
面向对象
面向对象编程
核心是‘对象’二字,对象指的是盛放相关的数据与功能的容器
基于该思想编写程序就在创造一个个的容器来把相关的东西盛到一起
优点:扩展性强
缺点:加大了编程的复杂度
类
类是用来解决对象之间代码冗余问题的
类定义阶段发生的三件事:
1、会执行类体的代码
2、会产生一个类的名称空间,用来将类体代码运行过程中产生的名字都丢进去
3、将名称空间的内存地址绑定给类名
类调用阶段发生了三件事:
1、会创建空对象(调用__ new __方法来创建的空对象)
2、会自动触发类中__ init __ 函数的运行,__ init __ (空对象,‘egon’,18,‘male’),完成对象的初始化操作。注意:__init __ 不能有返回值
3、返回该对象,赋值给stu1_dic
封装
封装指的就是把数据与功能都整合到一起,听起来是不是很熟悉,没错,我们之前所说的”整合“二字其实就是封装的通俗说法。
class Student:
school = '上海DNF培训'
def __init__(stu_name, name, age, gender, courses=None):
if courses is None:
courses = []
stu_name.name = name
stu_name.age = age
stu_name.gender = gender
stu_name.courses = courses
def choice_course(str_dic, course):
str_dic.courses.append(course)
print('学生', str_dic['name'], '选课成功:', course)
stu_name1 = Student('egon', 18, 'male')
stu_name2 = Student('飞鹏', 25, 'female')
print(stu_name1.__dict__)
# {'name': 'egon', 'age': 18, 'gender': 'male', 'courses': []}
print(stu_name2.__dict__)
# {'name': '飞鹏', 'age': 25, 'gender': 'female', 'courses': []}
print(Student.__dict__)
# {'__module__': '__main__', 'school': '上海DNF培训', '__init__': <function Student.__init__ at 0x00000168B638B1F0>, 'choice_course': <function Student.choice_course at 0x00000168B638B160>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None}
备注:
对象实例化之后 __dict__ 打印的是对象所有的属性
Student.__dict__ 打印的是类所包含的所有属性
类中有两种属性:
1、数据属性
print(Student.school)
2、函数属性
Student.choose_course
但是类中的属性其实是为对象准备
1、类的属性是直接共享给所有对象用的
2、类的函数属性是绑定给对象用的
类中定义的函数分为两大类
1、绑定方法:
特点:绑定给谁就应该由谁来调用,谁来调用就会将自己当做第一个参数传入
绑定给对象
但凡在类中定义一个函数,默认就是绑定给对象的,应该由对象来调用,会将对象当作第一个参数自动传入
绑定给类
如果想要将函数绑定给类的话就需要用到绑定到类的方法:用classmethod装饰器装饰的方法。
类中定义的函数被classmethod装饰过,就绑定给类,应该由类来调用。
类来调用会类本身当作第一个参数自动传入。
2、非绑定方法:
特点:不与类和对象绑定,意味着谁都可以来调用,但是无论谁来调用就是一个普通函数,没有自动传参的效果
类中定义的函数被staticmethod装饰过,就成一个非绑定的方法即一个普通函数。
谁都可以调用,但无论谁来调用就是一个普通函数,没有自动传参的效果
注意:与绑定到对象方法区分开,在类中直接定义的函数,没有被任何装饰器装饰的,都是绑定到对象的方法,可不是普通函数,对象调用该方法会自动传值,而staticmethod装饰的方法,不管谁来调用,都没有自动传值一说
# text_one.py
IP = '11.22.33.44'
PORT = 8080
# -------py---------
import text_one
import uuid
class Mysql:
def __init__(self, IP, PORT):
self.id =self.crteae_id()
self.ip = IP
self.port = PORT
# 但凡在类中定义一个函数,默认就是绑定给对象的,应该由对象来调用,
# 会将对象当作第一个参数自动传入
def tell_info(self):
print(' > %s:%s < ' % (self.ip, self.port))
# 类中定义的函数被classmethod装饰过,就绑定给类,应该由类来调用,
# 类来调用会类本身当作第一个参数自动传入
@classmethod
def from_conf(cla):
return cla(text_one.IP, text_one.PORT)
# 类中定义的函数被staticmethod装饰过,就成一个非绑定的方法即一个普通函数,谁都可以调用,
# 但无论谁来调用就是一个普通函数,没有自动传参的效果
@staticmethod
def crteae_id():
return uuid.uuid4()
obj = Mysql.from_conf()
print(obj.__dict__)
隐藏属性
针对封装到对象或者类中的属性,我们还可以严格控制对它们的访问,分两步实现:隐藏与开放接口.
