
运维面试题
Linux 面试题
1、如何看当前Linux系统有几颗物理CPU和每颗CPU的核数?
答:在/proc(puoruake)/cpuinfo文件中查看
2、查看系统负载有哪些?后面的三个数值表示什么含义呢?
答:top、w、uptime; 其中load average即系统负载,三个数值分别表示一分钟、五分钟、十五分钟内系统的平均负载,即平均任务数。
3、如何以交互式的方法将其文件中的所有abc字符串更换为ABC?
答:tr 或 sed
4、简述下linux系统里的buffer和cache区别?
答:Buffer 是对磁盘(块)数据的缓存,而 Cache 是对文件(block)数据的缓存,他们既会用在读请求中,也会用的写请求中。
5、如何实时查看网卡流量为多少?如何查看历史网卡流量?
答:安装sysstat包,使用sar命令查看。(sar -n DEV 1 10 #一秒显示一次,一共显示10次;sar -n DEV -f /var/log/sa/sa22 #查看指定日期的流量日志)
6、如何查看当前系统都有哪些进程?
答:ps -aux 或者ps -ef
7、ps 查看系统进程时,有一列为STAT, 如果当前进程的stat为Ss 表示什么含义?如果为Z表示什么含义?
答:S表示正在休眠;s表示主进程;Z表示僵尸进程。
8、僵尸进程对系统有害吗?如何杀掉僵尸进程?
答:重启服务器电脑、找到该defunct僵尸进程的父进程,将该进程的父进程杀掉(ps -ef | grep defunct_process_pid)
9、如何查看某个网卡是否连接着交换机?
答:mii-tool eth0 或者 mii-tool eth1
10、linxu下设置DNS需要修改哪个配置文件?
答:(1)在文件 /etc/resolv.conf 中设置DNS;(2)在文件 /etc/sysconfig/network-scripts/ifcfg-eth0 中设置DNS
11、iptables四表五链都有哪些?简述下filter、nat表的作用。
答:四表=filter(fliute)【过滤数据包】、nat【网络地址转换】、managle(mannige)、raw(rou),默认是filter表;五链:PREROUTING(perrui) 、INPUT、FORWARD(fuo)、OUTPUT、POSTROUTING
12、把iptable的规则保存到一个文件中如何做?如何恢复?
答:使用iptables-save重定向到文件中;使用iptables-restore(weisituoer)反重定向回来
13、如何备份某个用户的任务计划?
答:将/var/spool/cron/目录下指定用户的任务计划拷贝到备份目录cron_bak/下即可
14、任务计划格式中,前面5个数字分表表示什么含义?
答:依次表示:分、时、日、月、周
15、某个账号登陆linux后,系统会在哪些日志文件中记录相关信息?
答:用户身份验证过程记录在/var/log/secure(sekuer)中,登录成功的信息记录在/var/log/wtmp。
16、网卡或者硬盘有问题时,可以通过使用哪个命令查看相关信息?
答:使用命令dmesg
17、shell中什么时候会用到break和continue命令?并且这两个命令的作用是什么?
答:在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell使用 break 和 continue 来跳出循环。break命令 允许跳出所有循环(终止执行后面的所有循环)。continue命令 不会跳出所有循环,仅仅跳出当前符合条件的循环。
18、如何查看当前系统有几块盘?磁盘的使用率和磁盘io的读写使用情况用什么工具可以查看?
答:lsblk 、df -Th 、iostat -xdm 1 # 一般会有个经验值,比如,ioutil要小于80%, svctm要小于2ms。
19、自定义解析域名的时候,我们可以编辑哪个文件?是否可以一个ip对应多个域名?是否可以一个域名对应多个ip?
答:编辑 /etc/hosts ,可以一个ip对应多个域名,不可以一个域名对多个ip
20、有一天你突然发现公司网站访问速度变的很慢很慢,你该怎么办呢?(服务器可以登陆,提示:你可以从系统负载和网卡流量入手)
答:可以从两个方面入手分析:分析系统负载,使用w命令或者uptime命令查看系统负载,如果负载很高,则使用top命令查看CPU,MEM等占用情况,要么是CPU繁忙,要么是内存不够,如果这二者都正常,再去使用sar命令分析网卡流量,分析是不是遭到了攻击。一旦分析出问题的原因,采取对应的措施解决,如决定要不要杀死一些进程,或者禁止一些访问等。
21、LVM新增磁盘扩容过程
答:
1、创建物理卷并添加卷组
2、添加到逻辑卷
3、现在,逻辑卷已经扩展,你需要调整文件系统的大小以扩展逻辑卷内的空间
文件句柄面试题
1. 什么是文件句柄?
- 文件句柄是操作系统用来标识和管理打开文件的抽象概念。它是一个整数或指针,程序通过它来访问文件。
- 在 Linux/Unix 系统中,文件句柄通常是一个非负整数(文件描述符,File Descriptor)。
- 在 Windows 系统中,文件句柄是一个指针(HANDLE)。
2、文件描述符(File Descriptor)是什么?
文件描述符是 Linux/Unix 系统中用于标识打开文件的整数。
每个进程都有一个文件描述符表,用于记录打开的文件。
标准文件描述符:
- 0:标准输入(stdin)
- 1:标准输出(stdout)
- 2:标准错误(stderr)
3、df -h 发现磁盘空间满了,但是任凭各个文件目录下 du -sh * 也找不到大文件,怎么解决
答:lsof -n | grep deleted 查看到占用的进程,通过kill -9 进程号或重启服务解决;当我们使用rm在linux上删除了大文件,但是如果有进程打开了这个大文件,却没有关闭这个文件的句柄,那么linux内核还是不会释放这个文件的磁盘空间
Shell
1、如何检查文件或目录是否存在?
答:检查文件:-f;检查目录:-d;
2、如何在出现异常时退出shell脚本?
答:使用 $? ,进行判断
3、如何调试 Shell 脚本?
答:使用 -x 参数运行脚本,打印每条命令及其结果
4、如何定义和调用函数?

grep、awk、sed 三剑客
1、grep 的常用选项有哪些?
- -i:忽略大小写。
- -v:反向匹配,输出不匹配的行。
- -r:递归搜索目录中的文件。
- -n:显示匹配行的行号。
- -c:统计匹配的行数。
- -E:支持扩展正则表达式(等同于 egrep)。
2、如何使用 grep 递归搜索目录?
答:grep -r "pattern" /path/to/dir
3、如何使用 grep 统计匹配的行数?
答:grep -c "pattern" file.txt
4、如何使用 awk 打印文件的某一列?
答:awk '{ print $1 }' file.txt
5、如何使用 awk 计算某一列的总和?
答:awk '{ sum += $1 } END { print sum }' file.txt
6、如何使用 awk 设置字段分隔符?
