[AI] 构建本地RAG应用
准备工作
本地模型
模型分为两种:
1.专有模型:闭源模型
- OpenAI GPT4
- Cluade
优点:强大的商业支持
缺点:付费、数据的隐私
2.开源模型(学习阶段)
- 微软:Phi
- Meta:Llama
- deepseek
不需要联网
安装Ollama
- Ollama:模型平台,可以安装各种模型:Qwen、Deepseek、Llama...
- Llama:模型(最新 Llama)
ollama run <模型的名字>
本身是运行XX模型的意思,如果没有该模型,会先去下载。
启动模型后,ollama 会启动一个服务,坚听 11434 端口。
curl http://localhost:11434/api/tags # 查看本地模型
本地的一个聊天机器人
回头RAG应用基于这个聊天机器人。
RAG基本的理论
大语言模型的缺陷:回答问题基于训练过的数据。
RAG:Retrieval-Augmented Generation,检索增强生成。
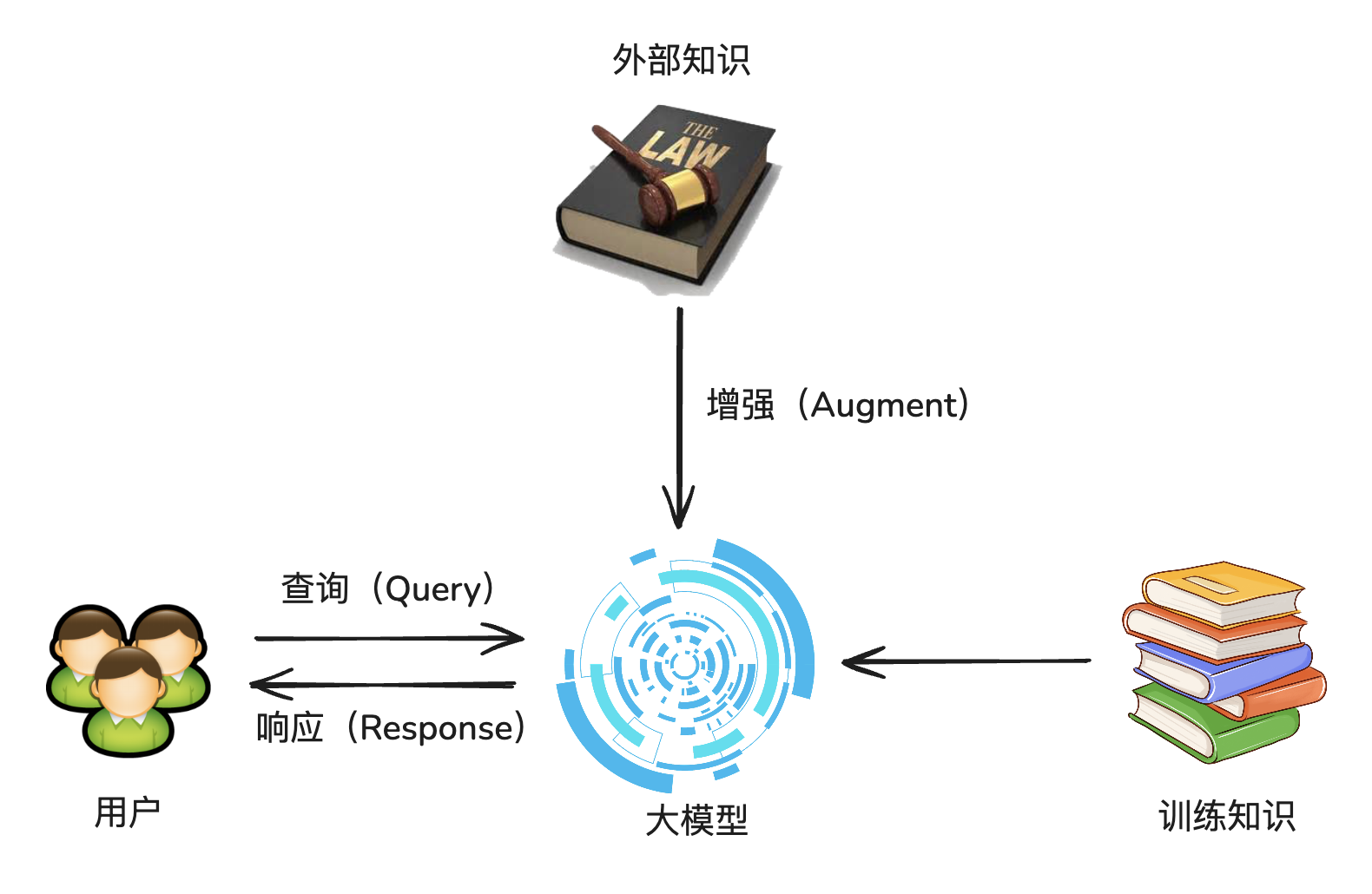
