链接-动态链接
共享库
共享库的动机是什么 ,我们从前面的静态链接的时候学习到了静态链接库 ,可以知道静态链接库的缺点如下 :


这里有个问题 ,就是每个进程都拥有虚拟空间地址 ,然后共享库又只会有一个 ,那么共享库如何做到给各个进程共享呢? 这个问题我们放在了其他这一个章节
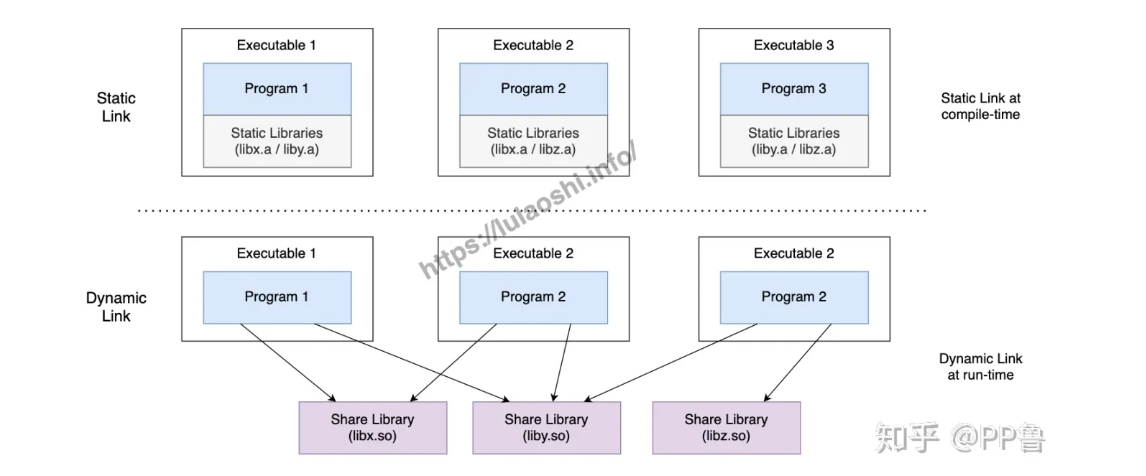
动态链接和静态链接的一个区别
自定义一个共享库

可以看到我们我们使用了 gcc 的命令生成了位置无关的代码 ,简称 PIC .
