

EEG2Video: Towards Decoding Dynamic Visual Perception from EEG Signals
EEG2Video: Towards Decoding Dynamic Visual Perception from EEG Signals
动机
- 探索从EEG解码动态视觉感知(视频)
- 填充EEG-视频数据集的空白
数据集
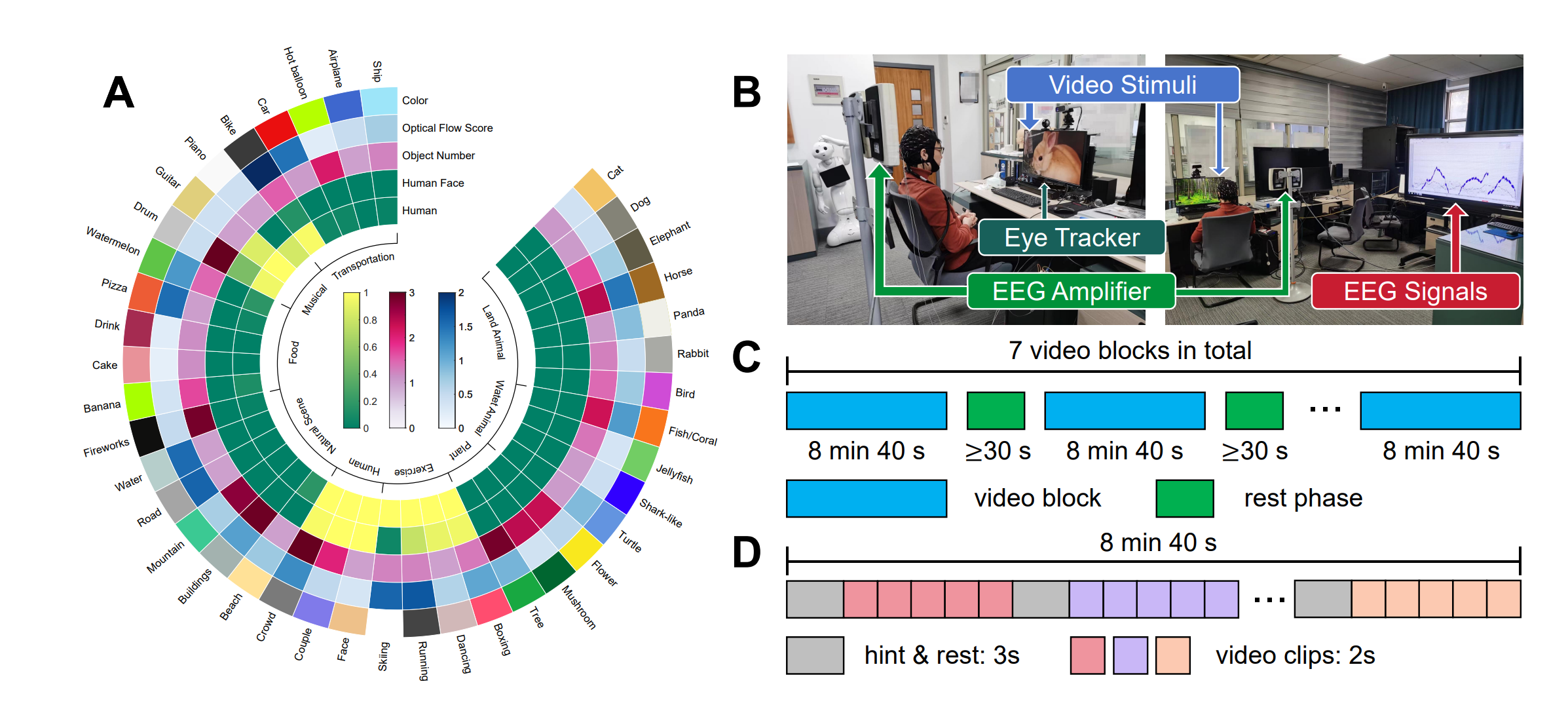
本文提出了一个EEG-视频数据集SEED-DV,包含40个概念(Concept),共计1400个视频片段。
每个概念收集了35个不同的2秒视频片段,分为7组,每组5个。随后,根据将\(40\times7\)个组重新随机排列,得到7个块(block)。每个块内包含40组不同概念的视频,即块内有\(40\times5\)个视频,块内40个标签的视频顺序为随机。
数据采集使用62通道10-10系统,采样率为1000Hz;同时也采集了EOG、ECG以及250Hz的眼动。共有20名受试者参与。
