
跟案例用springboot框架写简单项目
springboot创建模块时应该用jar包的,忘了
原始springMVC是war包没错
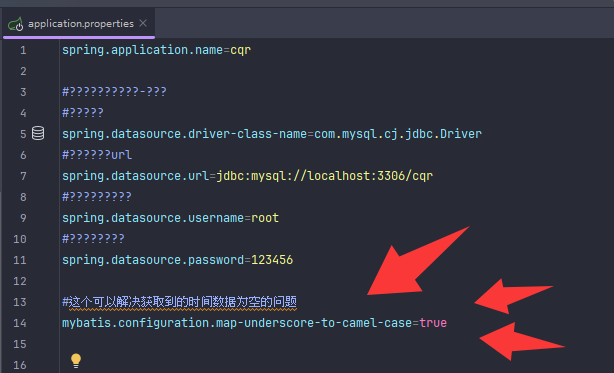
#这个可以解决获取到的时间数据为空的问题
mybatis.configuration.map-underscore-to-camel-case=true
先视频

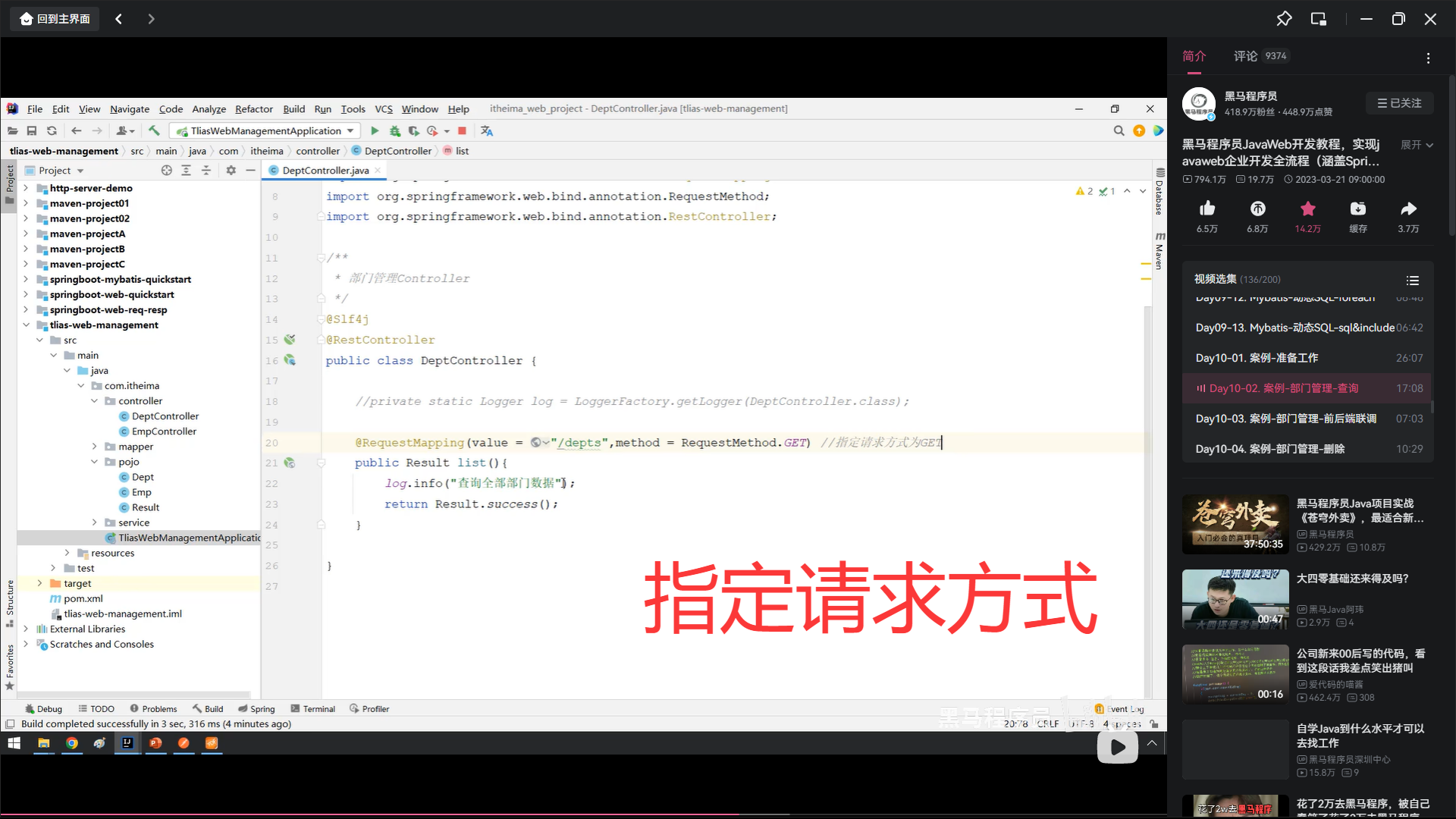
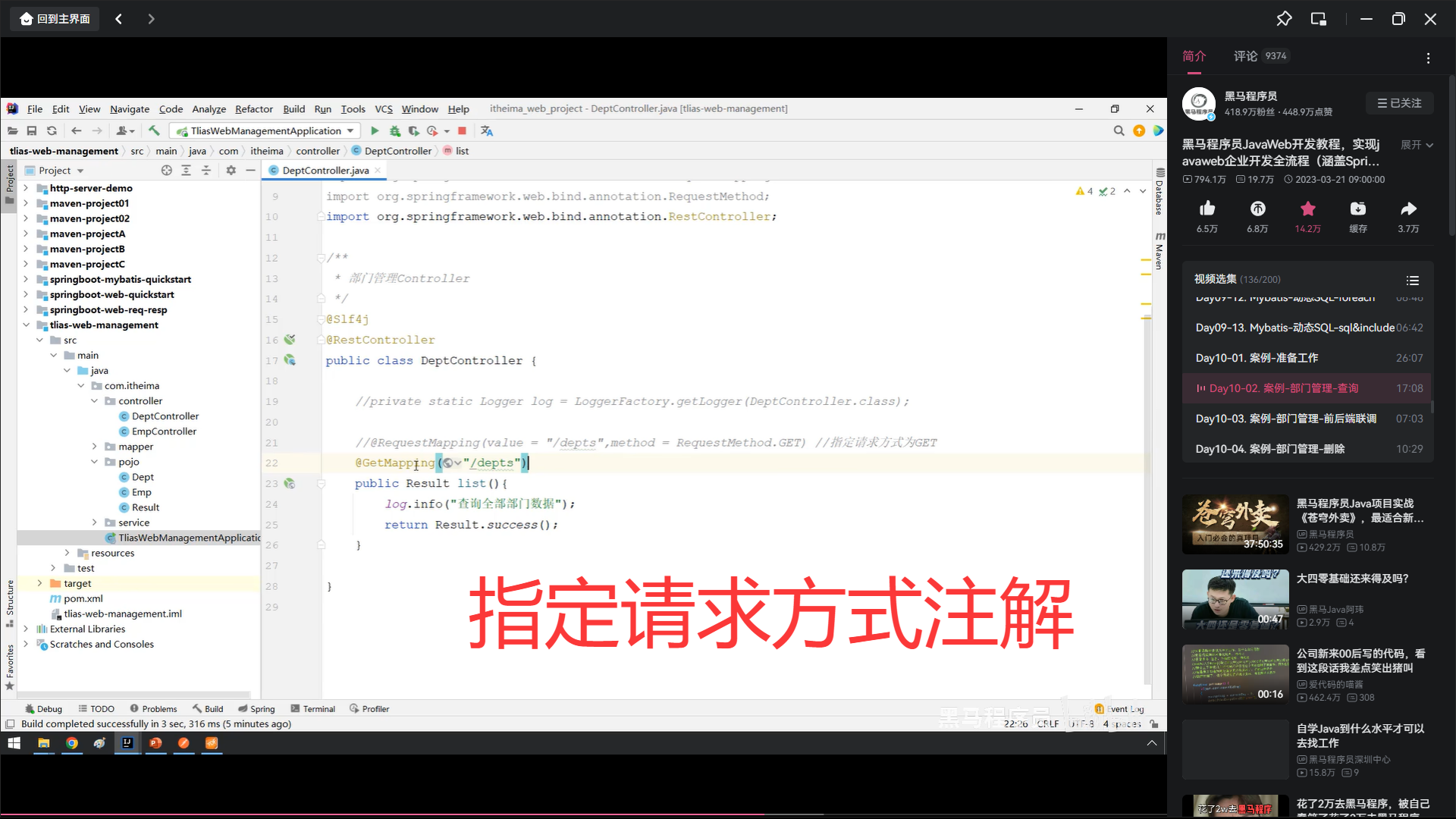
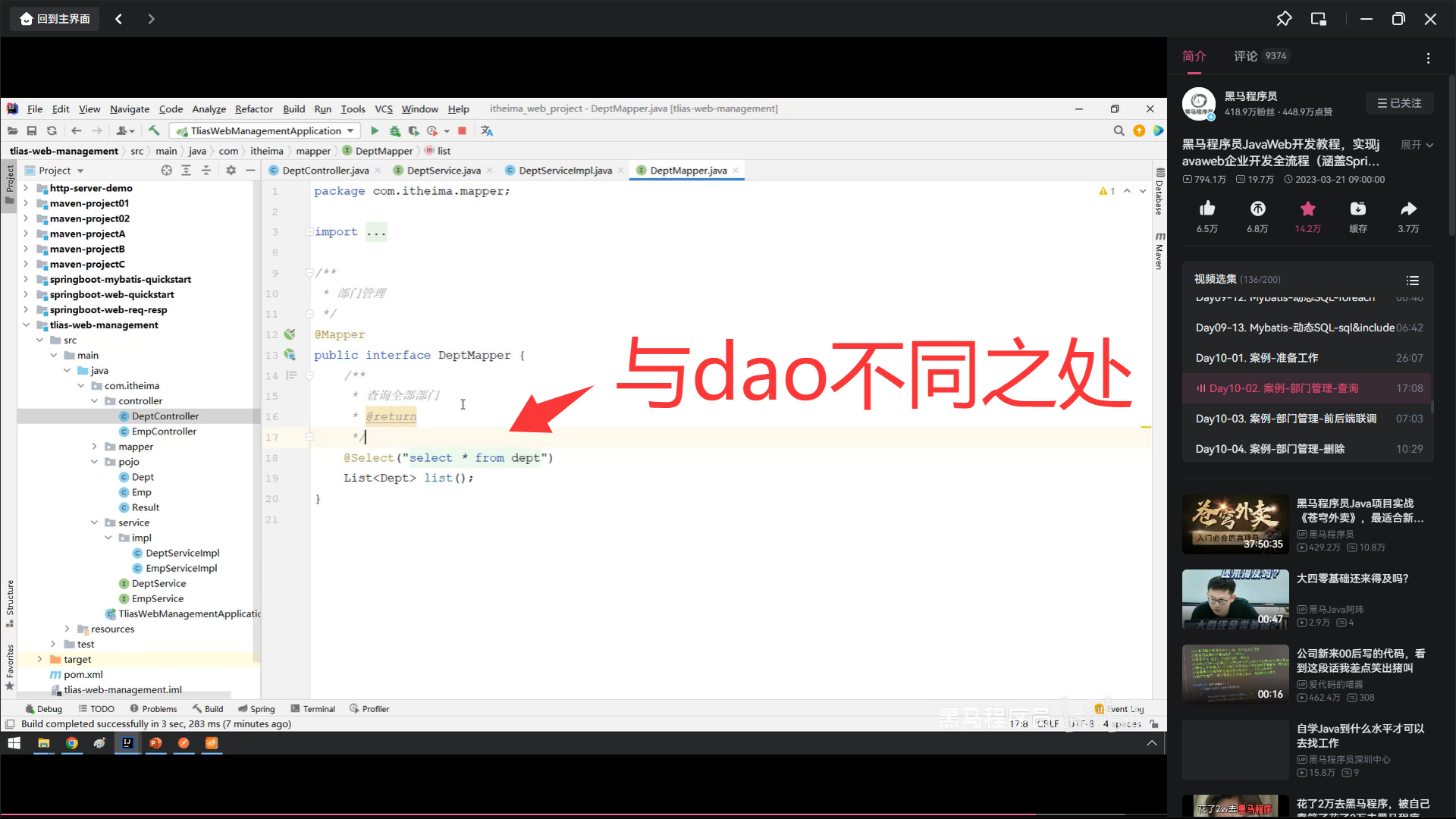
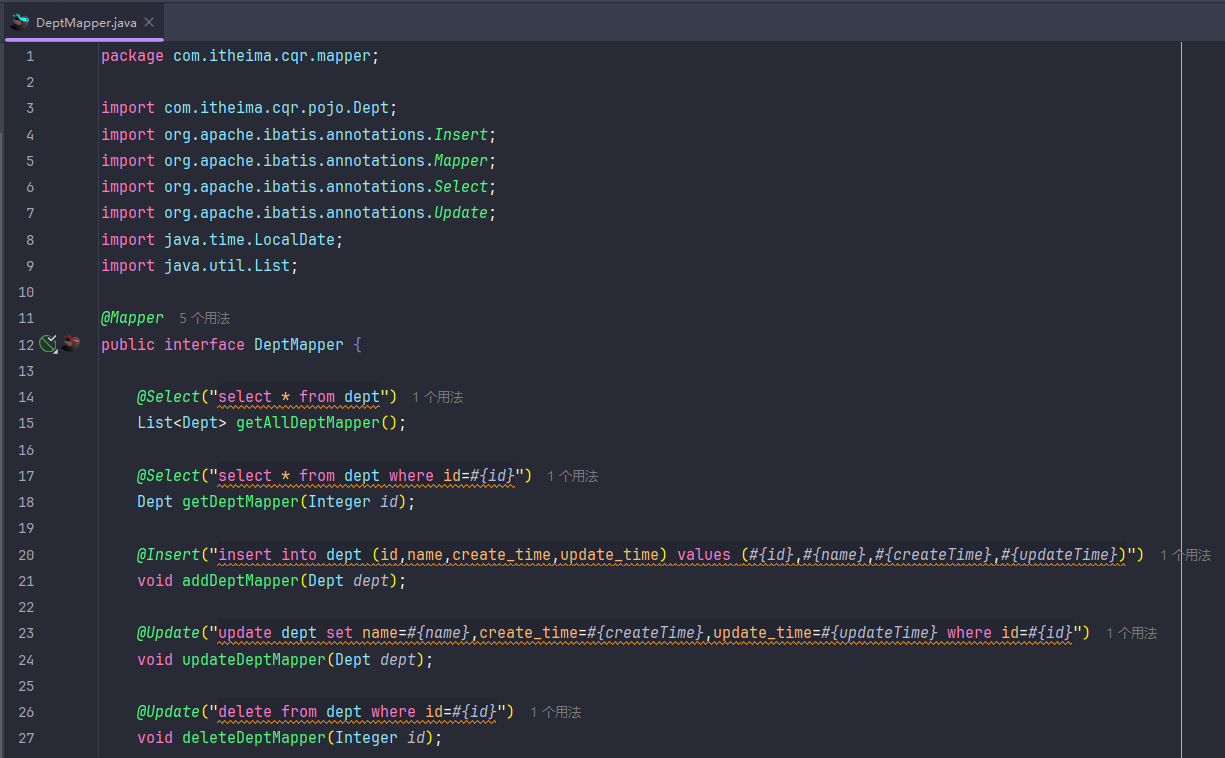
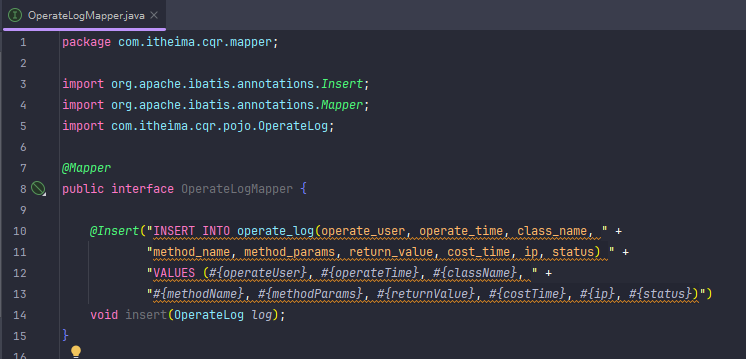
写增加数据库数据。mapper层的错
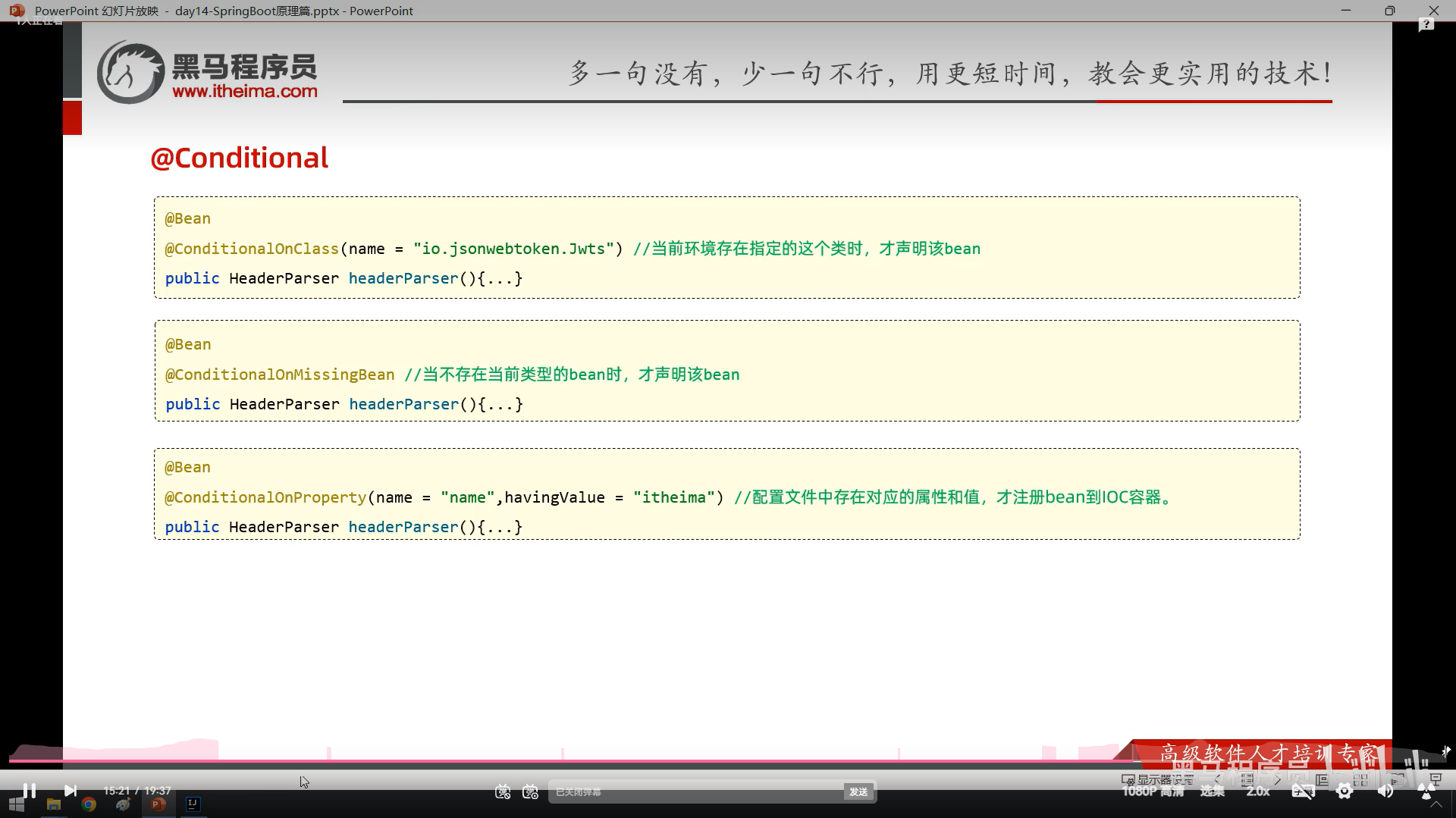
你的添加语句(@Insert注解和方法)标红,主要有以下几个原因:
SQL语句语法错误
你在@Insert注解里的SQL语句,字段和参数都被双引号包裹,导致语法错误。
正确写法应该用#{}占位符绑定参数,例如:#{name}。
注解字符串拼接错误
你的@Insert注解字符串里,双引号嵌套导致编译器无法识别字符串边界。
接口方法不能有方法体
Mapper接口中的方法不能有方法体(不能有大括号和实现代码),只能声明方法。
SQL语句中的字段名和表名不能用双引号包裹,应该直接写字段名。
@Insert注解的字符串外面多了一个双引号,导致语法错误。
方法声明后面缺少分号。
简单增删改查

接口不用写公有私有
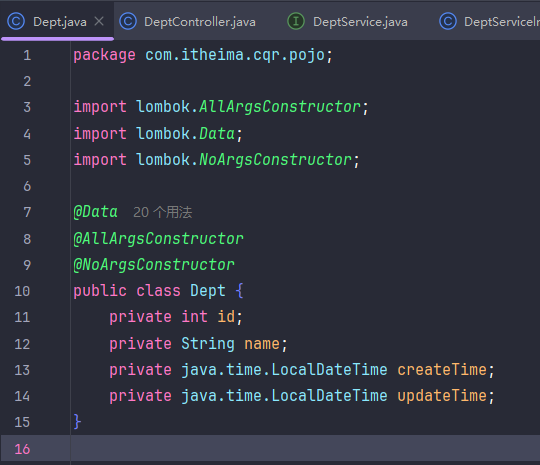
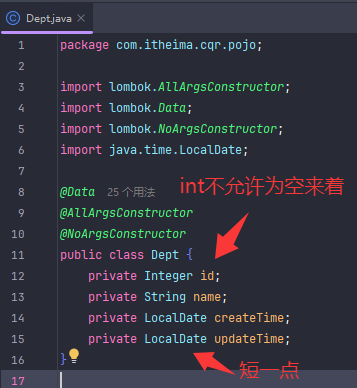
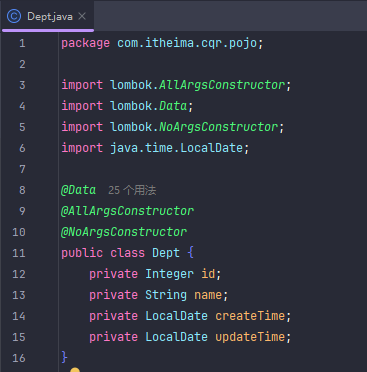
注意这个java的时间类型,
如果数据库的字段类型是datetime年月日时分秒。则后端实体类变量数据类型是LocalDateTime年月日时分秒。
如果数据库的字段类型是date年月日。则后端实体类变量数据类型是LocalDate年月日。
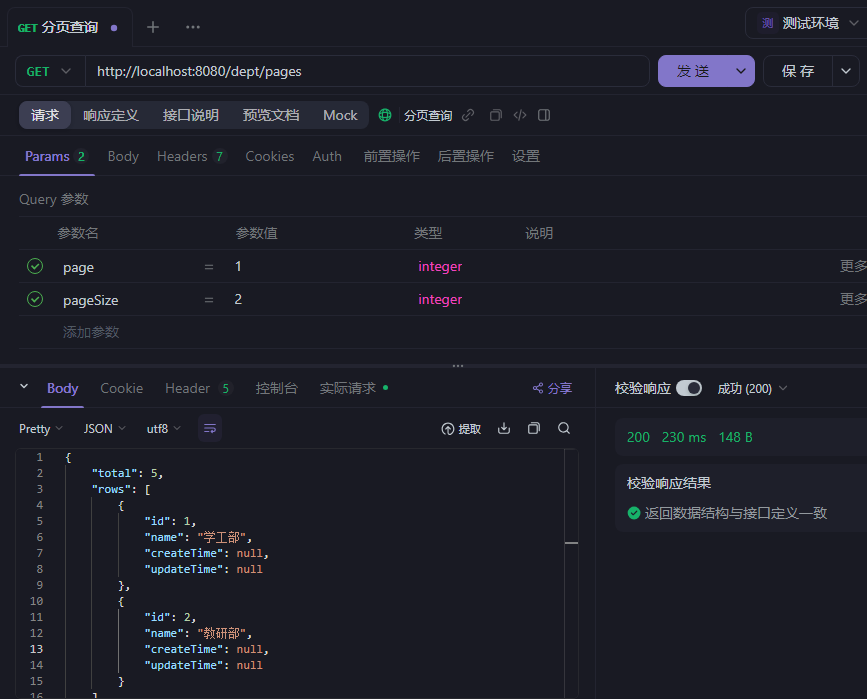
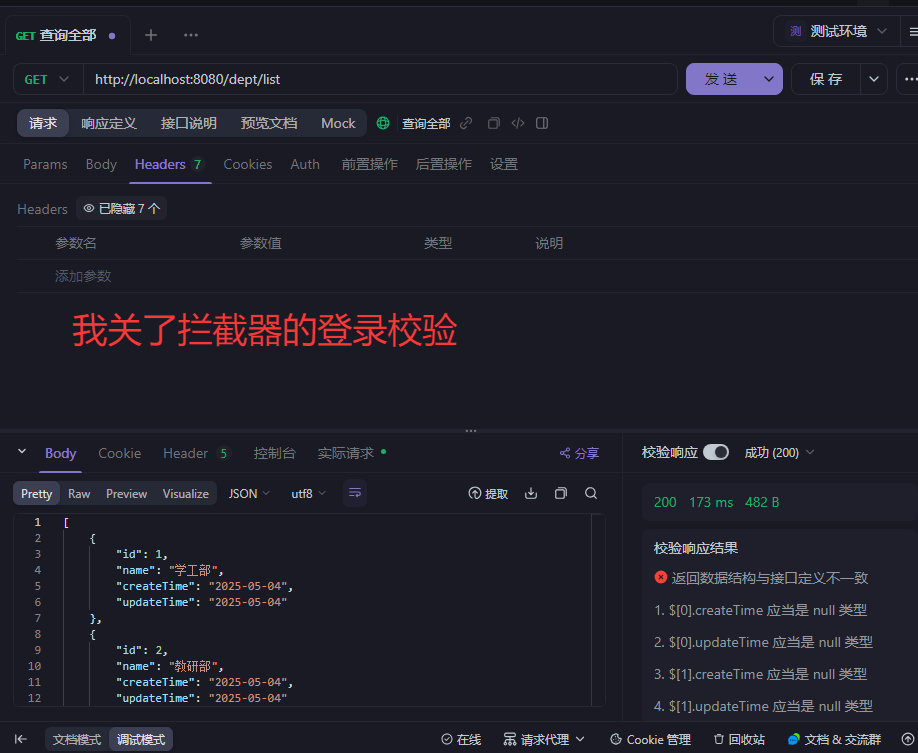
用apifox接口调用,不建议用test测试类因为,测试类只能检查你的三层架构的流程对不对但是没办法完全模拟前端调用请求的情况
注意你时间数据类型是什么
post请求记得加上headers

删除有两种写法
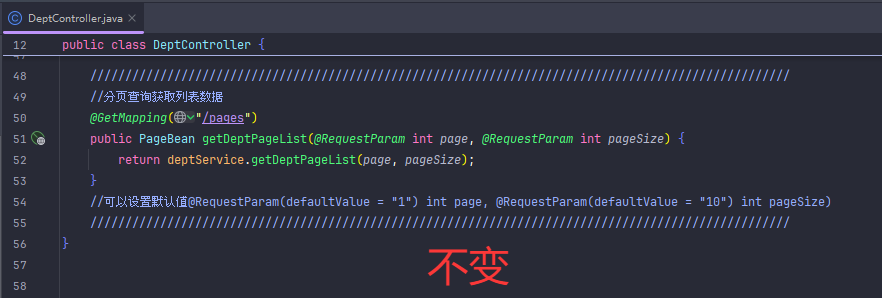
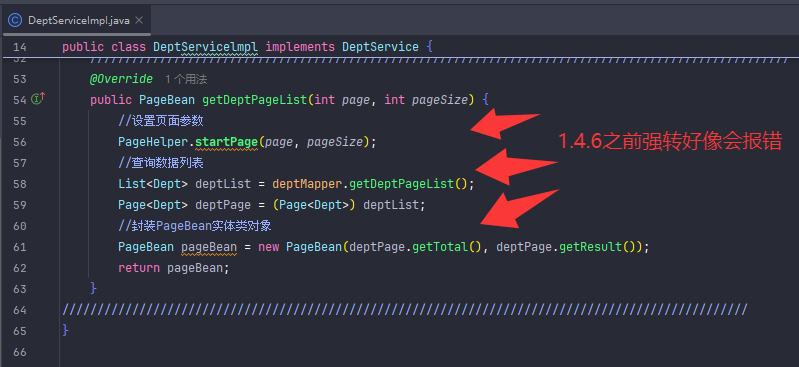
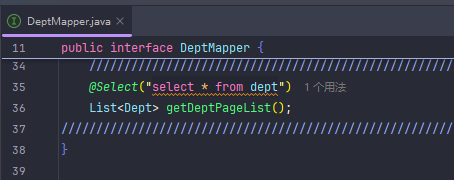
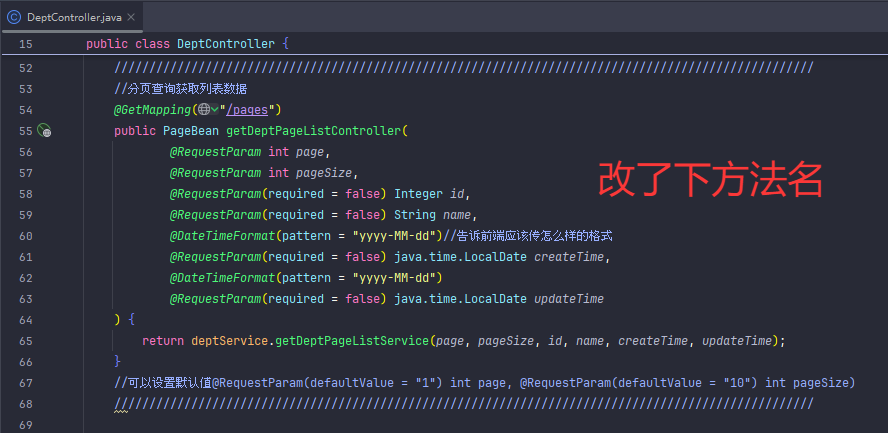
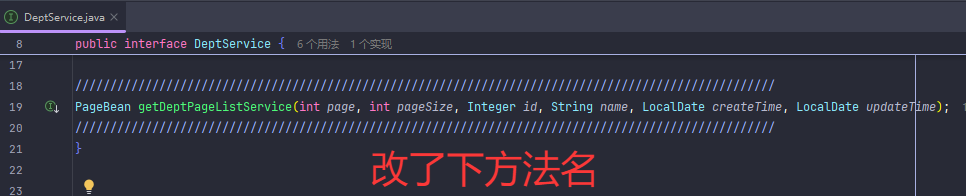
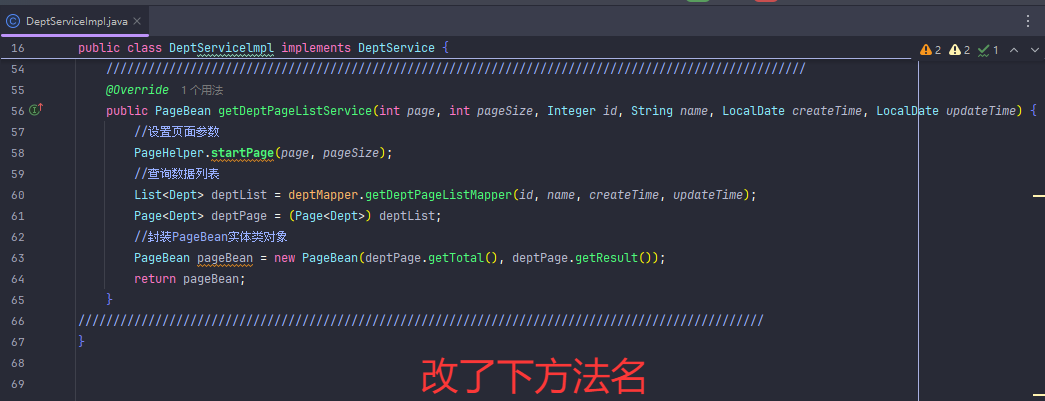
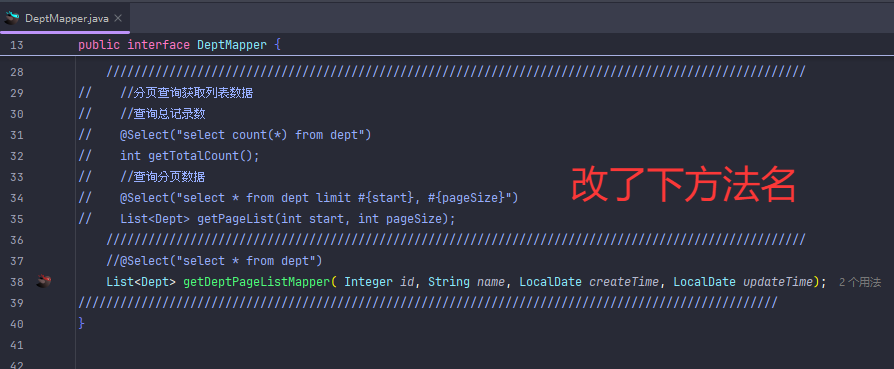
分页查询(传统版)
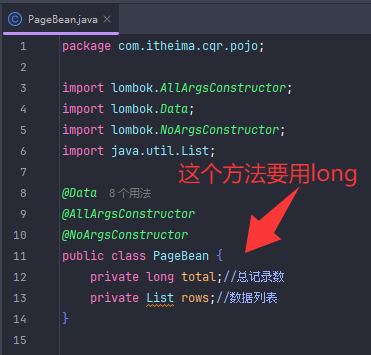
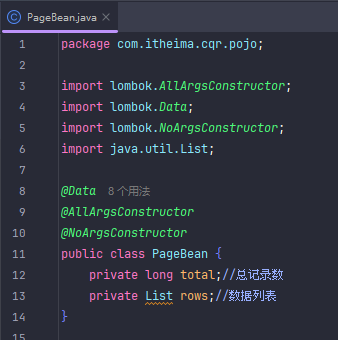
PageBean 是用来封装分页结果(如总数、数据列表),而不是用来接收分页请求参数(如 page、pageSize、student 条件)。

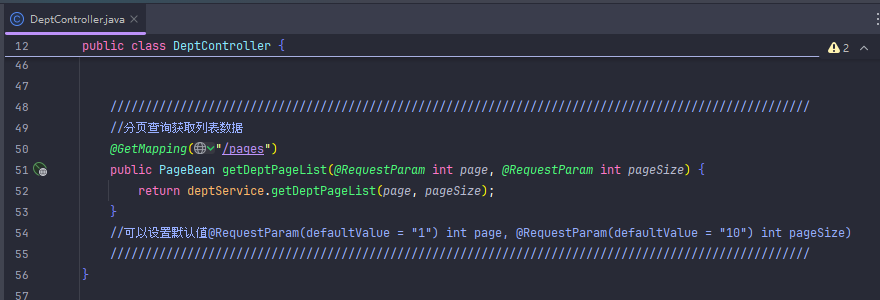
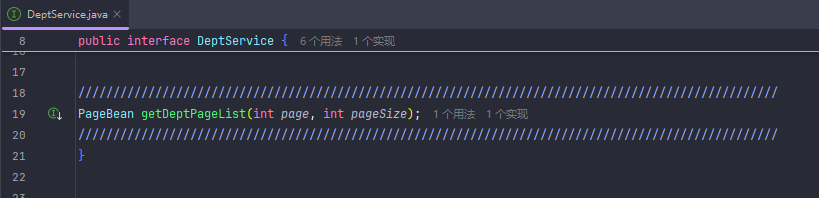
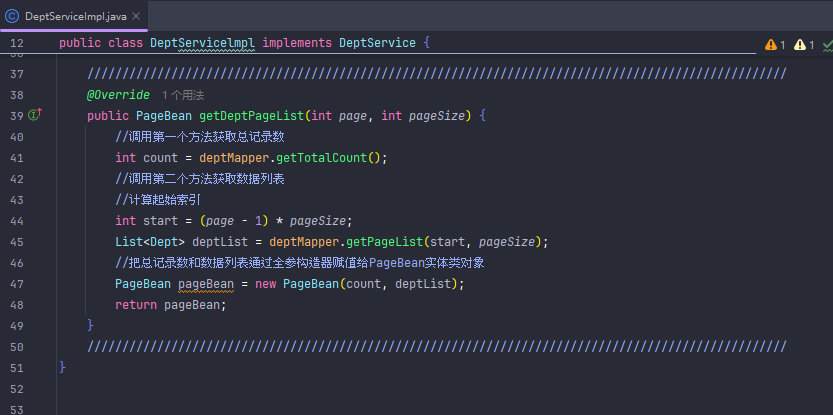

