BUAA_OO_UNIT1
BUAA_OO_2021_第一单元总结
随着第三次测评截止、bug修复开始,OO第一单元暂告一段落。本单元主要目标为面向对象思想的学习与熟悉,以及化整为零、分工合作思想的进一步巩固。现对本人的学习心得与体会进行总结。
第一次作业(多项式求导)
基于度量的代码结构分析
第一次作业为多项式求导,不涉及三角函数、嵌套、表达式因子等情况,且没有WF,保证输入完全正确,故处理起来较为简单。UNL图如下:
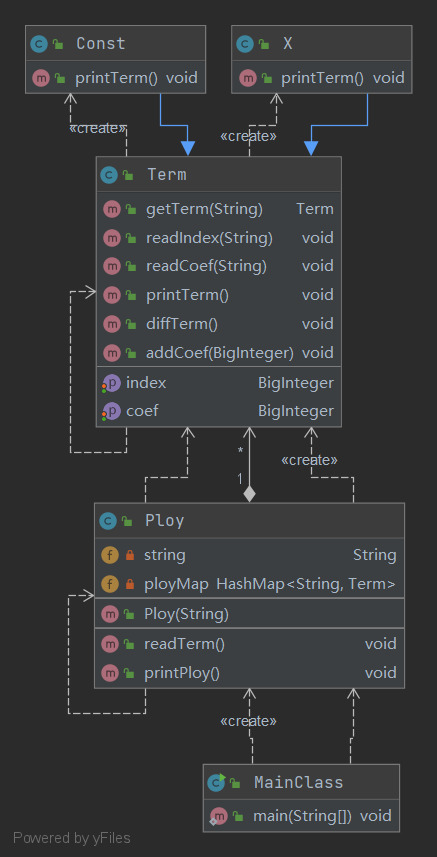
-
架构
第一次作业我因保证数据正确性,故先在MainClass中对输入进行处理。先出去所有空格,再将所有三个连续符号替换为一个符号、将'--'、'++'替换为'+',将'+-'与'-'替换为'+-',再将'*+'替换为'*'。此举会将所有的项以'+'分割开。
因第一次作业求导较简单,故在Term类主要实现读取系数、指数与实现求导,子类实现输出;X、Const类继承Term类,覆写输出方法;Ploy类接收传进来的String,分割得到项,然后读取、求导项,之后输出;最后通过HashMap实现合并化简。
-
函数调用:主程序调用Ploy构造器,再调用readTerm,此时Poly自行调用Term的求导方法;再调用printPloy,进行输出。
虽然寒假已经做好pre,但由于对面向对象、化整为零思想不够熟练,各个类与方法独立性不足。
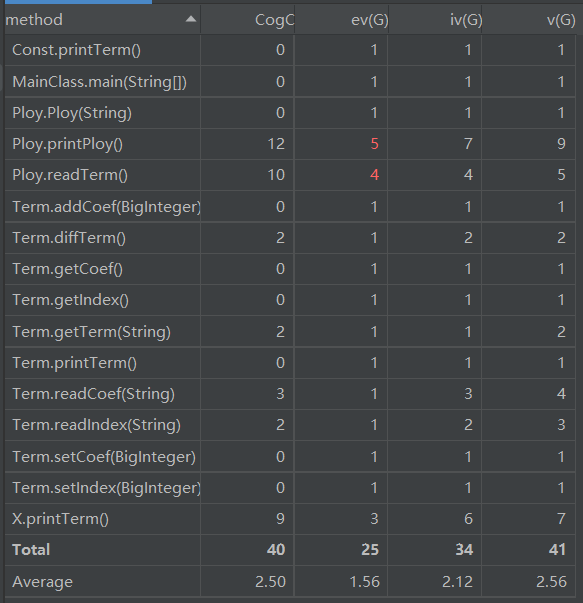
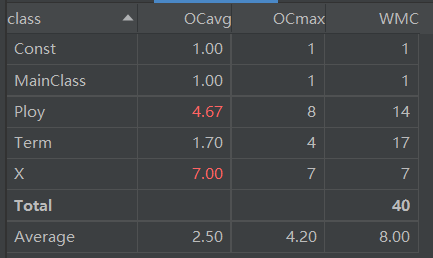

从代码复杂度分析数据可以发现,除了Poly类的printPoly、readTerm()方法基本复杂度较高外,其余方法复杂度都在合理范围内。分析得,其中if语句后面基本没有else,导致基本复杂度较高。而Poly类因过多for each遍历、X类因过多if-else而平均循环复杂度偏高。
