泛型
一、泛型 Generic
不指定泛型的容器,可以存放任何类型的元素
指定了泛型的容器,只能存放指定类型的元素以及其子类
package property;
public class Item {
String name;
int price;
public Item(){
}
//提供一个初始化name的构造方法
public Item(String name){
this.name = name;
}
public void effect(){
System.out.println("物品使用后,可以有效果");
}
}
package collection;
import java.util.ArrayList;
import java.util.List;
import property.Item;
import charactor.APHero;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
//对于不使用泛型的容器,可以往里面放英雄,也可以往里面放物品
List heros = new ArrayList();
heros.add(new Hero("盖伦"));
//本来用于存放英雄的容器,现在也可以存放物品了
heros.add(new Item("冰杖"));
//对象转型会出现问题
Hero h1= (Hero) heros.get(0);
//尤其是在容器里放的对象太多的时候,就记不清楚哪个位置放的是哪种类型的对象了
Hero h2= (Hero) heros.get(1);
//引入泛型Generic
//声明容器的时候,就指定了这种容器,只能放Hero,放其他的就会出错
List<Hero> genericheros = new ArrayList<Hero>();
genericheros.add(new Hero("盖伦"));
//如果不是Hero类型,根本就放不进去
//genericheros.add(new Item("冰杖"));
//除此之外,还能存放Hero的子类
genericheros.add(new APHero());
//并且在取出数据的时候,不需要再进行转型了,因为里面肯定是放的Hero或者其子类
Hero h = genericheros.get(0);
}
}
二、泛型的简写
为了不使编译器出现警告,需要前后都使用泛型,像这样:
List<Hero> genericheros = new ArrayList<Hero>();
不过JDK7提供了一个可以略微减少代码量的泛型简写方式
List<Hero> genericheros2 = new ArrayList<>();
后面的泛型可以用<>来代替,聊胜于无吧
package collection;
import java.util.ArrayList;
import java.util.List;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
List<Hero> genericheros = new ArrayList<Hero>();
List<Hero> genericheros2 = new ArrayList<>();
}
}
ArrayList遍历
| 关键字 | 简介 | 示例代码 |
|---|---|---|
| for | 用for循环遍历 | 示例代码 |
| iterator | 迭代器遍历 | 示例代码 |
| for: | 用增强型for循环 | 示例代码 |
步骤1:用for循环遍历
通过前面的学习,知道了可以用size()和get()分别得到大小,和获取指定位置的元素,结合for循环就可以遍历出ArrayList的内容
package collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
List<Hero> heros = new ArrayList<Hero>();
// 放5个Hero进入容器
for (int i = 0; i < 5; i++) {
heros.add(new Hero("hero name " + i));
}
// 第一种遍历 for循环
System.out.println("--------for 循环-------");
for (int i = 0; i < heros.size(); i++) {
Hero h = heros.get(i);
System.out.println(h);
}
}
}
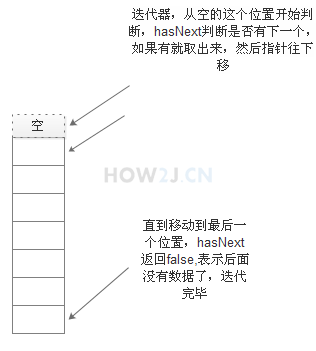
步骤2:迭代器遍历
使用迭代器Iterator遍历集合中的元素
package collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
List<Hero> heros = new ArrayList<Hero>();
//放5个Hero进入容器
for (int i = 0; i < 5; i++) {
heros.add(new Hero("hero name " +i));
}
//第二种遍历,使用迭代器
System.out.println("--------使用while的iterator-------");
Iterator<Hero> it= heros.iterator();
//从最开始的位置判断"下一个"位置是否有数据
//如果有就通过next取出来,并且把指针向下移动
//直到"下一个"位置没有数据
while(it.hasNext()){
Hero h = it.next();
System.out.println(h);
}
//迭代器的for写法
System.out.println("--------使用for的iterator-------");
for (Iterator<Hero> iterator = heros.iterator(); iterator.hasNext();) {
Hero hero = (Hero) iterator.next();
System.out.println(hero);
}
}
}
步骤3:用增强型for循环
使用增强型for循环可以非常方便的遍历ArrayList中的元素,这是很多开发人员的首选。
不过增强型for循环也有不足:
无法用来进行ArrayList的初始化
无法得知当前是第几个元素了,当需要只打印单数元素的时候,就做不到了。 必须再自定下标变量。
package collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
List<Hero> heros = new ArrayList<Hero>();
// 放5个Hero进入容器
for (int i = 0; i < 5; i++) {
heros.add(new Hero("hero name " + i));
}
// 第三种,增强型for循环
System.out.println("--------增强型for循环-------");
for (Hero h : heros) {
System.out.println(h);
}
}
}
其他集合LinkedList
序列分先进先出FIFO,先进后出FILO
FIFO在Java中又叫Queue 队列
FILO在Java中又叫Stack 栈
示例1:LinkedList与List接口
与ArrayList一样,LinkedList也实现了List接口,诸如add,remove,contains等等方法。 详细使用,请参考 ArrayList 常用方法,在此不作赘述。
接下来要讲的是LinkedList的一些特别的地方
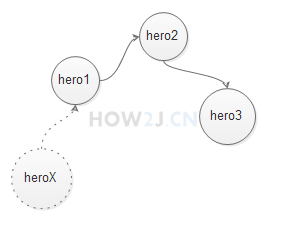
示例2:双向链表-Deque
除了实现了List接口外,LinkedList还实现了双向链表结构Deque,可以很方便的在头尾插入删除数据
什么是链表结构: 与数组结构相比较,数组结构,就好像是电影院,每个位置都有标示,每个位置之间的间隔都是一样的。 而链表就相当于佛珠,每个珠子,只连接前一个和后一个,不用关心除此之外的其他佛珠在哪里。
package collection;
import java.util.LinkedList;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
//LinkedList是一个双向链表结构的list
LinkedList<Hero> ll =new LinkedList<Hero>();
//所以可以很方便的在头部和尾部插入数据
//在最后插入新的英雄
ll.addLast(new Hero("hero1"));
ll.addLast(new Hero("hero2"));
ll.addLast(new Hero("hero3"));
System.out.println(ll);
//在最前面插入新的英雄
ll.addFirst(new Hero("heroX"));
System.out.println(ll);
//查看最前面的英雄
System.out.println(ll.getFirst());
//查看最后面的英雄
System.out.println(ll.getLast());
//查看不会导致英雄被删除
System.out.println(ll);
//取出最前面的英雄
System.out.println(ll.removeFirst());
//取出最后面的英雄
System.out.println(ll.removeLast());
//取出会导致英雄被删除
System.out.println(ll);
}
}
步骤3:队列-Queue
LinkedList 除了实现了List和Deque外,还实现了Queue接口(队列)。
Queue是先进先出队列 FIFO,常用方法:
offer 在最后添加元素
poll 取出第一个元素
peek 查看第一个元素
package collection;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
//和ArrayList一样,LinkedList也实现了List接口
List ll =new LinkedList<Hero>();
//所不同的是LinkedList还实现了Deque,进而又实现了Queue这个接口
//Queue代表FIFO 先进先出的队列
Queue<Hero> q= new LinkedList<Hero>();
//加在队列的最后面
System.out.print("初始化队列:\t");
q.offer(new Hero("Hero1"));
q.offer(new Hero("Hero2"));
q.offer(new Hero("Hero3"));
q.offer(new Hero("Hero4"));
System.out.println(q);
System.out.print("把第一个元素取poll()出来:\t");
//取出第一个Hero,FIFO 先进先出
Hero h = q.poll();
System.out.println(h);
System.out.print("取出第一个元素之后的队列:\t");
System.out.println(q);
//把第一个拿出来看一看,但是不取出来
h=q.peek();
System.out.print("查看peek()第一个元素:\t");
System.out.println(h);
System.out.print("查看并不会导致第一个元素被取出来:\t");
System.out.println(q);
}
}
其他集合二叉树
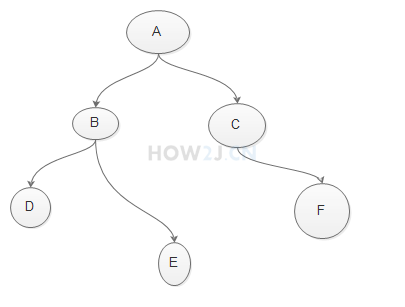
示例1:二叉树感念
二叉树由各种节点组成
二叉树特点:
每个节点都可以有左子节点,右子节点
每一个节点都有一个值
package collection;
public class Node {
// 左子节点
public Node leftNode;
// 右子节点
public Node rightNode;
// 值
public Object value;
}
示例2:二叉树排序-插入数据
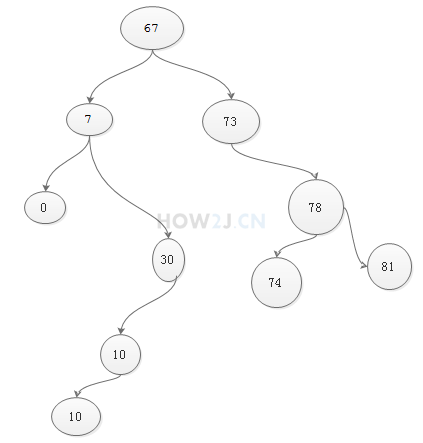
假设通过二叉树对如下10个随机数进行排序
67,7,30,73,10,0,78,81,10,74
排序的第一个步骤是把数据插入到该二叉树中
插入基本逻辑是,小、相同的放左边,大的放右边
\1. 67 放在根节点
\2. 7 比 67小,放在67的左节点
\3. 30 比67 小,找到67的左节点7,30比7大,就放在7的右节点
\4. 73 比67大, 放在67的右节点
\5. 10 比 67小,找到67的左节点7,10比7大,找到7的右节点30,10比30小,放在30的左节点。
...