隐藏属性的真正目的就是为了不让使用者在类外部的直接操作属性
__开头的属性隐藏有四个特点:
1、并不是真正的隐藏,只是一种语法意义上的变形
2、该变形操作只在类定义阶段扫描语法时发生一次,类定义之后__开头的属性不会变形
3、该隐藏对外不对内
4、可以防止子类覆盖父类的某个属性
在python中用双下划线开头的方式将属性隐藏起来(设置成私有的),但其实这仅仅只是一种变形操作
# 类中所有双下划线开头的名称如__x都会在类定义时自动变形成:_类名__属性名的形式:
class People:
# 类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的 ↓
__country = "China" # 变形为 _People__country = "china"
def __init__(self,name,age):
self.__name = name # self._People__name = name
self.__age = age # self._people__age = age
def __func(self): # _People__func
print('xx')
def tell_name(self):
print(self.__name) # self._People__name
print(People._People__country) # 只有在类内部才可以通过__开头的形式访问到.
print(People._People__func)
print(People.__dict__)
obj1 = People("egon",18)
print(obj1.__dict__)
# __开头的属性的特点:
# 1、并没有真的藏起来,只是变形了
# 2、该变形只在类定义阶段、扫描语法的时候执行,此后__开头的属性都不会变形
obj1.__gender = "male"
print(obj1.__dict__)
print(obj1.__gender )
# 3、该隐藏对外不对内
obj1.tell_name()
封装的真谛在于明确地区分内外,封装的属性可以直接在内部使用,而不能被外部直接使用,然而定义属性的目的终归是要用,外部要想用类隐藏的属性,需要我们为其开辟接口,让外部能够间接地用到我们隐藏起来的属性,那这么做的意义何在???
1、隐藏数据属性的目的
将数据隐藏起来这不是目的。隐藏起来然后对外提供操作该数据的接口,然后我们可以在接口附加上对该数据操作的限制,以此完成对数据属性操作的严格控制。
# 为何要隐藏属性
# 1、隐藏数据属性为了严格控制类外部访问者对属性的操作
class People:
def __init__(self, name, age):
self.__name = name
self.age = age
def get_name(self):
print(self.__name)
def setter_name(self, name):
if not type(name) is str:
print('必须输入字符')
return
self.__name = name
def del_name(self):
del self.__name
obj = People('矮根', 15)
obj.get_name() # 矮根
obj.setter_name(123) # 必须输入字符
obj.get_name() # 矮根
obj.del_name() # 删除name
2、隐藏函数属性的目的
# 取款是功能,而这个功能有很多功能组成:插卡、密码认证、输入金额、打印账单、取钱
# 对使用者来说,只需要知道取款这个功能即可,其余功能我们都可以隐藏起来,很明显这么做
# 隔离了复杂度,同时也提升了安全性
# 隔离复杂度的例子
class ATM:
def __card(self):
print('插卡')
def __auth(self):
print('用户认证')
def __input(self):
print('输入取款金额')
def __print_bill(self):
print('打印账单')
def __take_money(self):
print('取款')
def withdraw(self):
self.__card()
self.__auth()
self.__input()
self.__print_bill()
self.__take_money()
a=ATM()
a.withdraw()
小结:
真正的封装是,经过深入的思考,做出良好的抽象,给出“完整且最小”的接口,并使得内部细节可以对外透明
(注意:对外透明的意思是,外部调用者可以顺利的得到自己想要的任何功能,完全意识不到内部细节的存在)
property
类的装饰器
property是一种特殊的属性,访问它时会执行一段功能(函数)然后返回值
为函数伪装成数据类型
class Student:
def __init__(self, name, age, gender):
self.__name = name
self.age = age
self.gender = gender
def get_name(self):
return '学生:%s' % self.__name
def sel_name(self, name):
self.__name = name
