[GenAI] Intro LLM发展史
LLM,Large Language Model,大语言模型。
🤔思考: LLM 和 AI 这个词是完全等价的?或者说 AI 就是 LLM 么?
LLM 仅仅是 AI 的一个分支。
任何能够使机器模仿人类行为的技术,都可以称之为人工智能技术。
人工智能下面有很多的分支,其中一个就是机器学习。
人类不直接给出决策,而是通过一些算法,让机器从示例中学习,然后机器来做出决策。
深度学习(Deep Learning)又是机器学习下面的一个分支。受到人脑神经系统的启发。
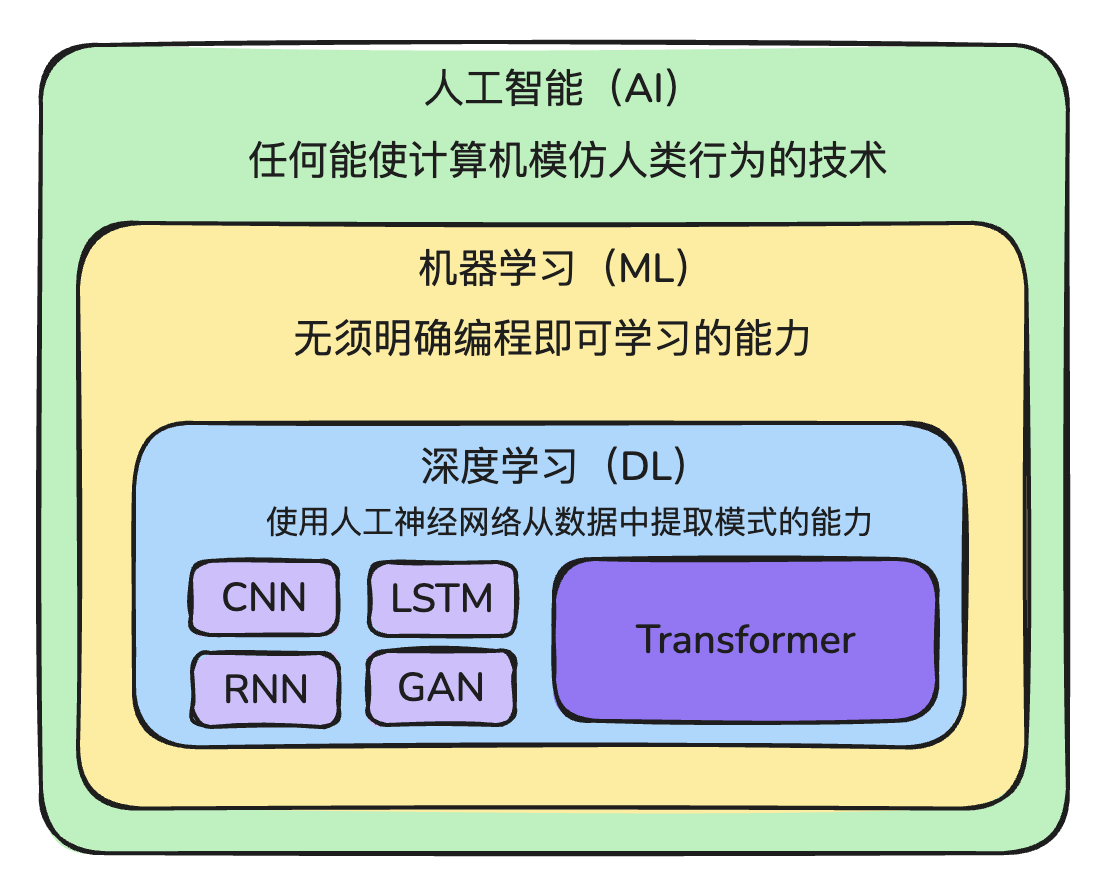
- CNN:卷积神经网络,主要处理图像
- RNN:循环神经网络,其中里面有一种解决方案,LSTM 是 RNN 的其中一种解决方案
- GAN:生成对抗网络
- Transformer:GPT系列、DeepSeek
LLM发展史
AI 技术两大核心应用方向:
- 计算机视觉:Computer Vision,CV 让计算机能够看懂图片
- 自然语言处理:Natural Language Processing,NLP,让计算读懂、理解、写出人类的语言
早期 AI 技术研究基本上聚焦于 CV,NLP 属于这几年后来居上。
关于语言
🤔思考:何为语言?信息又如何传播?
