
OO第三次博客作业
OO第三次博客作业
OO课程的第三单元是基于JML规格实现一个简单的社交网络。
一:总结分析实现规格所采取的设计策略
1、仔细阅读JML
本单元首要的一步就是阅读JML,在coding之前阅读是为了更好的coding体验,在debug阶段阅读有利于快速找到bug。在此,我也梳理一些在阅读JML时容易由于粗心导致出错的地方:
-
\forall和\exists两者的嵌套使用,一不小心就容易被绕晕 -
\sum求和的内容需要仔细分析,特别是和\forall和\exists混合使用时,容易算成其他元素的和 -
exceptional_behavior异常处理时的顺序和传参的内容,需要结合JML和指导书中相关内容
2、确定数据存储方式
JML中的规格描述很喜欢使用数组,但不代表着只能用数组,甚至尽量减少使用数组(课程组在寒假的pre部分就反复强调容器的优点)。在根据JML实现规格时,也要选择合适的数据存储方式,主要体现在选择合适的容器,有关容器的选择将在第三部分做具体介绍。
3、设计优化算法
在第二次作业强测CTLE了九个点之后,我才以惨痛的教训明白了JML中的代码并不是让我们当”老实人“,直接将JML无脑翻译成JAVA代码,而是在理解JML中代码的整个实现过程后,用更优的算法来实现这个函数,有关优化算法将在第四部分做具体介绍。
二:结合课程内容,整理基于JML规格来设计测试的方法和策略
1、单元模块测试
根据JML规格,将本单元的指令主要分为三种类型:
-
第一类:直接对数据进行修改且返回
OK:如ap、ar等 -
第二类:直接对数据进行修改并返回相应内容:如
dce、sim等 -
第三类:查询指令(不会改变数据):
q开头的指令
对于第一种类型的指令,返回值也无法说明问题,但是它们只涉及简单的对数据的操作,实现起来一般不会有什么问题,因此也不需要在这类指令上花过多时间进行测试。
对于第二类指令,更容易出现WA的报错,这时可以先利用第一类指令构建出一个社交网络,再在其中有针对性地对第二类指令中的某一条进行专门测试,从而通过测试或者找到bug。
对于第三类指令,更容易出现CTLE/TLE的报错,一般情况下是算法不够优化导致的。可以先利用和第二类指令测试时类似的方式对指令进行单独测试,但是需要先构建一个更复杂的网络,方便找出CTLE/TLE的bug。当找到某一条或某几条可能会导致超时的指令后,再针对这几条指令对应的函数进行算法的优化。
2、构造数据
-
第一步,利用第一类指令(
ap、ar、ag等)构建出一个图作为基础; -
第二步:对于第二类指令,尝试多种组合方式构造数据,一般情况下不同的组合也会返回不同的结果;
-
第三步:对于第三类指令,在指令条数范围内,使用大量相同指令,插入到测试样例的各个地方,构造针对性的测试数据;
-
第四步:对于异常处理,一般容易出现异常处理函数调用错误、参数内容错误等问题,将一些会导致异常的指令混在前三步即可。
3、其他
课程组推荐使用JUnit来进行测试,但是由于本人实在没有时间去学习如何利用Junit进行测试,因此本篇博客也不再介绍该方法。但是,在我修复bug的时候,发现利用Excel进行对拍和检查还挺香——利用Excel中的函数能够方便快捷地找到出现bug的指令(面向Excel编程?)
