[LLM] 嵌入
嵌入(Embedding),这是一种寻找词和词之间相似性的 NLP 技术,它把词汇各个维度上的特征用数值向量进行表示,利用这些维度上特征的相似程度,就可以判断出哪些词和哪些词语义更加接近。
- 对文本进行嵌入操作:会生出向量的表示形式
- 对文本进行向量化操作:和上面一个意思
基本概念
举个例子:假设有这么一段文本
我喜欢小猫和小狗
经过分词器(Tokenizer)处理后,会变成词元 ID 列表:
| 词语 | 词元ID |
|---|---|
| 我 | 1001 |
| 喜欢 | 1002 |
| 小猫 | 2001 |
| 和 | 1003 |
| 小狗 | 2002 |
到目前为止,对于模型来讲看到的仍然只是一堆编号,没有任何语义信息。接下来要做的嵌入操作,就是要给这些词添加语义信息。
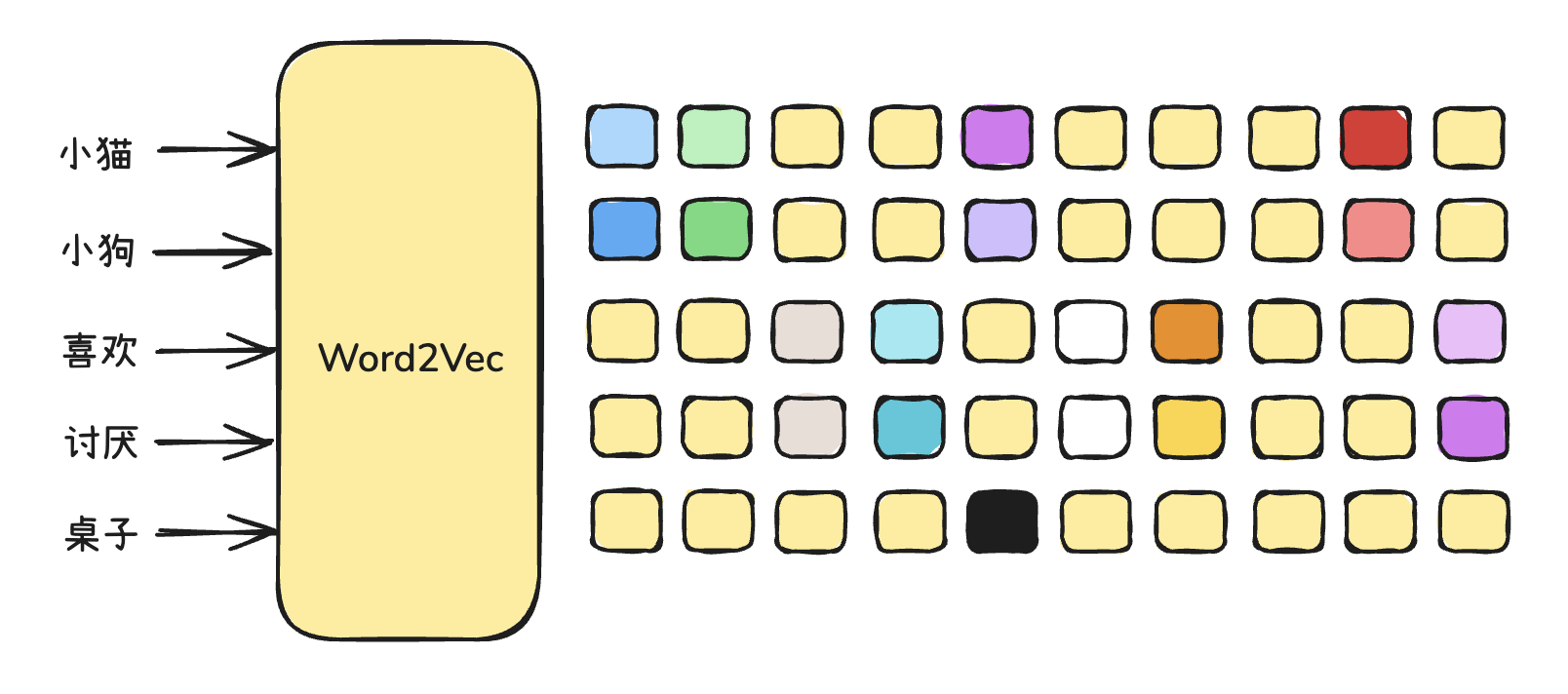
接下来引入一个 嵌入矩阵(embedding matrix),为每个词元嵌入向量信息。向量信息是多(高)维度的,一般能够达到成百上千维度。每一个维度,代表的就是一个语义方向。
这里我们做一个简化,假设就 4 维。如下:
| 向量维度 | 可能的语义方向(隐含) | 小猫的值 | 粗略含义类比 |
|---|---|---|---|
| 第 1 维 | 是否是动物? | 0.72 | 是动物,得分高 |
| 第 2 维 | 亲和力/可爱度 | 0.35 | 稍微可爱 |
| 第 3 维 | 体型大小(抽象) | 0.11 | 比较小 |
| 第 4 维 | 家养 vs 野外 | 0.80 | 更偏向家养 |
那么此时词元就嵌入了向量值,如下:
| Token ID | 词语 | 嵌入向量(4维) |
|---|---|---|
| 2001 | 小猫 | [0.72, 0.35, 0.11, 0.80] |
| 2002 | 小狗 | [0.70, 0.38, 0.14, 0.78] |
| 1002 | 喜欢 | [0.10, 0.93, 0.21, 0.11] |
现在,“小猫”和“小狗”不再是冰冷的词元ID,而是“位置相近的向量”,如下表所示:
| 对比项 | 小猫 🐱 | 小狗 🐶 | 差异分析 |
|---|---|---|---|
| 词元ID | 2001 | 2002 | 没有语义 |