动态链接的方式
1.加载时动态链接
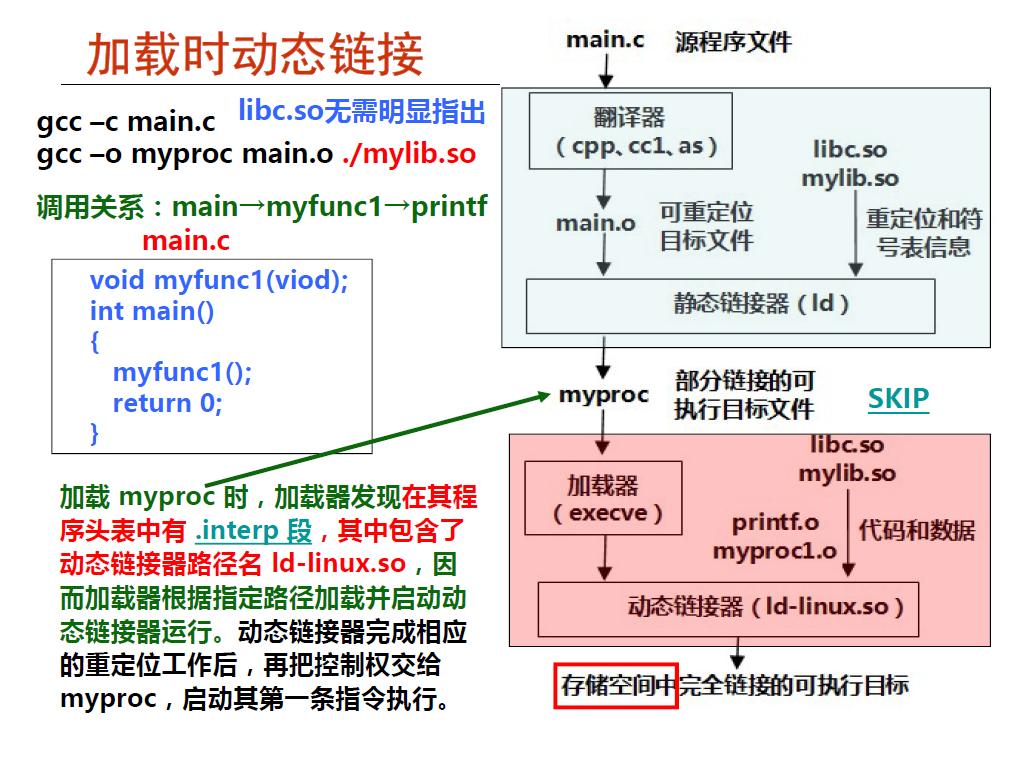
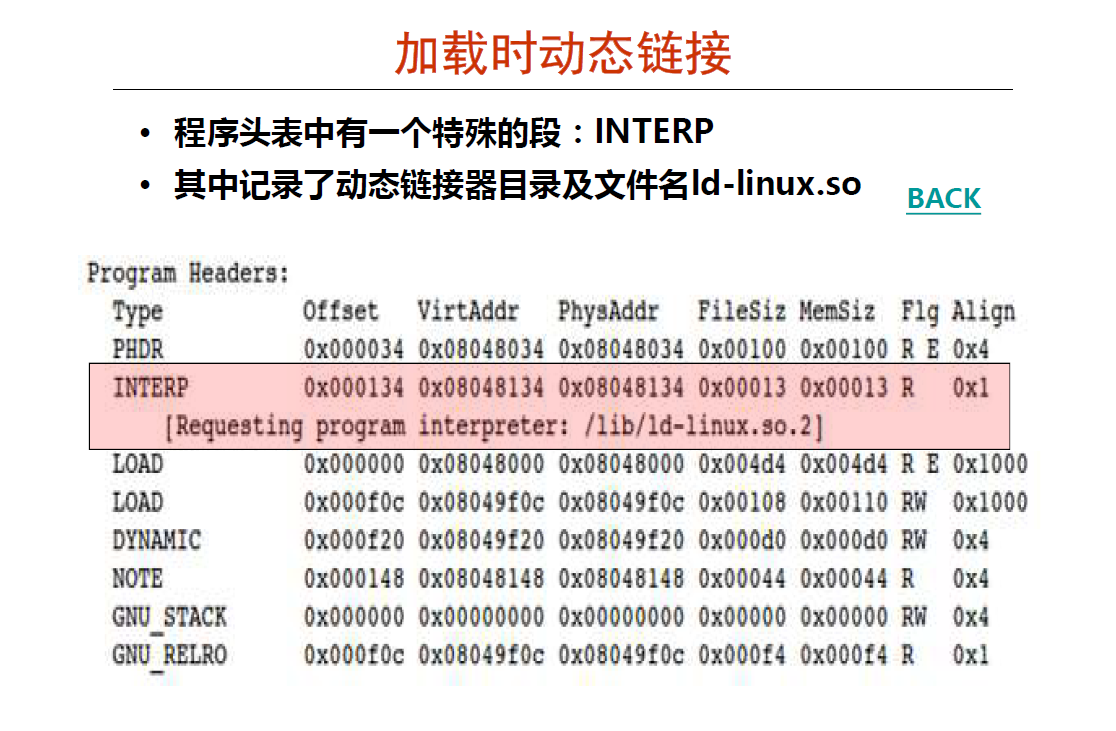
当发现有一个 .interp 的段(section)的时候就会触发动态连接. 我们这里并没有深入动态链接器(ld-linux.so) 的工作原理 ,不过基本也可以才到它的主要工作就是加载共享库到内存中去并且映射到各个进程的内存映射区域去 ,然后后面的工作就有点像静态链接一样, 修改调用的地址了.