语言:声音为媒介
口头传播的缺点:信息不容易积累
原始人:结绳、刻契、图画---> 图形符号 ----> 文字
文字:承载信息

语言是信息的载体。口头话语和书面文字都是语言的重要组成部分。有了语言,就有了信息沟通的基础。
除了语言这个信息载体之外,我们需要在信息的通道中为语言 编码 和 解码。
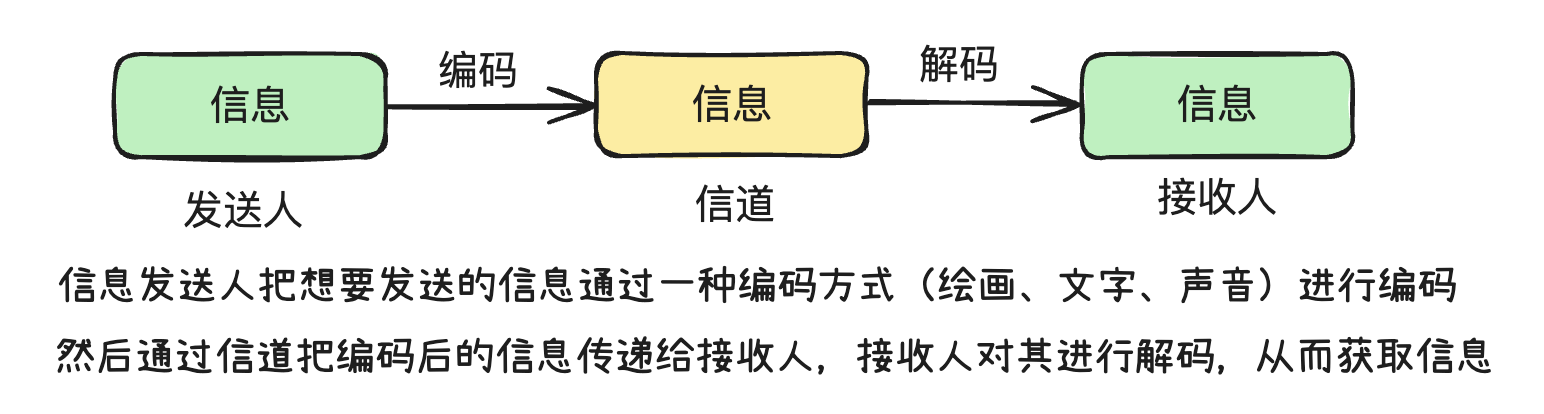
同理,计算机也是不能够直接理解人类的自然语言的,可以理解为两个不同的物种,无法直接进行交流。
- 人类:自然语言
- 计算机:0101010 二进制
早期是人类向计算机妥协,学习计算机的二进制交流方式,然后和计算机进行交流。
研究方向:如何让计算机向人类妥协,人类不再使用二进制,而是使用我们擅长的自然语言和计算机进行交流
- 汇编语言和计算机进行交流
- 高级语言:C、C++、Java、JS 和计算机进行交流
- 自然语言和计算机进行交流
所以现在所出现的 AI 编码(Agent),其实就是实现的自然语言和计算机交流。
这个就是 NLP 的核心任务。NLP 是人类通过自然语言和计算机进行交流的一个桥梁。
NLP演进史
NLP 发展粗略的分为如下 4 个阶段:
- 起源
- 基于规则
- 基于统计
- 深度学习和大数据驱动
1. 起源
阿兰・图灵在 20 世界 50 年代提出的图灵测试。(模仿游戏)
图灵测试的基本思想是,如果一个计算机程序能在自然语言对话中表现得像一个人,那么我们可以说它具有智能。
NLP 问题是 AI 理论诞生之初就亟须解决的一个问题。
2. 基于规则
人们尝试通过基于语法和语义规则的方法来解决 NLP 问题。这也是我们人类在学习一门新的语言的时候的主要思路。
一门语言的规则就非常非常的多,而且十分复杂,这还只是一门语言,如果想要覆盖世界上所有的语言,难上加难。
而且,语言是一门随时变化的艺术。
3. 基于统计
1970 年以后,以弗雷德里克・贾里尼克为首的 IBM 科学家们采用了 基于统计 的方法来解决语音识别的问题,终于把一个基于规则的问题转换成了一个数学问题,最终使 NLP 任务的准确率有了质的提升。
一句话解释什么是语言模型,那就是:
一种捕捉自然语言中词汇、短语和句子的概率分布的统计模型。
简单来说,语言模型的目的是估计给定文本序列出现的概率,从而帮助理解语言的结构和生成新的文本。
该阶段一些具有代表性的模型和方法:
| 模型 / 方法 | 简介 |
|---|---|
| Bag-of-Words(BoW) | 最早期的文本表示方法之一,将文本看作词的集合,忽略语序,仅统计词频或词是否出现。广泛用于文本分类和信息检索。 |
| N-Gram 模型 | 最具代表性的统计语言模型之一,利用前 N−1 个词预测下一个词,体现了语言的局部依赖性。 |
| Hidden Markov Model(HMM) | 一种生成式模型,广泛用于语音识别、词性标注等任务,结合状态转移概率和观测概率进行序列建模。 |
