数据库 | Database
1 入门
1.1 元数据
数据可以分为两类: 元数据和实际数据.
元数据是描述数据的数据, 也可以被称为 "数据的数据". 它们提供了关于数据的信息, 例如数据的来源, 格式, 大小, 类型, 版本, 创建日期, 更新日期等等. 元数据通常用于数据管理和数据发现, 以帮助用户更好地理解和使用实际数据.
实际数据是指包含有意义信息的数据, 通常用于实际的分析, 研究, 决策和应用. 这些数据可以是数字, 文本, 图像, 视频, 声音等形式的数据. 实际数据可以包括原始数据, 处理后的数据, 分析结果, 报告等等.
DB (数据库) 被 DBMS (数据库管理系统) 所管理, 而 DB 和 DBMS 则一起构成了 DBS (数据库系统).
1.2 文件系统
对于直接管理数据的系统如使用文件系统, 可能出现数据冗余和不一致 (相同数据多个副本?), 访问困难 (获取每一属性都需要额外编写函数?), 数据孤立 (数据分散难以获取?), 数据一致性 (不同格式的数据之间难以合并?), 更新操作的原子性 (原子操作不能被间断?), 多用户并发访问 (多个用户同时读写?), 安全性问题 (数据的可访问性?).
1.3 数据视图
数据视图就是从数据库中选择一部分数据, 组合起来形成一个虚拟的表格, 提供给用户方便的查询和访问. 数据视图是一个 "表". 它相当于是一个数据库查询的快捷方式, 让用户只看到他们需要的数据, 隐藏掉不必要的信息, 即三层结构中的外模式部分.
三层结构:
-
外部层 (外模式 / 视图层): 是用户能够看到和访问的数据视图. 外部模式定义了用户如何看待数据, 包括数据的组织方式, 数据的格式, 数据的查询方式等.
-
概念层 (模式 / 逻辑层): 是数据库管理员看到的数据视图. 概念模式定义了整个数据库的逻辑结构, 包括数据的实体, 关系, 属性以及它们之间的联系. SQL 主要就是基于这一层.
-
内部层 (内模式 / 物理层): 是数据库存储在计算机硬件上的实际结构. 内部模式定义了数据在存储介质上的物理结构和存储方式, 包括数据的文件, 索引, 存储器和存储空间等.
物理数据的独立性指的是内部层对于概念层独立, 逻辑数据的独立性指的是概念层对于外部层独立. 底层数据的修改对于上层是透明的.
1.4 数据模型
- 物理模型
eg: B+ 树, 平衡树
- 逻辑模型
eg: 关系模型, 网状模型, 层次模型, 基于对象的数据模型, 半结构化数据模型
- 概念模型
eg: 实体 - 联系模型, 流程图
物理层使用物理模型, 逻辑层与视图层都采用逻辑模型.
半结构化数据指的是类似 HTML, XML, JSON 的具有标签与属性的不稳定数据. 结构化数据使用 DBMS, 非结构化数据使用 Hadoop.
1.5 数据库分类
1.5.1 NoSQL
NoSQL 数据库是一类非关系型数据库管理系统, 它们不使用传统的 SQL 语言进行查询.
- 列式数据库
列式数据库 (Column-Oriented Database) 是一种数据存储方法, 将数据按照列 (Column) 而不是行 (Row) 进行存储和管理. 这与传统的行式数据库 (Row-Oriented Database) 有所不同, 行式数据库在读取数据时通常会读出多余数据, 列式数据库在某些场景下具有更高的性能和存储效率.
Monetdb 是常见的列式数据库.
- 键值数据库
键值数据库 (Key-Value Database) 是一种非关系型数据库, 它采用简单的键值对 (Key-Value Pair) 数据结构来存储和管理数据. 键值数据库具有高度可扩展性, 低延迟和高性能的特点, 因此常被用于处理大量读写操作的场景.
Redis 是常见的键值数据库.
- 文档数据库
文档数据库是一种基于文档的数据库管理系统, 其中数据以类似于 JSON 的结构化文档格式存储.
MongoDB 是常见的文档数据库.
- 图数据库
图数据库是一种专门用于存储和查询图形数据结构的数据库管理系统. 图形数据结构由节点 (Nodes) 和边 (Edges) 组成, 节点表示实体, 边表示实体之间的关系. 与其他数据库类型相比, 图数据库能够更有效地处理复杂的关系和图遍历查询.
Neo4j 是常见的图数据库.
1.5.2 SQL
SQL 数据库也称为关系型数据库, 是基于关系模型的数据库管理系统. 关系型数据库使用 SQL (Structured Query Language) 作为查询语言, 支持事务处理, 数据完整性和并发控制等功能.
常见的关系型数据库有 Oracle, MySQL, SQLite 等. SQLite 是最轻量化的知名数据库系统.
1.5.3 NewSQL
NewSQL 数据库是一类新型数据库管理系统, 旨在克服传统关系型数据库在可扩展性和性能方面的局限, 同时保持其优秀的事务处理, 数据完整性和 SQL 查询能力.
常见的 NewSQL 数据库有 Google Spanner, CockroachDB 和 TiDB.
2 关系模型
关系是通过笛卡尔积定义的. 与传统的笛卡尔积不同, 元组的各个属性间的顺序可以调换. 关系的模式指的是结构化的定义, 关系的值指的是该关系的实例. 关系表本身是一种数据结构.
关系数据模型的三要素: 数据的完整性约束, 数据结构, 数据操作.
2.1 定义
-
元组 (Tuple): 元组是关系中的一行, 表示一个数据记录. 元组中的每个元素对应于关系的一个属性.
