
2025.6
复健。做不了什么难题。
CF2115C,P12865,ECF2024C。
CF2048G Kevin and Matrices
将好的位置定义为该位置为所在行的最大值且为所在列的最小值。则只需统计有好的位置的矩阵有多少。自己做的时候就观察到这了,然后就开始想奇奇怪怪的计数了。
实际上不必着急,观察到好的位置具有非常好的传递性,所有好的位置可以描述用行的集合 \(S\) 和列的集合 \(T\) 描述,此时就可以容斥了。
大力列式子后二项式定理即可。
CF2115D Gellyfish and Forget-Me-Not
好难啊。
二选一异或的经典套路是令 \(x\) 异或上全部的 \(a_i\) 后令 \(c_i=a_i\oplus b_i\),此时就变成 \(c_i\) 选或者不选。最优化看上去就要按位做,最高位是什么容易判断(由最后一个操作最高位的人确定)。但是最高位接下来的位直接用此做法会受到更高位的影响,考虑所有最高位下标的集合 \(S\) 以及 \(t=\max(S)\)。充分利用异或的性质,类似线性基地,将所有 \(i\in S\) 做 \(c_i\leftarrow c_i\oplus c_t\),代表选择 \(c_i\) 会使得 \(c_t\) 是否选择变成相反的状态,同时 \(x\leftarrow x\oplus c_t\)。可以发现这样做后问题仍然为原问题。
这咋想到的啊???
CF2115C Gellyfish and Eternal Violet
看上去好典啊。首先全部变成 \(1\) 太丑了,改成全部变成 \(0\)。
单点操作显然只会对最大值操作,同时当最大值和最小值不相等时所有操作都一定会进行(除非操作以后会产生负数)。考虑第一次最大值和最小值相等的时刻,此后所有时刻必然满足最大值和最小值的差不超过 \(1\),据此设计 dp,\(f_{i,j,k}\) 代表有 \(k\) 个最小值 \(i\),\(n-k\) 个最大值 \(i+1\),还剩 \(j\) 轮获胜的概率。转移考虑下一次作何操作。
这样对于每组数据,枚举第一个使得最大值和最小值相等的时刻即可计算答案。如此的复杂度为 \(O(n^2mh)\),很不厉害。注意到预处理后每组数据的复杂度为 \(O(m)\),很不平衡。
这个做法怎么这么没前途,先让我朝三暮四一下。
P8425 [JOI Open 2022] 长颈鹿 / Giraffes
赛时一上来方向就错了,对于合法序列的判定一直着眼于找出最大值所在的位置后研究两边的性质,虽有一定前途但过于复杂,这种看上去赛时就不会做很长时间的题遇到今天这种问题是很倒闭的。还是直觉少了。
\(1\) 和 \(n\) 必然有一个需要填在序列的开头或结尾,重复该过程可以得到判定合法序列的必要条件:
每次删去当前序列开头或结尾中的特定一个,剩下的一定是值域上的一段区间。
这也是充分的,考虑若存在反例则无法使序列删空(无法接触到不合法区间的最值)。据此可以得到一个 \(O(n^3)\) 的 dp。不妨更深一步地理解这个判定,将 \((i,a_i)\) 放到平面上,此时题目中所述合法意味着对于任意 \((l,r)\),包含该段横坐标所有点的最小矩形必有一个顶点在 \((l,a_l)\) 或者 \((r,a_r)\)。上文所述判定意味着确定了 \(n\) 个正方形,边长依次为 \(n,n-1,\dots,1\)(每个 \((i,a_i)\) 都是至少一个正方形的顶点),我们的目标是保留尽可能多的 \((i,p_i)\) 在最后的排列中。被保留的 \((i,p_i)\) 一定会有一个以其为顶点的正方形留存于最后的排列图像中。每个 \((i,p_i)\) 都对应着 \(O(n)\) 个以其为顶点的正方形,将所有 \(O(n^2)\) 个正方形找出来,则问题等价于找出尽可能多的正方形使得之间严格包含。根据正方形构造原排列是容易的。
可以设计出一个 \(O(n^2\times\rm{polylog}(n))\) 的 dp,状态为某个正方形最多包含多少个正方形。转移限制为二维偏序形式(并非二维偏序,我在说梦话)。注意到排列随机,直觉上不会包含太多正方形,感受一下这个二维上升子序列的问题数量级肯定和原序列上升子序列数量级类似,随机排列这是 \(O(\sqrt{n})\) 的。定义域远大于值域,同时 dp 值有单调性,不难想到交换定义域和值域,状态为以 \((i,p_i)\) 为顶点的正方形若要包含若干个正方形至少需要多少的边长,状态数变成了 \(O(n\sqrt{n})\) 级别。转移仍然为二维偏序形式。时间复杂度 \(O(n\sqrt{n}\log n)\)。
