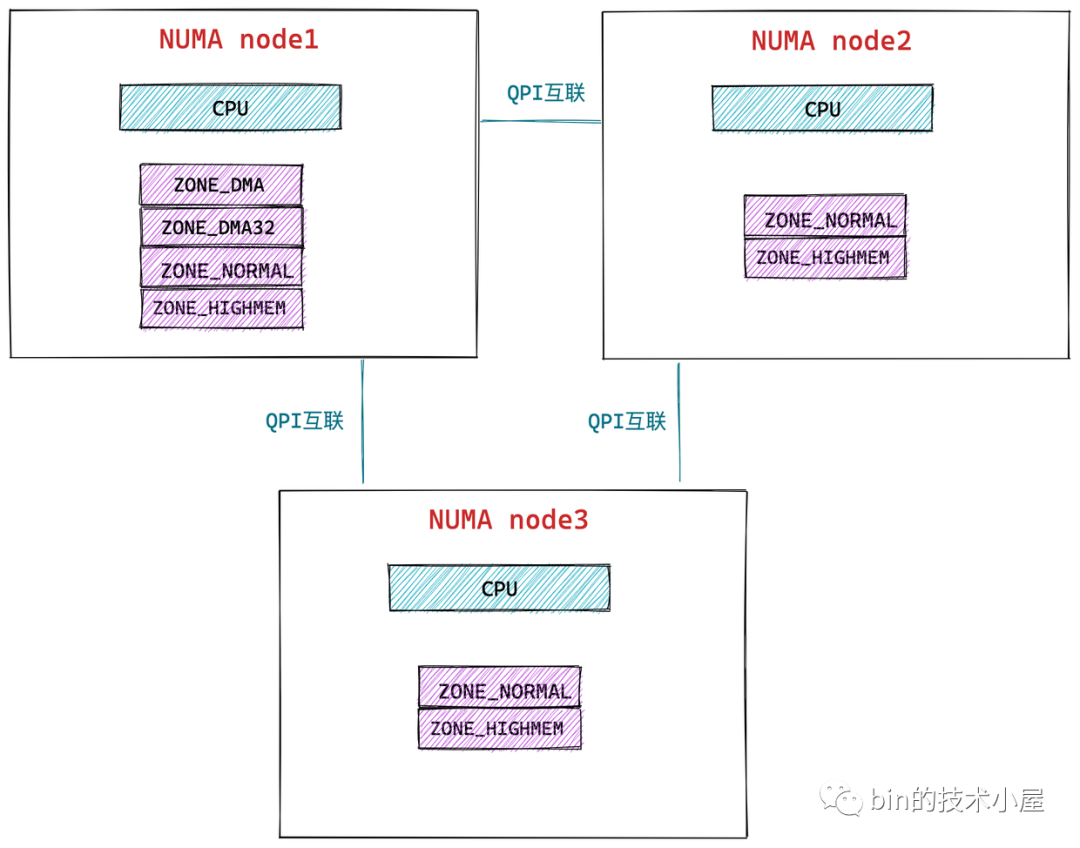
NUMA 总概图
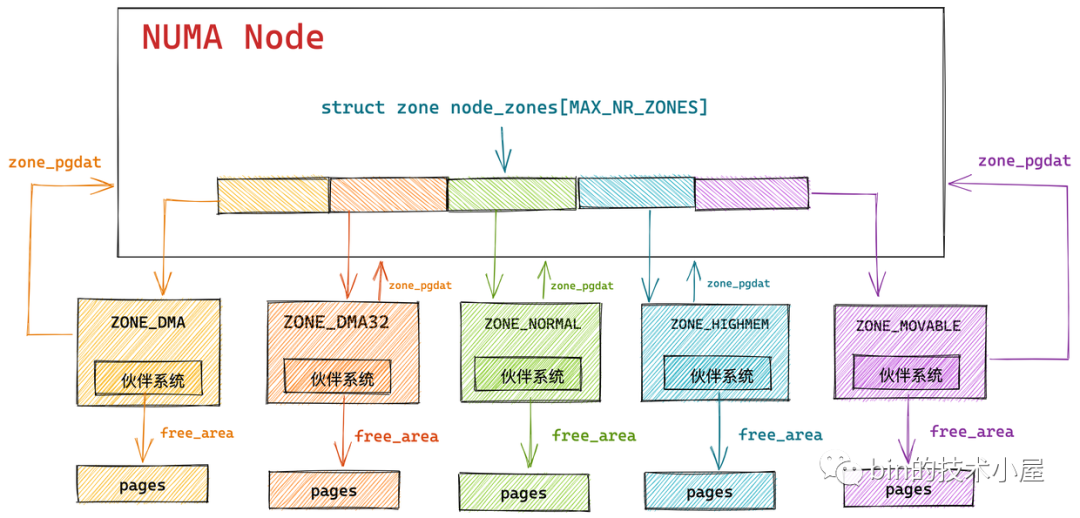
概述
内存管理框架和内存模型是同一个东西吗, 如何理解他们? 模型是方法论, 框架集成模型.
内存模型
linux的物理内存管理机制将物理内存划分为三个层次来管理,依次是:Node(存储节点)、Zone(管理区)和Page(页面)。
(而这个内存管理框架 ,重点在管理上,这一块一块 ,)
- flat memory model,
- Discontiguous memory model
- sparse memory model
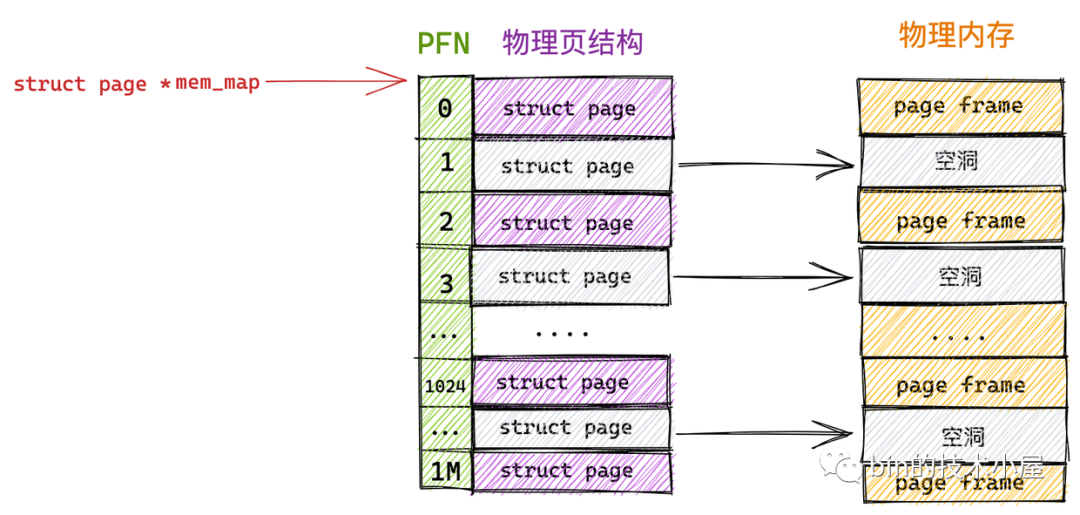
平坦内存模型(Flat memory model)
其中平坦内存模型(Flat memory model)主要特点是CPU访问系统的整个内存,其物理内存空间是连续的,并且访问任意点的时间和速度都是相同的。而管理上,每一个物理页帧都会有一个page数据结构来抽象,因此系统中存在一个struct page的数组(mem_map),每一个数组条目指向一个实际的物理页帧(page frame)。物理页面与page结构数组关系是一一对应。
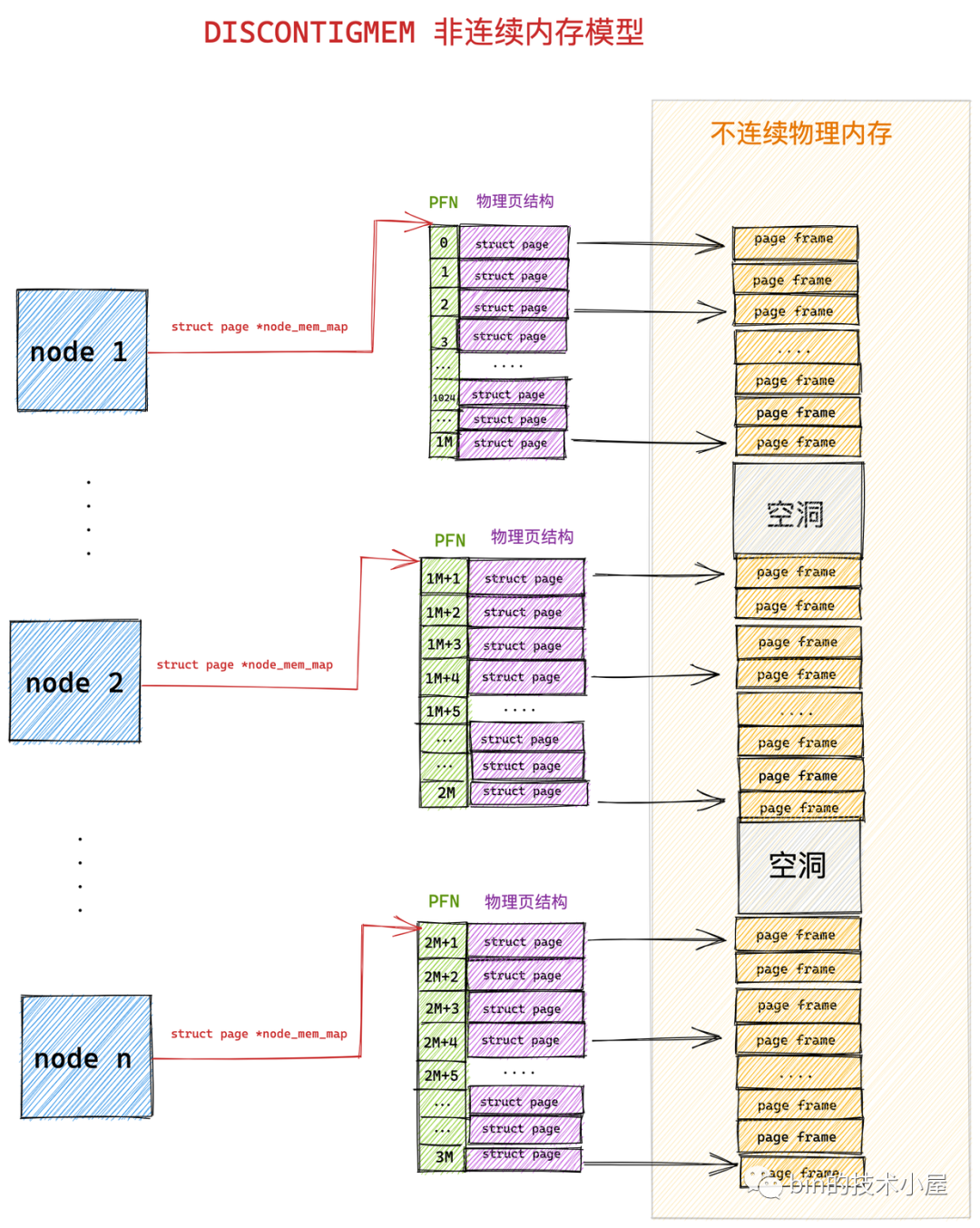
不连续内存模型(Discontiguous memory model)
关于NUMA 的介绍见下一个章节
随着计算机发展,后面多CPU的出现,每个CPU都有自己独立的内存通道,通过自己的内存通道访问与之连接的内存,其速度是均匀的。但是如果要是想访问其他CPU内存通道连接的内存,则时间上开销就慢许多了,而且内存甚至不连续,由此造成了全局内存的访问速度差异以及不连续性。这就是NUMA架构的由来,为此引入了不连续内存模型(Discontiguous memory model)。
该模型对内存的管理是平坦模型的延续,它将连续的访问速度一致的一片大内存归为一个node,而node内的内存管理则采用了平台内存模型的管理方式,page结构数组与物理页面一一对应管理。其中每个node管理的物理内存page结构保存在struct
pglist_data 数据结构的node_mem_map成员中。
因为 FLATMEM 平坦内存模型是利用 mem_map 这样一个全局数组来组织这些被划分出来的物理页 page 的,而对于物理内存存在大量不连续的内存地址这种情况时,这些不连续的内存地址区间就形成了内存空洞。
由于用于组织物理页的底层数据结构是 mem_map 数组,数组的特性又要求这些物理页是连续的,所以只能为这些内存地址空洞也分配 struct page 结来填充数组使其连续。
而每个 struct page 结构大部分情况下需要占用 40 字节(struct page 结构在不同场景下内存占用会有所不同,这一点我们后面再说),如果物理中存在的大块的地址空洞,那么为这些空洞而分配的 struct page 将会占用大量的内存空间,导致巨大的浪费。