| 嵌入向量 | [0.72, 0.35, 0.11, 0.80] | [0.70, 0.38, 0.14, 0.78] | 两者向量“很接近” |
| 结论 | 表示语义上很相似的动物 | 表示语义上很相似的动物 | 模型会把它们“当成相似概念”处理 |
我们可以将高维向量投影成二维空间来“可视化”它们之间的语义关系:
相似的词会靠得更近。
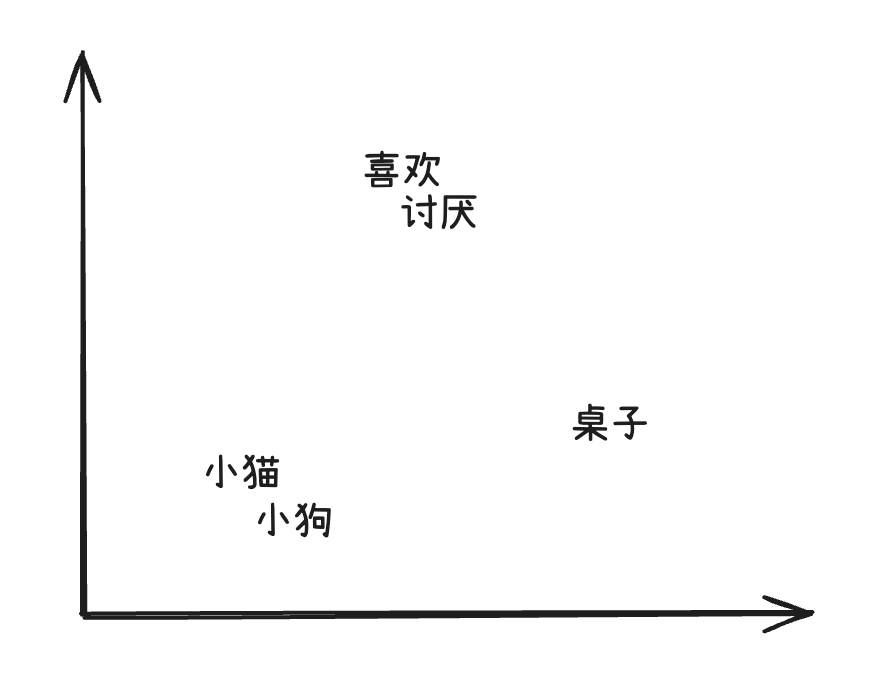
- “小猫”和“小狗”这种意思相近的词元,会靠得更近
- “喜欢”这种语义不同的词,会离它们稍远一些
- “讨厌”“桌子”这种不相关的词,也会离得比较远
通过向词元嵌入向量信息,能够带来如下的好处:
- 传递语义相似性:相似词向量靠近
- 支持上下文学习:嵌入可更新
- 可参与数学运算:词向量支持加减
- 输入给神经网络:向量可计算梯度
Word2Vec
文本、文字 TO Vec(向量那个单词的缩写)
2013年,托马斯・米克洛夫和他 Google 的同事们开发了 Word2Vec 算法,Word2Vec 采用了一种高效的方法来学习词汇的连续向量表示,这种方法将词汇表中的每个词都表示成固定长度的向量,从而使在大规模数据集上进行训练变得可行。
Word2Vec 有两种训练方式:
- CBOW模型
- Skip-Gram模型
这两种刚好是相反的。
1. CBOW模型
CBOW模型的核心思想是:给定一个词的上下文(前后词),预测中心词(目标词)。
例如有如下句子:
我 喜欢 吃 苹果
当输入上下文(“我”,“吃”)的时候,模型能够预测出“喜欢”
2. Skip-Gram模型
Skip-Gram模型则刚好相反,核心思想是:给定中心词,预测它的上下文词。
仍然还是这个句子:
我 喜欢 吃 苹果
当输入中心词:“喜欢”的时候,模型能够预测上下文词:“我”、“吃”
两者的对比
| 比较项 | CBOW | Skip-Gram |
|---|---|---|
| 训练目标 | 预测中心词 | 预测上下文 |
| 输入是什么? | 上下文词(多个) | 中心词(一个) |
| 输出是什么? | 中心词(一个) | 上下文词(多个) |
| 训练速度 | 快 | 慢 |
| 对稀有词表现 | 一般 | 更好 |
| 语义表达能力 | 差一些 | 更强 |
| 适合场景 | 大词频、高效率、短上下文窗口 | 稀有词、多语义任务、大语料 |