pp_orange 提出了 \(O(n\sqrt{n})\) 做法,貌似是对平面分块,每次转移只需考虑 \(O(1)\) 个块产生的影响。晦涩的。
ARC200E popcount <= 2
赛时没有发现第一步转化,于是后面的思考都建立在一个非常复杂的模型上,中考后脑子本来就不清醒,最后理所当然地没做出来。
就如排列题要置换一样,这种题直接做有点太复杂了。观察到序列 \(\{A_i\}\) 合法则 \(\{A_i\oplus x\}\) 也合法,于是考虑序列 \(\{A_i\oplus A_1\}\),这个序列有很好的性质。注意到虽然并非双射但是每个新合法序列显然对应 \(2^M\) 个原合法序列,因此统计新的合法序列数量即可。
考虑新合法序列有什么性质,显然 \(\rm{popcount}(A_i)\leq 2\) 同时 \(A_1=0\)。同时直觉上 \(\rm{popcount} (A_i)=2\) 的不同 \(A_i\) 不会很多,对 \(|\{A_i|\rm{popcount} (A_i)=2\}|\) 的大小进行讨论。
当 \(|\{A_i|\rm{popcount} (A_i)=2\}|=0\) 时,可以任意填,方案数为 \((M+1)^{n-1}\)。
当 \(|\{A_i|\rm{popcount} (A_i)=2\}|=1\) 时也很简单,方案数为 \(\binom{M}{2}(4^{n-1}-3^{n-1})\)。
当 \(|\{A_i|\rm{popcount} (A_i)=2\}|\geq 2\) 时,讨论所有这样 \(A_i\) 的按位与。若为 \(0\) 则说明可以用三个数字 \(2^{k1}\),\(2^{k2}\),\(2^{k3}\) 刻画,方案数为 \(\binom{M}{3}(4^{N-1}-3\times3^{N-1}+3\times3^{N-1}-1)\),容斥中第三项的系数为 \(3\) 是因为 \(0\) 可以不出现,只在对三个数容斥。若不为 \(0\) 则考虑共有的位 \(2^k\),可以发现所有 \(\rm{popcount}(A_i)=1\) 的 \(A_i\) 都必须满足 \(A_i=2^k\),不难得到方案数 \(M((M+2)^{N-1}-(M-1)\times(3^{N-1}-2^{N-1})-2^{N-1})))\),注意对于集合大小的限制。
P12865 [JOI Open 2025] 冒泡排序机 / Bubble Sort Machine
先写人类做法。
冒泡排序从数的角度来考虑,每次就是前缀最大值移到下一个前缀最大值后整体往前平移一个。自然想到将前缀最大值和非前缀最大值分开维护。
摆了。
树同构
无根树同构代表两棵树可以经过恰当的旋转变成无标号后相同。有根树同构意味着根被固定,任意排列子树使得两棵树相同。树哈希可以简单判断树同构,需要一个厉害的多重集哈希函数。
这里要写的是一种叫做 AHU 的东西,起因是 cancan123456 在去年三轮省集切了 P3993 直接拿了 rk2,刚才重新看了这道题发现自己完全不会做,遂感 cancan123456 之强大。首先考虑判断有根树同构。定义以 \(A\) 为根的树的括号序是 \(A((),(),())\),里面的括号是每棵子树的括号序。显然如果在拼接的时候令字典序较小的括号序先被拼接,则只需比较两棵树的括号序即可。时间复杂度 \(O(n^2)\)。
瓶颈在于括号序太长了,考虑用一个数来替代括号序。对于一个深度为 \(i\) 的点,定义其排名为两棵树深度为 \(i\) 的点中括号序小于它的点的数量 \(+1\),两个子树的排名相同意味着子树同构。同时这个排名可以推出 \(i-1\) 层的排名情况。直接基数排序即可做到线性。
上面写的都是有根树同构。考虑如何判断两棵无根树同构,对于两棵无根树 \(T_1\) 和 \(T_2\),分别找出重心。若重心数量不相同则显然不同构,否则以重心为根看一下是否有根树同构即可。
记得去做 P3993!!!
