
强化学习(一)基础概念
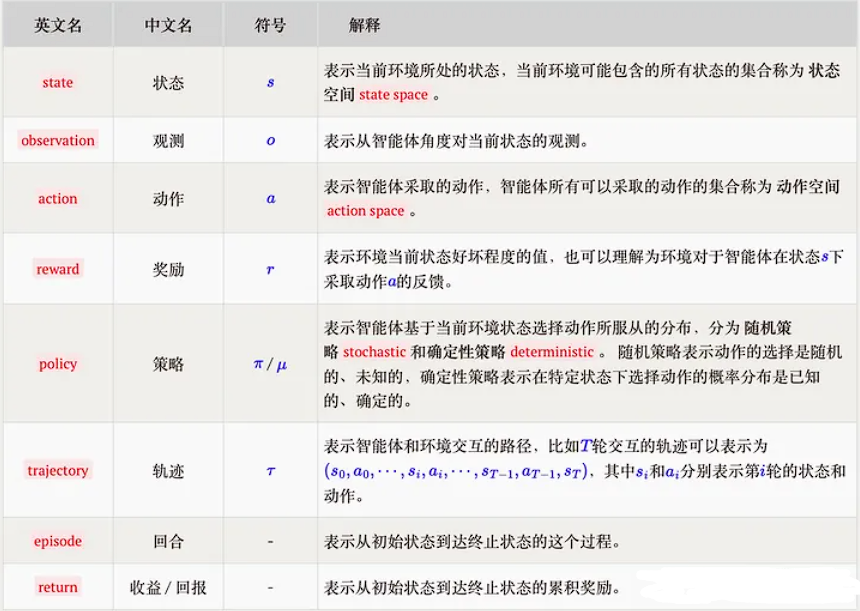
1、相关概念
state:状态,S,表示当前环境所处的状态,当前环境可能包含的所有状态的集合称为状态空间state space。
observation:观测值,O,表示从智能体角度对当前状态的观测。
action:动作,a,表示智能体采取的动作,智能体可以采取的动作的集合称为动作空间action space。
reward:奖励,r,表示环境对于agent在当前state下采取action的反馈。
policy:策略,π/μ,表示agent基于当前state选择action所服从的分布,分为随机策略(随机的、未知的)和确定性策略(已知的、确定的)。
trajectory:轨迹,τ,表示agent和envir交互的路径,(S0,A0,S1,A1...,ST)。
episode:回合,表示从初始状态到终止状态的过程。
return:收益/回报,表示从初始状态到终止状态的累计奖励。
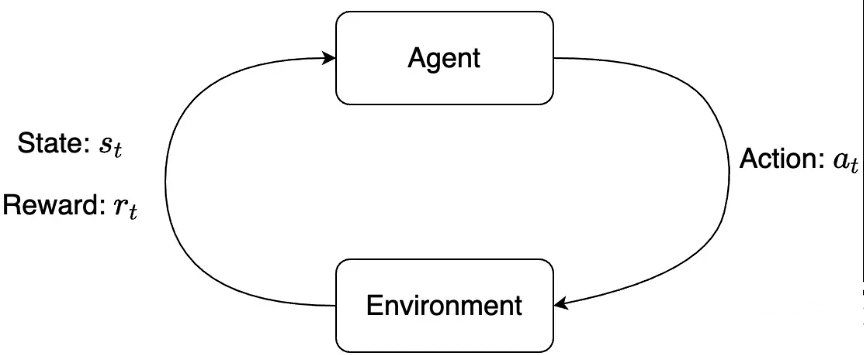
强化学习中两个核心的概念就是:agent和environment。环境表示智能体生存以及交互的世界。每一次交互时,智能体会观察到世界当前所处state的observation,然后决定采取什么action。环境会随着智能体的动作而发生变化,当然环境自身也可能一直处于变化中。智能体会从环境中接收到一个「奖励」reward信号,这个信号可能是一个数值,表示当前环境所处状态的好坏。智能体的目标是:最大化「累积奖励」cumulative reward,也称为「收益」return。强化学习方法就表示智能体通过学习行为来达到这个目标的途径。
2、术语详细理解
智能体状态和观测:「状态」是对环境当前所处环境的完整描述,对于状态来说环境的所有信息都是可知的。而「观测」则是一个状态的部分描述,可能会忽略一些信息。在深度强化学习中,我们通常会使用实值向量vector、矩阵matrix或者高维张量tensor来表示状态和观测。比如,视觉的观测可以表示为像素值构成的RGB矩阵,机器人的状态则可以表示为其关节角度和速度。当智能体能够观测到环境的全部状态时,这样的环境是可完全观测的fully observed;当智能体只能观测到部分状态时,这样的环境称为可部分观测partially observed。
「注」:在强化学习的公式中我们经常会看到表示状态的符号s,但是实际上更准确的用法应该是使用表示观测的符号o。比如,当我们探讨智能体如果进行动作决策时,公式中通常会说动作是基于状态的,但是「实际上动作是基于观测的」,因为智能体是无法直接感知到状态的。为了遵循惯例,之后的公式仍然会使用符号s。
动作空间:
「给定的环境中有效的动作集合称为动作空间」。有些环境中(比如Atari和Go):
「动作空间是离散的」discrete,也就是说智能体的动作数量是有限的;而有些环境中(比如机器人控制)
「动作空间是连续的」continuous,这些空间中动作通常用实值向量表示。 「动作空间是离散的还是连续的」在强化学习问题中非常重要,有些方法只适合用于其中 一个场景,所以这点需要特别关注。
策略:「策略表示智能体决策采取哪种动作的规则」。策略可以是确定性的deterministic,「确定性策略」通常使用μ表示,即:
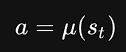
也可以是随机的stochastic,「随机性策略」通常使用π表示,即:
![]()
由于策略是智能体的“大脑”,所以在一些表述中会直接用策略来指代智能体,比如This policy is trying to maximize reward。在强化学习问题中,我们经常会面 对「参数化的策略」parameterized policies,即:策略是指基于一些参数(比如神经网络的权重和偏置)的可计算函数,我们可以通过优化算法来调节这些参数从而改变智能体的行为。我们通常将策略中的参数表示为θ或者Φ,然后将这种表示符号作为策略符号的下标来强调这种关联。
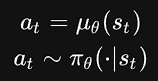
确定性策略 举个例子,我们可以用一个神经网络来表示一个连续动作空间简单的确定性策略:
pi_net = nn.Sequential(
nn.Linear(obs_dim, 64),
