Unifying VL Tasks:Transformer 与大模型
1 Transformer Encoder
Transformer 诞生于 2017 年。最初始的 Transformer 用于机器翻译。
Encoder(编码器)是为了处理一个输入的语句。
1.1 自注意力机制
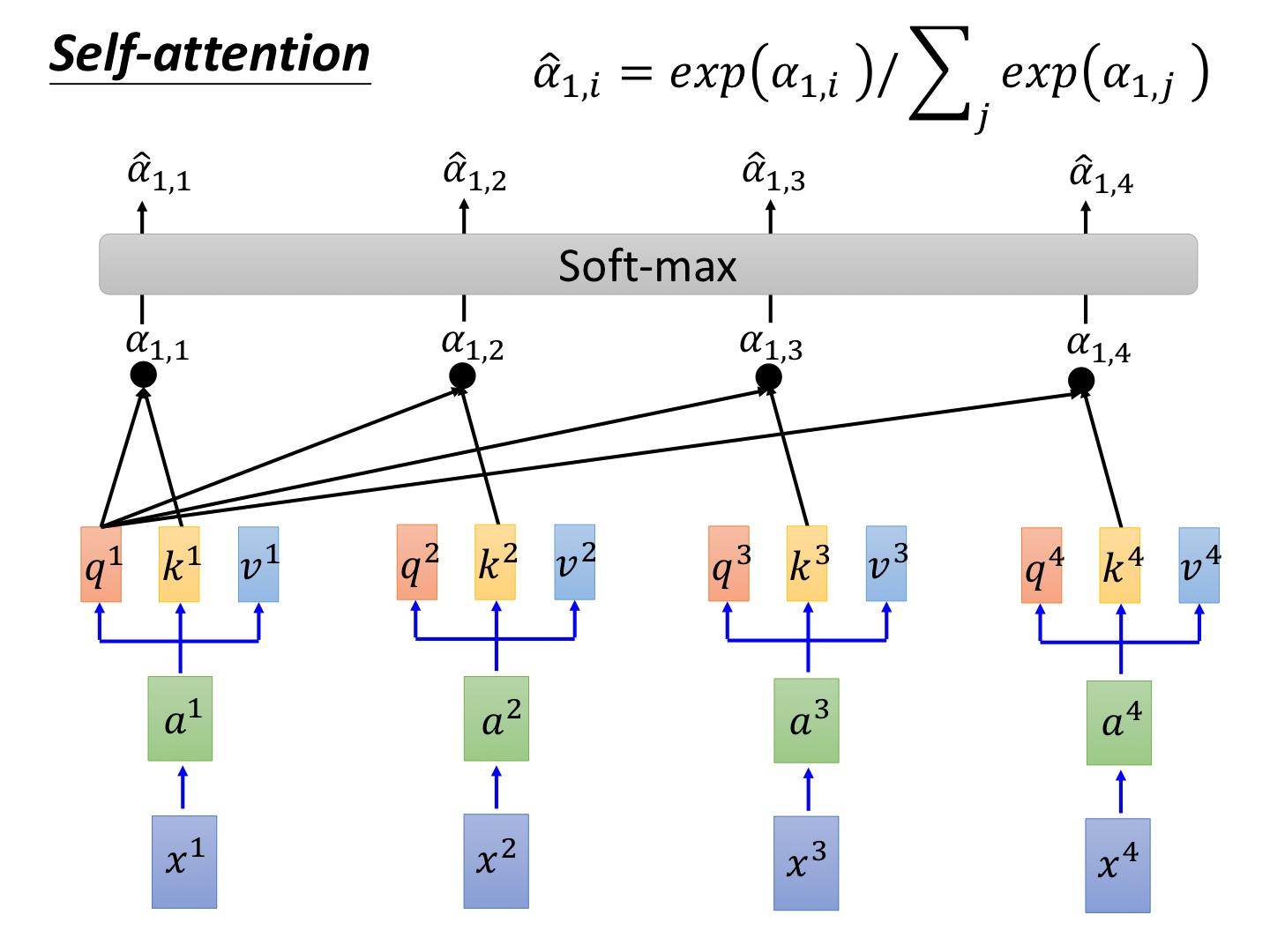
Self-Attention(SA,自注意力)机制是 Transformer(中文叫“变压器”)的核心机制。Transformer 的并行能力来自 SA(传统的基于 RNN 的 Seq2Seq 并行不了)。
其中 \(Q,K,V\) 分别是 Query,Key,Value 向量,每一组 \(Q,K,V\) 是由输入的一句话中的一个 Word Embedding(词嵌入向量)与三个学习矩阵的乘积得到的。无论输入序列中的词是什么,都使用相同的三个矩阵转换所有的词到对应的 \(Q,K,V\)。在 SA 机制中,\(K,V\) 对应同一个词的 Embedding,Value 和 Key 是紧密相关的。
\(\sqrt{d_k}\) 是为了缩放的因子,其中 \(d_k\) 是 Key 的维度。
-
Word Embedding 是什么?
