

python爬虫(三)
一、正则表达式
1.正则表达式的概念
- 正则表达式是用来简洁表达一组字符串的表达式
- 正则表达式是一种通用的字符串表达框架
- 正则表达式是一种争对字符串表达“简洁”和“特征”思想的工具
2.正则表达式的应用
- 表达文本类型的特征
- 同时查找和替换一组字符串
- 匹配字符串的全部或部分(最主要应用在字符串匹配中)
3.正则表达式的使用
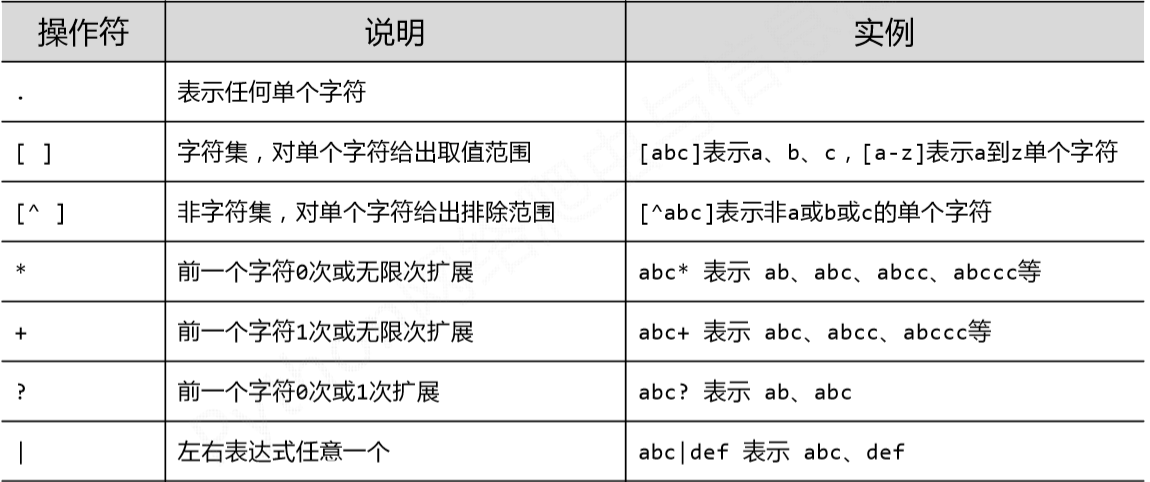
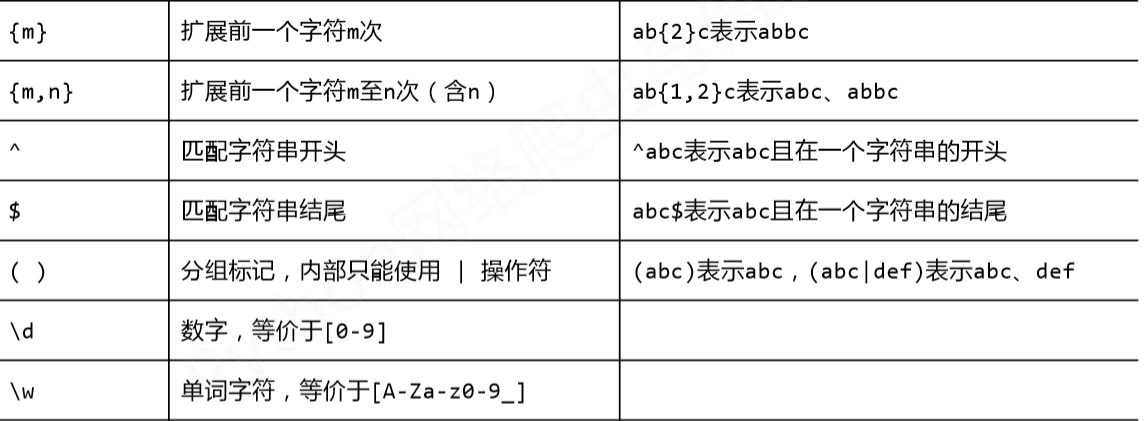
正则表达式的语法由字符和操作符构成
正则表达式的常用操作符:


#P(Y|YT|YTH|YTHO)?N ===》 'PN'、'PYN'、'PYTN'、'PYTHN'、'PYTHON' #PYTHON+ ===》 'PYTHON'、'PYTHONN'、'PYTHONNN'… #PY[TH]ON ===》 'PYTON'、'PYHON' #PY[^TH]?ON ===》 'PYON'、'PYaON'、'PYbON'、'PYcON'… #PY{:3}N ===》 'PN'、'PYN'、'PYYN'、'PYYYN'…
# ^[A-Za-z]+$ 由26个字母组成的字符串 # ^[A-Za-z0-9]+$ 由26个字母和数字组成的字符串 # ^-?\d+$ 整数形式的字符串 # [0-9]*[1-9][0-9]*$ 正整数形式的字符串 # [1-9]\d{5} 中国境内邮政编码,6位 # [\u4e00-\u9fa5] 匹配中文字符 # \d{3}-\d{8}|\d{4}-\d{7} 国内电话号码 #匹配IP地址的正则表达式: #把255分成四段标识 #(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])
二、re库的使用
1.正则表达式的表示类型
- rwa string类型(原生字符串类型),raw string是不包含对转义符再次转义的字符串。例如:r'[1-9]\d{5}'
- string类型。string是包含对转义符再次转义的字符串。例如:'[1-9]\\d{5}'
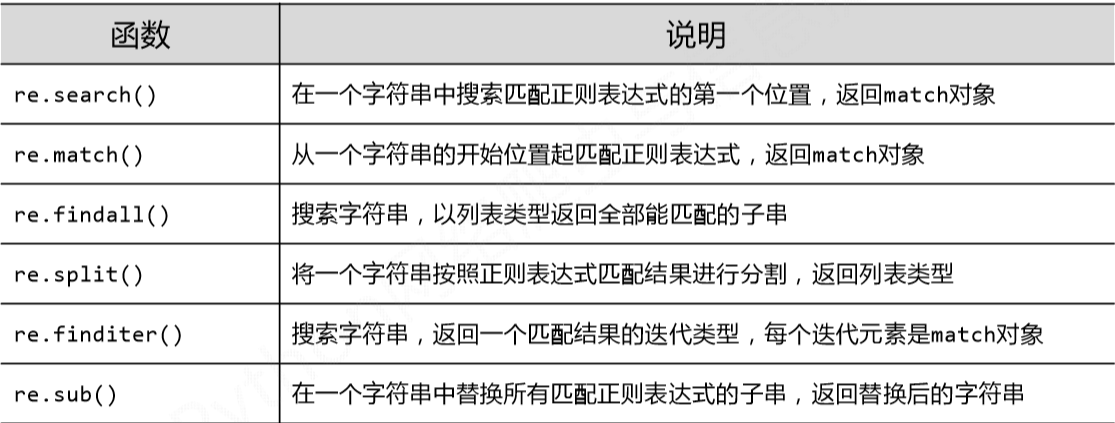
2.re库的主要功能函数
re.match(pattern,string,flags=0),在一个字符串的开始位置起匹配正则表达式,返回match对象。
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正则表达式使用时的控制标记
re.search(pattern,string,flags=0),在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正则表达式使用时的控制标记

re.findall(pattern,string,flags=0),搜索字符串,以列表类型返回全部能匹配的字串
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正则表达式使用时的控制标记
re.split(pattern,string,maxsplit=0,flags=0),将一个字符串按照正则表达式匹配结果进行分割返回列表类型
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正则表达式使用时的控制标记
- maxsplit:最大分割数,剩余部分作为最后一个元素输出
re.finditer(pattern,string,flags=0),搜索字符串,返回一个匹配结果的迭代类型,每个迭代类型是match对象
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正则表达式使用时的控制标记
re.sub(pattern,repl,string,count=0,flags=0),在一个字符串中替换所有匹配正则表达式的字串,返回替换后的字符串
- pattern:正则表达式的字符串或原生字符串表示
- repl:替换匹配字符串的字符串
- string:待匹配字符串
- count:匹配的最大替换次数
- flags:正则表达式使用时的控制标记
总结:
3.re库的另一种等价用法
regex=re.compile(pattern,flags=0),将正则表达式的字符串形式编译成正则表达式对象。
- pattern:正则表达式的字符串或原生字符串表示
- flags:正则表达式使用时的控制标记

4.match对象介绍
match对象的属性:
- .string:待匹配的文本
- .re:匹配时使用的pattern对象
- .pos:正则表达式搜索文本的开始位置
- .endpos:正则表达式搜索文本的结束位置
match对象的方法:
- .group(0):获取匹配后的字符串
- .start():匹配字符串在原始字符串的开始位置
- .end():匹配字符串在原始字符串的结束位置
- .span():返回(.start(),.end())
5.re库的贪婪匹配和最小匹配
re库默认采用贪婪匹配,即输出匹配最长的字串
import re string="PYONOOOOOOON" match=re.search(r'PY.*N',string) print(match.group(0)) #PYONOOOOOOON
最小匹配:
import re string="PYONOOOOOOON" match=re.search(r'PY.*?N',string) print(match.group(0)) #PYON
最小匹配操作符:
- *?: 前一个字符0次或无限次扩展,最小匹配
- +?: 前一个字符1次或无限次扩展,最小匹配
- ??: 前一个字符0次或1次扩展,最小匹配
- {m,n}?: 扩展前一个字符m至n次,最小匹配

 浙公网安备 33010602011771号
浙公网安备 33010602011771号