...
\9. 10比67小,找到67的左节点7,10比7大,找到7的右节点30,10比30小,找到30的左节点10,10和10一样大,放在左边
package collection;
public class Node {
// 左子节点
public Node leftNode;
// 右子节点
public Node rightNode;
// 值
public Object value;
// 插入 数据
public void add(Object v) {
// 如果当前节点没有值,就把数据放在当前节点上
if (null == value)
value = v;
// 如果当前节点有值,就进行判断,新增的值与当前值的大小关系
else {
// 新增的值,比当前值小或者相同
if ((Integer) v -((Integer)value) <= 0) {
if (null == leftNode)
leftNode = new Node();
leftNode.add(v);
}
// 新增的值,比当前值大
else {
if (null == rightNode)
rightNode = new Node();
rightNode.add(v);
}
}
}
public static void main(String[] args) {
int randoms[] = new int[] { 67, 7, 30, 73, 10, 0, 78, 81, 10, 74 };
Node roots = new Node();
for (int number : randoms) {
roots.add(number);
}
}
}
示例3:二叉树排序-遍历
通过上一个步骤的插入行为,实际上,数据就已经排好序了。 接下来要做的是看,把这些已经排好序的数据,遍历成我们常用的List或者数组的形式
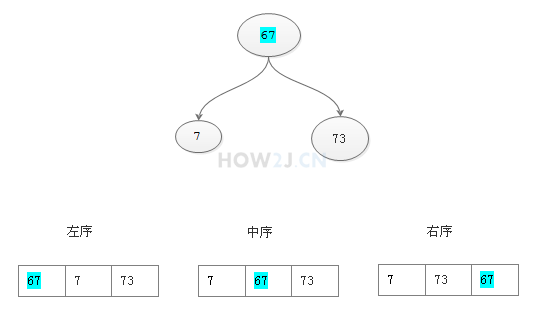
二叉树的遍历分左序,中序,右序
左序即: 中间的数遍历后放在左边
中序即: 中间的数遍历后放在中间
右序即: 中间的数遍历后放在右边
如图所见,我们希望遍历后的结果是从小到大的,所以应该采用中序遍历
package collection;
import java.util.ArrayList;
import java.util.List;
public class Node {
// 左子节点
public Node leftNode;
// 右子节点
public Node rightNode;
// 值
public Object value;
// 插入 数据
public void add(Object v) {
// 如果当前节点没有值,就把数据放在当前节点上
if (null == value)
value = v;
// 如果当前节点有值,就进行判断,新增的值与当前值的大小关系
else {
// 新增的值,比当前值小或者相同
if ((Integer) v -((Integer)value) <= 0) {
if (null == leftNode)
leftNode = new Node();
leftNode.add(v);
}
// 新增的值,比当前值大
else {
if (null == rightNode)
rightNode = new Node();
rightNode.add(v);
}
}
}
// 中序遍历所有的节点
public List<Object> values() {
List<Object> values = new ArrayList<>();
// 左节点的遍历结果
if (null != leftNode)
values.addAll(leftNode.values());
// 当前节点
values.add(value);
// 右节点的遍历结果
if (null != rightNode)
values.addAll(rightNode.values());
return values;
}
public static void main(String[] args) {
int randoms[] = new int[] { 67, 7, 30, 73, 10, 0, 78, 81, 10, 74 };
Node roots = new Node();
for (int number : randoms) {
roots.add(number);
}
System.out.println(roots.values());
}
}
其他集合HashMap
示例1:HashMap的键值对
HashMap储存数据的方式是—— 键值对
package collection;
import java.util.HashMap;
public class TestCollection {
public static void main(String[] args) {
HashMap<String,String> dictionary = new HashMap<>();
dictionary.put("adc", "物理英雄");
dictionary.put("apc", "魔法英雄");
dictionary.put("t", "坦克");
System.out.println(dictionary.get("t"));
}
}
示例2:键不能重复,值可以重复
对于HashMap而言,key是唯一的,不可以重复的。
所以,以相同的key 把不同的value插入到 Map中会导致旧元素被覆盖,只留下最后插入的元素。
不过,同一个对象可以作为值插入到map中,只要对应的key不一样
package collection;
import java.util.HashMap;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
HashMap<String,Hero> heroMap = new HashMap<String,Hero>();
heroMap.put("gareen", new Hero("gareen1"));
System.out.println(heroMap);
//key为gareen已经有value了,再以gareen作为key放入数据,会导致原英雄,被覆盖
//不会增加新的元素到Map中
heroMap.put("gareen", new Hero("gareen2"));
System.out.println(heroMap);
//清空map
heroMap.clear();
Hero gareen = new Hero("gareen");
//同一个对象可以作为值插入到map中,只要对应的key不一样
heroMap.put("hero1", gareen);
heroMap.put("hero2", gareen);
System.out.println(heroMap);
}
}
示例3:查找内容性能比较
准备一个ArrayList其中存放3000000(三百万个)Hero对象,其名称是随机的,格式是hero-[4位随机数]
hero-3229
hero-6232
hero-9365
...