在训练 Word2Vec 时,可以选择使用其中一种。
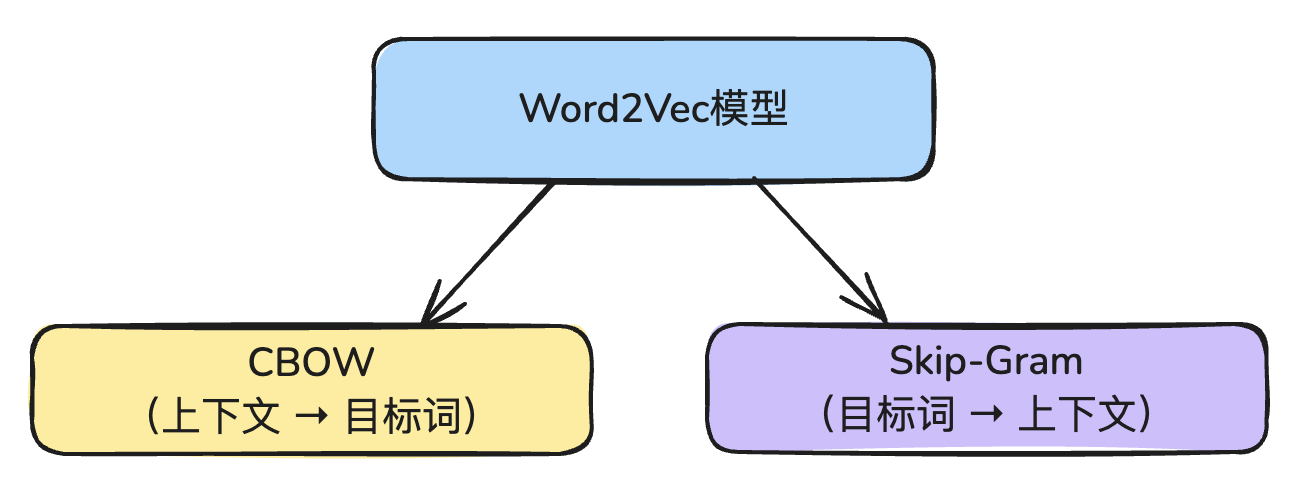
在训练 Word2Vec 时,只需在代码中指定:
sg=0表示使用 CBOW 模型sg=1表示使用 Skip-Gram 模型
代码实践
train_word2vec.py 文件,该文件用于做训练工作的:
import Word2Vec from gensim.models
// 拿出牛奶从冰箱里
from gensim.models import Word2Vec
# 从冰箱里拿出牛奶
# 示例语料
sentences = [
["i", "love", "deep", "learning"],
["i", "love", "nlp"],
["deep", "learning", "is", "fun"],
["nlp", "is", "a", "part", "of", "ai"],
["word2vec", "is", "a", "powerful", "embedding"]
]
# 训练模型
model = Word2Vec(sentences, vector_size=100, window=2, min_count=1, sg=1)
# 保存模型
model.save("word2vec.model")
print("模型训练完成并已保存。")
test_word2vec.py 用于测试:
from gensim.models import Word2Vec
# 加载模型
model = Word2Vec.load("word2vec.model")
# 获取某个词的词向量
print("词向量(nlp):")
print(model.wv["nlp"])
# 找出最相似的词
print("\n与 'nlp' 最相似的词:")
print(model.wv.most_similar("nlp", topn=3))
# 计算两个词的相似度
print("\n'deep' 和 'learning' 的相似度:")
print(model.wv.similarity("deep", "learning"))
-EOF-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号