RAG 就是临时给大模型外挂一个知识库
整个 RAG 的架构如下:
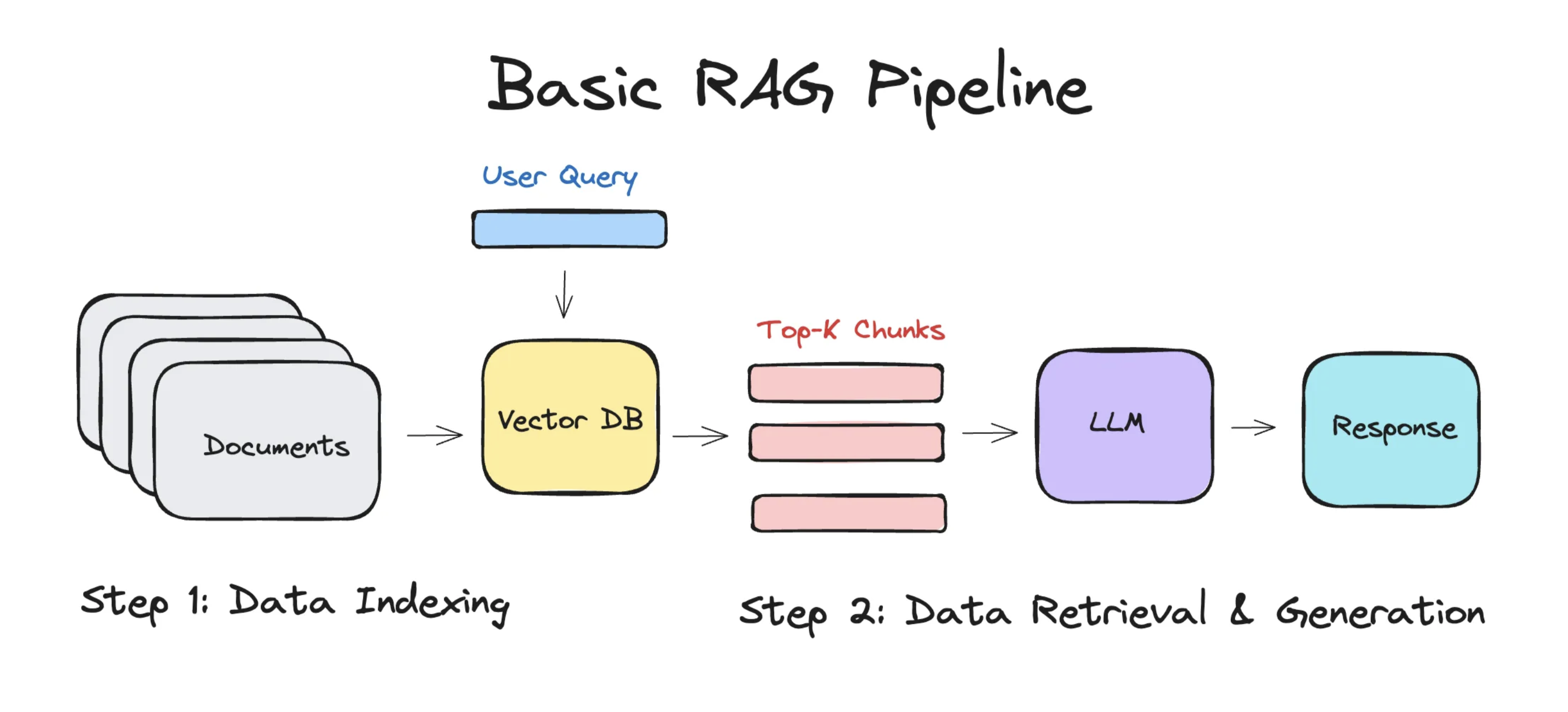
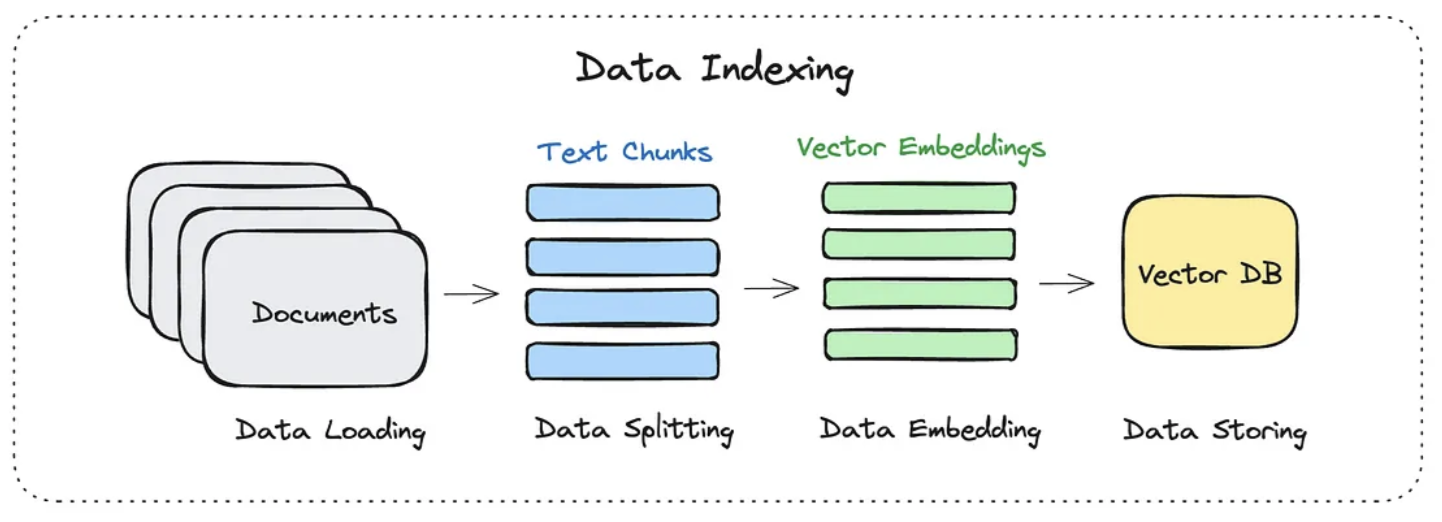
1. 数据索引
Data Indexing
数据索引主要是做下面几件事情:
- 加载文档(你要外挂的知识库)
- 切分成一个一个 chunks(块)
- 转换为高维度向量
- 将结果存储到向量数据库
这是一只小猫。
[0.71, 0.32, -0.56, ....]