2.运行时动态链接

动态链接的的另外一种方式这是通过代码调用, 再加载到程序中去
PIC

从上面的讲义中, 我们可以知道引入PIC的目的是 链接器无需修改代码即可将共享库加载到任意地址运行
PIC 的实现
实现位置无关代码(PIC)所依赖的理论依据其中之一是:在链接阶段,链接器就已经知道代码段和数据段之间的偏移。 当链接器将若干个目标文件链接在一起时,它会将相似段合并(例如,将所有的代码段合并成一个大的段,段的名称依然叫代码段)。 所以,链接器是知道每个段的大小以及段与段之间的相对位置的。
来看一个例子,假设代码段之后紧接着就是数据段,那么代码段中的任何一条指令与数据段的开始之间的偏移就是代码段的大小减去指令到代码段开始的偏移 —— 当然,这两个值链接器都是知道的。
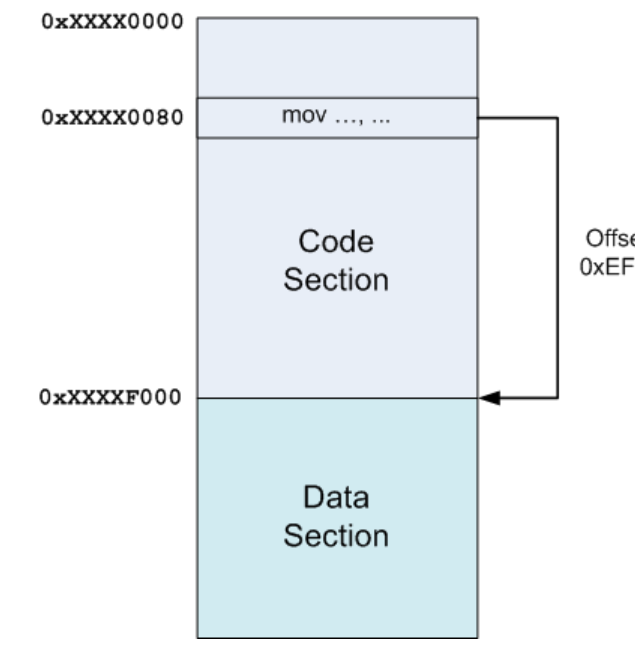
在上图中,可以看到代码段的加载地址(这个地址在链接阶段是不知道的)是0xXXXX0000(X代表任意值),而且数据段紧跟其后,加载地址为0xXXXXF000。 如果代码段内偏移0x80处的指令需要访问数据段中的数据,那么链接器就会知道指令与所需访问数据之间的相对偏移(在这里相对偏移是0xEF80),并且将这个相对偏移硬编码于指令中。
上面的理论依据只有在我们需要相对偏移时才有用,可是在x86架构上的数据访问却需要数据的绝对地址(例如mov指令),那我们怎么做呢?
如果已知相对地址,然后需要其绝对地址,那么我们还需要知道的就是指令指针(instruction pointer)的值(因为依据定义,相对地址是相对于指令位置的地址)。 遗憾的是X86架构没有直接获得指令指针的值的指令,不过我们可以利用一个小技巧来获得,如下面的汇编伪代码所示:
call tmep
tmep:
pop ebx
解释如下:
1.CPU执行了call TMPLABEL,所以会将下一条指令(就是pop ebx)的地址压入栈顶,然后跳到TMPLABEL标签处。
2.因为在标签TMPLABEL处的指令是pop ebx,所以接下来就执行它,它会从栈顶取出一个值存入寄存器ebx。 这样就可以知道这个值就是这条指令本身的地址,所以此时ebx实际上就包含了指令指针的值。
理解了上面所说的,我们终于可以开始看看位置无关代码(PIC)是如何在X86架构上实现的了。主要是利用全局偏移表(global offset table)来实现的,全局偏移表简称GOT。
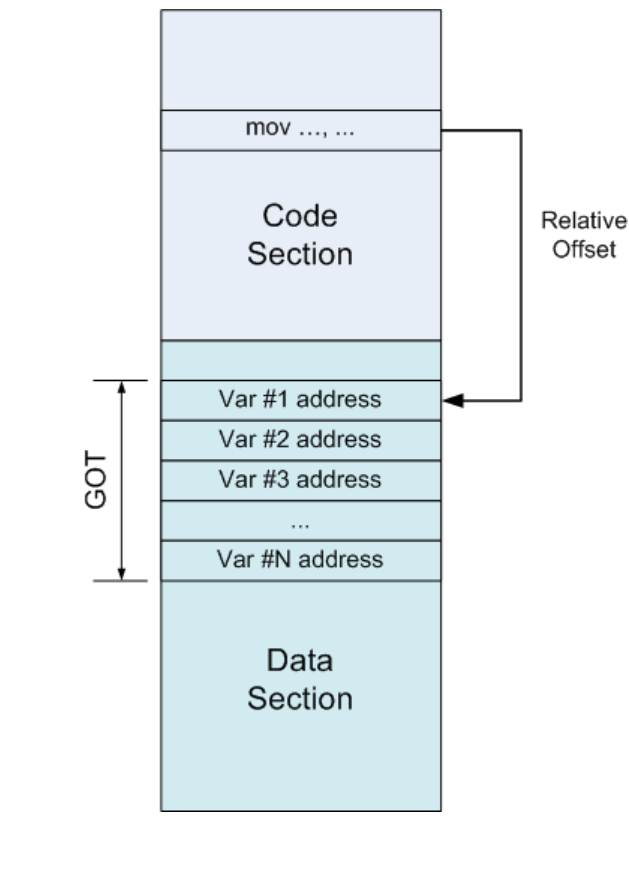
