realsync常用工具
概览
- olfx/xdt/ologx——> 主要针对 redo 文件来进行解析或转储(dbf文件)
- xfview
- xexp/ximp ———>dsg软件自带的导出或导入
- vagentd -re/vagentd -rdba ———> 对rowid这个动作来进行格式的转换
- exp test ———>测试远距离异地容灾复制带宽
- xdisptach ———> 启用loder -r实时装载时,启用多进程装载时使用的
- aiod ——>应用在我们没开归档或者数据库日志切换过快
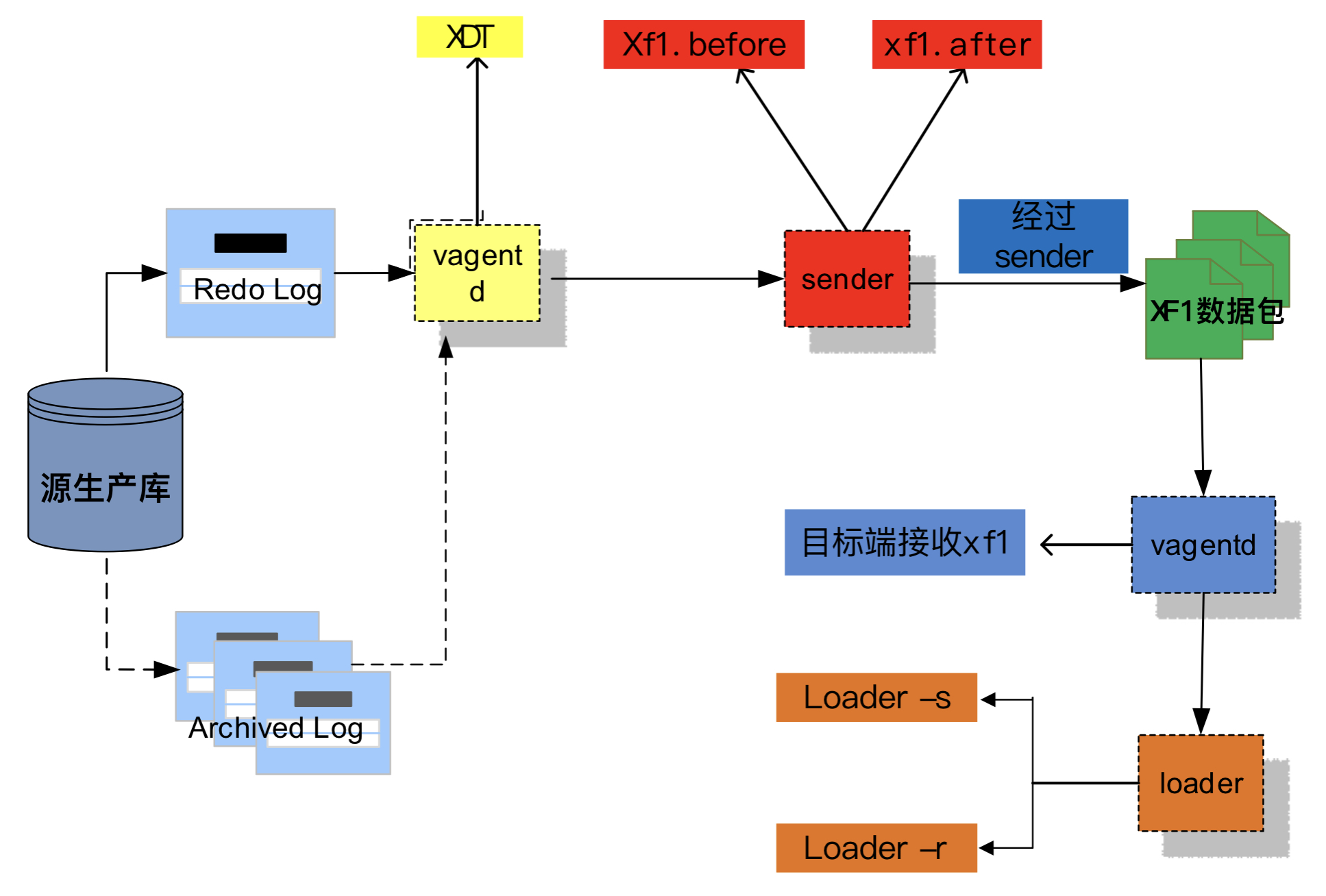
源端中的vagentd解析redo,生成 xdt文件:如果不开启vagentd不加xf1back的话一般是看不见的。
sender:不仅只有发送的功能,还有交易合成和处理行链接的动作
loder:开启xf1back来接收
好好理解数据流向对以后问题追踪有帮助
ps:个人理解在源端实际经过了两层转储,一个是vagentd解析redo生成xdt,之后转储生成xf1文件由sender分发xf1.before和xf1.after。
如何在mapping.ini修改
在使用vm指令之前程序不会读取该文件
-
注释:#
ps:在vi mapping之后,一定要检查,cat 一下防止写错。 -
当不抓取某一张表
real_where:实时增量的这个将你不需要的表删除掉
full_where:什么都不用干,也就是将这底下所有的东西全部注释掉
olfx/xdt/ologx 工具
这三个工具是分析日志的工具(分析redo文件或归档文件)
适用场景:
1)当vagentd 发生core的时候可以先用这三个工具来分析一下是否也产生core,如果产生及时保留日志文件。
2)追踪交易的时候(比如insert丢了,不知道是数据流向的哪个地方出现问题)
实质:
- olfx/olax:模拟vagentd来形成xdt。
- xdt工具:可以查看xdt文件(通过vi是没有办法看见的)
- ologx工具:模拟redo/归档文件直接生成xf1(验证日志中内容,数据流向过程中是否有丢失,注意过滤问题)
1. olfx/olax工具
用法:olfx -all 日志文件名.dba -o 输出名.xdt
olfx -h:帮助查看
ps:olax是最新一代的解析工具,与olfx的参数差不多
2. xdt工具
xdt 文件生成两个途径:
1)olfx/olax分析redo形成xdt
2)vagentd 启用xf1back生成xdt
用法:./xdt 分析文件名.xdt>输出文本名
说明:xid:事务编号;
rowid:所有的rowid都睡源端的
OP:11.2:事务的插入
OP5.4:事务的提交
objd:段号
objn:对象号
ps:xdt可以和oracle 的dump文件进行比较理解。
3. ologx工具
用法:./ologx -h
./ologx 用户名/口令 -nofilter 文件名 -o 输出文件名.xf1————>去拿./xfview -show l 文件名.xf1>输出文件名
这里一般新建一个目录temp,在终端窗口输下方两个,来添加环境。
export VCFS_HOME=pwd/temp
export XLDR_HOME=pwd/temp
原因:这样不会影响正在运行的复制队列。
xfview
-
作用:查看或修改xf1的内容
小结:源端的sender,目标端的loder用xf1back备份的是xf1。源端的vagentd使用xf1back备份的是xdt -
在rmp文件夹下的xdt文件命名规则:
seq1.175.xdt:seq后的数字代表是单节点还是多节点。175:日志的序号
sender:有两个before和after
对于数据库中的操作通过此命令查看:在log文件夹下执行tail -f log.r0
xfview的看
- 简单看:
xfview -show 1 查看文件名>输出文件名
输出内容:TSI一个特殊用途;scn:提交的scn号;之后一行代表一次操作;
例如:002B6C7D.002B6C7D.06BF00B8.0000 B2(IRP)
- 第一列数字:代表这张表在源端object id(oid一般统称为源端)
- 第二列数字:data object ID(段号)
- 第三列数字:data block address
- 第四列数字:slot号
- B2:操作码;这是个insert操作
- 简单来说这一行就是rowid,只是表示不同
-
好好看:
xfview -show 2 查看文件名>输出文件名
显示更全,具体值用16进制表示
rowid:002B 6C7D 06BF 00B8-0000
前8位:object ID ,前面补0
接下来8位数:data block address,前面补0
最后四位数:slot号 -
sql语句看
./xfview -show 3 -dict ../imp_*/s_dict.xf1 文件名.xf1 >输出文件名
rowid还是源端的
xfview的修改
- xf1文件中某个表的所有事务:
xfview -delobj <objected> 文件名 - 删除单独一行:
xfview -delrowid <rowid> 文件名 - 删除某一类操作(insert,update,delete):
xfview -delopc 0xb2 文件名将文件中b2操作删除掉
xexp和ximp
xexp
用途:
- xexp尝试导出数据
- 目标端字典s_dict可以用xexp来生成,只导出结构不导出数据。
- 修复数据
语法:

ps:1)当只想复制指定表的时候,可以把对应real_where这一行复制到一个文件中(假设保存文件名为1),./xexp 用户名/口令 -exp_where_file 1 -rows n -to_file 导出文件名.xf1,这里是根据队列中的表,将对应表的字典导出。
2)./xexp 用户名/口令 -exp_where_file 1 -to_file /dev/null输出且不占存储空间,可以用来判断到处表的速度。
3)导出单行数据一定要加-only_rows这个参数。
ximp
语法:
./ximp 用户名/口令 -usermap "导出用户名 导入用户名" 文件名.xf1
vagentd -re/vagentd -rdba
这两个工具都是翻译oracle rowid的。
vagentd -re
./vagented -re <rowid>=./rowid -re <rowid>
vagentd -rdba
将rowid翻译成oracle的 datablock address和块号
./vagented -rdba <rowid>
去oracle的udump目录上取得dump块的trc文件:alter system dump datafile 0 block min 68386 block max 68388
小结
rowid有两种常用的形式:AAAQ8LAAEAAAPUgAAA 或 0001 0F0B 0100 F520-0000
rowid组成:段号oid+Data block id+slot号
如何去查看rowid的映射关系?
- 把某张表全打印出来:rmp_list:
rmplist pwd <objectid/objn> >输出文本名 - 找到某一行的映射关系:rmpsearch:
rmpsearch pwd objn onjd dba slot(全是源端的东西)
pwd:rowmapping存在于目标端的rmp目录下的imp_*开头的目录
测试带宽(是否存在网络瓶颈)
exp_test:./exp_test -host up -port -m -n -s size
-s:大小,可以用G
-m:并发数
xdispatch
- 业务量大的时候
- 有特殊业务主干表:单独制定loder来处理
情况一:已经有很多积压做拆分
1)拆分之前
- 将需要拆分的队列拷贝到临时目录
$ stop 目标端进程
$cd /dsg10/yh/dt /rmp
$mv real0 tmp.real0
- 写real_q.conf配置文件
$cd /dsg10/yh/dt /config
$ vi real_q.conf
1 DSG:TEST
- 生成cfg.objs文件:在源端执行下面的sql语句生成cfg.objs文件。生成后放到目标端的 /dsg10/yh/dt/rmp目录下
改文件,立规矩,生成文件。下方是文件内容
set pagesize 100000
set echo off
select o1.obj# as objn,
o.obj# as objp,
o.dataobj# as objd,
u.name||'.'||o.name||'.'||o.subname as OBJ_NAME
from sys.user$ u, sys.obj$ o, sys.obj$ o1, dba_tables dt, dba_objects dob
where o.owner# = u.user#
and o1.owner# = u.user#
and o1.name=o.name
and u.name not in ('SYS','SYSTEM')
and o.type# in ( 2, 19, 34, 39, 40 )
and o.dataobj# is not null
and o1.type# = 2
and dt.OWNER = u.NAME and dt.TABLE_NAME = o.NAME and
dt.TEMPORARY='N'
and dob.OWNER= u.NAME and dob.OBJECT_NAME=o.NAME and
dob.OBJECT_TYPE='TABLE'
and (用户条件) order by objn,objp
只需要换用户名 和 o.name 所需的表名即可!(real_where后面那个sql)
2)拆分
$cd /templv/oracle10/zl/dt/rmp
$export XLDR_HOME=/templv/oracle10/zl/dt/rmp
$export VCFS_HOME=/templv/oracle10/zl/dt/vcfsa
$./xdispatch -p /templv/oracle10/zl/dt/rmp/tmp.real0 -n 0 1
其中 -n 参数为需要拆分的起始xf1编号和最后一个xf1编号
3)修改config目录下的 .profile_dt文件中local_loader_r_parallel参数
4)重新启动vagentd和loader进行装载,重启后新产生的 xf1文件也将沿用该多队列方式进行分发和装载
aor与aiod
aor:单独生成redo,用于非归档,日志切换太快
aoid:远距离传输,用于接收远程传输的aor


 浙公网安备 33010602011771号
浙公网安备 33010602011771号