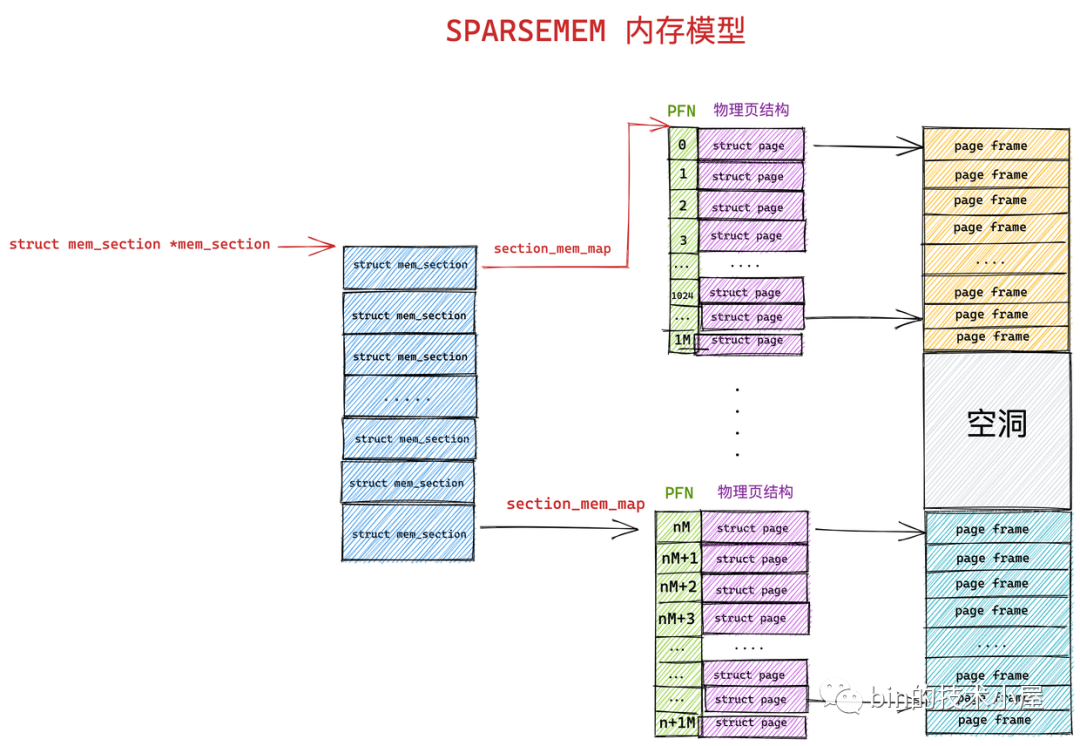
稀疏内存管理模型(Sparse memory model)
首次引入SPARSEMEM时的commit。https://lwn.net/Articles/134804/ 原文中阐明了它的三个优点:
- 可以解决内存空洞导致的内存浪费。
- 支持内存的热插拔(memory hotplug)。
- 支持nodes间的overlap。
技术永远在进步,随着hotplug内存热插拔的出现,那么node节点内的内存也可能出现不连续的情况,由此又演进出了稀疏内存管理模型(Sparse memory model),该模型下连续的地址空间按照SECTION(例如1G)被分成了一段一段的,其中每一section都是hotplug的。
内存管理的时候,整个连续的物理地址空间是按照一个section一个section来切断的,每一个section内部,其memory是连续的(即符合flat memory的特点),因此,mem_map的page数组依附于section结构(struct mem_section)而不是node结构了(struct pglist_data)。实际上不连续内存模型和稀疏内存模型都可以对NUMA架构进行内存管理,因为NUMA没有明确内存必须连续的,所以两种模型都可以管理NUMA架构的内存。
内存管理架构
一致性内存访问 UMA 架构
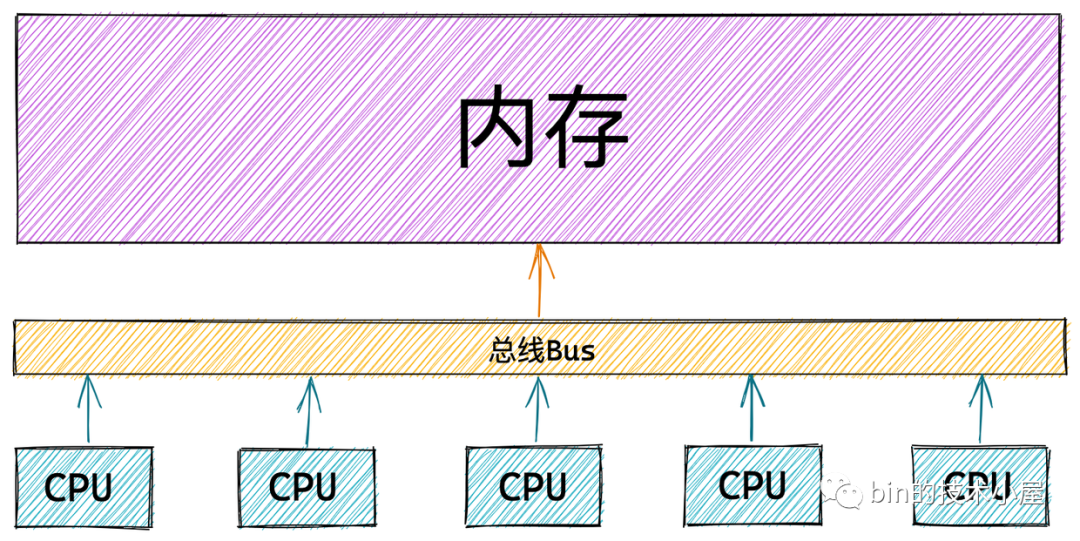
在 UMA 架构下,多核服务器中的多个 CPU 位于总线的一侧,所有的内存条组成一大片内存位于总线的另一侧,所有的 CPU 访问内存都要过总线,而且距离都是一样的,由于所有 CPU 对内存的访问距离都是一样的,所以在 UMA 架构下所有 CPU 访问内存的速度都是一样的。这种访问模式称为 SMP(Symmetric multiprocessing),即对称多处理器
但是随着多核技术的发展,服务器上的 CPU 个数会越来越多,而 UMA 架构下所有 CPU 都是需要通过总线来访问内存的,这样总线很快就会成为性能瓶颈,主要体现在以下两个方面:
- 总线的带宽压力会越来越大,随着 CPU 个数的增多导致每个 CPU 可用带宽会减少
- 总线的长度也会因此而增加,进而增加访问延迟
非一致性内存访问 NUMA 架构
什么是 NUMA (牛马架构) ,存在的动机是什么
NUMA 存在的动机前我们得先了解南北桥 ,
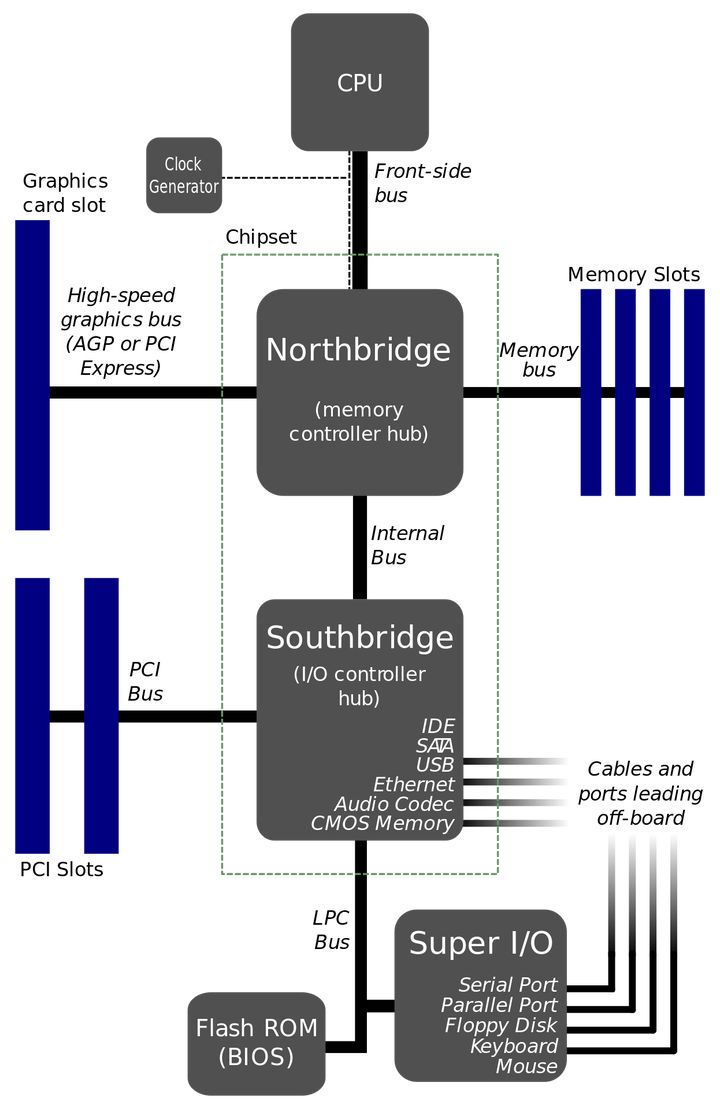
大体上说:北桥负责与CPU通信,并且连接高速设备(内存/显卡),并且与南桥通信;南桥负责与低速设备(硬盘/USB)通信,时钟/BIOS/系统管理/旧式设备控制,并且与北桥通信。