| Maximum Entropy Model(最大熵模型) | 判别式模型,可灵活建模特征对输出的影响,常用于命名实体识别、文本分类等任务。 |
| IBM 模型(1~5) | IBM 提出的统计机器翻译模型,专注于词对齐、翻译概率和句子结构建模,对早期翻译系统影响深远。 |
| BLEU 指标(虽然不是模型,但重要) | 一种用于评估机器翻译结果的指标,衡量候选翻译与参考翻译的 n-gram 重合度,是机器翻译研究的重要标准。 |
4. 深度学习和大数据驱动
统计方法被广泛运用后,NLP 技术有了质的飞跃。后面,又出现了深度学习和大数据,这两个技术逐渐取代了传统的统计方式。
这一阶段可以大致分为两个浪潮:
- 第一波(2013~2018):深度学习技术开始应用于 NLP,词向量(word embedding)等方法显著提升了模型的表示能力;
- 第二波(2018~至今):以 Transformer 为核心架构的大规模预训练模型兴起,依托海量语料数据,实现了更强的语言理解与生成能力。
该阶段一些著名的语言模型如下表所示:
| 模型 | 简介 |
|---|---|
| Word2Vec(2013) | Google 提出,通过上下文学习词向量,标志着词嵌入(embedding)时代的开始。 |
| GloVe(2014) | Stanford 提出,基于共现矩阵的全局词嵌入方法。 |
| ELMo(2018) | 使用双向 LSTM,能根据上下文动态生成词表示,是上下文词向量的开端。 |
| BERT(2018) | Google 提出,使用 Transformer 编码器,预训练-微调范式奠定现代 NLP 基础。 |
| GPT 系列(2018–至今) | OpenAI 提出,基于 Transformer 解码器,擅长自然语言生成,GPT-3、GPT-4 代表当今 LLM 顶尖水平。 |
| T5(2019) | Google 提出,统一 NLP 任务为“文本到文本”的框架。 |
| RoBERTa、XLNet、ERNIE 等 | 各大公司在 BERT 基础上优化推出的改进版本。 |
| ChatGPT(2022)、GPT-4(2023) | 标志着 LLM 进入应用时代,表现出对话、编程、写作等通用能力。 |
整个 NLP 模型发展阶段与代表模型如下:
| 阶段 | 时间 | 方法 / 模型 | 类型 | 主要用途 | 是否考虑词序 / 语义 |
|---|---|---|---|---|---|
| 规则阶段 | 1950s–1970s | 语法规则、人工模板 | 人工构建规则系统 | 机器翻译、问答系统 | ✅ 语法结构,❌语义 |
| 统计阶段 | 1970s–2010s | Bag-of-Words (BoW) | 特征表示方法 | 文本分类、情感分析 | ❌ |
| TF-IDF | 加权特征表示 | 文本检索、关键词提取 | ❌ | ||