P3993 [BJOI2017] 同构
注意到原图没有非平凡自同构等价于补图没有非平凡自同构,因此转成补图后计算边数最少为多少。首先需要知道当 \(n>6\) 时存在无非平凡自同构的树,由此补图是一个森林:
-
若补图并非森林,设一个非树的联通块点数为 \(i\),如果图中还有没填进去的大小为 \(i\) 的无非平凡自同构树则可以将该联通块替换为树。
-
\(i\) 的大小 \(>6\),因为 \(<6\) 时不存在无非平凡自同构的图,\(=6\) 时可以根据下文不劣地变成树。
-
否则,考虑任选一棵树,将这 \(i\) 个点作为一条链接到直径上,不难发现仍然没有非平凡自同构。
只需求出 \(f_i\) 代表 \(i\) 个点的无非平凡自同构的无根树数量后背包即可。直接算 \(f_i\) 会算重,类似 AHU 地,以重心为根后可以转化为有根树的问题,设 \(g_i\) 为无非平凡自同构的有根树数量,讨论重心的数量:
-
只有一个重心,则加上每个子树大小不超过一半的条件后做背包贡献到 \(f_i\) 即可。
-
两个重心。两个重心之间的边将树分成两个大小相同的部分,两个部分不能有自同构且互相不同构,直接算即可。
现在考虑求 \(g_i\)。令 \(h_{n,m}\) 代表 \(n\) 个点分成若干个大小不超过 \(m\) 的子树且两两不同构的方案数,\(h_{n,m}\) 经典的转移是考虑大小恰为 \(m\) 的子树数量。\(f_i\) 只需算到 \(54\) 项即可。无根树钦定根后变成有根树,\(g_i\) 的计数都是非常经典的套路!
ucup3rd PA F
神秘构造。
回忆二轮省集,告诉我们斐波那契的增长速度非常之快,于是在这题中考虑使用同样的方式构造。根据忘了什么定理,每个数可以表示成若干互不相同的斐波那契数之和。考虑原序列的样子:
暴力构造:
利用斐波那契数列构造:
可以发现次数是对的。
UOJ33 树上 GCD
有根树点分治。
首先考虑菊花套链怎么做。统计 \(k_i\) 为有多少权值是 \(i\) 的倍数,最后套一个 \(O(n\log n)\) 的容斥就可以得到答案。
