
| 博客班级 | <2018级计算机和综合实验班> |
|---|---|
| 作业要求 | <作业要求> |
| 作业目标 | <采集腾讯视频里电视剧《在一起》的全部评论信息,将采集到的评论信息做成词云图> |
| 作业源代码 | <Github> |
| 学号 | <211806111> |
| 过程 | 花费时间 |
|---|---|
| 分析数据 | 很长 |
| 代码实现 | 很长 |
| 数据可视化 | 30 min |
| 写博客 | 很长 |
一、分析数据:
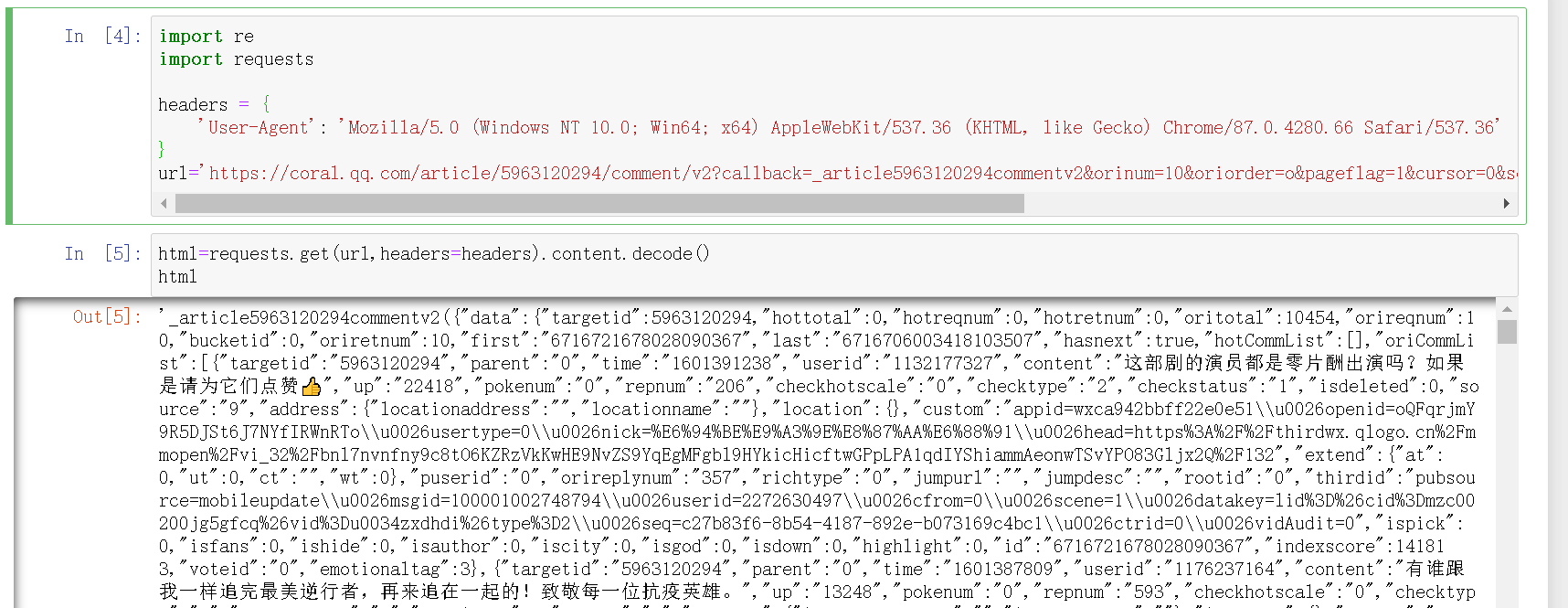
腾讯视频点开《在一起》,再点开影评,一切是那么轻松,因为在学数据挖掘与预处理时习惯用 selenium 了(除了上课时老师规定不能用 selenium 时我都在用 selenium ),一上来就直接那一套了,但是这次却碰上硬茬了,网页能自动打开,能滑倒最底部,但是就是不能点击“查看更多评论”, 这让我很恼火(但是此时的我还是没有意识到这个网站不能获取到源代码),我又去试了别的网站看看是不是我哪里写错了,试了一圈,