答:awk -F':' '{ print $1 }' /etc/passwd
7、sed 的基本语法是什么?
答:sed 's/old/new/' file.txt
- s:替换命令。
- old:被替换的内容。
- new:替换后的内容。
8、如何将文件中的 "foo" 替换为 "bar"。?
答案:sed 's/foo/bar/' file.txt
9、如何使用 sed 删除文件中的第 5 行内容?
答:sed '5d' file.txt
10、如何使用 sed 替换文件中的所有匹配内容?
答案:使用 g 标志 --- sed 's/foo/bar/g' file.txt
iptables
1、iptables 与 firewalld/nftables 有什么区别?
- iptables:传统的 Linux 防火墙工具,直接操作内核 netfilter
- firewalld:动态防火墙管理器,底层使用 iptables 或 nftables
2、iptables 有哪几个内置表?各自的作用是什么?
- filter 表:默认表,用于数据包过滤(INPUT/OUTPUT/FORWARD)
- nat 表:网络地址转换(PREROUTING/POSTROUTING/OUTPUT)
- mangle 表:特殊数据包修改(所有链)
- raw 表:连接跟踪豁免(PREROUTING/OUTPUT)
- security 表:SELinux 相关标记(较少使用)
3、解释 iptables 的默认链及其数据流
- PREROUTING:数据包进入路由决策前
- INPUT:目标为本机的数据包
- FORWARD:需要转发的数据包
- OUTPUT:本机产生的数据包
- POSTROUTING:数据包离开路由决策后
4、如何查看当前的 iptables 规则?
- iptables -L -n -v # 查看 filter 表规则
- iptables -t nat -L -n -v # 查看 nat 表规则
5、如何保存和恢复 iptables 规则?
- 保存规则(取决于发行版):iptables-save > /etc/iptables.rules
- 恢复规则:iptables-restore < /etc/iptables.rules 或 service iptables save # RHEL/CentOS
git
1、Git 的基本工作流程是怎样的?
- 修改工作目录中的文件
- 将更改暂存 (git add)
- 提交更改到本地仓库 (git commit)
- 推送到远程仓库 (git push)
2、如何创建一个新的 Git 仓库?
- 初始化新仓库:git init
- 克隆现有仓库:git clone
3、解释 .git 目录下的重要文件和目录
- HEAD:当前所在分支或提交
- config:仓库配置
- objects/:Git 对象存储(提交、树、blob)
- refs/:引用(分支和标签)
- hooks/:客户端和服务端钩子脚本
- index:暂存区信息
4、如何查看当前仓库的状态?
git status
5、如何撤销最后一次提交?
- 保留更改在工作目录:git reset --soft HEAD~1
- 完全删除提交(慎用):git reset --hard HEAD~1
6、如何创建和切换分支?
- 创建分支:git branch
- 切换分支:git checkout
- 创建并切换分支(一步完成):git checkout -b
docker 容器
1、容器隔离及限制的底层技术是什么?
答:cgroup 和 namespace 是最重要的两种技术。cgroup 实现系统资源限额, namespace 实现资源隔离。
2、namespace 分别对应六种资源有什么?
答:Mount(文件系统)、UTS(主机名称)、IPC(内存)、PID(进程)、Network(网络) 和 User(用户)
3、Docker 安装时会自动在 host 上创建三个网桥模式,都叫什么?并简述下这几个不同的网络模式。
答:bridge、host、none
4、Docker架构简单描述下
答:docker采用的是c/s架构。客户端向服务端发送请求,服务端负责构建、运行和分发容器。并且客户端和服务端可以运行在同一个宿主机上,客户端也可以通过socket与远程的服务端通信。
5、Docker 的核心组件都有什么?
答:Docker 客户端 - Client 、Docker 服务器 - Docker daemon 、Docker 镜像 - Image、 Registry 仓库 – Registry、Docker 容器 - Container
6、创建容器的过程docker都做了哪些事情,简单描述下
答:
-
Docker 客户端执行 docker run 命令。
-
Docker daemon 发现本地没有 httpd 镜像。
-
daemon 从 Docker Hub 下载镜像。
-
下载完成,镜像 httpd 被保存到本地。
-
Docker daemon 启动容器。
7、为什么 base 镜像 都很小?就比如centos在docker这里就很小,200M左右。
答:Linux系统的组成,Linux 操作系统由Bootfs(内核空间)和 Rootfs(用户空间)组成,因为对于 base 镜像来说,底层直接用宿主机的 kernel,自己只需要提供 rootfs 。
8、简述容器中copy-on-Write的特性
答:当用某个镜像创建了一个容器,在容器中只有当需要修改时才复制一份数据在容器层,这种特性被称作 Copy-on-Write。
9、Dockerfile 的基本结构是什么?
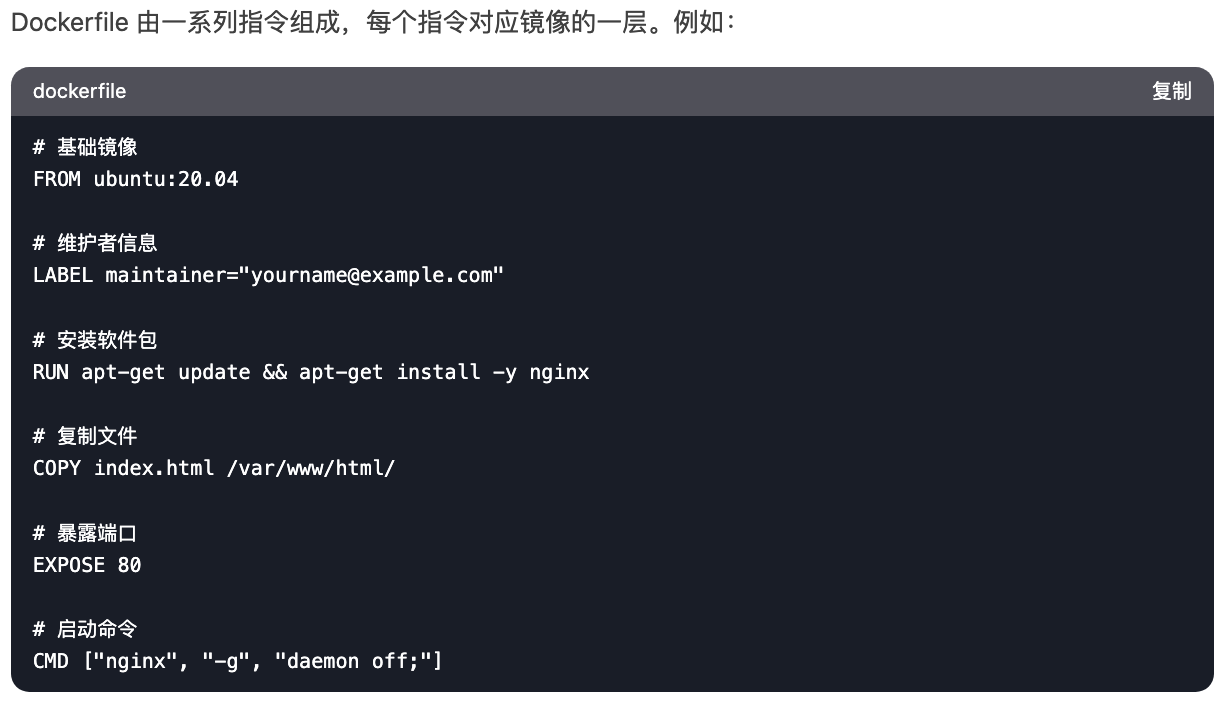
10、RUN 和 CMD 的区别是什么?
