[Machine Learning] Normal Equation for linear regression
We have used gradient descent where in order to minimize the cost function J(theta), we would take this iterative algorithm that takes many steps, multiple iterations of gradient descent to converge to the global minimunm.
In contrast, the normal equation would gibe us a method to solve for theta analytically, so that rather than needing to run this iterative algorithm, we cna instead just solve for the optimal value for theta all at one go, so that in basically one step you get to the optimal value there.
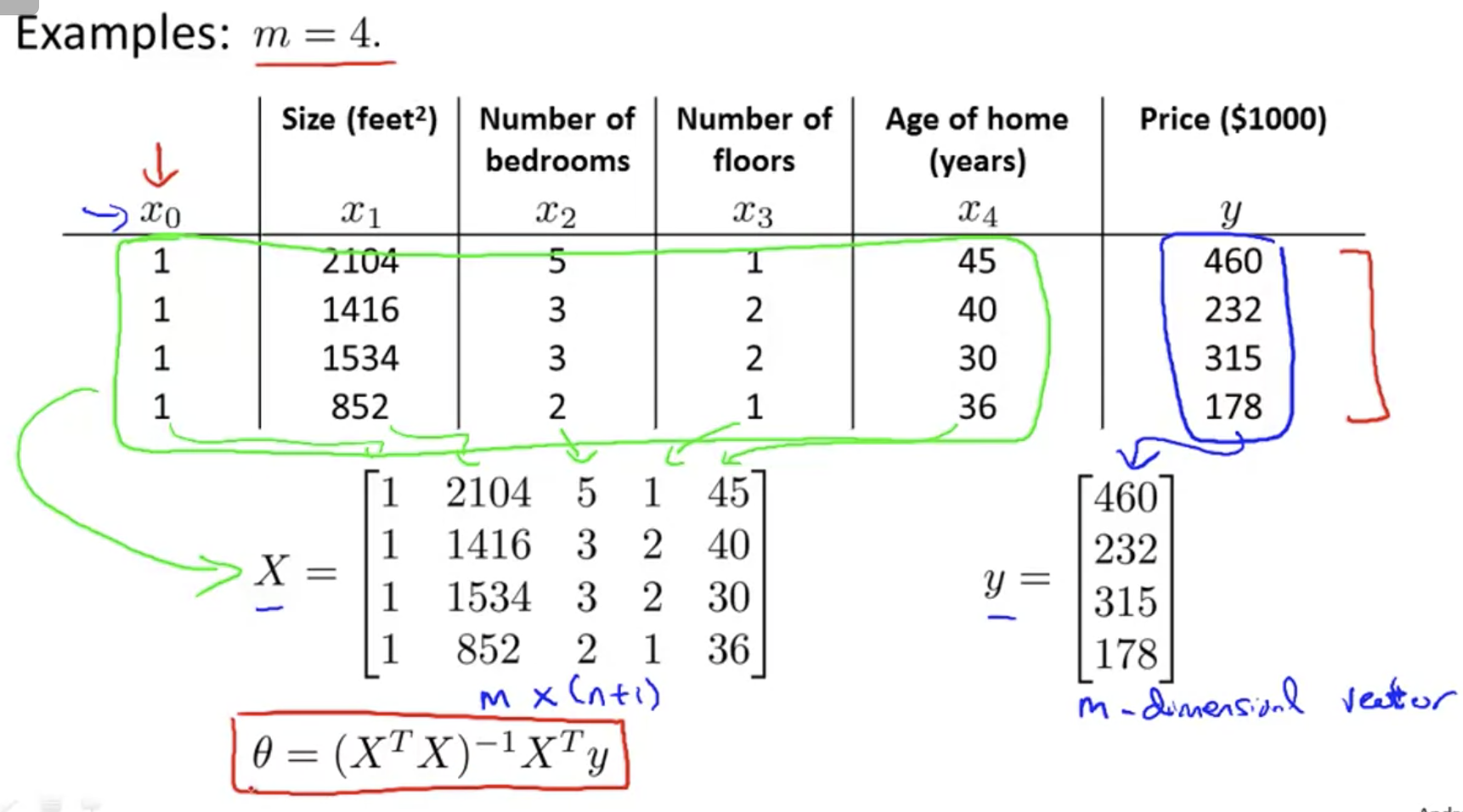
There is no need to do feature scaling with the normal equation.
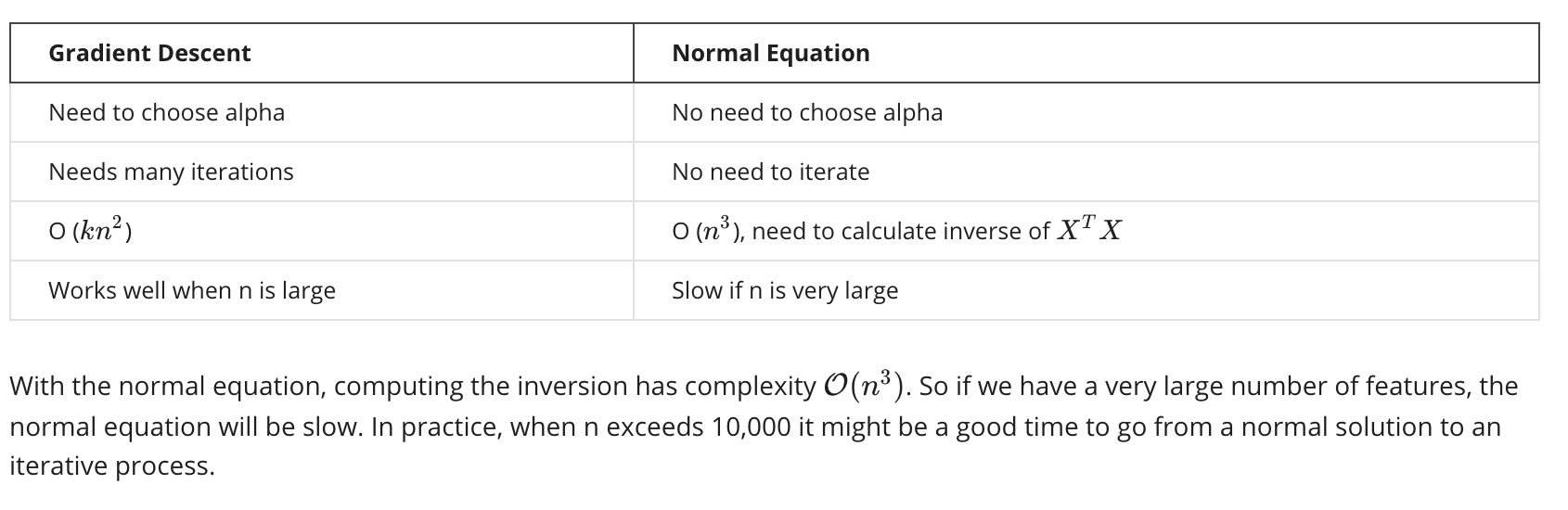
The following is a comparison of gradient descent and the normal equation:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号