因为总数很大,所以几乎每种都有重复,把名字叫做 hero-5555的所有对象找出来
要求使用两种办法来寻找
\1. 不使用HashMap,直接使用for循环找出来,并统计花费的时间
\2. 借助HashMap,找出结果,并统计花费的时间
package collection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
List<Hero> hs =new ArrayList<>();
System.out.println("初始化开始");
for (int i = 0; i < 3000000; i++) {
Hero h = new Hero( "hero-" + random());
hs.add(h);
}
//名字作为key
//名字相同的hero,放在一个List中,作为value
HashMap<String,List<Hero>> heroMap =new HashMap();
for (Hero h : hs) {
List<Hero> list= heroMap.get( h.name);
if(list==null){
list = new ArrayList<>();
heroMap.put(h.name, list);
}
list.add(h);
}
System.out.println("初始化结束");
System.out.println("开始查找");
findByIteration(hs);
findByMap(heroMap);
}
private static List<Hero> findByMap(HashMap<String,List<Hero>> m) {
long start =System.currentTimeMillis();
List <Hero>result= m.get("hero-5555");
long end =System.currentTimeMillis();
System.out.printf("通过map查找,一共找到%d个英雄,耗时%d 毫秒%n",result.size(),end-start);
return result;
}
private static List<Hero> findByIteration (List<Hero> hs) {
long start =System.currentTimeMillis();
List<Hero> result =new ArrayList<>();
for (Hero h : hs) {
if(h.name.equals("hero-5555")){
result.add(h);
}
}
long end =System.currentTimeMillis();
System.out.printf("通过for查找,一共找到%d个英雄,耗时%d 毫秒%n", result.size(),end-start);
return result;
}
public static int random(){
return ((int)(Math.random()*9000)+1000);
}
}
需要注意的是:
Map的key是字符串,英雄的名称
Map的value是List,里面放了名称相同的多个英雄
其他集合HashSet
示例1:元素不重复
Set中的元素,不能重复
package collection;
import java.util.HashSet;
public class TestCollection {
public static void main(String[] args) {
HashSet<String> names = new HashSet<String>();
names.add("gareen");
System.out.println(names);
//第二次插入同样的数据,是插不进去的,容器中只会保留一个
names.add("gareen");
System.out.println(names);
}
}
示例2:没有顺序
Set中的元素,没有顺序。
严格的说,是没有按照元素的插入顺序排列
HashSet的具体顺序,既不是按照插入顺序,也不是按照hashcode的顺序。
以下是HashSet源代码中的部分注释
/**
\* It makes no guarantees as to the iteration order of the set;
\* in particular, it does not guarantee that the order will remain constant over time.
*/
不保证Set的迭代顺序; 确切的说,在不同条件下,元素的顺序都有可能不一样
换句话说,同样是插入0-9到HashSet中, 在JVM的不同版本中,看到的顺序都是不一样的。 所以在开发的时候,不能依赖于某种臆测的顺序,这个顺序本身是不稳定的
package collection;
import java.util.HashSet;
public class TestCollection {
public static void main(String[] args) {
HashSet<Integer> numbers = new HashSet<Integer>();
numbers.add(9);
numbers.add(5);
numbers.add(1);
// Set中的元素排列,不是按照插入顺序
System.out.println(numbers);
}
}
示例3:遍历
Set不提供get()来获取指定位置的元素
所以遍历需要用到迭代器,或者增强型for循环
package collection;
import java.util.HashSet;
import java.util.Iterator;
public class TestCollection {
public static void main(String[] args) {
HashSet<Integer> numbers = new HashSet<Integer>();
for (int i = 0; i < 20; i++) {
numbers.add(i);
}
//Set不提供get方法来获取指定位置的元素
//numbers.get(0)
//遍历Set可以采用迭代器iterator
for (Iterator<Integer> iterator = numbers.iterator(); iterator.hasNext();) {
Integer i = (Integer) iterator.next();
System.out.println(i);
}
//或者采用增强型for循环
for (Integer i : numbers) {
System.out.println(i);
}
}
}
示例4:HashSet和HashMap的关系
通过观察HashSet的源代码
可以发现HashSet自身并没有独立的实现,而是在里面封装了一个Map.
HashSet是作为Map的key而存在的
而value是一个命名为PRESENT的static的Object对象,因为是一个类属性,所以只会有一个。
private static final Object PRESENT = new Object();
package collection;
import java.util.AbstractSet;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
//HashSet里封装了一个HashMap
private HashMap<E,Object> map;
private static final Object PRESENT = new Object();
//HashSet的构造方法初始化这个HashMap
public HashSet() {
map = new HashMap<E,Object>();
}
//向HashSet中增加元素,其实就是把该元素作为key,增加到Map中
//value是PRESENT,静态,final的对象,所有的HashSet都使用这么同一个对象
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
//HashSet的size就是map的size
public int size() {
return map.size();
}
//清空Set就是清空Map
public void clear() {
map.clear();
}
//迭代Set,就是把Map的键拿出来迭代
public Iterator<E> iterator() {
return map.keySet().iterator();
}
}
示例5:练习
创建一个长度是100的字符串数组
使用长度是2的随机字符填充该字符串数组
统计这个字符串数组里重复的字符串有多少种
使用HashSet来解决这个问题
package collection;
import java.util.HashSet;
public class TestCollection {
public static void main(String[] args) {
String[] ss = new String[100];
// 初始化
for (int i = 0; i < ss.length; i++) {
ss[i] = randomString(2);
}
// 打印
for (int i = 0; i < ss.length; i++) {
System.out.print(ss[i] + " ");
if (19 == i % 20)
System.out.println();
}
HashSet<String> result = new HashSet<>();
for (String s1 : ss) {
int repeat = 0;
for (String s2 : ss) {
if (s1.equalsIgnoreCase(s2)) {
repeat++;
if (2 == repeat) {
// 当repeat==2的时候,就找到了一个非己的重复字符串
result.add(s2);
break;
}
}
}
}
System.out.printf("总共有 %d种重复的字符串%n", result.size());
if (result.size() != 0) {
System.out.println("分别是:");
for (String s : result) {
System.out.print(s + " ");
}
}
}
private static String randomString(int length) {
String pool = "";
for (short i = '0'; i <= '9'; i++) {
pool += (char) i;
}
for (short i = 'a'; i <= 'z'; i++) {
pool += (char) i;
}
for (short i = 'A'; i <= 'Z'; i++) {
pool += (char) i;
}
char cs[] = new char[length];
for (int i = 0; i < cs.length; i++) {
int index = (int) (Math.random() * pool.length());
cs[i] = pool.charAt(index);
}
String result = new String(cs);
return result;
}
}
其他集合Collection
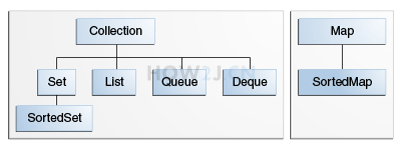
Collection是一个接口
Collection是 Set List Queue和 Deque的接口
Queue: 先进先出队列
Deque: 双向链表
注:Collection和Map之间没有关系,Collection是放一个一个对象的,Map 是放键值对的
注:Deque 继承 Queue,间接的继承了 Collection
其他集合Collections
Collections是一个类,容器的工具类,就如同Arrays是数组的工具类
| 关键字 | 简介 | 示例代码 |
|---|---|---|
| reverse | 反转 | 示例代码 |
| shuffle | 混淆 | 示例代码 |
| sort | 排序 | 示例代码 |
| swap | 交换 | 示例代码 |
| rotate | 滚动 | 示例代码 |
| synchronizedList | 线程安全化 | 示例代码 |
步骤1:反转
reverse 使List中的数据发生翻转
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollection {
public static void main(String[] args) {
//初始化集合numbers
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 10; i++) {
numbers.add(i);
}
System.out.println("集合中的数据:");
System.out.println(numbers);
Collections.reverse(numbers);
System.out.println("翻转后集合中的数据:");
System.out.println(numbers);
}
}
步骤2:混淆
shuffle 混淆List中数据的顺序
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollection {
public static void main(String[] args) {
//初始化集合numbers
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 10; i++) {
numbers.add(i);
}
System.out.println("集合中的数据:");
System.out.println(numbers);
Collections.shuffle(numbers);
System.out.println("混淆后集合中的数据:");
System.out.println(numbers);
}
}
步骤3:排序
sort 对List中的数据进行排序
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollection {
public static void main(String[] args) {
//初始化集合numbers
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 10; i++) {
numbers.add(i);
}
System.out.println("集合中的数据:");
System.out.println(numbers);
Collections.shuffle(numbers);
System.out.println("混淆后集合中的数据:");
System.out.println(numbers);
Collections.sort(numbers);
System.out.println("排序后集合中的数据:");
System.out.println(numbers);
}
}
步骤4:交换
swap 交换两个数据的位置
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollection {
public static void main(String[] args) {
//初始化集合numbers
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 10; i++) {
numbers.add(i);
}
System.out.println("集合中的数据:");
System.out.println(numbers);
Collections.swap(numbers,0,5);
System.out.println("交换0和5下标的数据后,集合中的数据:");
System.out.println(numbers);
}
}
步骤5:滚动
rotate 把List中的数据,向右滚动指定单位的长度
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollection {
public static void main(String[] args) {
//初始化集合numbers
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 10; i++) {
numbers.add(i);
}
System.out.println("集合中的数据:");
System.out.println(numbers);
Collections.rotate(numbers,2);
System.out.println("把集合向右滚动2个单位,标的数据后,集合中的数据:");
System.out.println(numbers);
}
}
步骤6:线程安全化
synchronizedList 把非线程安全的List转换为线程安全的List。
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollection {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
System.out.println("把非线程安全的List转换为线程安全的List");
List<Integer> synchronizedNumbers = (List<Integer>) Collections.synchronizedList(numbers);
}
}
ArrayList vs HashSet
示例1:是否有顺序
ArrayList: 有顺序
HashSet: 无顺序
HashSet的具体顺序,既不是按照插入顺序,也不是按照hashcode的顺序。关于hashcode有专门的章节讲解: hashcode 原理。
以下是HasetSet源代码中的部分注释
/**
\* It makes no guarantees as to the iteration order of the set;
\* in particular, it does not guarantee that the order will remain constant over time.