Intel从第一代Core i7 (i7 9xx)开始,将原属于北桥功能的内存控制器整合到CPU当中,在主流机Core i中(i7 8xx)更将PCI-e控制器(主要负责连接显卡)整合到CPU当中,这时候传统意义上的北桥的所有功能都已经整合到CPU内部了,所以Intel 50系芯片“组”(X58除外,这是搭配i7 9xx用的,还有北桥)已经没有传统意义的北桥了,而南桥依然负责处理低速设备(SATA/USB/PCI等)、时钟等功能。由于只剩下一个芯片了,也没有“芯片组”的说法了,只剩下孤零零的PCH (Platform Controller Hub)。
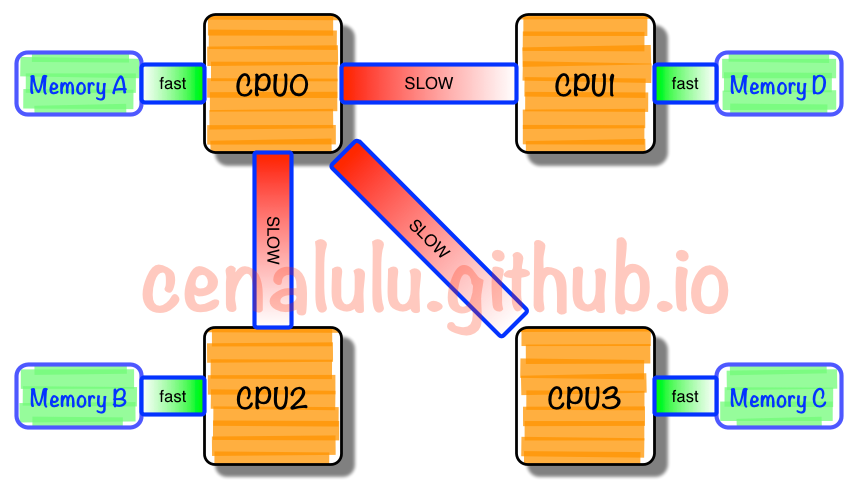
由于所有CPU Core都是通过共享一个北桥来读取内存,随着核数如何的发展,北桥在响应时间上的性能瓶颈越来越明显。于是,聪明的硬件设计师们,先到了把内存控制器(原本北桥中读取内存的部分)也做个拆分,平分到了每个die上。于是NUMA就出现了!
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名。
作者:喵喵
链接:https://www.zhihu.com/question/66881178/answer/246813653
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
NUMA 的使用
安装 numactl
numactl 文档:https://man7.org/linux/man-pages/man8/numactl.8.html
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
node 0 size: 64794 MB
node 0 free: 55404 MB
node 1 cpus: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
node 1 size: 65404 MB
node 1 free: 58642 MB
node 2 cpus: 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
node 2 size: 65404 MB
node 2 free: 61181 MB
node 3 cpus: 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
node 3 size: 65402 MB
node 3 free: 55592 MB
node distances:
node 0 1 2 3
0: 10 16 32 33
1: 16 10 25 32
2: 32 25 10 16
3: 33 32 16 10
绑定 NUMA 节点
有些特殊的场景我们就需要绑定某些特定的应用到指定的CPU , 可以看一下其他章节的例子 .
使用命令进行绑定
numactl --membind=nodes --cpunodebind=nodes command
例如
numactl --membind=0 --cpunodebind=0 ./numatest.out
NUMA 相关知识点
此处使用的是 V5.0.21 版本的Linux 源码
