[GenAI] 词元与嵌入
NLP 发展的4个阶段:
| 阶段 | 时间 | 方法 / 模型 | 类型 | 主要用途 | 是否考虑词序 / 语义 |
|---|---|---|---|---|---|
| 规则阶段 | 1950s–1970s | 语法规则、人工模板 | 人工构建规则系统 | 机器翻译、问答系统 | ✅ 语法结构,❌语义 |
| 统计阶段 | 1970s–2010s | Bag-of-Words (BoW) | 特征表示方法 | 文本分类、情感分析 | ❌ |
| TF-IDF | 加权特征表示 | 文本检索、关键词提取 | ❌ | ||
| N-Gram | 统计语言模型 | 语言建模、机器翻译 | ✅ 局部上下文,❌长依赖 | ||
| HMM | 概率生成模型 | 词性标注、语音识别 | ✅ | ||
| IBM 模型(1~5) | 对齐翻译模型 | 统计机器翻译 | ✅ 局部 | ||
| 深度学习阶段 | 2013–2018 | Word2Vec | 分布式词向量 | 构建语义空间、分类器输入 | ❌(静态嵌入) |
| GloVe | 基于矩阵的词向量 | 同上 | ❌ | ||
| ELMo | 上下文词向量(LSTM) | 命名实体识别、问答等 | ✅ 局部语境 | ||
| 大语言模型阶段 | 2018–至今 | BERT | 编码器(Transformer) | 预训练+微调,适用于多数 NLP 任务 | ✅ 深层语义 |
| GPT 系列(GPT-2/3/4) | 解码器(Transformer) | 文本生成、对话系统 | ✅ 强上下文与推理能力 | ||
| T5 | 编码器-解码器结构 | 多任务文本生成 | ✅ | ||
| ChatGPT | 应用层 LLM | 对话、创作、问答 | ✅ 多轮对话上下文 |
词袋模型会忽略词的顺序,只看词的集合:
- 我打了他
- 他打了我
词元
词元,英语里面叫做 Token,这是模型里面一个最基本的概念。大多数人和模型进行交互的时候,是通过网页平台的聊天界面来和模型进行交互。
在 OpenAI 平台官网,提供了在线查看词元的方式。
一句话--->分解成一个一个词元----> 输入LLM ---> 生成一个一个的词元
输入一句话,会进行一个分词的操作,分词的操作最终得到的是一个一个的词元。
每一个词元,都会有一个唯一的 ID,因此,最终输入到大模型的数据,是一个词元 ID 列表。
"this is a test"
["this", " is", " a", "test"]
[1122, 98, 3305, 13] ---> 送入到 LLM 里面
即便是分词,也会有不同的策略,常见的有:
- 词级分词
- 子词级分词
- 字符级分词
- 字节级分词
1. 词级分词
直接以“完整的词”为单位进行切分。适用于空格分隔语言,例如英语。
说白了就是以一个一个的单词为粒度来进行分词。
"this is a test"
["this", " is", " a", "test"]
特点:
- 粒度较大,语义清晰
- 对英文常见词效果很好
- 缺点是无法处理未登录词,不支持OOV
[!tip]
Out-of-Vocabulary,超出了(模型的)词表。所谓不支持 OOV,指的就是超出了模型的词表的词,就无法处理。
2. 子词级分词
这是目前 比较常用 的分词方案,将词分成更小的子词单元,如词干、前缀、后缀,适合处理未知词。
["this is a lovely dog"]
词级分词:["this", " is", " a", " lovely", " test"]
子词级分词:["th", "is", "a", "love", "ly", "te", "st"]
特点:
- 兼顾词级和字符级优点
- 支持 OOV,即便训练的词表里面没有这个单词,LLM 也能够处理。
3. 字符级分词
将每个字符作为一个词元,不依赖词典。
Hello
['H', 'e', 'l', 'l', 'o']
特点:
- 适合拼写敏感任务(如语言模型、自动补全)
- 能处理所有字符,OOV 问题消失(不存在造不出来的词)
- 缺点是序列长度变长,难以建模高级语义结构
4. 字节级分词
指的是将输入文本首先按UTF-8 字节切分,再对这些字节组成的序列进行建模或进一步压缩。换句话说,它的基本单位是字节而不是字符或词,因此具有语言无关性。
Hello 😊
[72, 101, 108, 108, 111, 32, 240, 159, 152, 138]
字节级分词是一种颇具竞争力的方法,其优势如下:
- 语言无关
- 处理 OOV 词能力强
- 简化 tokenizer 设计
- 对多语言非常友好
- 压缩空间效率高
不过也有一定的代价:
- 初始序列更长
- 解释性较差
- 模型训练更复杂
不同的语言模型,分词的效果也会不同,这里举个例子:
ChatGPT真厉害!