对于一般情况仍然类似菊花套链的容斥。进行点分治,不过无法直接统计信息。考虑 \(u\to\rm{LCA}(u,v)\to v\) 经过重心 \(c\) 的点对 \((u,v)\),分类讨论。
-
\(\rm{LCA}(u,v)=c\)。枚举除了 \(c\) 的父亲外的每个子树,记录子树到 \(c\) 的距离信息。枚举不大于子树高度的 \(d\) 统计信息。
-
\(\rm{LCA}(u,v)\neq c\)。考虑 \(c\to root\) 上的每个点 \(a_1,a_2,\dots,a_k\)。枚举 \(\rm{LCA}(u,v)\),维护不在 \(c\) 方向上的所有子树信息,然后需要做一个对于 \(c\) 子树内信息的查询编号差 \(d\) 的子序列信息的和,记忆化可以做到 \(O(H\sqrt{H})\)。
QOJ3998 The Profiteer
神了啊。
考虑一个优于直接做的做法,区间左右端点扩张后不合法的区间一定不会变成合法,因此双指针求出所有合法的区间,这里的复杂度是 \(O(n^2k)\) 的,\(\max\) 卷积没法退背包。没有什么前途。
回顾整体二分,一般的整体二分是为了解决:
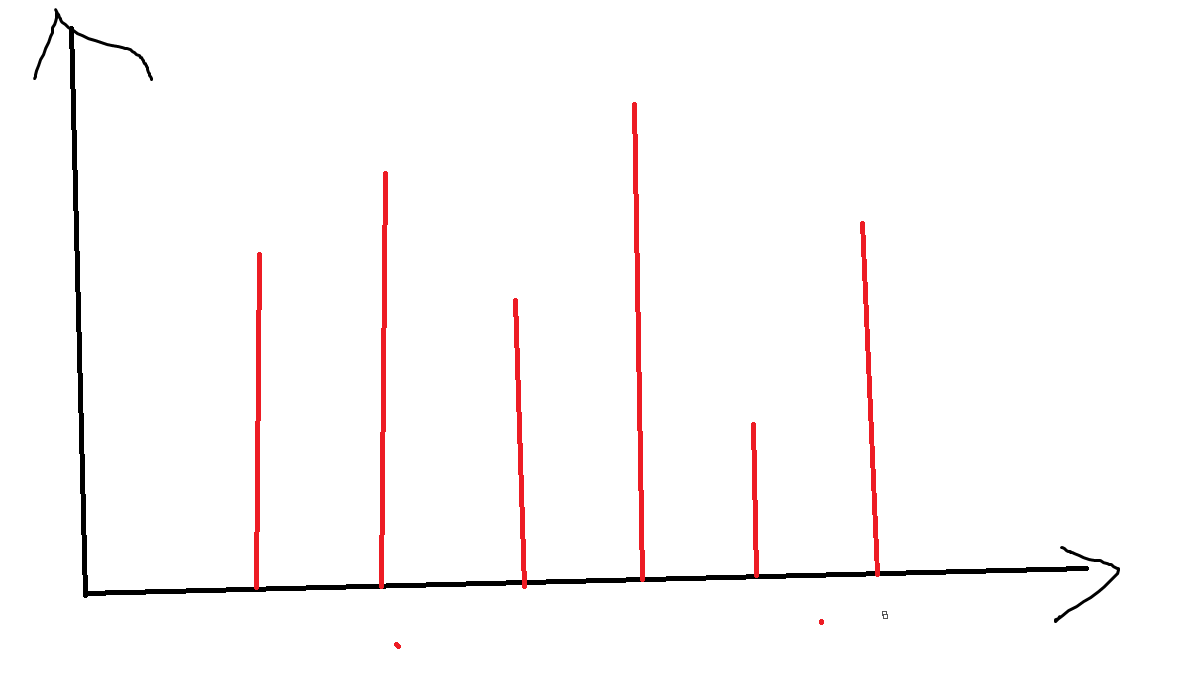
其中横坐标是若干个问题,每个横坐标对应纵坐标的一段前缀合法,需要求出每个横坐标的合法前缀有多长。对于每个横坐标做一遍二分相当于存在方法判断一个点是否是红色,每次二分都在询问一个点。整体二分则是对于纵坐标分治,每个分治区间中记录可能落到当前区间的横坐标有哪些,取出纵坐标区间中点对应的直线后分治,复杂度由跳过没有横坐标的区间保证。判断横坐标落在哪个区间是一个判定性问题,扫描线维护信息即可。
考虑这个题,实际上是这个样子:
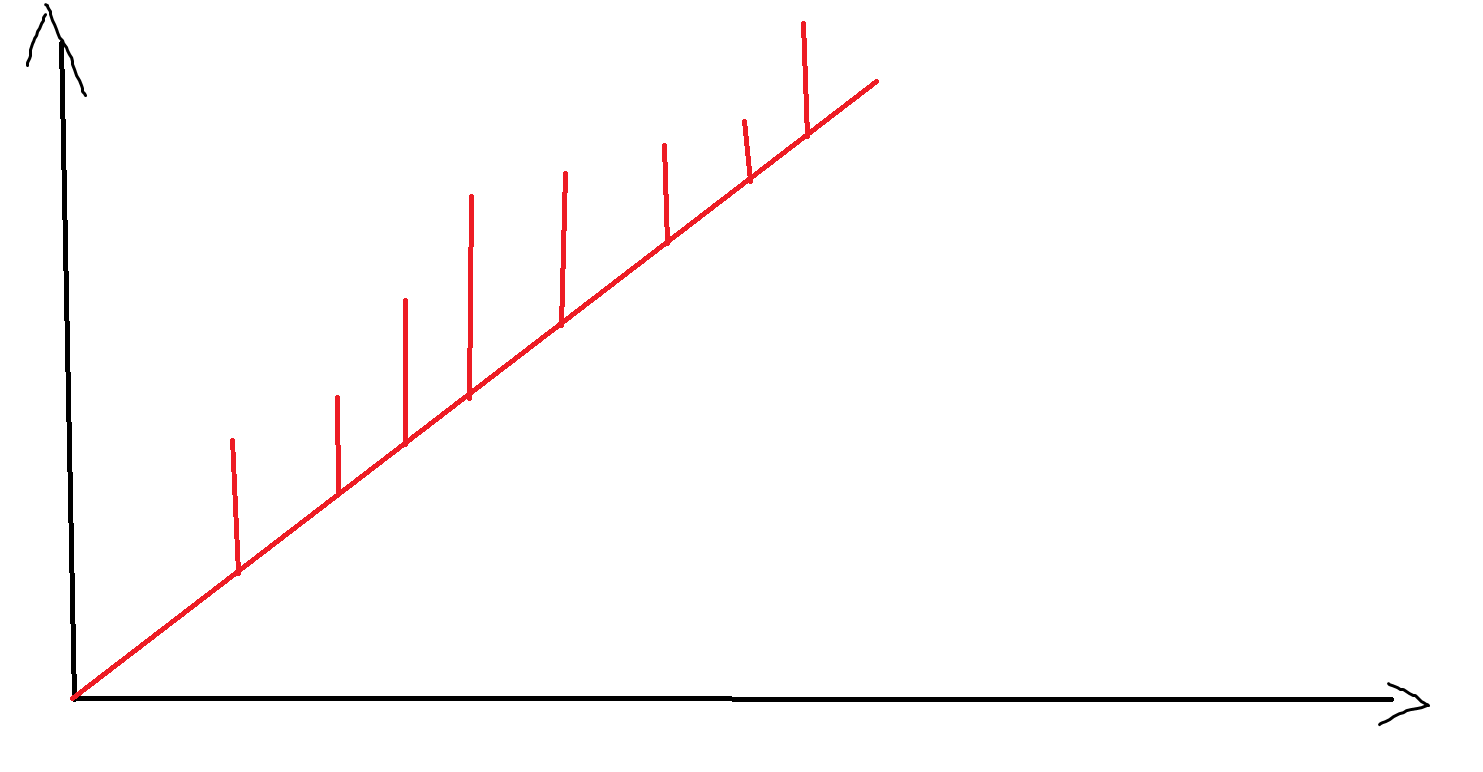
其中 \((i,j)\) 为红色代表 \([i,j]\) 这段区间合法。此时像上面一样划分若干条直线,无法扫描线判断每个点的颜色(信息不可逆)。不过在 \(y=x\) 上方的点关于 \(x\) 有单调性,考虑类似分治:
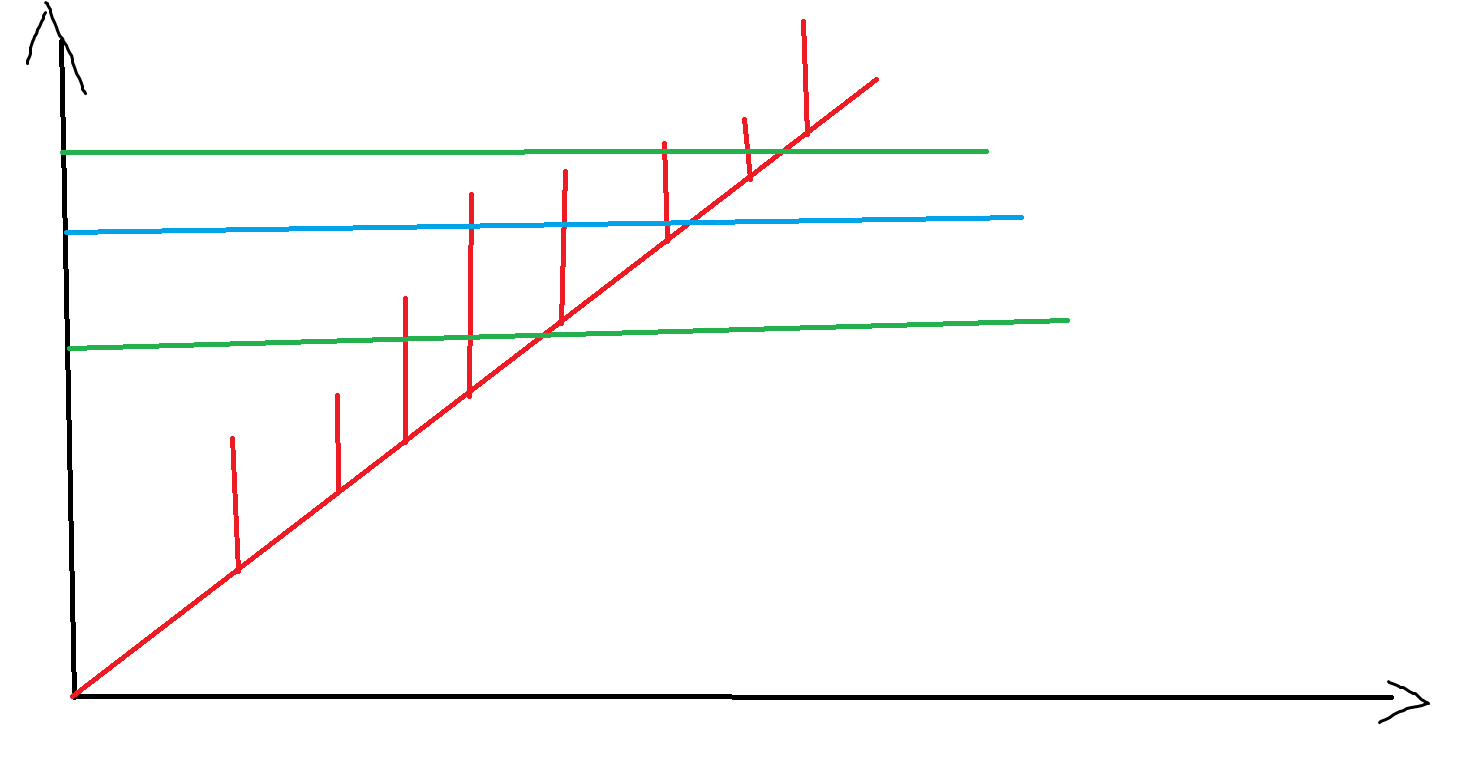
