【机器学习】一般线性回归
注:对于最重要的两类回归模型,之前总结了逻辑回归模型,这里总结一下"线性回归"模型。
0. 概述
线性回归应该是我们听过次数最多的机器学习算法了。在一般的统计学教科书中,最后都会提到这种方法。因此该算法也算是架起了数理统计与机器学习之间的桥梁。线性回归虽然常见,但是却并不简单。该算法中几乎包含了所有有监督机器学习算法的重要知识点,比如数据的表示、参数的训练、模型的评价、利用正则化防止过拟合等概念。所以说如果掌握了线性回归,可以为后面的学习打下坚实的基础。
1. 线性回归的基本形式
最简单的线性回归就是直接利用一条直线拟合二维平面上的一系列点,目的是利用这条直线概括所有训练集中样本的散布规律或趋势,最终用于新样本点的预测。二维平面上直线方程的一般形式为$y = ax + b$,使用训练集中的数据以某种方式训练该模型后,就可以确定方程中的两个参数$a, b$的最优值。后面如果观察到了新的样本$x^i$,就可以带入上面学习到的公式计算$y$的值了。
在三维空间中,需要学习的是确定一个二维平面的参数;
以此类推,在$n$维空间中,需要学习的是确定一个$n - 1$维的超平面的参数.
之所以称该方法为线性模型,是因为该模型是由所有特征的线性组合构成的,基本形式为:
$$\hat{y} = h_{\theta}(x) = \theta_0 + \theta_1x_1 + \theta_2x_2 + \cdots + \theta_nx_n \quad \cdots \ (1-1)$$
- $\hat{y}$表示线性回归模型的预测值(相对于真实观察值);
- $n$表示特征的数量;
- $x_i$表示第$i$个特征的观察值;
- $\theta_j$表示第$j$个参数的值.
如果模型包括$n$个特征,那么就会包括$n + 1$个参数,还包括常数项(还是被称为截距)。
式子(1-1)使用向量化形式可以表示为$h_{\theta} = \theta^T \cdot x$, 在多样本的情况下通常表示为:
$$h_{\theta}(x) = X \cdot \theta + \epsilon \quad \cdots \ (1-2)$$
- $X$是$m \cdot (n+1)$的矩阵,其中$m$表示样本的数量;
- $\theta$是包含所有参数的列向量,长度为$n + 1$;
- $\epsilon$表示随机误差,长度为$m$,一般假设为服从正态分布.
式子(1-2)表示所有样本值的矩阵与对应参数向量的乘积,属于矩阵乘法((Matrix multiplication)。通过$X$或$y$与$\epsilon$之间的关系也可以用来评估模型结果的好坏,如果数据中的$X$与$y$之间的关系符合线性回归模型的假设,那么残差$\epsilon$与$X$和$y$之间应该不存在相关性(线性关系已经被模型解释);反之如果残差与$X$或$y$存在某种显而易见的相关性,就说明数据原本就不符合线性模型的假设。
具体可以参考我的另一篇博客【机器学习】一些基本概念及符号系统中的“4. 模型的表示”部分。
2. 线性回归的代价函数
假设现在有了训练数据和模型,那么要怎么开始训练呢?这时候就必须定义一个代价函数,代价函数量化了模型预测值与实际观察值之间的误差大小。有了代价函数就可以评价取当前参数时模型性能的好坏。
在选择一个恰当的代价函数后,整个模型的训练过程就是求代价函数最小值的过程。这个过程并不容易,可能会出现下面两种情况:
- 得到全局最优解:即代价函数的最小值;
- 得到局部最优解:由于很多原因我们可能仅仅只能求的代价函数在某个区间内的极小值.
如果代价函数是一个凸函数(convex function),那么从数学上可以保证肯定能求得全局最优解;如果代价函数是非凸函数,就无法从理论上保证最终能得到代价函数的全局最优解(NP-hard问题)。
对于线性回归算法,比较常用的代价函数是均方误差(Mean Square Error, MSE)函数:
$$J(\theta) = MSE(X, h_{\theta}) = \frac{1}{2m}\sum_{i=1}^{m}{(\hat{y}^{(i)} - y^{(i)})^2} = \frac{1}{2m}\sum_{i=1}^{m}{(\theta^T \cdot x^{(i)} - y^{(i)})^2} \quad \cdots \ (2-1)$$
- 上式表示所有模型的预测值与实际观察值之差的平方和,因此训练集中任何一个实际观察值与模型预测值之间的误差都包含在了这个公式中;
- 为了求导方便,添加了一个系数$\frac{1}{2}$,实际的MSE的定义中是没有的;
- 该函数是一个凸函数.