name = property(get_name, sel_name)
s1 = Student('小明', 20, 'male')
print(s1.name)
s1.name = '晓鹏飞啊'
print(s1.name)
# 学生:小明
# 学生:晓鹏飞啊
# ------------------------------------------
class Student:
def __init__(self, name, age, gender):
self.__name = name
self.age = age
self.gender = gender
@property # 1.查看行为
def name(self): # 被property装饰的name函数,其实是__name被藏起来了
return '学生:%s' % self.__name
@name.setter # 2.修改行为
def name(self, name):
self.__name = name
@name.deleter # 3.删除行为
def name(self):
del self.__name
print('删除成功')
s1 = Student('小明', 20, 'male')
print(s1.name) # 通过@property访问到的self.__name的属性
# 学生:小明
s1.name = '小鹏飞啊' # 对应修改name行为
print(s1.name)
# 学生:小鹏飞啊
del s1.name # 对应删除name行为
# 删除成功
# ps: 配合property可以先将一个属性藏起来,__name这个属性被藏起来了,藏起来之后定义三个函数都叫name
# 这三个函数里面分别写上name的1、2、3的三种行为,跟操作一一对应
继承
什么是继承
继承是创建新类的一种方式,新建的类称之为子类/派生类,被继承的类称之为父类、基类、超类
继承的特点:子类可以遗传父类的属性
为什么要用继承
类是用来解决对象之间冗余问题的
而继承则是解决类与类之间冗余问题的
如何继承
在python中支持多继承
在python 3 中如果一个类没有继承任何父类,那么默认继承objece类
但凡是继承了object类的子类,以及该字类的子子孙孙类都能用到object内的功能,称之为新式类
没有继承了object类的字类,以及该字类的子子孙孙类都用不到object内的功能,称之为经典类
ps:只有在python2中才区分经典类与新式类,python3都是新式类
-
先抽象再继承
继承描述的是子类与父类之间的关系,是一种什么是什么的关系。要找出这种关系,必须先抽象再继承
抽象即抽取类似或者说比较像的部分。
抽象分成两个层次:
1.将奥巴马和梅西这俩对象比较像的部分抽取成类;
2.将人,猪,狗这三个类比较像的部分抽取成父类。
抽象最主要的作用是划分类别(可以隔离关注点,降低复杂度)
继承:是基于抽象的结果,通过编程语言去实现它,肯定是先经历抽象这个过程,才能通过继承的方式去表达出抽象的结构。
抽象只是分析和设计的过程中,一个动作或者说一种技巧,通过抽象可以得到类
-
继承背景下的属性查找
# 示例1 class Bar: # 定义类 def f1(self): print('Bar.f1') def f2(self): print('Bar.f2') self.f1() # obj.f1() class Foo(Bar): def f1(self): print("Foo.f1") obj = Foo() obj.f2() # 先从对象obj找没有--》去对象的类Foo里面找没有--》去Bar里面找有,会打印'Bar.f2' # 紧接着找self.f1()调的是obj.f1(),按顺序查找打印结果'foo.f1' # 示例2 class Bar: def __f1(self): # 在定义阶段扫描语法变形成_Bar__f1 print('Bar.f1') def f2(self): print('Bar.f2') self.__f1() # 在类定义阶段扫描语法变形成 self._Bar_f1 class Foo(Bar): def __f1(self): # _Foo__f1 print("Foo.f1") obj = Foo() obj.f2() # 按顺序查找到'Bar.f2'并打印, 紧接着查找self.__f1(),打印结果Bar.f1
继承应用
类与类之间的继承指的是什么’是’什么的关系(比如人类,猪类,猴类都是动物类)。子类可以继承/遗传父类所有的属性,因而继承可以用来解决类与类之间的代码重用性问题。比如我们按照定义Student类的方式再定义一个Teacher类
class Student: # 定义学生类
school = "虹桥校区" # 冗余共同属性
def __init__(self,name,age,gender): # 学生类与老师类有冗余部分
self.name = name
self.age = age
self.gender = gender
def choose(self):
print("%s 选课成功" %self.name)
stu1 = Student("jack",18,"male")
stu2 = Student("tom",19,"male")