答:
- RUN:在构建镜像时执行命令,用于安装软件包或配置环境。
- CMD:在容器启动时执行命令,用于定义默认的容器行为。
11、COPY 和 ADD 的区别是什么?
答:
- COPY:仅支持复制本地文件或目录到镜像中。
- ADD:除了复制功能外,还支持自动解压和从远程 URL 下载文件。
12、如何查看 Docker 镜像的构建历史?
答:使用 docker history 命令
13、如何清理未使用的 Docker 资源?
删除未使用的镜像:docker image prune -a
删除未使用的容器:docker container prune
删除未使用的卷:docker volume prune
14、如何启动 Docker Compose 应用
答案:docker-compose up -d。 -d:后台运行。
15、如何指定 Docker Compose 文件?
答:docker-compose -f custom-compose.yml up
16、如何查看 Docker Compose 应用的日志?
答:使用 docker-compose logs 命令
编排k8s
1.说下k8s的核心组件都有哪些,并简述下他们各自的作用
答:
- API Server:提供 Kubernetes API。
- Scheduler:负责调度 Pod 到合适的节点。
- Controller Manager:运行控制器(如 Node Controller、Replication Controller)。
- etcd:分布式键值存储,保存集群状态。
- Kubelet:管理节点上的 Pod 和容器。
- Kube Proxy:实现服务负载均衡和网络代理。
- Container Runtime:运行容器的软件(如 Docker、containerd)。
2、k8s中都有哪些对象资源?
答:namespace、controller、pod、pv、pvc、configmap、secret、service、ingress
3、labels 的本质是什么?他的作用又是什么?
答:Label其实就一对 key/value ,被关联到对象上。他可以起到服务发现和集群调度的作用。
4、Service 在 K8s 中有哪几种类型?
答:ClusterIp、NodePort、LoadBalancer
5、Secret 在k8s中的作用?
答:Secret 解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者 Pod Spec中。
PS : 只有与 apiserver 组件进行交互的 pod 才会有如下的 证书、命名空间、tekon密钥。
6、简述下PV 和 PVC是什么
答:PV 可以看作可用的存储资源,PVC则是对存储资源的申请需求
7、简述Kubernetes Replica Set 和 Replication Controller 之间有什么区别?
答:两者几乎一样,都是确保在任何给定时间运行指定数量的 Pod 副本。不同之处在于RS 使用基于集合的选择器,而 Replication Controller 使用基于权限的选择器。
8、一般Kubernetes是如何进行优雅的节点关机维护?
答:由于Kubernetes节点运行大量Pod,因此在进行关机维护之前,建议先使用kubectl drain将该节点的Pod进行驱逐,然后进行关机维护。
**9、什么是 ConfigMap 和 Secret?
- ConfigMap:用于存储非敏感的配置数据。
- Secret:用于存储敏感数据(如密码、密钥)。
10、什么是 StatefulSet?
答案:StatefulSet 用于管理有状态应用,确保 Pod 的唯一性和持久化存储。
11、什么是 Service?
答案:Service 用于定义一组 Pod 的访问策略,提供负载均衡和服务发现。
12、什么是 DaemonSet?
答案:DaemonSet 用于在每个节点上运行一个 Pod 副本,通常用于日志收集或网络代理。
13、什么是 Ingress?
答案:Ingress 用于管理外部访问集群服务的 HTTP/HTTPS 路由。
14、如何定义资源清单中的环境变量?

15、资源清单中的 apiVersion 字段有什么作用?
答案: apiVersion 指定了 Kubernetes API 的版本,不同资源可能属于不同的 API 组。例如:
核心 API 组:v1(如 Pod、Service)。
扩展 API 组:apps/v1(如 Deployment)、batch/v1(如 Job)。
16、如何定义资源清单中的资源限制(Resource Limits)?
答案:
requests: 容器启动时请求的资源。
limits: 容器资源使用的上限。
17、如何定义 Pod 的健康检查
答:
livenessProbe: 检查容器是否存活。
readinessProbe: 检查容器是否准备好接收流量。
18、pod的生命周期
pod对象自从创建开始至终止退出的时间范围称为生命周期,在这段时间中,pod会处于多种不同的状态,并执行一些操作;其中,创建主容器为必须的操作,其他可选的操作还包括运行初始化容器(init container)、容器启动后钩子(start hook)、容器的存活性探测(liveness probe)、就绪性探测(readiness probe)以及容器终止前狗子(pre stop hook)等,这些操作是否执行则取决于pod的定义。
19、描述 Pod 从创建到终止的完整生命周期过程
kubectl 调用 apiserver –> etcd –> kubelet –> CRI 进行容器初始化;
首先会先启动一个pause容器(任何pod启动时都会先pause容器);
init C 容器不会伴随整个pod的生命周期;如果是正常退出(0),进入main C,否则(非0),一直重启 失败;
进入main C后有两个参数,start:在刚启动时可以允许他执行一个命令,stop:退出时也可以允许他执行一个命令;
readiness模板:可以在main C运行的多少秒之后进行就绪检测;检测通过后,pod状态就为running,否则为failed;
liveness模板:伴随着整个main C的生命周期,当main C里面的进程 与 liveness检测结果不一致时,就可以执行对应的命令;
20、Pod 生命周期有哪些主要阶段?