好像都没问题,但是回到这个网站,代码报错依然是“没有这个元素”(这期间花了我很长时间,但是没有去截图),这时我就去点了一下“检查网页源代码”,这才发现源代码里面没有网友评论得部分,这才停下了用selenium 获取源代码的尝试,就去找评论的源代码是藏哪了,几经探索才发现评论的源代码藏在了这里面
![]()
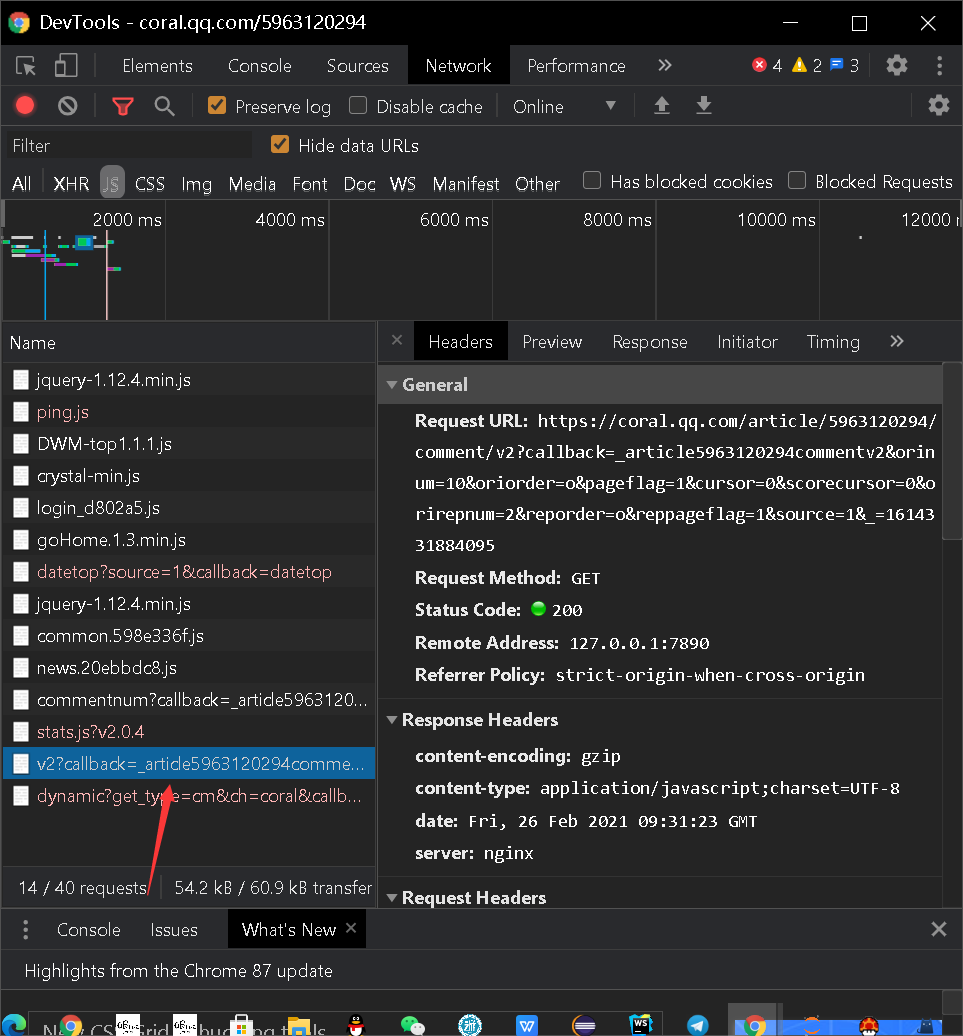
还发现评论的源代码网站是变化的,网站的cursor值,和_值是会变化的,_
值是递增,逐渐加一的