关于代价函数的更多解释,可以参考另一篇博客【机器学习】代价函数(cost function)
2. 利用正规方程求解
先看一下正规方程的定义:
最小二乘法可以将误差方程转化为有确定解的代数方程组(其方程式数目正好等于未知数的个数),从而可求解出这些未知参数。这个有确定解的代数方程组称为最小二乘法估计的正规方程
就像利用“一阶导数等于0的点是极值点”的性质,可以非常容易求出一元二次方程的极值点一样,我们也可以采用代数的方法直接计算式子(2-1)的最小值点。实际上经过计算可以得到:
$$\theta = (X^TX)^{-1}X^Ty$$
也就是说,不用经过训练就可以直接利用上面的公式计算出线性回归模型的最优解。既然有了这么方便的方法,为什么我们还需要其他的训练方法(例如梯度下降)呢?这是因为求一个矩阵的逆运算量非常大,例如求一个$n \cdot n$的矩阵的逆,其计算复杂度为$O(n^3)$。因此,在样本量非常大时利用梯度下降来训练模型所消耗的时间远远小于直接使用正规方程计算结果所消耗的时间。当然,在样本量非常小的情况下,利用该方法还是非常方便的。
3. 利用梯度下降训练模型
梯度下降几乎可以说是机器学习算法中,训练模型和调参最重要的方法了。梯度就是所有偏导数构成的向量。因为计算代价函数的梯度需要求导,这里应该是机器学习中使用微积分最多的地方了。微博上爱可可老师分享过一个“梯度下降算法演化史”的视频,链接在这里。
3.1 梯度下降的一般步骤
- 参数的初始化:通常所有参数都初始化为1;
- 确定学习率;
- 求代价函数的梯度(所有参数的偏导数);
- 所有参数都沿梯度方向移动一步,步长就是学习率的大小;
- 重复步骤4直到参数不再发生变化(此时取到极值点,梯度为0)或达到预先设定的迭代次数.
3.1.1 学习率
学习率一般用希腊字母$\alpha$表示,可能需要多尝试几次,才能找到合适的学习率。过大的学习率会导致梯度下降时越过代价函数的最小值点,随着训练步数的增加,代价函数不减反增;如果学习率太小,训练中的每一步参数的变化会非常小,这时可以看到代价函数的值在不断减小,但是需要非常大的迭代次数才能到达代价函数的最小值点。
按照吴恩达老师的建议,每次可以3倍放大或者3倍缩小来调整,直到找到合适的学习率。
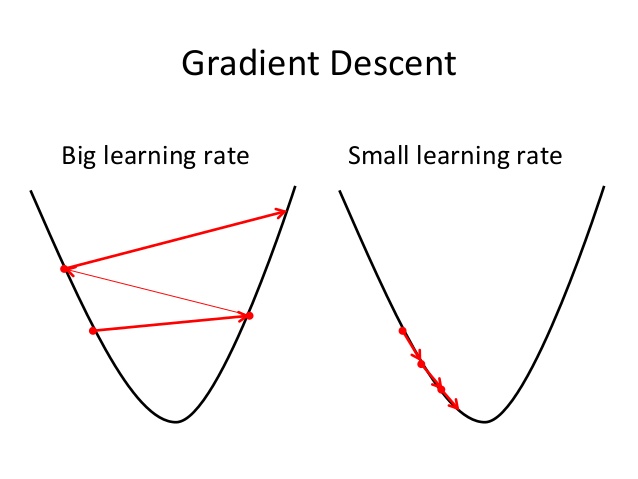
图3-1,学习率过大会导致参数的取值越过最小值点;学习率过小会导致参数变化缓慢
3.1.2 代价函数的梯度
在机器学习中,对代价函数包含的每一个参数求偏导数,这些偏导数组成的向量就是代价函数的梯度。
这个时候就要用到微积分中求导数的知识了。如果自己有兴趣可以在草稿纸上手动算一算;如果不想自己算,常见的代价函数的求导过程在网上很容易找到。
均方误差函数的梯度
为了简单起见,先考虑只有一个特征的直线方程:$h_{(\theta)} = \theta_0 + \theta_1x_1$
令$x_0 = 1$,则可得$h_{(\theta)} = \theta_0x_0 + \theta_1x_1$
参考MSE的公式,见式子(2-1),可得,
- $J(\theta)$对$\theta_0$的偏导数:$\frac{\partial}{\partial \theta_0} J(\theta) = \frac{1}{m} \sum_{i=1}^{m}{[(h_{\theta}(x^{(i)}) - y^{(i)}) \cdot x_0^{(i)}]} \quad \cdots \ (3-1)$;
- $J(\theta)$对$\theta_1$的偏导数:$\frac{\partial}{\partial \theta_1} J(\theta) = \frac{1}{m} \sum_{i=1}^{m}{[(h_{\theta}(x^{(i)}) - y^{(i)}) \cdot x_1^{(i)}]} \quad \cdots \ (3-2)$;
其中$m$表示样本数量;$y^{i}$表示第$i$个样本的观察值;$x_1^{i}$表示第$i$个样本的第1个特征的观察值;式子中的点号$\cdot$表示普通乘法。