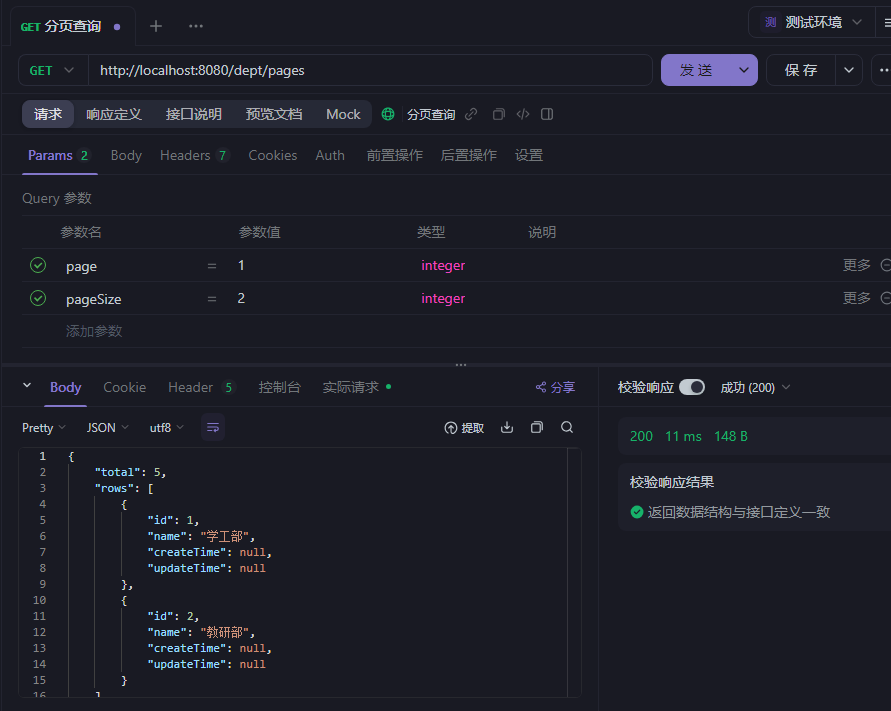
设置了默认值的情况

分页查询(说是防止代码冗余改良版,感觉没传统法好记)
条件查询
xml的配置文件是用来写动态sql语句的,比如条件查询
条件查询和分页查询写一起
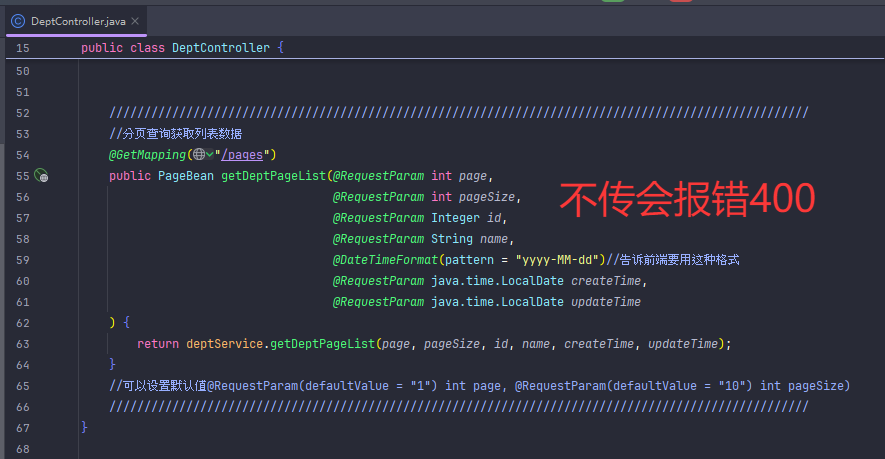
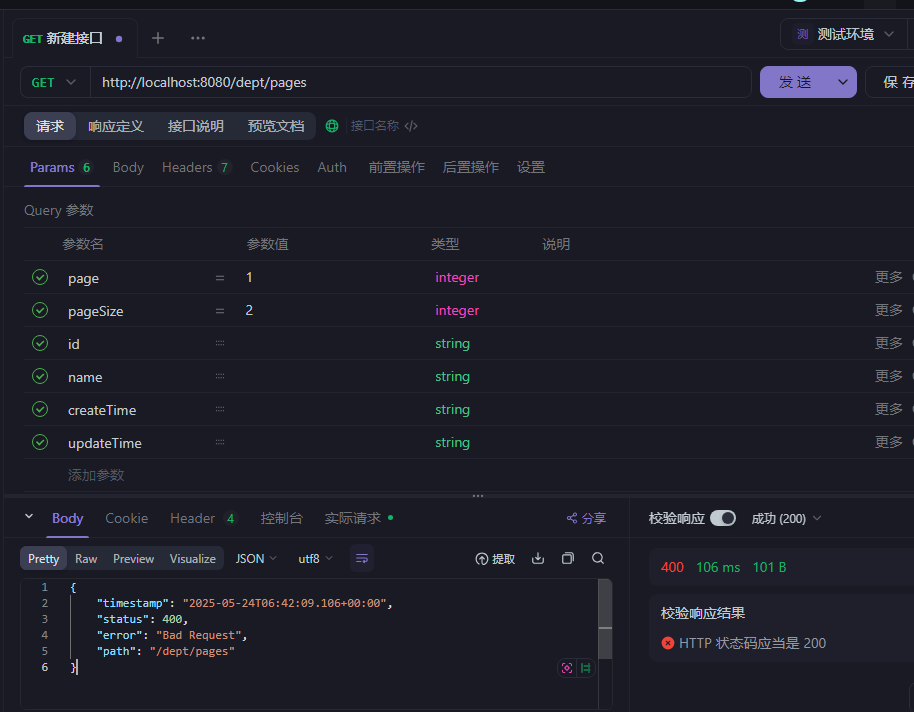
400错误根源:原代码强制要求所有参数必传(如int id会强制要求传值,且不能为null)
@RequestParam 默认是 required = true,所以前端不传这些参数会报 400。需要加上 required = false,这样参数才可以不传,默认为空。
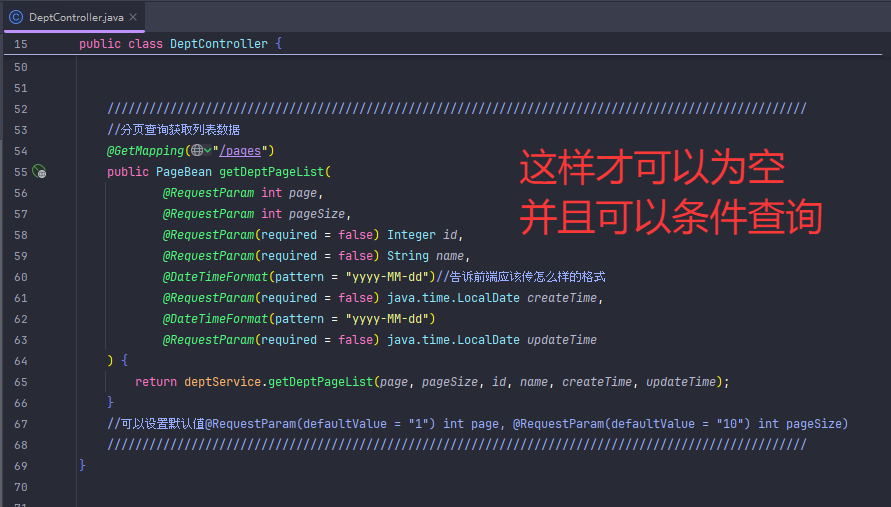
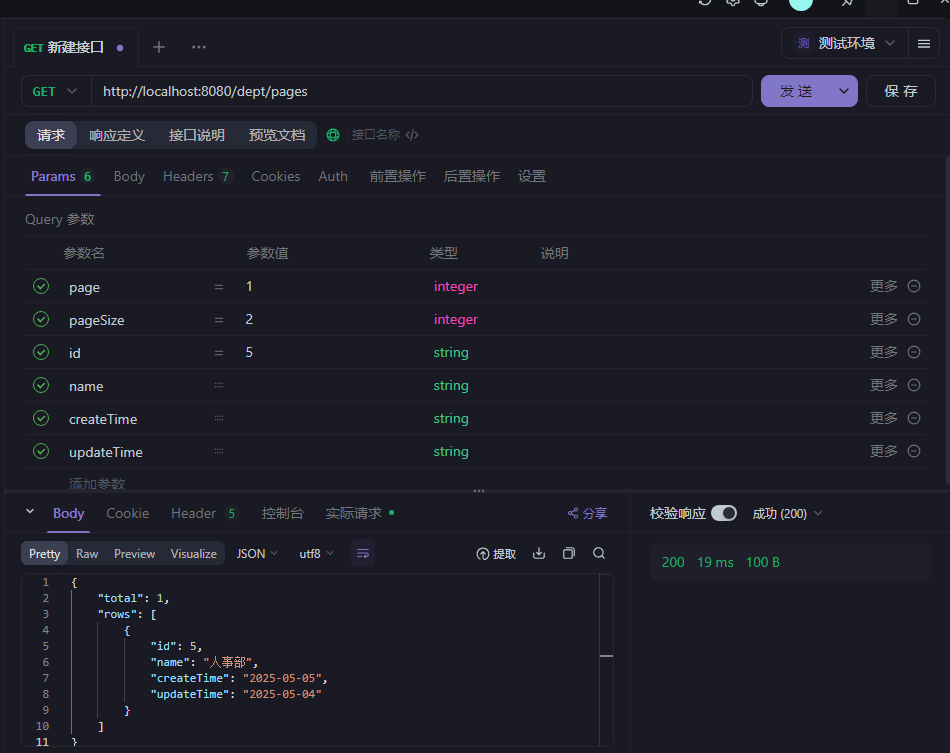

以下是完整条件查询+分页查询
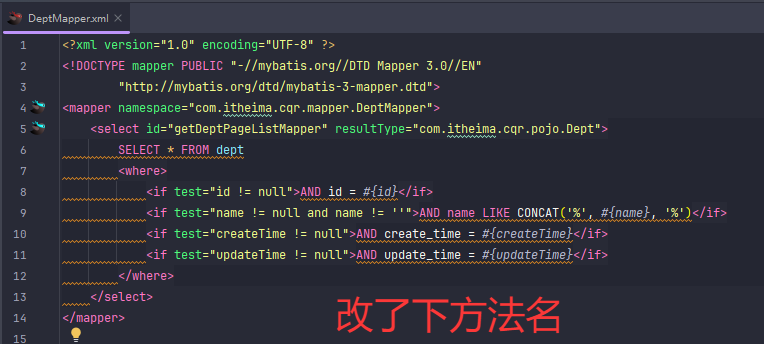
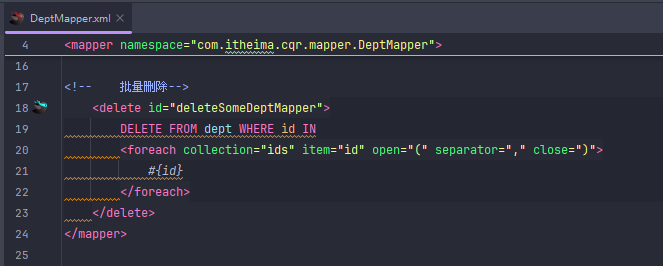
批量删除

MyBatis 的 <foreach> 标签,用于批量操作(如批量删除、批量插入)时动态生成 SQL 片段。 含义如下:
collection="ids":遍历传入的参数 ids(通常是一个 List<Integer>)。
item="id":每次遍历的元素命名为 id,可用 #{id} 取值。
open="(":生成 SQL 时以 ( 开头。
separator=",":每个元素之间用逗号分隔。
close=")":以 ) 结尾。
最终效果: 如果 ids=[1,2,3],生成 SQL 片段为 (#{id1},#{id2},#{id3}),实际参数为 (1,2,3)。 常用于 WHERE id IN (...) 这种批量操作。

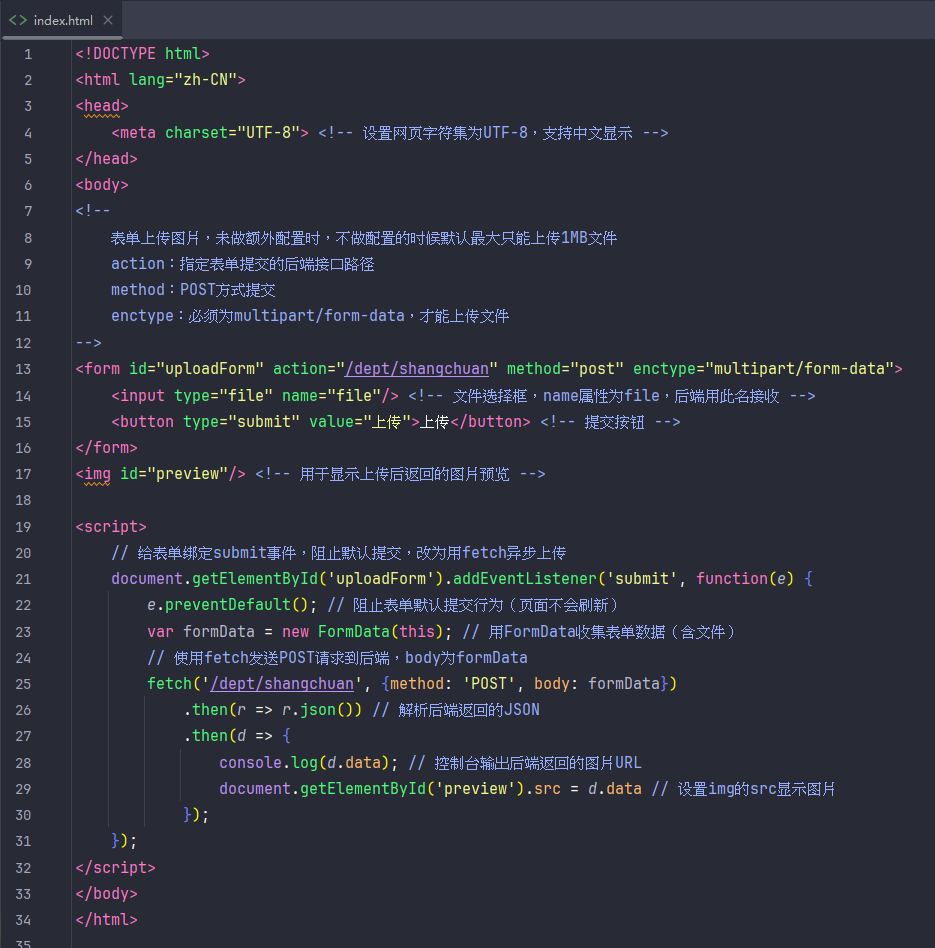
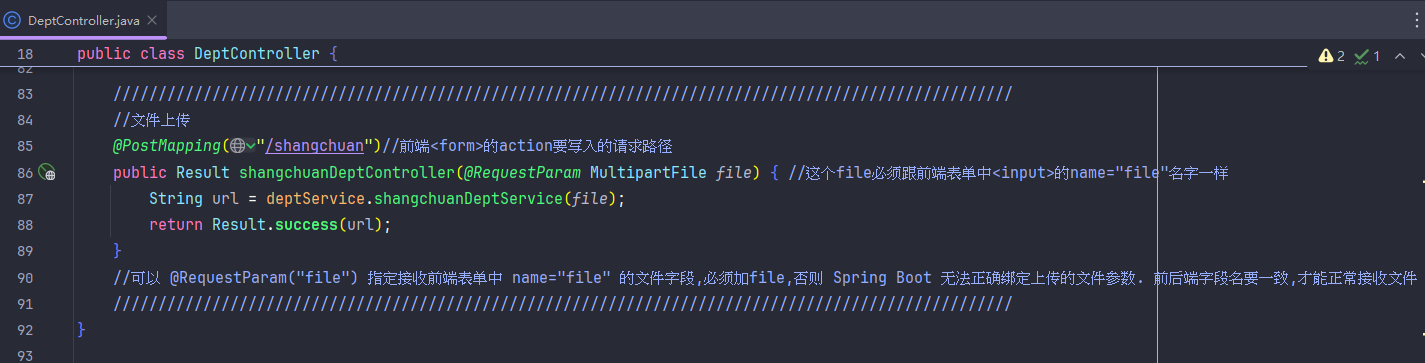
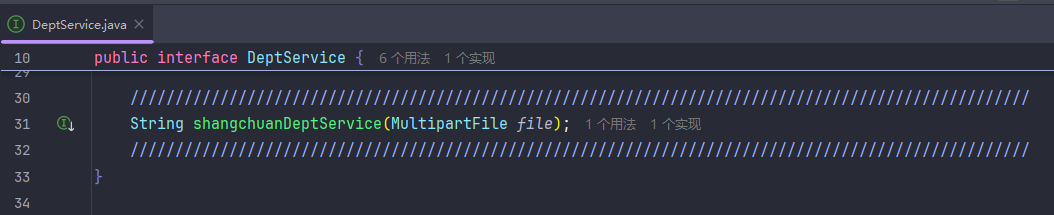
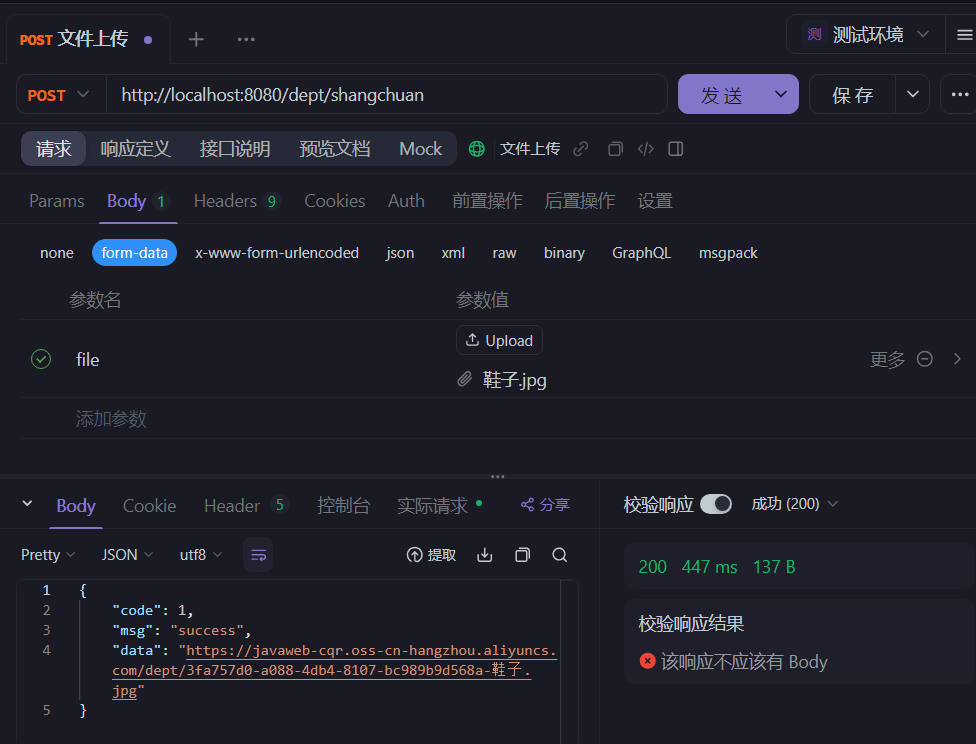
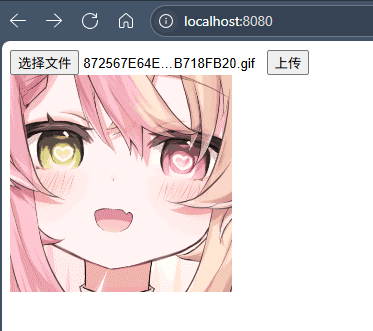
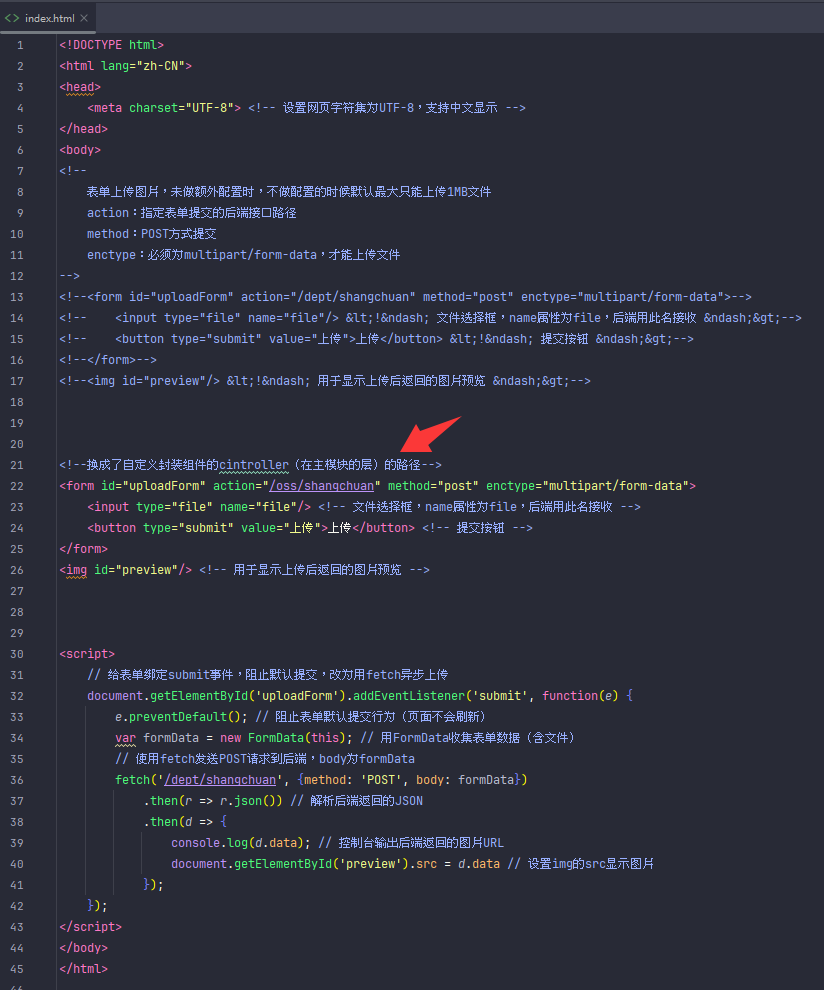
文件上传(本地上传)
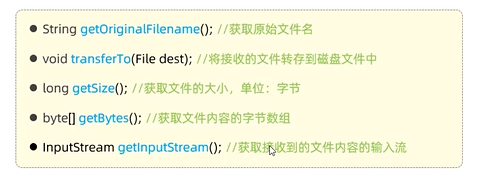
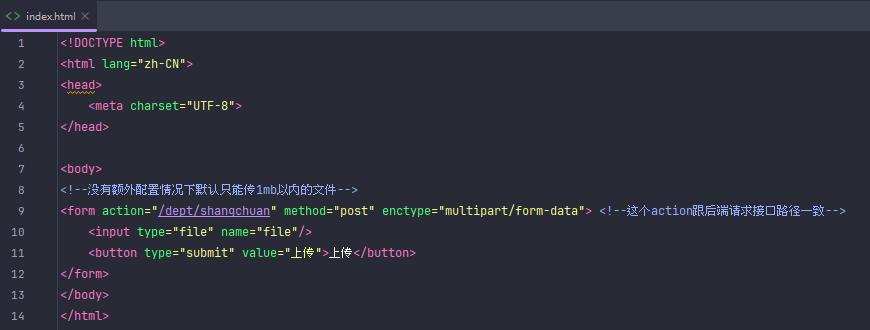
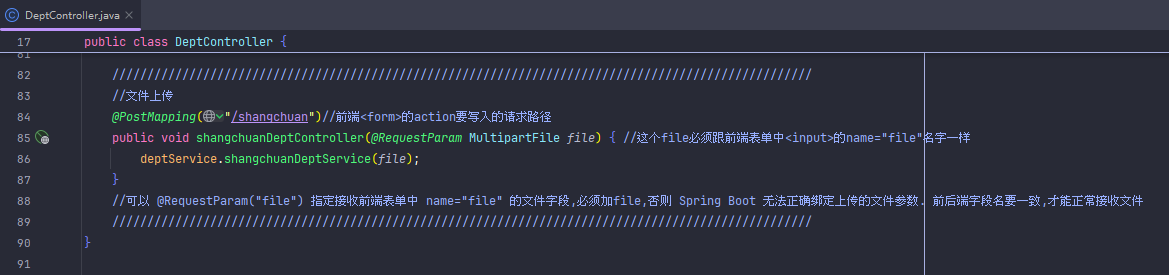
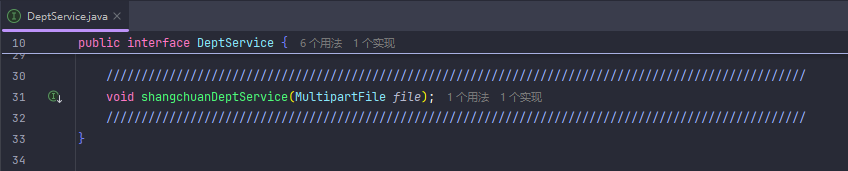

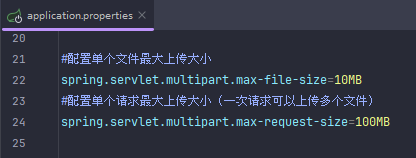
这个可以解决默认文件大小1mb的问题
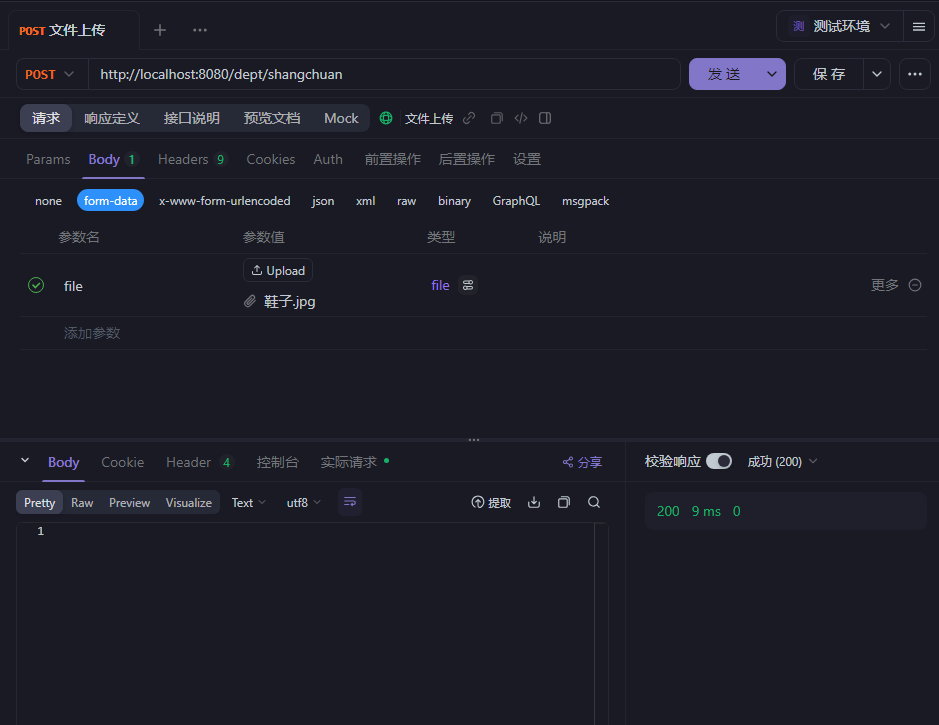
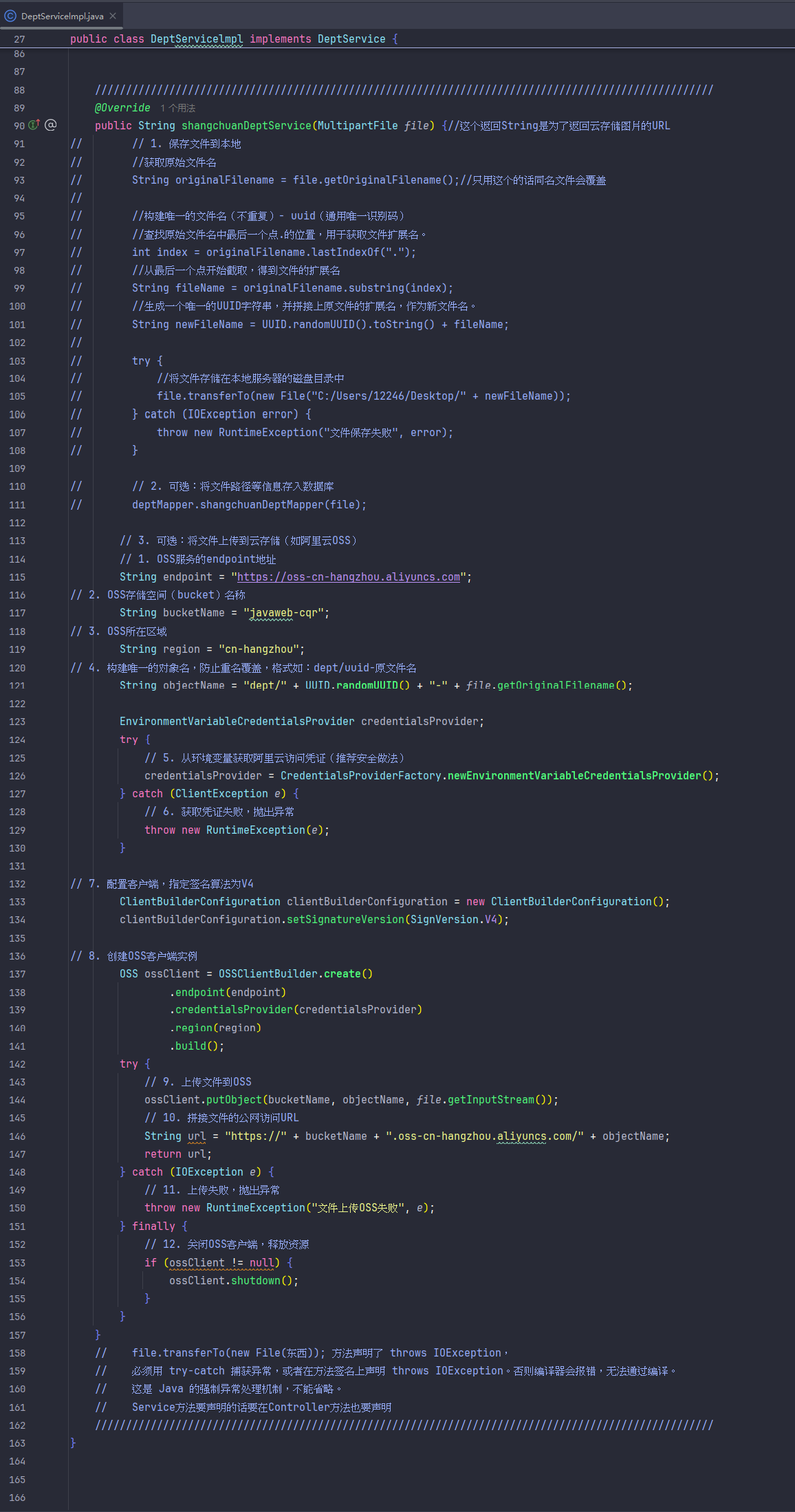
除了传进数据库还能传进云存储(如阿里云OSS)
首先要按照步骤开通然后搞好环境安装maven依赖,用示例代码的话会每传一个文件就创建一个bucket,传一次实验一下能不能传就行,等几秒估计就传好了
Service层是数据处理逻辑处理用的所以放那里
如果前端用 fetch 或 axios 发送请求,且默认把响应当作 JSON 解析,而直接返回字符串(URL)的话,前端会报 “Unexpected token 'h'...” 的错误。
推荐做法: 让后端返回 JSON 格式,前后端更通用、健壮。比如:加个工具类Result
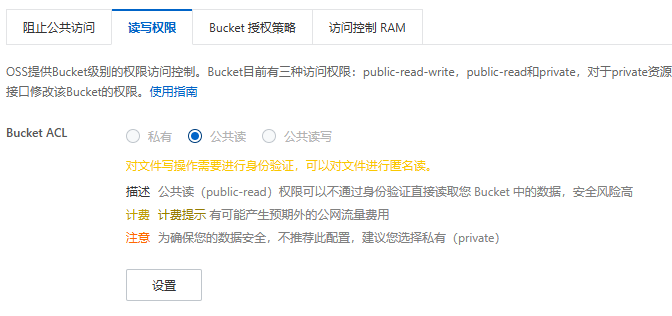
如果你得到的url链接在浏览器打开是这样的,说明你的阿里云oss的ducker读写权限弄了私有,要改成公共读


以下是完整第三种文件上传方法-云存储
因为前端需要所以先创个工具类封装请求响应的数据
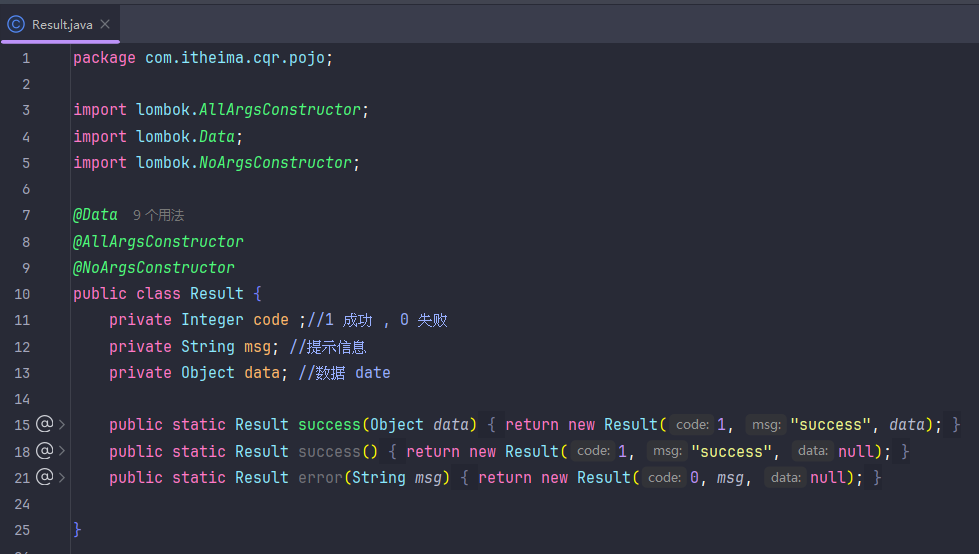