- 比如用 Word2Vec 和 Glove 算法把自然语言的词改写成向量表示。Embedding 本质上就是编码。
-
这个式子是什么意思呢?
-
对于给定的 Query,要计算其与所有 Key 的相似度,即取 \(Q\) 和每个 \(K\) 的点积(MatMul)来完成,计算得到一个分数。\(Q,K,V\) 的维度和输入的 Embedding 维度相同。
-
为了确保这些分数被合理地解释为权重,使用 Softmax(\(\sigma\))函数转换为概率分布。Softmax 优于普通的 Scale(注意 Scale 和 Norm 不同,前者仅缩放,后者可能会改变分布,如偏峰转换,Softmax 也是一种 Norm),有助于放大特征间的差异。
-
使用上面计算出的权重来对 Query 的每个 Key 的 Value 进行加权求和,和 Query 匹配度高的 Key 的 Attention 得分高,占有较大权重。
-
整个过程相当于给输入序列的每个 Embedding 都进行 SA 的变换,每个 Embedding 对应一个维数不变的输出向量。这个输出向量通常加到原输入上。
-
-
为什么已经有了 Key 用于匹配查询,还要用 Value 表示信息含量呢?
- 打个比方:某些词(如 the,is,of 等)经常出现并与许多查询匹配,但它们本身不携带太多特定的语义信息。这种情况 Key 与许多 Query 有高匹配度,但其 Value 不会为最终的输出提供太多有价值的信息。
1.2 多头自注意力机制
Multi-Head Attention(MH/MSA,多头自注意力)机制使用多个独立的注意力头,分别计算注意力权重。
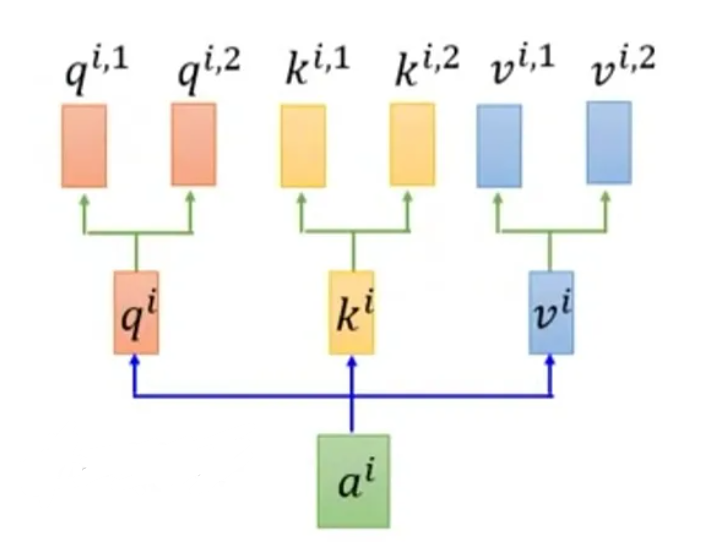
每个 Embedding 不再只生成一组 \(Q,K,V\) 而是被传入不同的权重矩阵生成多组 \(Q,K,V\)(此时 \(Q,K,V\) 的维度比 Embedding 小)。一个词的所有头的注意力计算完成后,通过 Concat(拼接)的方式进行整合。
1.3 位置编码
Transformer 的核心机制是基于 SA 的,这种结构本质上没有考虑输入数据的顺序,它不像 RNN 或 LSTM 能自然维持序列信息,因此 Positional Encoding(PE,位置编码)被引入以提供序列中各个元素的位置信息。
