pandas.groupby
groupby,分组统计,是数据分析时常用的一种手段
所谓的groupby就是一个拆分再合并的过程,就如下图所示:
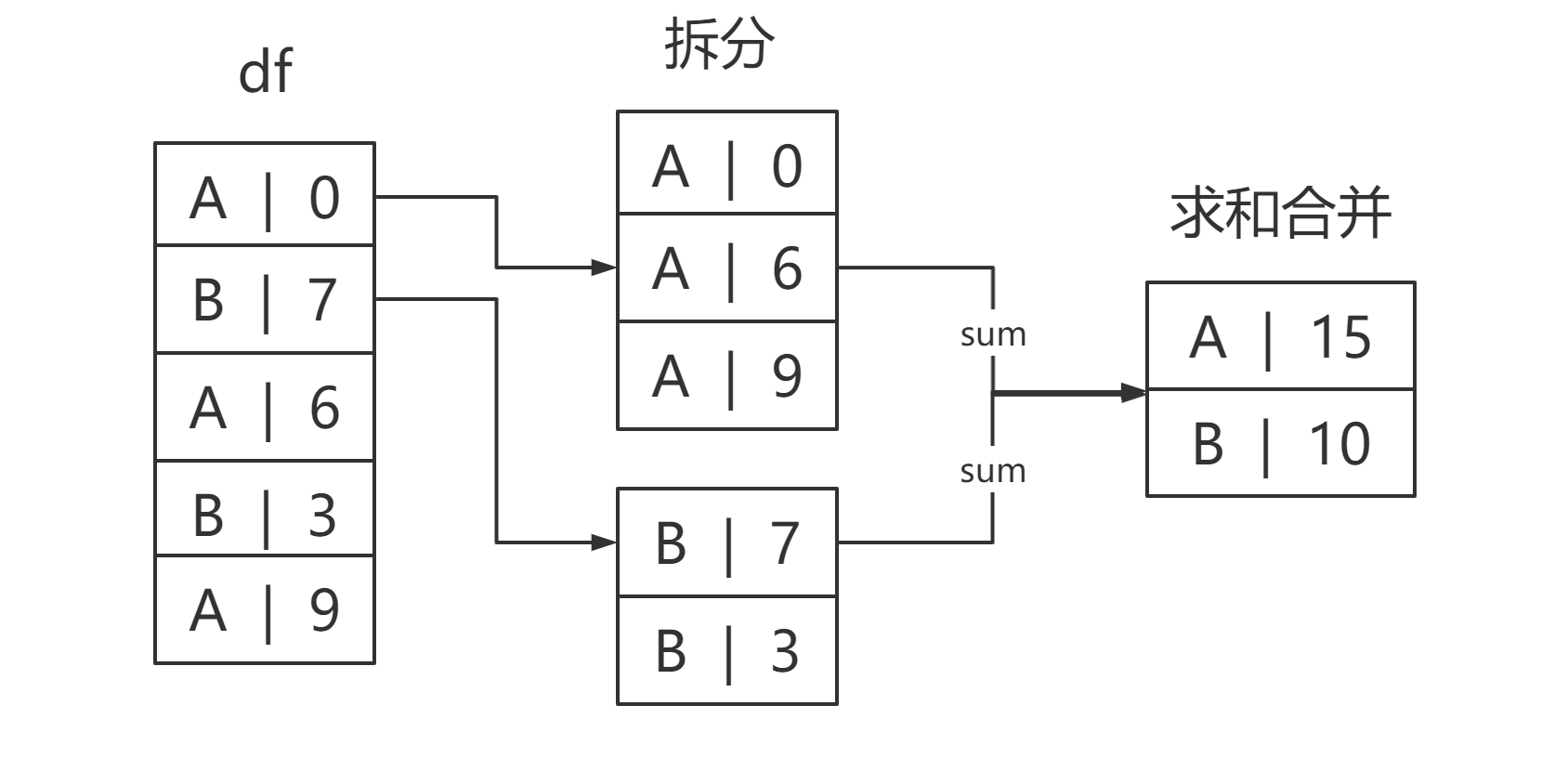
以列的名称作为分组依据
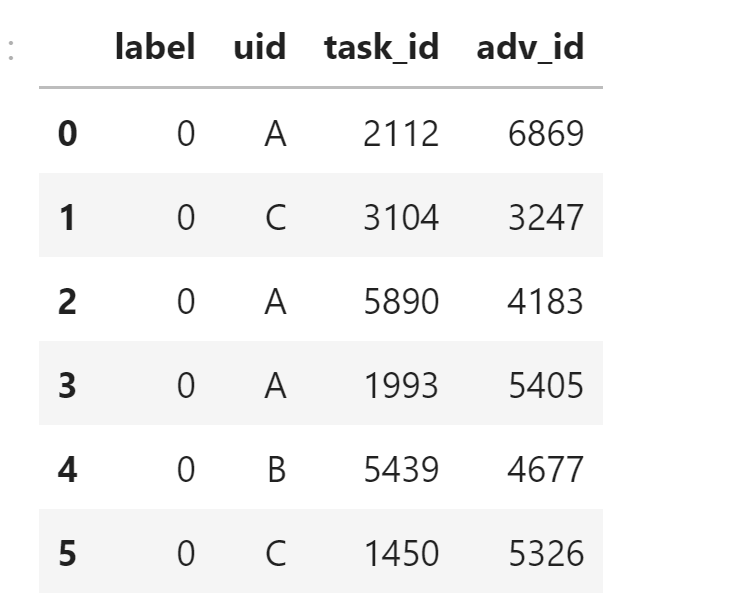
比如对于如下的训练集
对其他特征数量按照uid进行统计
b.groupby('uid').count()
结果如下:

对其他特征按照uid进行求和
b.groupby("uid").sum()
结果如下:

也可以单独选出某个列让他们按照升降序顺序排列
pd.DataFrame(b.groupby("uid").sum()['adv_id'].sort_values(ascending=False))
结果如下:

groupby分组产生的是一个二元元组,由分组名+数据块组成。实际上对于这个分组我们本身也是可以对他进行迭代遍历的:
for name,group in b.groupby('uid'):
print(name)
print(group)
print("*************")
结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号