NUMA 的层级是这样的 : NUMA --> ZONE ---> PAGE , 注意都是一对多的关系 , 并且在代码中 , 一个NUMA 被抽象成一个 node 节点 , 这一点在Linux 命名和注释中也可以看到
NUMA 关联 page 和 cpu
内核使用了一个大小为 MAX_NUMNODES ,类型为 struct pglist_data 的全局数组 node_data[] 来管理所有的 NUMA 节点。
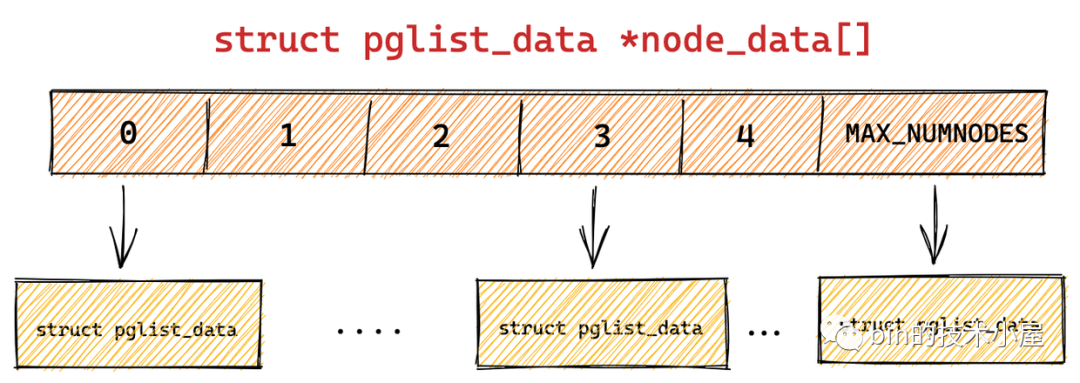
也就是用 pglist_data用来表示一个 NUMA 节点
typedef struct pglist_data {
// (重要) 该节点下所有 zone
struct zone node_zones[MAX_NR_ZONES];
// (重要) 其他 numa 下的 zone 列表
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
// (重要) 配置了稀疏内存模型 , 指向 NUMA 节点内管理所有物理页 page 的数组 ,注意是所有,包括空洞的页
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
#if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT)
/*
* Must be held any time you expect node_start_pfn,
* node_present_pages, node_spanned_pages or nr_zones to stay constant.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG
* or CONFIG_DEFERRED_STRUCT_PAGE_INIT.
*
* Nests above zone->lock and zone->span_seqlock
*/
// 保证多进程可以并发安全的访问 NUMA 节点
spinlock_t node_size_lock;
#endif
// (重要) NUMA 节点内第一个物理页的 pfn
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
int kswapd_order;
enum zone_type kswapd_classzone_idx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_classzone_idx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
#endif
/*
* This is a per-node reserve of pages that are not available
* to userspace allocations.