Pending:Pod 已被系统接受,但容器尚未创建或运行;
Running:Pod 已绑定到节点,所有容器已创建且至少有一个在运行;
Succeeded:所有容器成功终止且不会重启;
Failed:所有容器终止,且至少有一个容器以失败状态退出;
Unknown:无法获取 Pod 状态(通常由于节点通信问题);
21、Service Account的作用
答:Service Account 用来访问 Kubernetes API,由 Kubernetes 自动创建,并且会自动挂载到 Pod的/run/secrets/kubernetes.io/serviceaccount目录中。PS : 只有与 apiserver 组件进行交互的 pod 才会有如下的 证书、命名空间、tekon密钥。

22、PV和PVC的生命周期
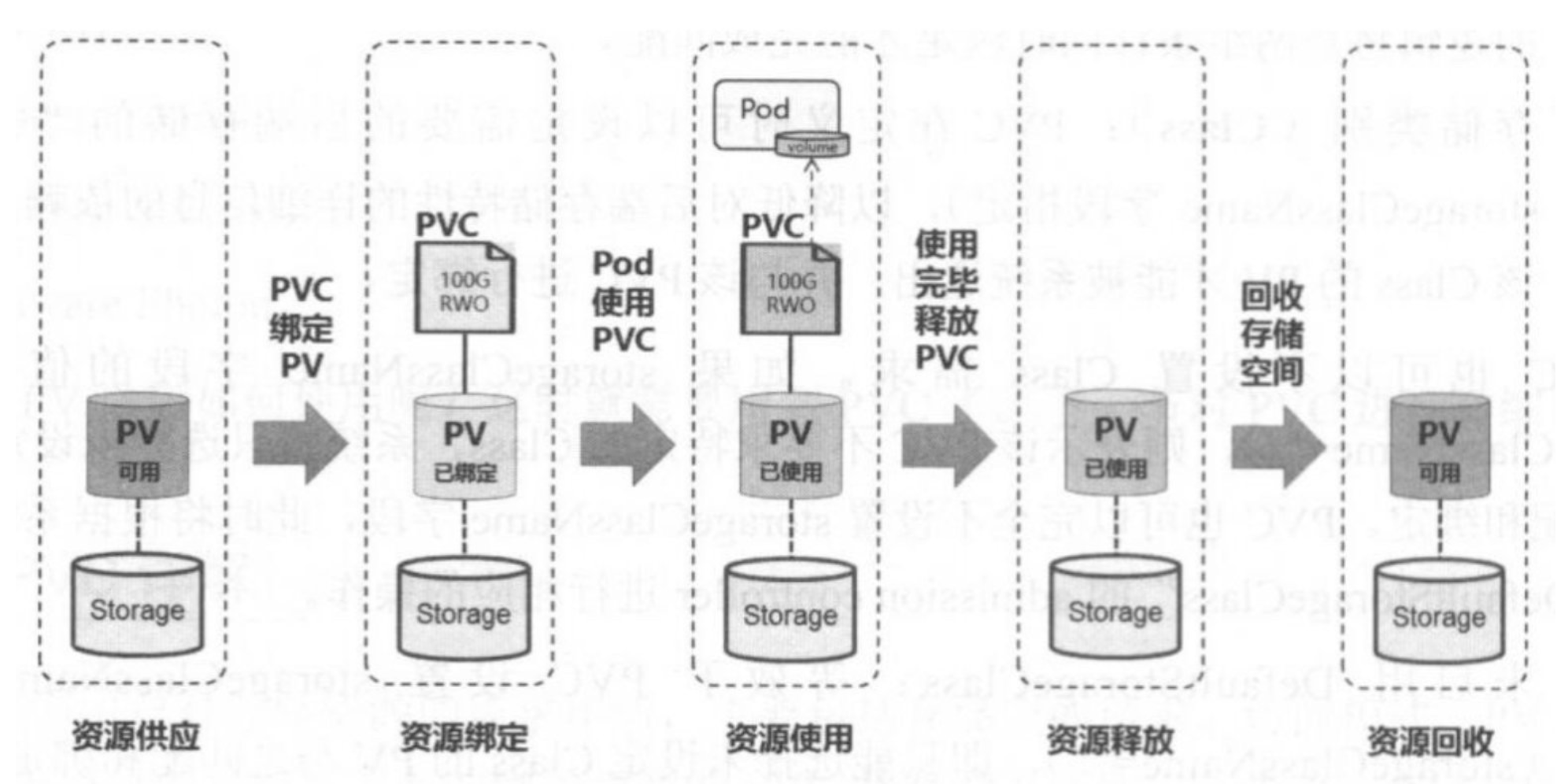
23、PV卷都有哪些声明状态
Available(可用)——一块空闲资源还没有被任何声明绑定
Bound(已绑定)——卷已经被声明绑定
Released(已释放)——声明被删除,但是资源还未被集群重新声明
Failed(失败)——该卷的自动回收失败
ansible自动化
1、Ansible常用模块及左右
答:command ping yum copy service shell file replace user group
2、什么是Playbooks?简答讲下
答:Playbooks 可以理解为一个编排文件,基于YAML语言编写的。用于描述远程系统实施的过程,或者描述流程中的一系列步骤。
3、shell模块与command模块的区别?
答:command只能识别一些简单的linux命令,shell能识别一点复杂性命令。
4、要对1000台机器收集内核版本,如何让ansible以面向过程的方式执行收集这些信息?
答:将其配置文件中的 forks 参数改为1就好。
5、如何调试 Ansible Playbook
答:使用 --check 参数进行模拟运行
6、如何收集目标主机的 Facts系统信息?
答:使用 setup 模块收集 Facts;
web网站
1、一个网站的形成都有哪些东西?
答:域名、网页、主页;HTTP、URL、HTML、超链接
2、简述下静态页面与动态页面的差别
答:静态页面内容几乎是固定的, 而动态页面的内容会因用户、浏览器、时间等而发生变化。
3、URL的组成部分都有哪些?
答:协议、域名、端口、URL文件资源、参数(query)、片段(fragment)
4、简单介绍下HTTP协议
答:HTTP就是一个超文本传输协议,定义了客户端与服务器端之间文本传输的规范。
5、返回码 200、301、302、404 的含义是什么?
答:200 服务器成功返回内容,301/2 永久/临时重定向,404 请求的页面不存在
6、简述DNS进行域名解析的过程
答:
-
浏览器缓存:浏览器会按照一定的频率缓存DNS记录。
-
操作系统缓存:如果浏览器缓存中找不到需要的DNS记录,那就去操作系统中找。
-
路由缓存:路由器也有DNS缓存。
-
缓存代理:国内代理的DNS服务器,有点类似于阿里云的CDN。
-
dns根服务器:ISP是互联网服务提供商(Internet Service Provider)的简称,ISP有专门的DNS服务器应对DNS查询请求。
Nginx服务
1、什么是正向代理和反向代理?
答:正向代理就是一个人发送一个请求直接就到达了目标的服务器;反方代理就是请求统一被Nginx接收,nginx反向代理服务器接收到之后,按照一定的规 则分发给了后端的业务处理服务器进行处理了
2、nginx中的location主要作用是什么?
答:location就是根据用户请求的URI来执行不同的应用,也就是根据用户请求的网站URL进行匹配,匹配成功即进行相关的操作。
3、什么是动静分离?
答:将动态请求和静态请求区分访问,静态由Nginx处理, 动态由PHP处理或Tomcat处理。
4、Nginx负载均衡是基于那个模块来实现的?