PE 通过一系列正余弦函数计算得到,直接加到相应的 Embedding 向量上,然后才进入 SA 机制计算。PE 的每个维度都使用如下的公式计算:
其中 \(pos\) 是一个词在句子的位置索引,\(i\) 是 Embedding 的一个维度索引,\(d\) 是 Embedding 的维度。
1.4 前馈网络
FNN(前馈网络)也叫 MLP(多层感知机)。前馈网络一般包含两层线性变换,中间插入一个非线性激活函数(ReLU 或 GELU)。
例如第一层将输入映射到一个高维度(如 512 到 2048),接着应用非线性激活函数,第二层再将这个高维空间的表示映射回低维度(如 2048 到 512)。
1.5 残差连接
每个 SA 和 FNN Layer 在输出前都有一个 Add(残差连接/算术加法,Residual Connection)Layer,然后是 Norm(层归一化,Layer Normalization)Layer。因为恒等函数的导数是 1,所以这部分梯度不会衰减,相当于解决了梯度消失问题。层归一化将其转化均值为 0,方差为 1。Transformer 的 Layer 之间普遍采用 Add & Norm。
对 SA Layer 而言,这意味着将 SA 处理后的序列直接加到原始序列上;对 FNN 而言,这意味着将 FNN 的输入加到其输出上。
1.6 总结
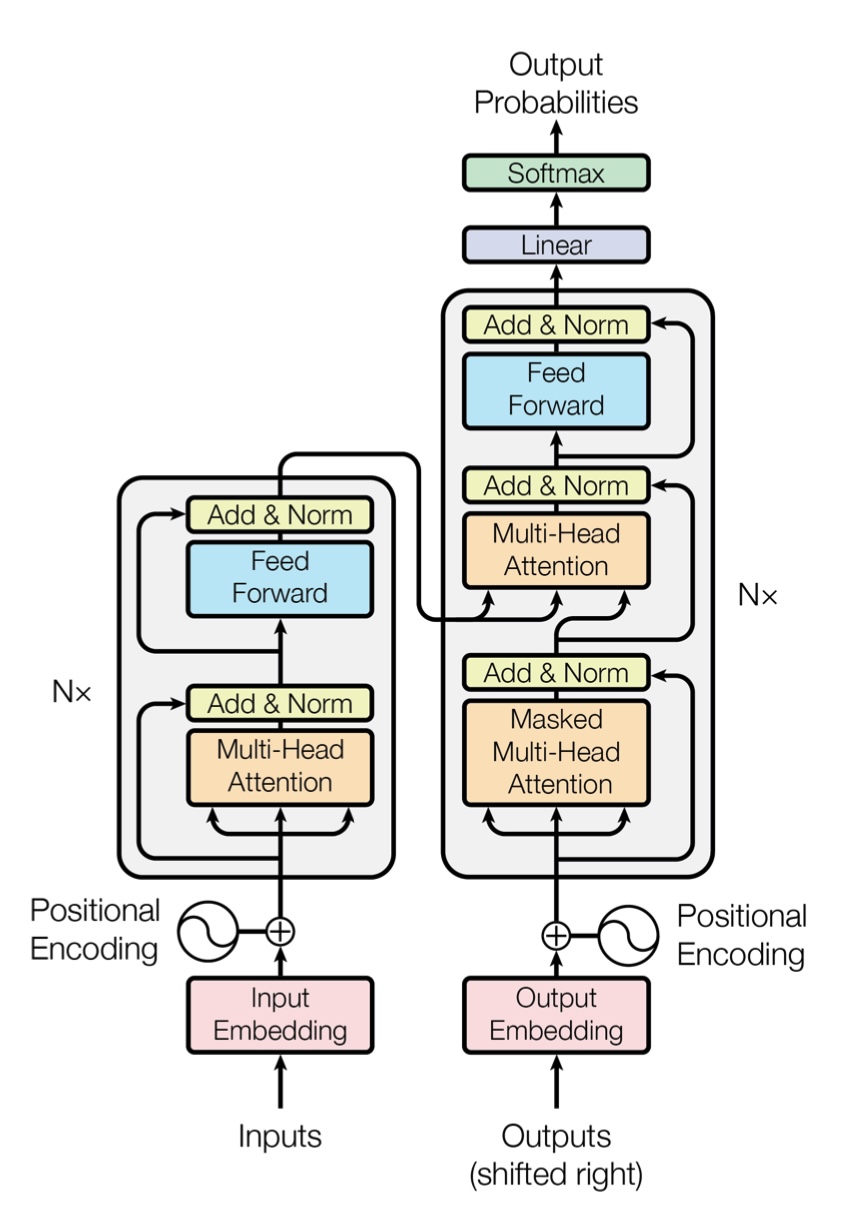
Transformer 的 Encoder 在对输入的自然语句完成 Embedding 和 PE 后,由多个相同的 Block 组成,每个 Block 包括两个主要的 Layer:MH Layer 和 FNN Layer。
Encoder 的每个 Block 的输入是一个向量序列。每个 Block 的输入交给 MH 机制计算,经过 Add & Norm 后,送至 FNN,再经过 Add & Norm。Encoder 每个 Block 输出处理后的更好的向量序列,可以给下一个 Block 使用。第一个 Block 的输入向量序列就是 PE 后的 Embedding。
Encoder 的目的是将原始的向量序列转换为一系列上下文增强的向量序列。
2 Transformer Decoder
Decoder(解码器)是为了生成一个输出的词语。
2.1 掩蔽多头自注意力