![]()
![]()
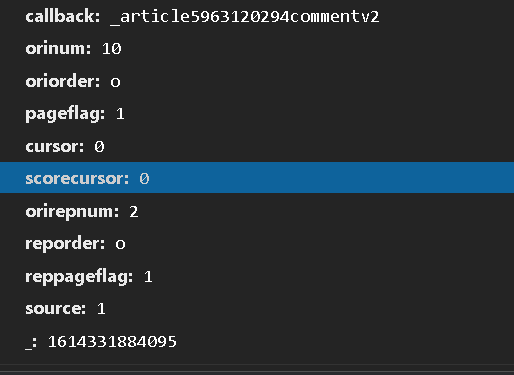
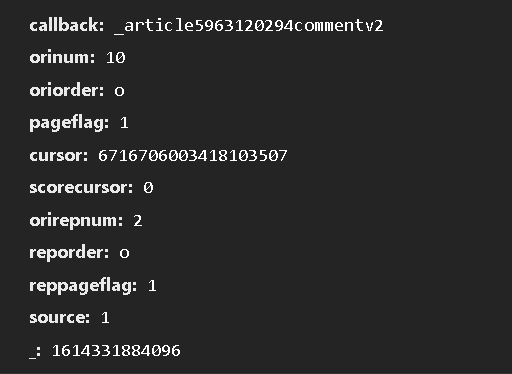
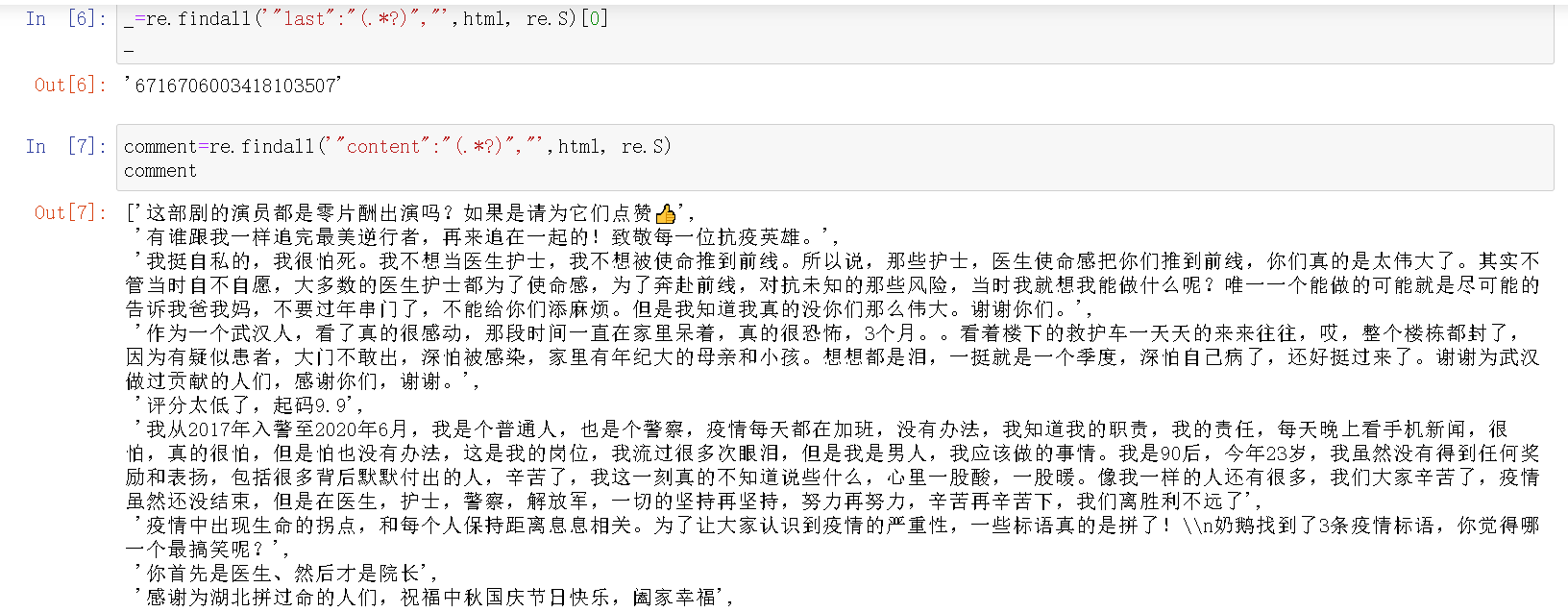
cursor值是藏在上一个网站的“last"中的,
![]()
![]()
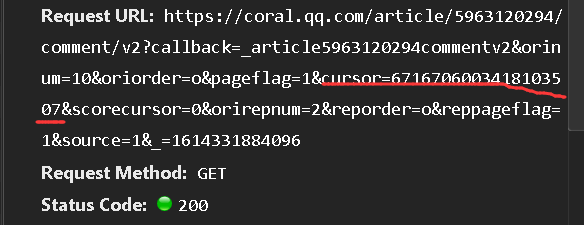
在写循环以前,都喜欢先做一次没有循环的,看看效果,然后再写循环