*/
unsigned long totalreserve_pages;
#ifdef CONFIG_NUMA
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spinlock_t split_queue_lock;
struct list_head split_queue;
unsigned long split_queue_len;
#endif
/* Fields commonly accessed by the page reclaim scanner */
struct lruvec lruvec;
unsigned long flags;
ZONE_PADDING(_pad2_)
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;
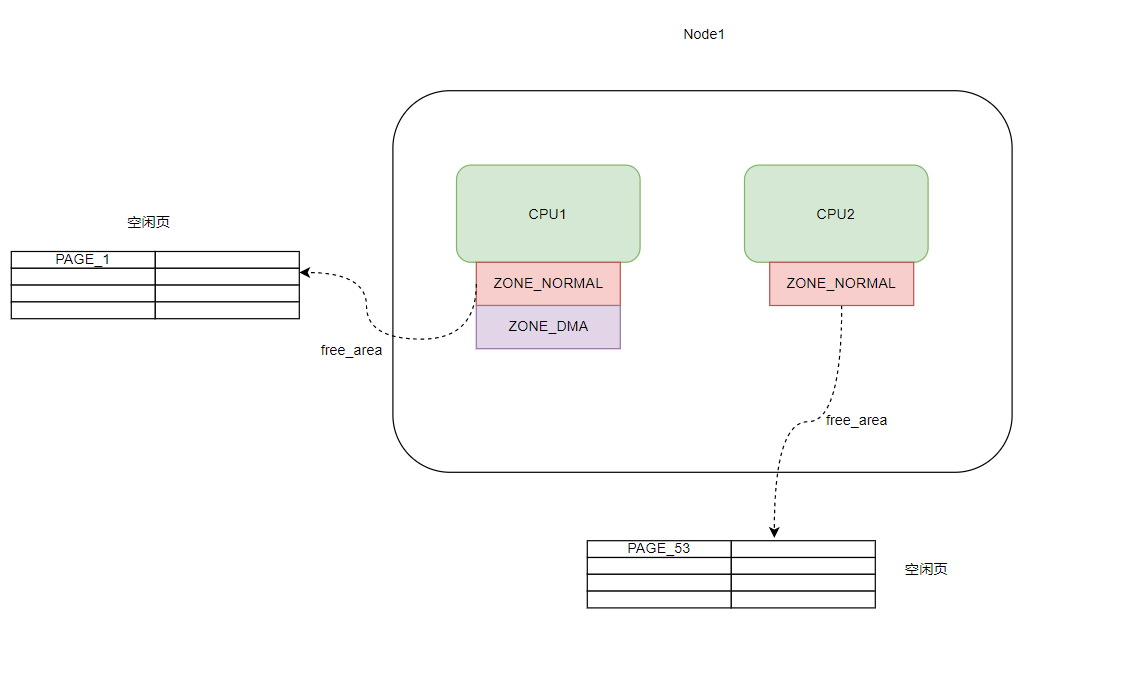
示意图如下 :
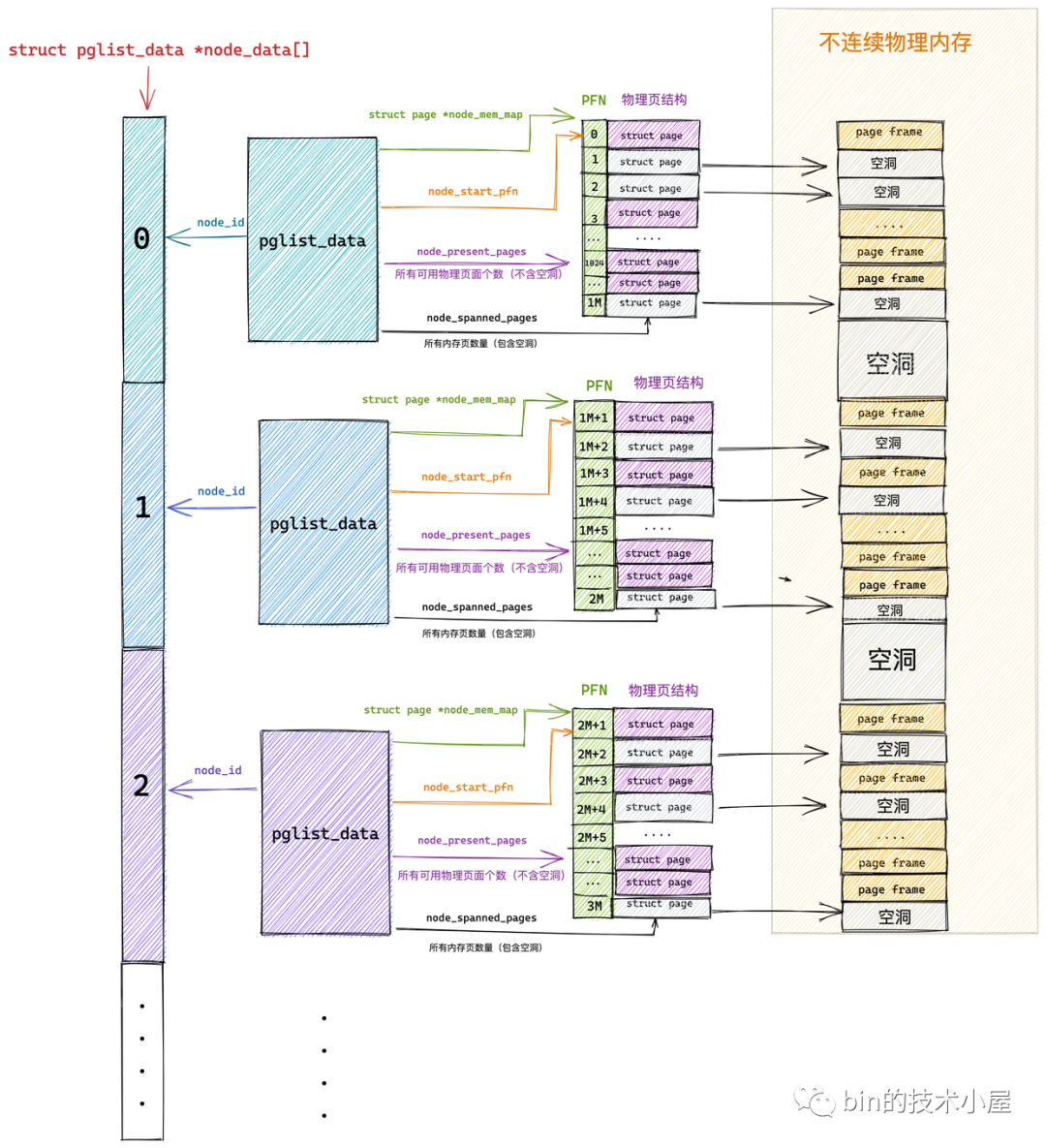
这里有个需要注意的地方
struct page *node_mem_map;
node 里的这个字段表示的是所有的页(即是说包括空洞的页!!) ,而在后面你就会看到ZONE里面有个 free_area,里面的话就是未分配的页
NUMA 节点物理内存区域的划分
在之前这篇文章讲过<<操作系统-内存映射[半原创]>> , 物理内存的分区 : ZONE_DMA , ZONE_HIGHMEM , ZONE_NORMAL
现在 NUMA 要对物理内存管理了, 并且每个Node 负责一部分的内存 , 所以内核会根据各个物理内存区域的功能不同,将 NUMA 节点内的物理内存主要划分为以下四个物理内存区域:
- ZONE_DMA:用于那些无法对全部物理内存进行寻址的硬件设备,进行 DMA 时的内存分配。例如前边介绍的 ISA 设备只能对物理内存的前 16M 进行寻址。该区域的长度依赖于具体的处理器类型。
- ZONE_DMA32:与 ZONE_DMA 区域类似,该区域内的物理页面可用于执行 DMA 操作,不同之处在于该区域是提供给 32 位设备(只能寻址 4G 物理内存)执行 DMA 操作时使用的。该区域只在 64 位系统中起作用,因为只有在 64 位系统中才会专门为 32 位设备提供专门的 DMA 区域。
- ZONE_NORMAL:这个区域的物理页都可以直接映射到内核中的虚拟内存,由于是线性映射,内核可以直接进行访问。
- ZONE_HIGHMEM:这个区域包含的物理页就是我们说的高端内存,内核不能直接访问这些物理页,这些物理页需要动态映射进内核虚拟内存空间中(非线性映射)。该区域只在 32 位系统中才会存在,因为 64 位系统中的内核虚拟内存空间太大了(128T),都可以进行直接映射。
