

python爬虫(一)
一、HTTP协议
1.基本概念
HTTP,Hypertext Transfer Transfer Peotocol,超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
Http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省端口为80
path:请求资源的路径
HTTP URL实例:
http://www.bit.edu.cn
http://220.181.111.188/duty
HTTP URL的理解:
URL是通过HTTP协议存取资源Internet路径,一个URL对应一个数据资源
2.HTTP协议对资源的操作
- GET 请求URL位置的资源
- HEAD 请求URL位置资源的响应消息报告,即获得该资源的头部信息
- POST 请求向URL位置的资源后附加新的数据
- PUT 请求向URL位置存储一个资源,覆盖原URL位置的资源
- PATCH 请求局部更新URL位置的资源,即改变该处资源的部分内容
- DELETE 请求删除URL位置存储的资源
其中GET、HEADE方法主要是用于获取数据,PUT、POST、PATCH、DELETE主要用于提交数据

3.PATCH与PUT的区别
假设URL位置有一组数据UserInfo,包括UserID,UserName等20各字段
需求:用户修改了UserName,其他不变
- 采用PATCH,仅向URL提交UserName的局部跟新请求
- 采用PUT,必须将所有的20个字段一并提交到URl,未提交字段将被删除
PATCH的最主要的好处:节省网络带宽
二、requests库的使用
requests库的7个主要方法:
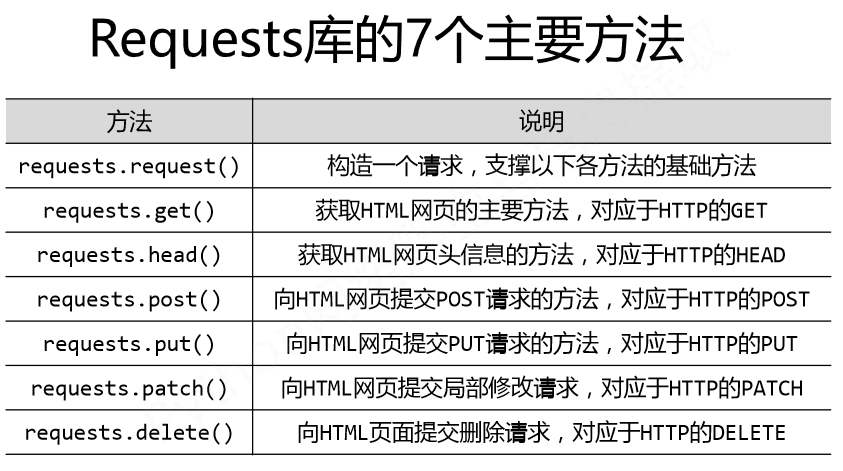
1、GET方法

(一)requests.get(url,params=None,**kwargs)
url:拟获取页面的url链接
params:url中的额外参数,字典或字节流格式,可选
**kwargs:12各控制访问的参数
(二)response对象
response对象的属性
- r.status_code HTTP请求的返回状态,200表示连接成功,404或其他表示失败
- r.text HTTP响应内容的字符串形式
- r.encoding 从HTTP header中猜测的响应内容编码方式
- r.apparent_encoding 从HTTP响应内容分析出的内容编码方式
- r.content HTTP响应内容的二进制形式
(三)response的编码
r.encoding:如果header中不存在charset,则认为编码为ISO--8859-1
r.text根据r.encoding显示网页内容
r.apparent_encoding:根据网页内容分析出的编码方式
可以看作是r.encoding的备选
例子:


# -*- coding:utf-8 -*- #!/user/bin/env.python #Author:Mr Wu import requests url="https://www.baidu.com" r=requests.get(url) print(r.encoding) #ISO-8859-1 print(r.text[1000:2000]) #无法正常显示字符 ''' pan class="bg s_btn_wr"><input type=submit id=su value=ç¾åº¦ä¸ä¸ class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ°é»</a> \ <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>å°å¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§é¢</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn& u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç»å½</a> </noscript> script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">ç»å½</a>'); </script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ´å¤äº§å< ''' r.encoding=r.apparent_encoding #替换编码 print(r.encoding) #utf-8 print(r.text[1000:2000]) #可正常显示 ''' n_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn& u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script> document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent (window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>'); </script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;"> 更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p '''
2.HEADE方法
r=requests.head(ur,**kwargs)
url:拟获取页面的url链接
**kwargs:12个可控制的访问参数
例子:
import requests url="http://httpbin.org/get" r=requests.head(url) #请求头部信息 print(r.headers) ''' {'Access-Control-Allow-Credentials': 'true', 'Access-Control-Allow-Origin': '*', 'Content-Encoding': 'gzip', 'Content-Type': 'application/json', 'Date': 'Sun, 28 Jul 2019 09:01:44 GMT', 'Referrer-Policy': 'no-referrer-when-downgrade', 'Server': 'nginx', 'X-Content-Type-Options': 'nosniff', 'X-Frame-Options': 'DENY', 'X-XSS-Protection': '1; mode=block', 'Connection': 'keep-alive'} '''