在 SA 计算过程中,当前词之后的位置被设置为非常大的负数,经过 Softmax 后权重接近于零,实现 Mask(掩蔽)效果。Mask 具体位于 Query 与 Key 点积之后,Softmax 之前。
Mask 机制确保在生成当前词的同时,模型只能利用前面的词作为上下文来预测下一个词,实现 Autoregressive(自回归性)。Autoregressive 是使用 Decoder 而不是普通分类器的原因。
-
Mask 只用于 Decoder 的训练过程吗?
- 对。生成文本时不需要 Mask。
2.2 编码器-解码器注意力
Encoder-Decoder Attention(编码器-解码器注意力)Layer 的 Query 来源于 Decoder 当前 Block 的前一个 Layer 即 Masked MH 的输出,Key 和 Value 来源于 Encoder 的最后一个 Block 的输出(所以不再是“自”注意力)。这意味着每个生成步骤都根据已经生成的输出内容,动态搜索 Encoder 输出中最相关的部分。
Encoder-Decoder Attention 的计算方法与 MH 机制相同。
2.3 前馈网络
与 Encoder 类似,是由两个线性变换和一个非线性激活函数组成的简单网络。
2.4 总结
Transformer 的 Decoder 在对已经生成的词语完成 Embedding 和 PE 后,由多个相同的 Block 组成,每个 Block 包括三个主要的 Layer:Masked MH Layer、Encoder-Decoder Attention Layer 和 FNN Layer。
Decoder 的每个 Block 的输入是一个向量序列。每个 Block 先经过 Masked MH 计算,经过 Add & Norm 后,然后交给 Encoder-Decoder Attention Layer,经过 Add & Norm 后,送至 FNN,再经过 Add & Norm。Decoder 的每一个 Block 输出处理后的更好的向量序列,可以给下一个 Block 使用。最后,整个 Decoder 通过 Softmax 多分类器输出一个词。
-
预测时,Encoder 提供了整句话的 Word Embedding,Decoder 每次只能预测一个词(即使有多个 Decoder Block)预测完后再重新构建 PE 后的 Embedding,然后继续预测下一个词直到预测完一句话吗?