可以看到GOT 放在了 Data 节的开头处 , 一个GOT就是一个简单的指针数组,位于数据段中。 假设代码段中有一些指令需要访问数据,那么它们不会使用绝对地址(因为这需要重定位操作),而是会引用GOT中的一个项。 因为GOT位于数据段中,所以链接器知道对GOT中项的引用是使用的相对地址。GOT中的项实际就是变量的绝对地址 .
我们可以看到饶了一大圈 ,我们还是的最终解析绝对地址 ,只是说中间多了一层 GOT , 那么使用 GOT 的好处是什么呢?
1.如果是代码段的重定位,那么链接器会为代码中每一次的变量引用执行重定位操作,而如果使用GOT的话,只需为每一个变量执行一次重定位操作。因为程序中极有可能会对一个变量引用多次,那么只执行一次重定位操作,势必会在程序启动阶段节约大量的时间。
2.因为数据段是可写的,并且在进程间是不共享的,所以在数据段执行重定位操作并没有什么伤害。再者,将重定位操作从代码段移至数据段,就可以将代码段设置成可读的,并且可以在多个进程间共享。
PIC-延迟加载
延迟加载 ,就和我们学 spring bean的时候的懒加载 ,等到需要用到的时候我再加载这个 bean , 之前没有用到我就先不进行加载 . 具体的做法是用到了一个叫PLT 的结构
延迟加载过程
过程如下 :

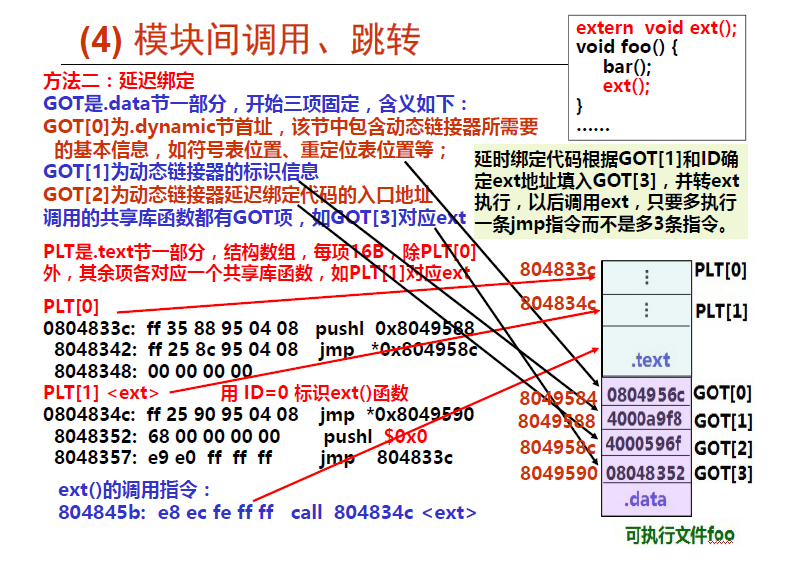
左图 展示了 GOT 和 PLT 如何协同工作,在 addvec 被第一次调用时,延迟解析它的运行时地址:
- 第 1 步。不直接调用 addvec,程序调用进入 PLT[2],这是 addvec 的 PLT 条目。
- 第 2 步。第一条 PLT 指令通过 GOT[4] 进行间接跳转。因为每个 GOT 条目初始时都指向它对应的 PLT 条目的第二条指令,这个间接跳转只是简单地把控制传送回 PLT[2] 中的下一条指令。
- 第 3 步。在把 addvec 的 ID(0x1)压入栈中之后,PLT[2] 跳转到 PLT[0]。
- 第 4 步。PLT[0] 通过 GOT[1] 间接地把动态链接器的一个参数压入栈中,然后通过 GOT[2] 间接跳转进动态链接器中。动态链接器使用两个栈条目来确定 addvec 的运行时位置,用这个地址重写 GOT[4],再把控制传递给 addvec。
右图 给出的是后续再调用 addvec 时的控制流:
- 第 1 步。和前面一样,控制传递到 PLT[2]。
- 第 2 步。不过这次通过 GOT[4] 的间接跳转会将控制直接转移到 addvec。
补充
讲义中提到的

PIC 的引用的四种情况实际上就是上面我们讲到过程 , 只是讲义把成4种情况来讲.