*/
不保证Set的迭代顺序; 确切的说,在不同条件下,元素的顺序都有可能不一样
换句话说,同样是插入0-9到HashSet中, 在JVM的不同版本中,看到的顺序都是不一样的。 所以在开发的时候,不能依赖于某种臆测的顺序,这个顺序本身是不稳定的
示例2:能否重复
List中的数据可以重复
Set中的数据不能够重复
重复判断标准是:
首先看hashcode是否相同
如果hashcode不同,则认为是不同数据
如果hashcode相同,再比较equals,如果equals相同,则是相同数据,否则是不同数据
更多关系hashcode,请参考hashcode原理
练习:生成50个 0-9999之间的随机数,要求不能有重复的
使用Set来存放随机数,不断的向里塞,直到塞满50个位置。 因为Set有不重复的特性,所以最后得到的50个,就一定是不重复的
package collection;
import java.util.HashSet;
import java.util.Set;
public class TestCollection {
public static void main(String[] args) {
Set<Integer> numbers =new HashSet<>();
while(numbers.size()<50){
int i = (int) (Math.random()*10000);
numbers.add(i);
}
System.out.println("得到50个不重复随机数:");
System.out.println(numbers);
}
}
ArrayList vs LinkedList
示例1:ArrayList和LinkedList的区别
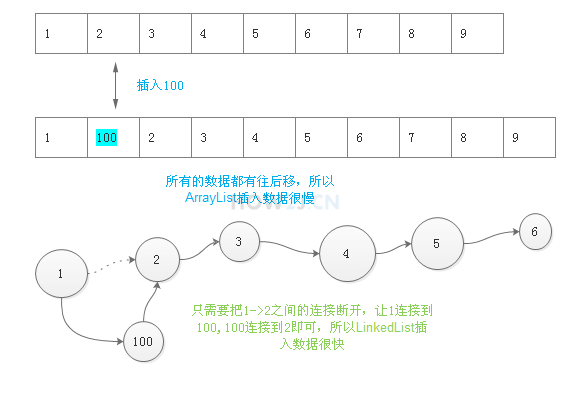
ArrayList 插入,删除数据慢
LinkedList, 插入,删除数据快
ArrayList是顺序结构,所以定位很快,指哪找哪。 就像电影院位置一样,有了电影票,一下就找到位置了。
LinkedList 是链表结构,就像手里的一串佛珠,要找出第99个佛珠,必须得一个一个的数过去,所以定位慢
示例2:插入数据
package collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class TestCollection {
public static void main(String[] args) {
List<Integer> l;
l = new ArrayList<>();
insertFirst(l, "ArrayList");
l = new LinkedList<>();
insertFirst(l, "LinkedList");
}
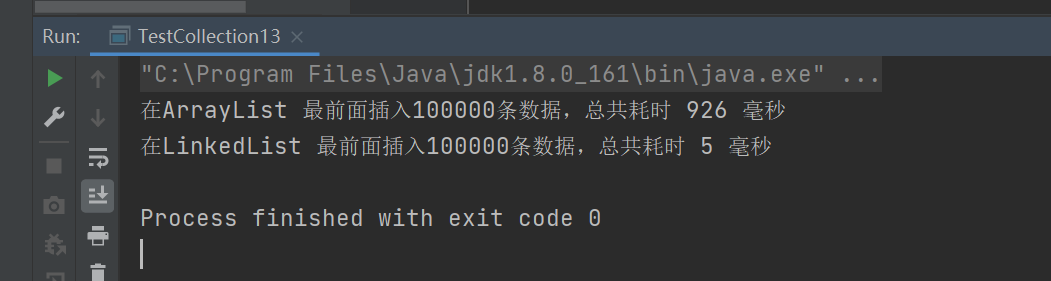
private static void insertFirst(List<Integer> l, String type) {
int total = 1000 * 100;
final int number = 5;
long start = System.currentTimeMillis();
for (int i = 0; i < total; i++) {
l.add(0, number);
}
long end = System.currentTimeMillis();
System.out.printf("在%s 最前面插入%d条数据,总共耗时 %d 毫秒 %n", type, total, end - start);
}
}
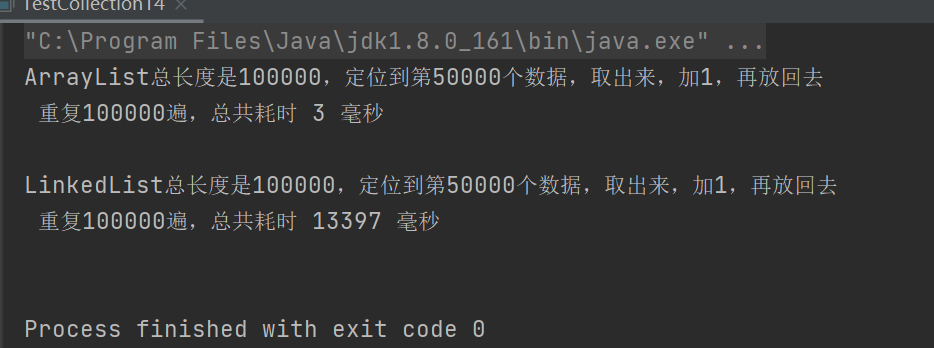
示例3:定位数据
package collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class TestCollection {
public static void main(String[] args) {
List<Integer> l;
l = new ArrayList<>();
modify(l, "ArrayList");
l = new LinkedList<>();
modify(l, "LinkedList");
}
private static void modify(List<Integer> l, String type) {
int total = 100 * 1000;
int index = total/2;
final int number = 5;
//初始化
for (int i = 0; i < total; i++) {
l.add(number);
}
long start = System.currentTimeMillis();
for (int i = 0; i < total; i++) {
int n = l.get(index);
n++;
l.set(index, n);
}
long end = System.currentTimeMillis();
System.out.printf("%s总长度是%d,定位到第%d个数据,取出来,加1,再放回去%n 重复%d遍,总共耗时 %d 毫秒 %n", type,total, index,total, end - start);
System.out.println();
}
}
HashMap vs HashTable
步骤1:HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,都是键值对保存数据的方式
区别1:
HashMap可以存放 null
Hashtable不能存放null
区别2:
HashMap不是线程安全的类
Hashtable是线程安全的类
package collection;
import java.util.HashMap;
import java.util.Hashtable;
public class TestCollection {
public static void main(String[] args) {
//HashMap和Hashtable都实现了Map接口,都是键值对保存数据的方式
HashMap<String,String> hashMap = new HashMap<String,String>();
//HashMap可以用null作key,作value
hashMap.put(null, "123");
hashMap.put("123", null);
Hashtable<String,String> hashtable = new Hashtable<String,String>();
//Hashtable不能用null作key,不能用null作value
hashtable.put(null, "123");
hashtable.put("123", null);
}
}
关系与区别几种Set
步骤1:HashSet LinkedHashSet TreeSet
HashSet: 无序
LinkedHashSet: 按照插入顺序
TreeSet: 从小到大排序
package collection;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.TreeSet;