3.POST方法
r=requests.post(url,data=None,json=None,**kwargs)
url:拟更新页面的url链接
data:字典、字节序列或文件,request的内容,向url post一个字典会自动编码成一个form表 单进行提交,向url post一个字符串会自动编码成data进行提交。
json:json格式的数据,request的内容
**kwargs:12个控制访问的参数
例子:
# -*- coding:utf-8 -*- #!/user/bin/env.python #Author:Mr Wu import requests url="http://httpbin.org/post" kv={'key1':'value1','key2':'value2'} r=requests.post(url,data=kv) #请求头部信息 print(r.text) ''' {.......... "form": { "key1": "value1", #向url post发送的一个字典自动编码成form表单 "key2": "value2" }, ............ } '''
# -*- coding:utf-8 -*- #!/user/bin/env.python #Author:Mr Wu import requests url="http://httpbin.org/post" r=requests.post(url,data='ABC') #请求头部信息 print(r.text) ''' {.......... "data": "ABC", "files": {}, #向url post一个字符串会自动编码成data "form": {}, ............ } '''
4.PUT方法
r=requests.put(url,data=None,**kwargs)
url:拟更新页面的url链接
data:字典、字节序列或文件,request的内容
**kwargs:12个控制访问的参数
例子:
# -*- coding:utf-8 -*- #!/user/bin/env.python #Author:Mr Wu import requests url="http://httpbin.org/put" kv={"k1":"v1","k2":"v2"} r=requests.put(url,data=kv) print(r.text) ''' {.......... "form": { "k1": "v1", #向url put一个字典会自动编码成一个form表单 "k2": "v2" }, ............ } '''
5.PATCH方法
r=requests.put(url,data=None,**kwargs)
url:拟更新页面的url链接
data:字典、字节序列或文件,request的内容
**kwargs:12个控制访问的参数
6.DELETE方法
r=requests.delete(url,**kwargs)
url:拟更新页面的url链接
**kwargs:12个控制访问的参数
7.request方法
request方法是以上5种方法的基础,上述6中方法都是通过调用request方法实现的
requests.request(method,url,**kwargs)
- method:请求方式,对应get/put/post等7种
- url:拟获取页面的链接
- params:字典或字节序列,作为参数增加到url中
- data:字典、字节序列或文件对象,作为request的内容
- json:JSON格式的数据,作为request的内容
- headers:字典,HTTP定制头 (headers={'User-Agent':"Chrome/10"})
- auth:元组,支持HTTP认证功能
- files:字典,传输文件
- timeout:设定超时时间,以秒为单位
- proxies:字典类型,设定代理服务器,可以增加登陆认证 proxies=pxs={"https":"https://user:pass@10.10.1:1234","http":"http://10.10.10.1:4321"}
- allow_redirectss:True/False,默认为True,重定向开关
- steam:True/False,默认为True,获取内容立即下载开关
- verify:True/False,默认为True,认证SSL证书开关
- cert:本地SSL证书路径
8.requests库的异常
- ConnectionError:网络连接异常,如DNS查询失败,拒绝连接
- HTTPError:HTTP错误异常
- URLRequired:URL缺失异常
- TooManyRedirects:超过最大重定向次数,产生重定向异常
- ConnectTimeout:连接远程服务器超时异常
- Timeout:请求URL超时,产生超时异常
9.response异常
response.raise_for_status() #若状态码不是200,产生异常requests.HTTPError
response.raise_for_status()在方法内部判断response.status_code是否等于200,不需要增加额外的if语句。
10.爬虫通用代码框架
import requests def getHTMLText(url): try: r=requests.get(url,timeout=30,headers={'User-Agent':'Mozilla/5.0',}) #替换headers来源标识 r.raise_for_status() #若status_code!=200 将产抛出HTTPError异常 r.encoding=r.apparent_encoding #替换编码 return r.text except Exception as e: print(e) if __name__ == '__main__': url=input("url: ") text=getHTMLText(url)
三、网络爬虫带来的问题
- 性能骚扰:web服务器默认接收人类的访问,受限于编写水平和目的,网络爬虫将会为web服务器带来巨大的资源开销
- 法律风险:服务器上的数据有产权归属,网络爬虫获取数据后牟利将带来法律风险
- 隐私泄露:网络爬虫可能具备简单访问控制的能力,获得保护数据从而泄露个人隐私
四、网络爬虫的限制
- 来源审查:判断User-Agent进行限制,检查来访HTTP协议头的User-Agent域,只响应浏览器或友好爬虫的访问
- 发布公告:Robots协议,告知所有爬虫网站的爬去策略,要求爬虫遵守