答:upstream
5、Nginx中负载均衡算法策略里常用的都有哪些?
答:轮询、权重、ip_hash
6、Nginx 的日志在那个模块下配置?
答:在 http 或 server 块中配置日志
7、Nginx 的 location 块有哪些匹配规则?
答:
- 精确匹配:location = /path。
- 前缀匹配:location /path。
- 正则匹配:location ~ .php$。
- 优先顺序:精确匹配 > 前缀匹配(最长匹配) > 正则匹配。
8、优化 Nginx 的性能可以从哪里入手
答:调整工作进程数、使用高效的epoll事件模型、启用 Gzip 压缩等
9、什么是 Nginx 的 rewrite 规则?
使用 rewrite 指令实现 URL 重写;
标志位
- break:停止处理当前 rewrite;
- redirect:302 临时重定向;
- permanent:301 永久重定向;
Mysql服务
1、查看当前库和表的命令
2、mysql的增删查改的命令
3、索引的作用是什么?
答:加快查询的速度。
4、简述下MysQL中的事物
答:事务就是由一组SQL语句组成的,保证一组SQL语句要么全部执行成功,要么全部执行失败,以此维护数据的完整性。
5、事务中的四个特性都是什么?
答: (Atomicity) 原子性、(Consistency) 一致性、 (Isolation) 隔离性、 (Durability) 持久性
- 原子性(Atomicity):事务中的操作要么全部成功,要么全部失败。
- 一致性(Consistency):事务执行前后,数据库的状态保持一致。
- 隔离性(Isolation):多个事务并发执行时,彼此隔离。
- 持久性(Durability):事务提交后,数据永久保存。
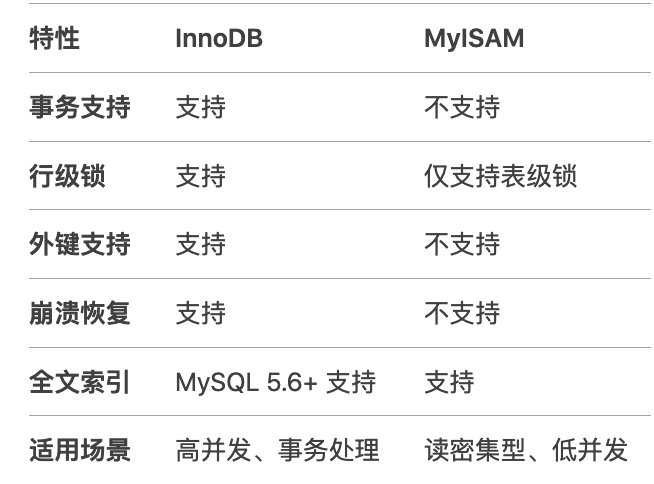
6、InnoDB和MyISAM存储引擎的区别
答:
- InnoDB:支持事务、行级锁和外键,适用于大多数场景。
- MyISAM:不支持事务和行级锁,但查询性能较高,适用于读密集型场景。
![]()
7、MySQL 的日志类型有哪些?
答:
错误日志(Error Log):记录 MySQL 运行时的错误信息。
查询日志(General Log):记录所有 SQL 查询。
慢查询日志(Slow Query Log):记录执行时间超过阈值的查询。
二进制日志(Binary Log):记录所有写操作,用于复制和恢复。
重做日志(Redo Log):InnoDB 用于崩溃恢复。
8、MySQL 的隔离级别有哪些?
答:MySQL 支持以下隔离级别:
- 读未提交(Read Uncommitted):最低级别,可能读到未提交的数据。
- 读已提交(Read Committed):只能读到已提交的数据。
- 可重复读(Repeatable Read):默认级别,保证同一事务中多次读取结果一致。
- 串行化(Serializable):最高级别,完全隔离事务。
- 可以通过 SET TRANSACTION ISOLATION LEVEL 设置隔离级别。
9、如何解决著主从复制中断问题?
常见原因:
- 主从数据不一致
- 网络中断
- 主库二进制日志被清理
解决方法: - 跳过错误(谨慎使用):SET GLOBAL sql_slave_skip_counter = 1; START SLAVE;
- 重新配置复制:STOP SLAVE; CHANGE MASTER TO ...; START SLAVE;
10、主库宕机后如何提升从库为新主库?
- 确认从库数据最新
- 停止复制:STOP SLAVE;
- 重置从库:RESET SLAVE ALL; (8.0+) 或 RESET MASTER;
- 启用写入:SET GLOBAL read_only = OFF;
- 重配其他从库指向新主库
Redis服务
1、简述下什么是redis?
答:Redis 是一个基于内存的高性能key-value数据库。
2、Redis五大数据类型是什么
答:String、list、set、zset、hash
3、Redis持久化有几种方式?他们的区别又是什么?
答:RDB持久化(类似于快照功能,定期将内存中的数据快照保存到磁盘)、AOF持久化(近似实时性,记录所有写操作命令)
- RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
- AOF持久化是以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
4、Redis 为什么单线程还这么快?
答:redis 是将所有的数据全部放在内存中的,所以说使用单线程去操作效率就是最高的,多线程(CPU上下文会切换:耗时的操作),对于内存系统来说,如果没有上下文切换效率就是最高的!多次读写都是在一个CPU上的,在内存情况下,这个就是最佳的方案!
5、Redis 的事务机制是什么?
答:Redis 通过 MULTI、EXEC、DISCARD 和 WATCH 命令实现事务:
- MULTI:开启事务。
- EXEC:执行事务中的所有命令。
- DISCARD:取消事务。
- WATCH:监视一个或多个键,如果在事务执行期间这些键被修改,则事务不会执行。
- 注意:Redis 的事务不支持回滚(Rollback)。
6、Redis 的缓存穿透、缓存击穿和缓存雪崩是什么?
答:
缓存穿透:大量请求查询不存在的数据,导致请求直接落到数据库。
解决方案:使用布隆过滤器(Bloom Filter)过滤无效请求。
缓存击穿:热点数据过期后,大量请求同时落到数据库。
解决方案:设置永不过期或使用互斥锁。
缓存雪崩:大量缓存同时过期,导致请求集中落到数据库。
解决方案:设置随机的过期时间。
7、Redis 的持久化文件如何备份?
答:
- 直接备份 RDB 文件(dump.rdb)或 AOF 文件(appendonly.aof)
- 使用 BGSAVE 命令创建 RDB 快照。
- 使用工具如 redis-cli --rdb 导出数据。
网络
1、tcp与udp的区别?