其中绿色是一个纵坐标区间,我们已经知道哪些横坐标落在里面(由于右端点的性质,这一定是一段连续的区间),蓝色是所划分的直线,如果没有单调性的话需要判断 \(n\) 个点的颜色,但是有单调性的话可以聪明一点,二分蓝线下面第一个端点,这样就能维护出新的纵坐标区间。解决的实际是:
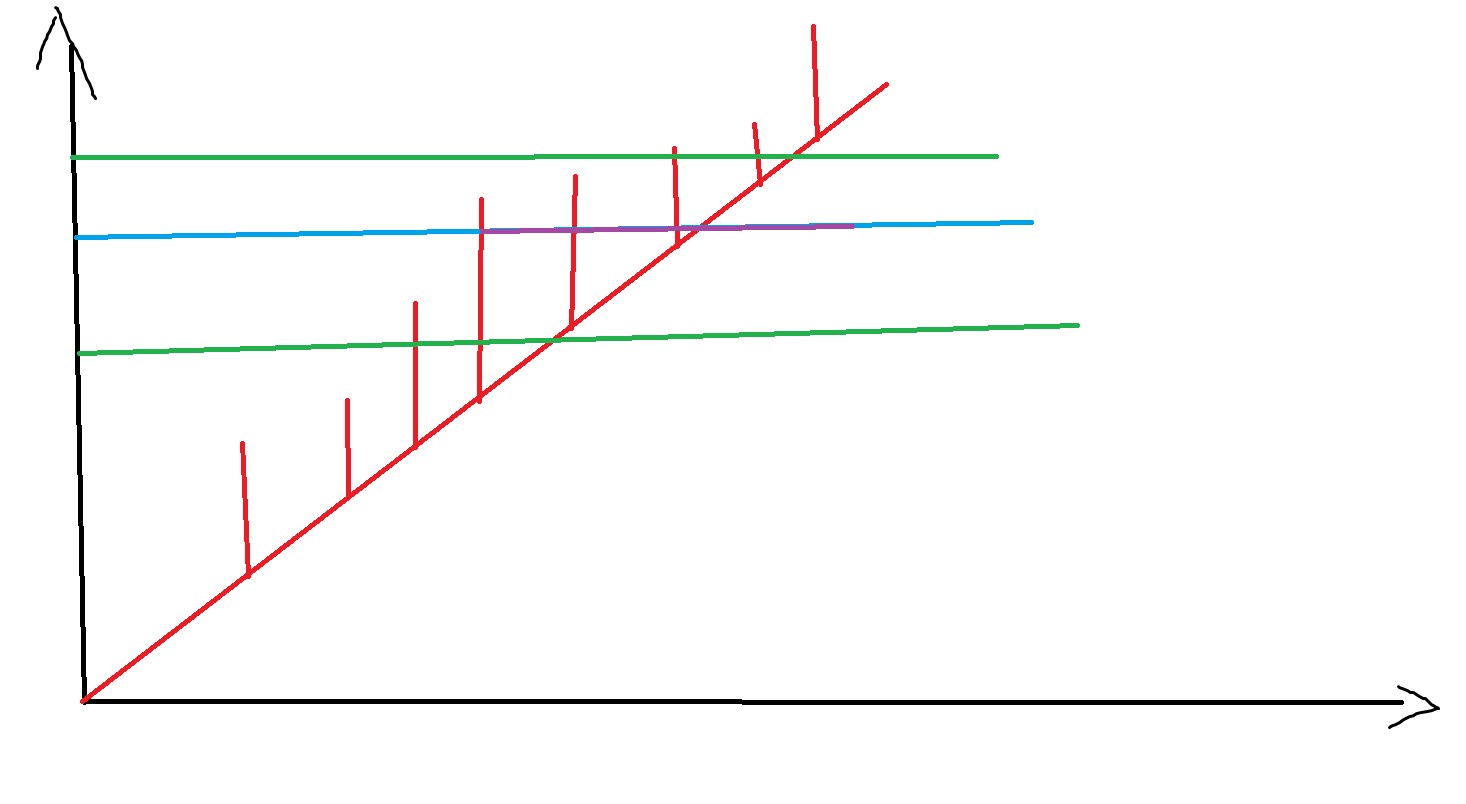
其中紫色是一个需要解决的新的问题,需要求出紫色的左端点,这是一个最普通的二分问题,询问一个点是否是红色即可。
这样复杂度仍然不太对,问题在于每次判断都需要加入很多点到背包里,考虑对求出紫色之后右端点已经确定,左端点会落在一个区间内,同时每次二分后带来的会是一半点的权值确定,将这些点加入背包即可。至于左端点所在区间外的点,经典套路是类似线段树分治一样 dfs 时加入这些点。分析一下一层分治中会有线性次背包加入,总的背包加入次数是 \(O(n\log n)\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号