一 python 写循环
在Python中,有多种方式可以实现循环。最常用的循环结构包括for循环和while循环。下面是一些基本的例子:
1. 使用for循环
for循环通常用于遍历一个序列(如列表、元组、字符串或范围)中的元素。
遍历列表
遍历范围
range()函数可以生成一个数字序列,然后你可以通过for循环来遍历这个序列。
2. 使用while循环
while循环会在给定的条件为真时重复执行代码块。
3. 使用for循环遍历字典的键、值或键值对
遍历字典的键
遍历字典的值
遍历字典的键值对
4. 使用列表推导式和生成器表达式进行循环(虽然不是传统意义上的循环,但常用于创建列表或生成器)
列表推导式示例
生成器表达式示例
5. 使用enumerate进行索引和值的迭代(常用于同时获取索引和值)
这些是Python中实现循环的几种基本方法。选择哪一种取决于你的具体需求和偏好。
在Python中,读取数组(或者说列表)的长度非常简单,你可以使用内置的len()函数。这个函数返回对象(比如列表)中元素的数量。
python写 if
if x > 5:
没有括号
在Python中,读取数组(在Python中通常被称为列表)中位置为i的值的操作非常直接。你可以使用下标访问(indexing)来实现这一点。下面是一些基本的方法:
使用下标访问
假设你有一个名为array的列表,你想读取位置为i的元素,你可以这样做:
2. 使用逻辑运算符
Python中的逻辑运算符包括and、or和not,可以用来组合多个条件。
3. 使用in和not in判断成员资格
4. 使用is和is not判断身份
is用于判断两个变量是否指向同一个对象。
在Python中,实现自减(即变量自身减1的操作)有多种方式,取决于你具体想要达到的效果。以下是几种常见的实现方式:
1. 使用 -= 操作符
-= 操作符可以用来实现自减操作。例如,如果你有一个变量x,想要将其值减1,可以这样做:
在Python中,判断重复通常指的是判断一组元素中是否有重复项。有多种方法可以实现这一目标,其中使用哈希表(在Python中通常指的是字典)是最直接和高效的方式之一。下面是一些使用哈希(字典)来判断重复的方法:
方法1:使用集合
由于集合(set)本身不允许重复元素,你可以将元素添加到集合中,如果添加时遇到KeyError,则说明元素已经存在。
1.3 基础操作
| 操作类型 | 方法/运算符 | 示例代码 | 说明 |
|---|---|---|---|
| 添加单个元素 | add() | fruits.add("grape") | 添加单个元素,元素存在则不处理 |
| 添加多个元素 | update() | fruits.update(["a", "b"]) | 从可迭代对象(列表/元组/字符串等)添加多个元素 |
| 删除元素 | remove() | fruits.remove("apple") | 删除指定元素,不存在则报错 KeyError,且只删除首位元素,删除后后面的元素会向前补位, |
| 安全删除 | discard() | fruits.discard("mango") | 删除指定元素,不存在则静默处理 |
| 随机删除 | pop() | removed = fruits.pop() | 随机删除并返回元素,集合为空时报错KeyError |
| 清空集合 | clear() | fruits.clear() | 移除所有元素,集合变为空。 |
| 成员检测 | in 运算符 | "banana" in fruits → True | 检查元素是否存在,返回布尔值 |
list添加元素
| append | list.qppend(0) | 在列表末尾加一个0 |
在Python中,对列表(list)进行排序是非常直观的,可以通过多种方式实现。这里将介绍几种常用的排序方法:
1. 使用sort()方法
sort()方法会直接在原列表上进行排序,不返回新的列表。
my_list = [3, 1, 4, 1, 5, 9, 2]
my_list.sort() # 默认升序排序
print(my_list) # 输出: [1, 1, 2, 3, 4, 5, 9]
# 降序排序
my_list.sort(reverse=True)
在Python中,如果你想定义一个元素为list的list(或者说一个列表的列表),你可以使用嵌套列表(nested lists)的概念。这意味着你将一个列表作为另一个列表的元素。这里有几种不同的方式来实现这一目标。
# 定义一个空列表,然后动态添加元素为list的list
nested_list = []
nested_list.append([1, 2, 3])
nested_list.append([4, 5, 6])
nested_list.append([7, 8, 9])
在Python中,哈希表可以通过几种方式实现,最常见的是使用字典(dict)。字典在Python中是实现哈希表的一种非常直观和高效的方式。下面是如何使用字典作为哈希表的一些基本操作:
1. 创建字典
创建一个空的字典很简单,只需使用大括号{}即可:
my_dict = {} 或者使用dict()构造函数:
my_dict = dict() 2. 添加键值对
向字典中添加键值对非常直接:
my_dict['key'] = 'value' 3. 访问字典中的值
可以通过键来访问字典中的值:
value = my_dict['key']
4. 检查键是否存在
在尝试访问一个不存在的键之前,可以先检查它是否存在:
if 'key' in my_dict: print("Key exists") else: print("Key does not exist") 5. 修改值
修改字典中已存在的键的值:
my_dict['key'] = 'new_value'在Python中,遍历一个字典有几种常见的方式:
方法一:遍历字典的键(keys()方法)
my_dict = {"a": 1, "b": 2, "c": 3} for key in my_dict.keys(): print(key)在Python中,如果你想将一个字符串中的字符按照字母顺序进行排序,可以使用多种方法。下面是一些常见的方法:
方法1:使用sorted()函数
sorted()函数可以返回一个列表,其中包含所有字符,这些字符根据字母顺序排序。你可以通过将结果转换回字符串来得到最终的排序字符串。
original_string = "python" sorted_string = ''.join(sorted(original_string))链表1. 定义节点类
首先,我们定义一个节点类(Node),每个节点包含数据和指向下一个节点的链接。
class Node:
def __init__(self, data):
self.data = data
self.next = None
在Python中,set和dict的核心区别在于存储结构和用途:dict存储键值对(key-value),用于高效映射和查找;set仅存储唯一元素(相当于dict的键集合),用于去重和成员测试。两者均基于哈希表实现,但dict通过键访问值,而set不存储值且元素不可重复。
- 两者均基于哈希表,查找、插入和删除操作时间复杂度为O(1),效率高。
- dict因存储值,内存占用略高于set。
在Python中,None 关键字用于表示空值或缺失的变量。它是Python的一个内置常量,等同于其他编程语言中的 null 或 NULL。
在Python中,True和False是布尔类型的两个取值,用于表示逻辑上的“真”和“假”状态。 12
表示方法
- True:表示条件成立、事实存在或肯定状态
- False:表示条件不成立、事实不存在或否定状态
在Python中,表示10的几次方有多种方法。以下是几种常见的方法:
1. 使用**运算符
**运算符用于计算幂,即一个数的指数次幂。例如,计算10的5次方:
result = 10 ** 5
print(result) # 输出: 100000
在Python中,取一个数值的个位数有多种方法,取决于你的具体需求。下面是一些常见的方法:
方法1:使用模运算符(%)
你可以使用模运算符(%)来获取一个数的个位数。模运算符返回两个数相除的余数。
num = 123
last_digit = num % 10
print(last_digit) # 输出: 3
在Python中,定义全局方法通常意味着将这些方法放在模块级别,即在任何函数或类之外直接定义。全局方法可以被模块内的其他函数或类直接调用,也可以在模块外部被导入后调用。
定义全局方法
直接在模块级别定义
你可以直接在Python文件的顶层级别定义函数,这些函数就可以作为全局方法使用。
# example.py
def global_method():
print("这是一个全局方法")
def another_function():
global_method() # 在这个函数内部调用全局方法
在Python中,定义一个新对象通常涉及到创建类的实例。Python是一种面向对象的编程语言,这意味着你可以通过定义类(class)来创建对象。下面是如何定义一个新对象的基本步骤:
1. 定义一个类
首先,你需要定义一个类。类是对象的蓝图,它定义了对象的属性(variables)和方法(functions)。
class MyClass:
def __init__(self, attribute):
self.attribute = attribute # 初始化属性
def method(self):
print("这是一个方法")
2. 创建类的实例
然后,你可以通过调用类的构造函数(__init__方法)来创建类的实例,也就是创建一个新对象。
# 创建MyClass的一个实例
my_object = MyClass("这是一个属性")