同时,可以看到各个类的内聚缺乏度(LCOM)较低,而Ploy类、Term类FANIN较高,说明基本符合高内聚低耦合的原则。究其原因,为Term类作为父类被多次继承、复用,Ploy类适当调用方法。而方法数目较为均衡,行数也较为平均。
测评
本次作业在中测、互测中均发现bug,起因为将'x**2'化简为'x*x'时输出换行,导致后续结果未被读取。
互测时发现有同学在指数过大、两个或三个符号连续出现时出现错误,为自己测试时留下的样例。可见项的读取与求导需要细致的分析。
出现bug的方法(X.printTerm)代码行数与复杂度皆比较低,出错原因是自己粗心orz
第二次作业(三角函数、表达式因子)
基于度量的代码结构分析
本次作业追加了三角函数sin(x)与cos(x)求导,因子中追加了表达式因子,同样保证没有WF。UML类图如下。

-
架构
基本上次作业投机取巧的面向过程写法,本次作业不得不重构。递归下降语法分析来判断格式以及提取项、因子。同时,去除Poly类,让sin、cos、x继承Term类,覆写求导diff与输出toString方法;建立项的处理者Item类,对项进行提取、求导处理;建立FactorFactory进行提取、求导处理。
上半部分显示了Term类的继承关系:sin、cos、x、const都继承自Term,拥有coef、index属性以及求导等方法。为了便于管理三角函数,设置一个新的类triangle继承Term,在内部管理sin与cos,通过引用类型Term来实现统一管理。FactorFactory作为因子工厂,提供读取并合并各种因子的方法。DetectPlus作为递归下降语法分析,能够有效拆分项(见下)。