stu3 = Student('lili',29,"female")
class Teacher: # 定义老师类
school = "虹桥校区"
def __init__(self,name,age,gender,level): # 老师类与学生类功能多一个level
self.name = name
self.age = age
self.gender = gender
self.level = level
def score(self):
print("%s 正在为学生打分" %self.name)
tea1 = Teacher('egon',18,"male",10)
tea2 = Teacher('lxx',38,"male",3)
从上面看出:类Teacher与Student之间存在重复的代码,老师与学生都是人类,所以我们可以得出如下继承关系,实现代码重用
在子类派生的新方法中重用父类的功能:
1、指名道姓的访问父类的函数,与继承无关
class Peopel:
school = '上海' # 将冗余数据放到父类当中
def __init__(self, name, age, gender, ):# 将学生类和老师类的共同属性放到父类中间解决冗余问题
self.name = name
self.age = age
self.gender = gender
class student(Peopel):
# 定义一个__init__函数是形参
# 空对象,'egon',18,"male",10
def __init__(self, name, age, gender, course=None):
# 调用父类的__init__是函数(实参)不是方法,为学生类的__init__进行传参
Peopel.__init__(self, name, age, gender) # 在子类的派生当中重用父类功能
if course is None:
course = []
self.course = course
def choose_course(self, course):
self.course.append(course)
print('学生 %s 选课 %s 成功' % (self.name, course))
class teacher(Peopel):
def __init__(self, name, age, gender, level):# 老师类多一个level就需要保留
# 调用父类的__init__是函数(实参)不是方法,为老师类的__init__进行传参
Peopel.__init__(self, name, age, gender) # 在子类的派生当中重用父类功能
self.level = level
def score(self, stu_obj, num):
stu_obj.num = num
print('老师 %s 为学生 %s 打分 %s' % (self.name, stu_obj.name, num))
stu1 = student('engon', 18, 'male')
tea1 = teacher('刘飞', 80, 'female', 10)
print(stu1.__dict__)
# {'name': 'engon', 'age': 18, 'gender': 'male', 'course': []}
print(tea1.__dict__)
# {'name': '刘飞', 'age': 80, 'gender': 'female', 'level': 10}
tea1.score(stu1,20)
# 老师 刘飞 为学生 engon 打分 20
2、super() 严格依赖继承
super()返回一个特殊的对象,该对象会参考发起属性查找的那一个类的mro列表,去当前类的父类中找属性,严格依赖继承
class People:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def __init__(self, name, age, gender, courses=None):
# People.__init__(self,name,age,gender)
super().__init__(name, age, gender)
if courses is None:
courses = []
self.courses = courses
def choose_courses(self, course):
self.courses.append(course)
class Teacher(People):
def __init__(self, name, age, gender, level):
# People.__init__(self,name,age,gender)
super().__init__(name, age, gender)
self.level = level
def stu_score(self, stu, num):
if stu.courses:
stu.num = num
print('老师 %s 给学生 %s 打分:%s' % (self.name, stu.name, num))
else:
print('学生 %s 没有选课,建议开除'%stu.name)
s1 = Student('刘鹏飞',18,'male')