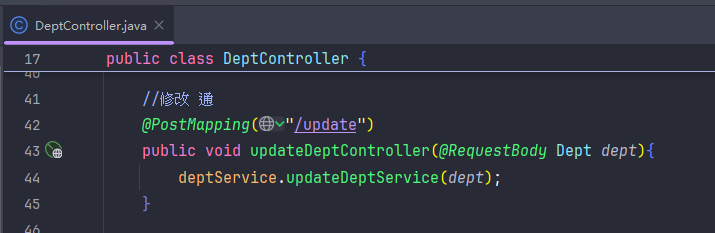
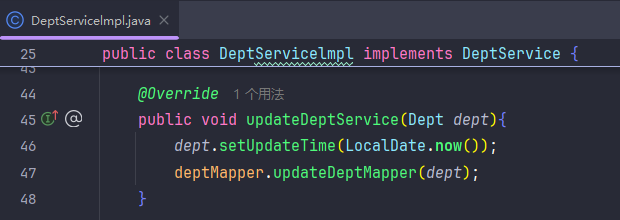
把修改变成动态修改


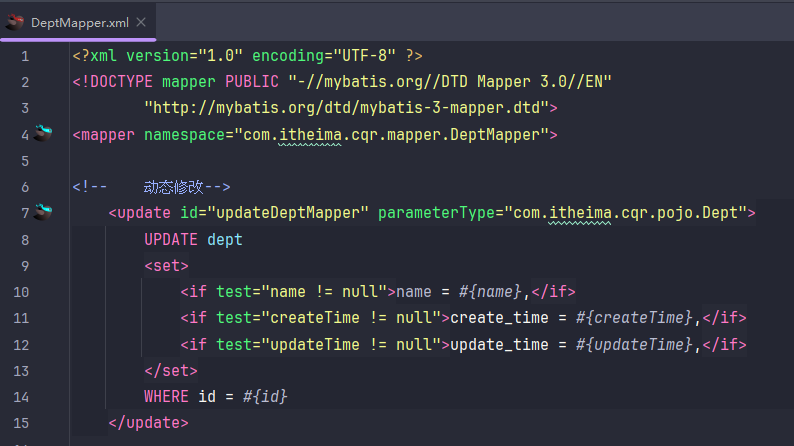
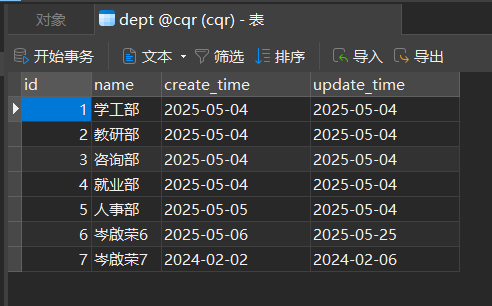
配置文件转换(application.properties转换成application.yml)

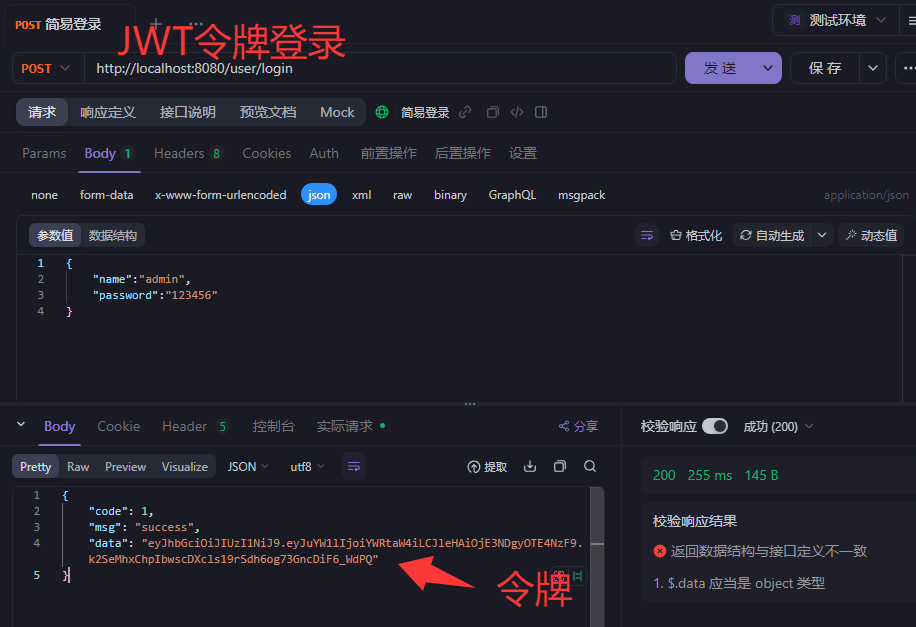
简易登录
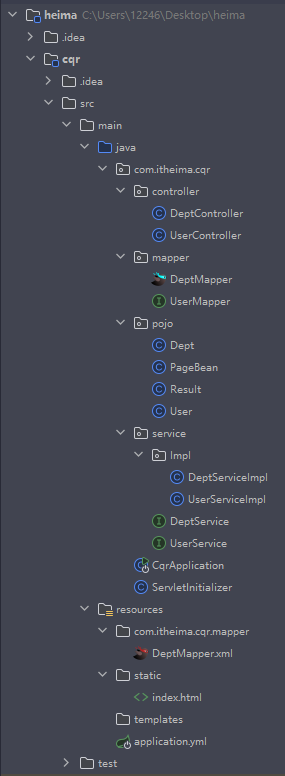
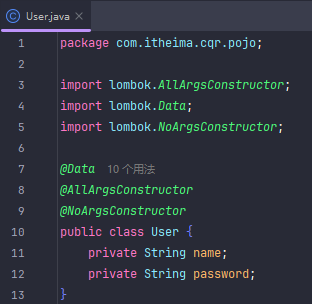
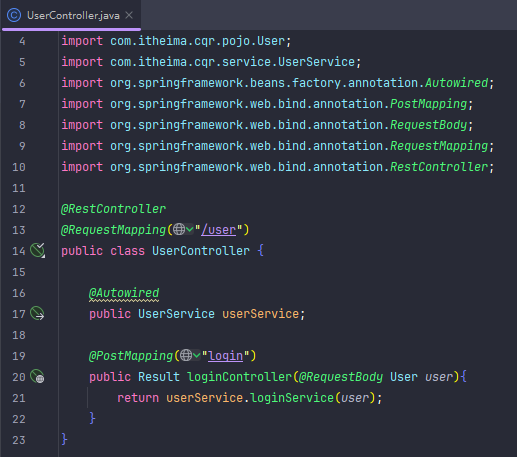
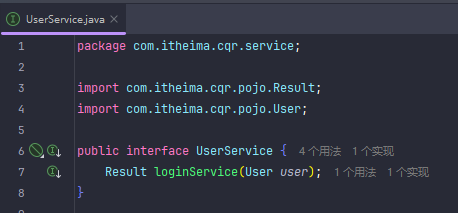
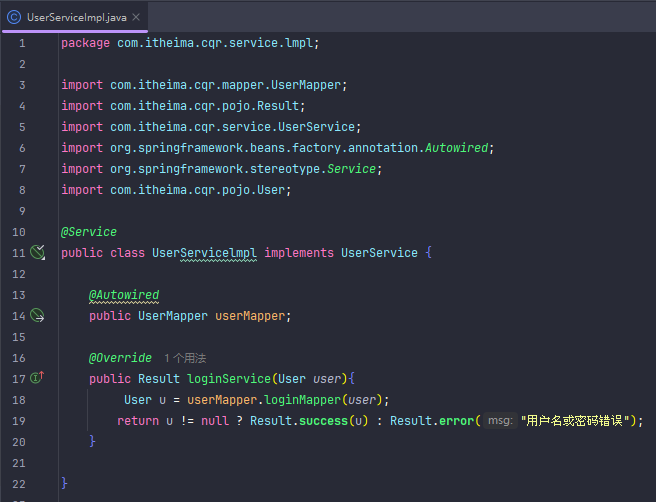

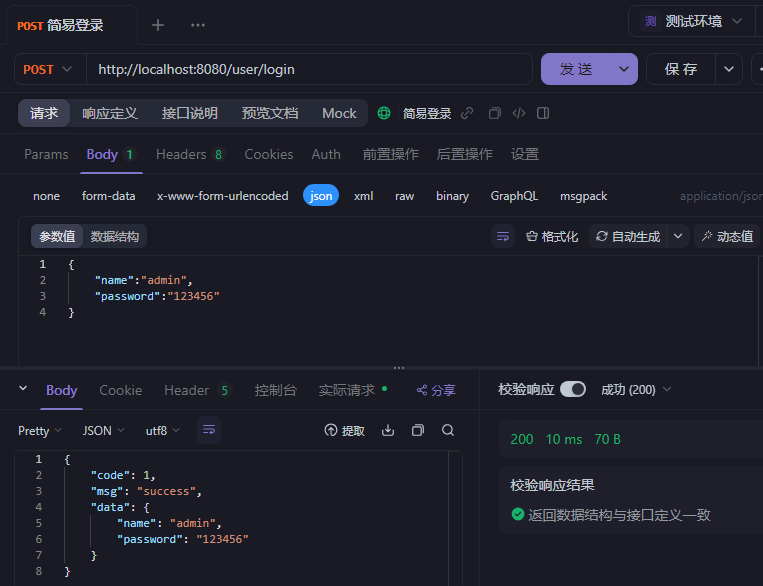
JWT令牌登录
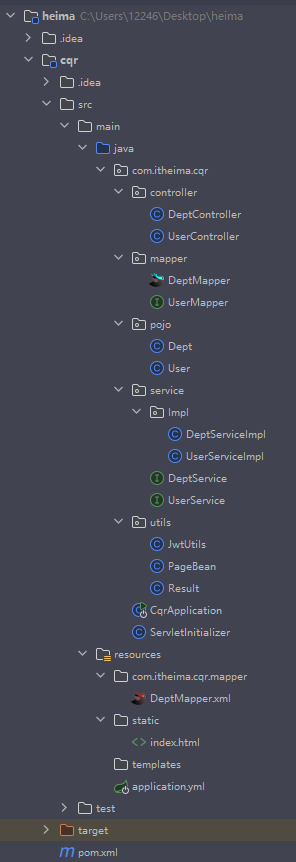
先后端生成Token并响应,现在项目结构长这样,把工具转移到utils,pojo专门放实体类
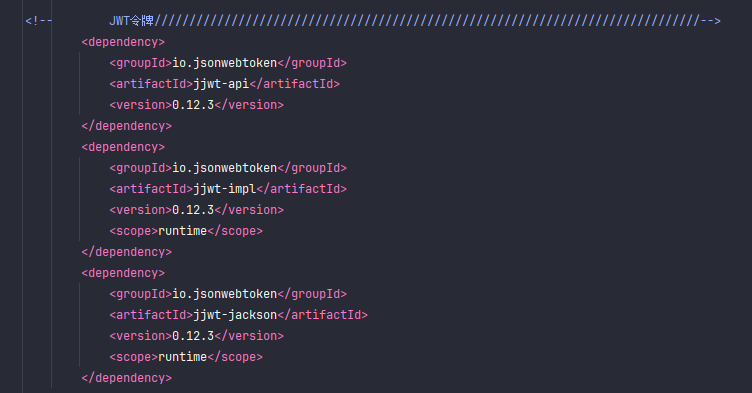

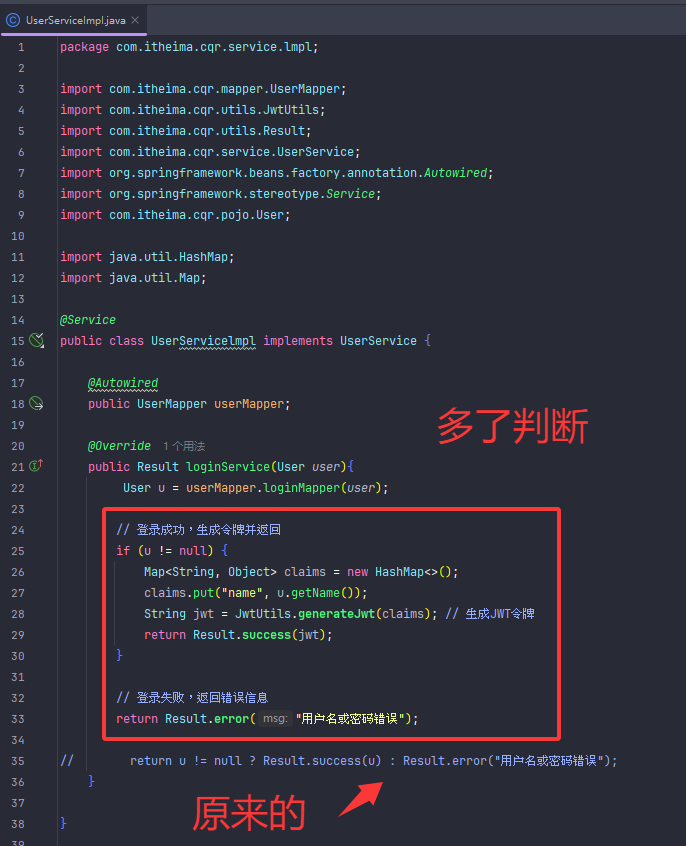
这是生成JWT令牌的工具
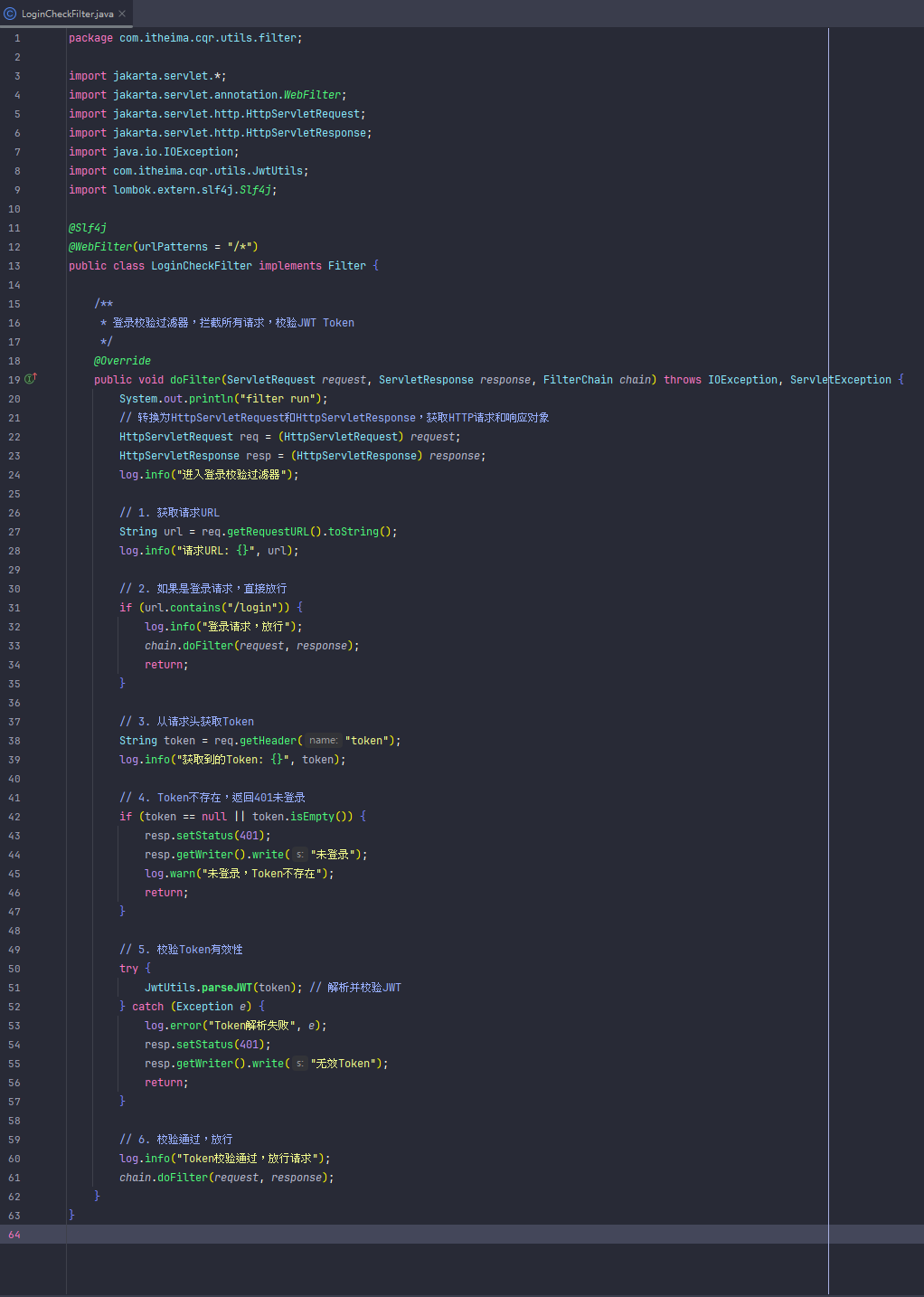
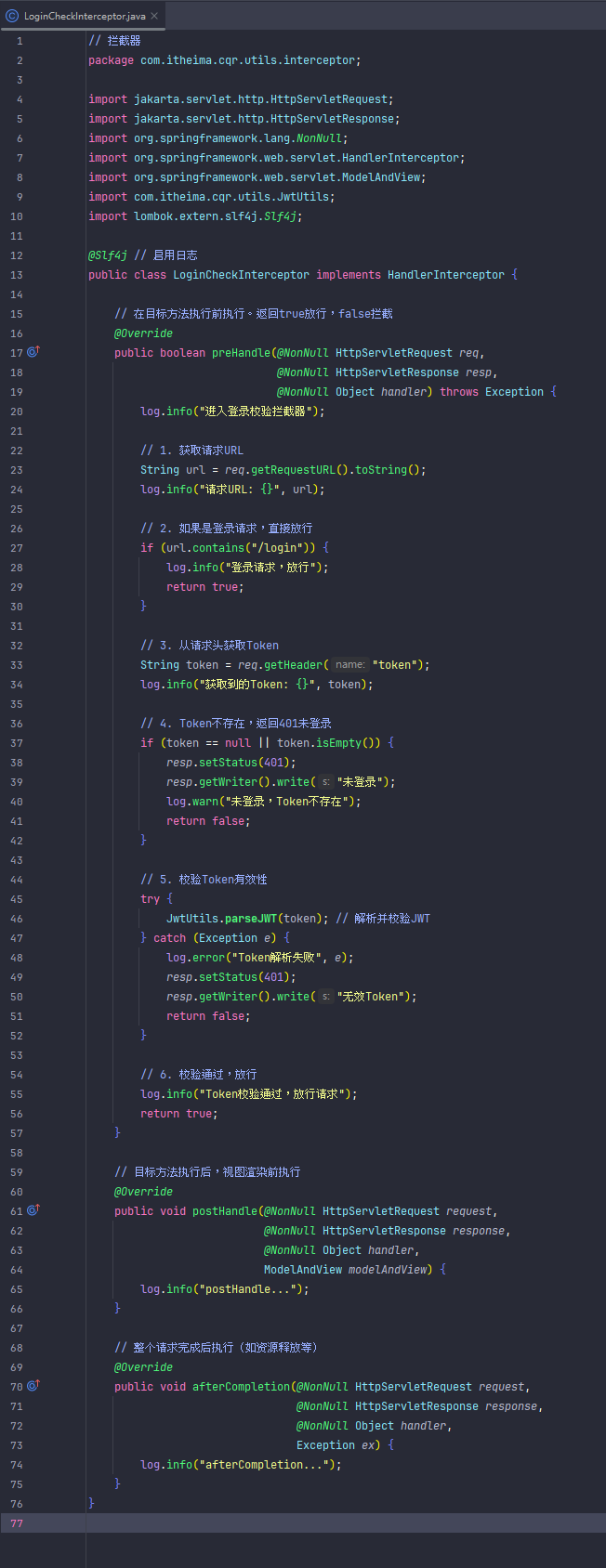
过滤器(记得引入的类是属于javax.servlet的)
登录校验过滤器的作用:(一般企业不用过滤器来做登录校验)
未登录(没有有效Token)时,除了登录接口,其他接口都无法访问。
登录成功后,前端拿到Token,后续请求都带上Token,过滤器校验通过才能访问其他资源。
这种方式适合大多数需要登录认证的系统。只要保证前端每次请求都带上Token,后端用过滤器校验即可实现“未登录不能访问资源,登录后才能访问”的效果。
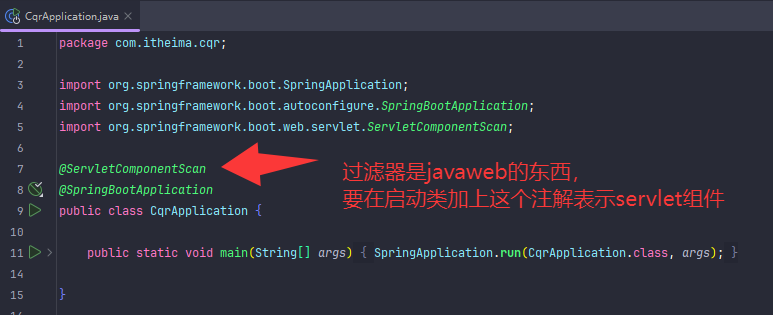
过滤器不生效,先去看看启动类有没有加注解,然后过滤器的引用不要用javax。
注意:所有相关 Servlet 类和注解都要用 jakarta.servlet 包! <hr></hr> Spring Boot 3.x 及以上版本已全面切换到 Jakarta EE(jakarta.*),否则 Filter 不会被扫描和注册。
以下是完整登录校验过滤器



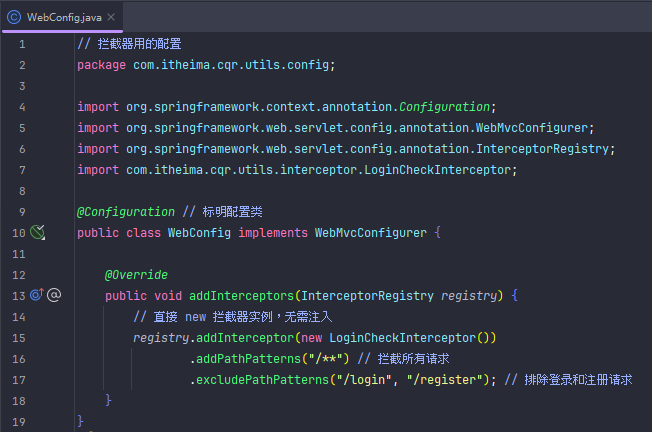
拦截器(感觉作用一样就没搞(但是实际上并不一样))
拦截器 vs 过滤器在登录校验中的核心差异(一般公司企业用拦截器做登录校验)
| 对比维度 | 过滤器(Filter) | 拦截器(Interceptor) |
|---|---|---|
| 技术栈支持 | 原生 Servlet 规范,与 Spring 解耦 | Spring 生态原生支持,深度集成 MVC 生命周期 |
| 依赖注入 | 需手动获取 Bean(如通过工具类) | 直接支持 @Autowired 注入 Service/组件 |
| 执行时机 | 在 Servlet 之前执行(过早,无法利用 Spring 上下文) | 在 Controller 方法前后执行(可获取完整上下文) |
| 细粒度控制 | 仅能基于 URL 匹配 | 可基于注解、方法签名、参数等灵活控制 |
| 异常处理 | 需自行处理异常和响应格式 | 可结合 @RestControllerAdvice 统一异常处理 |
核心区别与选型建议
| 维度 | 过滤器(Filter) | 拦截器(Interceptor) |
|---|---|---|
| 规范层级 | Servlet 规范(JavaEE 标准) | Spring 框架实现 |
| 作用范围 | 所有 Web 请求(包括静态资源) | 仅 Spring MVC 管理的控制器请求 |
| 执行时机 | 在 Servlet 之前/后执行(更底层) | 在 Controller 方法前后执行(更靠近业务) |
| 依赖注入 | 不支持 Spring 依赖注入(需手动获取 Bean) | 支持完整的 Spring 依赖注入 |
| 典型场景 | 跨域处理、字符编码、全局日志、XSS 过滤 | 权限校验、参数预处理、审计日志、接口限流 |
选型原则:
✔️ 优先拦截器:当需要 Spring 上下文支持(如注入 Service)或仅需拦截业务接口时。
✔️ 必须过滤器:当需处理静态资源、需最早/最晚处理请求(如性能监控)时。
一般情况下
以下是完整的登录校验拦截器(跟上面过滤器的文件比多了拦截器和全局异常处理器,全局异常处理器是下一个内容utils/exception文件夹那个)(拦截器登录校验逻辑跟过滤器登录校验逻辑差不多)
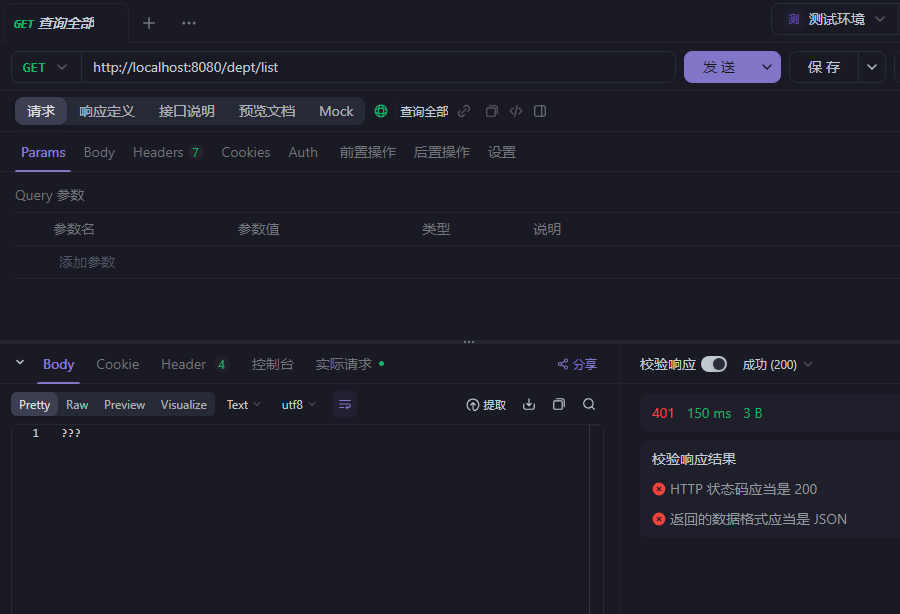
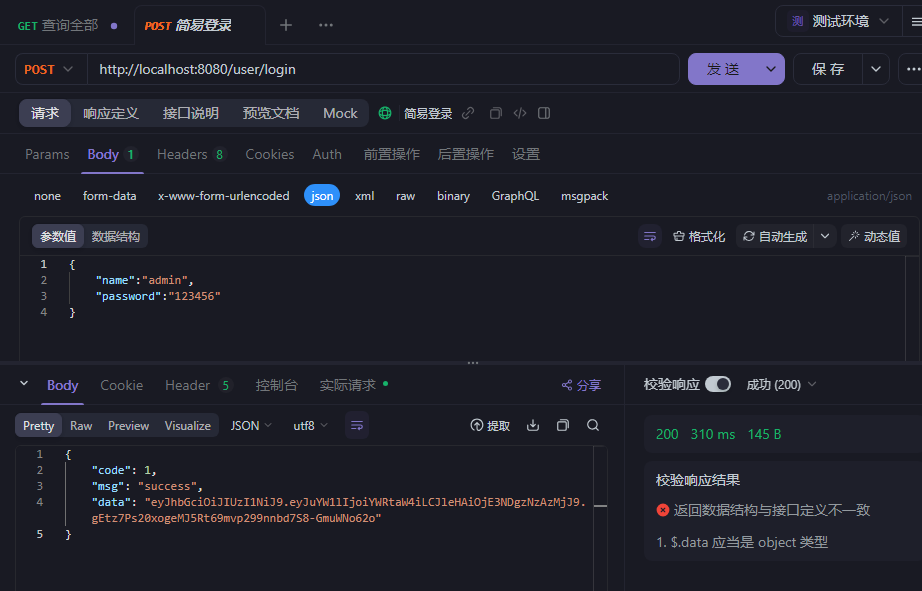
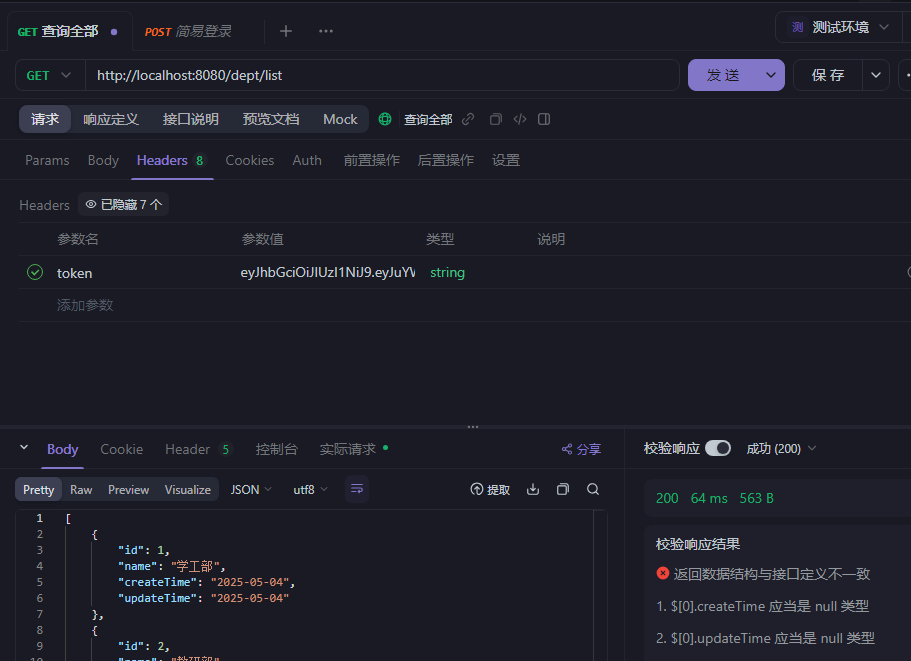
全局异常处理器(有些异常返回的不是json格式所以要统一格式)(上一个拦截器内容的项目文件里面就有全局异常处理器的文件夹位置utils/exception)
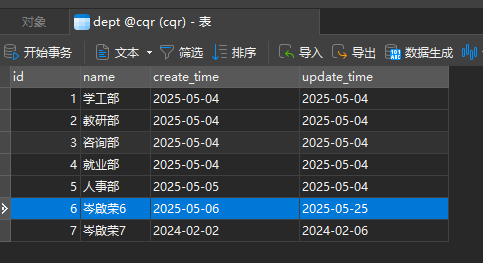
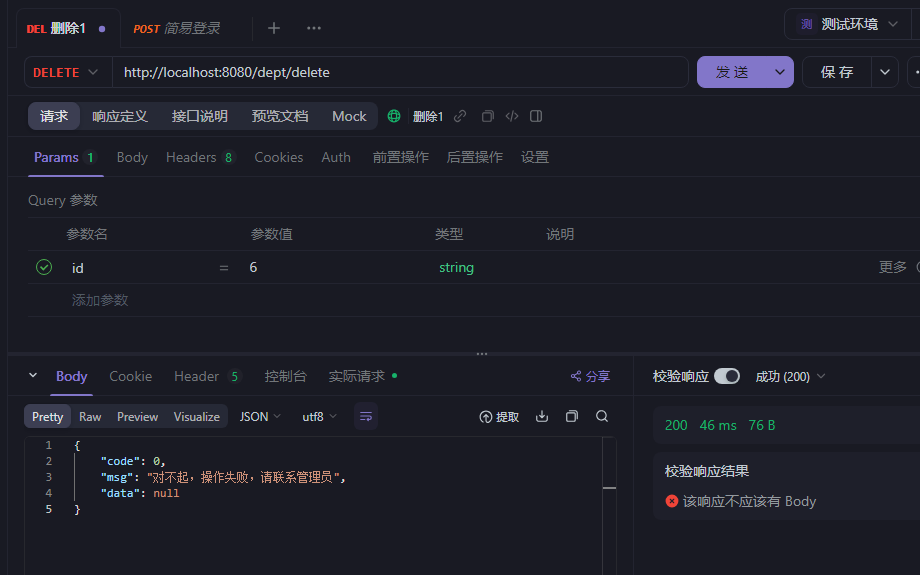
故意增加重复id的数据,返回报错统一格式
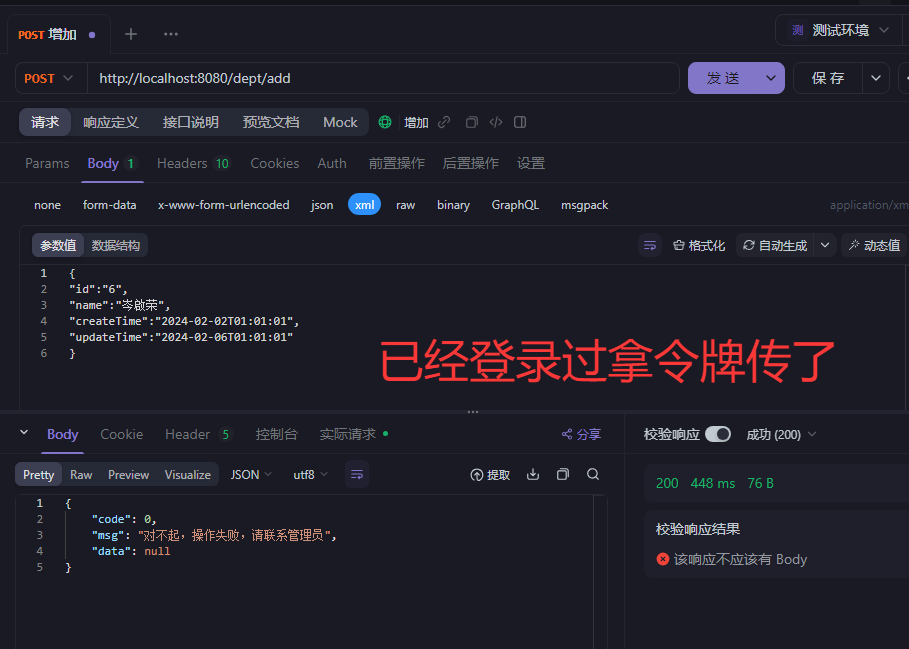
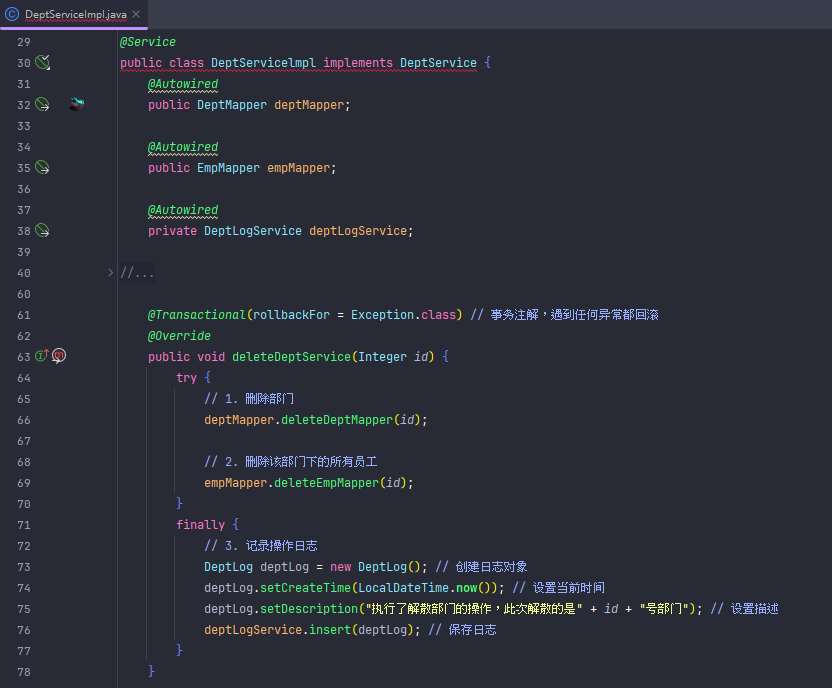
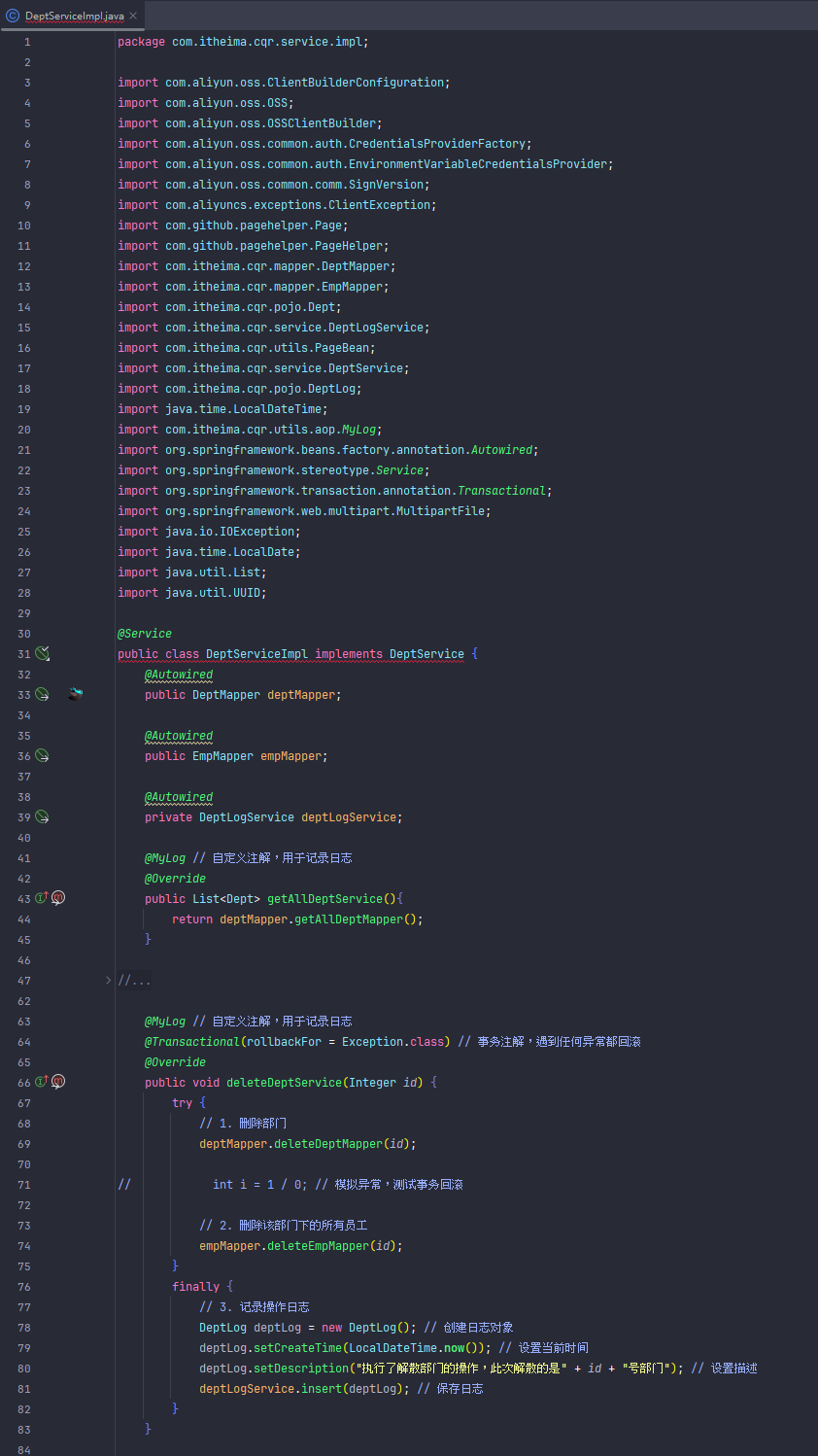
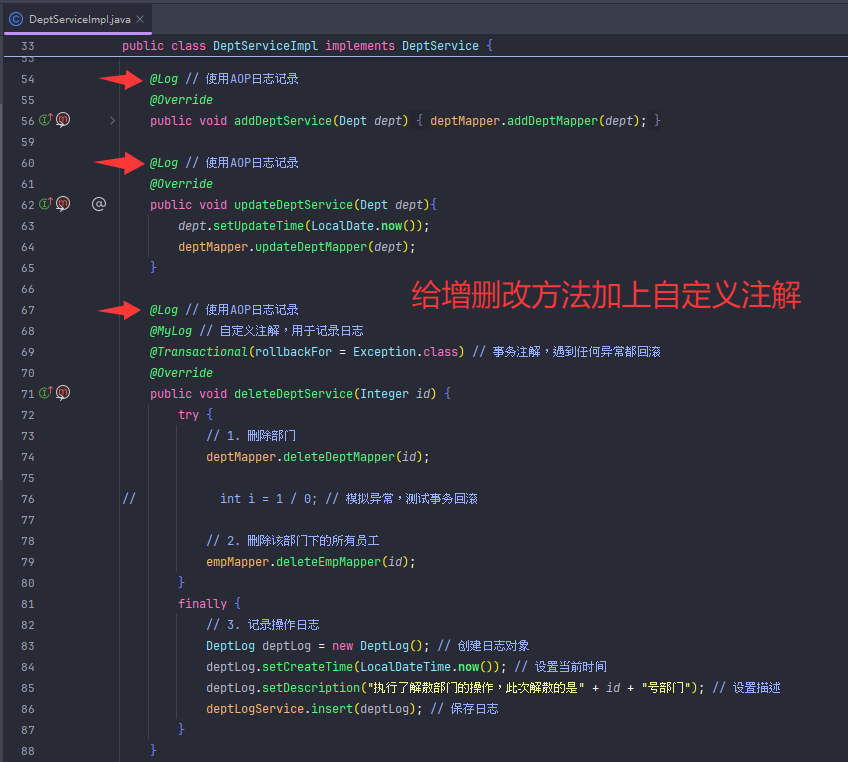
补充一个删除部门同时把部门员工一起删除的逻辑
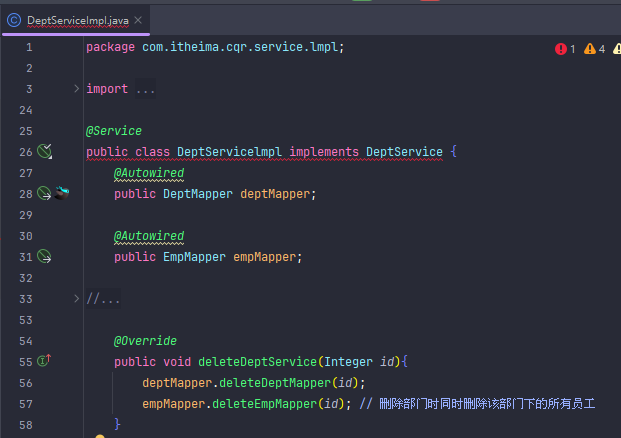
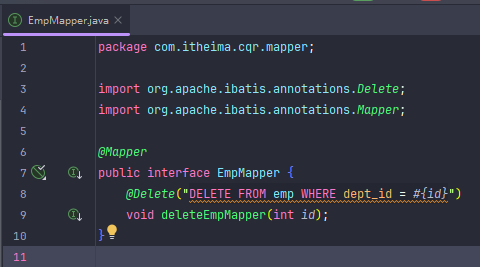
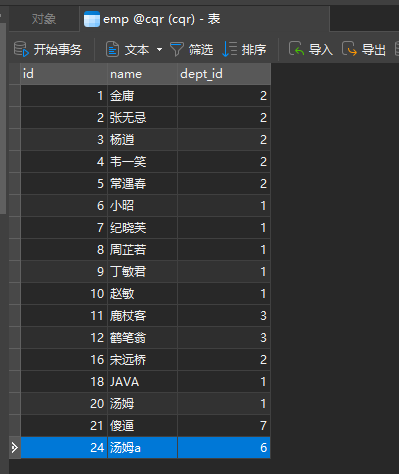
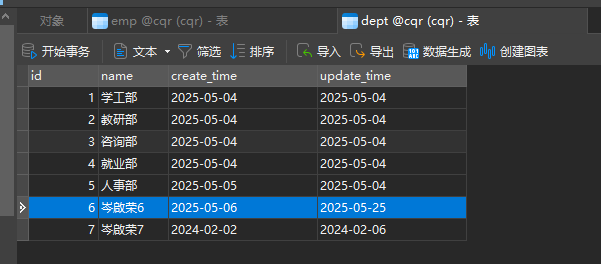