Optimization作为优化函数,调用DetectPlus实现。在MainClass中调用DetectPlus得到各个项,传入Item中,调用FactorFactory工厂的get方法得到因子形成Term,再调用各个Term多态求导,各自输出求导结果。实现化整为零、分工合作。
-
递归下降的语法分析
本次作业出现表达式因子,导致无论是上次作业的面向过程还是正则表达式,都难以处理,故采用递归下降的语法分析。先将**替换为^以便于分析,再分别根据不同的形式化表达建立函数,利用boolean值进行判断。同时,传递参数StringBuilder,在布尔值为true时将获取到的常数、指数、符号等加入到StringBuilder中,再在ItemPlus中进行分割,实现表达式的检查与拆分为各个项。
-
优化
本次作业因为重构,来不及做三角函数化简、同类项合并的优化,仅做了去括号、去空白项等简单处理。通过在Optimization中调用Item,实现递归下降、因子提取、去括号,再与之前未优化的长度比较,若比之前短则继续优化操作。
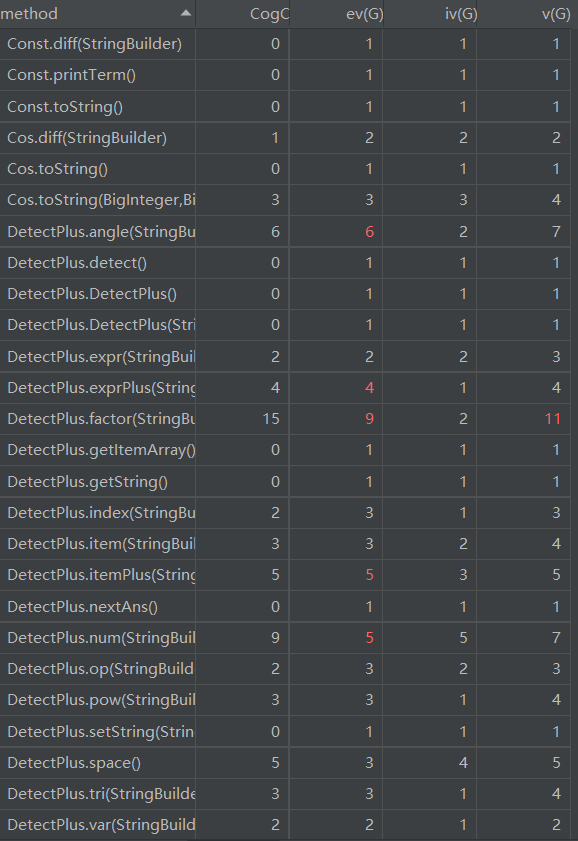
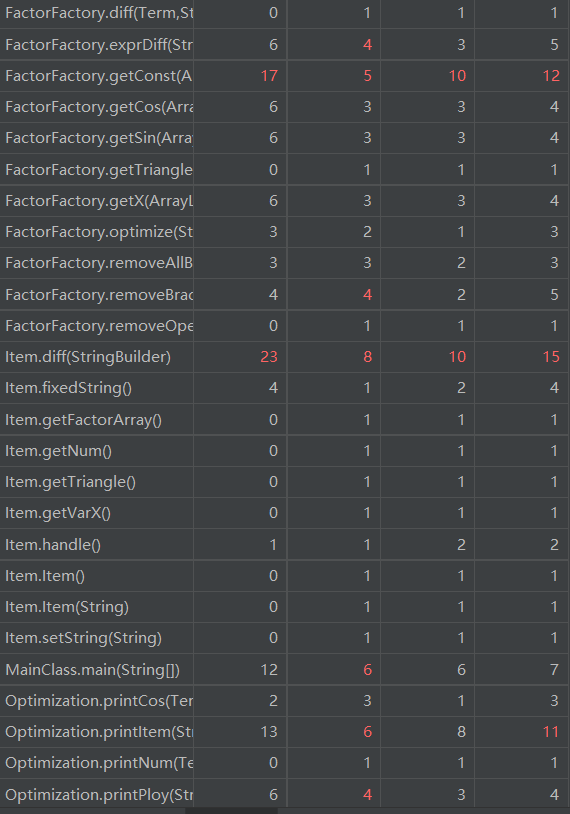
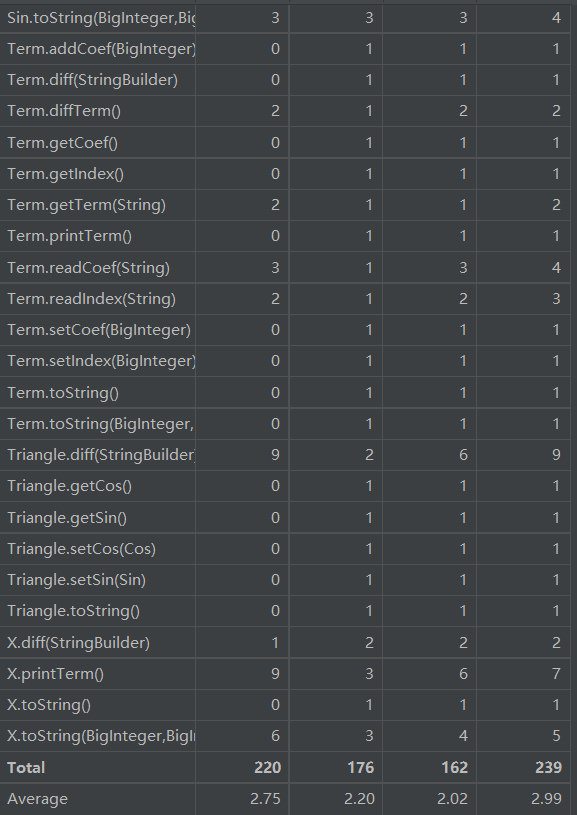
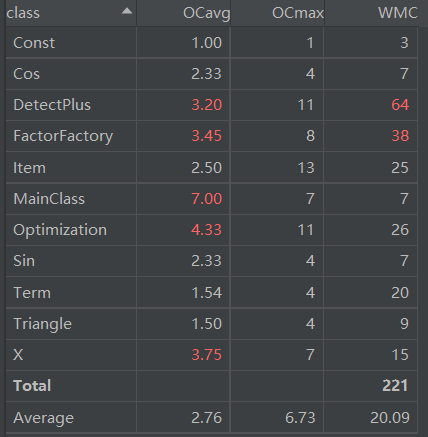
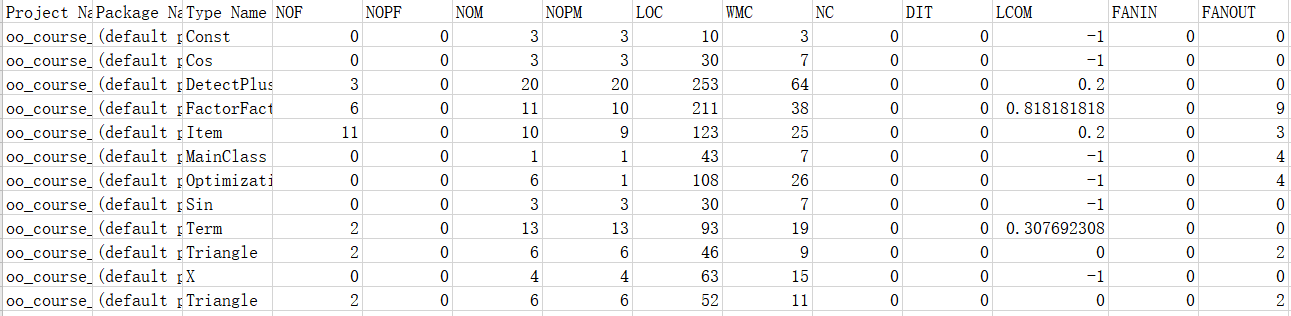
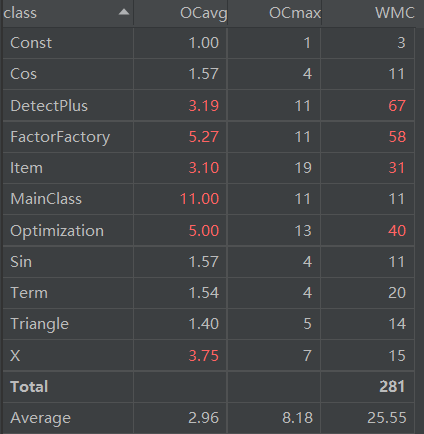