GPT2/GPT4
['Chat', 'G', 'PT', '真', '厉', '害', '!']
BERT
['[UNK]', '真', '厉', '害', '!']
Phi-3
['▁Chat', 'G', 'PT', '真', '厉', '害', '!']
具体如下表:
| 模型 | 分词方法 | 分词器工具 | 是否字节级 | 是否子词级 | OOV问题 |
|---|---|---|---|---|---|
| GPT-2 | Byte-level BPE | tiktoken |
是 | 是 | 无 |
| GPT-4 | Byte-level BPE(改进) | tiktoken |
是 | 是 | 无 |
| BERT | WordPiece | bert-tokenizer |
否 | 是 | 有 [UNK] |
| Phi-3 | SentencePiece (Unigram+BPE) | sentencepiece |
可选 | 是 | 无 |
嵌入
这是一种寻找词和词之间相似性的 NLP 技术,它把词汇各个维度上的特征用数值向量进行表示,利用这些维度上特征的相似程度,就可以判断出哪些词和哪些词语义更加接近。
举个例子:假设有这么一段文本
我喜欢小猫和小狗
首先第一步,需要进行分词处理:
| 词语 | 词元ID |
|---|---|
| 我 | 1001 |
| 喜欢 | 1002 |
| 小猫 | 2001 |
| 和 | 1003 |
| 小狗 | 2002 |
[1001, 1002, 2001, 1003, 2003]
目前为止,只是一个冷冰冰的词元ID列表。
接下来会为每一个词嵌入向量信息,向量信息是有非常非常多维度,做一个简化,假设只有4维:
小猫(2001),针对这个词,就会在每一个维度进行一个打分:
每一个维度的分数是0~1
| 向量维度 | 可能的语义方向(隐含) | 小猫的值 | 粗略含义类比 |
|---|---|---|---|