public class TestCollection {
public static void main(String[] args) {
HashSet<Integer> numberSet1 =new HashSet<Integer>();
//HashSet中的数据不是按照插入顺序存放
numberSet1.add(88);
numberSet1.add(8);
numberSet1.add(888);
System.out.println(numberSet1);
LinkedHashSet<Integer> numberSet2 =new LinkedHashSet<Integer>();
//LinkedHashSet中的数据是按照插入顺序存放
numberSet2.add(88);
numberSet2.add(8);
numberSet2.add(888);
System.out.println(numberSet2);
TreeSet<Integer> numberSet3 =new TreeSet<Integer>();
//TreeSet 中的数据是进行了排序的
numberSet3.add(88);
numberSet3.add(8);
numberSet3.add(888);
System.out.println(numberSet3);
}
}
Hashcode原理
步骤1:List查找的低效率
假设在List中存放着无重复名称,没有顺序的2000000个Hero
要把名字叫做“hero 1000000”的对象找出来
List的做法是对每一个进行挨个遍历,直到找到名字叫做“hero 1000000”的英雄。
最差的情况下,需要遍历和比较2000000次,才能找到对应的英雄。
测试逻辑:
\1. 初始化2000000个对象到ArrayList中
\2. 打乱容器中的数据顺序
\3. 进行10次查询,统计每一次消耗的时间
不同计算机的配置情况下,所花的时间是有区别的。 在本机上,花掉的时间大概是600毫秒左右
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
List<Hero> heros = new ArrayList<Hero>();
for (int j = 0; j < 2000000; j++) {
Hero h = new Hero("Hero " + j);
heros.add(h);
}
// 进行10次查找,观察大体的平均值
for (int i = 0; i < 10; i++) {
// 打乱heros中元素的顺序
Collections.shuffle(heros);
long start = System.currentTimeMillis();
String target = "Hero 1000000";
for (Hero hero : heros) {
if (hero.name.equals(target)) {
System.out.println("找到了 hero!" );
break;
}
}
long end = System.currentTimeMillis();
long elapsed = end - start;
System.out.println("一共花了:" + elapsed + " 毫秒");
}
}
}
步骤2:HashMap的性能表现
使用HashMap 做同样的查找
\1. 初始化2000000个对象到HashMap中。
\2. 进行10次查询
\3. 统计每一次的查询消耗的时间
可以观察到,几乎不花时间,花费的时间在1毫秒以内
package collection;
import java.util.HashMap;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
HashMap<String,Hero> heroMap = new HashMap<String,Hero>();
for (int j = 0; j < 2000000; j++) {
Hero h = new Hero("Hero " + j);
heroMap.put(h.name, h);
}
System.out.println("数据准备完成");
for (int i = 0; i < 10; i++) {
long start = System.currentTimeMillis();
//查找名字是Hero 1000000的对象
Hero target = heroMap.get("Hero 1000000");
System.out.println("找到了 hero!" + target.name);
long end = System.currentTimeMillis();
long elapsed = end - start;
System.out.println("一共花了:" + elapsed + " 毫秒");
}
}
}
步骤3:HashMap原理与字典
在展开HashMap原理的讲解之前,首先回忆一下大家初中和高中使用的汉英字典。
比如要找一个单词对应的中文意思,假设单词是Lengendary,首先在目录找到Lengendary在第 555页。
然后,翻到第555页,这页不只一个单词,但是量已经很少了,逐一比较,很快就定位目标单词Lengendary。
555相当于就是Lengendary对应的hashcode
步骤4:分析HashMap性能卓越的原因
-----hashcode概念-----
所有的对象,都有一个对应的hashcode(散列值)
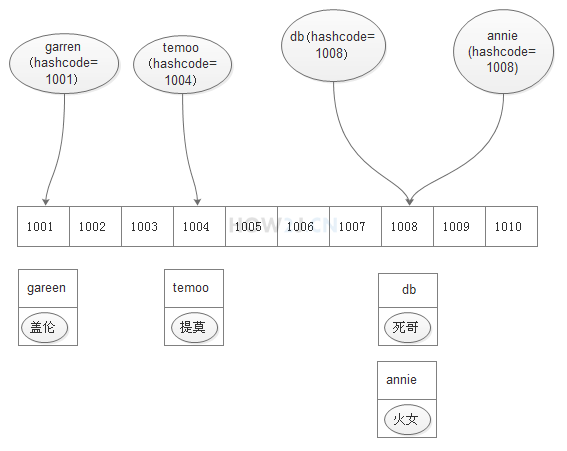
比如字符串“gareen”对应的是1001 (实际上不是,这里是方便理解,假设的值)
比如字符串“temoo”对应的是1004
比如字符串“db”对应的是1008
比如字符串“annie”对应的也****是1008
-----保存数据-----
准备一个数组,其长度是2000,并且设定特殊的hashcode算法,使得所有字符串对应的hashcode,都会落在0-1999之间
要存放名字是"gareen"的英雄,就把该英雄和名称组成一个键值对,存放在数组的1001这个位置上
要存放名字是"temoo"的英雄,就把该英雄存放在数组的1004这个位置上
要存放名字是"db"的英雄,就把该英雄存放在数组的1008这个位置上
要存放名字是"annie"的英雄,然而 "annie"的hashcode 1008对应的位置已经有db英雄了,那么就在这里创建一个链表,接在db英雄后面存放annie
-----查找数据-----
比如要查找gareen,首先计算"gareen"的hashcode是1001,根据1001这个下标,到数组中进行定位,(根据数组下标进行定位,是非常快速的) 发现1001这个位置就只有一个英雄,那么该英雄就是gareen.
比如要查找annie,首先计算"annie"的hashcode是1008,根据1008这个下标,到数组中进行定位,发现1008这个位置有两个英雄,那么就对两个英雄的名字进行逐一比较(equals),因为此时需要比较的量就已经少很多了,很快也就可以找出目标英雄
这就是使用hashmap进行查询,非常快原理。
这是一种用空间换时间的思维方式
步骤5:HashSet判断是否重复
HashSet的数据是不能重复的,相同数据不能保存在一起,到底如何判断是否是重复的呢?
