djangorestframework
1、安装
pip install djangorestframework
Serializers and ModelSerializer
首先我们要定义一些序列化程序。我们创建一个名为 tutorial/quickstart/serializers.py的文件,来用作我们的数据表示。


# by gaoxin from rest_framework import serializers from .models import Book class PublisherSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class AuthorSerializer(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) book_obj = { "title": "Alex的使用教程", "w_category": 1, "pub_time": "2018-10-09", "publisher_id": 1, "author_list": [1, 2] } data = { "title": "Alex的使用教程2" } # 验证器:为某些字段设置额外的验证 # 权重信息大于钩子,就是先验证该条件 def my_validate(value): if "敏感信息" in value.lower(): raise serializers.ValidationError("不能含有敏感信息") else: return value # class BookSerializer(serializers.Serializer): # required=False 设置是收数据是该字段可以为空 # id = serializers.IntegerField(required=False) # validators=[my_validate] 验证器:为该字段设置额外的验证函数 # title = serializers.CharField(max_length=32, validators=[my_validate]) # CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) # source="get_category_display" 获取数字所对应的值 read_only=True 设置为只用于发送数据,不用于验证信息 # category = serializers.ChoiceField(choices=CHOICES, source="get_category_display", read_only=True) # write_only=True 接受信息验证时使用该字段,前段传数据时key要用w_category # w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) # pub_time = serializers.DateField() # # publisher = PublisherSerializer(read_only=True) # publisher_id = serializers.IntegerField(write_only=True) # author = AuthorSerializer(many=True, read_only=True) # author_list = serializers.ListField(write_only=True) # # post 创建数据时需要重构该方法 # def create(self, validated_data): # book = Book.objects.create(title=validated_data["title"], category=validated_data["w_category"], # pub_time=validated_data["pub_time"], publisher_id=validated_data["publisher_id"]) # book.author.add(*validated_data["author_list"]) # return book # # put 更新数据时需要重构该方法 # def update(self, instance, validated_data): # instance.title = validated_data.get("title", instance.title) # instance.category = validated_data.get("category", instance.category) # instance.pub_time = validated_data.get("pub_time", instance.pub_time) # instance.publisher_id = validated_data.get("publisher_id", instance.publisher_id) # 多对多数据时的方法 # if validated_data.get("author_list"): # instance.author.set(validated_data["author_list"]) # instance.save() # return instance # # 局部钩子函数为title字段设置额外的验证要求 # def validate_title(self, value): # if "python" not in value.lower(): # raise serializers.ValidationError("标题必须含有python") # return value # # 全局钩子 # def validate(self, attrs): # if attrs["w_category"] == 1 and attrs["publisher_id"] == 1: # return attrs # else: # raise serializers.ValidationError("分类以及标题不符合要求") class BookSerializer(serializers.ModelSerializer): # 根据相应的get_...方法执行只获取我们想要的数据 category_display = serializers.SerializerMethodField(read_only=True) publisher_info = serializers.SerializerMethodField(read_only=True) authors = serializers.SerializerMethodField(read_only=True) def get_category_display(self, obj): return obj.get_category_display() def get_authors(self, obj): authors_query_set = obj.author.all() return [{"id": author_obj.id, "name": author_obj.name} for author_obj in authors_query_set] def get_publisher_info(self, obj): # obj 是我们序列化的每个Book对象 publisher_obj = obj.publisher return {"id": publisher_obj.id, "title": publisher_obj.title} class Meta: model = Book # fields = ["id", "title", "pub_time"] fields = "__all__" # depth = 1 根据外键关系只向下找一层 depth = 2 向下找二层 # depth = 1 这种是获取所有字段 # read_only=True 结合下面的"write_only": True 原来显示的字段不展示,只显示需要的数据 extra_kwargs = {"category": {"write_only": True}, "publisher": {"write_only": True}, "author": {"write_only": True}}
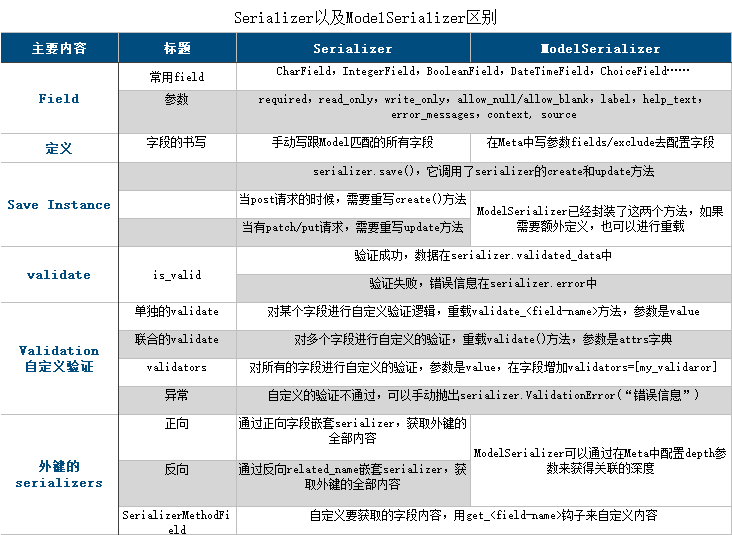
Serializer以及ModelSerializer区别(常用的)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号