用链表和数组实现HASH表,几种碰撞冲突解决方法
Hash算法中要解决一个碰撞冲突的办法,后文中描述了几种解决方法。下面代码中用的是链式地址法,就是用链表和数组实现HASH表。
he/*hash table max size*/ #define HASH_TABLE_MAX_SIZE 40 /*hash table大小*/ int hash_table_size=0; /*.BH----------------------------------------------------------------- ** 结构体定义 **.EH----------------------------------------------------------------- */ /*hashTable结构*/ typedef int HashKeyType; typedef struct{ OMS_TYPE__CurrFaultReport curr_fault_report; unsigned int begin_time[SYS_FAULT_REPORT_MAX_NUM]; unsigned int end_time[SYS_FAULT_REPORT_MAX_NUM]; unsigned int report_valid[SYS_FAULT_REPORT_MAX_NUM]; }HashValueType; typedef struct HashNode_Struct HashNode; struct HashNode_Struct { HashKeyType sKey; HashValueType nValue; HashNode* pNext; }; HashNode* hashTable[HASH_TABLE_MAX_SIZE]; //hash table data strcutrue /*=================hash table function======================*/ /*.BH----------------------------------------------------------------- ** **函数名: ** **功能:string hash function ** **参数: 无 ** **返回值:无 ** **设计注记: ** **.EH----------------------------------------------------------------- */ unsigned int hash_table_hash_str(const char* skey) { const signed char *p = (const signed char*)skey; unsigned int h = *p; if(h) { for(p += 1; *p != '\0'; ++p){ h = (h << 5) - h + *p; } } return h; } /*.BH----------------------------------------------------------------- ** **函数名: ** **功能:insert key-value into hash table ** **参数: 无 ** **返回值:无 ** **设计注记: ** **.EH----------------------------------------------------------------- */ int hash_table_insert(const HashKeyType skey, HashValueType nvalue) { unsigned int pos = 0; HashNode* pHead = NULL; HashNode* pNewNode = NULL; if (hash_table_size >= HASH_TABLE_MAX_SIZE) { printf("out of hash table memory!\n"); return 0; } pos = hash_table_hash_str(skey) % HASH_TABLE_MAX_SIZE; pHead = hashTable[pos]; while (pHead) { if (pHead->sKey == skey) { printf("hash_table_insert: key %d already exists!\n", skey); return 0; } pHead = pHead->pNext; } pNewNode = (HashNode*)malloc(sizeof(HashNode)); memset(pNewNode, 0, sizeof(HashNode)); pNewNode->sKey = skey; memcpy(&pNewNode->nValue, &nvalue, sizeof(HashValueType)); pNewNode->pNext = hashTable[pos]; hashTable[pos] = pNewNode; hash_table_size++; return 1; } /*.BH----------------------------------------------------------------- ** **函数名: ** **功能:lookup a key in the hash table ** **参数: 无 ** **返回值:无 ** **设计注记: ** **.EH----------------------------------------------------------------- */ HashNode* hash_table_find(const HashKeyType skey) { unsigned int pos = 0; pos = hash_table_hash_str(skey) % HASH_TABLE_MAX_SIZE; if (hashTable[pos]) { HashNode* pHead = hashTable[pos]; while (pHead) { if (skey == pHead->sKey) return pHead; pHead = pHead->pNext; } } return NULL; } /*.BH----------------------------------------------------------------- ** **函数名: ** **功能:free the memory of the hash table ** **参数: 无 ** **返回值:无 ** **设计注记: ** **.EH----------------------------------------------------------------- */ void hash_table_release() { int i; for (i = 0; i < HASH_TABLE_MAX_SIZE; ++i) { if (hashTable[i]) { HashNode* pHead = hashTable[i]; while (pHead) { HashNode* pTemp = pHead; pHead = pHead->pNext; if (pTemp) { free(pTemp); } } } } } //remove key-value frome the hash table /*.BH----------------------------------------------------------------- ** **函数名: ** **功能:string hash function ** **参数: 无 ** **返回值:无 ** **设计注记: ** **.EH----------------------------------------------------------------- */ void hash_table_remove(const HashKeyType skey) { unsigned int pos = hash_table_hash_str(skey) % HASH_TABLE_MAX_SIZE; if (hashTable[pos]) { HashNode* pHead = hashTable[pos]; HashNode* pLast = NULL; HashNode* pRemove = NULL; while (pHead) { if (skey == pHead->sKey) { pRemove = pHead; break; } pLast = pHead; pHead = pHead->pNext; } if (pRemove) { if (pLast) pLast->pNext = pRemove->pNext; else hashTable[pos] = NULL; free(pRemove); } } hash_table_size--; } /*.BH----------------------------------------------------------------- ** **函数名: ** **功能:print the content in the hash table ** **参数: 无 ** **返回值:无 ** **设计注记: ** **.EH----------------------------------------------------------------- */ void hash_table_print() { int i; printf("===========content of hash table===========\n"); for (i = 0; i < HASH_TABLE_MAX_SIZE; ++i){ if (hashTable[i]) { HashNode* pHead = hashTable[i]; printf("%d=>", i); while (pHead) { printf("%d:%d ", pHead->sKey, pHead->nValue.begin_time); pHead = pHead->pNext; } printf("\n"); } } } /*.BH----------------------------------------------------------------- ** **函数名: ** **功能:初始化系统名称的hashTable,插入所有系统名称 ** **参数: 无 ** **返回值:无 ** **设计注记: ** **.EH----------------------------------------------------------------- */ void Common_InitHashTable() { hash_table_size = 0; memset(hashTable, 0, sizeof(HashNode*) * HASH_TABLE_MAX_SIZE); }
Hash碰撞冲突
Hash函数的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰撞冲突。如下将介绍如何处理冲突,当然其前提是一致性hash。
1.开放地址法
开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,…,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,…m-1,称线性探测再散列。
如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,…k*k,-k*k(k<=m/2),称二次探测再散列。
如果di取值可能为伪随机数列。称伪随机探测再散列。
2.再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止
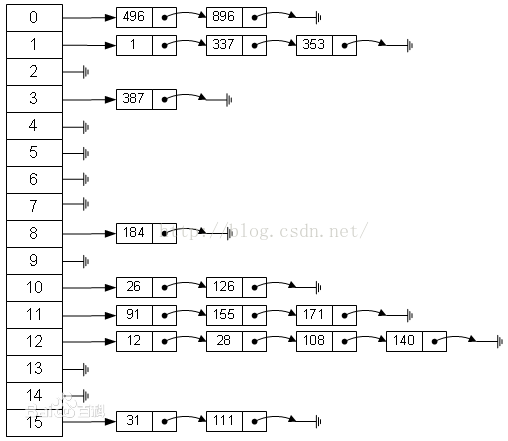
3.链地址法(拉链法)
将所有关键字为同义词的记录存储在同一线性链表中。如下:
因此这种方法,可以近似的认为是筒子里面套筒子
4.建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
优缺点:
优点:
①拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
②由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
③开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结 点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在 用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
缺点:
指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
开放地址法和拉链法是比较常用的两种,各有优缺点,开放地址法的过程可以参考以下链接。
参考链接:HASH碰撞

 浙公网安备 33010602011771号
浙公网安备 33010602011771号