

KT-pFL
相比于其他pFL,KT-pFL将聚合过程制定成个性化的群体知识迁移训练算法,使每个客户端都能在服务器端保持个性化的软预测,以指导其他客户端的本地训练。
KT-pFL 通过使用知识系数矩阵对所有局部软预测进行线性组合 来更新每个客户的个性化软预测,这可以自适应地加强拥有相似数据分布的客户之间的协作。此外,为了量化每个客户对他人个性化训练的贡献,知识系数矩阵被参数化,以便它可以与模型同时训练。知识系数矩阵和模型参数在每一轮中都按照梯度下降方式交替更新。在不同设置(异构模型和数据分布)下对各种数据集 (EMNIST、Fashion_MNIST、CIFAR-10) 进行了广泛的实验。结果表明,所提出的框架是第一个通过参数化组知识迁移实现个性化模型训练的联邦学习范式,同时与最先进的算法相比实现了显著的性能提升。
联邦学习
可以在多个客户端之间协作训练共享的机器学习模型,而无需直接访问私有数据。通过定期聚合客户端的参数进行全局模型更新。(高精度和强泛化)
问题
用户本地数据集中的异质性🔜采用个性化模型即个性化联邦学习(pFL)。
KT-pFL
允许每个客户端在服务器上维护个性化的软预测,该预测可以通过使用知识系数矩阵的所有客户端的局部软预测的线性组合来更新。为了量化每个客户对另一个客户的个性化软预测的贡献,我们将知识系数矩阵参数化,以便它可以在每轮迭代中以交替的方式与模型同时训练。
KT-pFL打破了同构模型限制壁垒,即每轮都需要传输整个参数集,其数据量远大于软预测,而且还通过使用参数化更新机制提高了训练效率。
假设n个客户端,每个客户端只能接触到自己的私有数据集
xi是第i个数据样本,yi是xi对应的标签

其中 Ln(w) 是第 n 个客户端的本地损失函数,用于测量私有数据集Dn上的局部经验风险, LCE 是交叉熵损失函数,用于测量预测值与真实值标签之间的差异。
改进
设 s(wnx) 表示来自客户端 n 的协作知识,x 表示来自所有客户端都可以访问的公共数据集 Dr 的数据样本。定义客户端 n 的个性化损失函数为
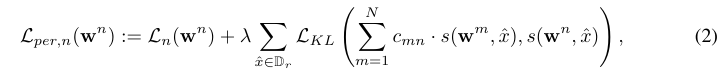
其中 入 > 0 是超参数,LKL 代表 Kullback-Leibler (KL) 发散函数,并添加到损失函数中,以将个性化知识从一位教师转移到另一位教师。CMN 是知识系数,用于估计客户 m 对 n 的贡献。
KT-pFL框架
- 对私有数据进行本地训练
- 3.各个客户端输出本地对公共数据的软预测并发给服务器。
- 服务器通过本地软预测和知识系数矩阵的线性组合计算每个客户的个性化软预测
- 每个客户端下载个性化软预测执行蒸馏阶段
知识蒸馏的关键在于如何传递知识。传统的训练是使用真实标签的hard targets,而知识蒸馏可能用到了教师模型输出的soft targets,也就是概率分布
- 服务器更新知识系数矩阵
![]()
不同情况下,知识既可以指软预测,也能指模型参数。

s(wn, x)可以认为是对客户n的软预测,用logits zn的softmax来计算,logits zn是客户n模型上最后一个完全连接层的输出,T是softmax函数的温度超参数

其中 为所有权重的连接向量,dn表示模型参数wN的维数。1∈Rn2是元素都等于1的单位矩阵。(4)中的第二项是保证整个学习系统泛化能力的正则化项。如果没有正则化项,数据分布完全不同的客户端往往会设置较大的知识系数值(即等于1),在这种情况下,训练过程中不会进行协作。ρ是一个大于0的正则化参数。
为所有权重的连接向量,dn表示模型参数wN的维数。1∈Rn2是元素都等于1的单位矩阵。(4)中的第二项是保证整个学习系统泛化能力的正则化项。如果没有正则化项,数据分布完全不同的客户端往往会设置较大的知识系数值(即等于1),在这种情况下,训练过程中不会进行协作。ρ是一个大于0的正则化参数。
KT-pFL Algorithm
提出了一种局部模型参数和知识系数矩阵交替更新的KT-pFL算法。为了实现FL中的个性化知识转移,我们根据相关的协作知识在本地训练个性化模型。将(2)插入(4)中,我们可以设计一种交替优化方法来求解(4),即在每轮中轮流固定w或c,交替优化未固定的w或c,直到到达一个收敛点。
在每一轮通信中,我们首先固定c并局部优化(训练)w几个epoch。在这种情况下,w的更新既依赖于私有数据(即Dn上的LCE, n∈[1,···,n]),也依赖于公共数据(即Dr上的LKL),这些私有数据只能被对应的客户端访问,而公共数据(即Dr上的LKL)则可以被所有客户端访问。👇


