爬虫学习
需要掌握Python对于文件的操作和json库
这是基于requests模块的爬虫学习
requests是Python原生中一款基于网络请求的模块,优势就是简单便捷,效率高。
作用:模拟浏览器发送请求。
使用方法:
- 指定url
- 发起请求
- 获取响应数据
- 对数据进行持久化存储
简单做个示例:
import requests
url = 'https://www.sogou.com/'
response = requests.get(url)
page_text = response.text
print(page_text)
with open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print("Successful!")
2、获取百度指定词条的搜索结果页面
第一种接触的反爬机制:UA(User-Agent)伪装,就是请求载体的身份标识,将自己伪装成浏览器而不是爬虫程序
UA伪装:将对应的User-Agent封装到一个字典中
import requests
# UA伪装
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url = 'https://www.baidu.com/s'
# 因为参数需要是动态的
# 处理URL携带的参数,封装到字典中
query = input("Input what you want to query")
param = {
'wd' : query
}
# 对指定的url发起请求
response = requests.get(url=url,params=param,headers=headers)
page_text = response.text
fileName = query + '.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print("Successful")
3、获取百度翻译的单词翻译结果
在百度翻译中我们遇到了一个页面局部刷新的情况,而页面局部刷新是可以由Ajax实现的,当我们在百度翻译的文本框中录入数据时,会自动进入Ajax请求发送,会对我们叶面的局部内容进行一个刷新。我们就可以去捕获一下这个Ajax请求。
现在我们在百度翻译的文本框中输入dog这个单词。
抓包中all对应所有请求,而XHR就是Ajax这些请求对应的数据包。、
在XHR中,通过分析可以发现sug中是一个Post请求,一个出现了三次,携带的参数分别为'd','do'和'dog',可知这就是3次Ajax请求,对应的是每一个字符的翻译结果。我们需要的是dog的,也就是第三个Ajax的结果。
在Response Headers中可以看到Content-Type,这就是服务器端响应回客户端的数据类型。可以知道我们返回的是一个json串,我们在Response选项卡中可以看到响应回来的json数据。
通过对转包的分析,我们可以知道:
- 我们发送了一个Post请求,这个请求携带了参数,我们需要request模块对这个请求的URL进行一次请求发送,且Post请求发送后如何处理这个请求携带的参数
- 这个响应数据是一组json数据
百度由于对百度翻译加上了反爬机制,所以目前获取不到结果了。不过headers(重点是useragent)和代理ip和动态验证码,这三个加上基本就没问题了,等学完爬虫来试一下能不能骗过百度的反爬机制。
import requests
import json
# UA伪装
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
post_url = 'https://fanyi.baidu.com/sug'
# 这里封装我们携带的参数
data = {
'word':'dog'
}
resopnse = requests.post(url=post_url,data=data,headers=headers)
json_obj = resopnse.json() # 直接返回一个对象
print(json_obj)
# 持久化存储
fp = open('./dog.json','w',encoding='utf-8')
# 返回的是有中文的,不能使用ASCII进行编码
json.dump(json_obj,fp=fp,ensure_ascii=False)
fp.close()
print("Success!")
4、爬取豆瓣电影分类排行榜
每次滚轮滑动到最下方滚轮就会回滚到中间,说明触发了Ajax请求。
通过抓包在XHR可以知道触发了Get请求,在最后可以看到Get请求携带的五个参数,说明我们对这个URL发起了一个Get请求并且携带参数,根据Content-Type可以知道返回的是一组Json数据。
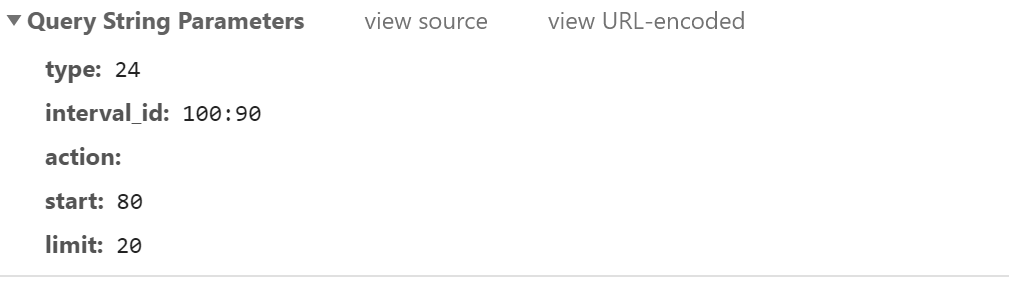
import requests
import json
# UA伪装
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
url = 'https://movie.douban.com/j/chart/top_list'
# 但凡有参数我们最好用字典封装起来
params = {
'type':'24',
'interval_id':'100:90',
'action':'',
'start':'1',
'limit':'20'
}
response = requests.get(url = url,params=params,headers=headers)
list_data = resopnse.json()
print(list_data)
fp = open('./douban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
fp.close()
print("Successful!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号