-
关系 (Relation): 关系是关系模型的基本构成单位, 表示为一个二维表格. 在实际数据库中, 关系通常对应于一个表. 表是一个存储元组的容器.
-
属性 (Attribute): 属性是关系中的一列, 表示数据的某个特征. 属性具有名称和数据类型.
-
域 (Domain): 域是属性可能取值的集合, 表示属性的值空间. 域定义了属性的数据类型, 范围和约束.
-
键 (Key): 键是关系中用于唯一标识元组的一个或多个属性的组合. 主键 (Primary Key) 是关系中的一个特殊键, 用于确保元组的唯一性.
NULL 代表空状态 (unknown), 它包括不存在状态.
2.2 完整性约束
完整性约束 (Integrity Constraints) 是用于确保数据的准确性, 一致性和可靠性的规则.
2.2.1 实体完整性约束
超码(Superkey)是关系模型中的一个重要概念. 超码指的是一个或一组属性, 其能够在关系中唯一地标识每个元组. 换句话说, 超码是一个使得在关系中不存在两个相同的元组的属性集合. 如果超码是关系本身则称全码.
这有点像哈希表, 哈希表也是存储唯一键值对的数据结构, 只不过哈希表是一个键对应一个键值, 超码是多个键对应一个元组.
候选码 (Candidate Key) 的任何真子集都不是超码, 也即最小超码. 包含在候选码中的属性称为主属性. 不出现在任何候选码中的属性称为非主属性.
主码 (Primary Key) 从候选码中选择, 用于唯一标识不同元组. 主码属性不允许为空. 主属性包括主码属性.
2.2.2 参照完整性约束
外码 (Foreign Key) 是一个关系表中的属性或属性组合, 它对应另一个关系表的主键. 通过外码和主键的关联, 关系模型中的表可以相互引用, 从而表示实体之间的关系. 外码的取值限制于另一个关系表的主码已有取值. 外码可以设置为空.
2.3 关系运算
任何运算的输入或输出都是关系.
-
选择 (Select): 选择运算用于从关系表中筛选出满足特定条件的记录. 结果仍然是一个关系表. 在 SQL 中, 这对应于使用 WHERE 子句进行筛选.
-
投影 (Project): 投影运算用于从关系表中选取指定的属性列. 结果是一个仅包含所需属性列的关系表. 在 SQL 中, 这对应于 SELECT 子句中列出所需的属性列.
-
连接 (Join): 连接运算用于将两个或多个关系表基于某种关联条件 (如相等的键值) 进行组合. 连接可以是内连接 (Inner Join), 外连接 (Outer Join, 包括左外连接, 右外连接和全外连接) 或自连接 (Self Join). 在 SQL 中, 这些操作通过 JOIN 子句及其变体 (如 LEFT JOIN, RIGHT JOIN 等) 实现.
-
集合运算: 关系模型中的集合运算基于数学集合论, 包括并集 (Union), 交集 (Intersection) 和差集 (Difference). 这些运算用于合并或比较具有相同属性列的关系表. 在 SQL 中, 这些操作分别对应于 UNION, INTERSECT 和 EXCEPT 子句.
3 SQL
SQL 分为数据操纵语言 (DML), 数据定义语言 (DDL) 和数据控制语言 (DCL).
3.1 数据操纵语言 (DML)
3.1.1 SELECT
SELECT 是用于查询数据的关键词, 其常配合 FROM 和 WHERE 使用. 例如取出薪资大于 2500 的员工的所有属性:
SELECT * FROM emp WHERE sal > 2500
此外, WHERE 子句就像 if 判断语句, 对每一行进行判断.
子句的执行顺序为:FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
SELECT WHERE 可以实现简单的笛卡尔积连接, 但这种方法并不推荐. 除了简单连接, 还有内连接 (JOIN), 外连接 (LEFT JOIN), 自然连接 (NATURAL JOIN) 和自连接等多种连接方式. 如果两个关系没有公共属性, 那么自然连接转化为笛卡尔积操作.
使用 LIKE 进行模式匹配: LIKE 操作符用于对字符串值执行模式匹配. '_' 可代替一个字符, '%' 可代替任意字符.
GROUP BY 和 HAVING: GROUP BY 用于对查询结果进行分组, 通常与聚合函数结合使用, 如 COUNT, SUM, AVG, MIN, MAX 等. 而 HAVING 用于对 GROUP BY 子句生成的分组应用筛选条件.
ORDER BY: ORDER BY 用于对查询结果进行排序.
3.1.2 INSERT
INSERT 用于向数据库表中插入新记录:
INSERT INTO Students (student_id, student_name, age)
VALUES (1, 'John', 18);
3.1.3 UPDATE
UPDATE 用于修改数据库表中的记录:
UPDATE Students
SET student_name = 'New Name', age = 25
WHERE student_id = 5;
3.1.4 DELETE
DELETE 用于从数据库表中删除记录:
DELETE FROM Students
WHERE age > 20;
3.2 数据定义语言 (DDL)
3.2.1 CREATE
CREATE 用于创建新的表:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT REFERENCES customers(customer_id),
order_date DATE,
order_time TIMESTAMP,
total_cost NUMERIC(10,2),
status VARCHAR(20),
CONSTRAINT ck_status CHECK (status IN ('open', 'closed', 'pending'))
);
3.2.2 DROP
DROP 用于删除表:
DROP TABLE students;
3.2.3 ALTER
ALTER 用于修改表的结构:
ALTER TABLE students ADD age INT;
3.3 数据控制语言 (DCL)
3.3.1 GRANT
GRANT 是一种用于给用户赋予数据库访问权限的命令. 这些权限包括 SELECT, INSERT, UPDATE, DELETE, EXECUTE 等等.