根据HashSet和HashMap的关系,我们了解到因为HashSet没有自身的实现,而是里面封装了一个HashMap,所以本质上就是判断HashMap的key是否重复。
再通过上一步的学习,key是否重复,是由两个步骤判断的:
hashcode是否一样
如果hashcode不一样,就是在不同的坑里,一定是不重复的
如果hashcode一样,就是在同一个坑里,还需要进行equals比较
如果equals一样,则是重复数据
如果equals不一样,则是不同数据。
比较器
步骤1:Comparator
假设Hero有三个属性 name,hp,damage
一个集合中放存放10个Hero,通过Collections.sort对这10个进行排序
那么到底是hp小的放前面?还是damage小的放前面?Collections.sort也无法确定
所以要指定到底按照哪种属性进行排序
这里就需要提供一个Comparator给定如何进行两个对象之间的大小比较
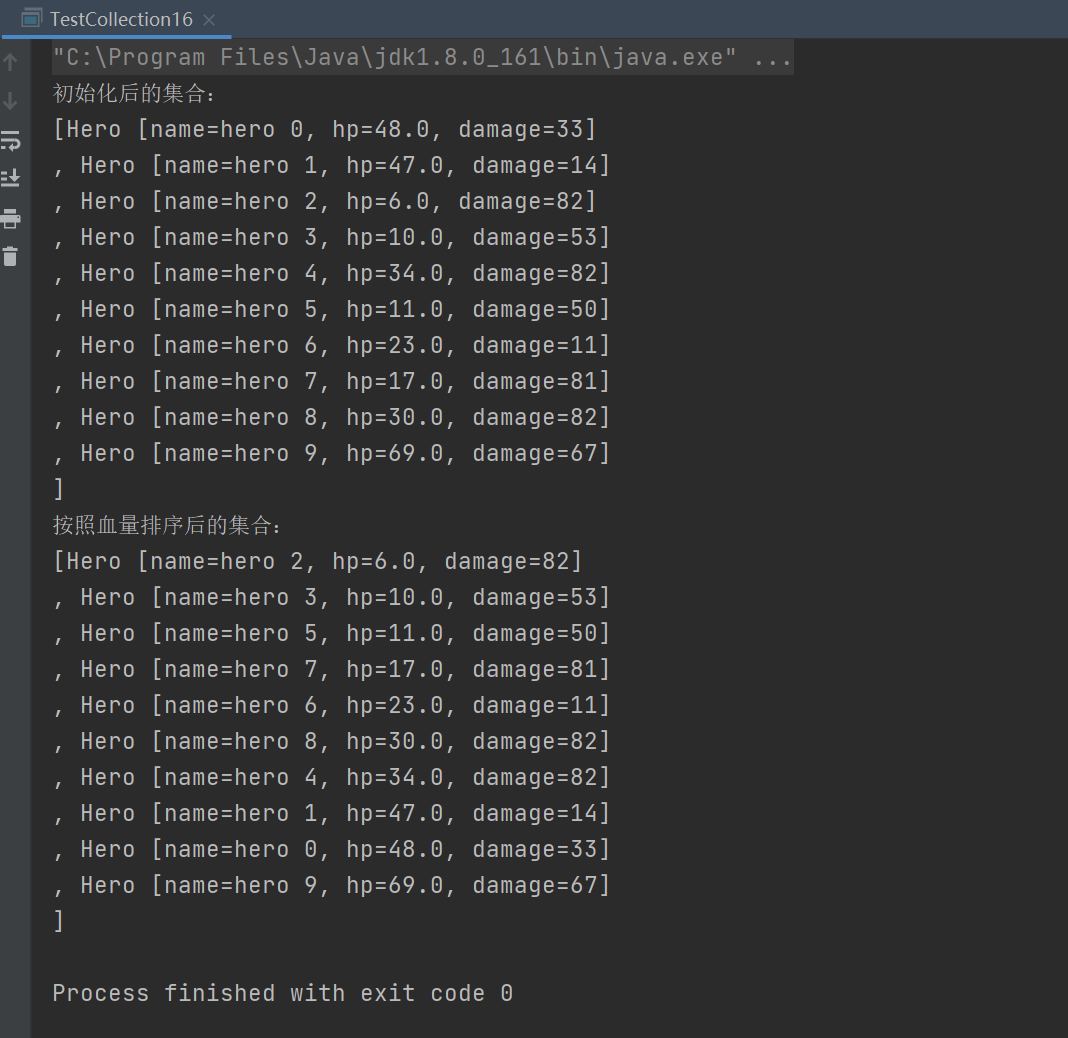
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Random;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
Random r =new Random();
List<Hero> heros = new ArrayList<Hero>();
for (int i = 0; i < 10; i++) {
//通过随机值实例化hero的hp和damage
heros.add(new Hero("hero "+ i, r.nextInt(100), r.nextInt(100)));
}
System.out.println("初始化后的集合:");
System.out.println(heros);
//直接调用sort会出现编译错误,因为Hero有各种属性
//到底按照哪种属性进行比较,Collections也不知道,不确定,所以没法排
//Collections.sort(heros);
//引入Comparator,指定比较的算法
Comparator<Hero> c = new Comparator<Hero>() {
@Override
public int compare(Hero h1, Hero h2) {
//按照hp进行排序
if(h1.hp>=h2.hp)
return 1; //正数表示h1比h2要大
else
return -1;
}
};
Collections.sort(heros,c);
System.out.println("按照血量排序后的集合:");
System.out.println(heros);
}
}
package charactor;
public class Hero {
public String name;
public float hp;
public int damage;
public Hero() {
}
public Hero(String name) {
this.name = name;
}
public String toString() {
return "Hero [name=" + name + ", hp=" + hp + ", damage=" + damage + "]\r\n";
}
public Hero(String name, int hp, int damage) {
this.name = name;
this.hp = hp;
this.damage = damage;
}
}
示例2:Comparable
使Hero类实现Comparable接口
在类里面提供比较算法
Collections.sort就有足够的信息进行排序了,也无需额外提供比较器Comparator
注: 如果返回-1, 就表示当前的更小,否则就是更大
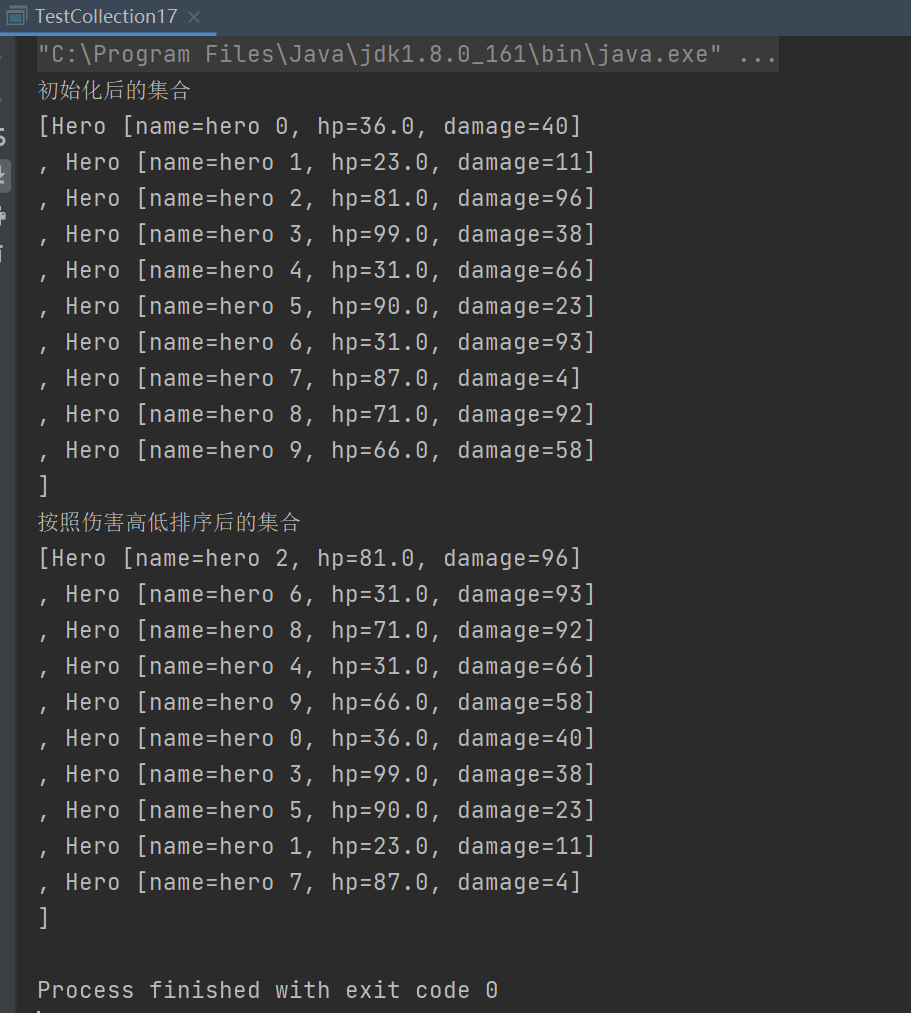
package charactor;
public class Hero implements Comparable<Hero>{
public String name;
public float hp;
public int damage;
public Hero(){
}
public Hero(String name) {
this.name =name;
}
//初始化name,hp,damage的构造方法
public Hero(String name,float hp, int damage) {
this.name =name;
this.hp = hp;
this.damage = damage;
}
@Override
public int compareTo(Hero anotherHero) {
if(damage<anotherHero.damage)
return 1;
else
return -1;
}
@Override
public String toString() {
return "Hero [name=" + name + ", hp=" + hp + ", damage=" + damage + "]\r\n";
}
}
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Random;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
Random r =new Random();
List<Hero> heros = new ArrayList<Hero>();
for (int i = 0; i < 10; i++) {
//通过随机值实例化hero的hp和damage
heros.add(new Hero("hero "+ i, r.nextInt(100), r.nextInt(100)));
}
System.out.println("初始化后的集合");
System.out.println(heros);
//Hero类实现了接口Comparable,即自带比较信息。
//Collections直接进行排序,无需额外的Comparator
Collections.sort(heros);
System.out.println("按照伤害高低排序后的集合");
System.out.println(heros);
}
}
聚合操作
步骤1:聚合操作
JDK8之后,引入了对集合的聚合操作,可以非常容易的遍历,筛选,比较集合中的元素。
像这样:
String name =heros
.stream()
.sorted((h1,h2)->h1.hp>h2.hp?-1:1)
.skip(2)
.map(h->h.getName())
.findFirst()
.get();
package lambda;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Random;
import charactor.Hero;
public class TestAggregate {
public static void main(String[] args) {
Random r = new Random();
List<Hero> heros = new ArrayList<Hero>();
for (int i = 0; i < 10; i++) {
heros.add(new Hero("hero " + i, r.nextInt(1000), r.nextInt(100)));
}
System.out.println("初始化集合后的数据 (最后一个数据重复):");
System.out.println(heros);
//传统方式
Collections.sort(heros,new Comparator<Hero>() {
@Override
public int compare(Hero o1, Hero o2) {
return (int) (o2.hp-o1.hp);
}
});
Hero hero = heros.get(2);
System.out.println("通过传统方式找出来的hp第三高的英雄名称是:" + hero.name);
//聚合方式
String name =heros
.stream()
.sorted((h1,h2)->h1.hp>h2.hp?-1:1)
.skip(2)
.map(h->h.getName())
.findFirst()
.get();
System.out.println("通过聚合操作找出来的hp第三高的英雄名称是:" + name);
}
}
泛型
集合中的泛型
示例1:不使用泛型
不使用泛型带来的问题