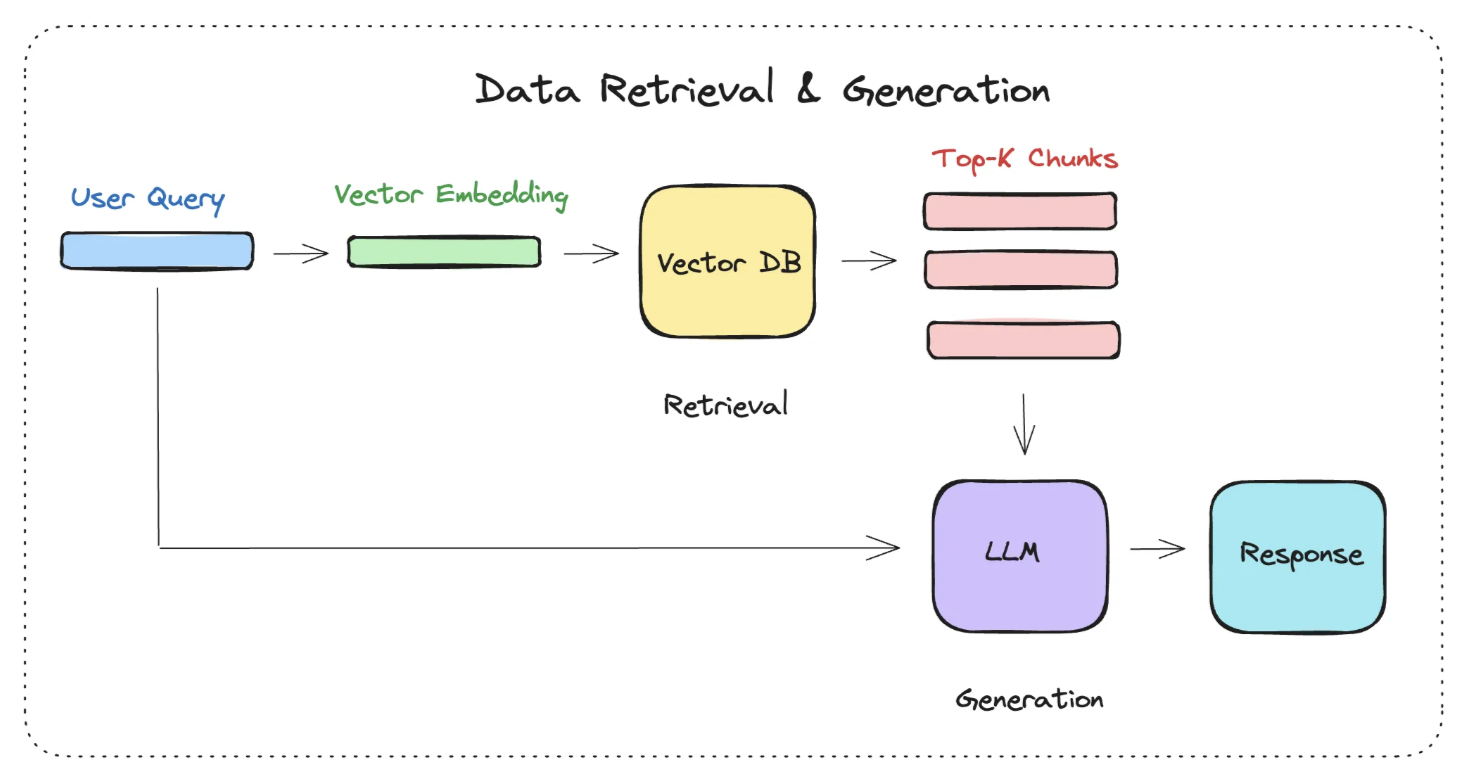
2. 数据查询
Query
介绍一下香蕉手机。
首先会把这个 Query 也转换成向量的形式。(方便计算)
拿到这个 Query Embeding 之后,去向量数据库里面找和 Query Embeding 相关的内容,取出相关内容的向量(Vector Embedding),然后将:
1. Vector Embedding
2. 用户的问题
一起交给大模型进行处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号