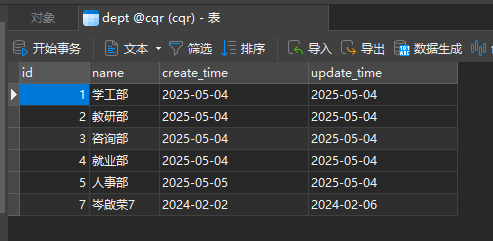
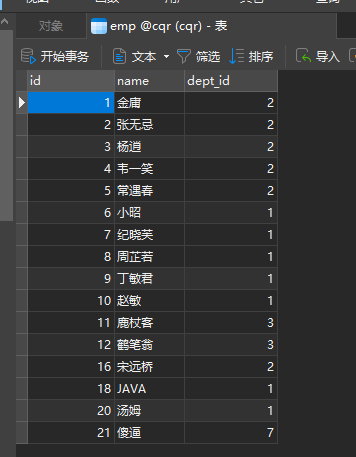
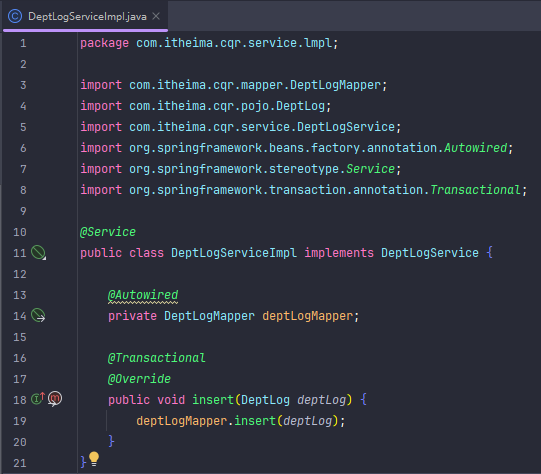
事务
接下来用上面那个删除部门同时删除部门员工的service层的方法来搞事务
事务回滚之后方法内的所有操作都不会执行,即数据不会改变

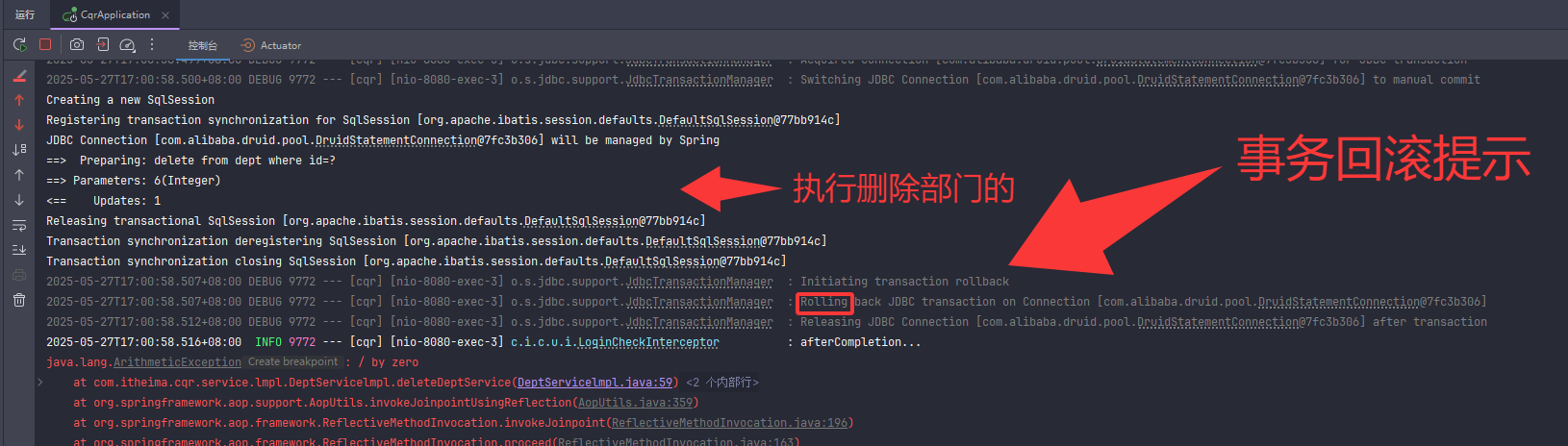
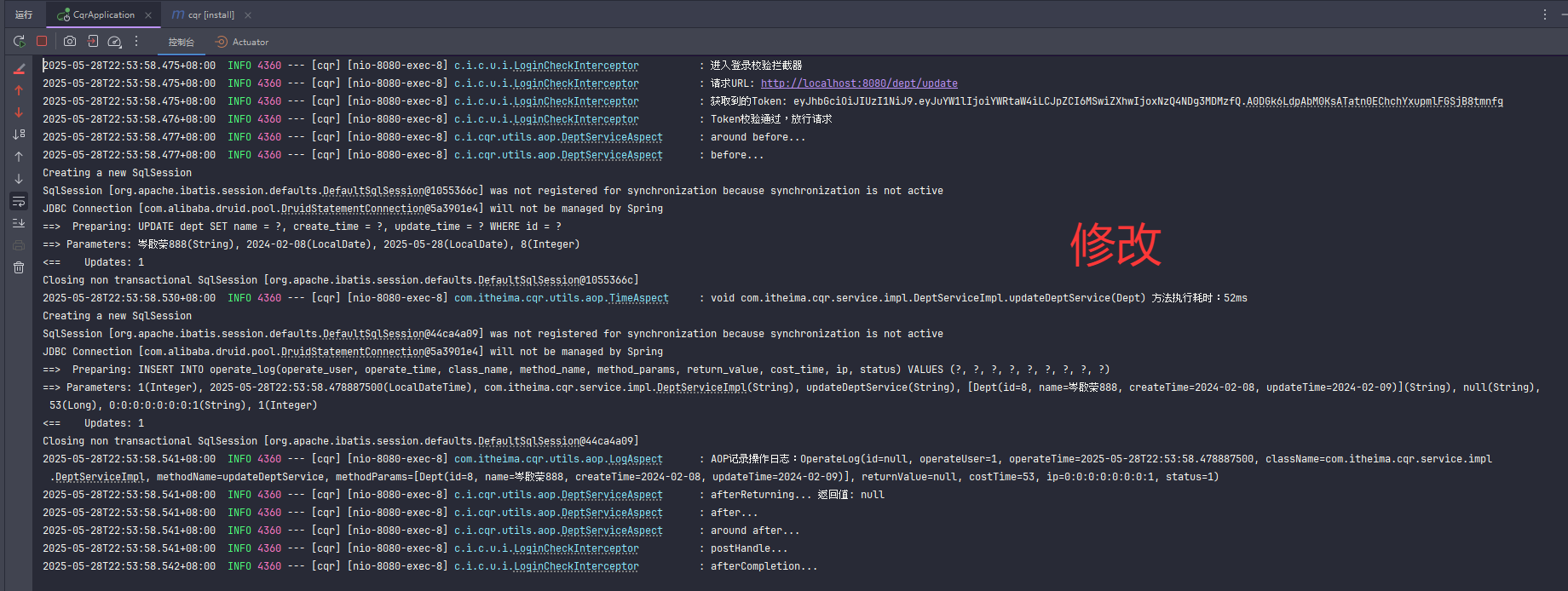
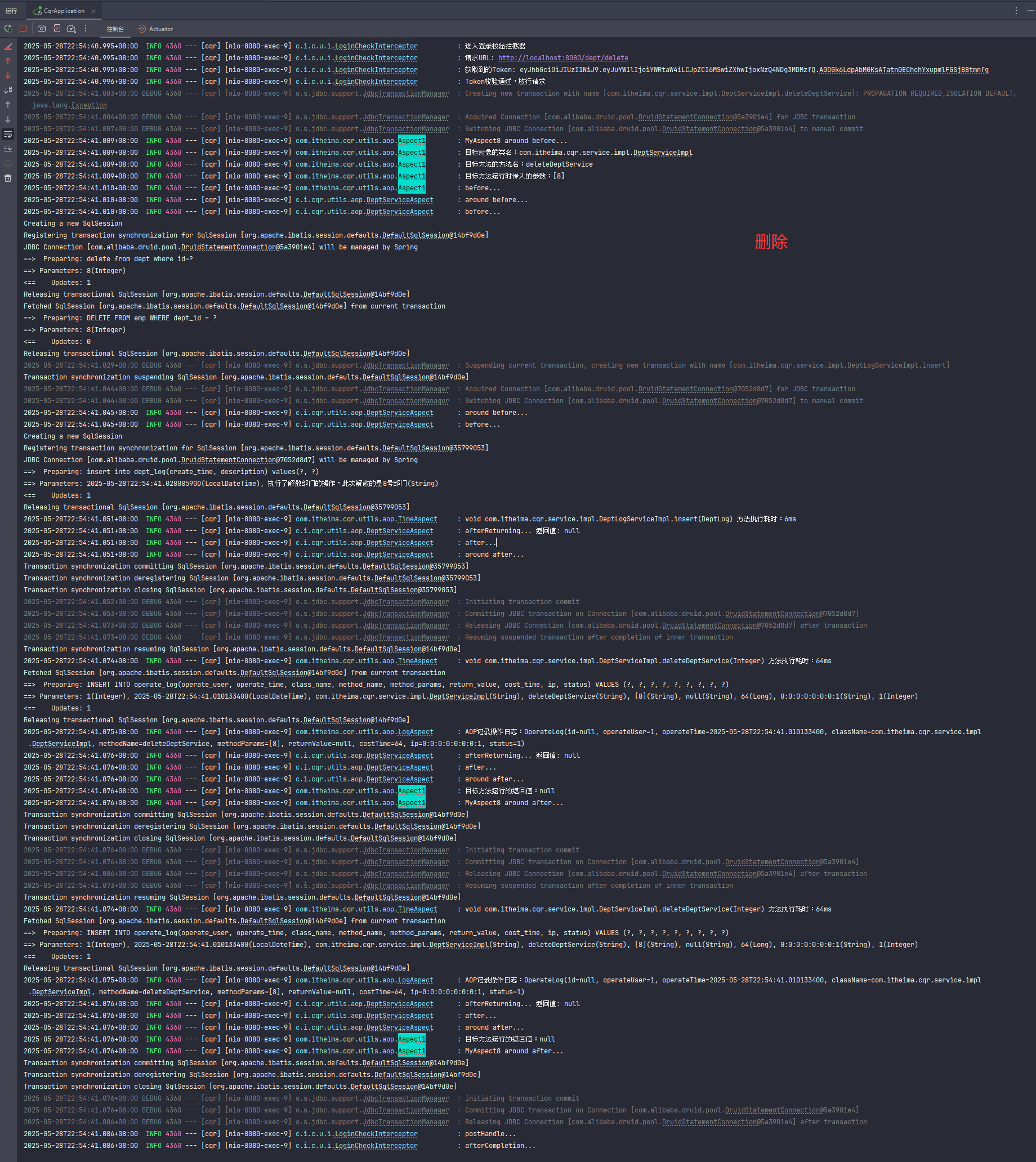
事务传播(一个事务里面调用另一个事务)(比如记录操作日志)
a方法调用b方法,a方法有事务,b方法也有事务,事务注解@Transactional的传播行为有默认属性值REQUIRED,表示需要事务,有则加入,无则创建新事务。在这种情况下a方法调用b方法,b方法会加入到a方法的事务,同时提交或同时回滚。若b方法改变事务注解传播行为的属性值为REQUIRES_NEW,表示需要新事务,无论有无都创建新事务。在这种情况下a方法调用b方法时,先挂起a事务,执行b事务,执行完b事务后再继续执行a事务,a事务回滚提交不影响b事务的回滚提交。
dept_log 表创建语句



左边是默认的,a方法有事务调用b方法情况下b方法不创建新事务,归入a方法事务,一起回滚一起提交。
右边是更换默认属性,b方法创建新事务,b事务回滚提交与a事务无关。
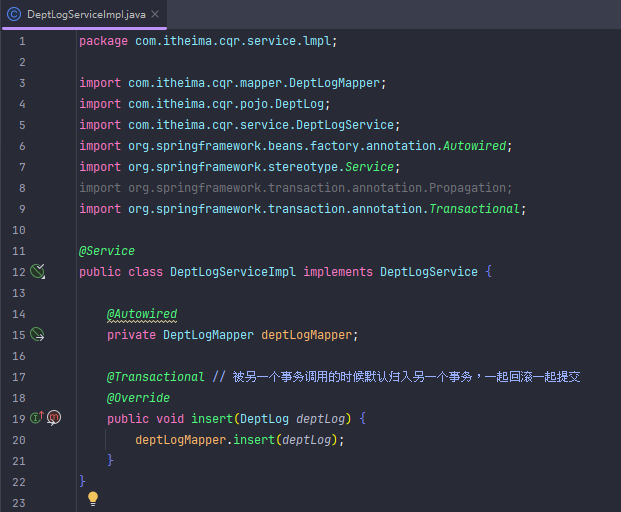
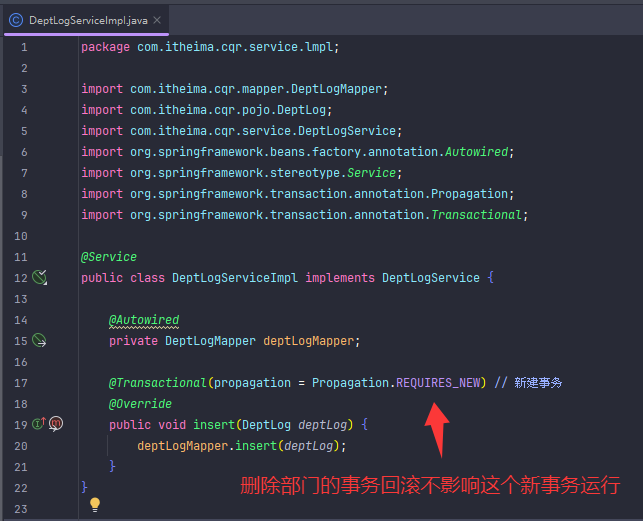
这是写在a方法的事务,调用b方法。

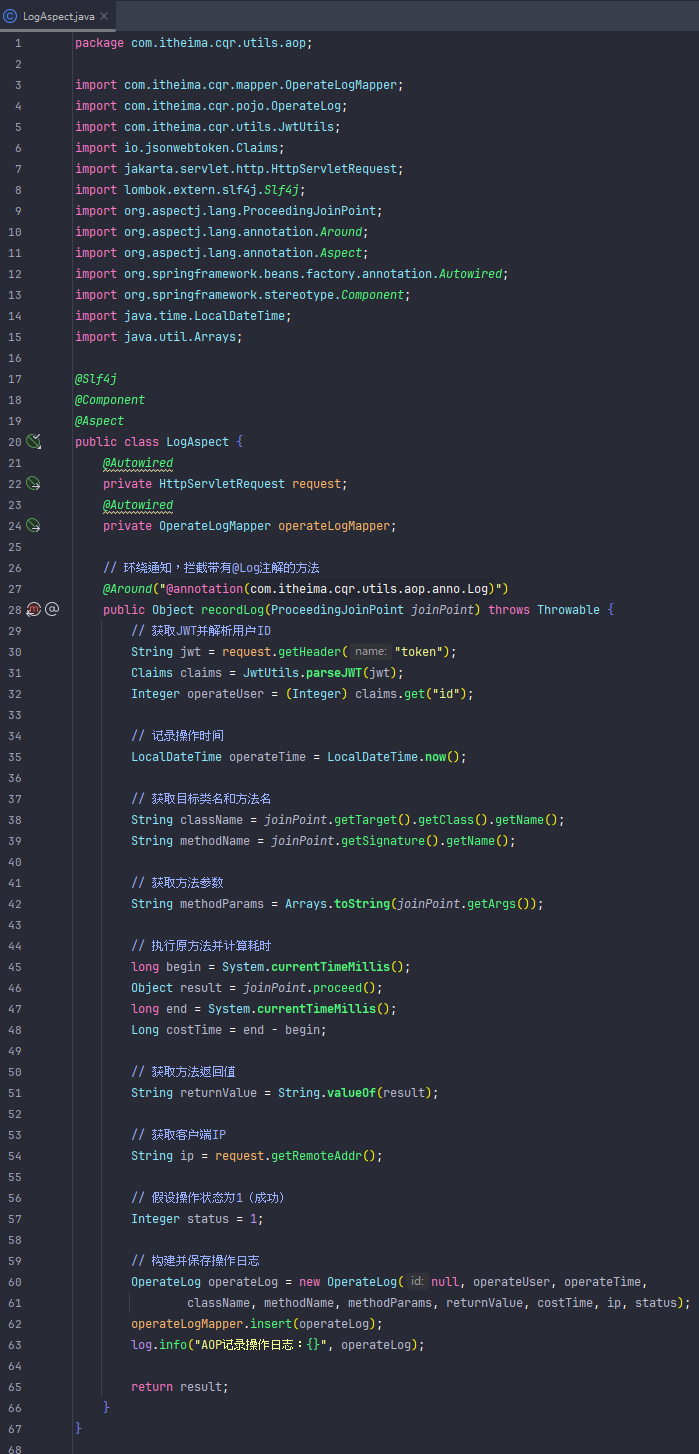
AOP
AOP(面向切面编程)是通过横向抽取与核心业务无关的公共功能(如日志、事务、权限),将其封装为可复用的切面,再通过动态代理织入目标对象的一种编程范式。
用大白话解释AOP:AOP就像给代码"加特效"——把那些每个方法都要写的重复代码(比如记日志、算耗时、检查权限)抽出来,做成一个"万能插件",自动给所有需要的方法批量加上这些功能。
举个生活例子:
- 核心业务:你每天的核心任务是"吃饭"
- 切面功能:但吃饭前要"洗手",吃完要"擦嘴"
- AOP做法:把洗手/擦嘴这些固定动作抽出来,以后只要说"吃饭",系统就自动给你加上前后步骤
关键好处:
- 核心代码更清爽(只关注吃饭)
- 改洗手步骤时,只需改一处
- 新加"刷牙"功能时,不用改原有方法
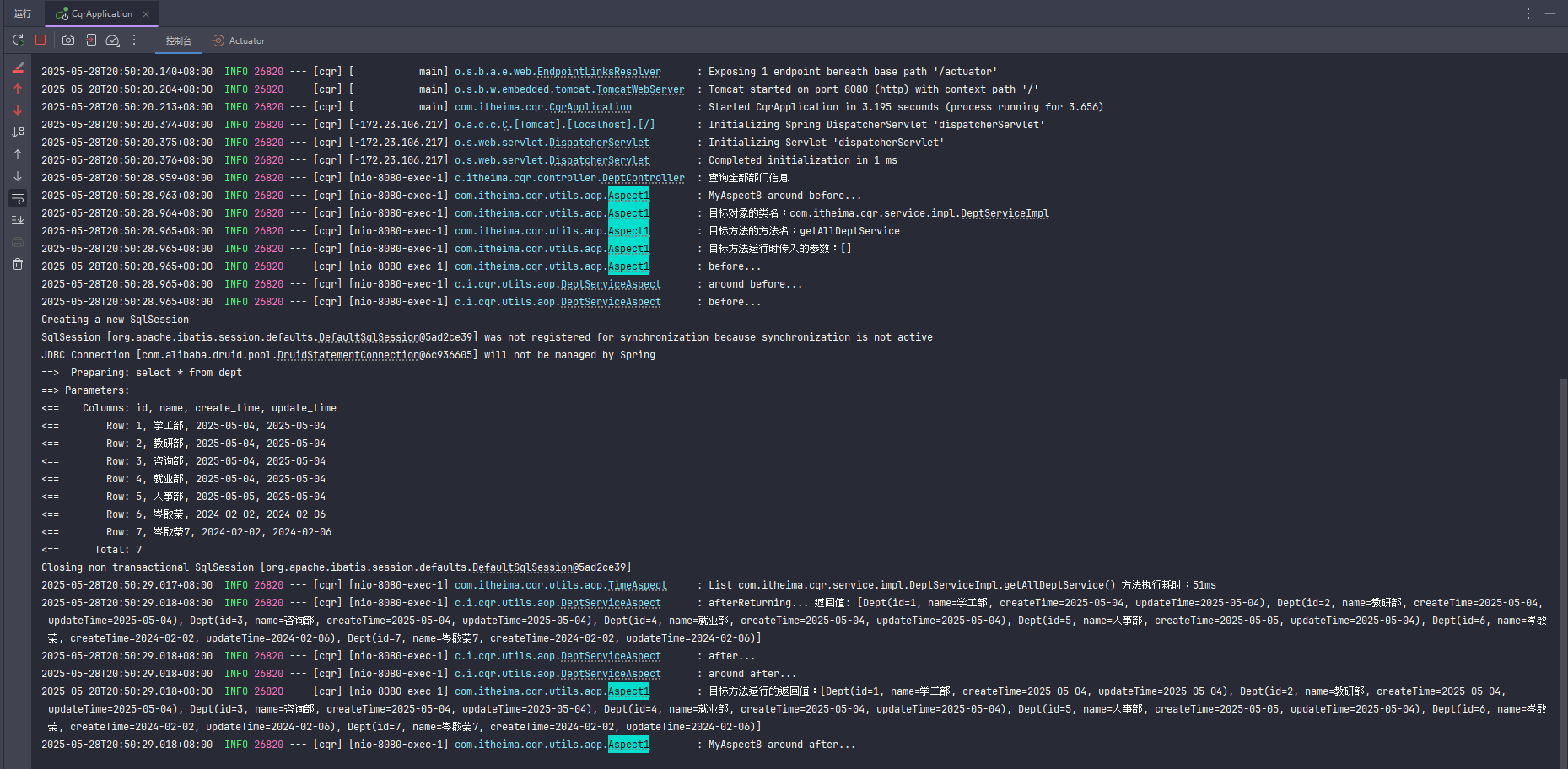
获取每个方法的执行时间
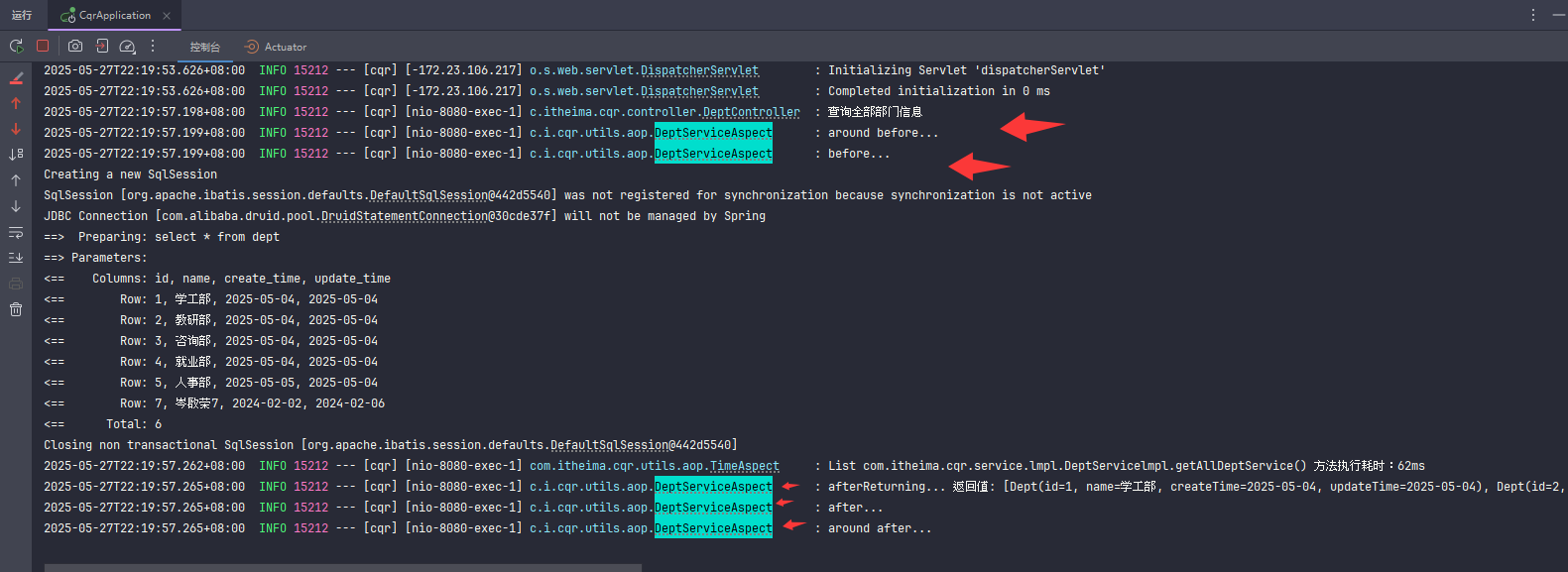
TimeAspect 切面类通过 Spring AOP 实现了对指定包下所有方法的耗时统计,流程如下:
Spring 启动时,@Aspect 注解的类会被识别为切面,AOP 框架会根据 @Around 注解里的切点表达式,自动为匹配的方法生成代理对象。
每次调用匹配的方法(如 com.itheima.cqr.service 包及其子包下的所有方法)时,实际执行的不是原始方法,而是代理对象的方法。
代理对象会先执行切面里的 recordTime 方法:
记录开始时间(long begin = System.currentTimeMillis();)
调用原始业务方法(joinPoint.proceed();)
记录结束时间(long end = System.currentTimeMillis();)
计算耗时并打印日志
返回原始方法的结果
这样每次方法被调用时,都会自动记录并输出耗时日志,无需在业务代码中手动添加。
执行时机: 只要调用了切点表达式匹配的方法(如 service 层的方法),就会自动触发切面逻辑,先执行切面代码,再执行原方法。