从代码复杂度分析数据可以看出,本次代码复杂度惨不忍睹。多个方法的基本复杂度超标,DetectPlus中原因为if-else模块缺少else,几乎都在if判断失败时return;其余也是因为if-else模块缺少else,都在if判断失败时继续向下执行。同时,多个方法中结构复杂度偏高,原因为多个if模块嵌套、并行,导致独立路径过多,造成代码难以维护。同时,多个类中平均循环复杂度偏高,或包含嵌套循环,或包含多个循环,导致代码需要不断循环,同时WMC也偏高。若要改良,可以将不同循环分割为不同方法,以降低维护难度。
再者,DetectPlus与FactorFactory代码行数过高,原因是前者需要多个函数调用实现递归下降,后者有多个提取因子、合并的方法。FactorFactory的内聚缺乏度过高,表征其内部结合相当不紧密,因其为了实现因子提取,与Term及其子类的关联度过高,导致内聚性不良。其余代码行数与方法复杂度都在可接受范围内。
另外,考虑到第三次可能的扩展,采取此层次架构。只需要在递归下降对sin、cos添加因子项,再稍微改动Item中求导,即可完成迭代开发。
测评
本次作业在强测、互测中均出现bug,原因为一处判断字符当前位置是否超出字符串范围的逻辑出错,导致抛出StringIndexOutOfBoundsException。后修正逻辑,即可正常运行。
互测中发现有同学在sin、cos多次相乘时出现指数错误,连续符号、x、三角函数同时出现时求导错误等情况。推测是由于分析时漏项、求导时疏忽等情况导致在高复杂度下出现bug。
DetecePlus代码行数过多、复杂度过高,导致我再进一步修改时没有很好地覆盖性测试,故出现字符串outOfBounds的情况。
第三次作业(嵌套、WF)
基于度量的代码结构分析
本次作业新增嵌套情况,在三角函数中能出现因子,同时需要对错误格式继续判断。由于上一次作业具备一定可扩展性,此次作业难度跨度不高。UML类图如下。
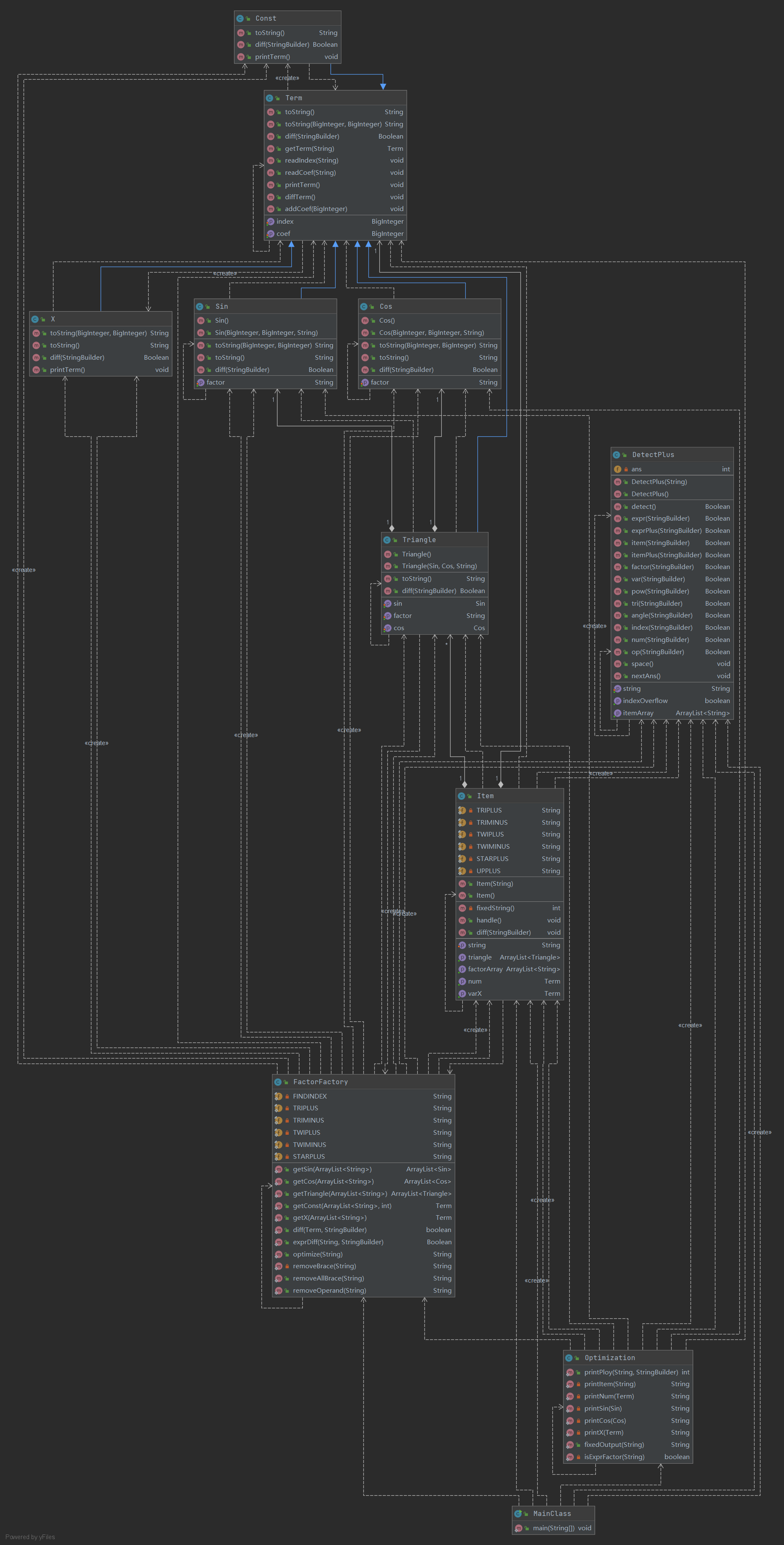
-
