

MySQL - 扩展性 1 概述:人多未必力量大
我们应该接触过或者听说过数据库的性能瓶颈问题。对于一个单机应用而言,提升数据库性能的最快路径就是氪金 - 买更高性能的数据库服务器,只要钱到位,性能不是问题。
但是当系统性能增加到一定地步时,你会发现,原先花 3000 块提升了 50% 的性能,现在花 30000 块,才提升了不到 10%。
也就是说,我们花了钱,但没有得到等价的性能提升,这个时候,我们就要考虑数据库的可扩展性了。
要讨论 MySQL 的可扩展性,就要先明确可扩展性的定义。在此之前,我们先抛开 MySQL,专注于扩展性,搞清楚什么是扩展性,才能更有针对性的去提高 MySQL 的扩展性。
1 什么是可扩展性
我们常常把“可扩展性”、“高可用性”以及“性能”用作同义词,但事实上它们是完全不同的。简单来说,性能是响应时间,可用性是宕机时间,而扩展性表明了当需要增加资源以执行更多工作时,系统能够获得等价的性能提升的能力。换种说法,可扩展性就是我们能够尽可能的花费相同的资源提升等价的性能。而缺乏扩展能力的系统在达到收益递减的转折点后,将无法进一步增长。
容量是一个和可扩展性相关的概念。系统容量表示在一定时间内能够完成的工作量。
容量和可扩展性并不依赖于性能。以高速公路上的汽车来类比的话:
- 性能是汽车的时速。
- 容量是车道乘以最大安全时速。
- 可扩展性就是在不减慢交通的情况下,能增加更多车和车道的程度。
在上面这个类比中,可扩展性依赖多个条件:换道设计是否合理、路上有多少车抛锚或发生事故、汽车行驶速度不同以及是否频繁变换车道。但一般来说,和汽车的引擎是否强大无关。
这并不是说性能不重要,性能确实重要,只是要注意的是,即使系统性能不是很高的系统也可以具备可扩展性。
从较高层次看,可扩展性就是能够通过增加资源来提升容量的能力。
对于容量,我们可以简单的认为是处理负载的能力,而从不同的角度考虑负载对我们优化扩展性很有帮助。
数据量
应用所能累计的数据量是可扩展性最普遍的挑战,特别是对于现在的互联网应用而言,因为从不删除数据。
用户量
首先,即使每个用户只有少量的数据,但在累计到一定数量的用户后,数据量也会开始不成比例的增长,且速度快过用户数增长。其次,更多的用户意味着要处理更多的事务,并且事务数可能和用户数不成比例。最后,大量用户也意味着更多复杂的查询。
用户活跃度
不是所有的用户活跃度都相同,并且用户活跃度也不总是不变的。如果用户突然变得活跃,例如 github 给小团队免费开放了私有化仓库,那么其对应的负载可能会明显提升。要注意的是,用户活跃度不仅仅指页面浏览数(PV),即使同样的 PV,如果网站的某个需要执行大量查询工作的功能变得更受欢迎,也可能导致更多的工作。
相关数据集的大小
如果用户间存在关系,应用可能需要在整个相关联用户群体上执行查询和计算,这比处理一个个的用户和用户数据要复杂的多。
说了这么多,只是为了让我们更好的理解可扩展性的让我们用下面图表来更明确的表达可扩展性。
假设有一个只有一台服务器的系统,并且能够测量它的最大容量,如图 1 所示:
假设我们现在增加一台服务器,系统的能力加倍,如图 2 所示:
图 2 就是线性扩展。我们增加了一倍的服务器,增加了一倍的容量。然而,理想是美好的,现实是骨感的。大部分系统并不是线性扩展的,而是如图 3 所示的扩展方式:
大部分系统都只能以比线性扩展略低的扩展系数进行扩展。这就导致,多数系统最终会达到一个最大吞吐量临界点,超过这个点后增加投入可能反而会降低系统的吞吐量。
到这一步,大家对扩展性应该已经有一个较为清晰的概念了。在此基础上,让我们再深入一步:Amdahl 扩展 和 USL 扩展。
简而言之,USL 说的是线下扩展的偏差可通过两个因素来建立模型:
- 无法并发执行的一部分工作;
- 需要交互的另外一部分工作。
在对第一个因素继续建模后,就有了著名的(听过这个著名吗?)阿姆达尔定律(Amdahl)。第一个因素最终会导致吞吐量趋于平缓。如果部分任务无法并行,那么不管你如果分而治之,该任务至少需要串行部分的时间。这句话很重要,让我们用一个栗子再简单阐述下:
假设大家都做过韭菜煎蛋这道菜,我们做这道菜时,有几个必要步骤:
- 切韭菜,耗时 t1;
- 打蛋液,耗时 t2;
- 开煎,耗时 t3;
就上面 3 个步骤而言,你可以在切韭菜的时候,让你女票帮你打蛋液,也就是说 1、2 是可以并行的,但是我们能边切菜边煎吗?或者边打蛋液边煎吗?显示是不行的。因此,步骤 3 和 1、2 是串行的。
这时候,我们就会发现,做韭菜煎蛋这个任务需要的时间 t 为:
t = MAX(t1, t2) + t3;
对第二个因素,需要交互的工作而言,交互就意味着内部节点间或者进程间的通信。这种通信的代价取决于通信信道的数量,而信道的数量将按照系统内工作者数量的二次方增长,所以最终开销比带来的收益增长的更快,这就是产生扩展性倒退的原因。由此和 Amdahl 定律,就得出了 USL。
图 4 阐明了目前讨论的三个概念:线性扩展、Amdahl 扩展以及 USL 扩展。而大多数真实系统看起来更像 USL 曲线。
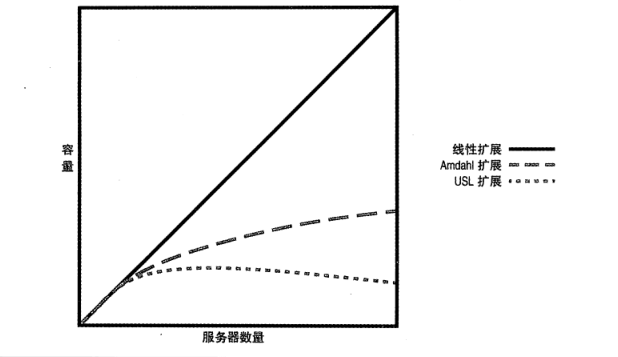
至此,关于扩展性的概念描述告一段落。接下来,我们回到正题,看看 MySQL 的扩展性如何规划。
2 规划可扩展性
什么情况下需要扩展?,这是个值得我们牢记的问题。当我们提到系统的可扩展性时,一般只有两种情况:
- 刚开始规划一个应用;
- 当前应用无法满足增加的负载;
上述两种情况,大多数情况下我们碰到的应该都是后者。具体表现为:
- CPU 密集型变成 I/O 密集型;
- 并发查询竞争;
- 不断增大的延迟;
如果是可扩展的应用,可以简单地增加更多的服务器来分担负载。但如果是可扩展性比较差的,你就会发现 - 只剩下提高可扩展性这一条路可走。
只有一条路,那就且行且 996 吧!
走上了提升扩展性这条路,接下来的问题就是,如何提高可扩展性?这里比较困难的部分是估算应用承担的负载到底有多少?这个值不一定非常精确,但必须在一定的数量级范围内。什么?你问为什么要在一定范围内?不清楚敌人的火力,咱们是准备用高射炮打蚊子还是用大刀对机枪呢?
除此之外,为了能帮助我们更好的规划可扩展性,咱们最好还能想清楚下面这个问题:
- 应用的核心功能完成了多少?很多可扩展性方案可能会导致某些功能实现起来更加复杂。在核心功能没完成前,问问自己,真的要走提升扩展性这条路吗?换个说法,准备好迎接 996 了吗?
3 为扩展赢得时间
程序员们理想的开发环境应该是:计划先行、有足够能够一起战斗的同伴、有花不完的预算等等。但现实是:
- boss:诶,小九啊,咱们系统提升下性能要多久啊?三天应该差不多了吧,最多不能超过一周,上次提升性能,小六一天就搞定了的。
- 小九:。。。卒
正常情况下,提升系统的扩展性的难度可能要比重构的难度还要大。因此,在你没有完全把系统摸熟悉,或对扩展性还模糊的时候,千万别给老板说要提升系统的扩展性。
在老板要求提升性能时,你要想尽一切办法满足他提升性能的需求,同时,要多想下如何提高系统的扩展性,为将来提升扩展性赢得时间。
可以通过以下工作先提升系统性能:
- 优化性能。很多时候可以通过一个简单的改动来获得明显的性能提升。例如为表建立正确的索引,或从 MyISAM 切换到 InnoDB。再进一步,可以通过慢日志来分析。
- 购买性能更强的硬件。在应用早期,升级或增加服务器可以显著的提升系统性能,并且还能快速的完成。就像我们把服务器从 1 台增加到 3 台,可能就能让性能提升 100%,但是当我们的服务器已经到达 100 台时,再从 100 增加到 300,这时候的复杂度和成本可能已经让你心甘情愿走上提升系统扩展性的道路上了。
总结
- 扩展性是当需要增加资源以执行更多工作时,系统能够获得等价的性能提升的能力。
- 不准确评估应用负载的扩展,都是耍流氓。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号