基本语法如下:
GRANT privileges
ON object
TO user;
其中 privileges 是授予的权限, object 是权限应用的数据库对象, user 是授权的用户.
3.3.2 REVOKE
REVOKE 是一种用于移除用户数据库访问权限的命令, 可以移除用户访问数据库, 表, 视图, 存储过程等对象的权限.
基本语法如下:
REVOKE privileges
ON object
FROM user;
其中 privileges 是移除的权限, object 是权限应用的数据库对象, user 是移除权限的用户.
3.4 一些常用函数和高级查询
3.4.1 to_date 和 date_trunc
to_date 和 date_trunc 是两个常用的处理日期和时间的函数.
3.4.2 子查询
子查询 (嵌套查询) 分为相关子查询和不相关子查询.
子查询只返回单一的值 (也就是一个标量) 称为标量子查询.
SELECT CustomerID, CustomerName
FROM Customers
WHERE CustomerID IN (
SELECT CustomerID
FROM Orders
WHERE OrderAmount > (
SELECT AVG(OrderAmount)
FROM Orders
)
);
在这个查询中, 标量子查询 SELECT AVG(OrderAmount) FROM Orders 返回所有订单的平均金额. 然后, 外层的不相关子查询 SELECT CustomerID FROM Orders WHERE OrderAmount > (...) 返回订单金额大于平均订单金额的所有客户 ID. 最后, 主查询返回这些客户的 ID 和名称.
3.4.3 EXISTS 和 IN
EXISTS 是 SQL 中的一种操作符, 用于检查子查询是否返回至少一行结果.
IN 运算符用于检查某个值是否在一组值中或子查询的结果中.
3.4.4 DISTINCT
DISTINCT 用于去重复行.
3.4.5 CASE 表达式
CASE 表达式用于控制分支语句, 可以用于添加标签和实现特殊排序.
ORDER BY CASE
WHEN region_name = 'Asia' THEN 1
WHEN region_name = 'Europe' THEN 2
WHEN region_name = 'Americas' THEN 3
WHEN region_name = 'Middle East and Africa' THEN 4
ELSE 5
END;
3.4.6 WITH 表达式
WITH 表达式用于创建局部视图, 可以提前准备好待查询的各个表.
3.4.7 递归查询
递归查询的基础是使用公共表表达式 (CTE, Common Table Expressions), CTE 由一个查询定义, 并且在执行该查询的同时, 该查询在其余部分也可用.
WITH leadership(employee_id, manager_id, iteration) AS (
SELECT employee_id, manager_id, 1
FROM employees
UNION ALL
SELECT e.employee_id, l.manager_id, l.iteration + 1
FROM employees e
JOIN leadership l ON e.manager_id = l.employee_id
)
这段语法的作用是从一个员工与经理的关系表中, 通过递归查询找出每个员工的上级经理, 以及递归的迭代次数. 通过逐级追溯经理关系, 我们可以形成一个员工与其所有上级经理的层级结构.
3.4.8 更新时的潜在问题
当创建一个视图时, 可以使用 WITH CHECK OPTION 来指定视图的约束选项. 如果更新后的数据不满足视图的条件, 将会引发错误并拒绝更新, 如
CREATE VIEW HighPaidEmployees AS
SELECT EmployeeID, FirstName, LastName, Salary
FROM Employees
WHERE Salary >= 5000
WITH CHECK OPTION;
现在, 我们尝试通过视图更新来修改一个工资较低的员工的记录:
UPDATE HighPaidEmployees
SET Salary = 4000
WHERE EmployeeID = 123;
由于我们在创建视图时使用了 WITH CHECK OPTION 子句, 这个更新操作将被拒绝, 因为它违反了视图的定义条件 (Salary >= 5000). 系统将返回一个错误, 指示更新违反了视图的约束条件.
对于 "无法定位原始视图具体位置的视图", 如
CREATE VIEW CustomerOrders AS
SELECT c.CustomerID, c.CustomerName, SUM(o.OrderAmount) AS TotalAmount
FROM Customers c
JOIN Orders o ON c.CustomerID = o.CustomerID
GROUP BY c.CustomerID, c.CustomerName;
在上述视图定义中, 我们通过连接基表 Customers 表和 Orders 表创建了一个伪表 CustomerOrders, 它显示每个客户的总订单金额. 如果执行
UPDATE CustomerOrders
SET TotalAmount = TotalAmount + 1000
WHERE CustomerID = 1;
会报错, 因为 TotalAmount + 1000 无法确定基表中具体每个订单金额增加了多少, 可以是 500 + 300 + 200, 也可以是 600 + 100 + 300 等等. 伪表的更新操作本质上是更新伪表所基于的基表.
4 关系代数
4.1 运算符
- \(\sigma\) 运算符:
\(\sigma\) 运算符(Restrict)用于选择满足指定条件的元组. 它基于一个给定的条件, 从关系中选择符合条件的元组, 并返回一个新的关系. 条件可以使用关系中的属性和比较运算符进行定义.
例如, 假设我们有一个关系表 \(R\), 包含属性 \(A\) 和 \(B\). 我们可以使用 \(\sigma\) 运算符选择属性 \(A\) 等于某个特定值的元组: \(\sigma_{A = 5}(R)\)
上述表达式将返回关系 \(R\) 中属性 \(A\) 等于 \(5\) 的所有元组.
- \(\Pi\) 运算符:
\(\Pi\) 运算符 (Project) 用于选择一个关系中的特定属性列, 生成一个新的关系, 该关系只包含所选属性列的值. 通过 \(\Pi\) 运算符, 我们可以从关系中提取所需的列, 而不考虑其他列的值.