架构
本次架构相较上次作业无大的变动。仅在递归下降语法分析时对sin、cos括号内进行因子判断,sin、cos求导方法新增因子的求导,在Item类求导稍作改动,在MainClass中对可能的StringIndexOutOfBoundsException进行捕获即可。
-
函数调用
与上一次作业类似。主要区别在于工厂中新增加对于表达式求导的函数exprDiff,在三角函数内部求导时会先调用exprDiff对因子进行求导,同时调用Optimization对因子及其求导结果进行化简。
-
优化
本次作业对优化相较于上次,为了防止出现bug而选择较有把握的优化,主要为优化系数为±1的项、对三角函数内部是否需要括号进行判断、不完全的同类项合并。性能并没有较好地进步,仍有很大的改进空间。
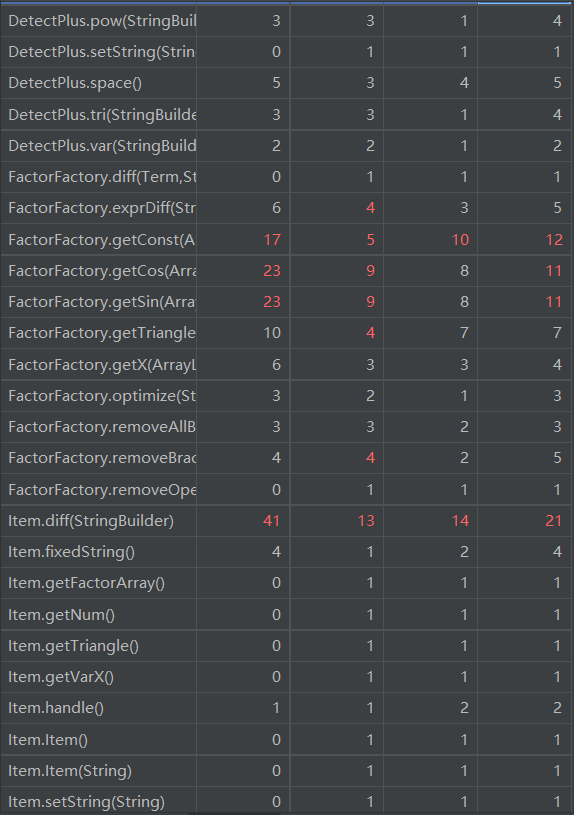
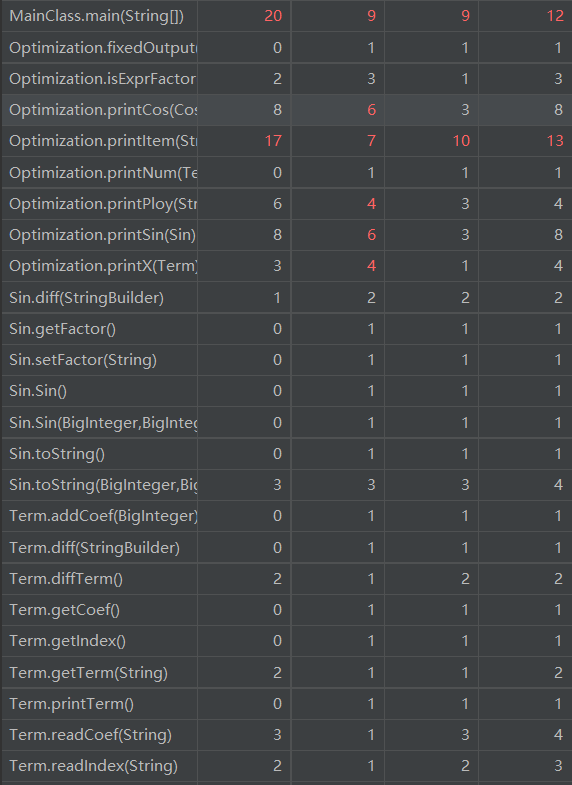
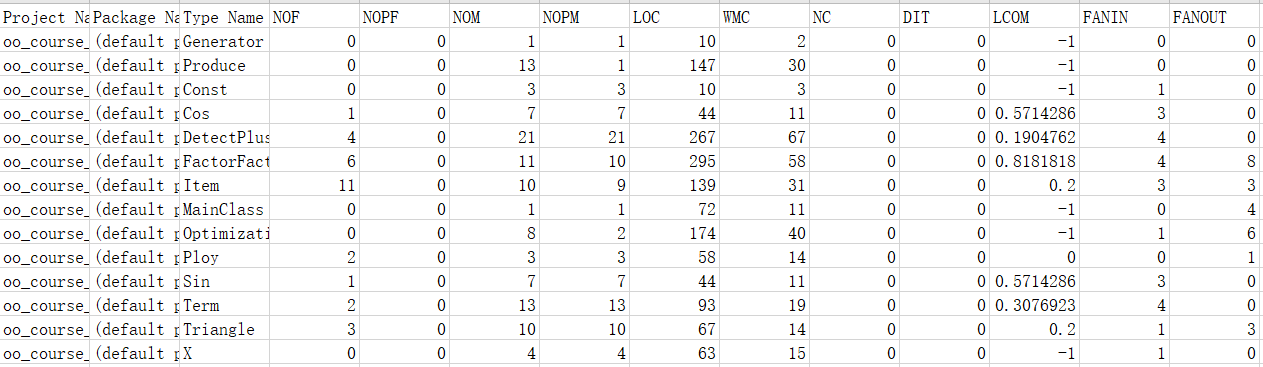
图像过多,仅放入关键部分图像
本次作业有部分方法被弃用,但并没有删去,故方法数目过多,一定程度上在我调用方法时造成困难。同时,延续了上一次的代码,导致不少方法代码量过大,不得不继续格式删减,诸如DetectPlus、Optimization中各种方法。可以看到,基本复杂度超标的方法也延续了上一次作业,原因几乎都出现在if-else模块。同时,多个类中平均循环复杂度偏高,在我扩展时造成了一定的困难。同时,由于是在几乎完全延续上一次作业方法基础之上进行扩展,许多方法的行数接近上限,导致修正格式花费了不少时间,也使得代码冗长不易维护。改进方法为将实现过于复杂功能的单一函数分割为各自实现不同方法的private函数,再进行统一调用。
