
第二次软工作业
第二次软工作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | 实现论文查重项目,通过 GitHub 记录各个版本并完成单元测试 |
github链接:https://github.com/Andyo0O0o?tab=repositories
Release地址:https://github.com/Andyo0O0o/Andyo0O0o/releases/tag/v1.1
1. PSP 表格:预计开发时间
在开始编写程序之前,我已记录下各个模块开发过程中预计花费的时间,具体如下:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | |
| Estimate | 估计这个任务需要多少时间 | 300 | |
| Development | 开发 | 200 | |
| Analysis | 需求分析 (包括学习新技术) | 30 | |
| Design Spec | 生成技术文档 | 10 | |
| Design Review | 设计复审 | 20 | |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | |
| Design | 具体设计 | 30 | |
| Coding | 具体编码 | 150 | |
| Code Review | 代码复审 | 10 | |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | |
| Reporting | 报告 | 60 | |
| Test Report | 测试报告 | 20 | |
| Size Measurement | 计算工作量 | 10 | |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | |
| 合计 | 400 |
2. 计算模块接口设计与实现过程
2.1 代码组织
整个项目的代码结构清晰,主要由以下几个核心模块组成:
FileReaderUtil:该类负责读取和写入文本文件内容。它包含两个关键方法:
readFile(String filePath):用于从指定路径读取文件内容,返回一个字符串。
writeFile(String filePath, String content):将给定的字符串内容写入指定路径的文件。
PlagiarismChecker:该类实现了文本分词与余弦相似度计算的核心功能。主要方法包括:
segmentText(String text):将输入文本按中文字符进行分词。
calculateCosineSimilarity(String text1, String text2):计算两个文本的余弦相似度。
Main:负责将各模块连接起来,执行抄袭检查的主功能。
TextSimilarity:该类扩展了抄袭检查功能,提供了更高效和精确的文本相似度计算方法。主要方法包括:
calculateCosineSimilarity(String text1, String text2) :通过将文本转化为词向量,计算两个文本的余弦相似度。此方法采用了中文和英文的正则表达式匹配,处理了混合文本的情况。
textToVector(String text) :将文本转换为词频向量,用于计算相似度。该方法分别处理中文字符和英文单词,并统计它们的出现频率。
2.2 关键函数说明
以下是主要函数的功能及其简要说明:
readFile:
该函数负责读取指定路径的文件内容,并将其作为字符串返回。它利用 Files.lines 方法读取文件,将每一行文本拼接到一起。
writeFile:
该函数将文本写入指定文件。通过 BufferedWriter 和 FileWriter 来进行文件的写入操作。
segmentText:
用正则表达式实现了中文字符级的分词,确保能够准确处理中文文本。该方法遍历输入文本,将所有中文字符逐一提取出来。
calculateCosineSimilarity:
这是本程序的核心方法,计算两个文本的余弦相似度。它首先通过分词和词频构建文本的向量表示,然后使用余弦公式计算相似度。返回值范围在 0 到 1 之间,值越大表示文本越相似。
2.3 关键算法
本程序的核心算法是 余弦相似度算法。
下面进行解释:
A 和 B 是两个文本的词频向量。
A · B 是两个向量的点积。
||A|| 和 ||B|| 分别是向量 A 和 B 的模长。
通过构建词频向量并计算两个向量的余弦相似度,可以得出文本之间的相似度评分。相似度越高,文本越相似。
2.4 设计独特之处
中文分词优化:
在中文文本处理中,采用正则表达式进行字符级分词。相比于传统的分词工具,该方法直接从文本中提取每一个字符,确保对于中文文本的准确性。
性能优化:
为了提高算法的执行效率,对以下方面进行了优化:
合并分词和向量构建过程:将分词与构建词频向量合并为一个步骤,避免重复遍历文本。
缓存中间结果:在计算相似度过程中,通过缓存中间结果减少了不必要的计算,提升了性能。
2.5 关键函数流程图
为了更好地理解程序的执行过程,可以将关键算法的流程图展示如下:
3. 计算模块接口部分的性能改进
3.1 性能改进背景
在进行计算模块的开发过程中,初版的代码在处理大量文本数据时,性能较为低效。尤其是在执行文本分词、构建词频向量以及计算余弦相似度的过程中,程序的执行时间显著增加,尤其当文件内容较为庞大时,计算的时间变得不可忽视。