例如, 假设我们有一个关系表 \(R\), 包含属性 \(A\), \(B\) 和 \(C\). 我们可以使用 \(\Pi\) 运算符选择只包含属性 \(A\) 和 \(B\) 的新关系: \(\Pi_{A, B}(R)\)
上述表达式将返回一个新的关系, 其中只包含关系 \(R\) 中的属性 \(A\) 和 \(B\).
- \(\cup\) 运算符
\(\cup\) 运算符用于将两个关系的元组合并成一个包含两个关系中所有元组的新关系. 它要求两个关系具有相同的属性集.
例如, 假设有两个关系表 \(R\) 和 \(S\), 它们具有相同的属性集. 我们可以使用 \(\cup\) 运算符将它们合并成一个新的关系: \(R \cup S\)
上述表达式将返回一个新的关系, 其中包含 \(R\) 和 \(S\) 中所有的元组.
- \(-\) 运算符
\(−\) 运算符用于从一个关系中删除另一个关系中存在的元组, 返回一个新的关系.
例如, 假设有两个关系表 \(R\) 和 \(S\), 我们可以使用 \(−\) 运算符从关系 \(R\) 中删除关系 \(S\) 中存在的元组: \(R − S\)
上述表达式将返回一个新的关系, 其中包含在关系 \(R\) 中存在但不存在于关系 \(S\) 中的元组.
- \(\times\) 运算符
\(\times\) 运算符用于将两个关系的元组进行组合, 生成一个新的关系. 结果关系的元组由两个关系的所有可能的组合组成.
例如, 假设有两个关系表 \(R\) 和 \(S\), 我们可以使用 \(\times\) 运算符生成它们的笛卡尔积: \(R \times S\)
上述表达式将返回一个新的关系, 其中的每个元组都是 \(R\) 中的一个元组和 \(S\) 中的一个元组的组合.
- \(\rho\) 运算符
\(\rho\) 是重命名运算符, 用于为关系中的属性或整个关系表分配一个新的名称.
例如, 假设有一个关系表 \(R\), 我们可以使用 \(\rho\) 运算符为关系表分配新的名称 \(r\), 属性 Name 分配新的名称 NewName: \(\rho_{r(\text{NewName})}(R)\)
上述表达式将返回一个新的关系, 其中属性 Name 被重命名为 NewName.
- \(\bowtie\) 运算符
\(\bowtie\) 是自然连接运算符.
假设有两个关系表 \(R\) 和 \(S\), 它们具有相同的属性 \(A\) 和 \(B\). 我们可以使用 \(\bowtie\) 运算符进行自然连接: \(R \bowtie S\)
上述表达式将返回一个新的关系, 其中的每个元组都是关系 \(R\) 中的一个元组和关系 \(S\) 中的一个元组的组合, 且它们的属性 \(A\) 和 \(B\) 的值相等.
\(\bowtie\) 下标添加参数可作为内连接的条件.
全外连接的符号是 ⟗, 左外连接的符号是 ⟕, 右外连接的符号是 ⟖.
- \(\mathcal{G}\) 运算符
这是分组运算符, 例如 \(_{\text{deptno}}\mathcal{G}_{avg(\text{sal})}(\text{emp})\) 表示从 \(\text{emp}\) 表中按 \(\text{deptno}\) 分组同时使用聚集函数 \(avg(\text{sal})\).
- \(\leftarrow\) 运算符
这是赋值运算符, 例如 \(e_1\leftarrow \text{employees}\) 表示将 \(\text{employees}\) 赋值给 \(e_1\), 相当于取一个别名. 这和使用 \(\rho\) 运算符为关系表重命名的效果相似.
- \(\div\) 运算符
这是关系除运算符. 关系除的意义是在一个较大的属性集合中, 寻找出那些包含了另一个较小集合的所有记录的行.
假设我们有两个关系 \(R\) 和 \(S\):
| A | B |
|---|---|
| 1 | 3 |
| 1 | 4 |
| 2 | 3 |
| 2 | 4 |
| 3 | 4 |
| B |
|---|
| 3 |
| 4 |
那么关系除的结果是:
| A |
|---|
| 1 |
| 2 |
这是因为在关系 \(R\) 中, 只有 \(A = 1\) 和 \(A = 2\) 的元组在属性 \(B\) 上包含 \(S\) 中的所有元组 \(B = 3\) 和 \(B = 4\).
4.2 实例
- 找出所有工资高于所在部门平均工资的员工, 输出员工姓名, 工资, 部门名称:
- 找到提供了工资在 2000 - 5000 之间的所有职位的部门, 输出部门名称:
- 找出每个部门工资高于 2500 的人数, 输出部门名称, 人数:
5 查询优化
5.1 语法树
考虑以下 SQL 查询:
SELECT *
FROM table1, table2
WHERE table1.id = table2.id AND table1.value > 100;
对应的语法树如下:
SELECT
/ | \
TABLE1 JOIN TABLE2
| |
VALUE CONDITION
在生成查询的执行计划时, 优化器可能考虑两种不同的策略:
- 先进行 JOIN 操作, 然后再进行筛选 (value > 100);
- 先进行筛选 (value > 100), 然后再进行 JOIN.
这两种策略会产生不同的执行计划树, 也就对应了不同的执行效率.
如果 table1 非常大, 但满足 value > 100 的行数相对较少, 那么优化器可能会选择第二种策略, 因为这样可以减少 JOIN 操作需要处理的行数, 从而提高查询的效率.
5.2 索引
全表扫描涉及到检查表中的每一行以找到满足查询条件的行, 效率非常低. 索引扫描通常比全表扫描更快, 因为它只需要查看索引并定位到表中满足查询条件的行, 而不是查看整个表.