答:他俩都是传输协议,基于连接与无连接;对系统资源的要求(TCP较多,UDP少);TCP保证数据完整性,UDP可能丢包;
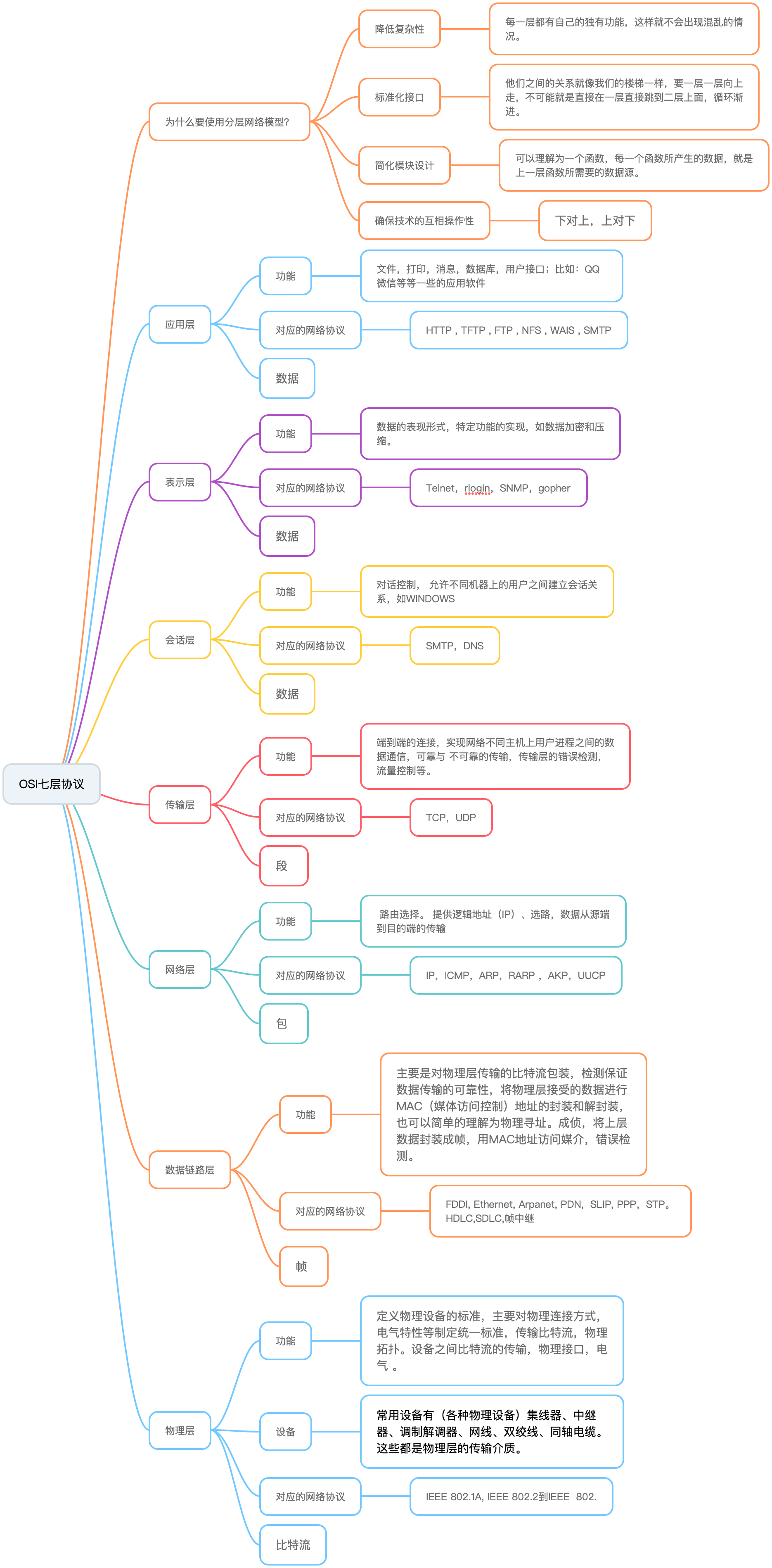
2、讲下网络7层模型OSI都有哪些?
答:OSI 七层模型架构图
3、简述下路由的过程
答:当路由器收到一个报文时,会找出目的IP地址,通过目的IP与自己的路由表进行匹配,根据路由条目的指示决定出接口及下一跳IP。
4、路由表的组成部分有哪些?
答:目的IP、掩码、路由协议、优先级、开销,下一跳IP及下一跳出接口。
5、怎么查看路由表?
答:dis ip routing
keeplived & LVS
1、keeplived 有哪些模块?并说下他们各自的作用
答:keepalived主要有三个模块,分别是core、check和vrrp
-
core模块为keepalived的核心,负责主进程的启动、维护及全局配置文件的加载和解析。
-
vrrp模块是来实现VRRP协议的。
-
check负责健康检查,常见的方式有端口检查及URL检查。
2、解释一下vrrp 协议
答:虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。
3、简述LVS的工作模式及其工作过程?
答:LVS 有三种负载均衡的模式,分别是VS/NAT(nat 模式)、VS/DR(路由模式)、VS/TUN(隧道模式)。
NAT模式(VS-NAT)
原理:首先负载均衡器接收到客户的请求数据包时,根据调度算法决定将请求发送给哪个后端的真实服务器(RS)。然后负载均衡器就把客户端发送的请求数据包的目标IP地址及端口改成后端真实服务器的IP地址(RIP)。真实服务器响应完请求后,查看默认路由,把响应后的数据包发送给负载均衡器,负载均衡器在接收到响应包后,把包的源地址改成虚拟地址(VIP)然后发送回给客户端。
优点:集群中的服务器可以使用任何支持TCP/IP的操作系统,只要负载均衡器有一个合法的IP地址。
缺点:扩展性有限,当服务器节点增长过多时,由于所有的请求和应答都需要经过负载均衡器,因此负载均衡器将成为整个系统的瓶颈。
IP隧道模式(VS-TUN)
原理:首先负载均衡器接收到客户的请求数据包时,根据调度算法决定将请求发送给哪个后端的真实服务器(RS)。然后负载均衡器就把客户端发送的请求报文封装一层IP隧道(T-IP)转发到真实服务器(RS)。真实服务器响应完请求后,查看默认路由,把响应后的数据包直接发送给客户端,不需要经过负载均衡器。
优点:负载均衡器只负责将请求包分发给后端节点服务器,而RS将应答包直接发给用户。所以,减少了负载均衡器的大量数据流动,负载均衡器不再是系统的瓶颈,也能处理很巨大的请求量。
缺点:隧道模式的RS节点需要合法IP,这种方式需要所有的服务器支持“IP Tunneling”。
直接路由模式(VS-DR)
原理:首先负载均衡器接收到客户的请求数据包时,根据调度算法决定将请求发送给哪个后端的真实服务器(RS)。然后负载均衡器就把客户端发送的请求数据包的目标MAC地址改成后端真实服务器的MAC地址(R-MAC)。真实服务器响应完请求后,查看默认路由,把响应后的数据包直接发送给客户端,不需要经过负载均衡器。
优点:负载均衡器只负责将请求包分发给后端节点服务器,而RS将应答包直接发给用户。所以,减少了负载均衡器的大量数据流动,负载均衡器不再是系统的瓶颈,也能处理很巨大的请求量。
缺点:需要负载均衡器与真实服务器RS都有一块网卡连接到同一物理网段上,必须在同一个局域网环境。
KVM虚拟化
1、什么是虚拟化?