- 是的,Transformer 的并行能力指的是训练过程。每生成一个词的时候,Encoder 提供的编码都是不变的,换句话说,是通过一个重复使用的 Decoder 串行生成一句话的。
实际上,在机器翻译任务中,整个输入句子在传入模型前已经完全可用。Transformer 的 Encoder 处理这个完整的输入句子,并输出全面的上下文表示的向量序列。然后,Transformer 的 Decoder 逐步生成翻译的输出,每生成一个词,都会基于所有之前生成的词和 Encoder 提供的输出向量序列。
GPT 主要用于文本生成,它只有 Decoder 而没有 Encoder;BERT 主要用于文本理解,它只有 Encoder(双向带 Mask 的 Bidirectional Encoder)而没有 Decoder。它们都采用 Self-supervised(无监督学习,不依赖人工标注)训练,GPT 通过提供片段(即 ALM 策略)预测下一个词训练,BERT 通过随机 Mask(即 MLM 策略)预测原本的值训练。它们都会对不同下游任务微调(如文本分类、情感分析、问答等),分类到下游任务的过程也由训练得到。
3 ViT
ViT 诞生于 2020 年。
Vision Transformers(广义的 ViT)是一种将 Transformer 用于纯视觉的例子,大多只用 Transformer 的 Encoder 部分,常用于图像分类、提取图片特征。
3.1 ViT
Vision Transformer(狭义的 ViT)将图像分割成多个 Patch(几个 Pixel),然后将这些 Patch 视为序列的元素,类似于在自然语言处理中处理单词。每个 Patch 首先被转换为一维的 Embedding 向量(Linear Projection,线性投影),然后输入到一个标准的 Transformer 架构中,其余步骤和基本的 Transformer 没有区别。
3.2 DeiT
Data-efficient Image Transformer(DeiT)是对 ViT 的扩展,通过使用知识蒸馏(用一个训练好的昂贵的 CNN 作为教师模型指导 Transformer 学习),使得 Transformer 能够在较少的数据上也能达到高性能。
3.3 CvT
Convolutional Vision Transformer(CvT)引入 Conv 提取图像特征,然后再转换为 Embedding 向量,输入到 Transformer 架构中。
3.4 Swin-T
Swin-T(Swin Transformer)是 2021 年 ICCV 最佳论文。它打败了 ViT 和 DeiT,核心是 Patch 合并和滑动 Window 机制。

红色方框是 Window,黑色小框是 Patch。Window 的实际尺寸不会随着 Stage 改变,数量会减少。