| 第 1 维 | 是否是动物? | 0.72 | 是动物,得分高 |
| 第 2 维 | 亲和力/可爱度 | 0.35 | 稍微可爱 |
| 第 3 维 | 体型大小(抽象) | 0.11 | 比较小 |
| 第 4 维 | 家养 vs 野外 | 0.80 | 更偏向家养 |
小猫这个词:
2001 --> [0.72, 0.35, 0.11, 0.8]
这个变化,我们称之为变成了一个多维的向量表,这个操作我们将其称之为嵌入。
在大模型中,一个词的维度能够达到成百上千。维度越高,语义就会越精确。
经过这么一步处理之后,每一个词元就变成了一个向量序列
| Token ID | 词语 | 嵌入向量(4维) |
|---|---|---|
| 2001 | 小猫 | [0.72, 0.35, 0.11, 0.80] |
| 2002 | 小狗 | [0.70, 0.38, 0.14, 0.78] |
| 1002 | 喜欢 | [0.10, 0.93, 0.21, 0.11] |
目前小猫和小狗就不再是冷冰冰的词元id,而是可以从多维向量中去判断两个词是否意思相近。(词袋模型)
| 对比项 | 小猫 🐱 | 小狗 🐶 | 差异分析 |
|---|---|---|---|
| 词元ID | 2001 | 2002 | 没有语义 |
| 嵌入向量 | [0.72, 0.35, 0.11, 0.80] | [0.70, 0.38, 0.14, 0.78] | 两者向量“很接近” |
| 结论 | 表示语义上很相似的动物 | 表示语义上很相似的动物 | 模型会把它们“当成相似概念”处理 |
如果对高维向量进行投影,投影成二维空间:
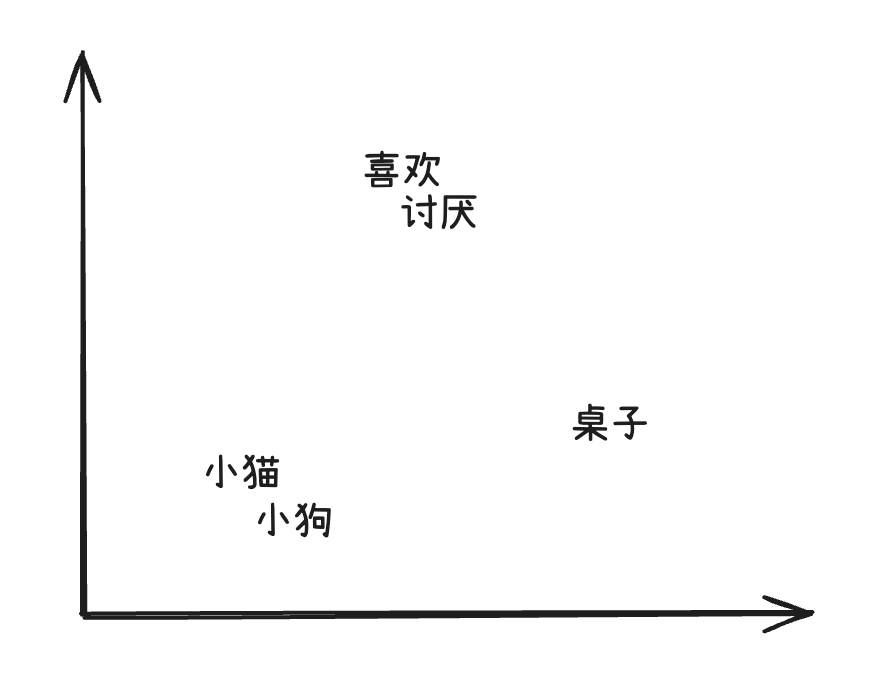
通过向词元嵌入向量信息,能够带来如下的好处:
- 传递语义相似性:相似词向量靠近
- 支持上下文学习:嵌入可更新
- 可参与数学运算:词向量支持加减
- 输入给神经网络:向量可计算梯度
Word2Vec
1. 基本介绍
