【Java学习】IO流 read( )原理困惑
在学习IO流读写文件时不清楚这个while循环存在的必要。
误以为read是把路径文件中的内容传入b中 再输出 输出的内容多少有数组长度决定 于是便有了第一张图。
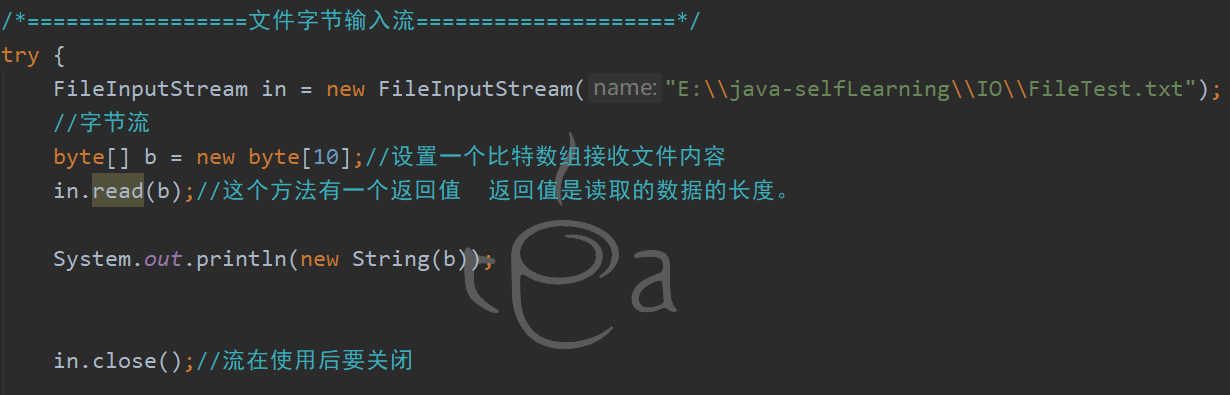
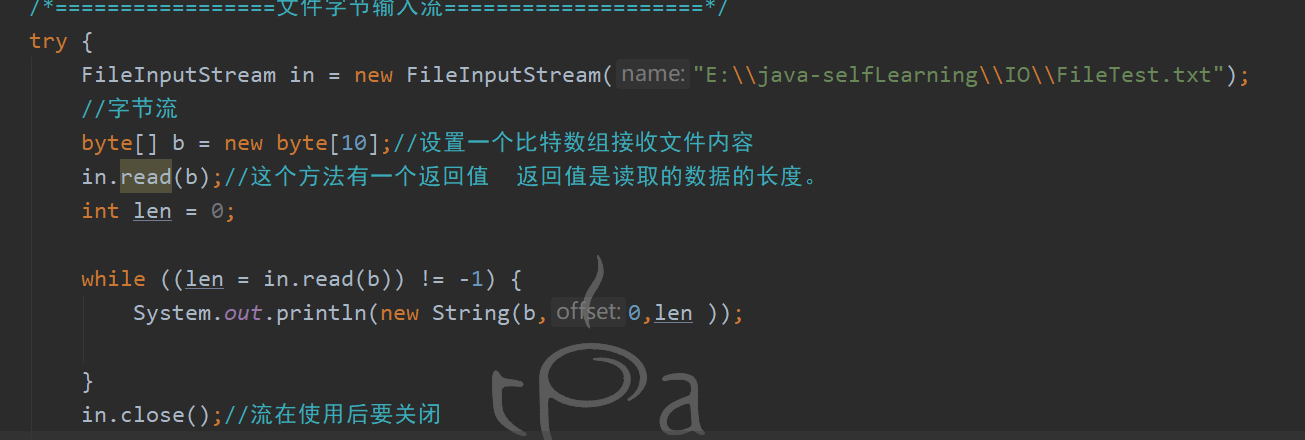
随着内容改变 数组内的值需要不断变化。就很麻烦 于是


查阅api发现 数组时决定最多读取数目的。
那我直接改大了 不久能读到下边的数字吗?
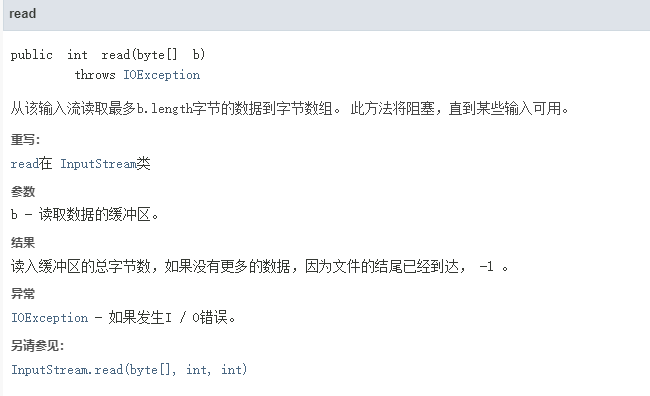
困惑之际 发现了六年前的知乎问题

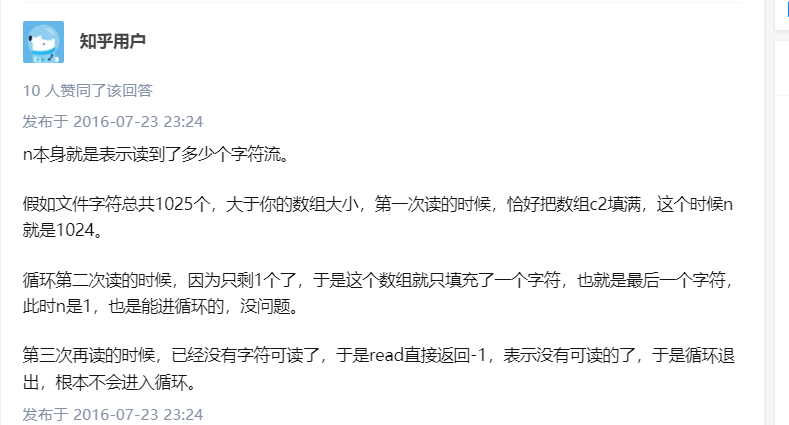
豁然开朗
try { FileInputStream in = new FileInputStream("E:\\java-selfLearning\\IO\\FileTest.txt"); //字节流 byte[] b = new byte[10];//设置一个比特数组接收文件内容 in.read(b);//这个方法有一个返回值 返回值是读取的数据的长度。 int len = 0; while ((len = in.read(b)) != -1) { System.out.println(new String(b,0,len )); } in.close();//流在使用后要关闭 }
read(b [ i ])
i 决定了一次能读到的数目
b 读取数据的缓冲区 换句话说 接收数据即文件内容
return b的长度 或者 文件到达末尾 返回-1
假设i = 10;
第一次读10个 并把1-10个字节的内容传给b[ ] 返回10 len = 10 != -1成立 输出b[0 - 9] 的内容
第二次读10个 并把11-20个字节的内容传给b[ ] 返回10 len = 10 !=-1 成立 输出 b[0 - 9] 的内容 此时的 b 已经赋了11-20的内容
重复上列操作
直到read 返回-1 结束循环。
这样就不会需要总是改变b数组的大小 就能把所有内容读出来
什么弱智问题 服了我自己了
写起来都觉得弱智 不就是一个循环吗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号