3.2 梯度下降的Python实现
3.2.1 方法1 - 原始实现
下面根据前面已经获得的信息,做一个简单的实现,首先利用直线方程生成一些数据(添加了一些随机误差)
1 import numpy as np 2 import matplotlib.pyplot as plt 3 m = 100 # 样本量 4 X = 2 * np.random.rand(m, 1) # 取大小在区间(0, 1)上的随机数,构成一个100*1的矩阵 5 y = 5 + 2 * X + np.random.rand(m, 1) 6 plt.plot(X, y, "b.") 7 plt.show()
显示如下,

图3-2,利用直线方程和随机误差生成的原始数据(训练集)
下面定义了计算代价函数的方法,并且利用梯度下降训练模型的参数。第16行对$\theta_0$求偏导数,相当于式子(3-1);第17行对$\theta_1$求偏导数,相当于式子(3-2).
1 # 计算代价函数 2 def L_theta(theta, X_x0, y): 3 delta = np.dot(X_x0, theta) - y # np.dot 表示矩阵乘法 4 L_theta = np.sum(np.multiply(delta, delta)) 5 return L_theta 6 7 T = 1000 # 迭代次数 8 theta = np.ones((2, 1)) # 参数的初始化 9 alpha = 0.06 # 学习率 10 X_x0 = np.c_[np.ones((100, 1)), X] # ADD X0 = 1 to each instance 11 12 13 for i in range(T): 14 theta_0 = theta[0, 0] 15 theta_1 = theta[1, 0] 16 theta_0 -= alpha*(1/m * np.sum(np.dot(X_x0, theta) - y)) 17 theta_1 -= alpha*(1/m * np.sum(np.dot(np.transpose(X), np.dot(X_x0, theta) - y))) 18 theta[0, 0] = theta_0 19 theta[1, 0] = theta_1 20 if i%100==0: 21 print(L_theta(theta, X_x0, y))
上面的代码中设置了总的迭代次数为1000次,并且每隔100次,计算当前参数下的代价函数值,输出如下:
2318.32226584 26.2317675878 10.6221201088 8.60799768785 8.3481142323 8.31458131008 8.31025453649 8.30969625023 8.30962421422 8.30961491936
从上面的输出可以看到,代价函数的值一直在减小,前面变化很大,后面变化的幅度非常小,说明后面的参数所在的位置已经非常接近代价函数的最小值点,这附近曲线比较平滑,梯度也比较小。
下面是训练完成后的参数$\theta$,即代码中变量theta的取值:
print(theta) # 训练结束后得到的最优参数值
输出结果如下:
array([[ 5.48119293],
[ 1.98150554]])
这个结果,与我们生成数据时设定的斜率和截距非常接近。有了参数,线性回归的方程就确定了,下面比较一下训练出来的直线与生成的数据之间的关系:
1 plt.plot(X, h, 'r-') 2 plt.plot(X, y, 'b.') 3 plt.axis([0, 2, 4, 12]) 4 plt.show()
结果如下,
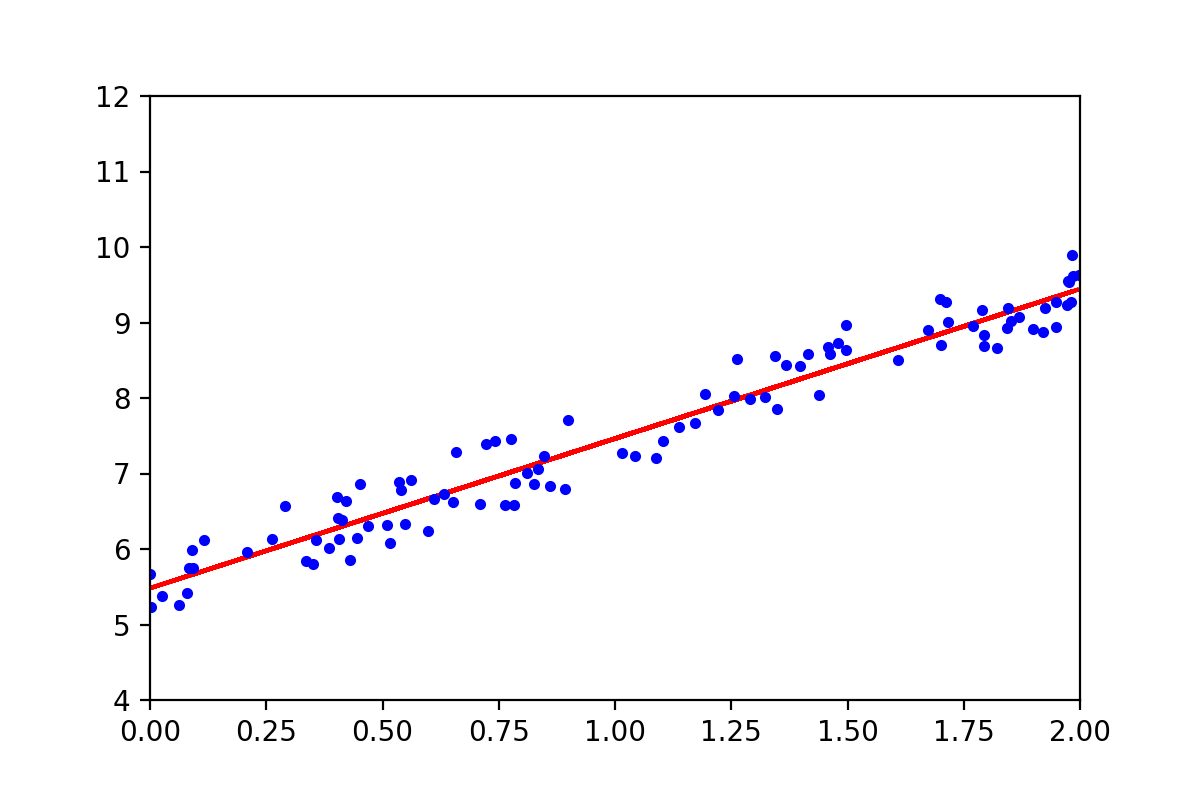
图3-3,训练出来的参数确定的直线方程与训练集中样本点的比较