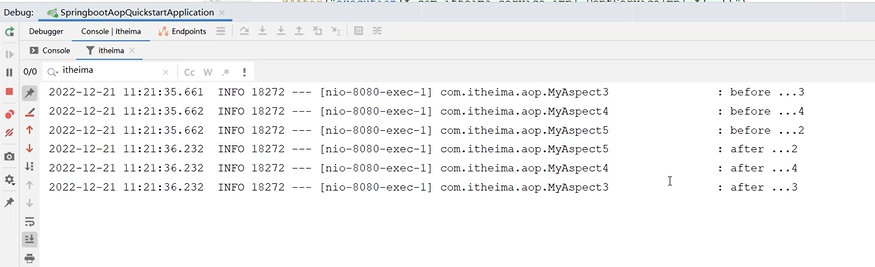
AOP五种通知类型


通知顺序
知道就行

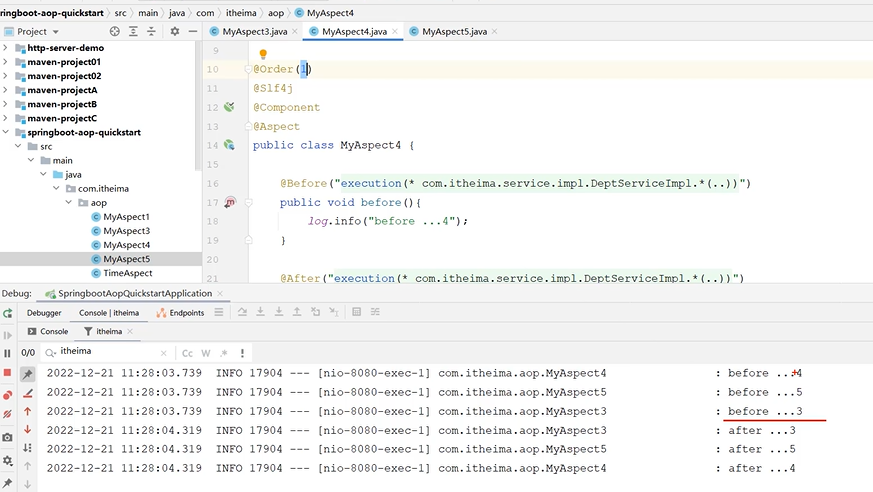
把2的方法名改成5
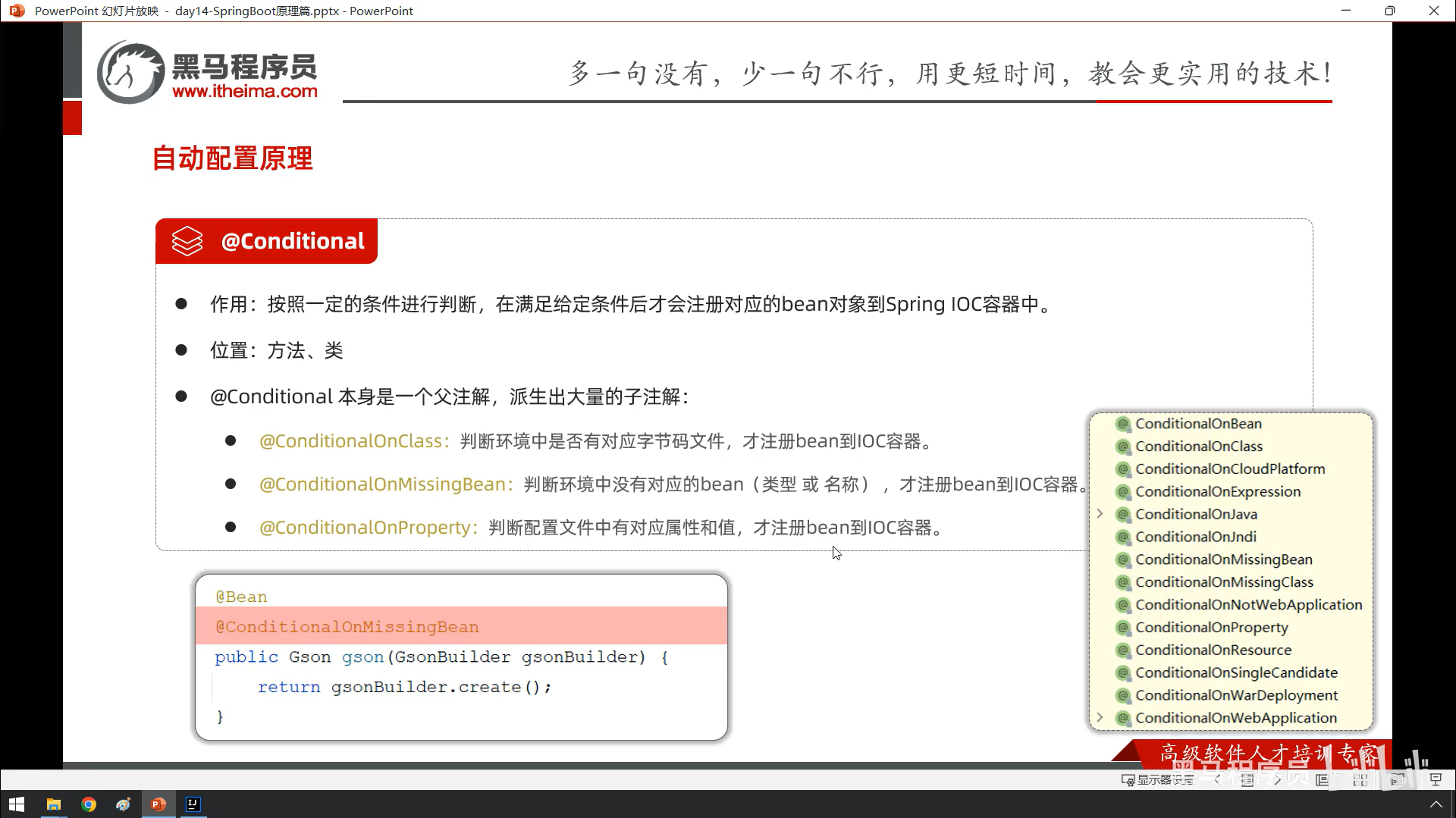
知识点

这是方法4的顺序级别为1
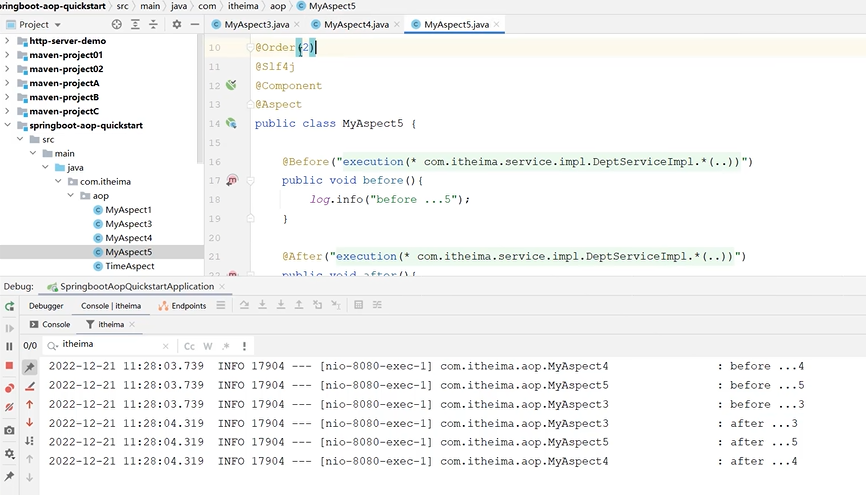
这是方法5的顺序级别为2
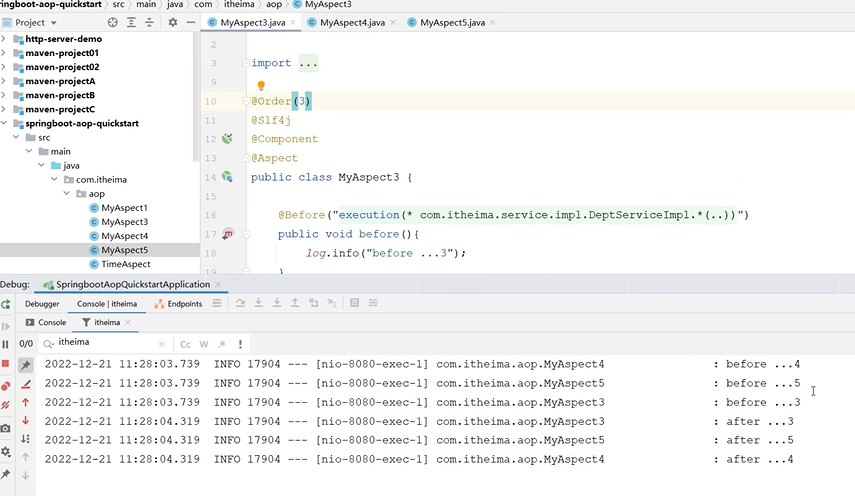
这是方法3的顺序级别为3
切入点表达式
service层那个实现类的文件夹是i啊。Impl文件夹,全大写是IMPL,然后实现类的名字后面是Impl,不是LMPL,我直到现在学切入点时才发现




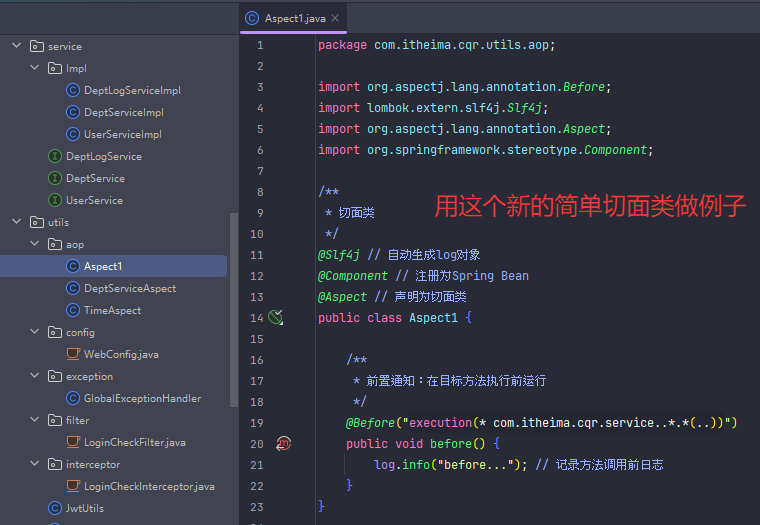
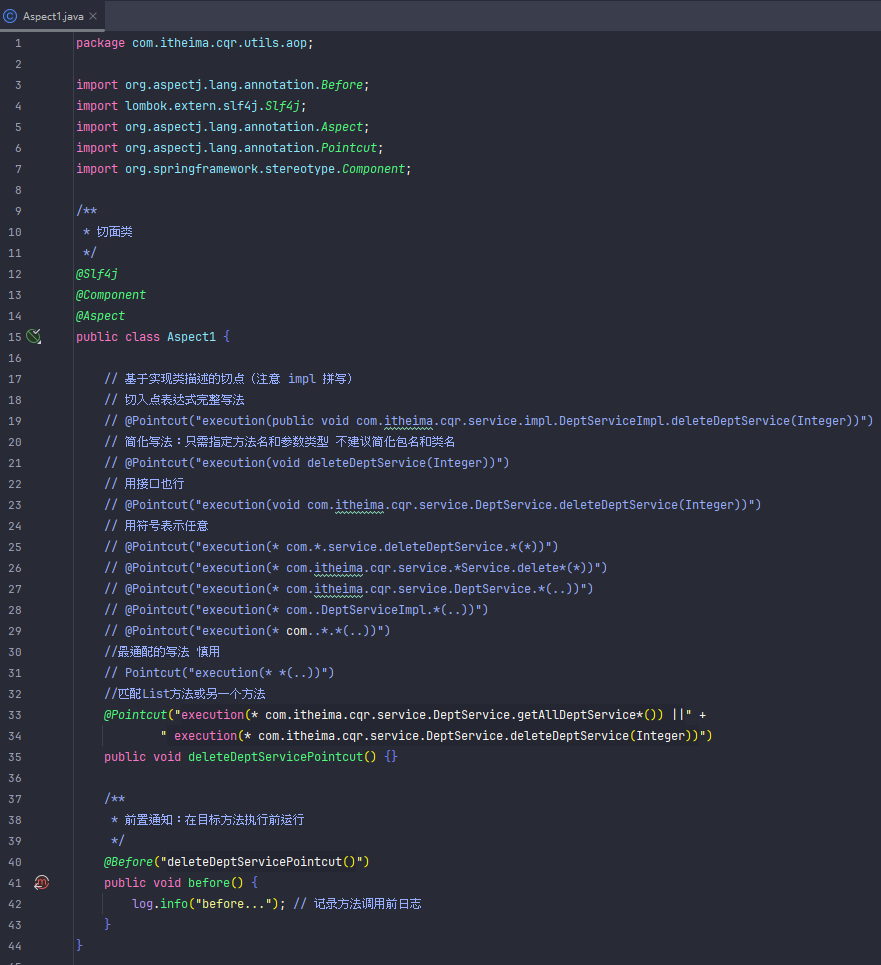
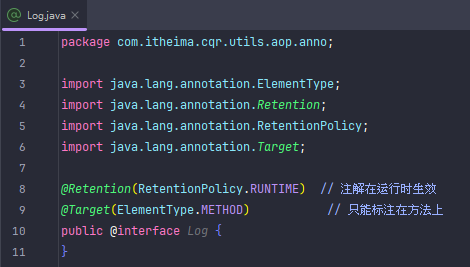
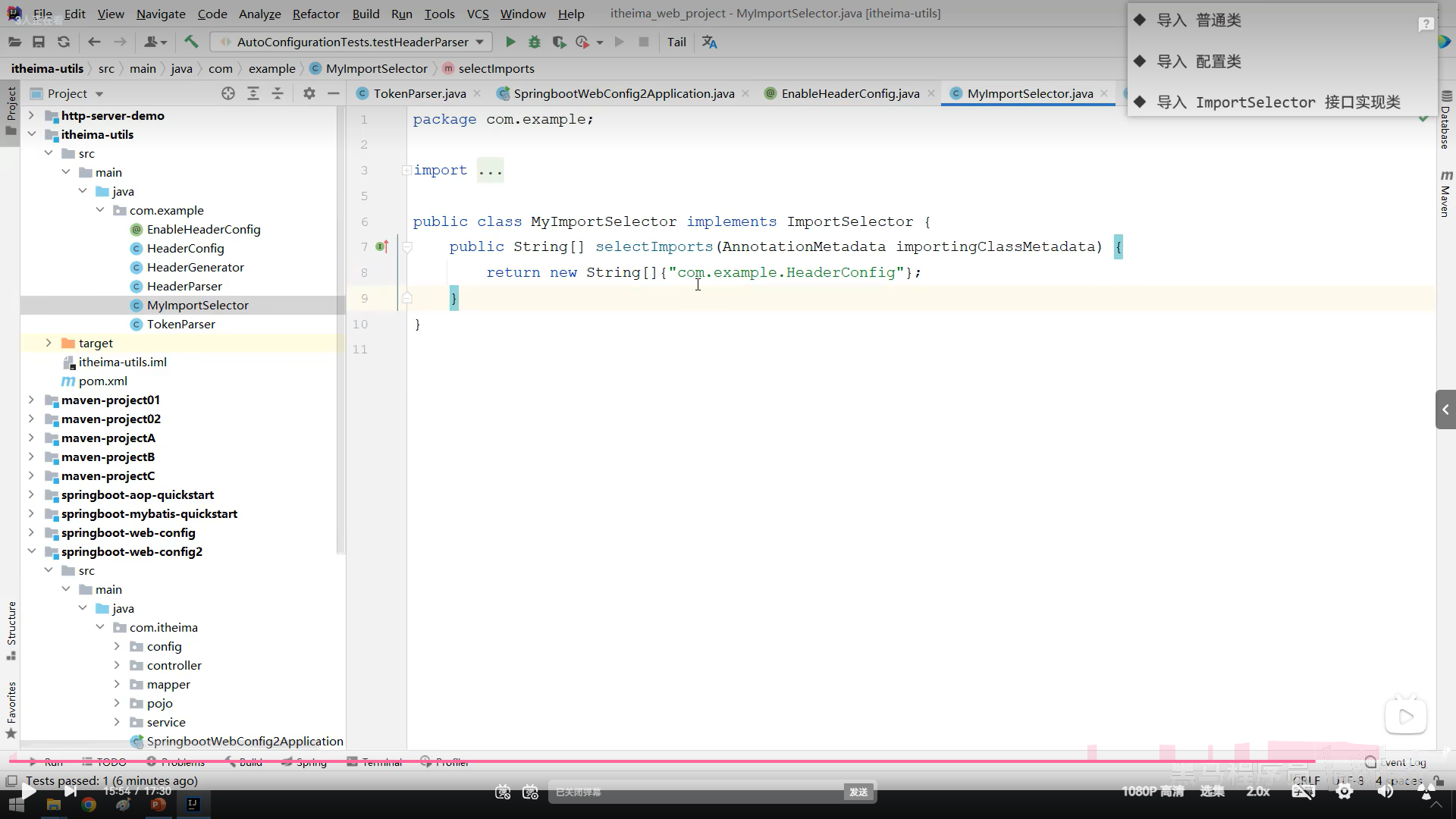
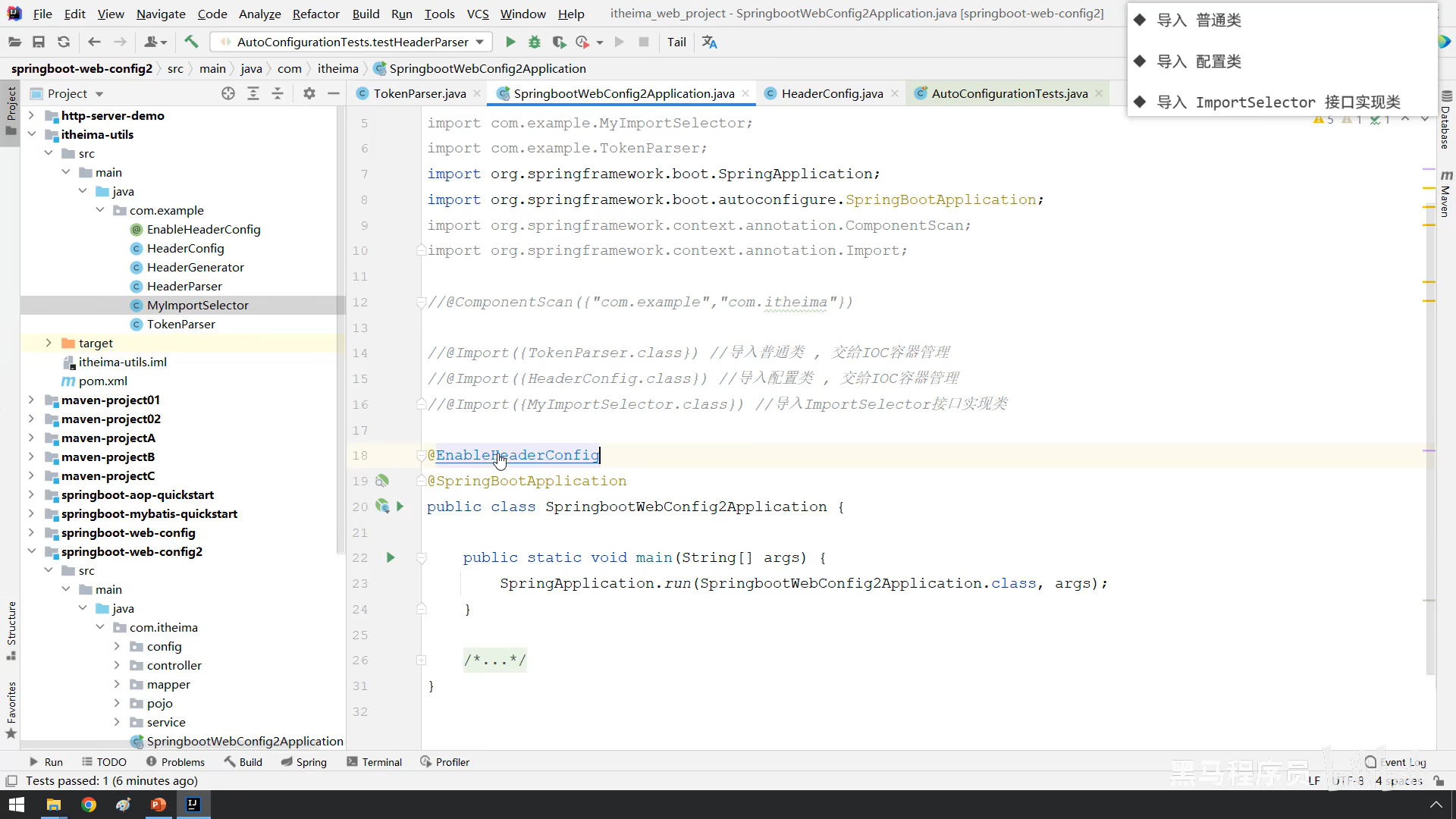
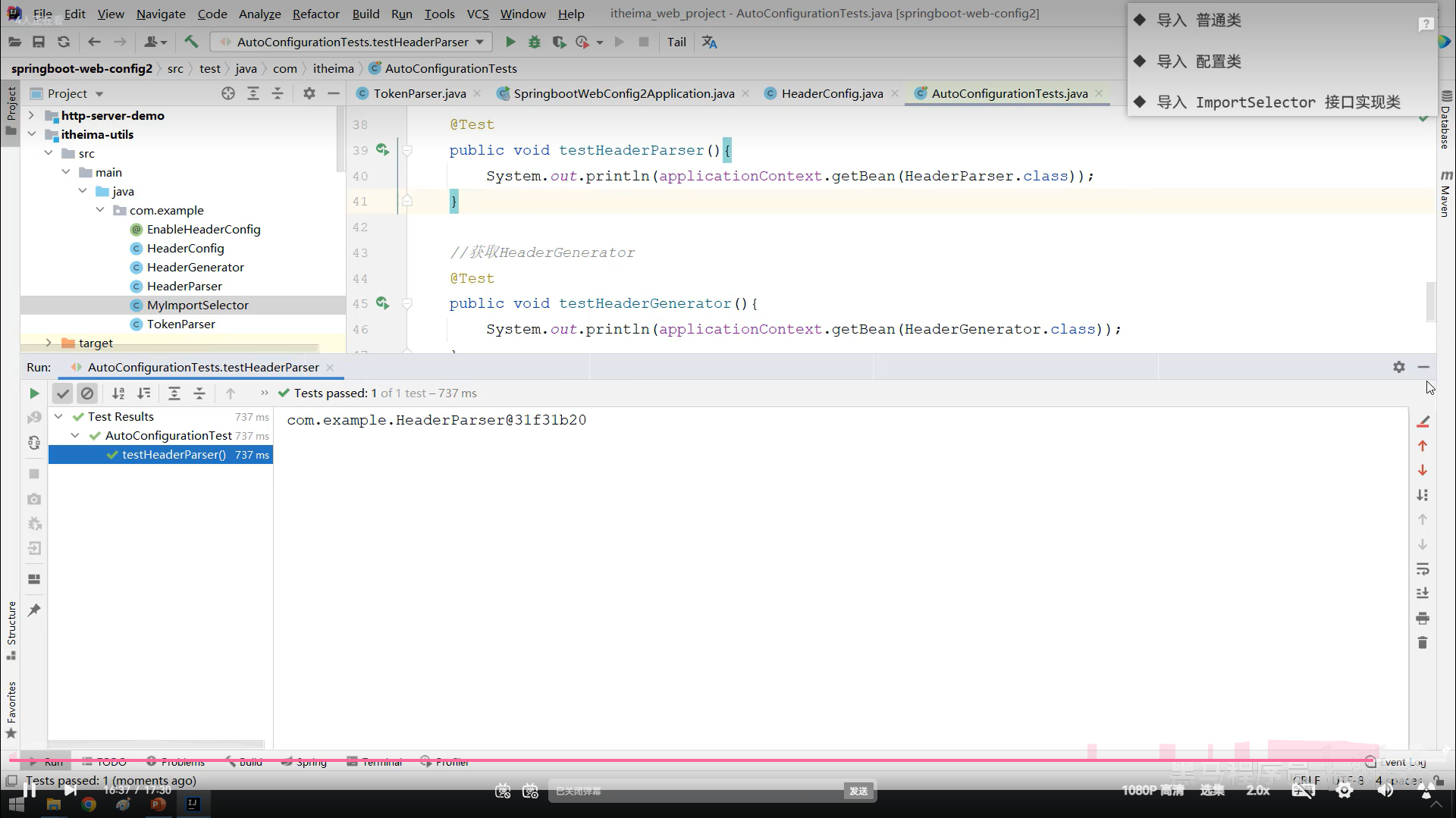
通过注解的方式匹配切入点方法(简单点就是自定义注解然后把注解标在需要运行的方法上,然后在切入点那里把标好的方法运行起来)
不能标在接口方法上,要标在实现类方法上

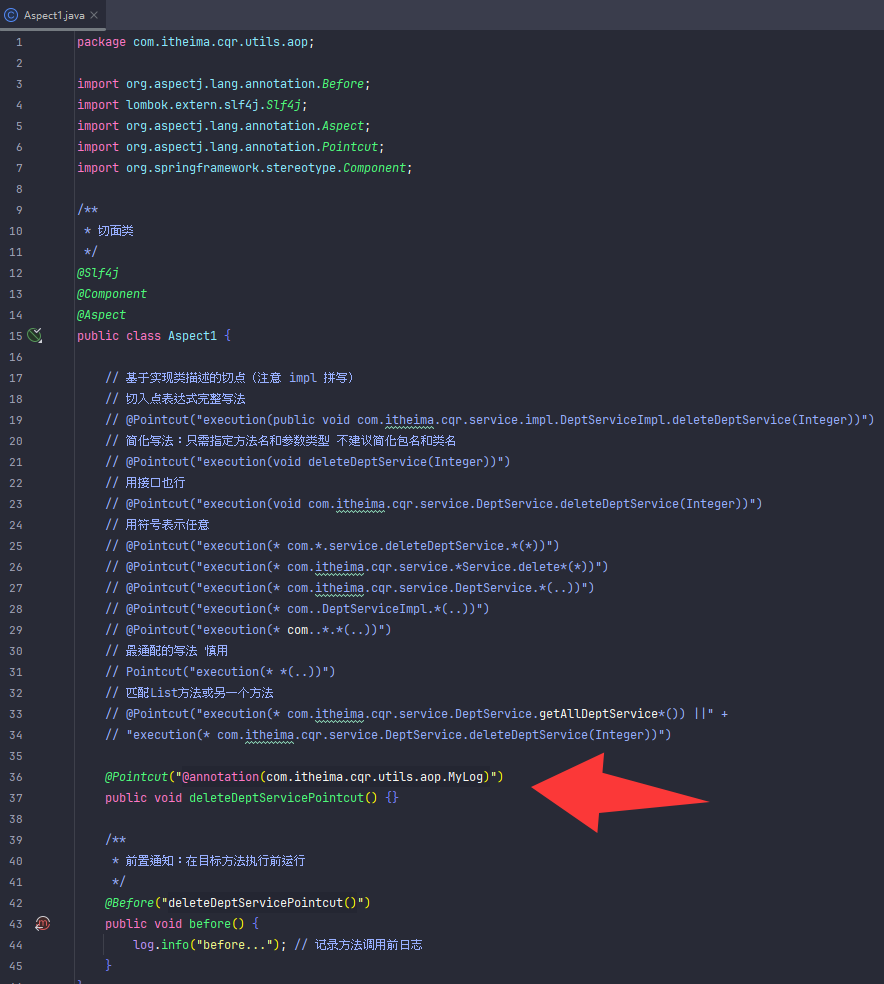
连接点

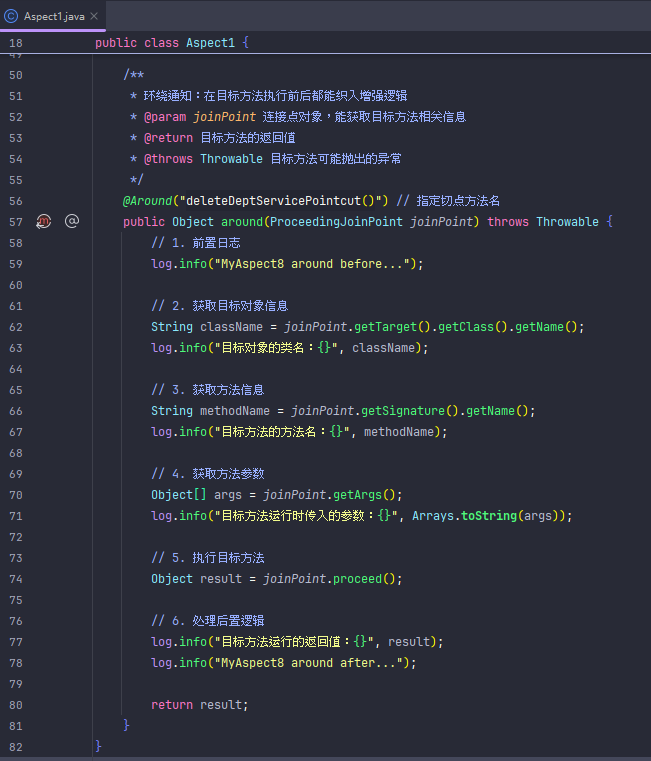
案例


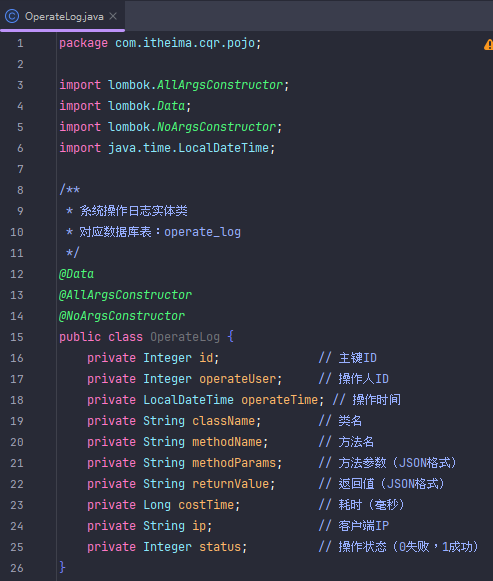
建一个放操作记录的数据库表
CREATE TABLE `operate_log` (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`operate_user` int unsigned DEFAULT NULL COMMENT '操作人ID',
`operate_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '操作时间',
`class_name` varchar(100) DEFAULT NULL COMMENT '类名',
`method_name` varchar(100) DEFAULT NULL COMMENT '方法名',
`method_params` varchar(1000) DEFAULT NULL COMMENT '方法参数(JSON格式)',
`return_value` varchar(2000) DEFAULT NULL COMMENT '返回值(JSON格式)',
`cost_time` bigint DEFAULT NULL COMMENT '耗时(毫秒)',
`ip` varchar(50) DEFAULT NULL COMMENT '客户端IP',
`status` tinyint DEFAULT '1' COMMENT '操作状态(0失败,1成功)',
PRIMARY KEY (`id`),
KEY `idx_user_time` (`operate_user`,`operate_time`) COMMENT '用户操作时间索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='系统操作日志表';
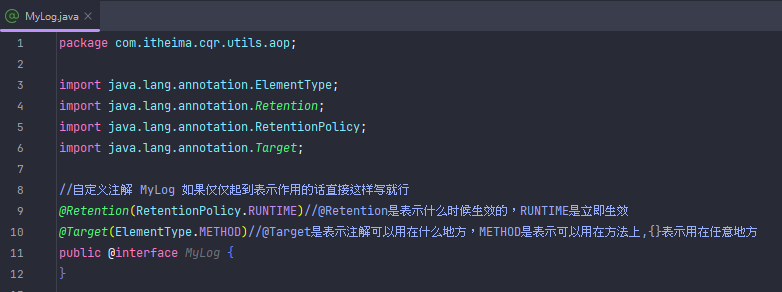
我把MyLog自定义注解转移到了anno文件夹