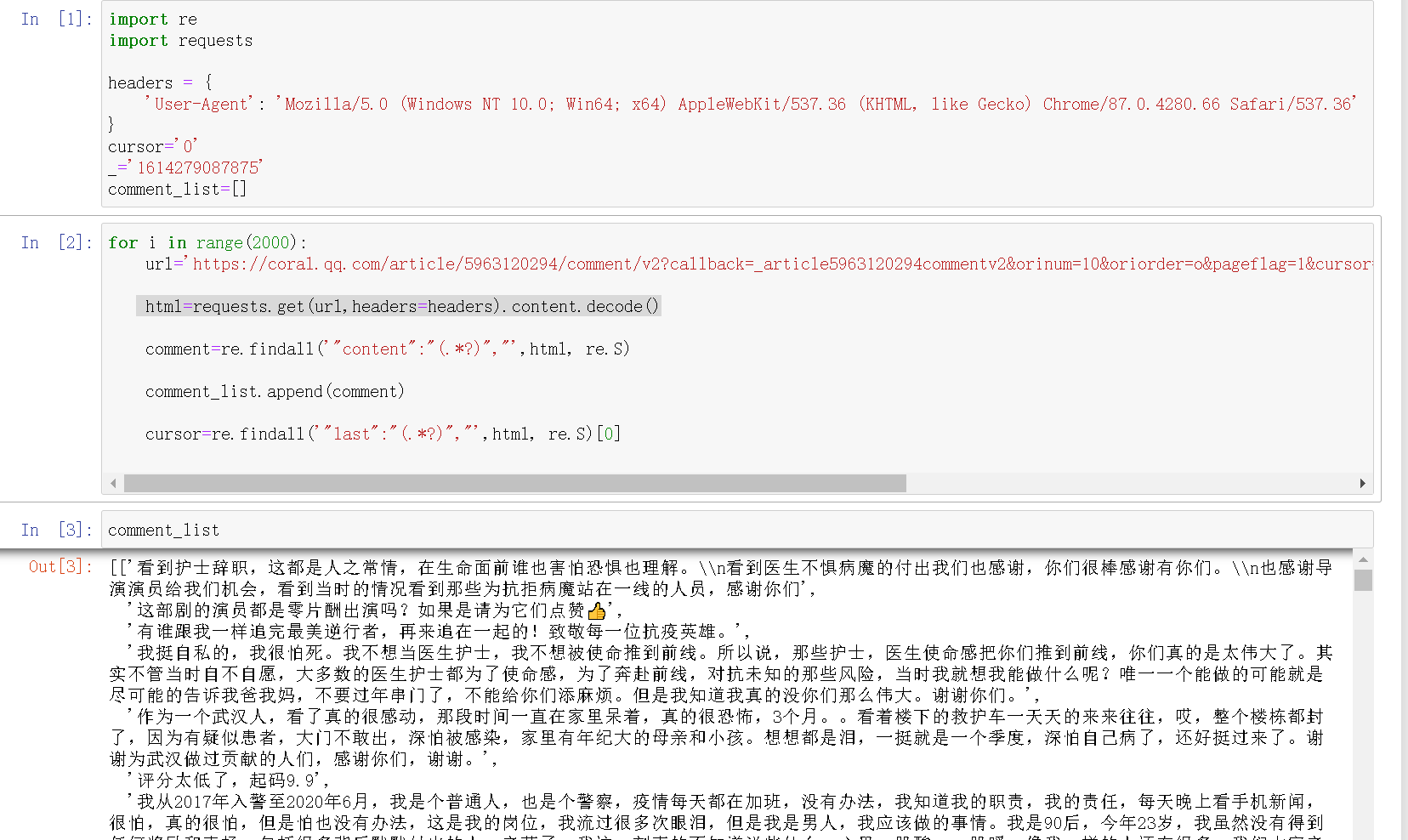
二、数据处理
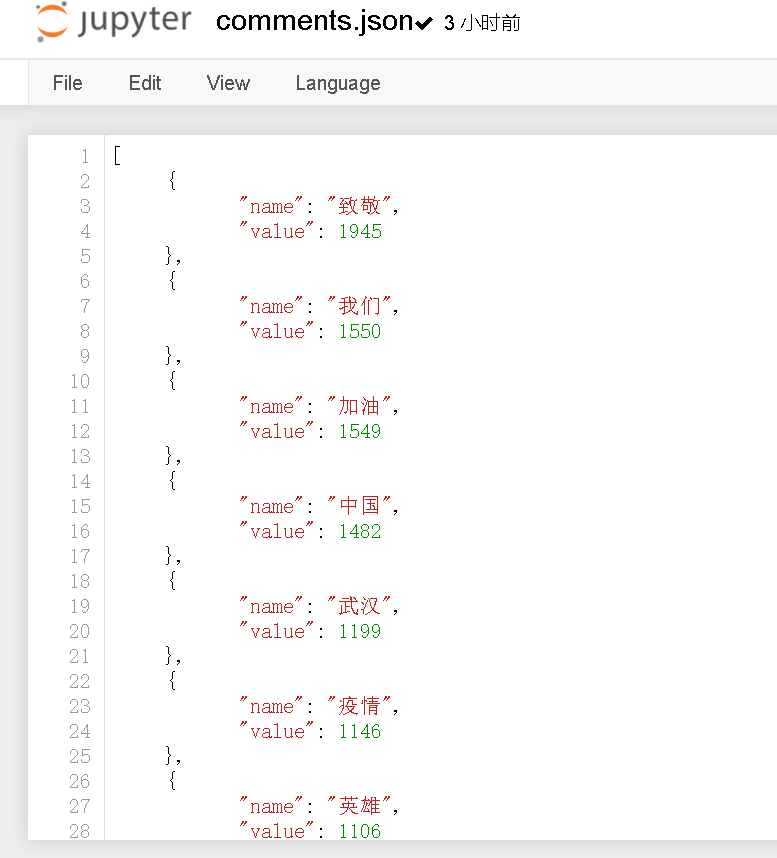
利用 jieba 库给评论分词
三、数据可视化
将分好的词进行可视化形成词图云,因为之前没有接触过 HTML 语言也是就形成一个词图云,就在网上找教程,利用别人写好的当成模板,图案我就自己加了一个中国的地图

四、上传


 浙公网安备 33010602011771号
浙公网安备 33010602011771号