首先在 Stage 1,Swin-T 用 Conv 完成 Patch Embedding 并初步划分 Window。然后,每经过一个 Stage,执行 Patch 合并和滑动 Window 步骤:将输入的各个 Window 的长和宽缩减为二分之一,维度升至四倍,经过全连接层降至二倍(和 CNN 很像,都是缩尺寸加厚度);W-MSA 将均匀划分的多个 Window 各自独立计算注意力,SW-MSA 采取一种偏移的划分将 Window 进行 Shift 重新拼成均匀的划分后计算注意力。
4 VLP
VLP 诞生于 2021 年。
下面介绍几种视觉和文本结合的 Vision-and-Language Pre-trained Transformer(VLP)结构。VLP 主要基于以下两点分类:
-
图像和文本这两个 Modal 的 Embedding 是不是具有相似的参数或者计算成本。
-
这两个 Modal 的 Embedding 结果是不是通过一个深度模型进行交互。

4.1 ViLT
ViLT(Vision-and-Language Transformer)是一种极简 Embedding 的 Multimodal Transformer 结构。ViLT 中没有 Conv 提取图像信息,而是直接 Linear Projection。
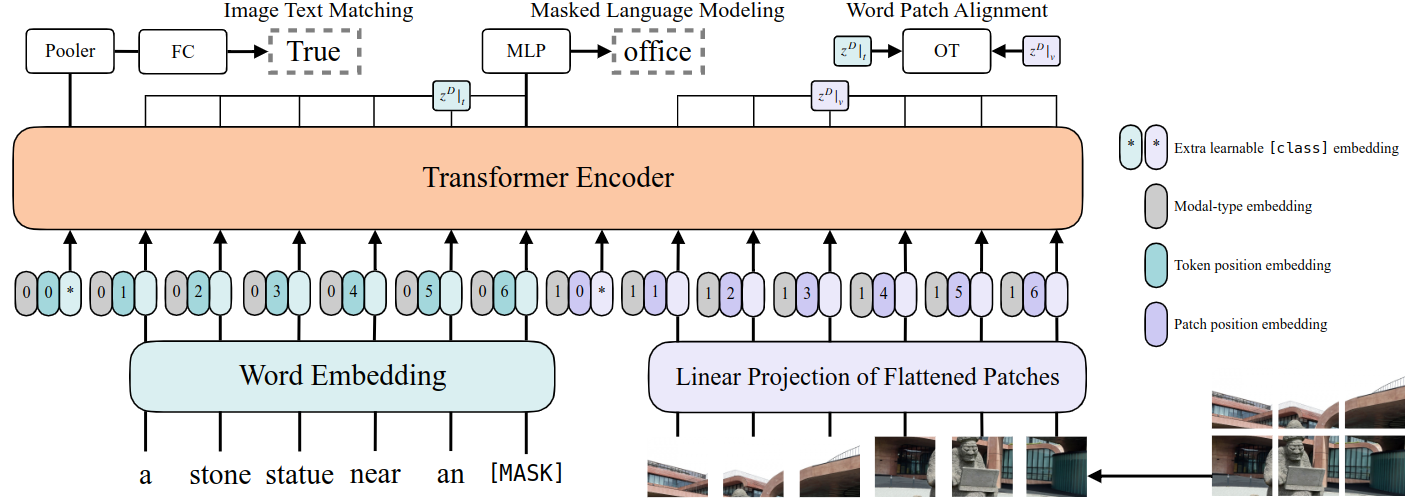
ViLT 的目标是理解问题并推理出答案,这通常直接从 Encoder 的输出分类来完成,无需 Autoregressive 的 Decoder。
4.2 VL-T5
Text-to-Text Transfer Transformer(T5)是一个大模型,它的统一框架把所有文本处理问题都转换为一个 Text-to-Text 形式(某种意义上也属于 Seq2Seq)的问题,然后做 Fine-tuning 迁移学习(也称预训练模型,基于超大数据集预训练的模型在特定任务上用相对小得多的数据集再做一次 Fine-tuning 训练)。T5 包括 Encoder 和 Decoder,相当于 Transformer 升级版。和其他大模型一样,T5 的训练需要提供前缀,指明任务类型。
在预训练阶段,一部分原始文本被替换为 Sentinel Token 标记,相邻的 Token 会合并。训练的任务是根据输入文本和这些标记预测缺失的文本片段。Sentinel Token 和 Mask 的区别就是前者可以一个对应多个遮盖的词,而后者一个只能对应一个词。
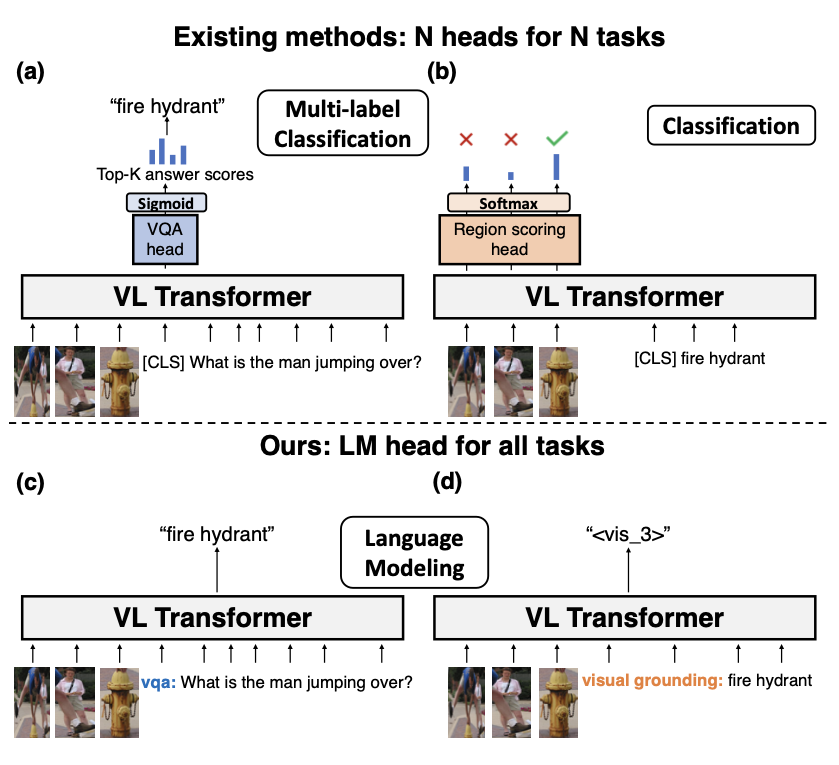
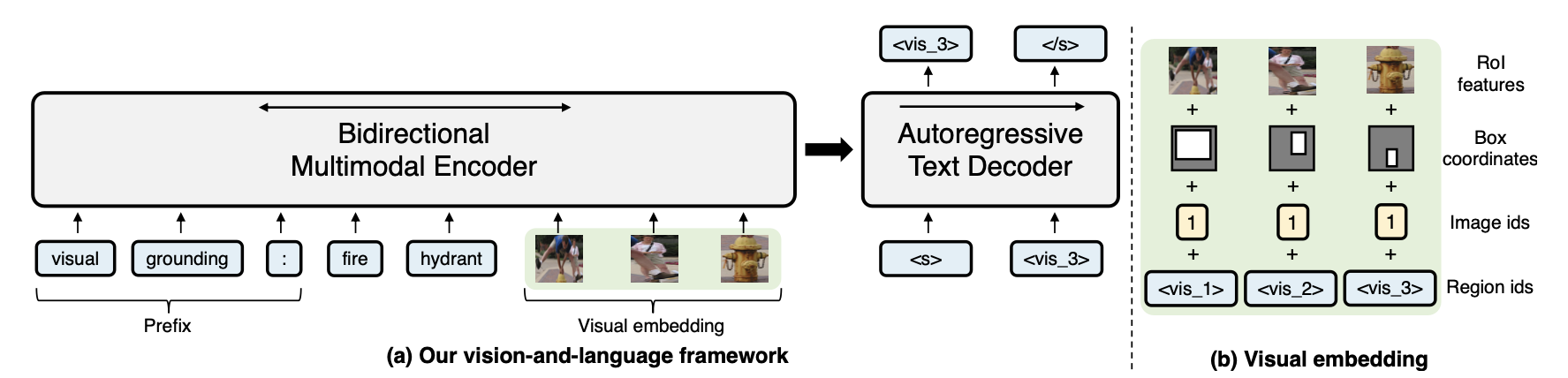
类似于 T5,VL-T5 也将所有的输入和输出格式化为文本形式。图片特征提取常用 ResNet CNN、ViT 等,转换到合适的嵌入空间后与相关的文本输入一起被送入模型的主体。
4.3 VL-BART
