
使用ML.NET实现基于RFM模型的客户价值分析
RFM模型
在众多的客户价值分析模型中,RFM模型是被广泛应用的,尤其在零售和企业服务领域堪称经典的分类手段。它的核心定义从基本的交易数据中来,借助恰当的聚类算法,反映出对客户较为直观的分类指示,对于没有数据分析和机器学习技术支撑的初创企业,它是简单易上手的客户分析途径之一。
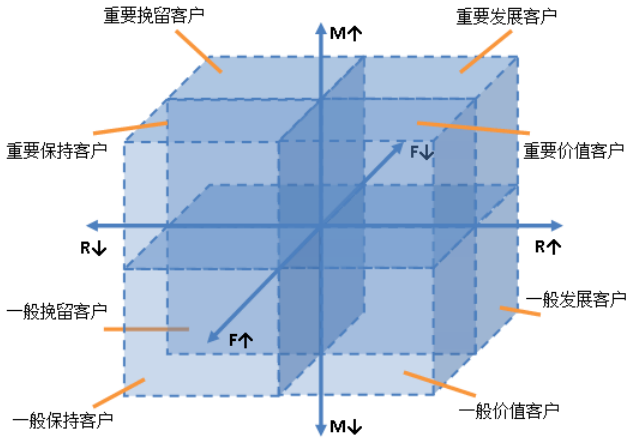
RFM模型主要有三项指标:
Recency:最近消费时间间隔
Frequency:消费频率
Monetary:消费金额
我们为客户在这三项指标上进行打分,那么总共会有27种组合的可能,使用K-Means算法,能够缩减到指定的有限数量的分箱(一般会为5类),计算出每个客户在分箱的位置即客户的价值。
当然RFM模型还有更多衍生版本,可以参考WiKi:RFM (customer value)。
ML.NET和K-Means
ML.NET自v0.2版本就提供了K-Means++ clustering的实现,也是非监督学习最常见的训练,正好适用于为RFM模型的分类执行机器学习。
动手实践
基本要求
- Visual Studio 2017 或者 Visual Studio Code
- DotNet Core 2.0+
- ML.NET v0.3
数据来源
本案例数据来自UCI:Online Retail,这是一个跨国数据集,其中包含2010年12月1日至2011年12月9日期间在英国注册的非商店在线零售业务中发生的所有交易。该公司主要销售独特的全场礼品。该公司的许多客户都是批发商。
属性信息:
InvoiceNo:发票编号。标称值,为每个事务唯一分配的6位整数。如果此代码以字母'c'开头,则表示取消。
StockCode:产品(项目)代码。标称值,为每个不同的产品唯一分配的5位整数。
Description:产品(项目)名称。标称。
Quantity:每笔交易的每件产品(项目)的数量。数字。
InvoiceDate:发票日期和时间。数字,生成每个事务的日期和时间。
UnitPrice:单价。数字,英镑单位产品价格。
CustomerID:客户编号。标称值,为每个客户唯一分配的5位整数。
Country:国家名称。每个客户所在国家/地区的名称。
数据处理
- 使用Excel,对原始数据增加4个字段,分别是Amount(金额,单价与数量相乘的结果)、Date(InvoiceDate的整数值)、Today(当天日期的整数值)、DateDiff(当天与Date的差值)。

- 建立透视图,获取每个客户在Amount上的总和,DateDiff的最大和最小值,并且通过计算公式
Amount/(DateDiff最大值-DateDiff最小值+1)算出频率值。
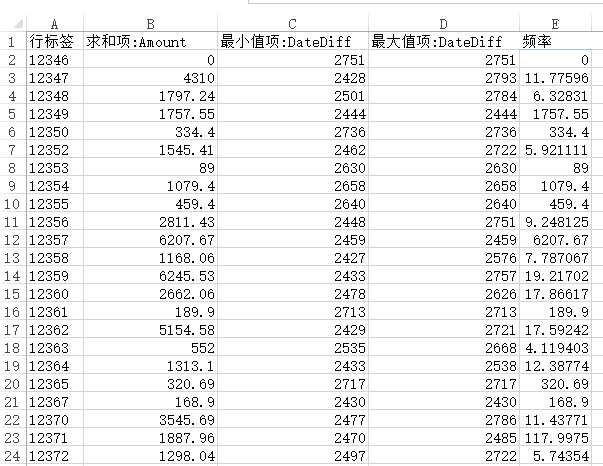
- 按照以下规则计算RFM的评分
- R:
(DateDiff最大值- DateDiff最小值-2000)的差值,小于480计3分,480-570之间计2分,570-750之间计1分,大于750计0分。 - F:频率值,大于1000计5分,500-1000之间计4分,100-500之间计3分,50-100之间计2分,0-50之间计1分,小于0计0分。
- M:Amount总和值,大于10000计5分,5000-10000之间计4分,2000-5000之间计3分,1000-2000之间计2分,0-1000之间计1分,小于0计0分。
- R:
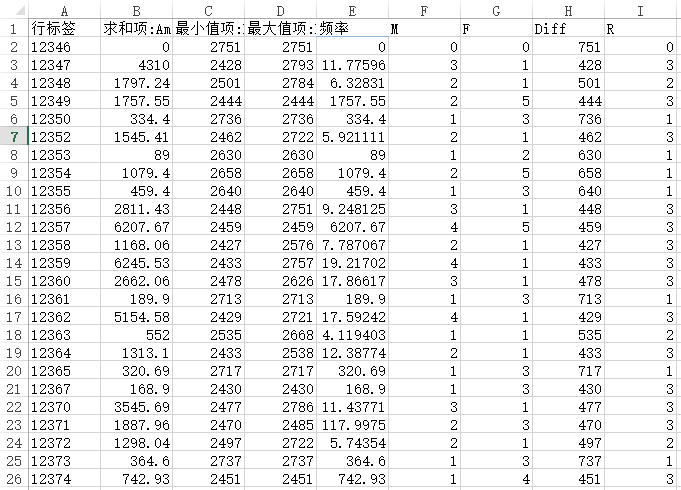
有小伙伴可能存在疑问,为什么要这么划分,其实这就是对数据分布合理分段的一种思想,为了减小数据源的不平衡性对机器学习的影响,我们尽量使得数据的分布是自然的。
编码部分
还是熟悉的味道,创建DotNet Core控制台应用程序,通过Nuget添加对ML.NET的引用。
- 创建用于学习的数据结构
public class ClusteringPrediction
{
[ColumnName("PredictedLabel")]
public uint SelectedClusterId;
[ColumnName("Score")]
public float[] Distance;
}
public class ClusteringData
{
[Column(ordinal: "0")]
public string CustomId;
[Column(ordinal: "1")]
public float Amount;
[Column(ordinal: "2")]
public float MinDataDiff;
[Column(ordinal: "3")]
public float MaxDataDiff;