| N-Gram | 统计语言模型 | 语言建模、机器翻译 | ✅ 局部上下文,❌长依赖 | ||
| HMM | 概率生成模型 | 词性标注、语音识别 | ✅ | ||
| IBM 模型(1~5) | 对齐翻译模型 | 统计机器翻译 | ✅ 局部 | ||
| 深度学习阶段 | 2013–2018 | Word2Vec | 分布式词向量 | 构建语义空间、分类器输入 | ❌(静态嵌入) |
| GloVe | 基于矩阵的词向量 | 同上 | ❌ | ||
| ELMo | 上下文词向量(LSTM) | 命名实体识别、问答等 | ✅ 局部语境 | ||
| 大语言模型阶段 | 2018–至今 | BERT | 编码器(Transformer) | 预训练+微调,适用于多数 NLP 任务 | ✅ 深层语义 |
| GPT 系列(GPT-2/3/4) | 解码器(Transformer) | 文本生成、对话系统 | ✅ 强上下文与推理能力 | ||
| T5 | 编码器-解码器结构 | 多任务文本生成 | ✅ | ||
| ChatGPT | 应用层 LLM | 对话、创作、问答 | ✅ 多轮对话上下文 |
语言模型
1. N-Gram模型
N-Gram模型诞生于 1950s–1960s,最早由香农(Claude Shannon)在信息论中提出,用于语言的概率建模,香农在 1951 年的论文中提出,使用 1-gram、2-gram 等方法估计英文文本的概率。前面的 N 是一个数字,表示你每次要看几个词,例如:
- 1-Gram(Unigram):只看一个词。
- 2-Gram(Bigram):看前一个词。
- 3-Gram(Trigram):看前两个词。
- 以此类推…
该模型基于马尔可夫假设,什么是马尔可夫假设呢?
一个词的出现概率,只依赖于它前面的 N−1 个词,而不是整个句子历史。
你妈妈在厨房:帮我从冰箱里面拿....
你的脑子会自然补出“鸡蛋/牛奶/苹果”
根据“拿”这个词来预测的下一个词
工作原理
以 Bigram 模型(2-gram)为例
假设我们有这样一个“语料库”,我们用这些数据来训练模型:
“我 爱 吃 苹果”
“我 爱 吃 香蕉”
“我 喜欢 吃 苹果”
Bigram 模型会根据一个词统计下一个词出现的概率,这里我们可以数一数所有词对:
| 前一个词 | 下一个词 | 次数 |
|---|---|---|
| 我 | 爱 | 2 次 |
| 我 | 喜欢 | 1 次 |
| 爱 | 吃 | 2 次 |
| 喜欢 | 吃 | 1 次 |
| 吃 | 苹果 | 2 次 |
| 吃 | 香蕉 | 1 次 |
比如:
- 我后面出现“爱”的概率是 2/3,出现“喜欢”的概率是 1/3。
- 吃后面出现“苹果”的概率是 2/3,出现“香蕉”的概率是 1/3。
所以:
如果你看到“我 爱 吃”,那下一个词大概率是“苹果”!
