
面对对象 第三单元总结
面对对象 第三单元总结
实现规格的设计策略
第1次作业
本次作业要求较简单,按题目所要求的jml进行编写即可。对于jml中的person数组,我采用了hashmap来储存,以加快查询速度。另外由于所有的异常类均需要有计数的功能,因此我创建了一个新的类Timer作为计数器,将方法封装好,调用方法的同时将自动完成计数。另外的一些较为复杂的方法在性能分析中说明。
第2次作业
本次作业增加了两个类,我的思路是先用python写好的文件比较器,比较之前的Person类和Network类和这次的差异,由此便可知道本次作业大致需要增加什么,以及之前的方法是否需要修改。接下来阅读增加的两个类,分析他们与之前的两个类的关系,发现是Network中包含了他们,由此先将这两新增的类完成,再回过头去完成Network。这次作业的异常类便完全照抄之前的类即可,只需要修改print的内容即可。
第3次作业
本次作业也与上次差不多,思路仍然是先比较,再写最基础的类,最后完成Network即可。其中不同的message都是继承了之前的message,因此只需要编写其特殊的方法和属性即可完成。最后是Network的编写,其中最复杂的方法是查询最短路,我使用的是堆优化的dijsktra算法解决。
基于JML规格来设计测试的方法和策略
随机构造
随机生成大量数据与同学对拍,为了确保一定强度,在一开始时加入一定数量的人和关系,之后再进行随机生成,确保进行查询时有人和关系。利用这个其实已经可以找出大部分bug。
边界构造
考虑题目中所出现的一些边界条件进行构造,如最多1111人,那么构造出一种加入超过1111人的测试数据,又如dce要求同时删除message,那么可以构造先加入emoji和其emojimessage,再进行dce之后观察是否删除了该emojimessage。
考察性能的构造
考察某些复杂方法的写法,如第1次作业的iscircle和queryBlockSum,第2次作业的qgvs,第3次作业的sim。构造相关的复杂图并多次查询调用这些方法,达到hack的效果。
容器选择和使用的经验
Arraylist
可以直接使用下标访问,但在查询时较慢(只能遍历查询),因此在本次作业中我使用到该容器的情况较少,只有在储存person中的messages时,由于要在头部插入并且有将最新的4个message调出来的需求,我使用了Arraylist。另外还有在我的储存blocks(用于第一次作业的连通块)的每一个连通块中的人的id时,也是使用的Arraylist,这是因为我的操作是将一个arraylist中所有的元素移动到另一个arraylist中,同时每一个元素都需要进行连通块编号的改变,因此相当于需要遍历整个表,因此也使用了Arraylist。
Hashmap
在进行查询时效率较高,因此在涉及到查询操作时我都使用了该结构,除了上面所说明的两种情况,其他都使用了hashmap。
Hashset
在写堆优化的dijsktra算法时使用了一次,用来记录该节点id是否已经到过了,即判断hashset是否包含这个id即可,效率较高。
性能问题与bug分析
第一次作业
本次作业的性能问题主要是连通块的问题。