答:就是将一台物理机虚拟成多台虚拟机,虚拟机之间互不干扰。
2、常见的虚拟化软件都有哪些?
答:vmware、kvm
3、怎么查看当前系统是使用哪家的虚拟化?
答:lscpu
4、kvm的三个组件及作用
答:libvirt(用来管理虚拟机)、virt(安装和克隆虚拟机)、qemu(管理虚拟机磁盘的)
5、如何查看正在运行的虚拟机
答:virsh list
6、kvm如何进行子机的开机关机操作
virsh start centos7 开机 virsh shutdown centos7 关机
7、kvm的网络模式有哪几种
- NAT模式:虚拟机通过主机的NAT网络访问外部网络。
- 桥接模式:虚拟机直接连接到物理网络,与主机在同一网络中。
- 用户模式:虚拟机通过主机的用户空间网络栈访问外部网络。
- VLAN模式:虚拟机连接到特定的VLAN。
8、KVM支持哪些存储格式?
- raw:原始格式,性能最好,但不支持快照。
- qcow2:支持压缩、快照和动态分配空间。
- vmdk:VMware兼容格式。
- vdi:VirtualBox兼容格式。
Jenkins
1、Jenkins 支持哪些触发器?
答:
- SCM 触发器:检测代码变更。
- 定时触发器:基于时间计划触发构建。
- 手动触发器:用户手动触发构建。
- 远程触发器:通过 API 或其他工具触发。
2、Jenkins 的工作流程是什么?
- 开发者提交代码到版本控制系统(如 Git)。
- Jenkins 检测代码变更,触发构建。
- 执行构建任务(如编译、测试)。
- 生成构建结果,反馈给开发者。
- 如果构建成功,可自动部署到目标环境。
3、大致讲一下jenkins是如何将gitlab仓库上的代码拉取到的本地并将其带脉发布到后端rs服务器上的
1. 准备工作
Jenkins 服务器:确保 Jenkins 已安装并正常运行。
GitLab 仓库:准备好需要拉取的代码仓库,并确保 Jenkins 有访问权限。
后端服务器:确保目标服务器(如 Tomcat、Nginx 等)已配置好,并支持部署。
插件安装:在 Jenkins 中安装必要的插件,如 Git、SSH、Pipeline 等。
2. 配置 Jenkins 任务
创建任务:
在 Jenkins 中创建一个新的任务(如 Freestyle 或 Pipeline 项目)。
配置 GitLab 仓库:
在任务配置中,选择源码管理为 Git。
填写 GitLab 仓库的 URL 和认证信息(如 SSH 密钥或用户名/密码)。
指定分支(如 main 或 master)。
配置构建触发器:
设置触发器为 GitLab Webhook,当代码推送到 GitLab 时自动触发构建。
或者使用轮询 SCM,定期检查代码变更。
配置构建步骤:
如果是 Freestyle 项目,添加构建步骤(如执行 Shell 脚本)。
如果是 Pipeline 项目,编写 Jenkinsfile 定义构建流程。
3. 编写构建和部署脚本
在构建步骤中,编写脚本完成以下操作:
拉取代码:
Jenkins 会自动从 GitLab 拉取代码到工作目录(WORKSPACE)。
构建代码:
根据项目类型,执行构建命令(如 mvn clean package 或 npm build)。
打包构建产物:
将构建生成的产物(如 WAR、JAR 或静态文件)打包。
部署到后端服务器:
使用 SCP 或 SSH 将构建产物上传到目标服务器。
在目标服务器上执行部署命令(如重启服务或解压文件)。
示例 Shell 脚本:
bash
# 构建代码
mvn clean package
# 将构建产物上传到服务器
scp target/myapp.war user@backend-server:/opt/tomcat/webapps/
# 在服务器上重启服务
ssh user@backend-server "systemctl restart tomcat"
4. 配置 GitLab Webhook
在 GitLab 仓库中,进入 Settings > Webhooks。
添加 Webhook URL,格式为:http://<jenkins-server>/gitlab/build_now。
选择触发事件(如 Push 事件)。
保存并测试 Webhook,确保 Jenkins 能正确接收通知。
5. 触发构建和部署
手动触发:在 Jenkins 界面手动点击“立即构建”。
自动触发:当代码推送到 GitLab 时,Webhook 会通知 Jenkins 自动触发构建和部署。
6. 查看构建结果
在 Jenkins 中查看构建日志,确认构建和部署是否成功。
如果失败,根据日志排查问题并修复。
总结
Jenkins 通过以下步骤实现从 GitLab 拉取代码并部署到后端服务器:
配置 GitLab 仓库和构建触发器。
编写构建和部署脚本。
使用 GitLab Webhook 实现自动触发。
执行构建和部署流程。
这种方式可以高效地实现持续集成和持续部署(CI/CD)。
4、jenkins都有哪些比较常用的自带变量
答:
与构建相关的变量
BUILD_NUMBER:当前构建的编号。
BUILD_ID:当前构建的唯一 ID。
BUILD_TAG:构建的标签,格式为 jenkins-
JOB_NAME:当前任务的名称。
JOB_BASE_NAME:当前任务的名称(不包含文件夹路径)。
EXECUTOR_NUMBER:执行构建的执行器编号。
与工作空间相关的变量
WORKSPACE:当前构建的工作目录路径。
WORKSPACE_TMP:临时工作目录路径。
与节点相关的变量
NODE_NAME:执行构建的节点名称(Master 或 Agent)。
NODE_LABELS:执行构建的节点的标签。
与源码管理相关的变量
GIT_COMMIT:Git 提交的哈希值。
GIT_BRANCH:Git 分支名称。
GIT_URL:Git 仓库的 URL。
SVN_REVISION:SVN 的版本号。
与时间相关的变量
BUILD_TIMESTAMP:构建的时间戳。
BUILD_DATE:构建的日期。
BUILD_TIME:构建的时间。
ELK
1、什么是 ELK Stack
Elasticsearch:分布式搜索和分析引擎,用于存储和检索数据。
Logstash:数据收集和处理管道,用于解析、转换和传输数据。
Kibana:数据可视化工具,用于展示和分析 Elasticsearch 中的数据。
2、如何优化 Elasticsearch 的性能?