s1.choose_courses('语文')
t1 = Teacher('刘浩杰',25,'male',10)
t1.stu_score(s1,50)
# 老师 刘浩杰 给学生 刘鹏飞 打分:50
继承的实现原理
继承顺序
Python中子类可以同时继承多个父类,如A(B,C,D)
如果继承关系为非菱形结构,则会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性
如果继承关系为菱形结构,那么属性的查找方式有两种,分别是:深度优先和广度优先

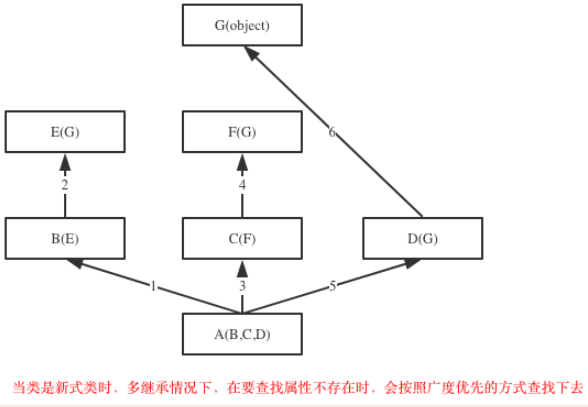
# 继承顺序
class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B):
def test(self):
print('from D')
class E(C):
def test(self):
print('from E')
class F(D,E):
# def test(self):
# print('from F')
pass
f1=F()
f1.test()
print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性
# 新式类继承顺序:F->D->B->E->C->A
# 经典类继承顺序:F->D->B->A->E->C
# python3中统一都是新式类
# pyhon2中才分新式类与经典类
菱形问题
大多数面向对象语言都不支持多继承,而在Python中,一个子类是可以同时继承多个父类的,这固然可以带来一个子类可以对多个不同父类加以重用的好处,但也有可能引发著名的 Diamond problem菱形问题(或称钻石问题,有时候也被称为“死亡钻石”),菱形其实就是对下面这种继承结构的形象比喻
菱形继承/死亡钻石
一个类继承多分枝最后汇总到一个非object类上
class G: # 在python2中,未继承object的类及其子类,都是经典类
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
# def test(self):
# print('from B')
pass
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A() # A->B->E->C->F->D->G->object
# print(A.mro())
obj.test()
-
继承原理
-
python到底是如何实现继承的呢? 对于你定义的每一个类,Python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表,如下
A.mro() # 等同于A.__mro__
[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>,
<class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>,
<class '__main__.G'>, <class 'object'>]
-
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。 而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
-
-
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
-
1、新式类:
广度优先
2、经典类
深度优先
Mixins机制
继承表达的是一个is-a的关系(什么是什么的关系)
单继承可以很好的表达人类的逻辑(一个子类继承一个父类符合逻辑且清晰)
多继承就有点乱,在人类的世界观里,一个物品不可能是多种不同的东西,因此多重继承
在人类的世界观里是说不通的,它仅仅只是代码层面的逻辑(还可能导致菱形问题)
民航飞机、直升飞机、轿车都是一个(is-a)交通工具,前两者都有一个功能是飞行fly,但是轿车没有,所以如下所示
# 我们把飞行功能放到交通工具这个父类中是不合理的
class Vehicle: # 交通工具
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(Vehicle): # 民航飞机
pass
class Helicopter(Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车并不会飞,但按照上述继承关系,汽车也能飞了
pass
Python语言没有接口功能,但Python提供了Mixins机制,简单来说Mixins机制指的是子类混合(mixin)不同类的功能,而这些类采用统一的命名规范(例如Mixin后缀),以此标识这些类只是用来混合功能的,并不是用来标识子类的从属"is-a"关系的,所以Mixins机制本质仍是多继承,但同样遵守”is-a”关系,如下
继承表达的关系是:is-a
组合表达的关系是:has-a
一个对象拥有一个属性,该属性值指向另一个对象
class Vehicle: # 交通工具
pass
class FlyableMixin: # 定义一个飞行功能
def fly(self):
print('flying')