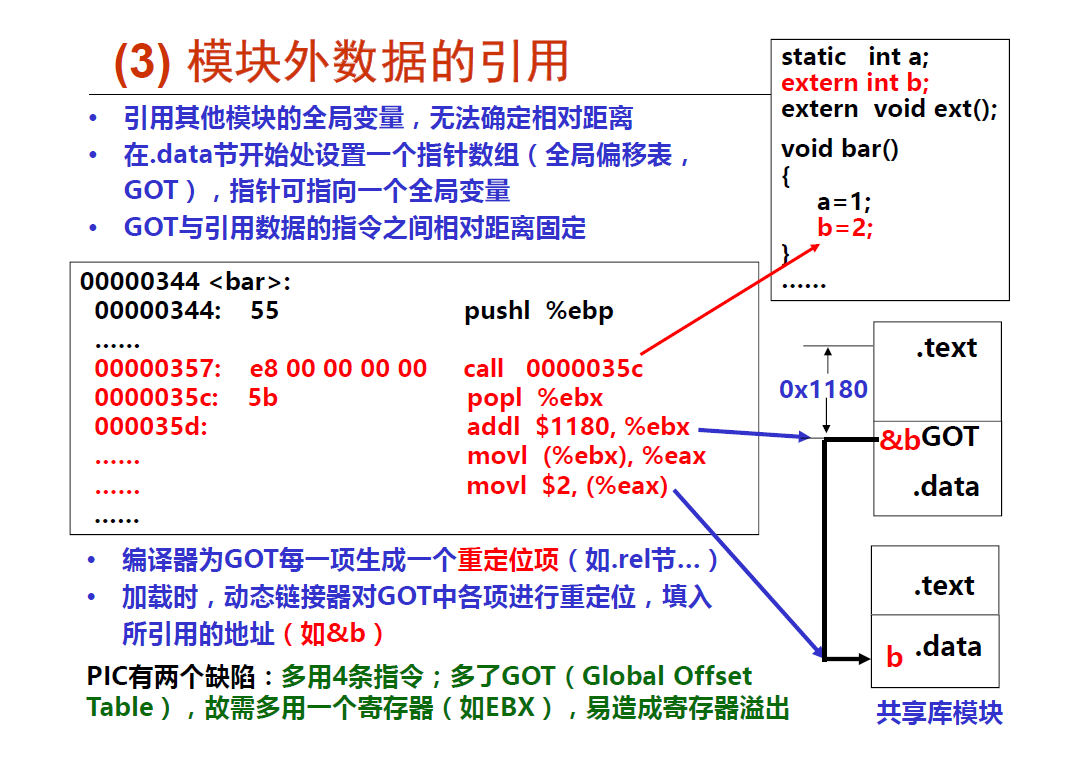
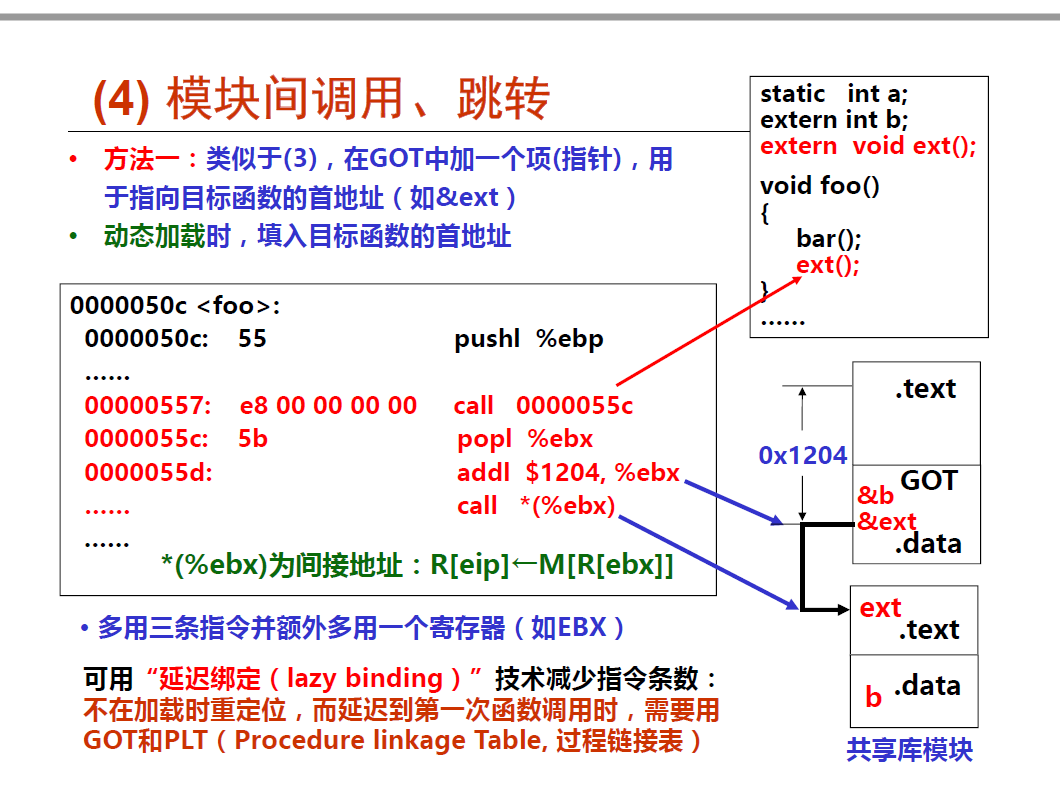
思想都是一样了, 利用了 在链接阶段,链接器就已经知道代码段和数据段之间的偏移。 当链接器将若干个目标文件链接在一起时,它会将相似段合并(例如,将所有的代码段合并成一个大的段,段的名称依然叫代码段)。 所以,链接器是知道每个段的大小以及段与段之间的相对位置的。
其他
共享库是如何加载到各个进程的虚拟空间的呢?
虚拟空间地址中有一块区域是专门存放内存映射的 :
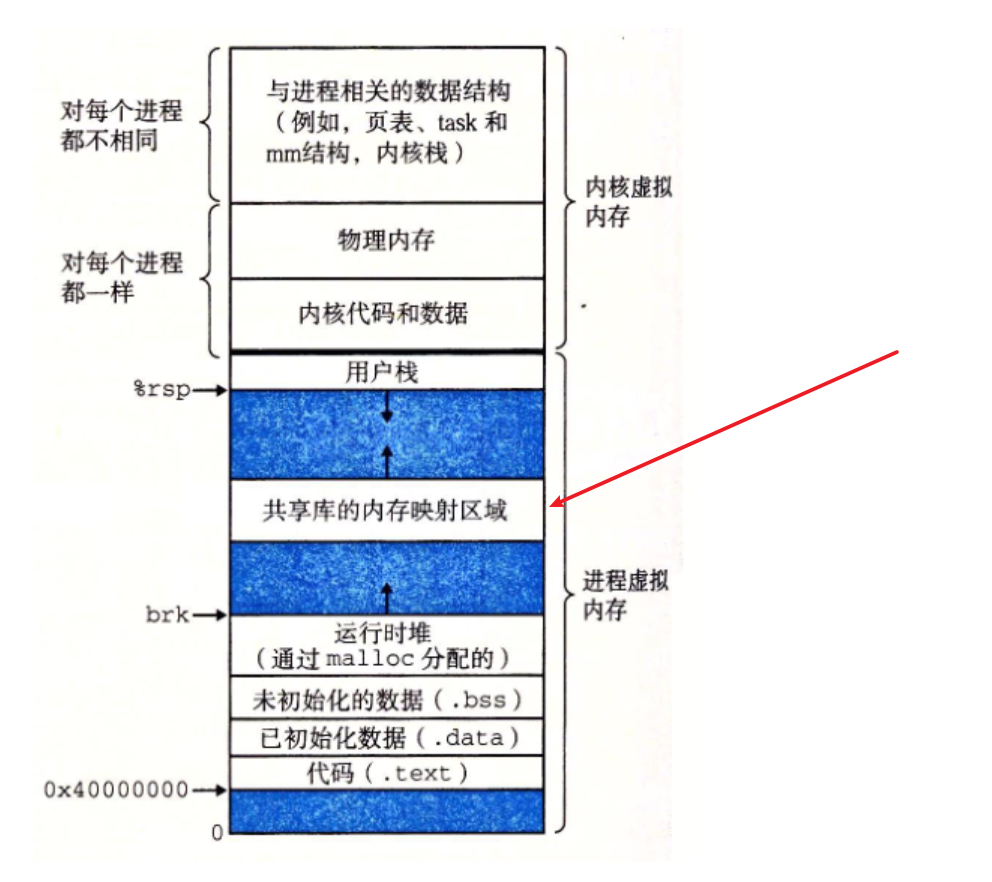
内存映射段(mmap)
内核将硬盘文件的内容直接映射到内存, 任何应用程序都可通过Linux的mmap()系统调用或Windows的CreateFileMapping()/MapViewOfFile()请求这种映射。内存映射是一种方便高效的文件I/O方式, 因而被用于装载动态共享库。用户也可创建匿名内存映射,该映射没有对应的文件, 可用于存放程序数据。在 Linux中,若通过malloc()请求一大块内存,C运行库将创建一个匿名内存映射,而不使用堆内存。”大块” 意味着比阈值 MMAP_THRESHOLD还大,缺省为128KB,可通过mallopt()调整。