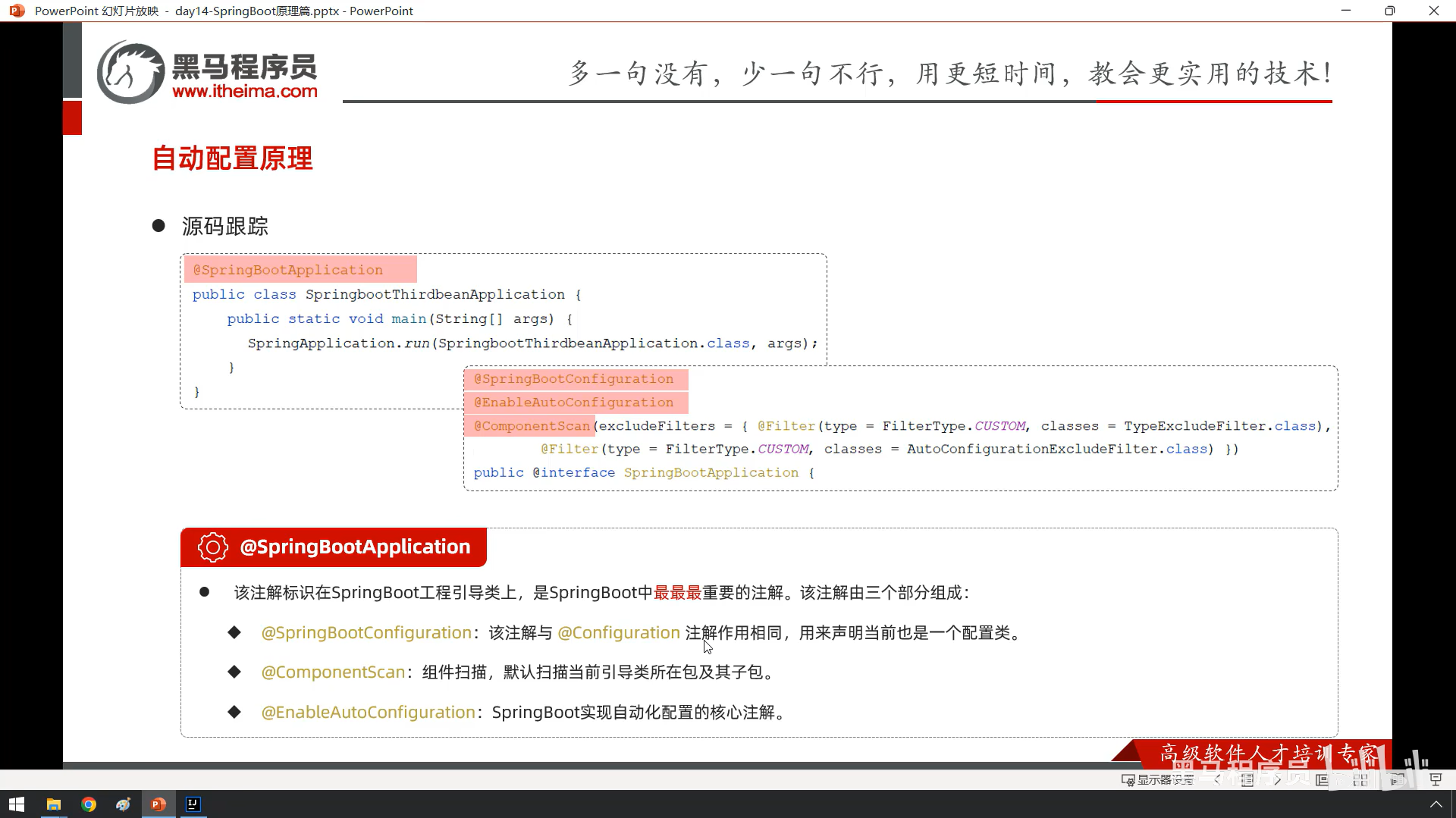
bean和springboot原理我没跟着敲截图了
1

2

3
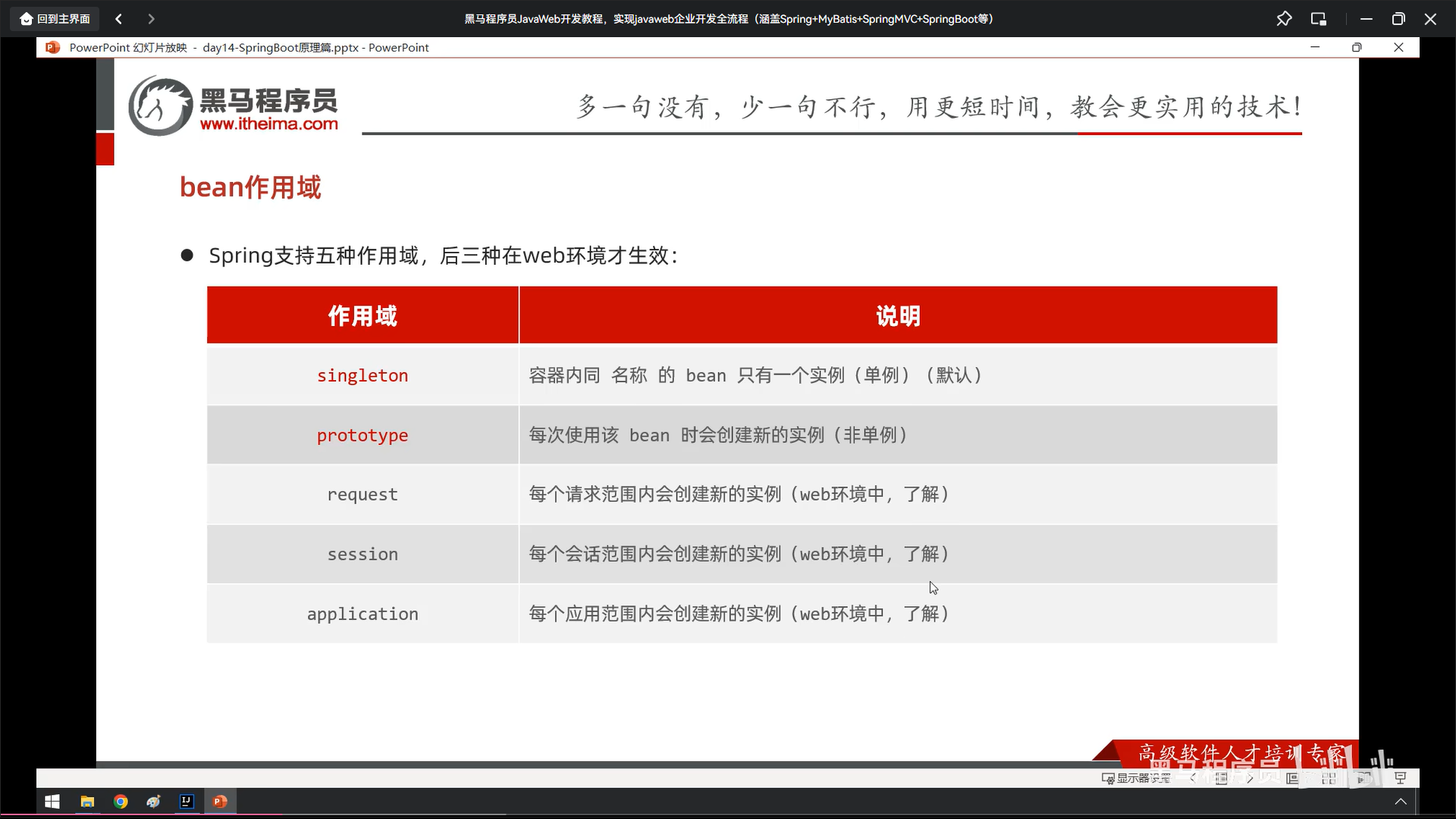
4
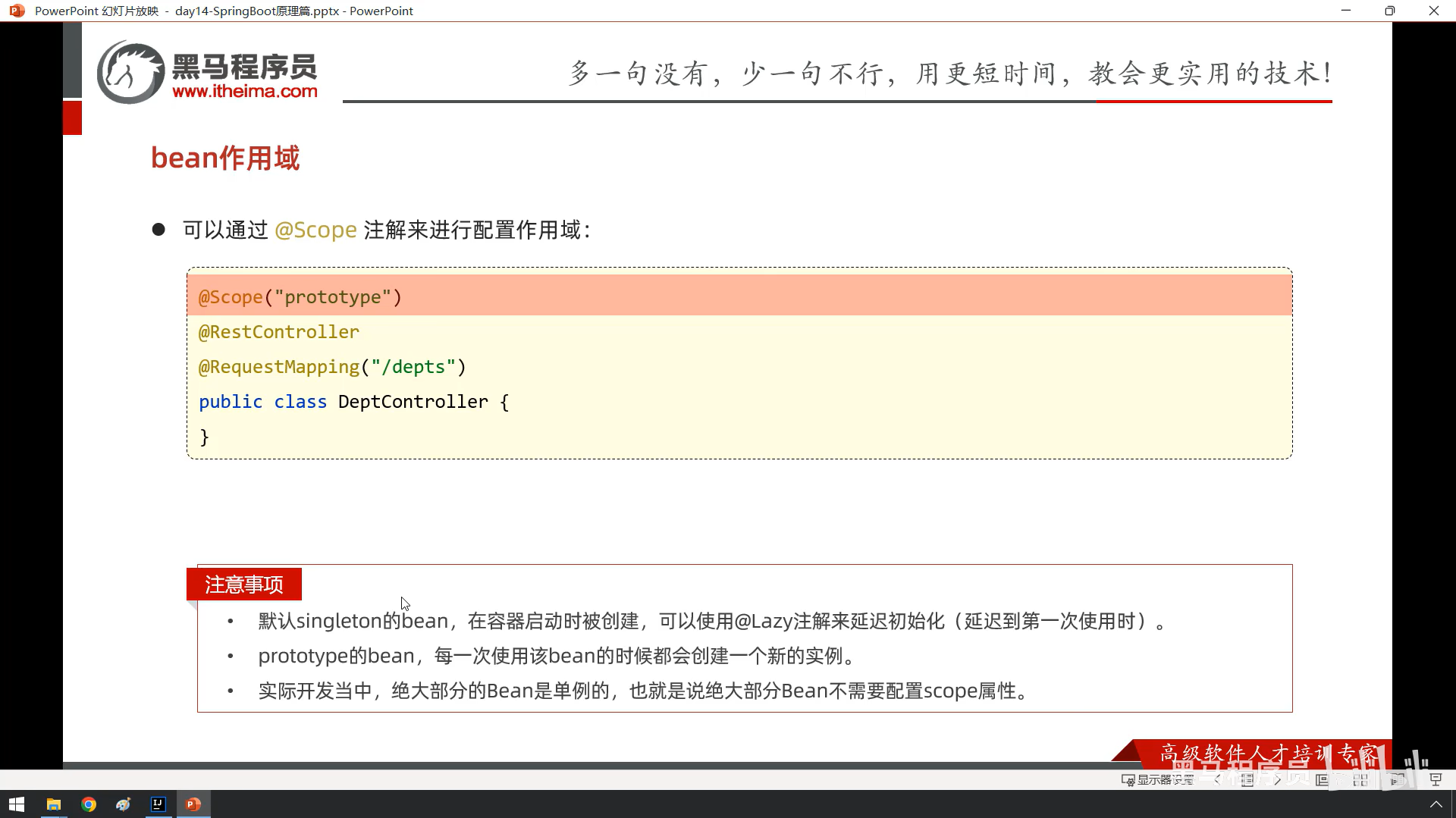
5
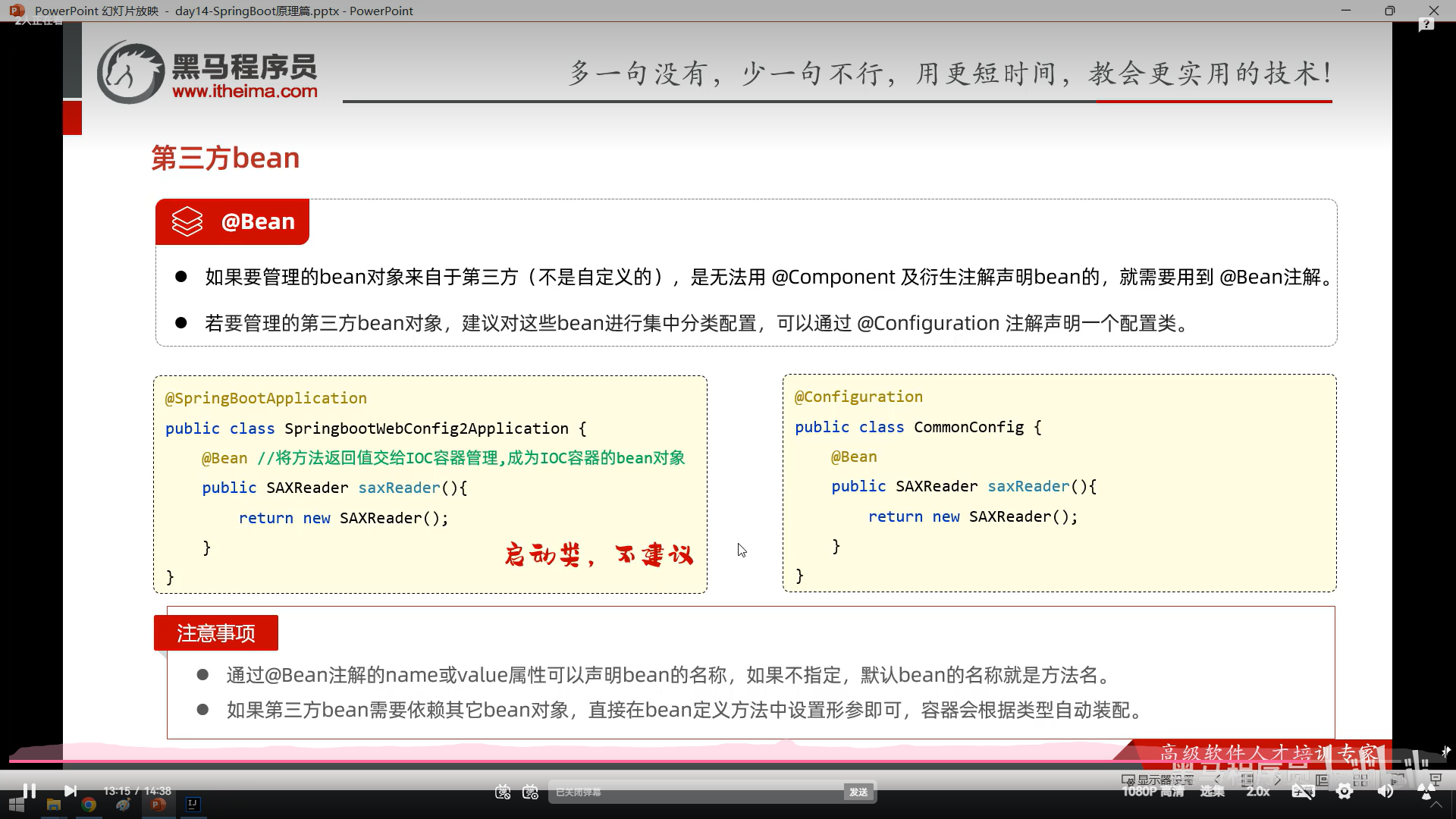
6
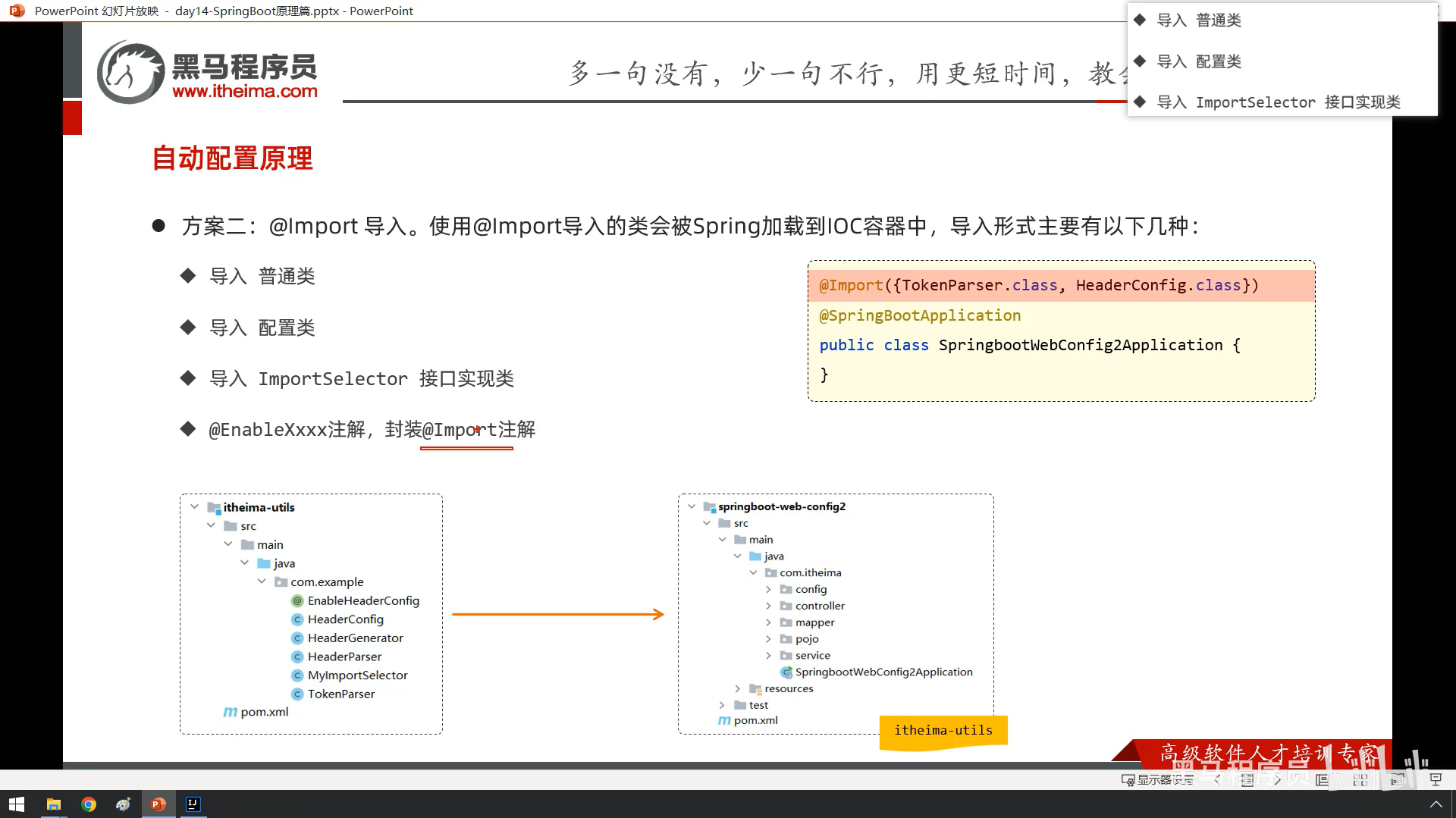
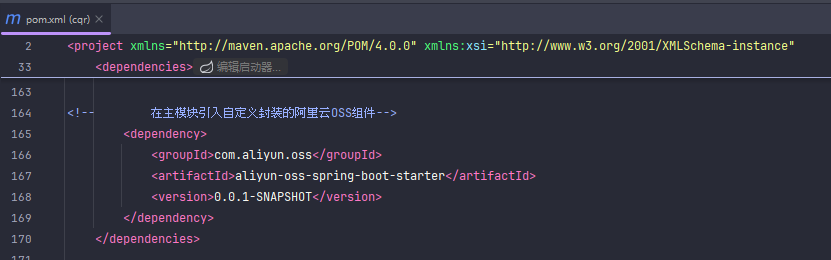
7
8
9
10
11
12
13
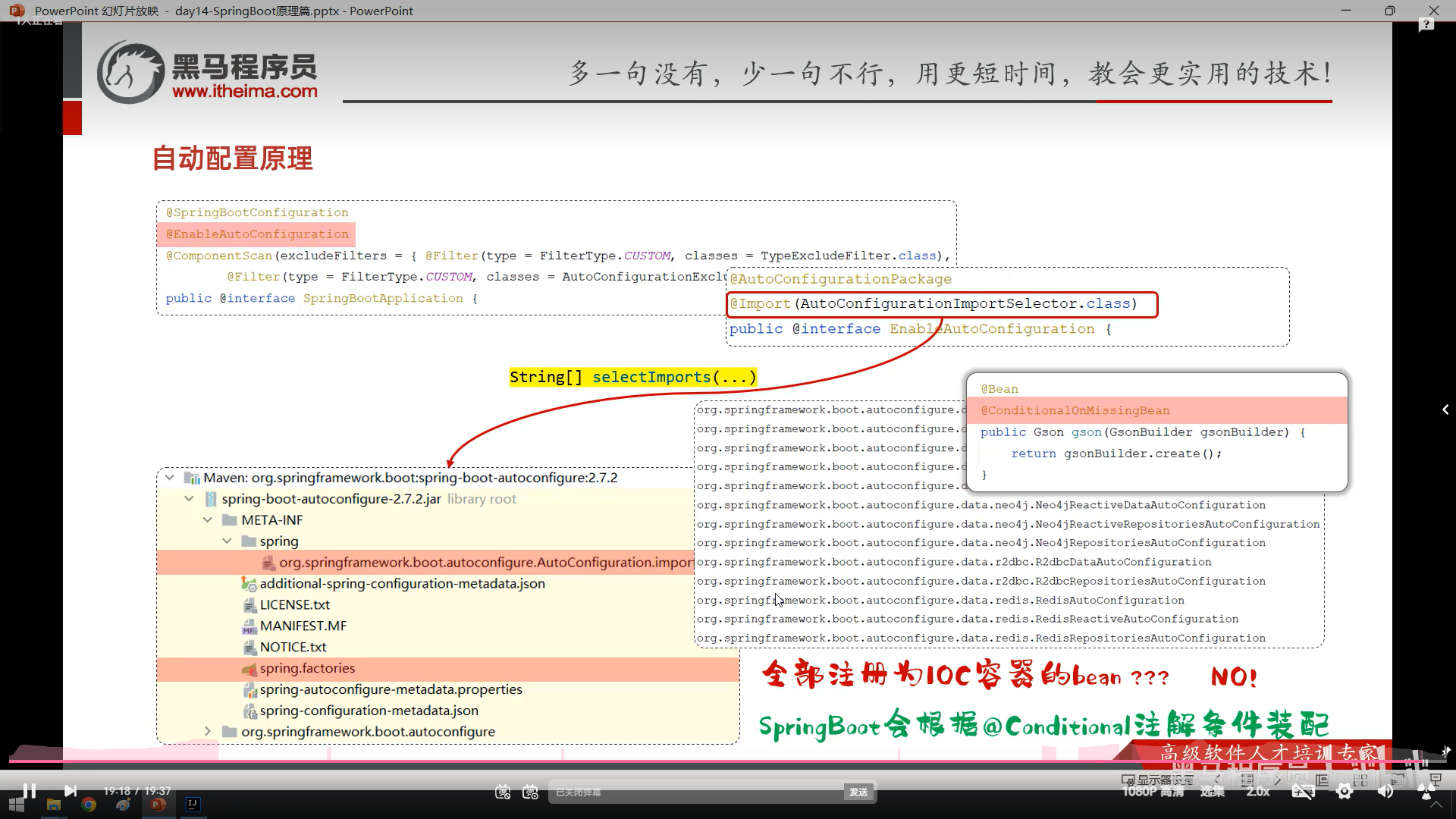
这个是springboot的封装组件技术,是上面bean和springboot原理的实践,感觉很常用所以我跟着来

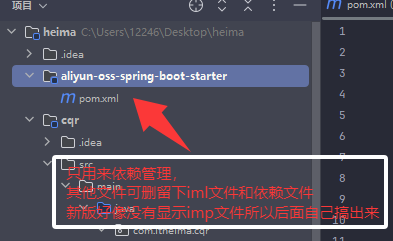
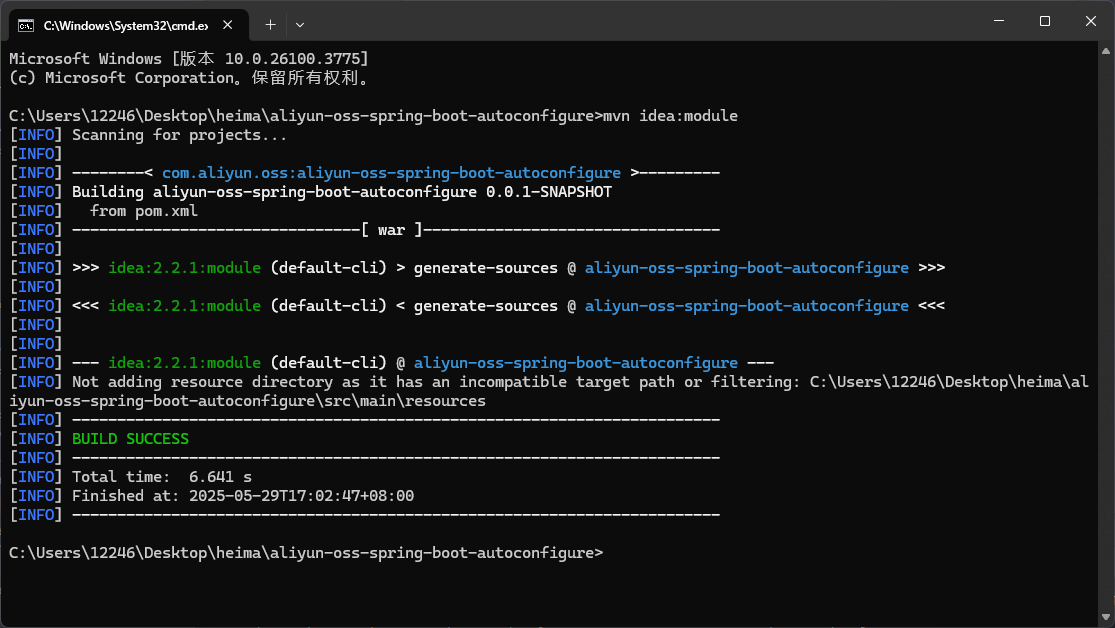
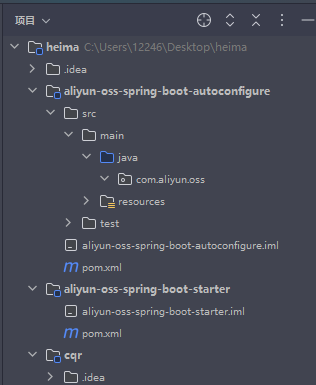
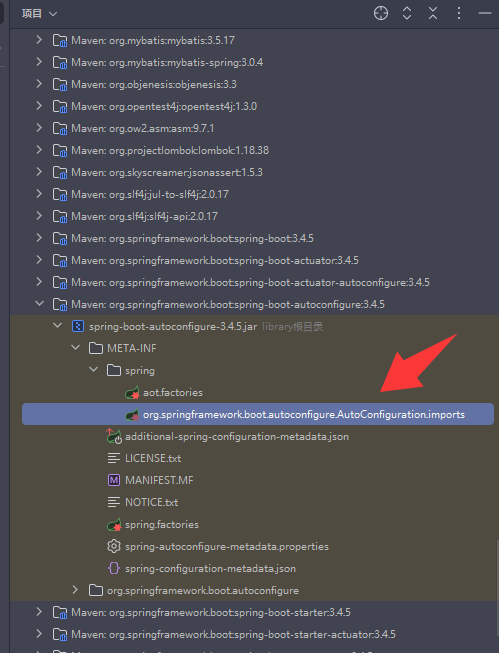
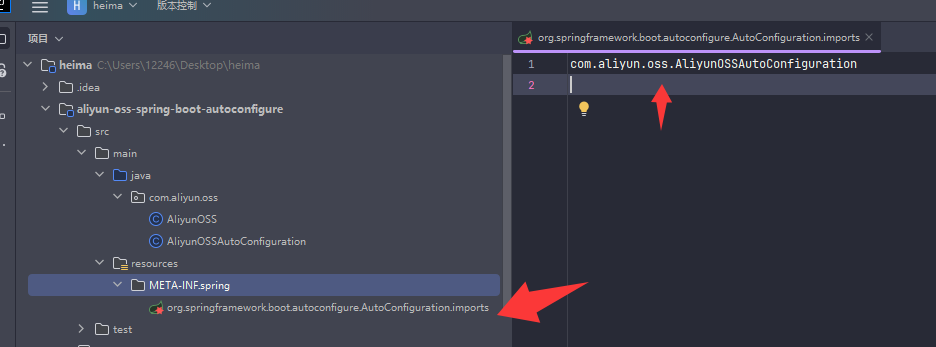
阿里云 OSS Starter 实际有两个模块:
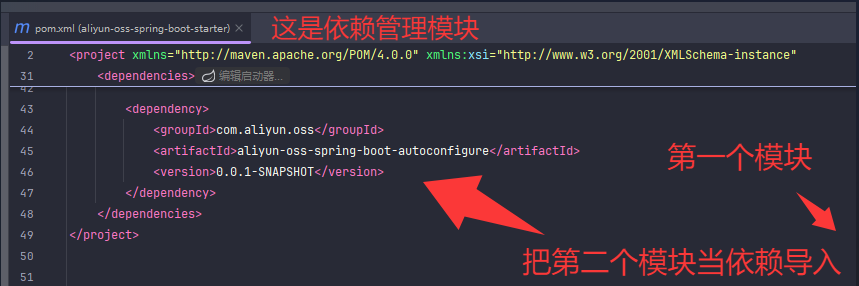
依赖管理模块(通常命名为 aliyun-oss-spring-boot-starter) 作用:
作为 starter 的入口,主项目只需引入这个模块即可自动获得所有相关依赖和自动配置。
依赖了自动配置模块(aliyun-oss-spring-boot-autoconfigure),自身一般不包含具体实现代码。
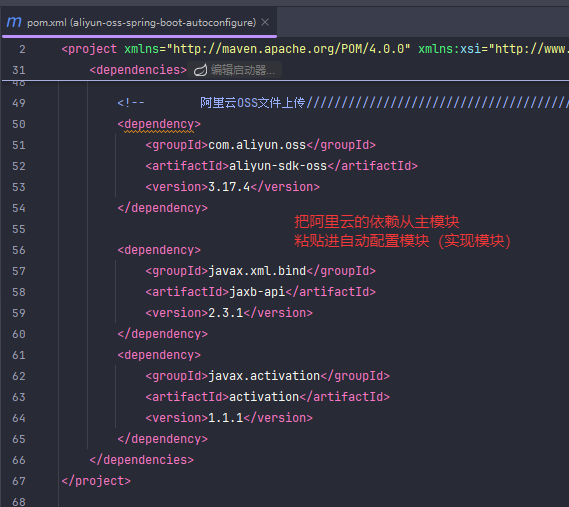
自动配置模块(aliyun-oss-spring-boot-autoconfigure) 作用:
提供自动配置类(如 AliyunOSSAutoConfiguration)和工具类(如 AliyunOSS)。
负责将 OSS 工具类自动注入 Spring 容器,读取配置参数,封装上传逻辑。
调用关系和作用总结:
主项目只需依赖 aliyun-oss-spring-boot-starter,starter 会自动 transitively 引入 aliyun-oss-spring-boot-autoconfigure。
自动配置模块负责 OSS 相关 Bean 的创建和配置。
依赖管理模块只做依赖聚合和 starter 标识,不含业务代码。
这样分层,starter 用户体验更好,结构更清晰,符合 Spring Boot 官方 starter 规范。
自动配置模块(aliyun-oss-spring-boot-autoconfigure)
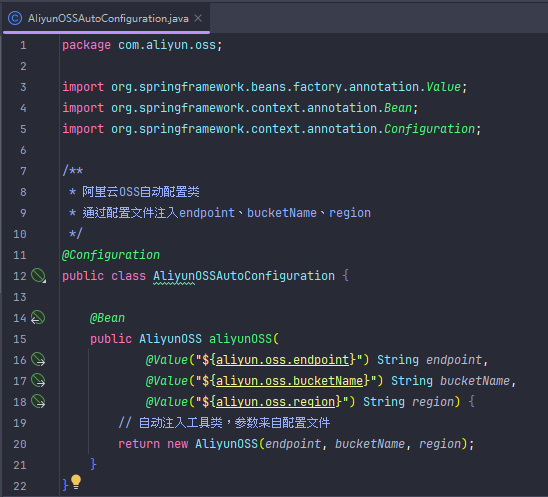
自动配置类(AliyunOSSAutoConfiguration) 这是一个 Spring Boot 自动配置类,作用是:
通过 @Configuration 注解让 Spring Boot 启动时自动加载。
通过 @Bean 方法将 AliyunOSS 工具类注入到 Spring 容器。
通过 @Value 注解从配置文件读取 endpoint、bucketName、region 等参数,自动传递给工具类。
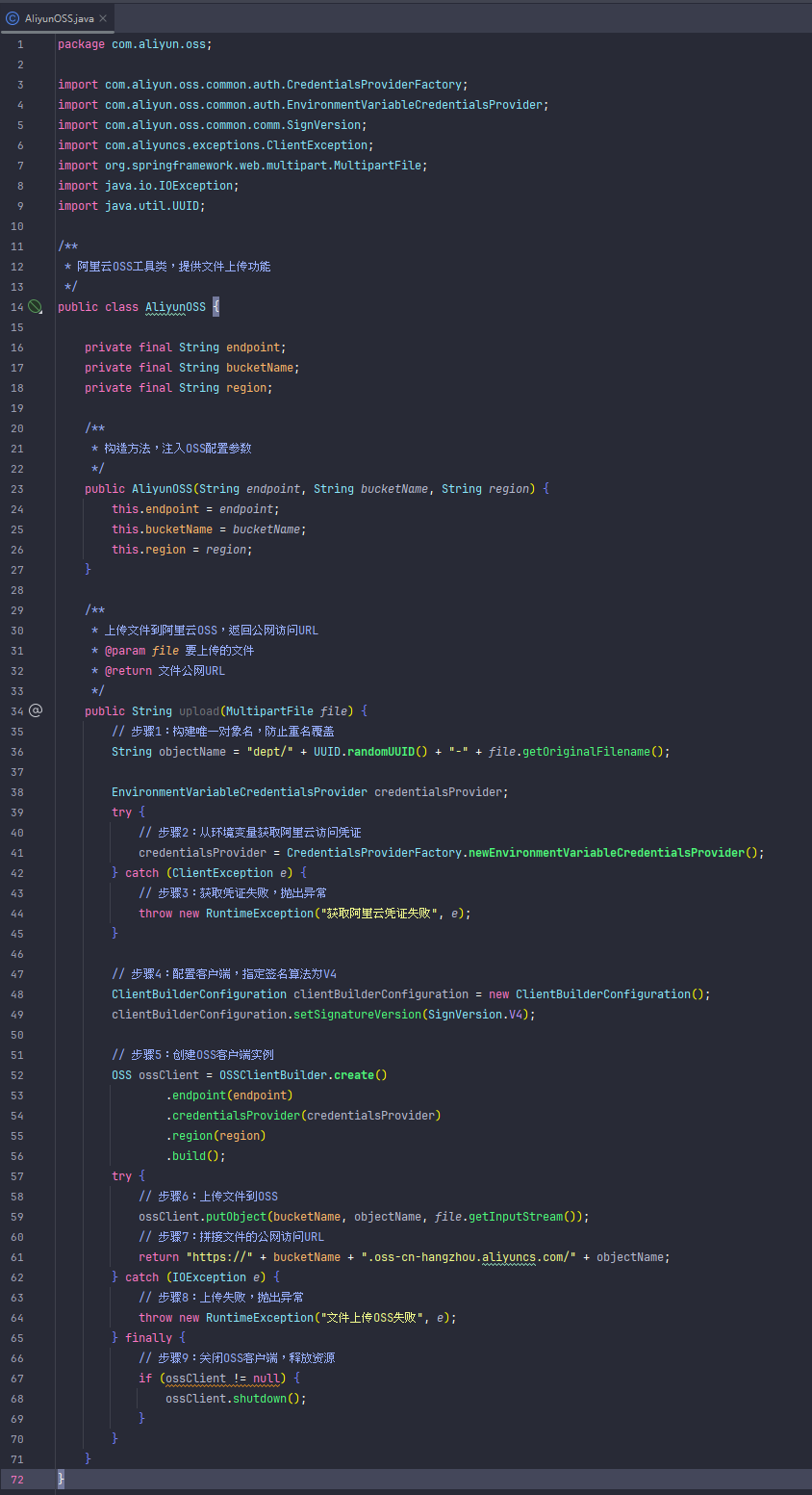
工具类(AliyunOSS) 这是一个封装了阿里云 OSS 文件上传逻辑的工具类,作用是:
通过构造方法接收 endpoint、bucketName、region 等配置参数。
提供 upload 方法,负责将文件上传到阿里云 OSS,并返回公网访问 URL。
内部处理凭证获取、OSS 客户端创建、文件上传、异常处理等细节,业务代码只需调用即可。
以下是完整流程:



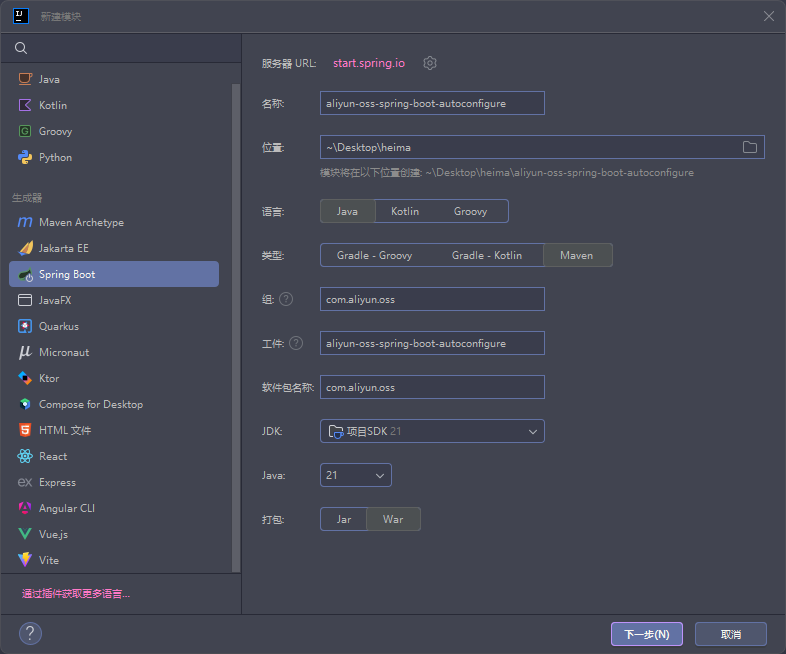
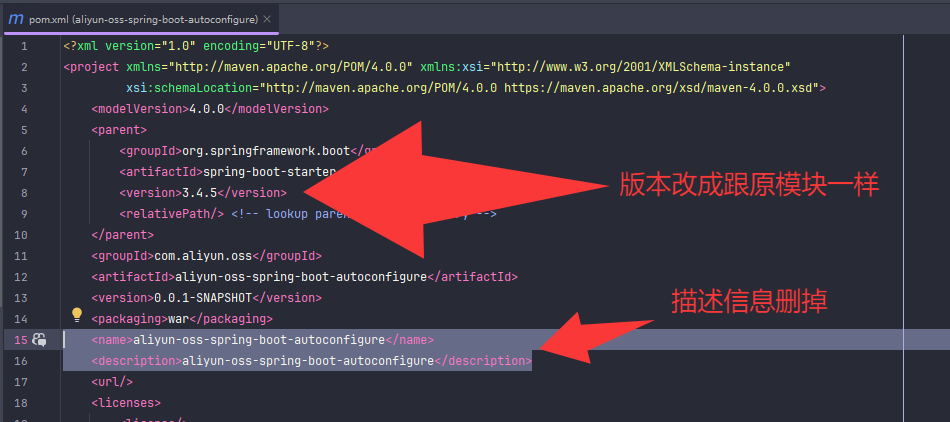 =
=