class CivilAircraft(FlyableMixin,Vehicle): # 民航飞机 继承了Flyablemixin就使用它的功能
pass
class Helicopter(FlyableMixin,Vehicle): # 直升飞机
pass
class Car(Vehicle): # 小汽车 不继承就不使用它的功能,也不影响
pass
# ps: 采用这种编码规范(如命名规范)来解决具体的问题是python惯用的套路,大家都照这种规范来
# 这种规范叫什么呢?
# 建议不要用多继承,如果要用到这个继承:把用来表达归属关系的那个类(当然也是最复杂的
# 那个类)往多继承的最右边去放(Vehicle)。把用来添加功能的类往左边放并改名Mixin为后缀
# 的名字(FlyableMixin)这种类的特点是这种类里面就只放功能,并且功能的特点是能独立运行
总结:可以看到,上面的CivilAircraft、Helicopter类实现了多继承,不过它继承的第一个类我们起名
FlyableMixin,而不是Flyable,这个并不影响功能,但是会告诉后来读代码的人,这个类是一个Mixin类
单词表示混入(mix-in),这个名字给人一种提示性的效果,只要以Mixin这种命名方式的类就知道这个类只
是为我这个类来添加功能的,只要继承这个类就说明混合了这个功能
组合
组合:一个对象的属性值是指向另外一个类的对象,称为类的组合
组合与继承都是用来解决代码的重用问题的,不同的是:
继承是一种什么“是”什么的关系
组合是则一种“有”什么的关系
比如学校有学生,老师,学生有多门课程,课程有:类别、周期、学费。学生选python课程或linux课程,或多门课程,应该使用组合,如下示例
class FOO:
def __init__(self, x, y):
self.x = x
self.y = y
def f1(self):
print('from foo')
class Bar:
def __init__(self, a, b):
self.a = a
self.b = b
def f1(self):
print('from Bar')
obj1 = FOO(10, 20)
obj2 = Bar(20, 30)
obj1.f1() # from foo
obj2.name = '刘德华'
print(obj2.__dict__) # {'a': 20, 'b': 30, 'name': '刘德华'}
obj2.f1() # from Bar
obj2.obj1 = obj1
print(obj2.__dict__) # {'a': 20, 'b': 30, 'name': '刘德华', 'obj1': <__main__.FOO object at 0x0000016779E66EB0>}
obj2.obj1.f1() # from foo
class People:
school = "虹桥校区"
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def choose(self):
print("%s 选课成功" %self.name)
class Teacher(People):
# 空对象,'egon',18,"male",10
def __init__(self,name,age,gender,level):
People.__init__(self,name,age,gender)
self.level = level
def score(self):
print("%s 正在为学生打分" %self.name)
class Course:
def __init__(self,name,price,period):
self.name = name
self.price = price
self.period =period
def tell(self):
print('课程信息<%s:%s:%s>' %(self.name,self.price,self.period))
# 课程属性
python = Course("python全栈开发",19800,"6mons")
linux = Course("linux",19000,"5mons")
# 学生属性
stu1 = Student("jack",18,"male")
stu2 = Student("tom",19,"male")
stu3 = Student('lili',29,"female")
# 老师属性
tea1 = Teacher('egon',18,"male",10)
tea2 = Teacher('lxx',38,"male",3)
stu1.course = python # 假如规定只有pyhton一门课程就直接等于python,这就叫组合
stu1.course.tell() # 直接查看课程信息
stu1.courses = [] # 给学生1添加多门课程
stu1.courses.append(python) # 给学生1添加python课程
stu1.courses.append(linux) # 给学生1添加linux课程
# 此时对象stu1集对象独有的属性、Student类中的内容、Course类中的内容于一身(都可以访问到),
# 是一个高度整合的产物
print(stu1.courses) # 查看学生1所学的多门课程的每一门课程的信息
for course_obj in stu1.courses:
course_obj.tell()
多态
-
多态与多态性
多态:同一种事物有多种形态
动物有多种形态:如狗、猫、猪
class Animal: # 同一类事物:动物
def talk(self):
pass
class Dog(Animal): # 动物的形态之一:狗
def talk(self):
print("汪汪汪")
class Cat(Animal): # 动物的形态之二:猫
def talk(self):
print('喵喵!')