[Column(ordinal: "4")]
public float MeanAmount;
[Column(ordinal: "5")]
public float M;
[Column(ordinal: "6")]
public float F;
[Column(ordinal: "7")]
public float RelativaDataDiff;
[Column(ordinal: "8")]
public float R;
}
- 训练部分
static PredictionModel<ClusteringData, ClusteringPrediction> Train()
{
int n = 1000;
int k = 5;
var textLoader = new Microsoft.ML.Data.TextLoader(DataPath).CreateFrom<ClusteringData>(useHeader: true, separator: ',', trimWhitespace: false);
var pipeline = new LearningPipeline();
pipeline.Add(textLoader);
pipeline.Add(new ColumnConcatenator("Features",
"R",
"M",
"F"));
pipeline.Add(new KMeansPlusPlusClusterer() { K = k });
var model = pipeline.Train<ClusteringData, ClusteringPrediction>();
return model;
}
- 评估部分
static void Evaluate(PredictionModel<ClusteringData, ClusteringPrediction> model)
{
var textLoader = new Microsoft.ML.Data.TextLoader(DataPath).CreateFrom<ClusteringData>(useHeader: true, separator: ',', trimWhitespace: false);
var evaluator = new ClusterEvaluator();
var metrics = evaluator.Evaluate(model, textLoader);
Console.WriteLine("AvgMinScore:{0}", metrics.AvgMinScore);
Console.WriteLine("Dbi:{0}", metrics.Dbi);
Console.WriteLine("Nmi:{0}", metrics.Nmi);
}
- 预测部分
static void Predict(PredictionModel<ClusteringData, ClusteringPrediction> model)
{
var predictedData = new ClusteringData()
{
R = 3F,
M = 3F,
F = 1F
};
var predictedResult = model.Predict(predictedData);
Console.WriteLine("the predicted cluster id is: {0}", predictedResult.SelectedClusterId);
}
- 调用部分
static void Main(string[] args)
{
var model = Train();
Evaluate(model);
Predict(model);
}
- 运行结果

可以看到,我用于测试的客户,被分到了第2类上面。
尽管完成了聚类的工作,对于学习出来的这5个类别,仍然需要按原始数据集全部遍历预测出对应的分类,根据客户的RFM评分与分类的对应关系,才能够对每个类别的意义进行有效地解释。
结尾
这个简单的案例为大家展示了使用ML.NET完成聚类的机器学习。对于想要上手针对自己公司的业务,进行一些门槛较低的客户分析,使用ML.NET将是一个不错的选择。当然ML.NET还在不断迭代中,希望大家持续关注新的特性功能发布。
完整代码如下:
using Microsoft.ML;
using Microsoft.ML.Models;
using Microsoft.ML.Runtime.Api;
using Microsoft.ML.Trainers;
using Microsoft.ML.Transforms;
using System;
namespace RMFClusters
{
class Program
{