五、Robots协议(Robots Exclusion Stadard,网络爬虫派出标准)
作用:网站告知网络爬虫哪些页面可以抓取,哪些不行
形式:在网站根目录下的robots.txt文件
例子:哔哩哔哩的robots.txt文件:
Robots协议的使用:
网络爬虫:自动或人工识别robots.txt,再进行内容爬取
约束性:Robots协议是建议但非约束性,网络爬虫可以不遵守,但存在法律风险
若使用爬去数据进行商业牟利,应当自行遵守
User-agent: * Disallow: /include/ Disallow: /mylist/ Disallow: /member/ Disallow: /images/ Disallow: /ass/ Disallow: /getapi Disallow: /search Disallow: /account Disallow: /badlist.html Disallow: /m/
六、网络爬虫实例
1.测试抓取一个网页一百次所花费的时间
#url:"https://www.bilibili.com/" #爬去网页总计花费时间:71.3538544178009s import requests,time def getHTML(url): try: r=requests.request('get',url) r.raise_for_status() #若status_code!=200则抛出异常 r.encoding=r.apparent_encoding #替换编码 return r.text except Exception as e: print(e) if __name__ == '__main__': url="https://www.bilibili.com/" start_time=time.time() for i in range(100): getHTML(url) end_time=time.time() total_spend_time=end_time-start_time print("爬去网页总计花费时间:%ss"%(total_spend_time))
2.爬取亚马逊某一商品的页面信息
#爬取相关网页的商品信息 import requests url_dict={ 'jd':'https://item.jd.com/100004538426.html', 'ymx':'https://www.amazon.cn/dp/B07BXKFXKH/ref=sr_1_1?brr=1&qid=1564219979&rd=1&s=digital-text&sr=1-1', } def getHTMLText(url): try: r=requests.get(url,timeout=30,headers={'User-Agent':'Mozilla/5.0',}) #替换headers标识 r.raise_for_status() #若status_code!=200 将产生异常 r.encoding=r.apparent_encoding #替换编码 print(r.request.headers) #{'User-Agent': 'Mozilla/5.0', .......} return r.text[0:1000] except Exception as e: print(e) if __name__ == '__main__': url=url_dict['ymx'] print(getHTMLText(url))
3.爬取百度查询信息
#使用get方法爬取搜索引擎的结果 import requests url_dict={ 'bd':'https://www.baidu.com/s' } def getHTMLText(url): try: r=requests.get(url,timeout=30,params={'wd':'原神'}) #params添加字段 r.raise_for_status() #若status_code!=200 将产生异常 r.encoding=r.apparent_encoding #替换编码 print(r.request.url) #https://www.baidu.com/s?wd=%E5%8E%9F%E7%A5%9E return r.text #内容无法解析,待定。。。。。 except Exception as e: print(e) if __name__ == '__main__': url=url_dict['bd'] print(getHTMLText(url))
4.利用相关网站查询IP信息,并爬取结果
#查询ip归属地等信息 import requests def getIpMessage(url): try: ip=input("输入您的IP地址:") r=requests.get(url,params={'ip':ip},headers={'User-Agent':'Mozilla/5.0'}) r.raise_for_status() r.encoding=r.apparent_encoding return r.text[7000:] except Exception as e: print(e) if __name__ == '__main__': url='http://www.ip138.com/ips138.asp' print(getIpMessage(url))
5.爬取国家地理的图片信息
#爬去图片 import requests,os url='http://img0.dili360.com/ga/M01/47/53/wKgBzFkP2yaAE3wtADLAEHwR25w840.tub.jpg@!rw9' root='D://python学习//projects//python爬虫//day1' path='//'.join([root,url.split('/')[-1].split('@')[0]]) def getHTMLJpj(url): try: if not os.path.exists(root): print("保存目录不存在!") else: if not os.path.exists(path): r=requests.get(url) r.raise_for_status() with open(path,"wb") as f: f.write(r.content) f.close() print("图片保存完毕") else: print("文件已存在!") except Exception as e: print(e) if __name__ == '__main__': getHTMLJpj(url)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号