class Pig(Animal): # 动物的形态之一:猪
def talk(self):
print("哼哼哼!")
# 实例化得到三个对象
obj1 = Dog()
obj2 = Cat()
obj3 = Pig()
# 父类的功能是用来统一子类的,定标准的,只要看父类功能就知道子类也有
多态性指的是可以在不用考虑对象具体类型的情况下而直接使用对象,这就需要在设计时,把对象的使用方法统一成一种:例如obj1、obj2、obj3都是动物,但凡是动物肯定有talk方法,于是我们可以不用考虑它们三者的具体是什么类型的动物,而直接使用
obj1.talk()
# 汪汪汪
obj2.talk()
# 喵喵!
obj3.talk()
# 哼哼哼!
在多态性背景下用的继承,父类的功能其实不是真的拿来给子类用的,而是用来给子类定标准的,用来统一子类的,只需要把父类的功能规定好了,子类就肯定有,这样的好处是只要看父类就知道子类有什么功能
更进一步,我们可以定义一个统一的接口来使用
def talk(animal): # 定义一个函数talk 传进来参数就叫动物
animal.talk() # 只要是动物就肯定有talk方法
# 三个对象统一用一个函数talk去调,用起来统一了
talk(obj1)
talk(obj2)
talk(obj3)
综上我们得知,多态性的本质在于不同的类中定义有相同的方法名,这样我们就可以不考虑类而统一用一种方式去使用对象,可以通过在父类引入抽象类的概念来硬性限制子类必须有某些方法名
import abc
# 指定metaclass属性将类设置为抽象类,抽象类本身只是用来约束子类的,不能被实例化
class Animal(metaclass=abc.ABCMeta):
@abc.abstractmethod # 该装饰器限制子类必须定义有一个名为talk的方法
def talk(self): # 抽象方法中无需实现具体的功能
pass
class Dog(Animal): # 但凡继承Animal的子类都必须遵循Animal规定的标准
def talk(self):
print("汪汪汪")
class Cat(Animal):
def talk(self):
print('喵喵!')
class Pig(Animal):
def tell(self): # 若子类中没有一个名为talk的方法则会抛出异常TypeError,无法实例化
print("哼哼哼!")
obj1 = Dog()
obj2 = Cat()
obj3 = Pig()
obj1.talk()
obj2.talk()
obj3.talk()
但其实我们完全可以不依赖于继承,只需要制造出外观和行为相同对象,同样可以实现不考虑对象类型而使用对象,这正是Python崇尚的“鸭子类型”(duck typing):“如果看起来像、叫声像而且走起路来像鸭子,那么它就是鸭子”。比起继承的方式,鸭子类型在某种程度上实现了程序的松耦合度,如下
# 三者看起来都像,三者都有talk功能,然而它们并没有直接的关系,且互相独立
class Dog:
def talk(self):
print("汪汪汪")
class Cat:
def talk(self):
print('喵喵!')
class Pig:
def talk(self):
print("哼哼哼!")
-
内置方法
什么是内置方法?
定义在类内部,__开头并且__结尾的属性会在满足某种条件下自动触发
为何要用内置方法?