三:总结分析容器选择和使用的经验
1、常用容器的介绍
在本学期的OO课学习过程中,我主要使用过以下几种容器:
-
List:以ArrayList为例进行介绍——一种最简单基础的容器,相当于可以改变大小的一维数组。-
创建:
new ArrayList<>() -
增加元素:
add(Obj)、addAll(Collection) -
删除元素:
remove(index)、remove(Obj)、removeIf() -
查询元素:
get(index) -
其他常用:
size()、sort()、contains(Obj)、isEmpty()等
-
-
Map:以HashMap为例进行介绍——哈希表,对关键字和值建立映射关系。-
创建:
new HashMap<>() -
增加元素:
put(key,value) -
删除元素:
remove(key) -
更新元素:
replace(key,value) -
查询元素:
get(key) -
其他常用:
size()、containsKey(key)、containsValue(value)、isEmpty()等
-
-
Queue:队列,符合先进先出FIFO原则的数据结构,分为阻塞和非阻塞。-
增加元素:
add(Obj) -
返回队列头部元素:
element() -
移除并返回队列头部元素:
remove()
-
-
Set:不允许重复元素的集合类,且最多包含一个null元素。-
增加元素:
add(Obj) -
删除元素:
remove(Obj) -
其他常用:
size()、toArray()、contains(Obj)、isEmpty()等
-
-
此外,还有一个特殊的容器:迭代器
Iterator,可以将前面介绍的那些容器“变身”为迭代器,在不知道原先数据的内部结构的情况下对内部元素进行操作,主要用于遍历元素。 -
附一张网上找到的
java容器关系图:![]()
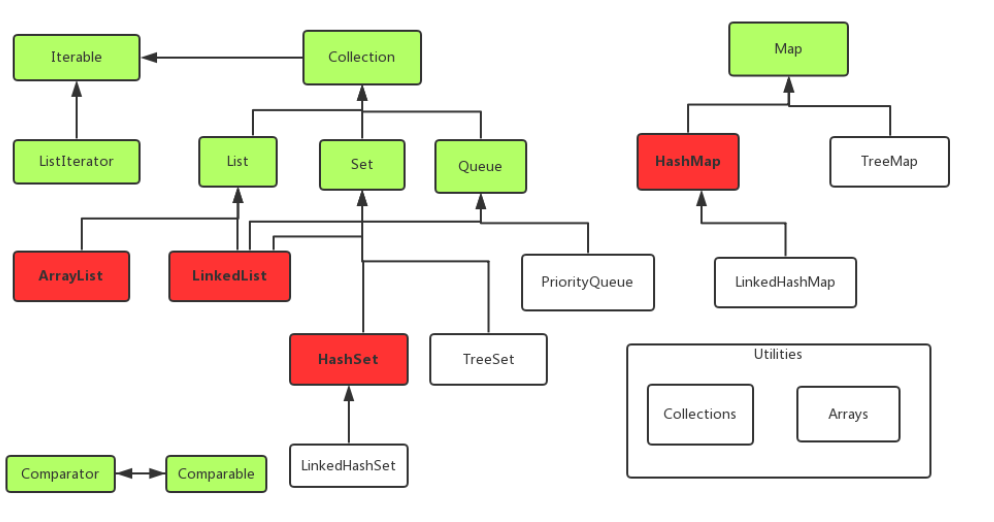
2、经验与教训
我自己也想不通为什么前两个单元沉迷HashMap的自己为什么在前两次作业中反而选择使用ArrayList,在本单元这么多需要根据id查询容器内元素的操作,直接用HashMap不香吗?还好在第二次作业的bug修复环节改过来了(HashMap yyds)。
不过话说回来,ArrayList和HashMap也并没有谁优谁劣,毕竟,Map在找数据和删除数据上要比List快得多,但是在存数据上还是要List更快,,根据规格和需求选择合适的容器才是王道。
四:针对本单元容易出现的性能问题,总结分析原因
1、数据结构算法的优化
本单元主要考察图的相关算法,涉及到了两个图的经典算法:图的连通分量,dijkstra算法求最短路径
-
图的连通分量:涉及到的相关指令是
qci和qbs-
原先算法:深度优先遍历算法
DFS-
算法描述:将与起始节点连通的节点放进一个队列中,每次从队列中取出一个节点,若该节点为目标节点,则两个节点连通,否则,将与当前节点连通且还没被访问的节点加入到队列中,直到位列为空,最终可判断两个节点是否连通,从而进一步求得整个图的连通分量。
-
缺陷分析:当图变得复杂时(节点和边的数量上千时)导致计算量过大,进行一次连通分量的计算要耗时几分钟(就是这么夸张),无法满足作业的时间要求,导致
CTLE/TLE。
-
-
优化算法:并查集算法
-
算法描述:用每个集合中的一个确定元素来代表整个集合,即为每个连通分量中的元素指派一个祖先元素,在增加节点和增加边的同时,更新相关节点的祖先节点。如果两个节点的祖先节点相同,则这两个节点连通。自身节点就是其祖先节点的节点个数即为连通分量的个数。
-
算法优势:将主要的处理放在了节点和边的增加过程中,而直接查询连通性和连通分量个数的时间得到了极大的缩短,从而满足了作业的时间要求。
-
-
-
dijkstra算法求最短路径:涉及到的相关指令是sim-
原先算法:普通的
dijkstra算法 -
优化算法:堆优化的
dijkstra算法 -
分析比较:普通的
dijkstra算法的时间复杂度为O(n^2),而堆优化的dijkstra算法的时间复杂度为O(Elog(V)),经分析,当节点数超过10^5时,复杂度会显著降低。但是本次作业节点数最多为四位数,两者的效果差距不明显,使用普通的dijkstra算法也能满足时间要求,通过强测。
-
2、计算的等价性
解决一个大的计算问题有两种方式:1、先计算其中的小问题,再由小问题的计算结果来计算大问题;2、直接计算大问题。
如果计算是一次性的,那么两种方式的计算时间是近似的。但是,如果计算是动态的,即每次改变一个小的条件,重新计算,不断重复,这样的话,第二种方式每次都要进行一次高复杂度的计算,而第一种方式只需要重新计算某一小问题的答案,再简单更新最终的答案就可以了。
那作业中的qgvs指令为例,如果采用第一种方式,每次查询都需要O(n^2)的时间复杂度,但是,如果把group value的值在add person from group、del person from group、add relation这些指令的执行过程中动态更新的话,最终的查询根本不需要计算,直接把当前结果拿来用就可以了!