在Python中,异或(XOR)操作符是 ^。异或操作通常用于比较两个位值是否不同,如果不同则结果为1,如果相同则结果为0。
list的初始赋值和长度定义可以用
s_count = [0] * 26
两个list是否相等可以用==来判断
- 功能定义:将单个字符转换为对应Unicode整数(范围0-1114111),支持ASCII(如'A'→65)、中文(如'智'→26230)及符号处理。
在Python中,你可以使用内置的max()函数来找出列表(List)中的最大值。这个函数可以直接应用于列表,非常方便。下面是一些例子:
示例 1:使用max()函数
numbers = [1, 3, 5, 7, 9]
max_value = max(numbers)
print(max_value) # 输出: 9
1.二维数组按第一列排序
arr = [[5, 2, 6], [1, 4, 3], [9, 8, 7]]
sorted_arr = sorted(arr, key=lambda x: x[0])
print(sorted_arr)
2.-1的含义:在Python中,-1用作索引时,它指的是列表的最后一个元素。
array_2d[-1]:这访问的是最外层列表的最后一个元素,即[7, 8, 9]。array_2d[-1][1]:这进一步访问上述子列表中的第二个元素,即8。
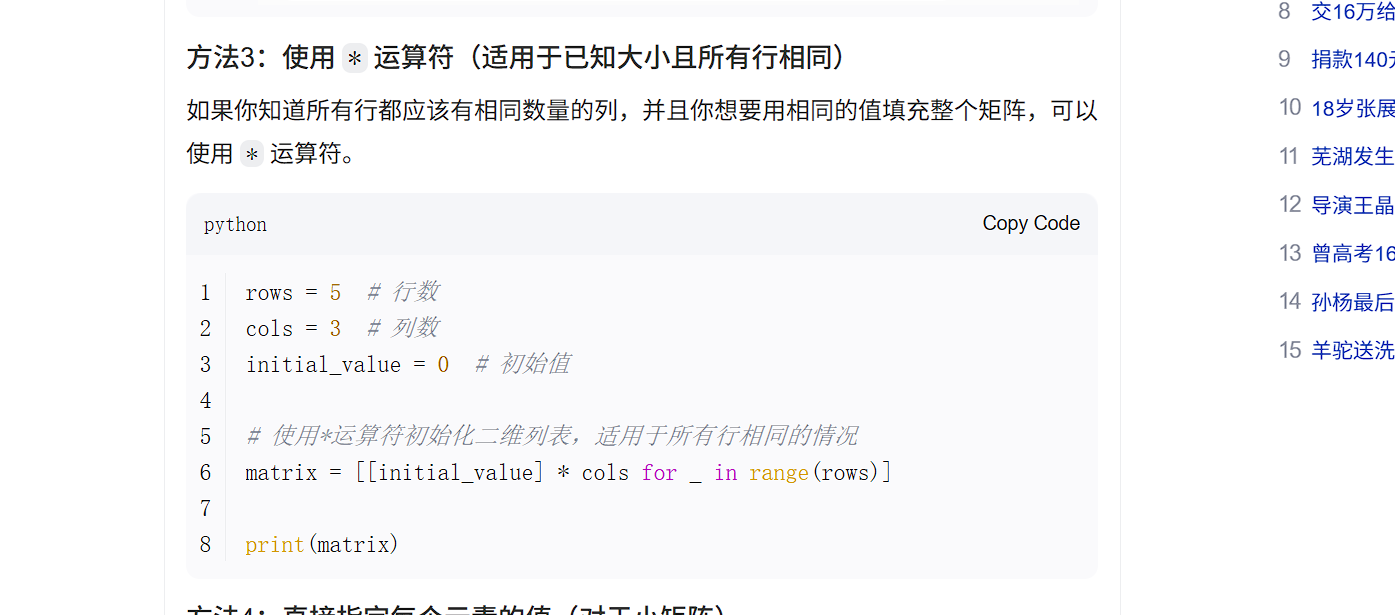
初始化一个二维数组
Python中 list可以做栈用,也有先进后出的特性
- 入栈:使用列表的
append()方法。 - 出栈:使用列表的
pop()方法。 - 查看栈顶:通过索引
[-1]获取最后一个元素。 - 查看list长度也可以用len()
Python中在对象里初始化和定义方法
class MinStack(object): def __init__(self): self.stack = [] self.min_stack = [] def push(self, val): """ :type val: int :rtype: None """ self.stack.append(val) if len(self.min_stack) != 0: self.min_stack.append(min(val, self.min_stack[-1])) else: self.min_stack.append(val) def pop(self): """ :rtype: None """ self.stack.pop() self.min_stack.pop() def top(self): """ :rtype: int """ return self.stack[-1] def getMin(self): """ :rtype: int """ return self.min_stack[-1]
List判断是否为空可以直接用 list 或者not list来判断
python中要写函数并使用如下所示,比如递归中要经常用到
1 # Definition for a binary tree node. 2 # class TreeNode(object): 3 # def __init__(self, val=0, left=None, right=None): 4 # self.val = val 5 # self.left = left 6 # self.right = right 7 class Solution(object): 8 def inorderTraversal(self, root): 9 """ 10 :type root: Optional[TreeNode] 11 :rtype: List[int] 12 """ 13 res = [] 14 def dfs(root): 15 if not root: 16 return 17 dfs(root.left) 18 res.append(root.val) 19 dfs(root.right) 20 dfs(root) 21 return res 22
深度优先搜索(DFS)
DFS的原理是沿着一条分支尽可能深入遍历,遇到死胡同则回溯,继续探索其他分支。它通常使用栈(或递归)实现,类似于树的先序遍历。DFS的优势是内存占用相对较少,适合寻找所有可能解或路径问题(如迷宫所有路径、拓扑排序)。缺点是可能陷入深层无用分支,无法保证找到最短路径。
广度优先搜索(BFS)
BFS的原理是按层次逐层遍历,先访问离起点近的节点4。它使用队列辅助搜索,从起点出发,先处理完当前层的所有节点再进入下一层。BFS的优势是能找到无权图中的最短路径,适合层级分析(如社交网络关系、最短路径问题)。缺点是内存消耗较大,需要保存大量节点。
核心区别
- 遍历顺序:DFS“一挖到底”,BFS“逐层扩展”。
- 数据结构:DFS用栈/递归,BFS必须用队列。
- 适用场景:DFS适合解空间探索,BFS适合最短路径和层级关系。