图中红色的线是训练出来的参数确定的直线,蓝色点是原始数据。从上图可以看出来,训练出来的直线方程与前面生成的数据匹配的非常好。确定了直线方程,获得新的数据点后直接带入该直线方程,就可以得到相应的预测值(这也是很多时候我们做线性回归分析的最终目的):
1 X_new = np.array([[0.5], [1.8]]) 2 X_new_b = np.c_[np.ones((2, 1)), X_new] # add x0 = 1 to each instance 3 y_predict = X_new_b.dot(theta) 4 print(X_new) 5 print(y_predict)
输出结果如下:
[[ 0.5] [ 1.8]] [[ 6.4719457] [ 9.0479029]]
上面的结果说明,如果0.5和1.8也用同样的方式产生出来的话,那么可以以非常高的可信度预测它们对应的函数值$h$大约为6.47和9.05。
3.2.2 方法2 - 梯度的向量化表示
上面的方法显得有点繁琐,在代码中对两个参数分别求偏导数,并且分别更新它们的值,假如有100个参数,就要重复100次几乎相同的步骤。因此这样的代码,可扩展性非常差。下面我们使用梯度和向量化的方式来重写梯度下降的实现过程。通过比较两个参数的偏导数,即式子(3-1)和(3-2),不难发现它们非常相似,如果把这些式子统一起来,所有参数的偏导数可以写成下面的样子:
$$\nabla_{\theta}MSE(\theta) = \begin{pmatrix} \frac{\partial}{\partial \theta_0} L(\theta) \\ \frac{\partial}{\partial \theta_1} L(\theta) \\ \vdots \\ \frac{\partial}{\partial \theta_n} L(\theta) \end{pmatrix} = \begin{pmatrix} \frac{1}{m} \sum_{i=1}^{m}{(\theta^T \cdot x^{(i)} - y^{(i)}) x^{(i)}_0} \\ \frac{1}{m} \sum_{i=1}^{m}{(\theta^T \cdot x^{(i)} - y^{(i)}) x^{(i)}_1} \\ \vdots \\ \frac{1}{m} \sum_{i=1}^{m}{(\theta^T \cdot x^{(i)} - y^{(i)}) x^{(i)}_n} \end{pmatrix} = \frac{1}{m} \begin{pmatrix} x_0^T \cdot e \\ x_1^T \cdot e \\ \vdots \\ x_n^T \cdot e \end{pmatrix} = \frac{1}{m} X^T \cdot e \quad \cdots \ (3-3) $$
上面式子中的倒三角是梯度的表示符号,其中,$x_n^T$表示所有样本第$n$个特征组成的向量的转置;$e = \hat{h} - y = (X \cdot \theta - y)$表示所有样本的误差;$\cdot$表示向量的点积(结果为一个标量)或矩阵乘法(结果为一个矩阵)。通过该式的表示,就把所有参数的偏导数表示成了一个式子。参数更新的过程就可以表示如下:
$$\theta = \theta - \alpha\nabla_{\theta}MSE(\theta) \quad \cdots \ (3-4)$$
下面是新的梯度下降的实现:
1 T = 1000 # 迭代次数 2 theta = np.ones((2, 1)) # 参数的初始化 3 alpha = 0.18 # 学习率 4 X_x0 = np.c_[np.ones((100, 1)), X] # ADD X0 = 1 to each instance 5 6 # print(np.multiply(delta, delta)) 7 8 # print(L_theta) 9 for i in range(T): 10 h = np.dot(X_x0, theta) 11 theta -= alpha * 1/m * np.dot(X_x0.T, h - y) 12 if i%100==0: 13 print(L_theta(theta, X_x0, y))