采用每次加人时构造一个新的block,加关系时将两者的block合并,在查询iscircle时只需要判断两者的block编号是否相同,查询连通块个数时只需要返回block的个数
private HashMap<Integer, ArrayList<Integer>> blocks;
数据结构如上,每一个编号对应一个Arraylist,Arraylist里存该block里的人的id。
在进行加人时添加一个bolck:
curOfBlock++;
numOfBlock++;
myPerson.setThOfBlock(curOfBlock);
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList.add(myPerson.getId());
blocks.put(curOfBlock, arrayList);
在进行增加关系时添加如下合并block的代码:
int newId = person2.getThOfBlock();
if (person1.getThOfBlock() != newId) {
for (int id : blocks.get(person1.getThOfBlock())) {
((MyPerson) getPerson(id)).setThOfBlock(newId);
blocks.get(newId).add(id);
}
numOfBlock--;
}
于是接下来的方法便十分简单:
public boolean isCircle(int id1, int id2) throws PersonIdNotFoundException {
//异常处理
return ((MyPerson) getPerson(id1)).getThOfBlock()
== ((MyPerson) getPerson(id2)).getThOfBlock();
}
public int queryBlockSum() {
return numOfBlock;
}
第二次作业
第2次作业的主要问题是qgvs,如果只使用俩个for的话很有可能出现一个人的朋友很多但是都不在这个group中,导致过多的无效查询,也有可能一个人的朋友很少但是这个group中人很多,导致按group查时也有无效查询。因此我先判断两种方法的查询次数,再根据结果来查询。
public int getValueSum() {
int sum = 0;
int peopleSize = people.size();
for (Person i : people.values()) {
HashMap<Integer, Integer> values = ((MyPerson) i).getValue();
if (values.size() < peopleSize) {
//查朋友
} else {
//查group
}
}
return sum;
}
第三次作业
这次作业主要是堆优化的dijkstra算法
这里我是先构造了一个实现了Comparable接口的Edge类,然后使用优先队列实现的。
public class Edge implements Comparable<Edge> {
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int getDis() {