nn.Tanh(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, act_dim))
通过这个神经网络就可以基于观测的表征obs来得到其对应的动作。
obs_tensor = torch.as_tensor(obs, dtype=torch.float32)
actions = pi_net(obs_tensor)
随机性策略
强化学习中有两种常见的随机性策略:
分类策略categorical policy:用来离散动作空间问题
对角高斯策略diagnoal Gaussian policy:用于连续动作空间问题
随机性策略的训练涉及两个关键问题:
从策略中采样sampling动作
计算特定动作的对数似然log![]()
离散动作空间:分类策略可以看做离散动作空间的分类器 —— 输入是观测,经过一些神经网络层,输出每个动作的logits,最后用softmax转化为每一个动作的概率probability。
「采样」:给定每一个动作的概率,可以使用Pytorch或者Tensorflow中的一些采样函数进行采样,比如Categorical distributions in PyTorch,torch.multinomial, tf.distributions.Categorical或者tf.multinomial。
「对数似然」:把最后输出的动作的概率分布表示为![]() ,这是一个概率向量,向量的索引就表示动作。所以,动作a的对数似然就可以基于其在概率向量中索引对应的值来计算:
,这是一个概率向量,向量的索引就表示动作。所以,动作a的对数似然就可以基于其在概率向量中索引对应的值来计算: ![]()
连续动作空间
一个多变量高斯分布可以描述为均值向量μ以及协方差矩阵Σ。对角高斯分布则是其中的一种特殊情形,此时协方差矩阵Σ只有对角为非零值,所以也可以表示为一个向量。
对角高斯策略通常需要使用一个神经网络将观测映射为动作分布均值向量![]() ;协方差矩阵则通常有两种不同的计算方式:
;协方差矩阵则通常有两种不同的计算方式:
将对数标准差logσ直接作为参数,和状态无关
使用一个神经网络根据观测将对数标准差log![]() 映射为向量,此时标准差向量和状态相关,也可以和均值网络共享部分参数
映射为向量,此时标准差向量和状态相关,也可以和均值网络共享部分参数
「注」:「无论通过哪种方式都是计算对数标准差而不是标准差」。这是因为对数标准差的值域是(−∞,∞),而标准差必须是非负的。一般来说,不对输出做过多约束的神经网络更容易训练。同时,在得到对数标准差之后,通过指数运算很容易就能得到标准差
通俗理解
- 确定性策略:相当于训练过程中的利用
exploitation,对应的操作是argmax - 随机性策略:相当于训练过程中的探索
exploration,对应的操作就是采样
奖励:
奖励函数在强化学习问题中至关重要,它通常取决于环境的当前状态,当前采取的动作以及下一个状态
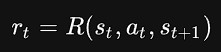
不过很多时候奖励函数也会简化为只取决于当前状态或者「状态-动作对」
收益:
智能体的目标是最大化轨迹的累计奖励。累积收益存在两种情况:
- 「有限范围下的无折扣收益」
finite-horizon undiscounted return:这种情况下,累计收益就是固定窗口中奖励的和 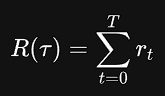
- 「无限范围下的折扣收益」
infinite-horizon discounted return:表示智能体之前得到的所有奖励的和,但是会基于奖励距离当前时刻的距离使用折扣因子进行加权,所以表达式中会包含一个折扣因子γ∈(0,1): 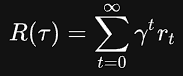
- 既然我们想要优化的是所有奖励的和,为什么还要使用折扣因子呢?直觉上来看,距离当前位置越近的对当前位置的影响越大。数学角度分析,无限范围奖励求和有可能无法收敛到一个有限值,并且在公式中也很难处理,所以需要折扣因子以及特定的条件才能保证无限和收敛。实际上,强化学习算法通常会模糊无折扣收益和折扣收益的区别,比如我们通常在构建算法时优化的是无折扣收益,但是在估计价值函数时使用的是折扣收益。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号