方法

本文方法比较直接。模型训练主要的思路可以分两条支路:
- EEG
- 将原始数据编码为特征\(\hat{z}_0\),并预测相应的语义特征\(\hat{e}_t\)及动态信息\(\hat{e}_d\)
- \(\hat{z}_0\)参考\(\hat{e}_t\)通过扩散模型生成\(z_0\),\(\hat{e}_d\)控制噪声的加权参数\(\beta\)
- \(z_0\)通过预训练VAE解码为视频
- 视频
- 通过与训练VAE编码得到\(z_0\)(黄),通过预训练CLIP得到语义特征\(e_t\)
- \(z_0\)(黄)参考\(e_t\)通过扩散模型生成\(z_0\)(粉)
- \(z_0\)(粉)通过预训练VAE解码为视频
这两条支路上的\((z_0,\hat{z}_0)\)以及\((e_t,\hat{e}_t)\)通过MSE损失进行对齐。
实验
EEG分类
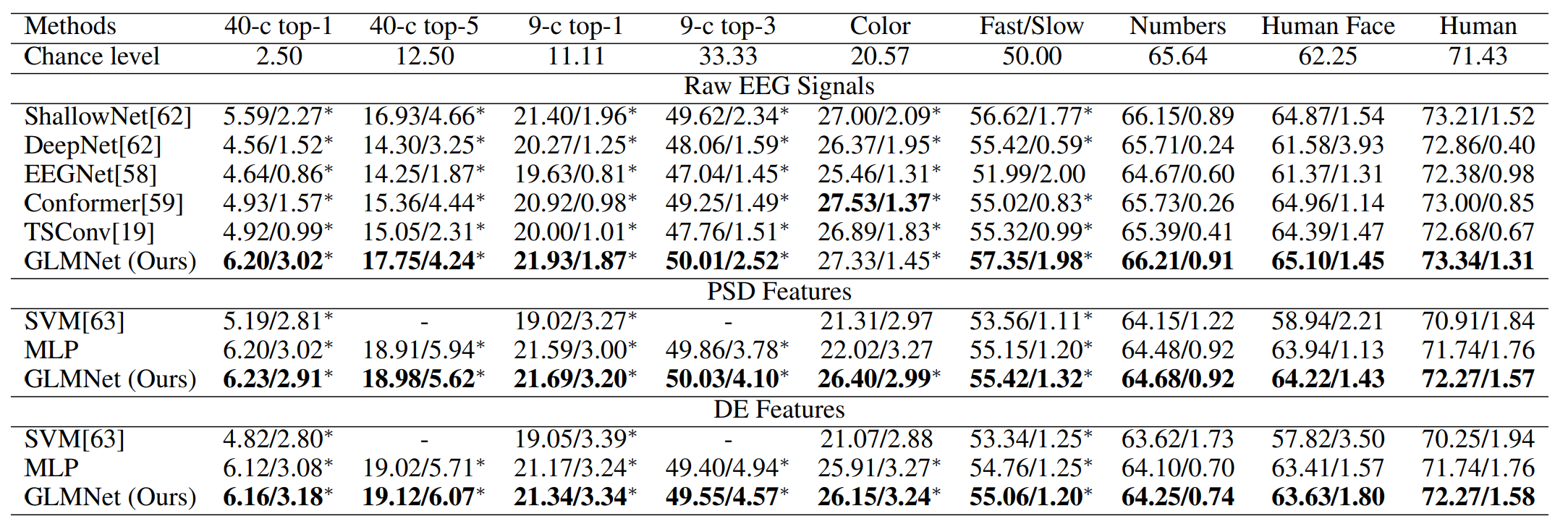
尝试以EEG为输入,分类视频的一些信息,包括视频概念、视频颜色等。作者认为实验结果表明EEG解码这些信息是可能的。