N-Gram模型缺陷
N-Gram模型是最早的语言模型原型,是整个统计语言建模的起点。不过 N-Gram 模型虽然是语言建模的奠基石之一,但它也存在不少关键缺陷,这些缺陷正是后来神经网络语言模型诞生的动因。
主要缺陷如下表:
| 缺陷点 | 说明 |
|---|---|
| 1. 语境短视(上下文长度有限) | N-Gram 只看前 N−1 个词,无法理解长距离依赖。例如在句子“我昨天见到一个朋友,他说他喜欢编程”中,“他”和“喜欢编程”之间相隔很远,Bigram / Trigram 很难建模这种关系。 |
| 2. 数据稀疏严重(Data Sparsity) | 语言中有大量的词组合从未在训练语料中出现过,即使它们是合理的,也会被模型认为概率为 0。这个问题在 N 值越大时越严重。 |
| 3. 无法泛化 | N-Gram 只能“记住”见过的词组合,对没见过的组合无能为力。比如语料中没有 “我 喜欢 吃 西瓜”,模型无法判断它是否合理。 |
| 4. 不具备语义理解能力 | N-Gram 模型只基于词频,不理解词义。它无法判断 “喜欢” 和 “热爱” 的相似性,也不能区分“我打了他”和“他打了我”之间的语义差异。 |
| 5. 参数维度膨胀 | 当 N 增大时,可能出现的 N-Gram 组合数呈指数级增长,需要的内存和存储量也随之暴增,训练成本高。 |
| 6. 不适合生成自然语言 | 基于固定窗口预测的方式,容易生成重复、呆板、逻辑不通的句子,不适合生成自然、连贯的文本(尤其是对话或文章生成)。 |
| 7. 不考虑词性、句法结构 | 它无法理解词的角色(如名词、动词),也不会分析句子的语法结构,这在许多高级 NLP 任务中是致命的。 |
2. 词袋模型
词袋模型(Bag-of-Words)是一种简单的文本表示方法,也是自然语言处理的一个经典模型。它将文本中的词看作一个个独立的个体,不考虑它们在句子中的顺序,只关心每个词出现的频次。
工作原理
词袋模型的核心思想是把:文本表示成一个“词频向量”,不看词的顺序、句法结构,只关注词是否出现和出现的次数。
举个例子:假设有三句话作为语料库(Corpus)
句子1:我喜欢吃苹果
句子2:我不喜欢吃香蕉
句子3:她喜欢吃葡萄
第 1 步分词:
["我", "喜欢", "吃", "苹果"]
["我", "不", "喜欢", "吃", "香蕉"]
["她", "喜欢", "吃", "葡萄"]
第 2 步构建词表:
词表 = ["我", "喜欢", "吃", "苹果", "不", "香蕉", "她", "葡萄"]
这个词表确定了向量的“维度”,共 8 个词,所以向量长度就是 8。
第 3 步构建词频向量
| 词汇位置 | 我 | 喜欢 | 吃 | 苹果 | 不 | 香蕉 | 她 | 葡萄 |
|---|---|---|---|---|---|---|---|---|
| 句子1 向量 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 句子2 向量 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 |
| 句子3 向量 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
这个表就是 BoW 特征向量化后的结果,每句话变成一个“向量”,可以用于计算机处理。
[1, 1, 1, 1, 0, 0, 0, 0]
[1, 1, 1, 0, 1, 1, 0, 0]
[1, 1, 1, 0, 0, 0, 0, 0]
BoW 相对于 N-Gram 的改进:
| 问题 | N-Gram 的缺陷 | BoW 的解决 |
|---|---|---|
| 维度膨胀严重 | N-Gram 组合数非常多(特别是 Trigram 以上) | BoW 只统计词,不考虑组合,向量维度更小 |
| 数据稀疏严重 | N-Gram 中很多词组组合没出现 | BoW 用词频统计,不会因未出现的组合而归 0,更稳定 |
| 上下文建模复杂 | N-Gram 有上下文,但建模代价大 | BoW 完全不建上下文,适合计算效率优先的场景 |
| 语言通用性差 | N-Gram 通常用于语言建模、生成 | BoW 更适合分类、聚类、检索等任务,不是用来“生成文本”的模型 |
词袋模型更擅长的任务是:
-
文本分类
-
文本相似度分析
-
信息检索 / 文档排序
词袋模型的缺陷
虽然 BoW 在早期 NLP 中广泛使用,但它也有明显不足:
| BoW 局限 | 表现在哪? |
|---|---|
| 只看词有没有,不看上下文 | “下次”、“还会来”、“满意”这些词在训练集中可能根本没出现,所以它无法学习 |
| 词序被忽略 | “我打了他”和“他打了我”在 BoW 中是一样的,无法影响分类 |
| 不能理解新词或组合 | “真的很满意”这个表达在训练集中可能完全没出现过 |
| 没语义泛化能力 | 模型不知道“满意”≈“不错”、“愉快”等词汇的同义性,“满意”和“不错”被看作两个完全不同的词 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号