分片和副本:合理设置分片和副本数量。
硬件配置:使用 SSD、增加内存和 CPU。
索引优化:定期删除旧索引,使用索引生命周期管理(ILM)。
查询优化:避免复杂的查询,使用缓存。
3、什么是 Elasticsearch 的倒排索引?
答:倒排索引是 Elasticsearch 的核心数据结构,用于快速查找包含特定词项的文档。它由词项到文档的映射组成,支持高效的全文搜索。
4、Kibana 如何与 Elasticsearch 集成?
答:Kibana 通过 RESTful API 与 Elasticsearch 通信。在 Kibana 配置文件中指定 Elasticsearch 的地址
5、如何实现es索引日志的归档和清理?
答:使用索引生命周期管理(ILM)自动归档和删除旧索引。或者手动删除旧索引:
6、什么是 Beats?
答:Beats 是轻量级的数据收集器,用于将数据发送到 Elasticsearch 或 Logstash。常见的 Beats 包括:
- Filebeat:收集日志文件。
- Metricbeat:收集系统和服务指标。
- Packetbeat:收集网络流量数据。
RabbitMQ
1、RabbitMQ 有哪些安全机制?
- 认证:内置数据库/LDAP/HTTP
- 授权:Vhost级别权限控制
- SSL/TLS:加密通信
- 防火墙:限制端口访问(5672/15672等)
2、什么是 RabbitMQ?它的核心组件是什么?
- 生产者(Producer):发送消息的应用
- 消费者(Consumer):接收消息的应用
- 队列(Queue):存储消息的缓冲区
- 交换机(Exchange):接收生产者消息并路由到队
- 绑定(Binding):交换机和队列之间的规则连接
- 虚拟主机(Vhost):隔离的环境单元
3、如何确保消息不丢失?
生产者确认机制、消息持久化、消费者手动ACK
4、RabbitMQ 有哪些常见的性能瓶颈?如何解决?
- 磁盘 I/O:使用SSD,分离数据和日志磁盘
- 内存:增加内存,监控内存使用(rabbitmqctl status)
- CPU:优化交换机类型(避免复杂路由)
- 网络:减少小消息,启用消息压缩
5、如何创建和管理用户权限?
- 创建用户:rabbitmqctl add_user myuser mypassword
- 设置权限:rabbitmqctl set_permissions -p /myvhost myuser "." "." ".*"
- 设置标签(角色):rabbitmqctl set_user_tags myuser administrator
Prometheus
1、Prometheus 的核心组件有哪些?
答:
- Prometheus Server:负责数据收集、存储和查询。
- Client Libraries:用于在应用程序中埋点,暴露指标数据。
- Pushgateway:用于支持短生命周期任务的指标推送。
- Exporters:将第三方系统的指标暴露给 Prometheus。
- Alertmanager:处理警报通知和去重。
2、Alertmanager 的主要功能是什么?
答;Alertmanager 负责处理 Prometheus 发送的警报,支持以下功能:
- 去重:合并相同或相似的警报。
- 分组:将相关警报合并为一个通知。
- 路由:根据规则将警报发送到不同的接收者(如邮件、Slack)。
- 静默:临时屏蔽特定警报。
3、Prometheus 的数据模型是什么?
答:Prometheus 使用时间序列数据模型,每个时间序列由以下部分组成:
- 指标名称(Metric Name):描述指标的类别(如 http_requests_total)。
- 标签(Labels):键值对,用于标识时间序列的维度(如 method="GET")。
- 时间戳(Timestamp):数据点的时间。
- 样本值(Sample Value):数据点的值。
4、Prometheus 的查询语言是什么?
答:PromQL,用于查询和分析时间序列数据
5、什么是 Pushgateway?
答:Pushgateway 用于支持短生命周期任务的指标推送。任务将指标推送到 Pushgateway,Prometheus 再从 Pushgateway 拉取数据。
NFS
1、如何解决 NFS 挂载失败的问题
答:
- 检查网络连接和防火墙设置。
- 确保 NFS 服务正在运行。
- 检查 /etc/exports 文件配置是否正确。
- 查看日志文件(如 /var/log/messages 或 /var/log/syslog)。
2、NFS 的默认端口是什么?
答案:
- portmapper:111(TCP/UDP)。
- NFS:2049(TCP/UDP)。
- mountd:动态分配(可通过 rpcinfo -p 查看)。
3、NFS 与 SMB/CIFS 的区别是什么?
答案:
- NFS:主要用于 Unix/Linux 系统,性能较高。
- SMB/CIFS:主要用于 Windows 系统,支持更多功能(如文件锁定、打印服务)。
4、如何限制 NFS 客户端的访问?
答案:在 /etc/exports 文件中指定允许访问的 IP 或网段。例如 /shared_dir 192.168.1.10(rw)
zabbix
1、zabbix分了三种架构?
答案:
server-client架构:也是zabbix的最简单的架构,监控机和被监控机之间不经过任何代理 ,直接由zabbix server和zabbix agentd之间进行数据交互。适用于网络比较简单,设备比较少的监控环境 。
master-node-client架构:该架构是zabbix最复杂的监控架构,适用于跨网络、跨机房、设备较多的大型环境 。每个node同时也是一个server端,node下面可以接proxy,也可以直接接client 。node有自已的配置文件和数据库,其要做的是将配置信息和监控数据向master同步,master的故障或损坏对node其下架构的完整性。
server-proxy-client架构:其中proxy是server、client之间沟通的一个桥梁,proxy本身没有前端,本身也并不存放数据,只是将agentd发来的数据暂时存放,然后再提交给server ;该架构经常是和master-node-client架构做比较的架构 ,一般适用跨机房、跨网络的中型网络架构的监控。
2、是Zabbix模板?它有什么作用?
模板是预定义的监控项、触发器、图形等的集合;
可以批量应用到多个主机,实现标准化监控配置;
便于管理和维护;
3、如何添加一个新的主机到Zabbix监控系统中?
通过Web界面导航到"配置"→"主机"→"创建主机";
填写主机名称、可见名称、所属组;
添加接口(Agent, SNMP等);
关联模板;
4、如何优化Zabbix的性能?
数据库优化(分区表、索引优化);
调整Housekeeper设置;
使用Proxy分担负载;
调整监控项更新间隔;
使用主动式Agent检查;
5、Zabbix Agent无法连接,如何排查?
检查Agent服务是否运行;
检查网络连通性;
检查防火墙设置;
检查Zabbix Server和Agent配置文件中的Server/ServerActive参数;
查看Agent日志;
6、Zabbix由哪些主要组件组成?
Zabbix Server:Zabbix系统的中央处理单元
Zabbix Agent:安装在监控目标上的数据采集代理
Zabbix Proxy:分布式监控的中介节点
Zabbix Web界面:系统管理配置和可视化的前端
数据库(MySQL, PostgreSQL等):存储所有监控配置和历史数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号