该区域用于映射可执行文件用到的动态链接库。在Linux 2.4版本中,若可执行文件依赖共享库,则系统会为这些动态库在从0x40000000开始的地址分配相应空间,并在程序装载时将其载入到该空间。在Linux 2.6内核中,共享库的起始地址被往上移动至更靠近栈区的位置。
从进程地址空间的布局可以看到,在有共享库的情况下,留给堆的可用空间还有两处:一处是从.bss段到0x40000000,约不到1GB的空间;另一处是从共享库到栈之间的空间,约不到2GB。这两块空间大小取决于栈、共享库的大小和数量。这样来看,是否应用程序可申请的最大堆空间只有2GB?事实上,这与Linux内核版本有关。在上面给出的进程地址空间经典布局图中,共享库的装载地址为0x40000000,这实际上是Linux kernel 2.6版本之前的情况了,在2.6版本里,共享库的装载地址已经被挪到靠近栈的位置,即位于0xBFxxxxxx附近,因此,此时的堆范围就不会被共享库分割成2个“碎片”,故kernel 2.6的32位Linux系统中,malloc申请的最大内存理论值在2.9GB左右。
参考
- https://eli.thegreenplace.net/2011/08/25/load-time-relocation-of-shared-libraries/
- https://eli.thegreenplace.net/2011/11/03/position-independent-code-pic-in-shared-libraries
- https://www.cnblogs.com/tekkaman/archive/2013/03/04/2943118.html
- https://juejin.cn/post/6844903609558106125
- https://hansimov.gitbook.io/csapp/part2/ch07-linking/7.10-dynamic-linking-with-shared-libraries
- https://hansimov.gitbook.io/csapp/part2/ch07-linking/7.12-position-independent-code
- https://blog.csdn.net/astrotycoon/article/details/8456453 (重要)
- https://www.jianshu.com/p/eece39beee20 (mmap)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号