2013年,托马斯・米克洛夫和他 Google 的同事们开发了 Word2Vec 算法,Word2Vec 采用了一种高效的方法来学习词汇的连续向量表示,这种方法将词汇表中的每个词都表示成固定长度的向量,从而使在大规模数据集上进行训练变得可行。
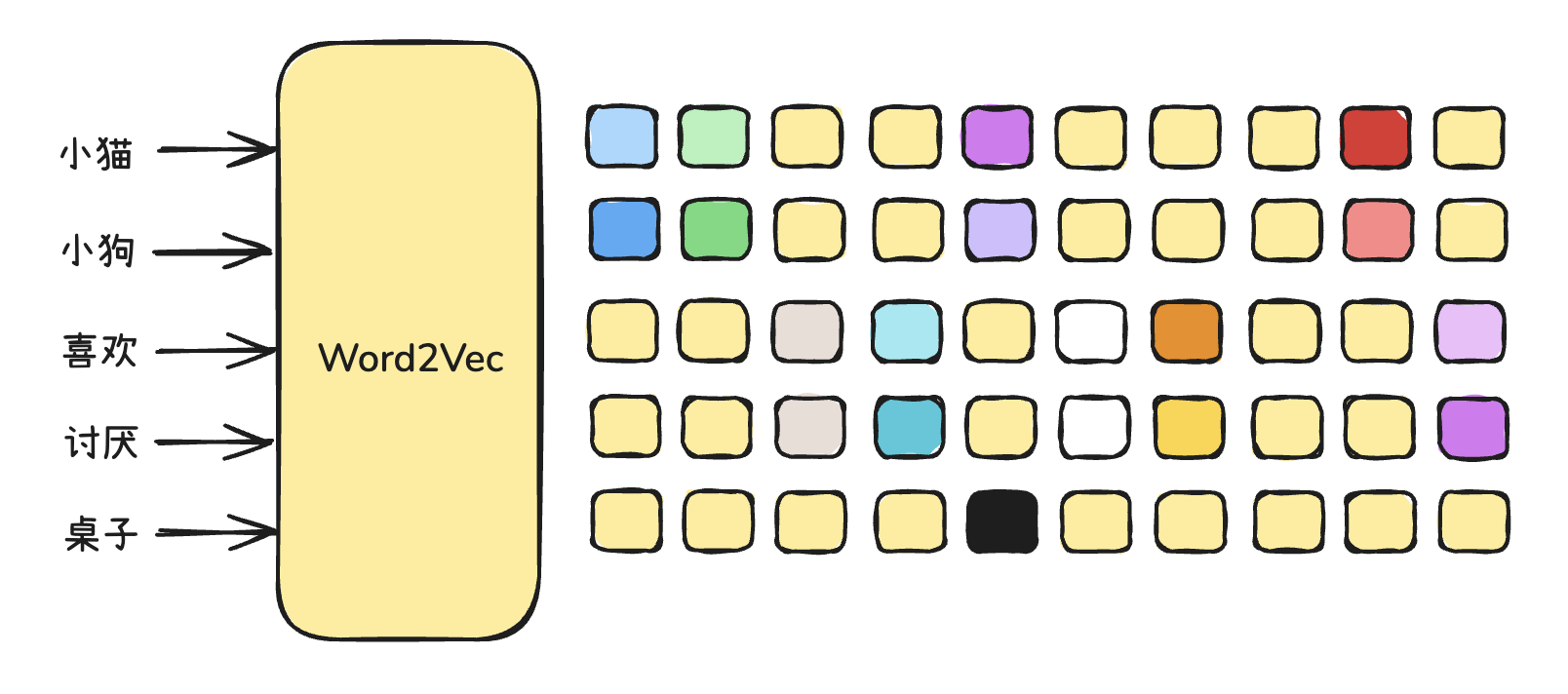
Word2Vec 有两种训练方式:
- CBOW模型
- Skip-Gram模型
1. CBOW模型
CBOW模型的核心思想是:给定一个词的上下文(前后词),预测中心词(目标词)。
我 喜欢 吃 苹果
给你两个词:我、吃
通过模型要能够预测:喜欢
2. Skip-Gram模型
Skip-Gram模型则刚好相反,核心思想是:给定中心词,预测它的上下文词。
我 喜欢 吃 苹果
给你一个词:喜欢
通过模型要能够预测出:我、吃
在训练 Word2Vec 时,可以选择使用其中一种。
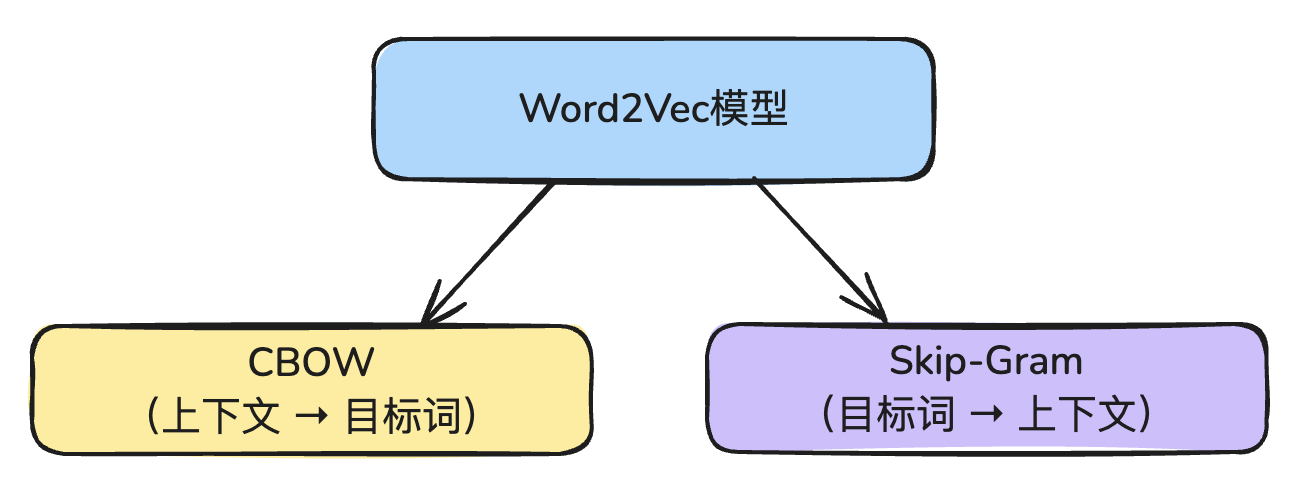
在训练 Word2Vec 时,只需在代码中指定:
sg=0表示使用 CBOW 模型sg=1表示使用 Skip-Gram 模型
大模型幻觉
首先需要了解 LLM 的工作原理。最核心的其实就是根据概率来输出下一个词。
大模型幻觉:指的是大模型生成的内容看起来合理、语法也正确,但是其实是 虚构的、伪造的、不准确、胡编乱造。
问:请问牛顿的母亲发明了什么科学理论?
答:牛顿的母亲发明了地心引力理论。
大模型幻觉常见类型:
- 编造事实
- 虚构引用
- 张冠李戴
- 胡乱编造API或者代码
- 虚构历史/人物行为
之所以会出现幻觉,就是因为大模型是基于统计来学习的,不理解真假的本质。
为了解决大模型的幻觉问题,常见的有三种方式:
- 提示词工程:构建良好的提示词
- RAG:检索增强生成,给大模型临时外挂知识库
- 大模型微调:针对某个领域去调整大模型。
-EOF-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号