return dis;
}
public void setDis(int dis) {
this.dis = dis;
}
private int id;
private int dis;
public Edge(int id, int dis) {
this.id = id;
this.dis = dis;
}
@Override
public int compareTo(Edge o) {
return this.dis - o.dis;
}
}
private int dijkstra(Person p1, Person p2) {
PriorityQueue<Edge> queue = new PriorityQueue<>();
HashMap<Integer, Integer> id2dis = new HashMap<>();
HashSet<Integer> id2vis = new HashSet<>();
queue.add(new Edge(p1.getId(), 0));
while (!queue.isEmpty()) {
Edge edge = queue.poll();
if (edge.getId() == p2.getId()) {
return edge.getDis();
}
if (id2vis.contains(edge.getId())) {
continue;
}
id2vis.add(edge.getId());
int base = edge.getDis();
((MyPerson) getPerson(edge.getId())).getValue().forEach((key1, value1) -> {
int key = key1;
int value = value1 + base;
if (!id2vis.contains(key)
&& (!id2dis.containsKey(key) || id2dis.get(key) > value)) {
id2dis.put(key, value);
queue.add(new Edge(key, value));
}
});
}
return 233333333;
}
架构设计
类图分析
三次作业的架构基本上都是按jml写的,只增加了一个Timer类用于计数,以及一个Edge类用于dijkstra算法。
下面是三次作业的类图:
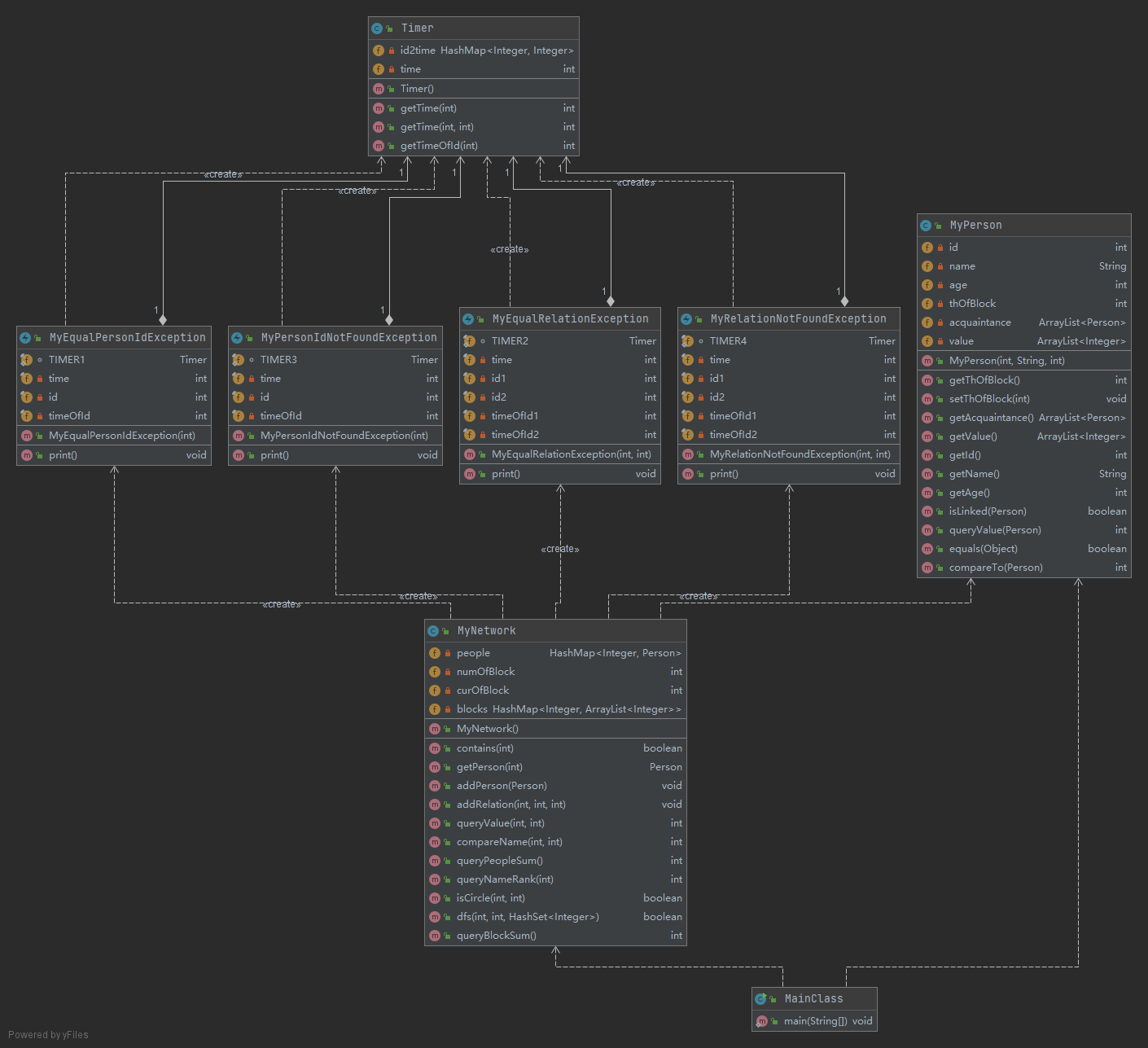

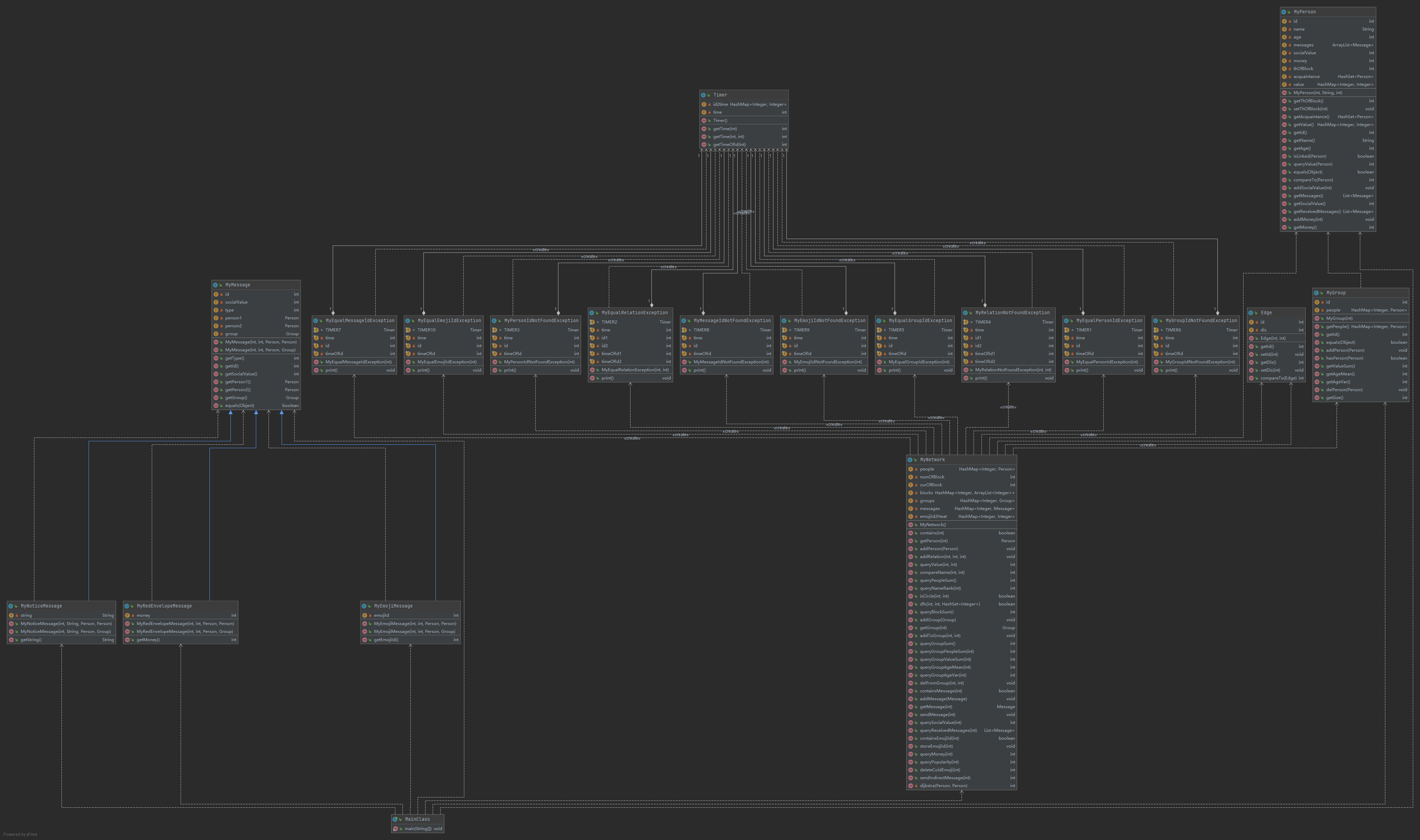
图模型构建与维护
为了维护连通块,我新建的数据结构已经在上面的性能分析的第一次作业中进行了详细的讲解。其他的均与jml相同,只是将jml中的数组替换为了查询效率更高的hashmap。
总结
这单元相比于前二个单元甚是友好,三次都没有出现bug(因为按jml写就不会错,但是也要仔细阅读,不能漏了一些细节,如1111人和dce的删除message都是我一开始写的时候忘掉的,后面对拍才发现问题),然后就是一些高级数据结构的使用以及对容器选择的训练,收获还是蛮大的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号