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
// 充当结束标记, 在内核中想要迭代系统中所有内存域时, 会用到该常量
__MAX_NR_ZONES
};
其中 :
ZONE_DEVICE 是为支持热插拔设备而分配的非易失性内存( Non Volatile Memory ),也可用于内核崩溃时保存相关的调试信息。
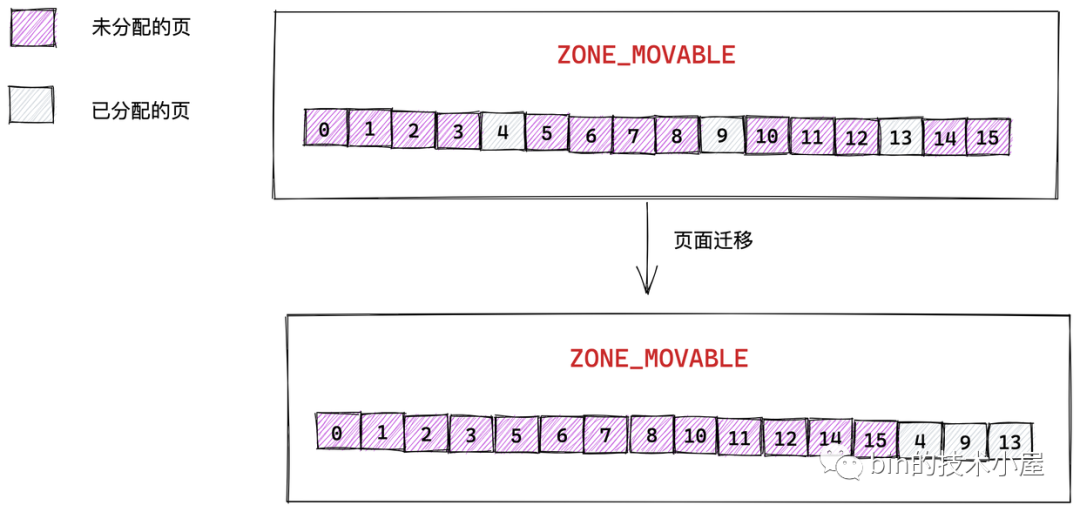
ZONE_MOVABLE 是内核定义的一个虚拟内存区域,该区域中的物理页可以来自于上边介绍的几种真实的物理区域。该区域中的页全部都是可以迁移的,主要是为了防止内存碎片和支持内存的热插拔, 见下面这两张图

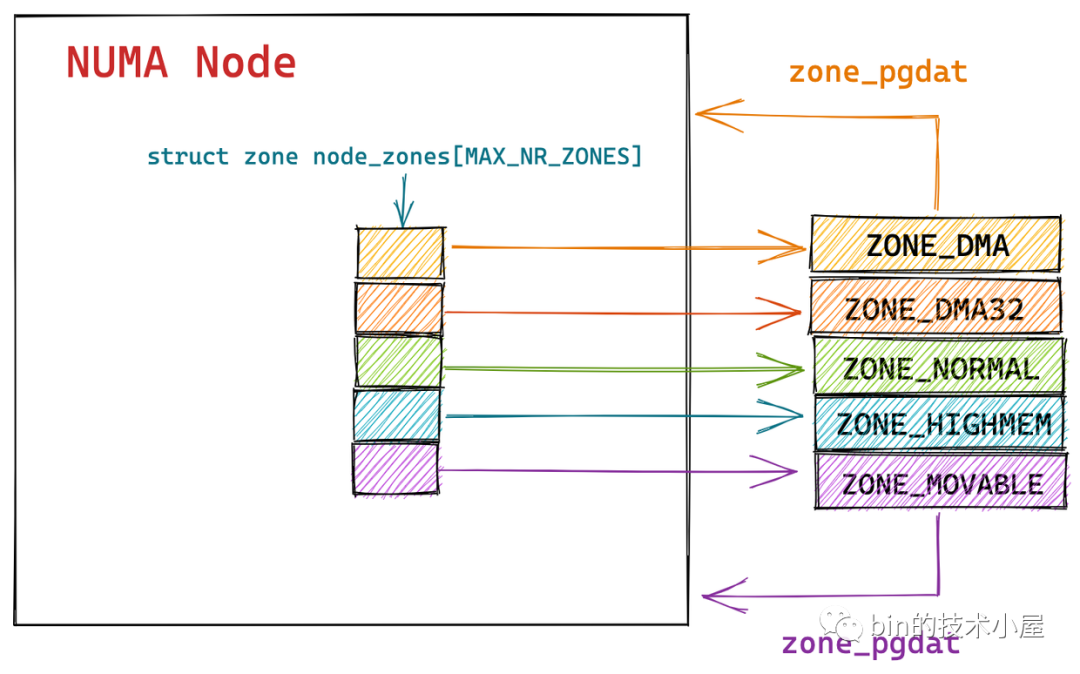
上一小节中代码中的两个字段node_zones[MAX_NR_ZONES] 和 node_zonelists[MAX_ZONELISTS]是和 zone 相关的, 这里进行解释 .
-
node_zones[MAX_NR_ZONES]数组包含了 NUMA 节点中的所有物理内存区域,物理内存区域在内核中的数据结构是 struct zone 。 -
node_zonelists[MAX_ZONELISTS]是 struct zonelist 类型的数组,它包含了备用 NUMA 节点和这些备用节点中的物理内存区域。备用节点是按照访问距离的远近,依次排列在 node_zonelists 数组中,数组第一个备用节点是访问距离最近的,这样当本节点内存不足时,可以从备用 NUMA 节点中分配内存。
zone 数组如下所示
NUMA 节点中的内存规整与回收(避免碎片化)
内存分配久了,就容易产生碎片 ,而对于碎片 ,Linux提供了以下的措施进行规避
- 迁移可移动的页面进行整理,形成更大的空闲内存空间 (类似于JVM 垃圾回收的内存规整)
- 页面回收线程, 回收不再使用的页面
typedef struct pglist_data {
.........
// 页面回收进程
struct task_struct *kswapd;
wait_queue_head_t kswapd_wait;
// 内存规整进程
struct task_struct *kcompactd;
wait_queue_head_t kcompactd_wait;
..........
} pg_data_t;
结合我们前面的总概图, 我们知道了node 里面包含回收线程和整理线程,持有 *node_mem_map,该字段表示node 持有的所有页(包括空洞的页), 而zone 包含伙伴系统(该系统集成了内存分配的算法), 并且 zone 还有 free_area , 也就是说 zone 的职责更像是分配内存, 而node 则包括规整回收,当然node 包含了 zone .