const string DataPath = @".\Data\Online Retail.csv";
public class ClusteringPrediction
{
[ColumnName("PredictedLabel")]
public uint SelectedClusterId;
[ColumnName("Score")]
public float[] Distance;
}
public class ClusteringData
{
[Column(ordinal: "0")]
public string CustomId;
[Column(ordinal: "1")]
public float Amount;
[Column(ordinal: "2")]
public float MinDataDiff;
[Column(ordinal: "3")]
public float MaxDataDiff;
[Column(ordinal: "4")]
public float MeanAmount;
[Column(ordinal: "5")]
public float M;
[Column(ordinal: "6")]
public float F;
[Column(ordinal: "7")]
public float RelativaDataDiff;
[Column(ordinal: "8")]
public float R;
}
static PredictionModel<ClusteringData, ClusteringPrediction> Train()
{
int n = 1000;
int k = 5;
var textLoader = new Microsoft.ML.Data.TextLoader(DataPath).CreateFrom<ClusteringData>(useHeader: true, separator: ',', trimWhitespace: false);
var pipeline = new LearningPipeline();
pipeline.Add(textLoader);
pipeline.Add(new ColumnConcatenator("Features",
"R",
"M",
"F"));
pipeline.Add(new KMeansPlusPlusClusterer() { K = k });
var model = pipeline.Train<ClusteringData, ClusteringPrediction>();
return model;
}
static void Evaluate(PredictionModel<ClusteringData, ClusteringPrediction> model)
{
var textLoader = new Microsoft.ML.Data.TextLoader(DataPath).CreateFrom<ClusteringData>(useHeader: true, separator: ',', trimWhitespace: false);
var evaluator = new ClusterEvaluator();
var metrics = evaluator.Evaluate(model, textLoader);
Console.WriteLine("AvgMinScore:{0}", metrics.AvgMinScore);
Console.WriteLine("Dbi:{0}", metrics.Dbi);
Console.WriteLine("Nmi:{0}", metrics.Nmi);
}
static void Predict(PredictionModel<ClusteringData, ClusteringPrediction> model)
{
var predictedData = new ClusteringData()
{
R = 3F,
M = 5F,
F = 1F
};
var predictedResult = model.Predict(predictedData);
Console.WriteLine("the predicted cluster id is: {0}", predictedResult.SelectedClusterId);
}
static void Main(string[] args)
{
var model = Train();
Evaluate(model);
Predict(model);
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号