

Pandas数据结构(二)——Pandas DataFrame
上回简单介绍了Pandas Series,我们了解到Series对象是一维标签(索引)数组,能够保存不同的数据类型,比如整型,浮点型,字符串或其他Python对象类型。
这次要介绍的是Pandas的另一种数据结构——Pandas DataFrame。DataFrame是一个二维标签的数组对象,和Series一样,DataFrame能接受不同类型的数据输入。
DataFrame包含行索引和列索引,你可以将它简单理解为类似于数据库表的结构,或者是包含字典类型的Series。
一、创建DataFrame对象
创建DataFrame对象的方式很多,主要有以下几种:
1.由包含ndarray或列表的字典构造
ndarray或列表的长度必须一致,相应地,传递的索引长度也必须与数组的长度相同。
import pandas as pd data = {'a':[1, 2, 3, 4], 'b': [5, 6, 7, 8], 'c': [9, 10, 11, 12]} pd.DataFrame(data)
运行结果:
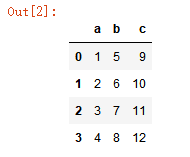
添加索引:
df=pd.DataFrame(data, index=['one', 'two', 'three', 'four']) df
运行结果:

还可以通过访问index和columns属性来访问行列标签:
df.index
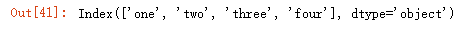
df.columns
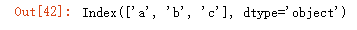
2.由包含Series的字典或嵌套字典构造
data1 = {'a': pd.Series([1, 2, 3]),
'b': pd.Series([1, 2, 3, 4]),
'c': pd.Series([1, 2, 3, 4, 5])}
pd.DataFrame(data1)
运行结果:

注意:NaN代表缺失的数据。
添加索引:
data1 = {'a': pd.Series([1, 2, 3], index=['one', 'two', 'three']),
'b': pd.Series([1, 2, 3, 4], index=['one', 'two', 'three', 'four']),
'c': pd.Series([1, 2, 3, 4, 5], index=['one', 'two', 'three', 'four', 'five'])}
pd.DataFrame(data1)
运行结果:
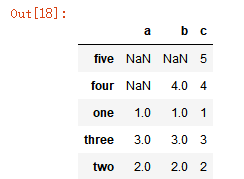
pd.DataFrame(data1, index=['five', 'four', 'three'])

pd.DataFrame(data1, index=['five', 'four', 'three'], columns=['b', 'c', 'd'])

3.由包含字典的列表构造
data2 = [{'a': 1, 'b': 2, 'c': 3},
{'a': 4, 'b': 5, 'c': 6},
{'a': 7, 'b': 8, 'c': 9, 'd': 10}]
pd.DataFrame(data2)
运行结果:
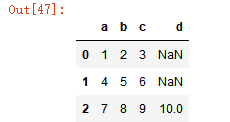
pd.DataFrame(data2, index=['one', 'two', 'three'], columns=['a', 'b', 'd'])

除了上面几种创建DataFrame对象的方法,还可以使用数组、元组等方式构造,方法比较类似,这里不作赘述。
二、对DataFrame对象的列的操作
类似于字典操作,对一个DataFrame对象可以进行获取列的值、对列赋值或删除列的操作。
我们以上述df为例,对该对象的列进行操作。
# 获取Name为a的列的值 df['a']

# 获取Name为a的列的值并对值进行计算 df['a']*3-2

# 对列值进行计算 df['d'] = df['a'] + df['b'] df['TF'] = df['d'] > 9 df
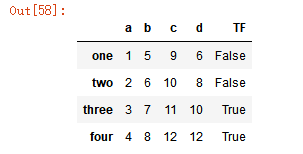
# 删除列 del df['TF'] df

# 取出列 pt = df.pop('d') df

# 被取出的列 pt

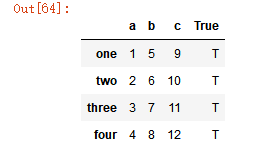
# 当插入一个标量值时,它会自动填满整列 df['True'] = 'T' df

 浙公网安备 33010602011771号
浙公网安备 33010602011771号