NUMA 节点的状态 node_states
enum node_states {
N_POSSIBLE, /* The node could become online at some point */
N_ONLINE, /* The node is online */
N_NORMAL_MEMORY, /* The node has regular memory */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* The node has regular or high memory */
#else
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif
#ifdef CONFIG_MOVABLE_NODE
N_MEMORY, /* The node has memory(regular, high, movable) */
#else
N_MEMORY = N_HIGH_MEMORY,
#endif
N_CPU, /* The node has one or more cpus */
NR_NODE_STATES
};
可以看到上线下线的状态 ,都是为了热拔插功能设置的
关于热拔插的内容我们在后续的文章会展开 .
其他
查看系统cpu 相关信息
[root@ht2 src]# lscpu
Architecture: x86_64 #x86架构下的64位
CPU op-mode(s): 32-bit, 64-bit #表示支持运行模式,getconf LONG_BIT 命令可以得到当前CPU运行在什么模式下,如果是64,但不代表CPU不支持32bi
Byte Order: Little Endian #Intel的机器(X86平台)一般都采用小端,Little Endian代表小段字节对齐
CPU(s): 80 #逻辑cpu颗数
On-line CPU(s) list: 0-79 #正在运行的cpu逻辑内核
Thread(s) per core: 2 #每个核的线程数(每个 Core 的硬件线程数)
Core(s) per socket: 10 #多少核
Socket(s): 4 #服务器面板上有4个cpu槽位
NUMA node(s): 4 #numa nodes的数量
Vendor ID: GenuineIntel #cpu厂商ID
CPU family: 6 #CPU产品系列代号
Model: 62 #CPU属于其系列中的哪一代的代号
Model name: Intel(R) Xeon(R) CPU #cpu型号
E7-4830 v2 @ 2.20GHz //型号
Stepping: 7 #步长
CPU MHz: 2180.664 #CPU的时钟频率(主频),是指CPU运算时的工作的频率,决定计算技术的运行速度,单位是Hz
CPU max MHz: 2700.0000 #cpu时钟最大频率
CPU min MHz: 1200.0000 #cpu时钟最小频率
BogoMIPS: 4389.73 #BogoMips 是衡量 CPU 速度的方法,它衡量的是“ CPU 每秒钟什么都不能做的百万次数”
Virtualization: VT-x #cpu支持的虚拟化技术,需要进入进入bios设置//要结合着理解L1d cache和L1i cache,他们两个差一个字母d和i
L1d cache: 32K #ld cache 内容缓存
L1i cache: 32K #li cache 指令缓存,L1是最靠近CPU核心的缓存。L2 cache: 256K #CPU未命中L1的情况下继续在L2寻求命中,L2二级缓存比L1一级缓存的容量要更大,但是L2的速率要更慢,离cpu远L3 cache: 20480K # #这里看到,cpu是采用numa硬件体系架构,首先确认看到cpu硬件是否支持numa的.#通过lscpu 、numactl --hardware、grep -i numa /var/log/dmesg等命令可以看到相关配置。#缓存速度上 L1 > L2 > L3 > DDR
NUMA node0 CPU(s): 0-9,40-49 #0-9和40-49 是由numa node0 来管理的NUMA node1 CPU(s): 10-19,50-59 #...NUMA node2 CPU(s): 20-29,60-69 #...NUMA node3 CPU(s): 30-39,70-79 #...
Flags: fpu ..... #cpu支持的技术特征 这里省略了.另外章节介绍
注意: 如果是 1个Sockets, 4个Cores,2 Thread(s) per core 1个cpu,4核8线程由上面上面NUMA 引出了,numa架构问题。
查看node 节点信息
[root@localhost ~]# cat /proc/zoneinfo
Node 0, zone DMA
pages free 3975
min 60
low 75
high 90
scanned 0
spanned 4095
present 3998
managed 3977
nr_free_pages 3975
nr_alloc_batch 15
nr_inactive_anon 0
nr_active_anon 0
nr_inactive_file 0
nr_active_file 0
nr_unevictable 0
nr_mlock 0
nr_anon_pages 0
nr_mapped 0
nr_file_pages 0
nr_dirty 0
nr_writeback 0
nr_slab_reclaimable 0
nr_slab_unreclaimable 2
nr_page_table_pages 0
nr_kernel_stack 0
nr_unstable 0
nr_bounce 0
nr_vmscan_write 0
nr_vmscan_immediate_reclaim 0
nr_writeback_temp 0
nr_isolated_anon 0
nr_isolated_file 0
nr_shmem 0
nr_dirtied 0
nr_written 0
numa_hit 1
numa_miss 0
numa_foreign 0
numa_interleave 0
numa_local 1
numa_other 0
workingset_refault 0
workingset_activate 0
workingset_nodereclaim 0
nr_anon_transparent_hugepages 0
nr_free_cma 0
protection: (0, 3324, 4307, 4307)
pagesets
cpu: 0
count: 0
high: 0
batch: 1
vm stats threshold: 6
cpu: 1
count: 0
high: 0
batch: 1
vm stats threshold: 6
cpu: 2
count: 0
high: 0
batch: 1
vm stats threshold: 6
cpu: 3
count: 0
high: 0
batch: 1
vm stats threshold: 6
all_unreclaimable: 1
start_pfn: 1
inactive_ratio: 1
Node 0, zone DMA32
pages free 35271
min 12992
low 16240
high 19488
scanned 0
spanned 1044480
present 913392