5.2.1 B 树索引
B 树的全称是平衡多路查找树. B 树索引有以下主要特点:
-
自平衡: B 树始终保持平衡. 无论我们在树中添加或删除键值, 它总是通过拆分或合并节点来保持树的高度尽可能小.
-
多路查找树: 每个 B 树节点可能有多个子节点 (可以大于两个), 而不仅仅是左子节点和右子节点. 这使得 B 树在存储大量数据时能够更高效地利用磁盘空间.
-
数据顺序存储: B 树索引将数据以排序的方式存储在每个节点, 这使得范围查询更加高效.
-
用于点查询和范围查询: 由于 B 树索引数据的有序性, B 树索引对于单个值的查询以及范围查询都非常有效.
5.2.2 哈希索引
哈希索引通过哈希函数将值映射到一个位置, 然后在该位置存储指向表中具有该值的行的指针. 哈希索引在处理 "等于" 查询时非常快, 但是对于范围查询则无法使用.
5.3 执行计划
5.3.1 RBO
规则基准优化器使用一组固定的规则和优先级来选择查询计划, 这些规则通常基于经验和启发式方法. 这种方法在早期的数据库系统中被广泛使用, 但现在已经大多被代价基准优化器取代, 因为它在处理复杂查询和大型数据库时可能不会生成最优的执行计划.
5.3.2 CBO
代价基准优化器使用统计信息来预测执行一个查询或一个查询计划所需的工作量, 然后选择代价最低的查询计划. 代价的计算考虑了多种因素, 如 I/O 操作, CPU 时间, 网络通信等. 这种方法在大多数现代的数据库系统中被广泛使用, 因为它可以生成高效的执行计划, 特别是在处理复杂查询和大型数据库时.
6 数据库设计
设计一个大学信息管理系统, 包含课程基本信息管理, 排课信息管理, 成绩信息管理, 教师信息管理, 学生信息管理, 导师指导信息管理六个模块.
- 课程基本信息管理要求能够管理课程基本信息, 课程的依赖关系 (先修课信息), 院系开课信息;
- 排课信息管理要求能够管理各个学期中各个课程的各个教学班的上课地点信息, 每个教学班在每周的上课时间安排, 每个教学班的授课教师信息;
- 成绩信息管理要求能够管理学生选修过课程的成绩信息, 包括学生选修的课程班级;
- 教师信息管理要求能够管理教师的所属院系, 教师的工资等基本信息;
- 学生信息管理要求能够管理学生的所属院系, 学生的当前已经获得学分;
- 导师指导信息管理要求能够管理每个学生的指导教师信息.
6.1 概念结构设计
概念结构设计的结果是得到 ER 图. ER 图中包括实体和关系:
-
实体 (Entity): 现实世界中可以独立存在, 可以区别于其他对象的事物. 例如在一个学校数据库中, 学生, 课程和教师可以被视为实体.
-
关系 (Relationship): 描述实体之间的联系. 例如学生可以选修课程, 这里 “选修” 就是一种关系.
-
属性 (Attribute): 描述实体或关系的性质. 例如学生实体的属性可能包括姓名, 学号等.
实体集通常用矩形表示, 关系集用菱形表示, 属性用椭圆表示, 单箭头表示 One, 单横线表示 Many, 双横线表示 All, 双菱形用于连接强实体集与弱实体集, 虚线用于连接关系集和描述性属性.
关系集主码的选取:
-
Many-to-Many: 选取两个实体集的主码总和;
-
One-to-One: 选取两个实体集主码二者之一;
-
One-to-Many: 选取 Many 侧的主码.
关系集的属性等于所连接的实体集的所有主键 (和描述性属性, 如果有). 如果两个实体集出现了重复属性, 那么应该将其中之一去掉, ER 图中一个属性只能出现一次.
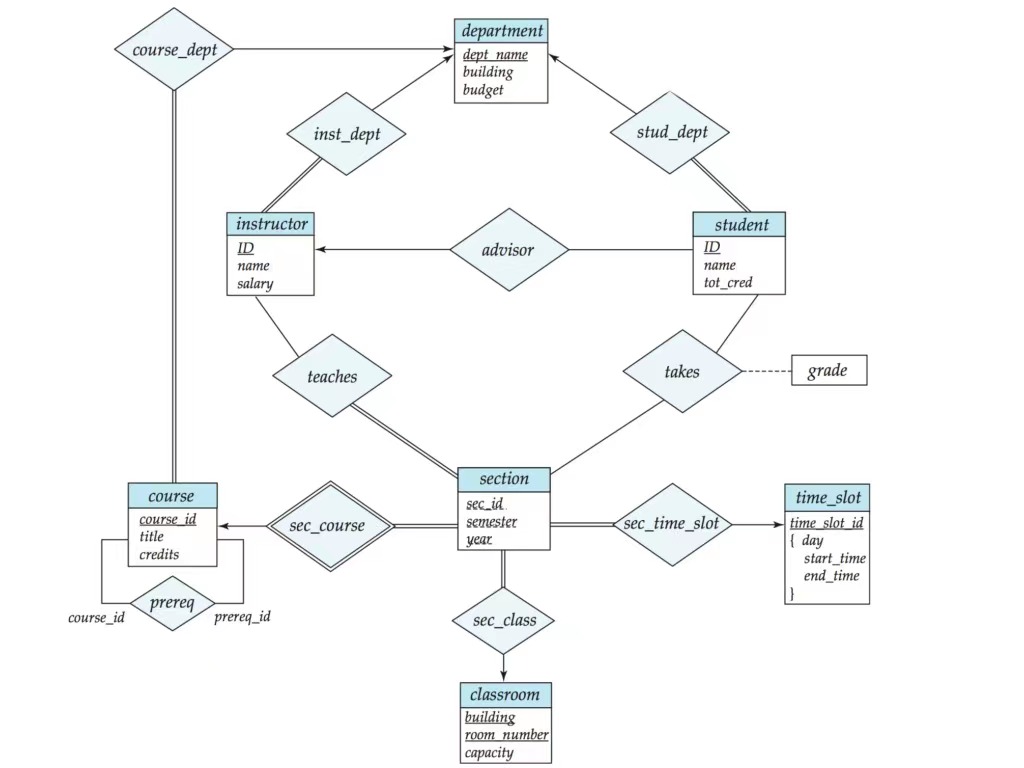
6.2 逻辑结构设计
逻辑结构设计的结果是得到逻辑存储方案.