BART 也是大模型。BART 不同于 GPT 和 BERT,它同时有 Transformer 的 Encoder 和 Decoder。BART 加入了噪声预训练,它的训练方式是重新生成乱序或损坏的文本。
BART 使用了类似于 BERT 的预训练策略。BART 会在输入文本中随机选择一些 Token,并将它们替换成一个特殊的 Mask Token,然后模型的任务是基于上下文预测这些被 Mask 掉的 Token。
VL-BART 也采用与 BART 类似的架构。
5 论文解读
5.1 Unifying Vision-and-Language Tasks via Text Generation(2021)
这篇论文用 VL-T5 和 VL-BART 预训练的大模型把图像和文本问题统一成文本生成问题,保留 Seq2Seq 核心思想(给定输入文本,生成输出文本)的同时,使用了 Transformer 架构。
-
在上游任务中:
-
对于多模态建模,在 VL-T5 采用 15% 的随机 Sentinel Token,在 VL-BART 采用 30% 的随机 Mask;
-
对于 VQA ,从原始格式生成文本而不是用一个分类器;
-
对于图片-文本配对,在正确的字幕边以 50% 概率添加一个来自其他配对的错误字幕;
-
对于视觉定位,利用 Visual Sentinel Token 根据文本描述给出区域 id;
-
对于定位字幕,根据区域 id 给出文本描述,相当于视觉定位的逆过程。
-

-
在下游任务中:
-
对于 VQA,经过实验发现在领域外子集上,生成式(使用 Transformer 的 Decoder)明显优于判别式(使用候选项目的 Multi-classifier);
-
对于 NLVR(自然语言视觉推理),对于同一个文本设置两幅图像学习 True/False 以适应不同图像情景,实验表明增加了双向注意力的编码要优于其他编码;
-
对于指代表达理解,基于已经用 Mask R-CNN 选好的候选区域与指代文本短语预测区域 id,VL-T5 表现突出;
-
对于 VCR(视觉常识推理),将上下文(图像和问题)与每个候选选择进行连接,让模型对于正确的选择生成 true 否则生成 false,实验表明这个需要用 VCR 的领域内语料库训练才能提升;
-
对于图像描述生成,由于这是一个文本上下文无意义的任务,提升并不明显,把 COCO 图像标签加进去会大幅提升 VL-BART 的表现;
-
对于多模态机器翻译,基于 VL-T5 的模型在各测试集上均优于使用强大数据增强的 Baseline;
-
对于 Fine-tuning,即使 VCR 没有第二阶段的预训练以及 COCO 图像描述没有对象标签,整体的多任务模型与单独优化的单任务模型都有相当的性能,具有单个共享预训练头部的 VL-T5 几乎达到了与任务特定头部相等的性能,同时总参数要少得多。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号