对于服务器:
把初始w0和c0给客户端,在每轮通信中:让每个客户端并行算wn t+1,就是自己的wn,更新知识系数矩阵c并把c t+1告诉所有客户端。
对于客户端:
客户端n收到服务器发的wn t和cn,每个本地epoch都进行小批量训练并上传。对于每个蒸馏步骤小批量训练再对公共数据更新参数。
local training: 通过应用梯度下降步骤对每个客户端的私有数据进行训练。
式中,ξn为局部训练中使用的小批数据Dn。η1为学习率。

distillation:蒸馏:将知识从个性化软预测转移到基于公共数据集的每个本地客户端;
式中,ξr为公共数据的小批量Dr, η2为学习率。c∗m = [cm1, cm2,···,cmN]为客户m的知识系数向量,可在c的第m行找到。注意,这一阶段需要所有的协作知识和知识系数矩阵来获得个性化软预测,这些知识和知识系数矩阵可在服务器中收集。

update c:在本地更新了几个epoch之后,我们转向固定w并在服务器中更新c。
η3是更新c的学习率。
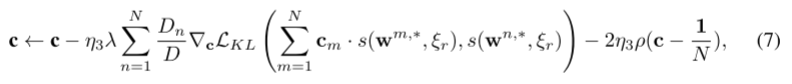
算法1演示了提出的KT-pFL算法,其背后的思想如图1所示。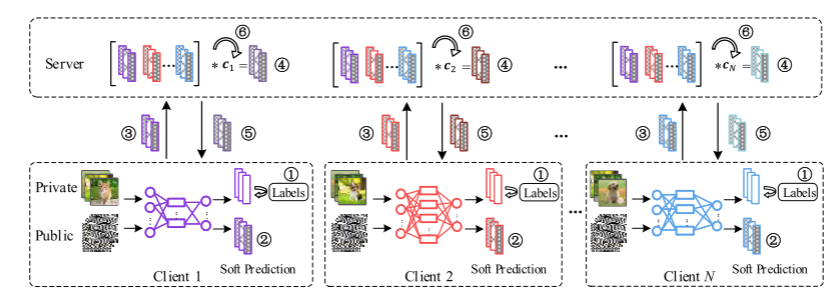
在每一轮通信训练中,客户端使用本地SGD基于私有数据训练多个epoch,然后将协作知识(例如对公共数据的软预测)发送给服务器。服务器接收到来自各个客户端的协作知识后,根据知识系数矩阵对其进行聚合,形成个性化的软预测。然后,服务器将个性化的软预测发送回每个客户端,以执行本地蒸馏。然后,客户端在公共数据集2上迭代多个步骤。然后,在服务器端更新知识系数矩阵,同时确定模型参数w。
Evaluation
Task and Datasets
在三个不同的图像分类任务:EMNIST[35]、Fashion_MNIST[36]和CIFAR-10[37]上评估了提出的训练框架。对于每个数据集,应用两种不同的Non-IId数据设置:1)每个客户端只包含两类样本;2)每个客户端包含所有类别的样本,而每个类别的样本数量与不同客户端不同。所有的数据集被随机分割,训练和测试的比例分别为75%和25%。每个客户机上的测试数据与其训练数据具有相同的分布。对于所有方法,我们记录了所有局部模型的平均测试精度进行评估
Model Structure
实验采用了LeNet[38]、AlexNet[39]、ResNet-18[40]和ShuffleNetV2[41]四种不同的轻量级模型结构。我们的pFL系统有20个客户端,它们被分配到4个不同的模型结构中,即每个模型5个客户端。
Baseline
我们将KT-pFL的性能与基于非个性化蒸馏的方法(FedMD [13], FedDF[16])和基于个性化蒸馏的方法(pFedDF3)以及其他简单版本的KT-pFL (Sim-pFL和TopK-pFL)进行了比较。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号