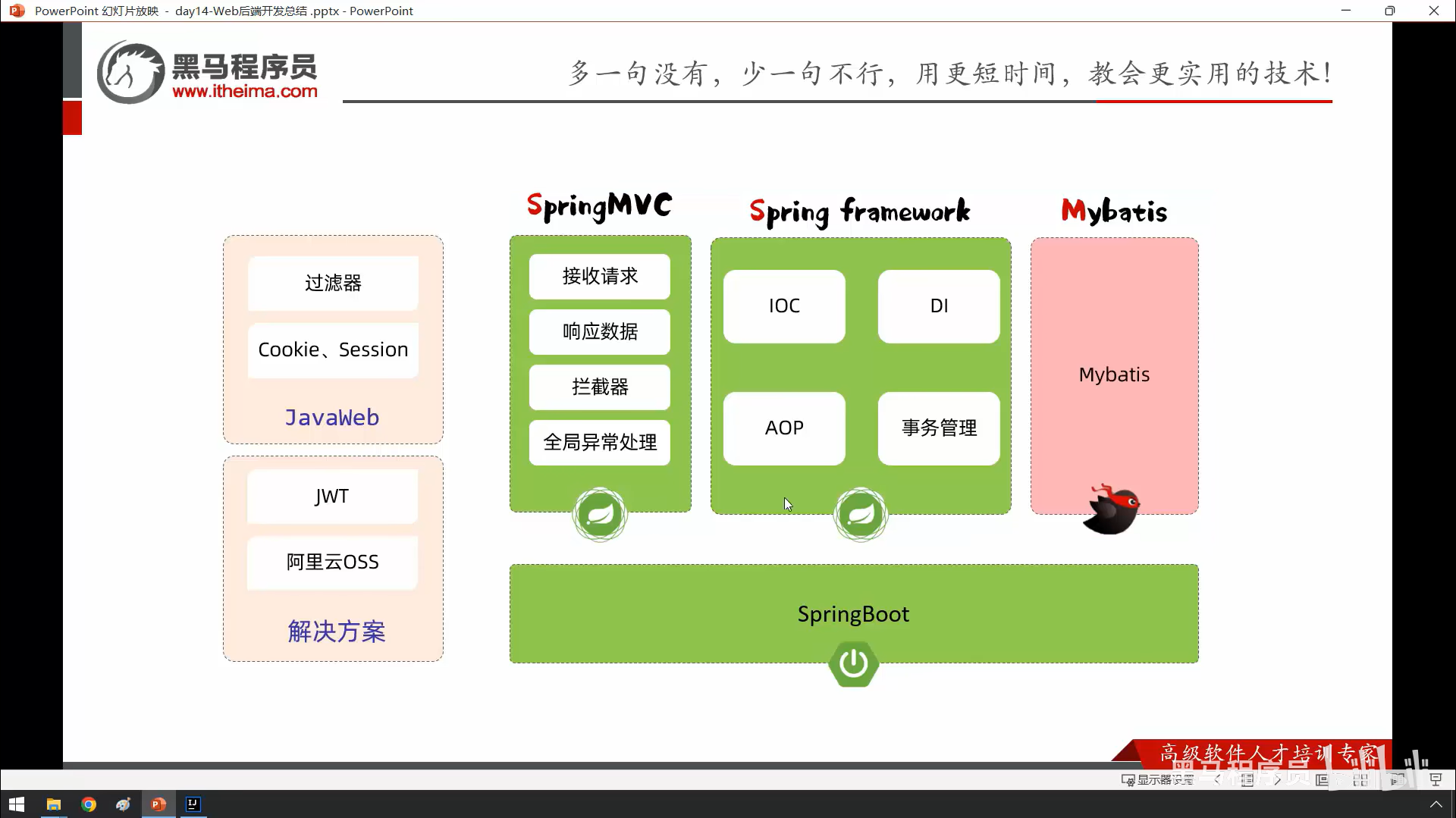
这是总结

技术框架全家桶
(像是一个“工具箱”,每个工具各司其职)
-
JavaWeb 基础
- 过滤器:像“安检门”,对所有请求做统一检查(比如屏蔽脏话)。
- Cookie/Session:用来记住用户登录状态(比如你关掉淘宝再打开,依然保持登录)。
- JWT:更安全的登录凭证(像电子身份证,不用每次都输密码)。
- 阿里云OSS:存图片/视频的工具(比如用户上传头像就存在这里)。
-
SpringMVC(核心控制器)
- 接收请求:比如浏览器输入网址
http://xxx.com/login,它负责接活儿。 - 响应数据:返回给浏览器页面或JSON数据(比如登录成功提示)。
- 拦截器:比过滤器更灵活,能针对特定请求做处理(比如检查权限)。
- 全局异常处理:万一程序崩了,给你一个友好的报错页面,而不是一堆代码。
- 接收请求:比如浏览器输入网址
-
Spring Framework(大管家)
- IOC:不用自己
new对象,容器自动给你(比如服务员直接端菜,不用你进厨房做)。 - DI:自动给对象“喂”它需要的其他对象(比如
Controller需要Service,容器会塞给它)。 - AOP:统一加“buff”(比如所有方法自动记录日志)。
- 事务管理:保证数据库操作要么全成功,要么全失败(比如转账不能扣了钱却没到账)。
- IOC:不用自己
-
MyBatis
- 帮你和数据库对话,把Java代码翻译成SQL语句(不用手写复杂的JDBC)。
-
SpringBoot(终极懒人包)
- 把上面所有工具打包,一键启动!不用配置到吐血。
请求的一生
(像快递从发货到收货的流程)
- 用户操作:你在浏览器点“登录”按钮 → 发送请求。
- 过滤器:第一道关卡(比如检查是否已登录)。
- 拦截器:第二道关卡(比如验证权限够不够)。
- Controller:接收请求,像前台接待员。
- Service:处理业务逻辑,像后台程序员(比如检查账号密码对不对)。
- Dao:和数据库打交道,像仓库管理员(从MySQL查用户数据)。
- 返回结果:沿着原路返回,最终展示“登录成功”页面。
▶ 头顶的“Buff光环”
- IOC/DI/AOP:全程默默支持(自动装配对象、加日志、管事务)。
- 全局异常处理:万一Service炸了,直接跳转到错误页,而不是让用户看到500报错。
▶ 底部的“小工具”
- Cookie/Session/JWT:管理登录状态的三种方式。
- 阿里云OSS/MyBatis:存文件的和操作数据库的。
现在以专业角度解释这两张PPT的内容和关联性:
第一张图:技术架构分层解析
(技术栈的横向切面展示)
-
JavaWeb基础层
- 过滤器(Filter):Servlet规范组件,实现
javax.servlet.Filter接口,基于函数回调对HTTP请求/响应做预处理(如字符编码、XSS防护)。 - Cookie/Session:会话管理机制。Cookie存储在客户端,Session依赖服务端存储(默认JSESSIONID绑定)。需注意分布式场景下的Session一致性方案。
- JWT:基于RFC 7519的无状态认证方案,通过HMAC或RSA对Header+Payload签名,解决服务端扩展性问题。
- OSS:对象存储服务,通过SDK实现文件上传/下载,需关注ACL权限控制和CDN加速配置。
- 过滤器(Filter):Servlet规范组件,实现
-
SpringMVC层
- DispatcherServlet:前端控制器,通过
HandlerMapping定位到@Controller,HandlerAdapter执行方法。 - 拦截器(Interceptor):实现
HandlerInterceptor接口,可精确控制到Controller方法的pre/post处理。 - 全局异常处理:通过
@ControllerAdvice+@ExceptionHandler统一处理各类异常,返回标准化错误DTO。
- DispatcherServlet:前端控制器,通过
-
Spring核心层
- IoC容器:基于
BeanDefinition注册表管理对象依赖关系,默认单例模式通过DefaultSingletonBeanRegistry实现。 - DI实现:按
@Autowired/构造器/Setter等注入方式,底层通过AutowiredAnnotationBeanPostProcessor处理。 - AOP:基于动态代理(JDK/CGLIB),通过
Pointcut+Advice实现声明式事务等横切逻辑。 - 事务管理:
PlatformTransactionManager抽象,配合@Transactional实现ACID,需注意传播行为和隔离级别配置。
- IoC容器:基于
-
持久层
- MyBatis:通过
SqlSessionFactory构建会话,MapperProxy动态代理接口方法,Executor执行SQL映射。
- MyBatis:通过
-
SpringBoot整合
- 通过
spring-boot-starter-web等starter自动配置组件,@SpringBootApplication复合注解触发自动装配。
- 通过
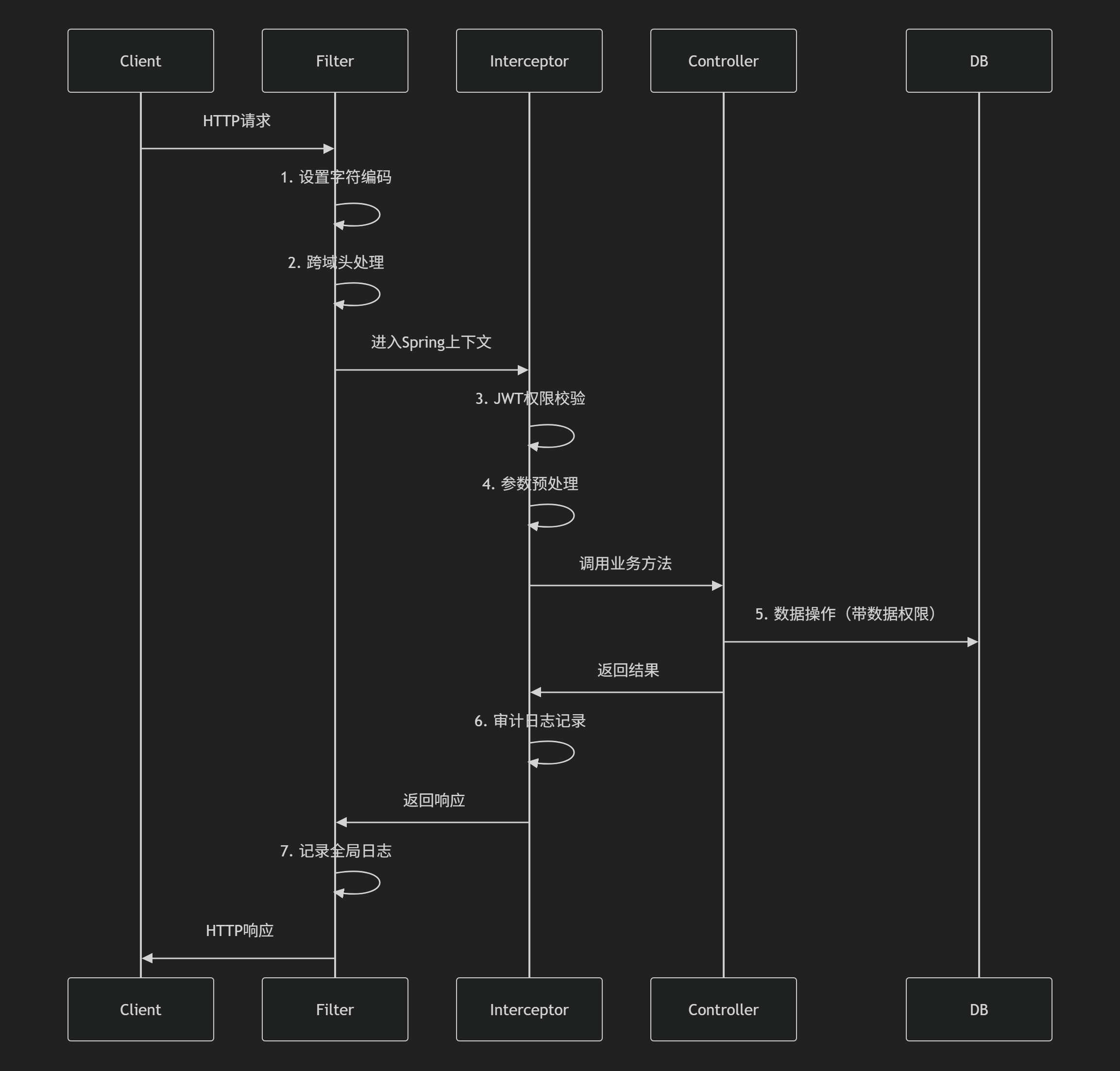
第二张图:请求处理流程
(纵向请求链路的数据流转)
-
请求入口
- HTTP请求首先经过Servlet容器(如Tomcat)的Filter链,执行
doFilter()链式调用。
- HTTP请求首先经过Servlet容器(如Tomcat)的Filter链,执行
-
SpringMVC处理阶段
- 拦截器
preHandle()执行权限校验等逻辑 → DispatcherServlet根据@RequestMapping路由到Controller方法 →- 参数解析器(
HandlerMethodArgumentResolver)处理请求参数 → - 返回值处理器(
HandlerMethodReturnValueHandler)转换响应数据。
- 拦截器
-
业务处理层
- Service层通过
@Transactional注解方法触发事务代理逻辑,需注意自调用失效问题。 - DAO层通过MyBatis的
SqlSession执行CRUD,一级/二级缓存需根据场景配置。
- Service层通过
-
数据持久化
- JDBC驱动最终与MySQL建立连接,连接池配置(如HikariCP)直接影响性能。
-
响应返回
- 经过拦截器
postHandle()处理 → - 过滤器链逆向执行
doFilter()→ - 响应通过
HttpServletResponse输出。
- 经过拦截器
架构关键点
-
IoC/DI的作用
- 容器通过
ApplicationContext管理Bean生命周期,解决对象创建和依赖耦合问题。 - 示例:Controller依赖Service时,容器自动注入代理对象(可能被AOP增强)。
- 容器通过
-
AOP实现原理
- 事务管理等通过
ProxyFactory创建代理对象,TransactionInterceptor实现环绕通知。 - 动态代理在运行时织入,需注意final方法和内部调用限制。
- 事务管理等通过
-
性能优化方向
- 过滤器/拦截器链应保持轻量
- MyBatis的N+1查询问题需通过
<collection>或批处理解决 - 事务范围应精确到最小粒度
-
安全考量
- 过滤器需处理XSS/CSRF防御
- JWT应设置合理过期时间并启用HTTPS
- SQL注入需通过MyBatis参数绑定规避
两图关联性
- 技术矩阵(图1)展示了架构的静态组成要素
- 流程架构(图2)体现动态交互关系
- 核心共性:Spring生态通过IoC容器统一调度各层组件,AOP实现横切关注点分离
这种架构设计实现了:
- 组件职责单一(SRP原则)
- 层间解耦(DIP原则)
- 非侵入式扩展(OCP原则)
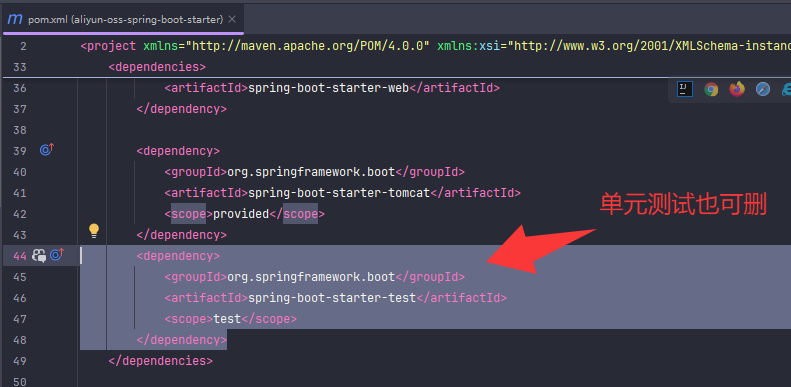
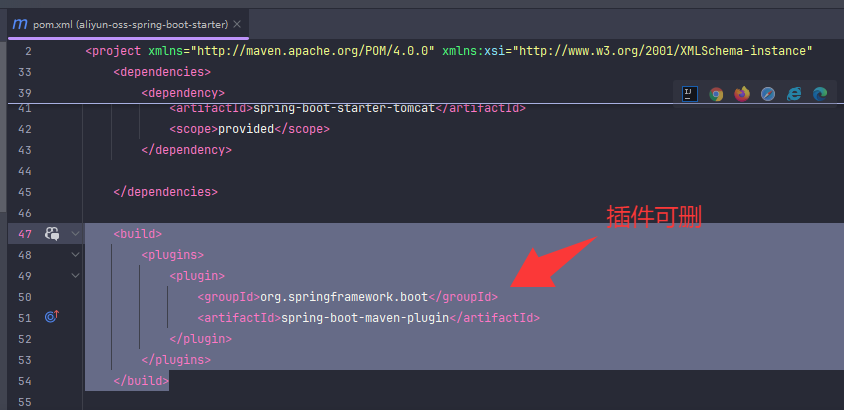
以下是maven高级
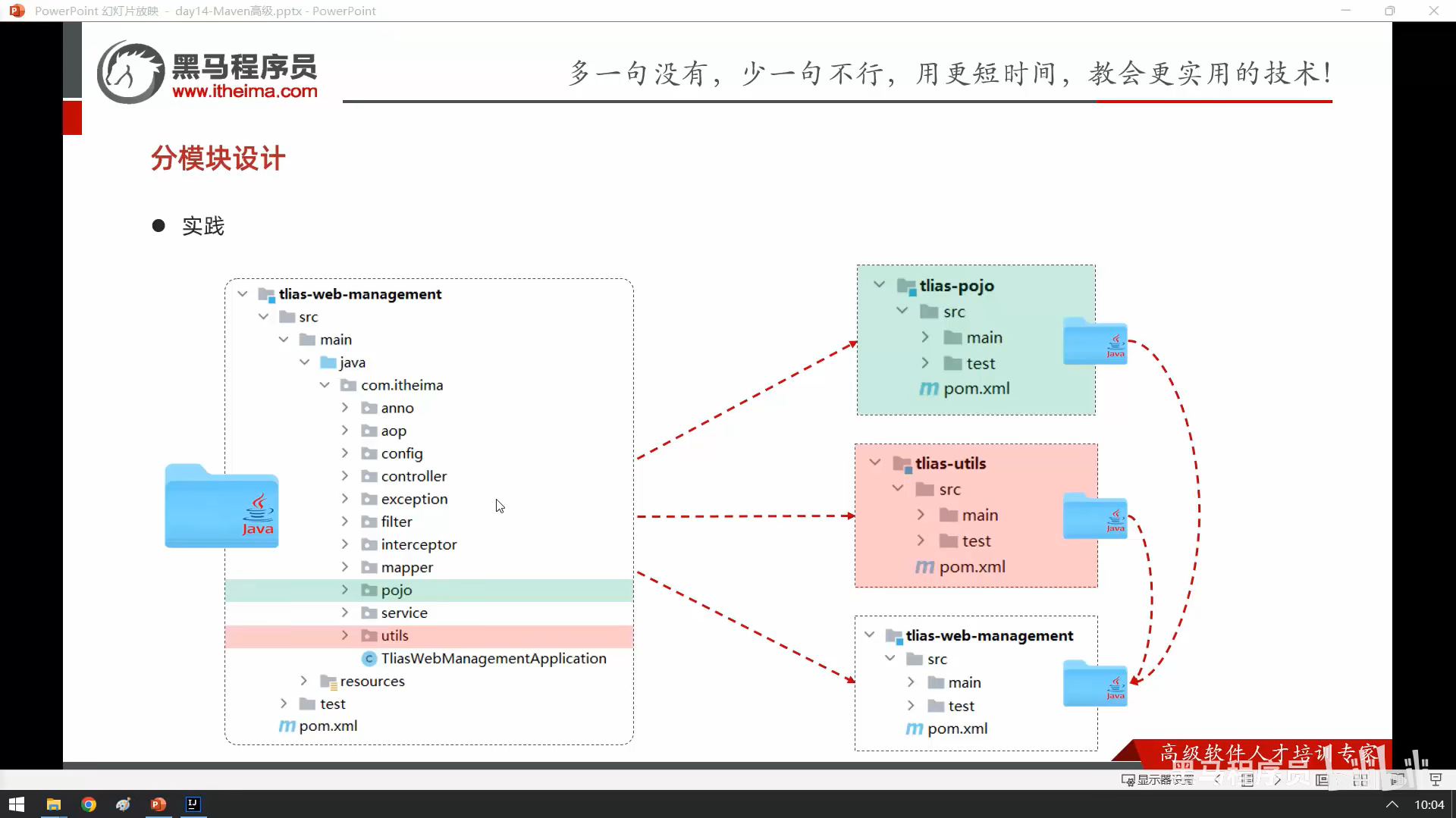
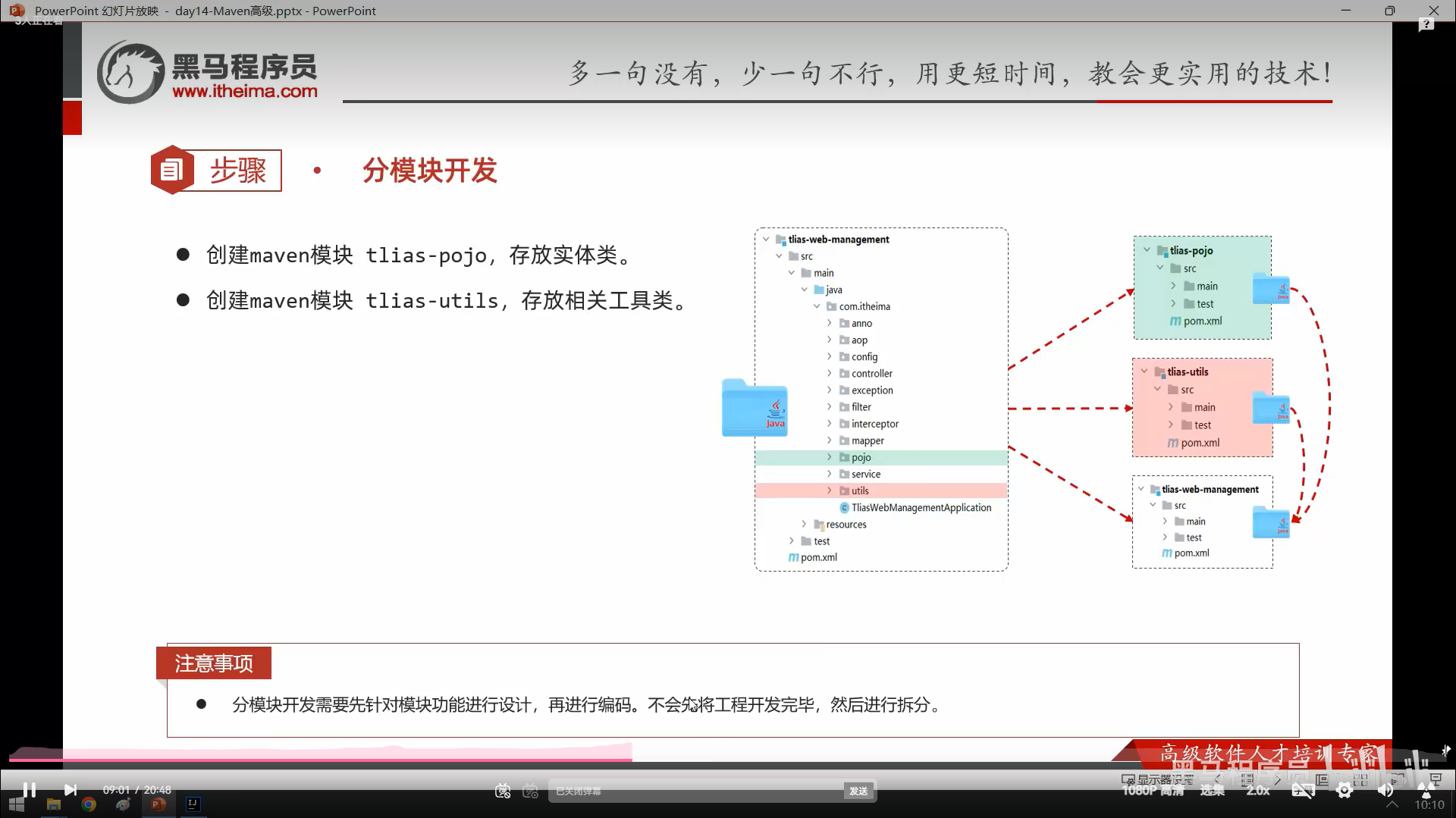
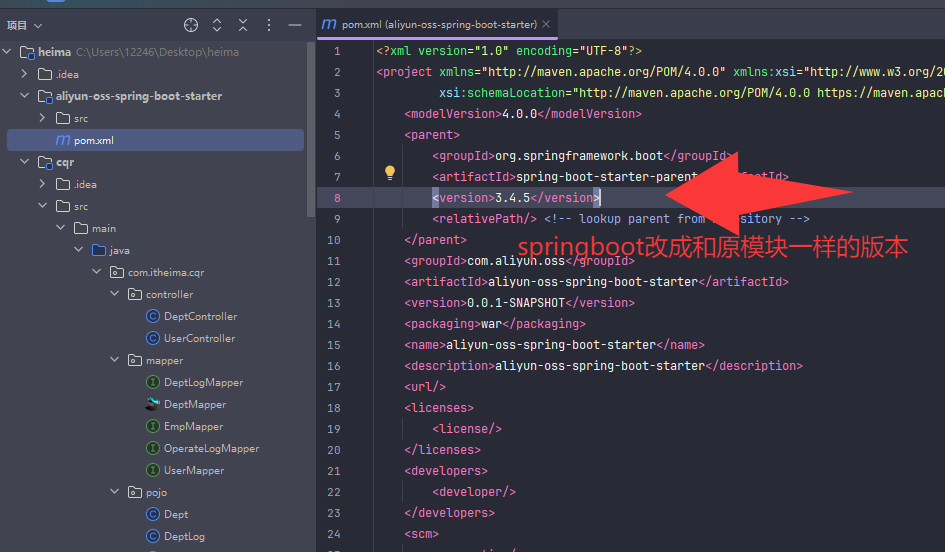
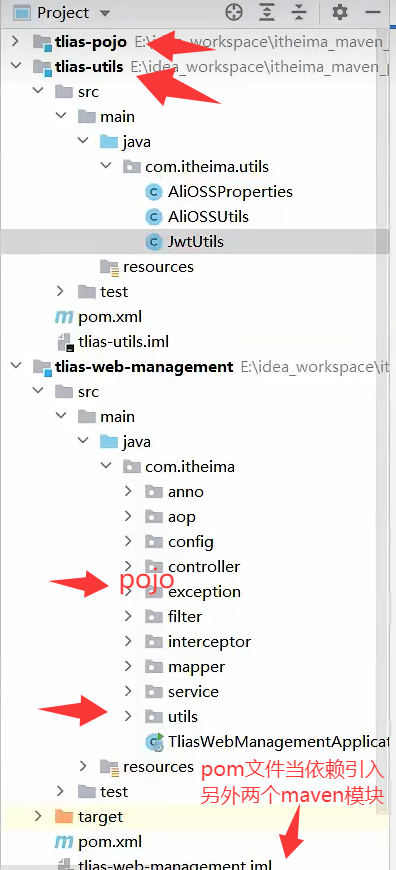
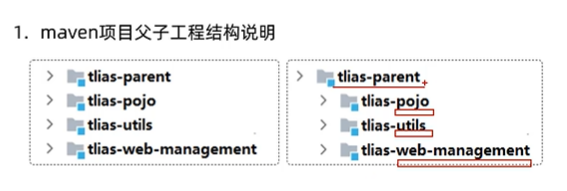
意思就是把原本项目的文件分开放到另外同项目里不同模块,
先在同一项目创建maven模块,
然后把原模块pojo文件转移到新建的maven模块,
然后新模块会有些标红,
这时候只要把对应依赖也一起转移就不标红了,
最后在原模块依赖里面引入这个新模块就能成功调用了,
utils文件也是同理
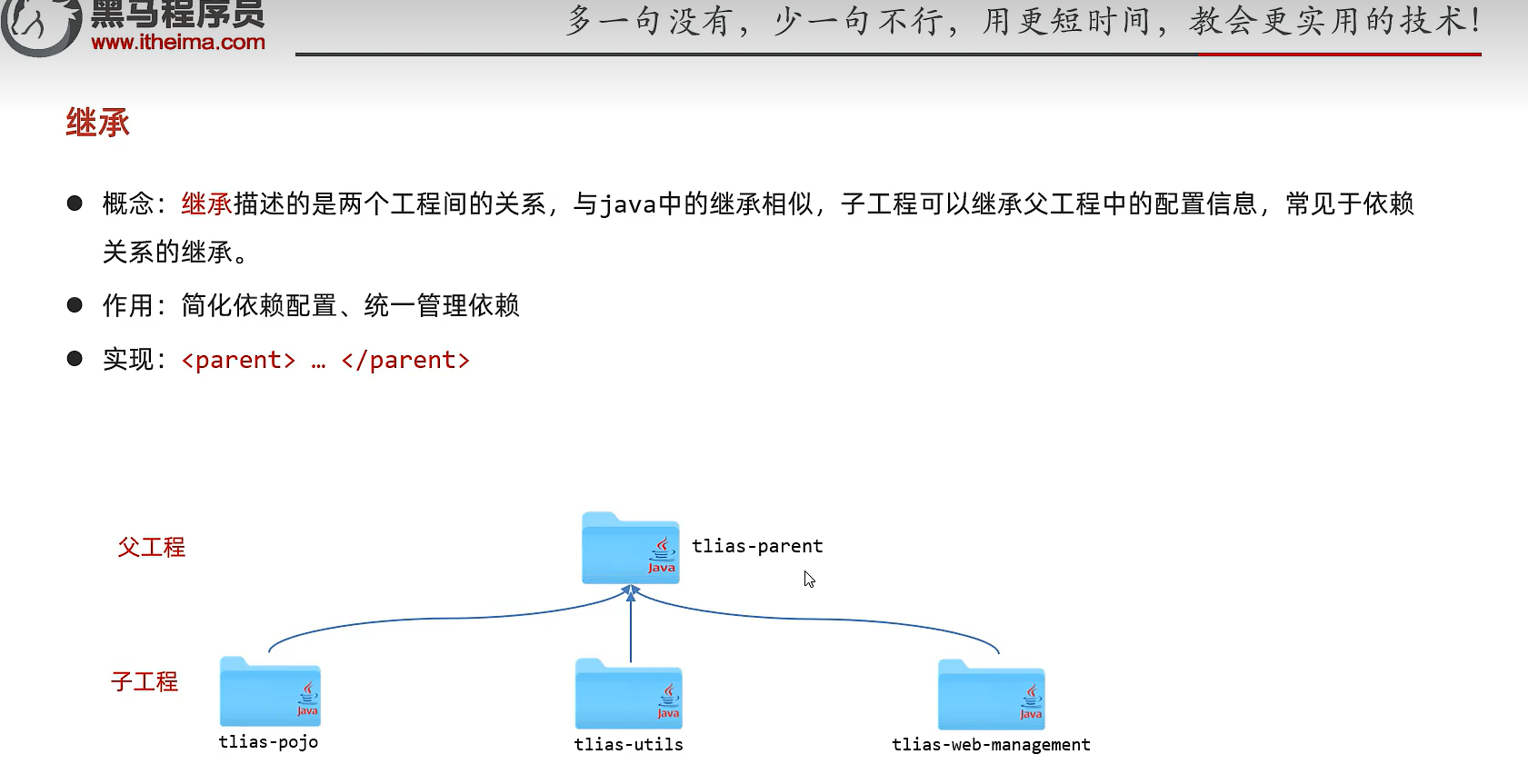
继承
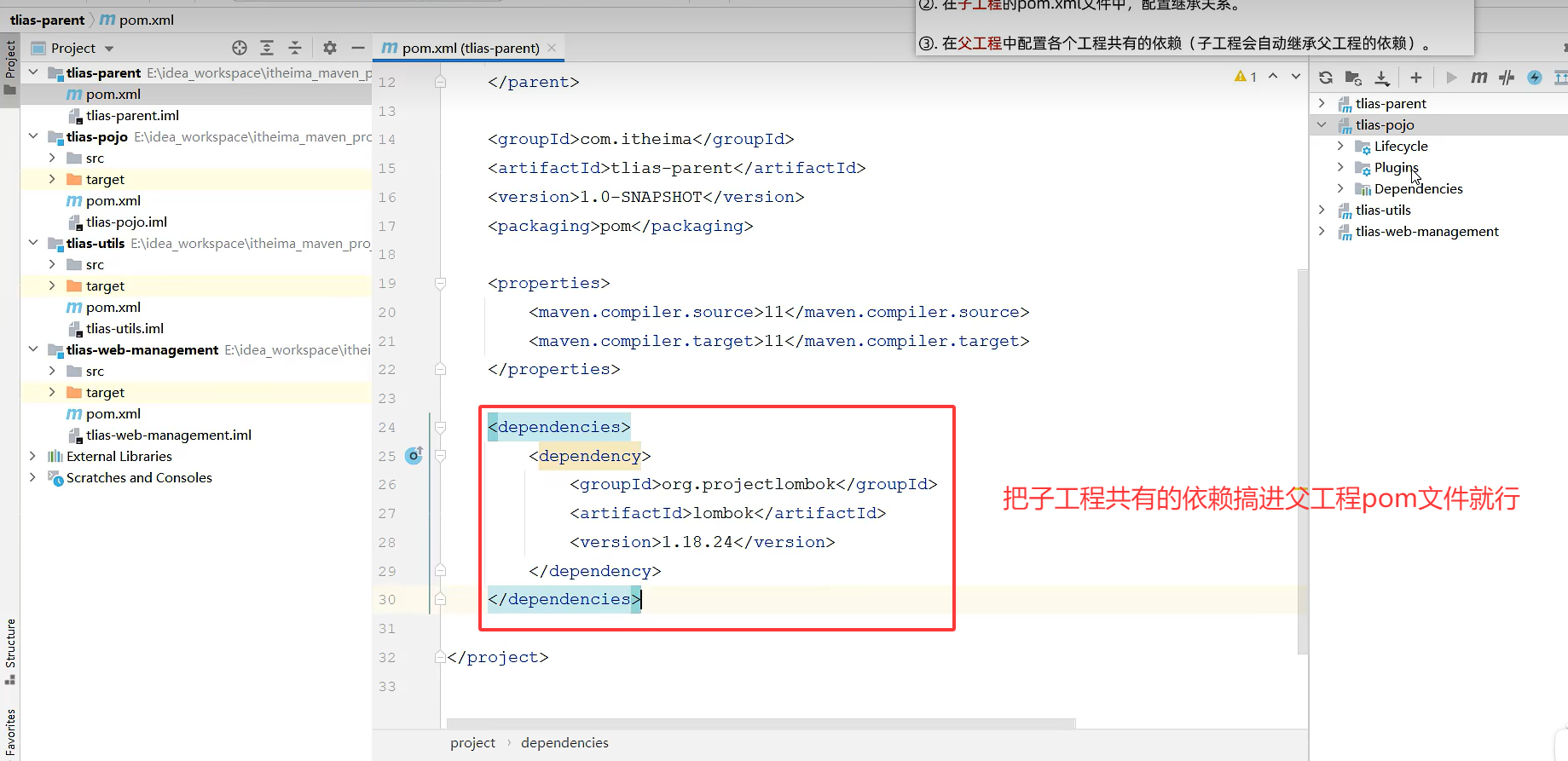
避免多个模块引用了相同代码造成代码冗余
(1)相同依赖问题