EEG视频生成
定量分析
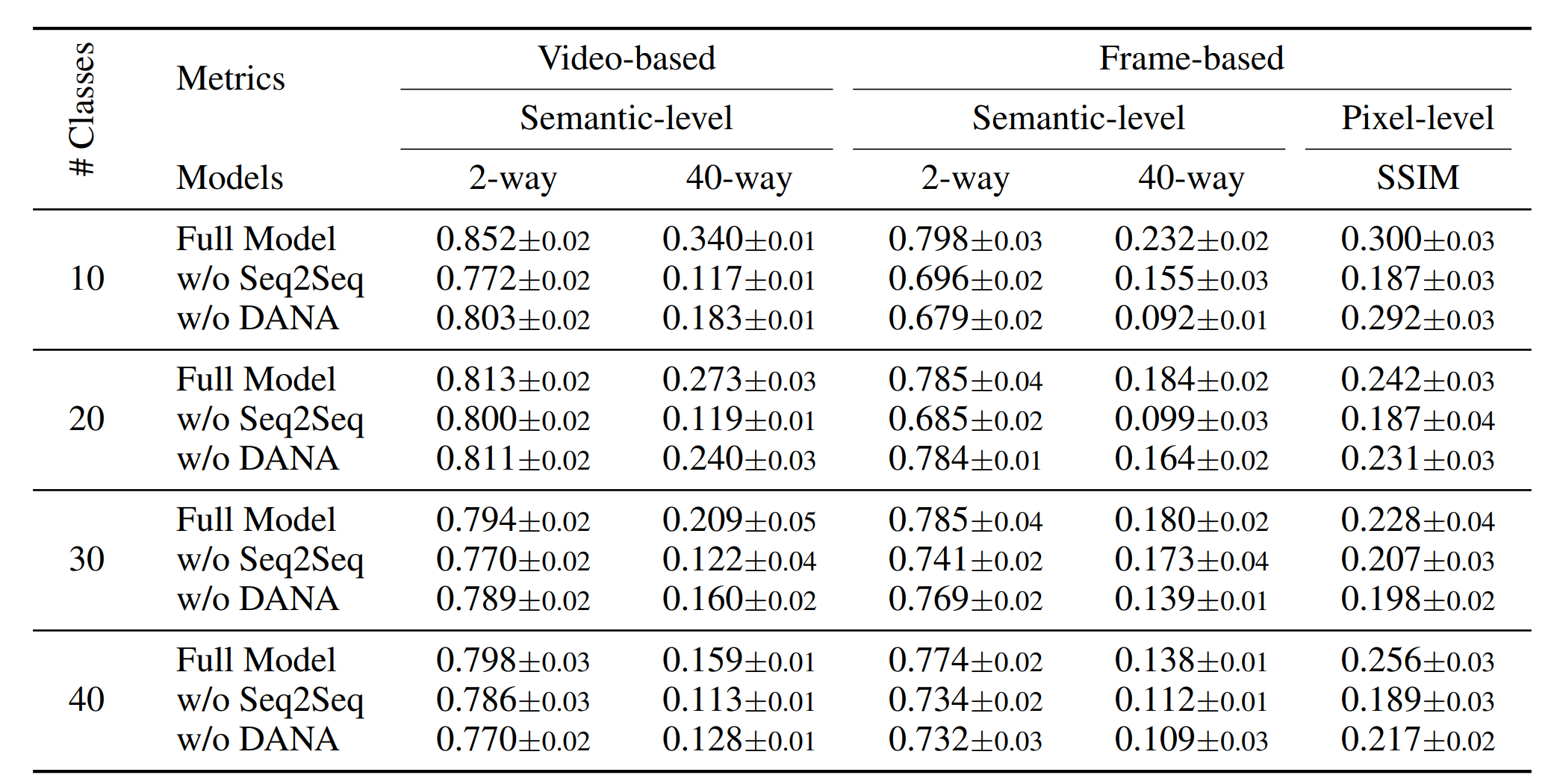
根据Rebuttal的信息,这里的“40-way”表示用一个训练好的40类分类器作为评估标准,此处作者参考了已有工作的评价方法。
重建结果
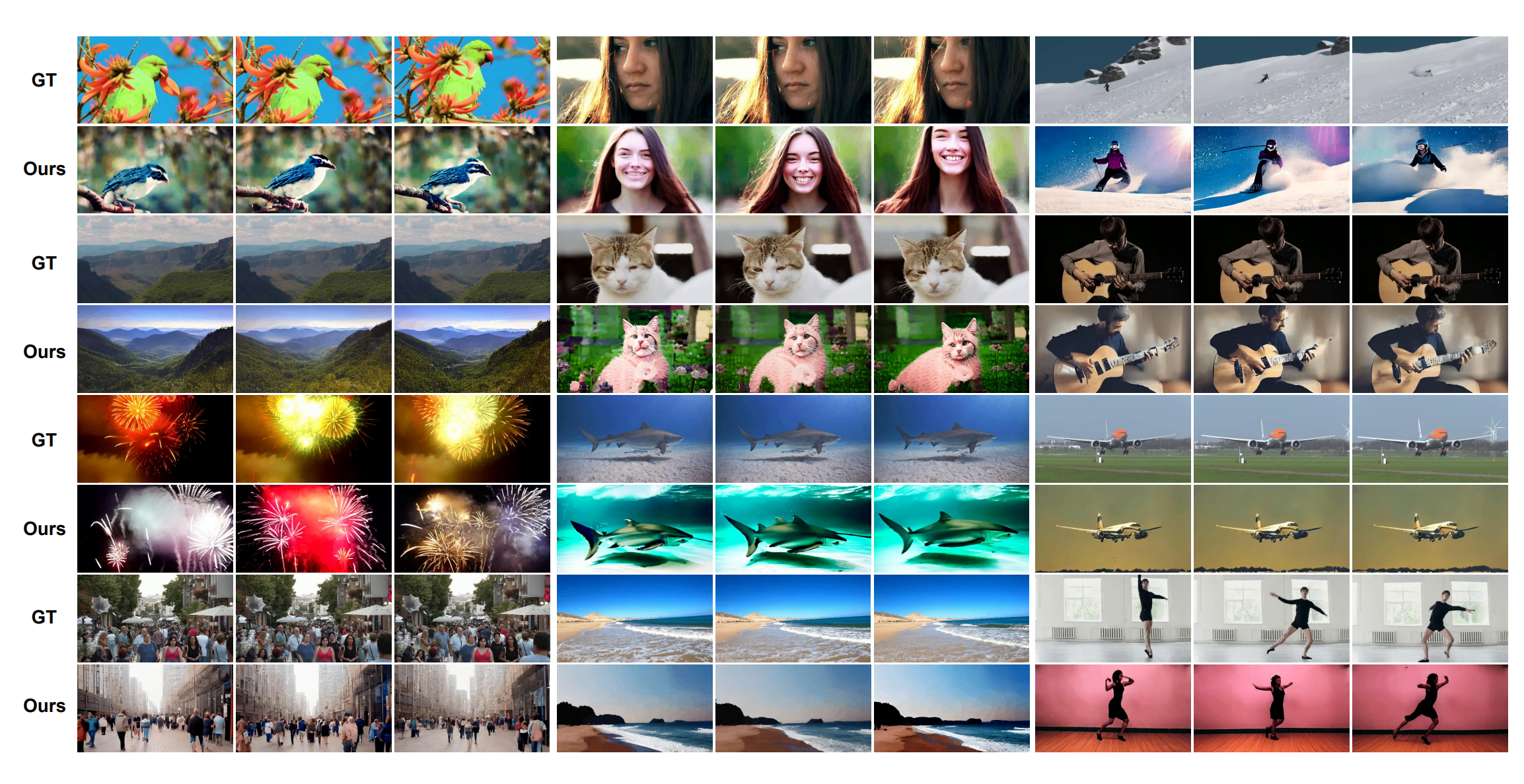
总结
本文是首个构建EEG-视频数据集并藉此完成EEG-视频生成任务的工作。然而,其依然存在一些不足。
-
虽然作者展示了一些EEG分类的结果,但实际上模型的分类性能距离“Chance-level”差距不大,因此也受到审稿人质疑。作者则声明这一实验本身就难度颇大,此处仅是为了探索EEG解码性能的边界。但笔者认为,就实验结果所反映的性能而言有些微妙。
-
虽然作者给出的重建结果中,确实能够还原观看视频的标签、颜色等信息。但是这些信息基本集中在高层语义(标签)或者是低频信息(颜色)。准确重建视频的结构、边缘等高频信息显然还是较为困难。
-
有审稿人质疑,本文工作是否仅仅是做了从EEG到概念(标签)的映射,而视频生成则仅由后续的扩散模型完成(大意)。作者和审稿人后续的讨论主要集中在“标签泄露”之类的问题上,不过作者也提到,本文的工作接近一种模态转换,要想实现更好的性能需要大量的数据支撑,而本文作为一个先锋工作,目前受限于现有的数据等只能做到目前的地步。但这也确实是本文工作无法避免的问题:生成的过程高度依赖预训练模型,例如视觉-语言模型、VAE等。在实际的实现中也是落在特征层面上的对齐。所以可能导致,解码EEG得到的特征更关注语义和低频信息这些容易在自编码过程中保留的信息,也就导致了高频信息的丢失。再加上,生成过程由扩散模型完成,而扩散模型的特点就是更擅长语义上的还原,而不是像素级对齐细节的还原。因此,本文虽然大量使用了“重建”标榜自己的工作,但实际上更接近于“EEG解码+视频生成”,其中存在一些微妙的差别和讨论空间,但考虑到本文确实是首个相关工作,其探索和贡献也不能忽略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号