对于复合属性, 应尽量将各字段拆开表示; 对于多值属性, 应添加一个实体集并以该属性为主属性通过外键相连接.
One-to-Many 的关系需要将 Many 侧的主码和关系集的主码合并; Many-to-Many 的情况需要为关系单独设计一个模式.
本题的关系模式应是 (横线表示主码, 波浪线表示外码):
-
Teaches (ID, course_id, sec_id, semester, year)
-
Takes (ID, course_id, sec_id, semester, year, grade)
-
Prereq (course_id, prereq_id)
-
Department (dept_name, building, budget)
-
Instructer (ID, name, salary, dept_name)
-
Student (ID, I_ID, name, tot_cred, dept_name)
-
Course (course_id, title, credits, dept_name)
-
Section (course_id, sec_id, semester, year, building, room_number, time_slot_id)
-
Classroom (building,room_number, capacity)
-
Time_slot (time_slot_id, {(day, start time, end time)})
6.3 物理结构设计
物理结构设计的结果是得到实际运行的代码.
7 关系数据理论
一个对应关系应该只存一遍. 这是一切判断的核心.
7.1 关系模式形式化定义
-
R: 这代表关系名, 在数据库中, 每个表或关系都有一个唯一的名称, 用于区分其他表.
-
U: 这是属性集合, 或者说是列的集合. 这些属性定义了表中的数据类型, 例如一个人的关系模式可能包含姓名, 年龄, 地址等属性.
-
F: 这是函数依赖集合, 它表示一组属性如何依赖于另一组属性, 函数依赖是数据库中的一个关键概念, 它有助于定义表的键和数据完整性规则.
关系模式可简化为三元组 R(U,F).
7.2 数据依赖
7.2.1 函数依赖
函数依赖可以用箭头表示, 例如 A -> B. 这意味着在一个关系中, 属性 A 的值可以唯一确定属性 B 的值.
完全函数依赖: 如果在一个函数依赖关系 X -> Y 中, 移除 X 中的任何属性后都无法保持这种依赖关系, 那么我们说 Y 对 X 是完全函数依赖的.
部分函数依赖: 在一个函数依赖关系 X -> Y 中, 如果 X 的某个子集可以确定 Y, 那么我们说 Y 对 X 是部分函数依赖的.
传递函数依赖: 传递函数依赖发生在一个函数依赖链中, 如果有一个函数依赖 A -> B, 并且有另一个函数依赖 B -> C, 那么我们可以说 C 对 A 是传递函数依赖的.
7.2.2 多值依赖
给定一个关系 R 和其中的属性 X, Y 和 Z, 如果存在一个多值依赖 X ->> Y, 那么对于 X 的每一个值, Y 的值的集合不依赖于 Z 的值. 每个 X 的值都有一组相关的 Y 的值, 这组值不会因 Z 的变化而变化.
7.3 范式
7.3.1 函数依赖范式
-
1 NF: 第一范式要求数据库表的每个属性都是原子的, 不能被进一步分解. 表中的每个单元格都只能包含一个值, 而不是一组值或列表.
-
2 NF: 第二范式适用于有复合主键的表. 它要求表中的所有非主属性完全依赖于整个主键, 而不仅仅是主键的一部分, 这消除了部分函数依赖.
-
3 NF: 第三范式要求一个表中的所有非主属性既不依赖于主键的一部分, 也不依赖于其他非主属性, 这消除了传递函数依赖.
-
BCNF: BC 范式是对第三范式的进一步强化. 在 BCNF 中, 每个函数依赖 X -> Y, X 必须是候选键, 这消除了由于候选键之间的依赖关系而产生的冗余.
7.3.2 多值依赖范式
-
4 NF: 第四范式主要解决多值依赖问题. 多值依赖在数据库中出现时, 一个属性依赖于另一个属性, 但是这种依赖是在多个值之间, 而不仅仅是单个值.
-
5 NF: 第五范式也被称为投影连接范式. 它处理的是更复杂的依赖问题, 一个关系不能被分解成多个关系, 然后通过自然连接操作恢复到原来的关系.
7.4 分解
7.4 1 无损分解
无损分解是指一个关系的分解, 使得我们可以通过在分解后的关系上进行自然连接来恢复原始关系, 而不会丢失信息.
7.4.2 有损分解
有损分解会使得我们无法通过在分解后的关系上进行自然连接来完全恢复原始关系.
7.4.3 投影独立性
投影独立性, 也被称为无损连接性, 它要求分解后的关系通过自然连接能够恢复到原来的关系, 而不会引入原来不存在的元组, 也不会丢失原来的元组.
7.5 Armstrong 公理
-
反身性 (Reflexivity): 如果 Y 是 X 的子集, 那么 X → Y.
-
增强性 (Augmentation): 如果 X → Y, 那么对于任何 Z, XZ → YZ.
-
传递性 (Transitivity): 如果 X → Y 且 Y → Z, 那么 X → Z.
根据 Armstrong 公理, 我们可以推导出以下推论:
-
联合规则 (Union): 如果 X → Y 且 X → Z, 那么 X → YZ.