3、其他
五、梳理自己的作业架构设计,特别是图模型构建与维护策略
本单元是根据JML规格写代码,因此总体的架构已经由课程组给出,不需要和前两个单元一样,自己设计作业的架构(也就很大程度上避免了令人烦躁的重构)。整个社交网络的层次如下:
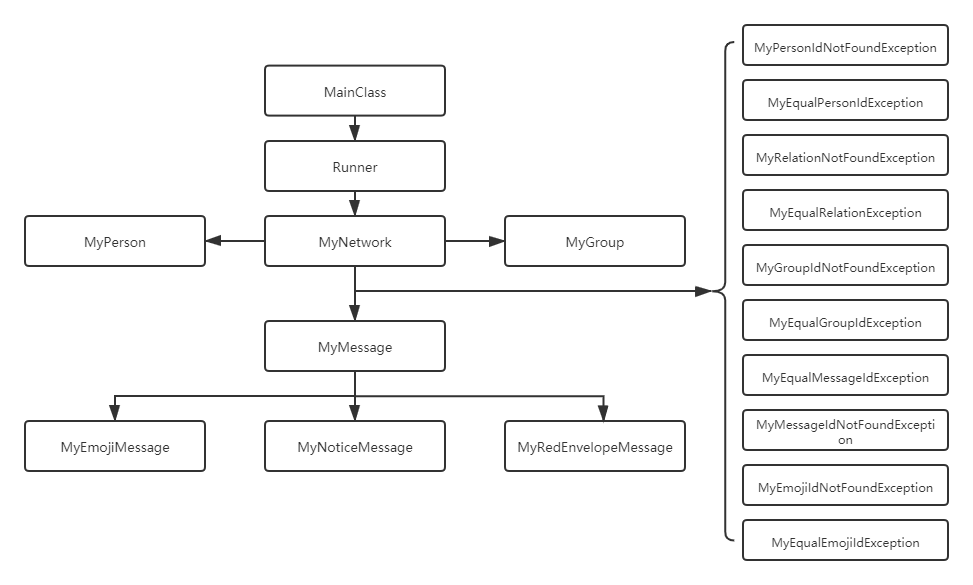
本单元的社交网络本质上是在维护一个图,作业中的指令可以抽象为对图的构建、刷新和查询:
-
构建:
-
addPerson:增加节点 -
addRelation:增加边 -
addGroup、addToGroup、delFromGroup:增加属性 -
……
-
-
刷新:
在图的构建过程中动态刷新某些图的属性,如前文提到的节点的祖先节点、
group的value sum等,具体刷新过程在前文算法部分已做相应介绍。 -
查询:
根据图中的节点、边及相应属性,查询得到相应结果。
六:心得体会
本以为OO第三单元会比较简单容易拿分(简单确实简单,但容易拿分就……),结果强测还是翻了车,面对一大片的CTLE深深地叹了一口气,甚至比前两个单元还做得差(侧面反映前两个单元我做得还不错?)。主要原因还是在于以下几个方面;
-
对于图相关算法的不熟悉
-
对于复杂度分析的不熟练
-
对于优化的无从下手
-
懒(临近考期留给OO的时间真的不太多)
总之,OO只剩下一个单元了,还是希望能拿出最好的状态面对最后一波“攻势”吧!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号