代码行数方面,除了DetectPlus与FactorFactory几乎照搬上一次作业而依旧超标,Optimization也因为追加去除内部括号、同类项合并而行数有些多。而LOCM方面,sin与cos骤增,问题主要为求导时需要调用对表达式因子的求导,进而层层诱发求导,导致sin、cos与Item、Optimization等关联过于紧密,进而导致LOCM骤增。
测评
本次在互测中未被测出bug,在强测中同样因为复杂而冗杂的DetectPlus,对三角函数内部指数错误(即绝对值大于50)判断出误而导致一个WF未判断到。改进方法为追加boolean值,进行内部错误指数的判断,并作为if条件的一个依据判断是否返回错误信息。
在互测中,找到同学WF错误。有三位同学因为对正确格式判断为WF,或括号间有\t而判错、或合理指数判错(如1*x**50*x**2)。前者为递归下降语法分析写漏条件,后者提前合并同类项导致出错。可见需要对题目形式化表述有进一步理解,才能较好地完成WF判断。
bug检测与分析
- 检测主要有手动构造与测评机两种。前者需要自己试着覆盖各种可能的情况,并对极端情况、极端分支进行构造,后者使用python脚本进行覆盖测试。主要bug在于错误的优化以及递归下降考虑不周。
- 发现bug时,我主要采取在可能出现问题的点输出数据的方式,通过模拟数据流向来推断bug出现的位置。
互测
互测是一个考验阅读他人代码、构造测评样例的环节。在以后工作中,除了测试工程师外,基本不可能有公测,更别提互测。在互测环节可以看到他人的思路与错误,从而扩宽自己的视野、避免未曾设想的错误。
互测环节我主要采取手动构造极端样例、自动测评的策略。前者在自动测评中不易出现,故手动构造以测试程序在极端情况下的鲁棒性;后者为大规模盲狙,以求更高效率的hack。
工厂模式