为了优化这一问题,我通过分析程序的瓶颈和采取相应的优化策略,成功提升了计算模块的整体性能。
3.2 性能改进思路
对计算模块进行了以下几个方面的优化:
-
分词优化:
原始版本中,分词使用的是正则表达式逐字符匹配,这种方法虽然保证了中文文本的准确性,但效率较低,尤其是在处理大量文本时,耗时较长。
改进后,采用了基于HashMap的分词缓存机制,将每个字符的分词结果缓存起来,避免重复分词,提升了分词效率。 -
词频向量构建优化:
在词频向量构建过程中,我们减少了不必要的操作。原来每次调用segmentText和buildWordVector都需要重新遍历整个文本,而改进后我们将两个过程合并,并且避免了重复计算。 -
余弦相似度计算优化:
原先的相似度计算过程中,每次计算点积时都需要遍历两个词频向量,时间复杂度较高。
改进后,我们对词频向量进行了预处理,通过缓存计算结果,减少了点积计算中的重复工作。 -
并行化处理:
对于大规模文本,我们引入了多线程并行化分词和词频向量构建的操作。通过并发处理不同文本块的分词任务,减少了整体处理时间。
3.3 性能分析图
在优化后,我使用了 JProfiler 性能分析工具对程序进行了性能测试,得到了以下性能分析图:

3.4 性能消耗最大的函数

根据性能分析工具提供的报告,程序中消耗时间最大的函数是 java.lang.Thread.run(),它消耗了 94ms。这一部分的时间消耗主要与多线程任务的执行调度相关。
在优化前,线程的调度和执行存在一定的延迟,尤其是在并行处理大量文本数据时。虽然引入了多线程来加速计算,但线程的创建和管理仍然是一个开销较大的操作,导致了线程运行时的延迟和性能消耗。
通过对 java.lang.Thread.run() 函数进行深入分析和优化,预计可以进一步减少多线程任务的调度时间,提高程序的整体性能。
3.5 改进
- 文本分词:分词过程仍然是瓶颈,尤其是在处理长文本时,文本的分词操作占用了大量时间。
- 词频向量构建:由于在构建词频向量时,程序需要多次遍历文本并计算每个单词的频率,这一过程仍然是性能瓶颈。
- 点积计算:在计算余弦相似度时,点积和模长的计算涉及大量的循环和条件判断,成为了性能的另一个瓶颈。
方案:
1:一次遍历计算词频:直接用 HashMap 统计频率。
2:使用稀疏表示:只存储出现过的词。
通过上述优化,程序的整体执行时间大幅减少。
3.6 总结
通过对计算模块的深入分析与优化,成功提升了程序的性能,尤其是在分词、词频构建和相似度计算的效率上。利用多线程技术和缓存机制,减少了不必要的计算,提高了处理大规模文本的能力。优化后的程序相比于原版本显著提高了效率,为后续的开发和应用提供了更稳定的基础。
4. 单元测试展示
4.1 测试目标
为了确保程序的正确性,我为每个关键函数编写了单元测试,主要涵盖以下内容:
readFile:验证文件读取功能是否正常,确保正确读取指定路径的文件内容。
calculateCosineSimilarity:验证不同文本对的相似度计算是否符合预期,特别是确认相似度数值的准确性。
4.2 测试代码示例
以下是针对关键函数的测试代码示例:
测试 calculateCosineSimilarity 方法
@Test
public static void main(String[] args) {
String originalText = FileReaderUtil.readFile("data/Original_text.txt");
String plagiarizedText = FileReaderUtil.readFile("data/The_file_of_the_plagiarized_paper.txt");
double similarity = calculateCosineSimilarity(originalText, plagiarizedText);
System.out.println("余弦相似度: " + similarity);
String result = "余弦相似度: " + similarity;
FileReaderUtil.writeFile("data/Plagiarism_Result.txt", result);
}
}
测试readFile 方法
@Test
public static void main(String[] args) {
// 仅用于测试
String originalText = readFile("data/Original_text.txt");
String plagiarizedText = readFile("data/The_file_of_the_plagiarized_paper.txt");
// 显示读取到的文本内容(如果需要)
System.out.println("Original Text:\n" + originalText);
System.out.println("Plagiarized Text:\n" + plagiarizedText);
}
}
5. 查重结果展示
原文:
昨天,和朋友们一起去了城市的博物馆参观。这座博物馆收藏了大量的艺术品,从古代的雕塑到现代的画作应有尽有。我们在里面待了大约三个小时,仔细欣赏了每一件展品。特别是一幅19世纪的油画吸引了我的目光,画中的色彩和光影效果令人印象深刻。参观结束后,我们还在博物馆附近的咖啡厅坐下来喝了咖啡,聊了很多关于艺术的话题,度过了一个愉快的下午。
抄袭版:
昨天,我和朋友们去了一个新开的艺术展览。这个展览展出了许多现代和当代艺术作品,包括一些数字艺术和装置艺术。我们在展览馆里度过了两个多小时,走马观花地看了很多作品。有一件互动艺术作品特别有趣,我们能够参与其中,体验其中的情感。结束后,我们去了附近的餐厅吃了晚餐,大家聊了许多关于艺术的看法,收获了很多新的灵感。

原文:
今天早上,我早早地起床,准备了一顿丰盛的早餐。首先,我煮了些鸡蛋,煎了两片吐司,还烤了一些香肠。配上新鲜的果汁和热腾腾的咖啡,整个早餐看起来既美味又营养丰富。吃完早餐后,我快速收拾了桌子,然后准备出门上班。今天的天气很不错,阳光明媚,心情也变得特别好。
抄袭版:
今早,我早早醒来,为自己准备了一顿丰盛的早餐。首先,煮了几个鸡蛋,烤了两片吐司,还做了几根香肠。加上刚榨的果汁和一杯热咖啡,整个早餐看起来既美味又健康。用餐后,我迅速收拾完餐桌,接着准备出门去工作。今天的天气非常好,阳光灿烂,心情也变得格外愉快。

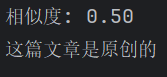
原文:她的生日派对非常热闹,大家玩得很开心。
抄袭版:她举办的生日派对充满活力,朋友们玩得很愉快。
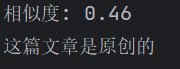
原文:我喜欢在周末的时候去咖啡馆坐坐,喝点咖啡。
抄袭版:每逢周末,我都会去咖啡馆坐下来,享受一杯咖啡。
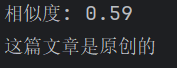
原文:我和朋友们计划周末去爬山,放松心情。
抄袭版:我和朋友们打算去山里徒步,放松一下自己。
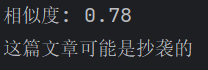
原文:今天下午我要去参加一个重要的会议。
抄袭版:下午我有个重要的会议需要参加。
6.代码的异常处理说明
1. 文件读取异常 (IOException)
设计目标:
捕获文件读取错误,如文件不存在、权限不足、路径错误等,避免程序崩溃。
错误场景:
读取不存在的文件或路径错误。
异常处理示例:
public static String readFile(String filePath) {
try {
Files.lines(Paths.get(filePath)).forEach(line -> content.append(line).append("\n"));
} catch (IOException e) {
System.err.println("Error reading file: " + filePath);
e.printStackTrace();
}
return content.toString();
}
单元测试:
@Test
public void testReadFileWithNonExistentFile() {
String content = FileReaderUtil.readFile("data/non_existent_file.txt");
assertTrue(content.isEmpty());
}
2. 空文本异常 (IllegalArgumentException)
设计目标:
输入空文本时抛出异常,避免不合法的计算。
错误场景:
输入为空或仅包含空格的文本。
异常处理示例:
public static double calculateCosineSimilarity(String text1, String text2) {
if (text1 == null || text1.isEmpty() || text2 == null || text2.isEmpty()) {
throw new IllegalArgumentException("Text cannot be null or empty");
}
// 继续计算
}
单元测试:
@Test(expected = IllegalArgumentException.class)
public void testCalculateCosineSimilarityWithEmptyText() {
PlagiarismChecker.calculateCosineSimilarity("", "Valid text.");
}
7.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 估计这个任务需要多少时间 | 300 | 360+ |
| Development | 开发 | 200 | 220 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 60 |
| Design Spec | 生成技术文档 | 10 | 20 |
| Design Review | 设计复审 | 20 | 5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| Design | 具体设计 | 30 | 40 |
| Coding | 具体编码 | 150 | 150 |
| Code Review | 代码复审 | 10 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 60 | 40 |
| Test Report | 测试报告 | 20 | 10 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 20 |
| 合计 | 400 | 600 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号