ADHero(物理攻击英雄) APHero(魔法攻击英雄)都是Hero的子类
ArrayList 默认接受Object类型的对象,所以所有对象都可以放进ArrayList中
所以get(0) 返回的类型是Object
接着,需要进行强制转换才可以得到APHero类型或者ADHero类型。
如果软件开发人员记忆比较好,能记得哪个是哪个,还是可以的。 但是开发人员会犯错误,比如第20行,会记错,把第0个对象转换为ADHero,这样就会出现类型转换异常
package generic;
import java.util.ArrayList;
import charactor.ADHero;
import charactor.APHero;
public class TestGeneric {
public static void main(String[] args) {
ArrayList heros = new ArrayList();
heros.add(new APHero());
heros.add(new ADHero());
APHero apHero = (APHero) heros.get(0);
ADHero adHero = (ADHero) heros.get(1);
ADHero adHero2 = (ADHero) heros.get(0);
}
}
示例2:使用泛型
使用泛型的好处:
泛型的用法是在容器后面添加
Type可以是类,抽象类,接口
泛型表示这种容器,只能存放APHero,ADHero就放不进去了。
package generic;
import java.util.ArrayList;
import charactor.APHero;
public class TestGeneric {
public static void main(String[] args) {
ArrayList<APHero> heros = new ArrayList<APHero>();
//只有APHero可以放进去
heros.add(new APHero());
//ADHero甚至放不进去
//heros.add(new ADHero());
//获取的时候也不需要进行转型,因为取出来一定是APHero
APHero apHero = heros.get(0);
}
}
示例 3 : 子类对象顶折
示例3:子类对象
假设容器的泛型是Hero,那么Hero的子类APHero,ADHero都可以放进去
和Hero无关的类型Item还是放不进去
package generic;
import java.util.ArrayList;
import property.Item;
import charactor.ADHero;
import charactor.APHero;
import charactor.Hero;
public class TestGeneric {
public static void main(String[] args) {
ArrayList<Hero> heros = new ArrayList<Hero>();
//只有作为Hero的子类可以放进去
heros.add(new APHero());
heros.add(new ADHero());
//和Hero无关的类型Item还是放不进去
//heros.add(new Item());
}
}
示例4:泛型的简写
为了不使编译器出现警告,需要前后都使用泛型,像这样:
ArrayList<Hero> heros = new ArrayList<Hero>();
不过JDK7提供了一个可以略微减少代码量的泛型简写方式
ArrayList<Hero> heros2 = new ArrayList<>();
package generic;
import java.util.ArrayList;
import charactor.Hero;
public class TestGeneric {
public static void main(String[] args) {
ArrayList<Hero> heros = new ArrayList<Hero>();
//后面可以只用<>
ArrayList<Hero> heros2 = new ArrayList<>();
}
}
支持泛型的类
步骤1:不支持泛型的Stack
以Stack栈为例子,如果不使用泛型
当需要一个只能放Hero的栈的时候,就需要设计一个HeroStack
当需要一个只能放Item的栈的时候,就需要一个ItemStack
package generic;
import java.util.LinkedList;
import charactor.Hero;
public class HeroStack {
LinkedList<Hero> heros = new LinkedList<Hero>();
public void push(Hero h) {
heros.addLast(h);
}
public Hero pull() {
return heros.removeLast();
}
public Hero peek() {
return heros.getLast();
}
public static void main(String[] args) {
HeroStack heroStack = new HeroStack();
for (int i = 0; i < 5; i++) {
Hero h = new Hero("hero name " + i);
System.out.println("压入 hero:" + h);
heroStack.push(h);
}
for (int i = 0; i < 5; i++) {
Hero h =heroStack.pull();
System.out.println("弹出 hero" + h);
}
}
}
package generic;
import java.util.LinkedList;
import property.Item;
public class ItemStack {
LinkedList<Item> Items = new LinkedList<Item>();
public void push(Item h) {
Items.addLast(h);
}
public Item pull() {
return Items.removeLast();
}
public Item peek() {
return Items.getLast();
}
public static void main(String[] args) {
ItemStack ItemStack = new ItemStack();
for (int i = 0; i < 5; i++) {
Item item = new Item("Item name " + i);
System.out.println("压入 Item:" + item);
ItemStack.push(item);
}
for (int i = 0; i < 5; i++) {
Item item =ItemStack.pull();
System.out.println("弹出 Item" + item);
}
}
}
步骤2:支持泛型的Stack
设计一个支持泛型的栈MyStack
设计这个类的时候,在类的声明上,加上一个
T是type的缩写,也可以使用任何其他的合法的变量,比如A,B,X都可以,但是一般约定成俗使用T,代表类型。
package generic;
import java.util.HashMap;
import java.util.LinkedList;
import charactor.Hero;
import property.Item;
public class MyStack<T> {
LinkedList<T> values = new LinkedList<T>();
public void push(T t) {
values.addLast(t);
}
public T pull() {
return values.removeLast();
}
public T peek() {
return values.getLast();
}
public static void main(String[] args) {
//在声明这个Stack的时候,使用泛型<Hero>就表示该Stack只能放Hero
MyStack<Hero> heroStack = new MyStack<>();
heroStack.push(new Hero());
//不能放Item
heroStack.push(new Item());
//在声明这个Stack的时候,使用泛型<Item>就表示该Stack只能放Item