为了定制化我们的类or对象
-
isinstance(obj,cls)和issubclass(sub,super)
isinstance(obj,cls)检查是否obj是否是类 cls 的对象
class Foo(object):
pass
obj = Foo()
print(isinstance(obj,Foo)) # 判断obj是不是Foo的一个实例或者说对象
# True
print(isinstance([1,2,3],list)) # 判断[1,2,3]是不是list的实例
# True
issubclass(sub, super)检查sub类是否是 super 类的派生类
class Foo(object):
pass
class Bar(Foo):
pass
print(issubclass(Foo,object)) # 判断Foo是不是object的子类
print(issubclass(Bar, Foo)) # 判断Bar是不是Foo的子类
--init--
类实例化的时候自动运行
--str--
打印对象自动触发
--del--
__del__会在对象被删除时自动触发。由于Python自带的垃圾回收机制会自动清理Python程序的资源,所以当一个对象只占用应用程序级资源时,完全没必要为对象定制__del__方法,但在产生一个对象的同时涉及到申请系统资源(比如系统打开的文件)的情况下,关于系统资源的回收,Python的垃圾回收机制便派不上用场了,需要我们为对象定制该方法,用来在对象被删除时自动触发回收系统资源的操作
--str-- :输出对象时运行,输出结果必须时字符串
class Peopel:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return '这个对象是关于 %s 的'%self.name # 返回值必须是字符串
s = Peopel('刘鹏飞',20)
print(s) # 这个对象是关于 刘鹏飞 的
--del--:删除对象时运行,可以用来回收系统资源,就算不添加手动运行del,最后程序结束也会自动运行del
class Peopel:
def __init__(self, name, age):
self.name = name
self.age = age
self.f = open('a.txt',mode='wb')
def __str__(self):
return '这个对象是关于 %s 的' % self.name
# 返回值必须是字符串
def __del__(self):
self.f.close()
print('我del函数运行啦')
s = Peopel('刘鹏飞', 20)
print(s) # 这个对象是关于 刘鹏飞 的
del s # 我del函数运行啦
print('我作为结束语句') # 我del函数运行啦
# 一般--del--用在 关闭 一些不会被系统自动回收的资源。比如打开的文件,没有关闭,就可以在del写一个关闭文件的代码,做资源回收
反射
python面向对象中的反射:通过字符串的形式操作对象相关的属性。python中的一切事物都是对象(都可以使用反射)
四个内置方法:
hasattr 检测是否含有某属性
getattr 获取属性
setattr 设置属性
delattr 删除属性
四个方法适用于类和对象(一切皆对象,类本身也是对象)
hasattr(对象,'字符串') # 查询字符串是否在对象中,返回True或者False
getattr(对象,'字符串','拿不到字符串返回值') # 拿到对象中字符串的内容,拿不到返回第三个参数的值
setattr(s,'1字符串','2字符串') # 等同于 s.1字符串 = 2字符串 可以修改对象中的值,或者给对象添加值
delattr(s,'字符串') # 删除对象中的某个属性值
class Peopel:
def __init__(self, name, age):
self.name = name
self.age = age
self.f = open('a.txt', mode='wb')
def __str__(self):
return '这个对象是关于 %s 的' % self.name
# 返回值必须是字符串
def __del__(self):
self.f.close()
# print('我del函数运行啦')
s = Peopel('刘鹏飞', 20)
print(hasattr(s,'name'))
# True
print(hasattr(s,'啊'))
# False
print(getattr(s,'name'))
# 刘鹏飞
setattr(s,'name','刘鹏飞啊') # 给对象的name改成刘鹏飞啊
print(s.__dict__)
# {'name': '刘鹏飞啊', 'age': 20, 'f': <_io.BufferedWriter name='a.txt'>}
delattr(s,'age') # 删除了对象的age
print(s.__dict__)
# {'name': '刘鹏飞啊', 'f': <_io.BufferedWriter name='a.txt'>}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号