-
分解规则 (Decomposition): 如果 X → YZ, 那么 X → Y 且 X → Z.
-
伪传递性 (Pseudo-Transitivity): 如果 X → Y 且 WY → Z, 那么 XW → Z.
7.6 相关算法
7.6.1 闭包算法
闭包的定义: 对于关系模式 R 和它的函数依赖集 F, 以及 R 的一个属性集合 X, X 的闭包 X+ 是所有在 F 的约束下可以从 X 推导出的属性的集合. 也就是说, 如果存在一个函数依赖 X → A, 在 F 的约束下成立, 那么 A 就在 X+ 中.
如 r(A, B, C, G, H, I), A → B, A → C, CG → H, CG → I, B → H,
可以得出 A → ABCH, CG → HI, B → H, AG → ABCGHI, 即 (AG)+ = U 是候选码.
7.6.2 BCNF 分解算法
同样是上面的例子, 根据闭包关系依次分解, 直到全部满足 BCNF.
首先 (A, B, C, G, H, I) → (A, B, C, H), (A, G, I), 考虑到 (A, B, C, H) 仍不满足 BCNF, 继续分解得 (A, B, C, H) → (A, B, C), (B, H).
另一个例子: R = (A, B, C, D, E, F, G, H), F = (AB → C, AC → B, AD → E, B → D, BC → A, E → G), R1 = (A, B, C, D, E), R2 = (D, E, G, H),
对于 R1, AB → ABCDE, AC → ABCDE, AD → E, B → D, BC → ABCDE, 因此有三个候选码: AB, AC, BC, 属于 1 NF.
从 AD → E 开始分解 (A, B, C, D, E) → (A, D, E), (A, B ,C, D), 其中 (A, B, C, D) → (B, D), (A, B, C).
对于 R2, DEH → G, 因此有一个候选码: DEH, 属于 1 NF.
分解 (D, E, G, H) → (E, G), (D, E, H).
8 数据库恢复技术
8.1 事务
事务 (Transaction) 是一个或多个相关的数据操作序列, 这些操作要么全部执行 (提交), 要么全部不执行 (回滚). 事务提供了一种机制, 使数据库从一种一致状态转换到另一种一致状态.
在 BEGIN TRANSACTION 和 COMMIT 之间的所有 SQL 语句组成了一个事务. 如果所有的操作都执行成功, 那么在 COMMIT 语句执行后, 这些操作对数据库的改变就会被永久保存下来. 如果在这个过程中出现了错误, 将使用 ROLLBACK 语句来撤销这个事务中的所有操作, 数据库会回到 BEGIN TRANSACTION 执行前的状态.
-
原子性 (Atomicity): 原子性是指一个事务作为一个单一的不可分割的单位, 要么全部成功执行, 要么全部不执行.
-
一致性 (Consistency): 一致性是指每个事务都将数据库从一种一致状态转换为另一种一致状态. 在事务开始和结束时, 数据库的完整性约束必须得到保持. 例如, 银行转账的场景下, 转账前后的资金总量应该是不变的.
-
隔离性 (Isolation): 隔离性是指并发执行的多个事务之间应该相互隔离, 每个事务都应该在一种看似独立运行的环境中执行.
-
持久性 (Durability): 持久性是指一旦一个事务被提交, 那么它对数据库中的更改就应该是永久性的. 即使在系统崩溃或断电的情况下, 这些更改也不应该丢失.
8.2 日志
日志文件可以被用于实现事务的撤销 (UNDO) 和重做 (REDO) 操作, 从而在系统崩溃或其他故障发生时恢复数据库到一个一致的状态.
使用日志文件进行撤销的操作是基于以下两种原则:
-
Write-Ahead Logging (先写日志): 在任何改变实际被应用到数据库之前, 相关的日志记录都应该先写入到日志文件中. 这确保了在系统崩溃后, 所有已提交的事务的日志记录都已经保存在日志文件中, 因此可以通过重做这些日志记录来恢复这些事务.
-
UNDO (撤销): 在数据库系统恢复期间, 可以利用日志文件中的信息来撤销那些未完成 (或者说未提交) 的事务. 具体的撤销操作是按照日志记录的逆序进行的, 从最新的日志记录开始, 一直到对应事务的开始日志记录为止.
8.3 检查点
在系统崩溃并重启后, 检查点有助于提高恢复效率:
-
重做 (REDO) 阶段: 系统从最近的检查点开始扫描日志. 对于每个检查点之后的事务, 如果找到了它的 COMMIT 记录, 那么就重做这个事务的所有操作. 这一阶段确保了所有在系统崩溃前已经提交的事务的更改都写入到磁盘中.
-
撤销 (UNDO) 阶段: 系统再次扫描日志, 但是这次是从最新的日志记录开始, 向前扫描到最近的检查点. 对于每个还没有完成的事务, 系统撤销其所有的操作. 这一阶段确保了所有在系统崩溃时还没有提交的事务的更改都被撤销。
8.4 备份
8.4.1 静态备份
静态备份, 也被称为冷备份或离线备份, 是指在系统完全停止服务或离线的状态下进行的备份. 这意味着在备份过程中, 系统中没有任何写入或更新操作在进行. 静态备份可以保证数据的一致性和完整性, 因为它排除了并发操作可能带来的影响. 但是静态备份需要停止系统的服务, 对于需要 24/7 服务的系统来说, 这是不可接受的.
8.4.2 动态备份
动态备份, 也被称为热备份或在线备份, 是指在系统正常运行和提供服务的状态下进行的备份. 这意味着在备份过程中, 可能有写入或更新操作在进行. 动态备份的优点是它可以在不中断服务的情况下进行, 这对于需要 24/7 服务的系统来说非常重要.