managed 851783
nr_free_pages 35271
nr_alloc_batch 389
nr_inactive_anon 138233
nr_active_anon 190754
nr_inactive_file 228496
nr_active_file 154166
nr_unevictable 0
nr_mlock 0
nr_anon_pages 80618
nr_mapped 23456
nr_file_pages 387972
nr_dirty 18
nr_writeback 0
nr_slab_reclaimable 48237
nr_slab_unreclaimable 37167
nr_page_table_pages 2156
nr_kernel_stack 299
nr_unstable 0
nr_bounce 0
nr_vmscan_write 3249
nr_vmscan_immediate_reclaim 0
nr_writeback_temp 0
nr_isolated_anon 0
nr_isolated_file 0
nr_shmem 4673
nr_dirtied 3961456
nr_written 3888791
numa_hit 53274906
numa_miss 0
numa_foreign 0
numa_interleave 0
numa_local 53274906
numa_other 0
workingset_refault 378230
workingset_activate 208136
workingset_nodereclaim 0
nr_anon_transparent_hugepages 475
nr_free_cma 0
protection: (0, 0, 983, 983)
pagesets
cpu: 0
count: 140
high: 186
batch: 31
vm stats threshold: 36
cpu: 1
count: 112
high: 186
batch: 31
vm stats threshold: 36
cpu: 2
count: 132
high: 186
batch: 31
vm stats threshold: 36
cpu: 3
count: 156
high: 186
batch: 31
vm stats threshold: 36
all_unreclaimable: 0
start_pfn: 4096
inactive_ratio: 5
Node 0, zone Normal
pages free 9497
min 3842
low 4802
high 5763
scanned 0
spanned 271104
present 271104
managed 251699
nr_free_pages 9497
nr_alloc_batch 0
nr_inactive_anon 54033
nr_active_anon 48681
nr_inactive_file 33704
nr_active_file 24820
nr_unevictable 0
nr_mlock 0
nr_anon_pages 36054
nr_mapped 6373
nr_file_pages 61714
nr_dirty 2
nr_writeback 0
nr_slab_reclaimable 14981
nr_slab_unreclaimable 13096
nr_page_table_pages 897
nr_kernel_stack 259
nr_unstable 0
nr_bounce 0
nr_vmscan_write 4115
nr_vmscan_immediate_reclaim 8778
nr_writeback_temp 0
nr_isolated_anon 0
nr_isolated_file 0
nr_shmem 1568
nr_dirtied 995948
nr_written 982436
numa_hit 25273912
numa_miss 0
numa_foreign 0
numa_interleave 16915
numa_local 25273912
numa_other 0
workingset_refault 65780
workingset_activate 20858
workingset_nodereclaim 0
nr_anon_transparent_hugepages 124
nr_free_cma 0
protection: (0, 0, 0, 0)
pagesets
cpu: 0
count: 163
high: 186
batch: 31
vm stats threshold: 24
cpu: 1
count: 37
high: 186
batch: 31
vm stats threshold: 24
cpu: 2
count: 181
high: 186
batch: 31
vm stats threshold: 24
cpu: 3
count: 157
high: 186
batch: 31
vm stats threshold: 24
all_unreclaimable: 0
start_pfn: 1048576
inactive_ratio: 1
页表小知识回顾
- 内核进程其页表有个统一的页表
- 用户态下每个进程都有自己独立的
页全局目录(不是页表 ,是页全局目录)和部分私有的页表。同样其页全局目录存储在task_struct结构下面的mm_struct内的pgd变量
NUMA 相关的例子
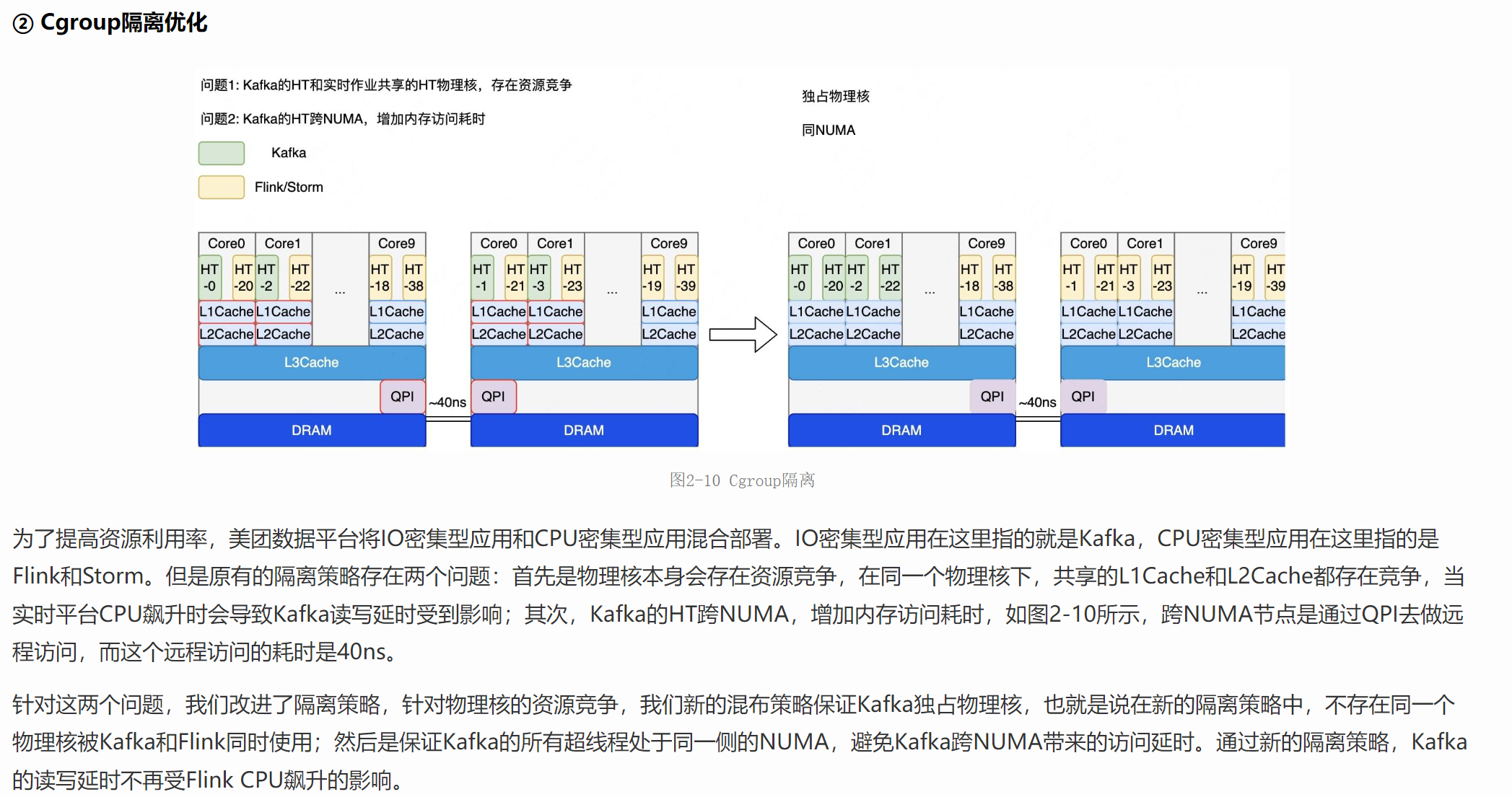
美团技术文章有一篇提到的 kafka 的优化可以学习一下 , 可以看到两个业务服务在混部署的情况下 , 业务会存在不同的 NUMA 节点 , 那么就会出现抢占CPU 的情况 ,并且内存不命中的情况 , 解决方法也很容易 , 只需要增加 cgroup 限制就行 (cgroup 是容器的主要实现技术)
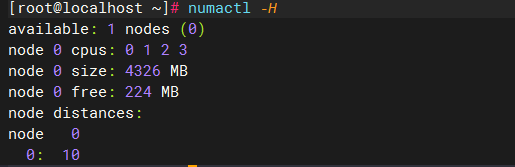
NUMA 只有一个核的时候
只有一个核就相当于兼容了前面几种模式
参考资料
- http://www.wowotech.net/memory_management/memory_model.html
- https://zhuanlan.zhihu.com/p/220068494
- https://www.one-tab.com/page/RMBW_P83SeauokNuqyXAqw
- https://www.one-tab.com/page/i2GeYr3HQEOqVzjTQHFjdQ
- NUMA架构的CPU -- 你真的用好了么? (推荐一读)
- 北桥南桥
- linux 系列博客
- https://tech.meituan.com/2022/08/04/the-practice-of-kafka-in-the-meituan-data-platform.html (重要 ,NUMA 中内存迁移相关问题)
- https://blog.csdn.net/Linux_Everything/article/details/113667395 (重要 ,NUMA 中内存迁移相关问题)
- https://lwn.net/Articles/789304/ (重要 ,3种模型的介绍)
- 一步一图带你深入理解 Linux 物理内存管理
- linux 在线源码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号