上面代码第11行是式子(3-4)的实现,比起方法1中的实现,不仅代码量更少,也不受参数数量的限制。而且矩阵的计算通常都经过了优化,计算起来效率也更高。所以能用向量化的方式表示的公式要尽量使用向量化表示。
上面的代码中将学习率放大了3倍,下面是每隔100次迭代相应参数下代价函数的取值:
1143.69070944 8.57809912576 8.31015455643 8.30961463254 8.30961354457 8.30961354237 8.30961354237 8.30961354237 8.30961354237 8.30961354237
从第600次迭代开始,代价函数的值开始保持不变,这说明后面的梯度等于0,参数已经取到了代价函数的最小值点,整个训练过程已经收敛。
最终训练出来的参数值如下:
array([[ 5.4812737 ],
[ 1.98144106]])
3.2.3 方法3 - 使用scikit-learn工具包
自己实现算法是学习算法最好的方式,当我们掌握了这类算法的基本原理,就不用每次都自己实现了。因为这些算法都是非常成熟的机器学习算法,有许多程序包都实现了这些算法。在Python中,使用比较广泛的是scikit-learn这个工具包,这个package最开始由google的暑期实习生David Cournapeau开发,第一个版本公开于2010年2月。现在是Python社区中开发活跃且广泛使用的开源机器学习工具。下面是使用sk-learn实现的线性回归分析:
1 from sklearn.linear_model import LinearRegression 2 lin_reg = LinearRegression() 3 lin_reg.fit(X, y) 4 print(lin_reg.intercept_, lin_reg.coef_)
结果如下:
[ 5.4812737] [[ 1.98144106]]
结果与方法2的结果相同,这验证了我们前面方法的正确性,也说明使用sk-learn直接就得到了参数的最优解。通过比较,可以发现sk-learn模型为我们做了下面这些事情:
- 参数的初始化;
- 选择学习率;
- 求代价函数的梯度;
- 参数的更新.
我们也不需要对输入的训练集做任何处理(例如前面的方法都需要为每一个样本点添加$x_0 = 1$),只需要选择算法并且输入带标签($y$)的训练集($X$)就可以了。模型训练完成后,截距($\theta_0$)的值保存在intercept_中,其他参数保存在coef_中。
下面使用训练好的线性回归模型预测新的样本点:
print(lin_reg.predict(X_new))
结果为:
[[ 6.47199423] [ 9.0478676 ]]
更多scikit-learn中关于线性回归模型的内容可以参考官方文档。
Reference
https://stackoverflow.com/a/18194919/2803344
http://scikit-learn.org/stable/modules/linear_model.html
Géron A. Hands-on machine learning with Scikit-Learn and TensorFlow: concepts, tools, and techniques to build intelligent systems[M]. " O'Reilly Media, Inc.", 2017. github
https://weibo.com/tv/v/F65eYBxan?fid=1034:14a15d4cfb023af5e168b015e7672ad4
https://en.wikipedia.org/wiki/Scikit-learn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号