在同一项目创建maven模块父工程,此时parent(父工程)选项先为none
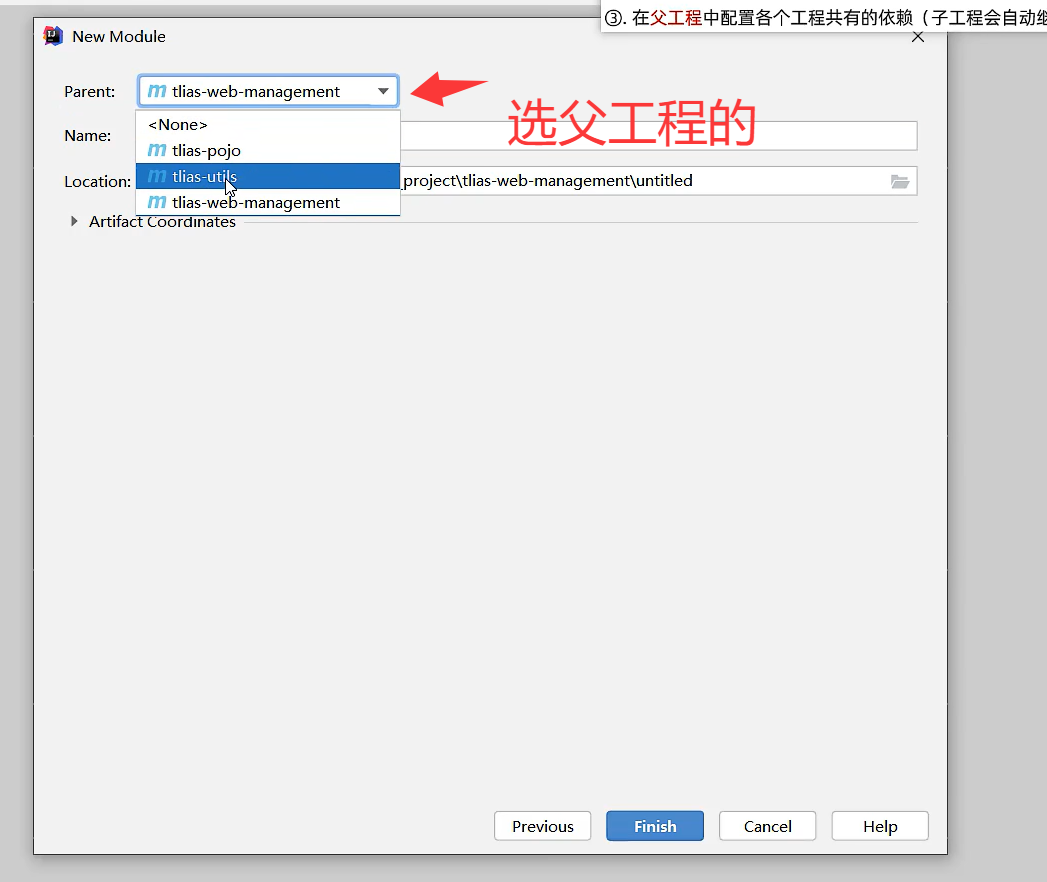
父工程依赖加个打包文件为pom
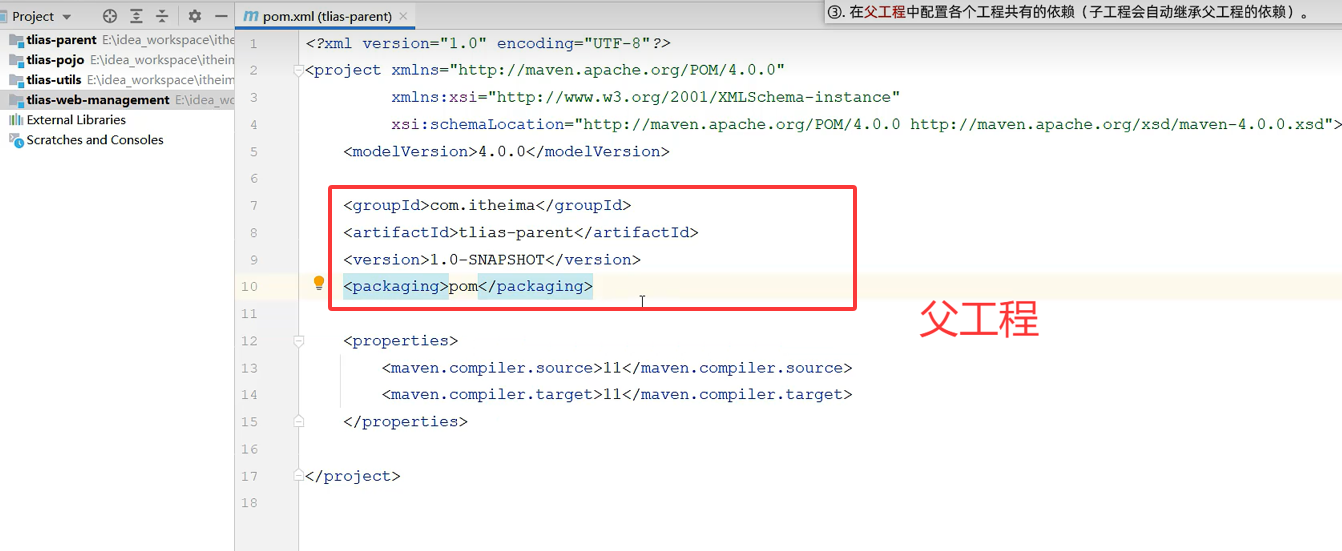
粘贴过来
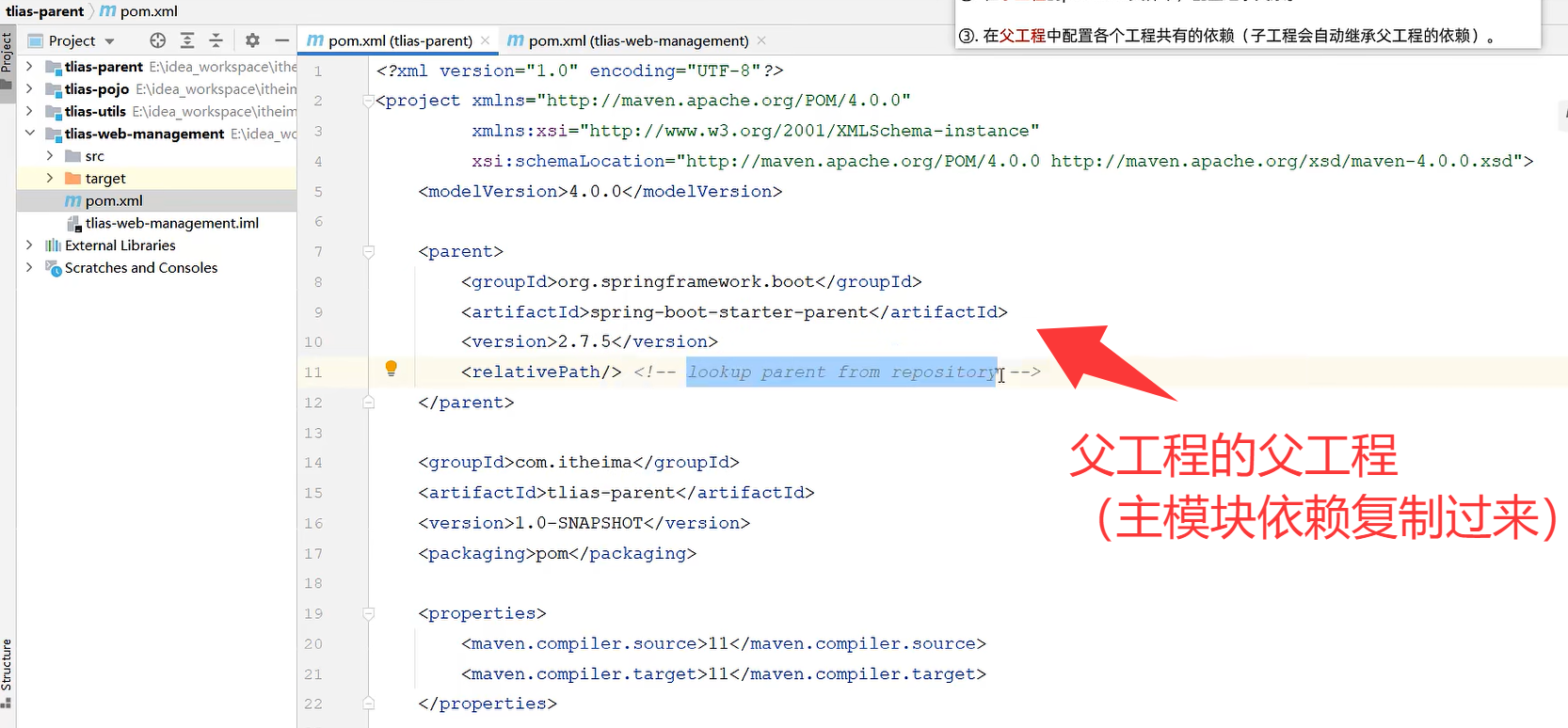
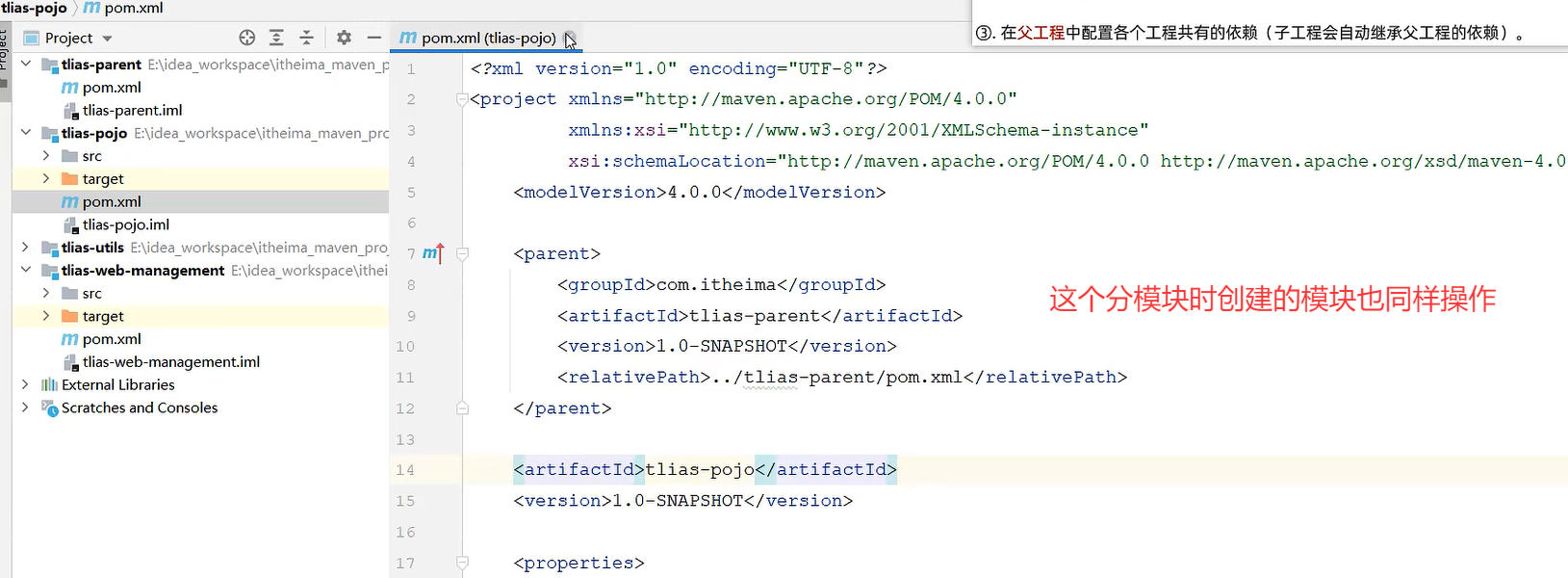
去子工程
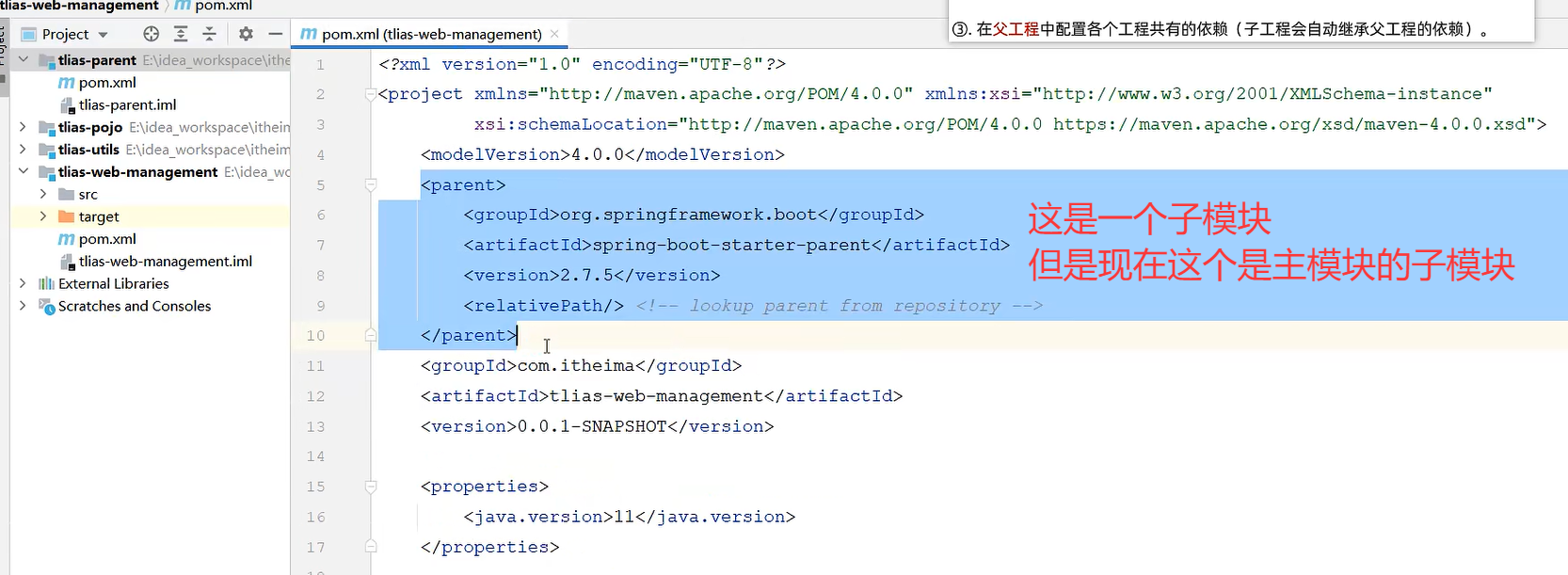
删了原来的parent
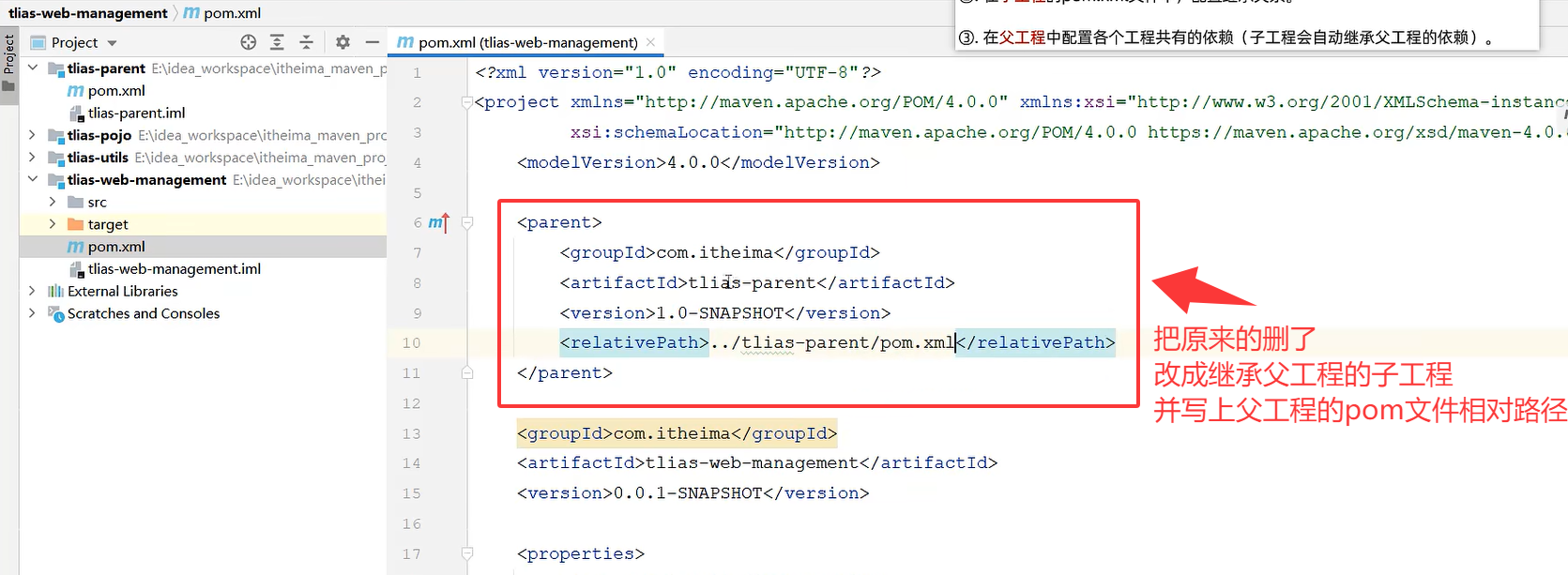
子工程的groupId报错的话删了就行因为子工程原本就继承父工程的groupId
最后


(2)非共有依赖版本问题

先把子工程的依赖搞进父工程的dependencyManagement标签里面
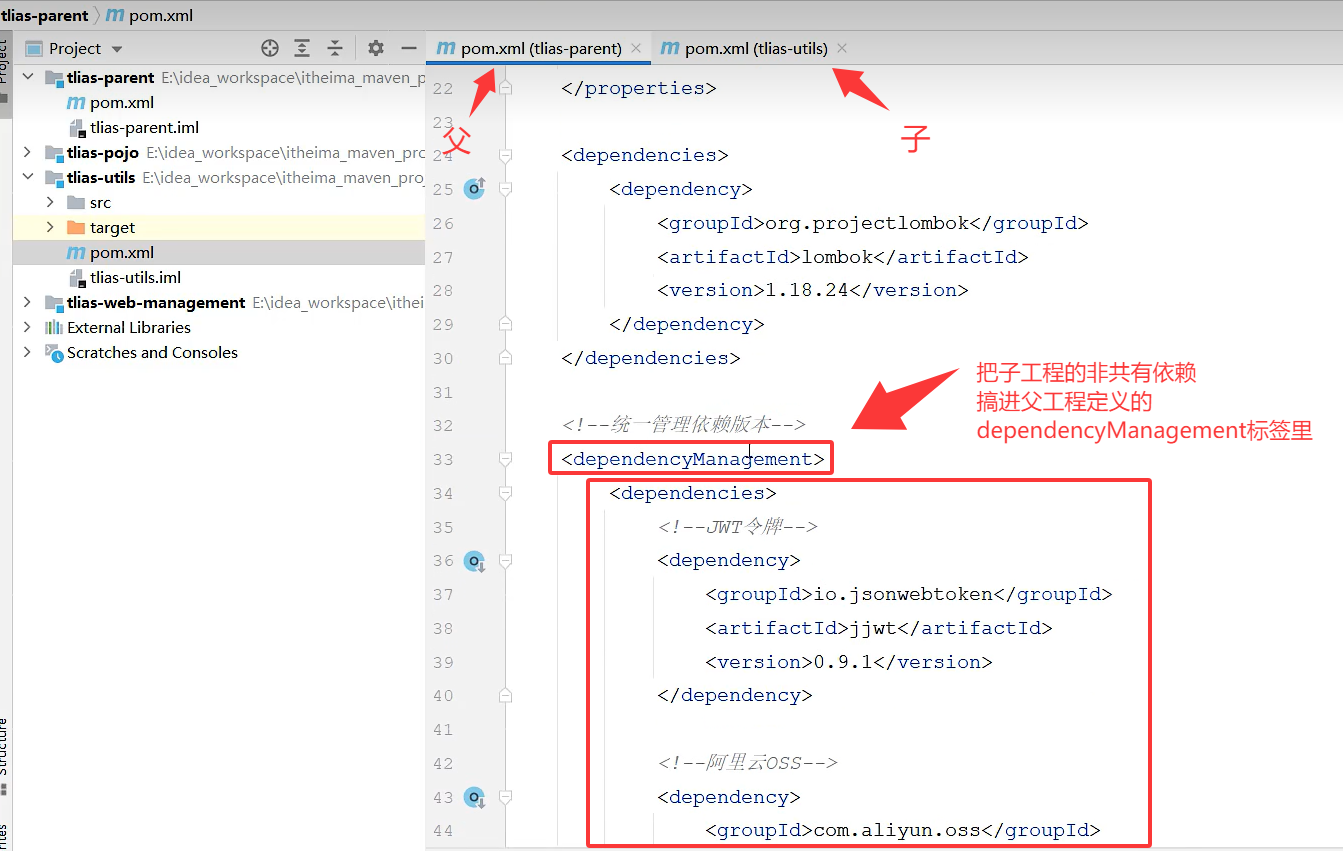
然后把子工程的依赖版本号删除

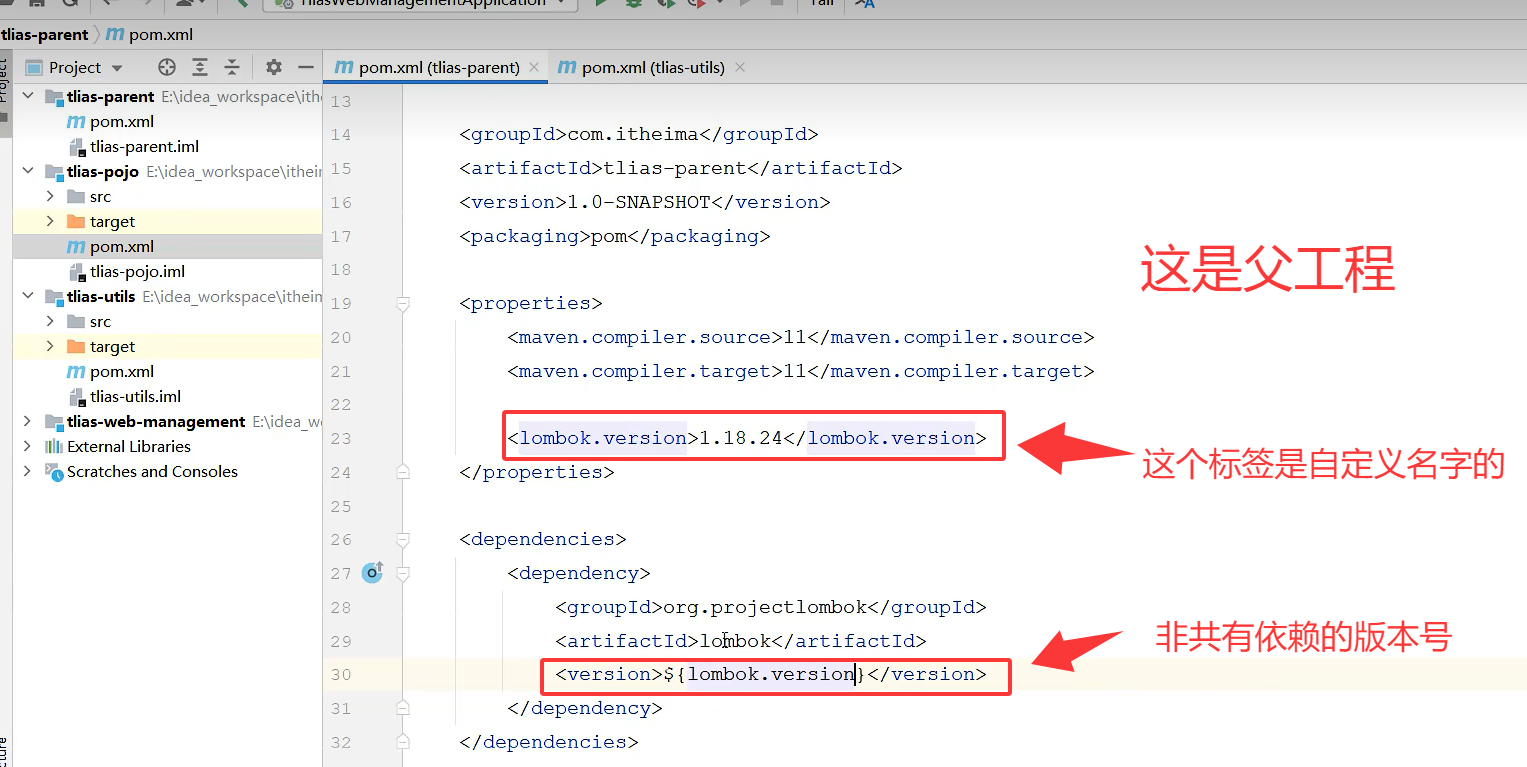
然后你就会发现父工程的依赖一多就会很难找,这时候就要在properties标签里面设置自定义标签控制版本号

以下是实践
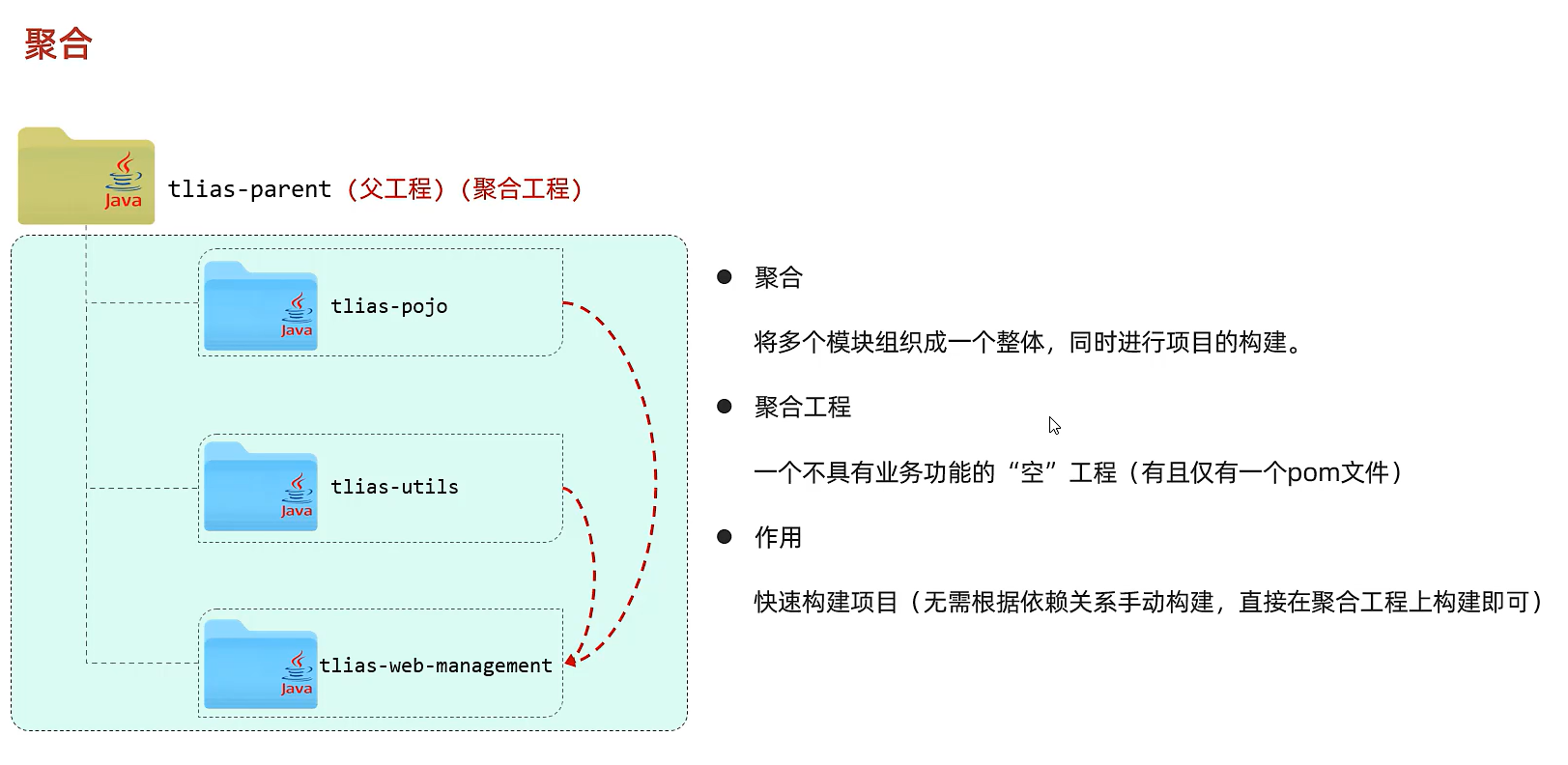
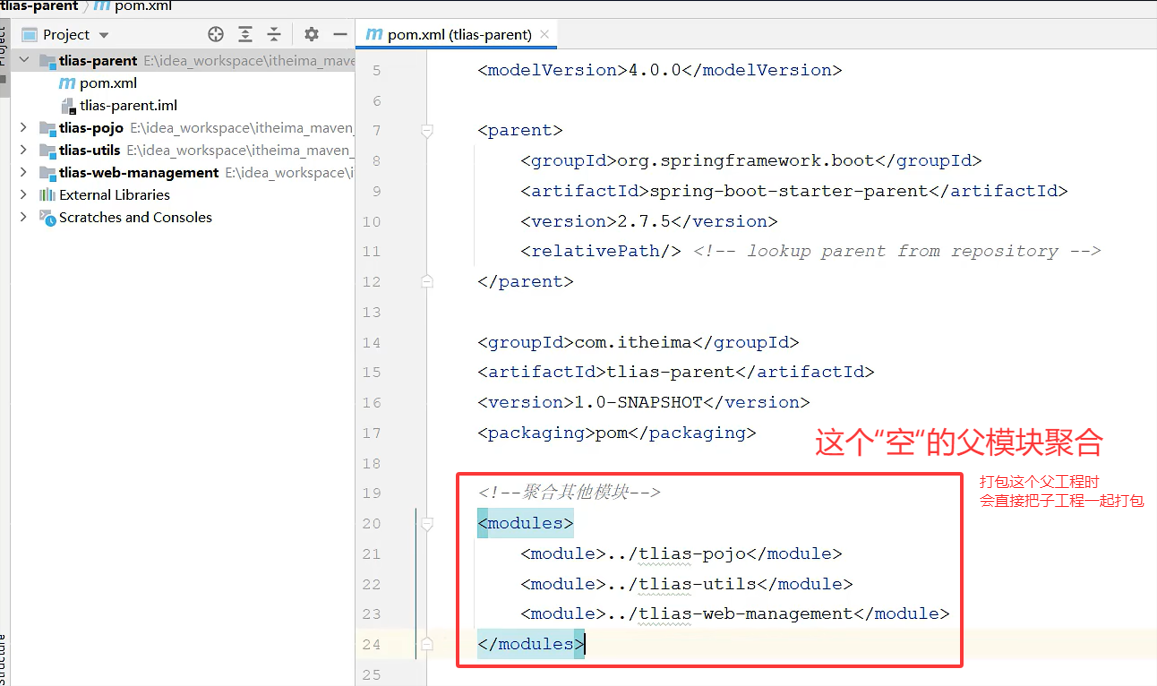
聚合(一起打包)
1
2

3
4

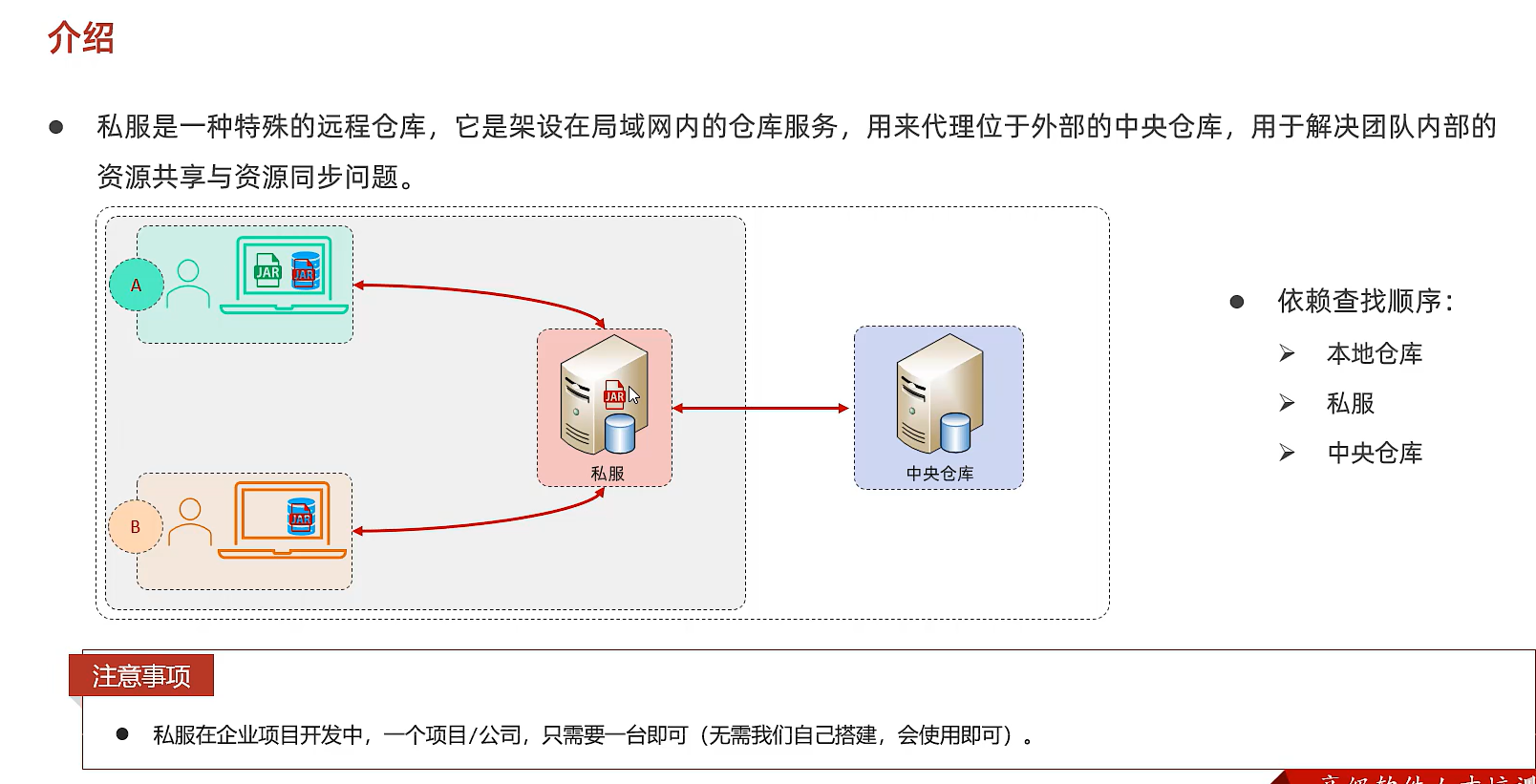
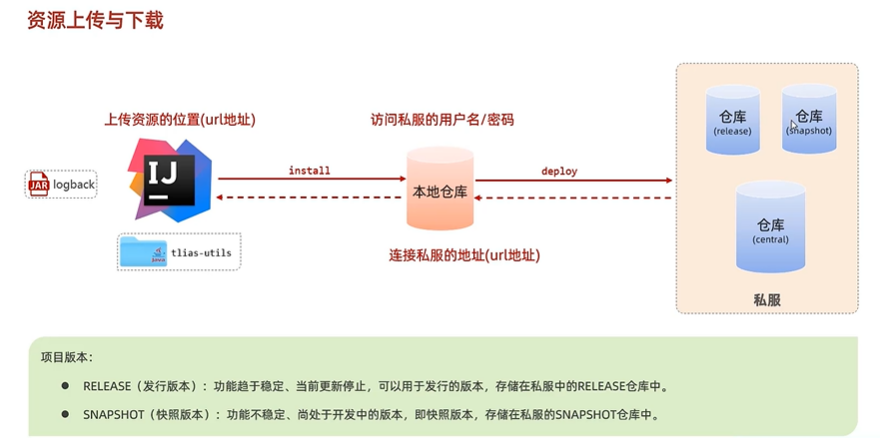
私服
1
2
3

4

5

6

7

8

9


 浙公网安备 33010602011771号
浙公网安备 33010602011771号