8.5 数据库镜像
数据库镜像的工作原理是: 每当在主数据库中进行更改时, 这些更改也会在镜像数据库中进行. 这是通过将事务日志从主数据库复制到镜像数据库, 并在镜像数据库中重新执行这些事务来实现的. 这样, 镜像数据库就始终保持与主数据库一致.
-
故障切换 (Failover): 如果主数据库出现故障, 可以快速切换到镜像数据库, 以此最小化系统的停机时间.
-
数据保护: 如果由于硬件故障, 数据损坏, 人为错误或其他原因导致主数据库的数据丢失, 可以从镜像数据库恢复数据.
-
负载平衡: 可以将只读查询发送到镜像数据库, 以此减轻主数据库的负载.
9 并发执行
9.1 隔离级别
-
读未提交 (Read Uncommitted): 这是最低的隔离级别. 在这个级别, 一个事务可能看到其他事务还未提交的更改, 这些更改有可能被回滚, 因此这个级别可能会产生脏读问题, 即一个事务读到了另一个未提交事务的中间状态数据.
-
读已提交 (Read Committed): 在这个级别, 一个事务只能看到其他事务已提交的更改. 这解决了脏读的问题, 但可能产生不可重复读问题, 即在同一个事务内多次读取同样的数据返回的结果却不相同.
-
可重复读 (Repeatable Read): 在这个级别, 一个事务在其执行期间总是看到一致的数据. 也就是说, 如果它读取一行数据, 那么在该事务剩余的执行期间, 它将总是看到该行的相同的内容, 即使其他事务试图修改它. 这解决了不可重复读 (UPDATE) 的问题, 但可能产生幻读 (INSERT) 问题, 即在事务重新执行一次查询时,会看到其他新插入的满足查询条件的行.
-
串行化 (Serializable): 这是最高的隔离级别. 在这个级别, 事务被完全串行化执行, 即每次只有一个事务在执行, 其他事务必须等待当前事务完成后才能执行. 这解决了幻读的问题, 但效率最低, 因为无法进行并发执行.
9.2 基本封锁类型
9.2.1 排他锁 (X)
排他锁 (Exclusive lock) 是一种被广泛应用于数据库并发控制的锁机制. 当一个事务在某个数据项上设置了排他锁后, 该数据项就只能被此事务读取和修改, 其它的事务无法对其进行读取或者修改操作. 直到拥有排他锁的事务结束, 该数据项才能被其它事务访问.
9.2.2 共享锁 (S)
共享锁 (Shared lock), 也被称为读锁, 是另一种常见的数据库并发控制机制. 与排他锁不同的是, 当一个事务在某个数据项上设置了共享锁后, 该数据项可以被其它的事务进行读取, 但是不能进行修改. 直到所有拥有共享锁的事务都结束, 这个数据项才能被其它事务修改.
9.3 封锁协议
9.3.1 一级封锁协议
一级封锁协议要求在一个事务开始读取或者修改某个数据项的时候, 必须对其设置排他锁, 只有当该事务结束时, 才能释放这个排他锁.
这等同于 Read Uncommited, 可能会产生脏读问题.
9.3.2 二级封锁协议
二级封锁协议在一级封锁协议的基础上, 增加了一个规则: 一个事务在读取数据项前, 必须对其设置共享锁, 操作完成后释放.
这等同于 Read Commited, 可能会产生不可重复读问题.
9.3.3 三级封锁协议
三级封锁协议在二级封锁协议的基础上, 增加了一个规则: 一个事务只有在其全部结束后, 才能释放所有的锁.
这等同于 Repeatable Read, 可能会产生幻读问题.
9.4 并发调度
并发调度常用两段锁协议.
按照两段锁协议, 事务 T 在其生命周期内的所有锁操作分为两个阶段: 首先是一个扩展阶段, 然后是一个收缩阶段.
-
扩展阶段 (Growing Phase): 在扩展阶段, 事务可以获取新的锁, 但不能释放任何已经持有的锁. 也就是说, 事务可以根据需要在多个数据项上逐个获取锁, 但一旦获取, 就不能在此阶段内释放.
-
收缩阶段 (Shrinking Phase): 进入收缩阶段后, 事务可以开始释放它持有的锁, 但不能再获取新的锁. 这意味着在此阶段, 事务只能释放锁, 不能再增加新的锁.
两段锁协议的关键在于, 一旦事务开始释放锁, 它就不能再获取新的锁. 这个特性可以保证事务的串行化, 从而避免许多并发控制的问题.
9.5 封锁粒度
9.5.1 多粒度封锁
数据库级别
这是最大的封锁粒度. 当数据库上设置了锁时, 整个数据库都不能被其他事务访问.
表级别
这是次大的封锁粒度. 对整个表进行加锁, 这样在锁定期间只有一个事务可以访问该表. 但这种锁的粒度依然比较大,容易引发锁冲突,降低并发性。
行级别
这是最小的封锁粒度. 它允许事务锁定单独的一行数据. 行级锁提供了最高的并发性, 但也需要更多的系统资源来管理大量的锁.
9.5.2 意向锁
意向锁是一种表级别的锁, 用来表明一个事务打算在某一行或多行上设置共享锁或排他锁.
有两种类型的意向锁: 意向共享锁 (IS) 和意向排他锁 (IX). 如果一个事务打算在一行或多行上设置共享锁, 就在表上设置意向共享锁; 如果打算设置排他锁, 就设置意向排他锁. 这样, 当一个事务想要在表级别上设置锁时, 就可以先检查表上的意向锁, 如果存在与其冲突的意向锁, 就说明有其他事务在行级别上设置了锁, 这个事务就需要等待.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号