MyStack<Item> itemStack = new MyStack<>();
itemStack.push(new Item());
//不能放Hero
itemStack.push(new Hero());
}
}
通配符
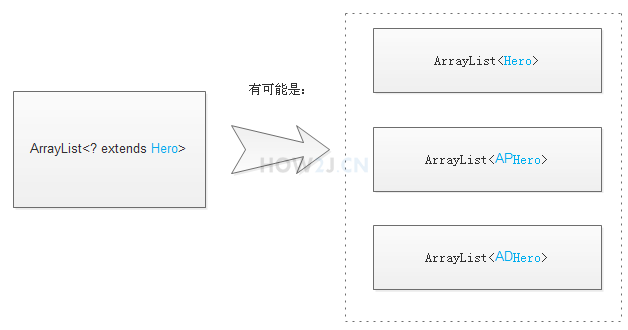
示例1:?extends
ArrayList heroList<? extends Hero> 表示这是一个Hero泛型或者其子类泛型
heroList 的泛型可能是Hero
heroList 的泛型可能是APHero
heroList 的泛型可能是ADHero
所以 可以确凿的是,从heroList取出来的对象,一定是可以转型成Hero的
但是,不能往里面放东西,因为
放APHero就不满足
放ADHero又不满足
package generic;
import java.util.ArrayList;
import charactor.ADHero;
import charactor.APHero;
import charactor.Hero;
public class TestGeneric {
public static void main(String[] args) {
ArrayList<APHero> apHeroList = new ArrayList<APHero>();
apHeroList.add(new APHero());
ArrayList<? extends Hero> heroList = apHeroList;
//? extends Hero 表示这是一个Hero泛型的子类泛型
//heroList 的泛型可以是Hero
//heroList 的泛型可以使APHero
//heroList 的泛型可以使ADHero
//可以确凿的是,从heroList取出来的对象,一定是可以转型成Hero的
Hero h= heroList.get(0);
//但是,不能往里面放东西
heroList.add(new ADHero()); //编译错误,因为heroList的泛型 有可能是APHero
}
}
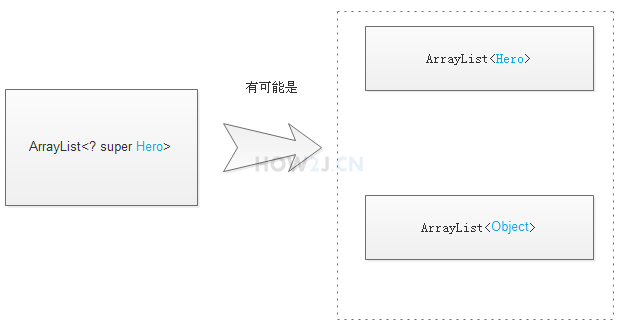
示例2:?super
ArrayList heroList<? super Hero> 表示这是一个Hero泛型或者其父类泛型
heroList的泛型可能是Hero
heroList的泛型可能是Object
可以往里面插入Hero以及Hero的子类
但是取出来有风险,因为不确定取出来是Hero还是Object
package generic;
import java.util.ArrayList;
import charactor.ADHero;
import charactor.APHero;
import charactor.Hero;
public class TestGeneric {
public static void main(String[] args) {
ArrayList<? super Hero> heroList = new ArrayList<Object>();
//? super Hero 表示 heroList的泛型是Hero或者其父类泛型
//heroList 的泛型可以是Hero
//heroList 的泛型可以是Object
//所以就可以插入Hero
heroList.add(new Hero());
//也可以插入Hero的子类
heroList.add(new APHero());
heroList.add(new ADHero());
//但是,不能从里面取数据出来,因为其泛型可能是Object,而Object是强转Hero会失败
Hero h= heroList.get(0);
}
}
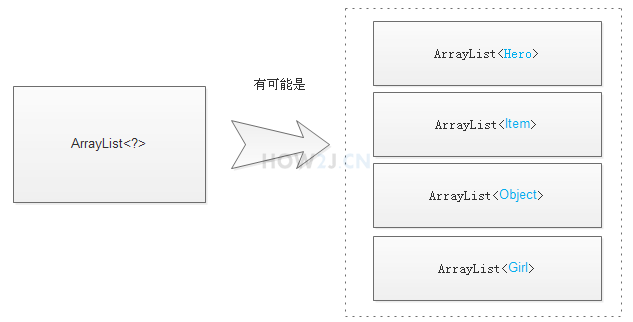
示例3:泛型通配符
泛型通配符? 代表任意泛型
既然?代表任意泛型,那么换句话说,这个容器什么泛型都有可能
所以只能以Object的形式取出来
并且不能往里面放对象,因为不知道到底是一个什么泛型的容器
package generic;
import java.util.ArrayList;
import property.Item;
import charactor.APHero;
import charactor.Hero;
public class TestGeneric {
public static void main(String[] args) {
ArrayList<APHero> apHeroList = new ArrayList<APHero>();
//?泛型通配符,表示任意泛型
ArrayList<?> generalList = apHeroList;
//?的缺陷1: 既然?代表任意泛型,那么换句话说,你就不知道这个容器里面是什么类型
//所以只能以Object的形式取出来
Object o = generalList.get(0);
//?的缺陷2: 既然?代表任意泛型,那么既有可能是Hero,也有可能是Item
//所以,放哪种对象进去,都有风险,结果就什么什么类型的对象,都不能放进去
generalList.add(new Item()); //编译错误 因为?代表任意泛型,很有可能不是Item
generalList.add(new Hero()); //编译错误 因为?代表任意泛型,很有可能不是Hero
generalList.add(new APHero()); //编译错误 因为?代表任意泛型,很有可能不是APHero
}
}
示例4:总结
如果希望只取出,不插入,就使用? extends Hero
如果希望只插入,不取出,就使用? super Hero
如果希望,又能插入,又能取出,就不要用通配符?
泛型转型
示例1:对象转型
根据面向对象学习的知识,子类转父类 是一定可以成功的
package generic;
import charactor.ADHero;
import charactor.Hero;
public class TestGeneric {
public static void main(String[] args) {
Hero h = new Hero();
ADHero ad = new ADHero();
//子类转父类
h = ad;
}
}
示例2:子类泛型转父类泛型
既然 子类对象 转 父类对象是可以成功的,那么子类泛型转父类泛型能成功吗?
如代码
hs的泛型是父类Hero
adhs 的泛型是子类ADHero
那么 把adhs转换为hs能成功吗?
package generic;
import java.util.ArrayList;
import charactor.ADHero;
import charactor.Hero;
public class TestGeneric {
public static void main(String[] args) {
ArrayList<Hero> hs =new ArrayList<>();
ArrayList<ADHero> adhs =new ArrayList<>();
//子类泛型转父类泛型
hs = adhs;
}
}
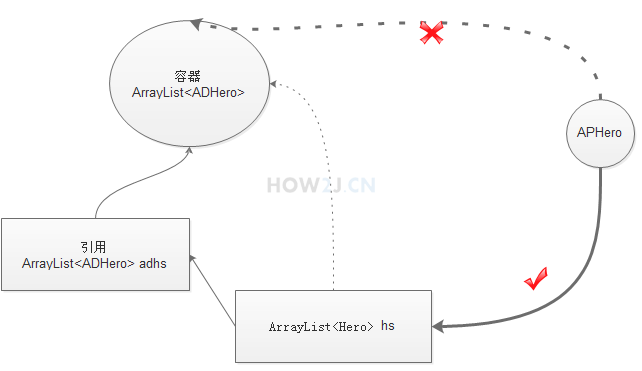
示例3:假设可以转型成功
假设可以转型成功
引用hs指向了ADHero泛型的容器
作为Hero泛型的引用hs, 看上去是可以往里面加一个APHero的。
但是hs这个引用,实际上是指向的一个ADHero泛型的容器
如果能加进去,就变成了ADHero泛型的容器里放进了APHero,这就矛盾了
所以子类泛型不可以转换为父类泛型
package generic;
import java.util.ArrayList;
import charactor.ADHero;
import charactor.APHero;
import charactor.Hero;
public class TestGeneric {
public static void main(String[] args) {
ArrayList<Hero> hs =new ArrayList<>();
ArrayList<ADHero> adhs =new ArrayList<>();
//假设能转换成功
hs = adhs;
//作为Hero泛型的hs,是可以向其中加入APHero的
//但是hs这个引用,实际上是指向的一个ADHero泛型的容器
//如果能加进去,就变成了ADHero泛型的容器里放进了APHero,这就矛盾了
hs.add(new APHero());
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号