本单元作业使用工厂模式来创建不同的因子,能够有效地减少因子提取过程。先是建立FactorFactory类,其中包含各种提取因子的方法,只需要调用即可。同时,还包含print、diff的调用方法,会调用因子的输出、求导方法,能够实现自顶向下依次调用,层次分明。
从第二次作业到第三次作业,只需要在工厂中加入对表达式的求导,再在sin、cos求导中加入使用因子求导,即可实现扩展。可见这种工厂模式具备较好的扩展性。
美中不足的是,我在工厂模式中加入了一些冗余的方法而未删去,导致工厂模式体量过大,不利于维护。
心得体会
-
pre
寒假的pre得好好做,不然开学起来没有太多JAVA语法基础下,立刻开始多项式求导可能会对你造成暴击(指我自己
-
评论区与博客
不论是跟大佬们交流还是看大佬们交流,都可能会对你的思路产生一定的帮助。特别是在优化、架构方面,有时候可能一语惊醒梦中人,让你少走很多弯路。
除了评论区,往届博客可能也有不少避坑、优化、结构等等方面的策略,值得大家参考。
-
架构
提前把架构用文字形式记录下来,细分到类、方法、属性、如何实现、调用关系等等,形同上学期的计组一般,这样在写代码时可以高效、流畅地把代码写出来,而不会中途卡壳,甚至看不懂自己在写什么。
同时,最好考虑后面作业的可扩展性。重构一时爽,debug就……
-
git
记得每次有改动都及时提交,并写上能够迅速了解有何改动的commit,有助于在发现错误时进行版本回退,可能减少不必要的重构。
-
递归下降的语法分析
无论讨论区还是课堂,都有提及这个概念。使用递归下降不仅可以很方便地判断格式正误、提取项、因子,更能提供很好的优化方式。将求导完的结构反复进行语法分析,再在其中合并同类项,与之前的String长度进行对比取舍,能有效地优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号