结对项目--第二次作业
结对项目--第二次作业
标签(空格分隔): 软工实践
这里是:作业的传送门
Generator的传送门
Match的传送门
结对情况:248 文航、205 汉森
汉森的传送门
一、设计说明
1.匹配算法设计
这是一个开放性的题目,题目给了两个开发性的思考点,
4、需要为匹配算法确立几条分配或排序原则,比如 绩点优先、或兴趣优先、或活动时间优先、或其他等等,请你们结对讨论确定。
5、对不同策略做出评价,并在博客中展示测试结果。提醒:对于同一组输入,输出的未被导师选中的学生数越少越好
。
(a、学生优先
一开始我看到这个题目要求的时候,特别是看到第五点的提示的时候,以为题目的要求是:
确定某种匹配原则,来使得尽可能多的学生都能加入部门,并且以此处为出发点,思考学生优先的匹配方案。
-
网络流思想
部门与学生可以看作是图中的点,学生向部门申请,可以给他们连一条边,每条边的边权由某些给定的计算方法得出,每个部门可以选择的边不能超过部门纳新人数上限,求尽可能多的连边的同时,保证选择的边权尽可能的大,没有选择中边的点尽可能的少。
某些给定的计算方法可以根据部门对学生的能力要求的不同,和学生自身能力值不同来确定,如:学习部对成绩方面的要求相对比较高,体育部对体育运动方面比较青睐、职业发展部对部员灵活的时间性方面要求比较高,需要随叫随到等。
因此,想要想到了网络流的算法思想:
1.学生和部门都当作一个点,新增一个源点和汇点
2.源点s连有向边到每个学生
3.学生向他申请的每个部门连一条有向边
4.每个部门向汇点t建一条有向边
5.部门到汇点的流量为部门纳人数上限,费用为0
6.学生和部门之间连边的流量为1,费用为给点的计算方法。
7.源点到学生的流量为申请数费用为,INF/学生的申请数
利用网络流中的最大费用最大流模型,满足匹配人数最多(最大流),人员分配合理(最大费用),让尽量多的学生都能匹配(源点到学生的费用为INF/学生的申请数 可以是的让申请部门少的同学占一些优势) -
贪心---优先级思想
利用贪心的思想,类比高考填报志愿,给每个学生的部门申请投以优先级:第一志愿>第二志愿>第三....
利用三层循环:第一层枚举部门,第二层枚举学生,第三层获取该学生对这个部门的匹配度,如:判断是否时间冲突、是第几个志愿等,然后贪心从匹配度高的开始一个部门一个部门的来
(b、部门优先
经过激烈的讨论后,我的学生优先的两个想法先后被自己和别人hack了。于是乎,我恍然大悟:没有必要以学生优先,实际的情况是,部门之间的选人是相对独立的,处于竞争状态,应该都是尽可能的选取最优秀的生源为主要目标,这个想法会比较合理
- 贪心
利用某个方法计算出 学生--部门 的匹配度,然后每次选取匹配度最高的 学生--部门 ,然后让这个学生加入对应的部门,同时更新这个学生对其他部门的匹配度(有些部门对部员加入的部门数有要求)
最终设计
最终,我们假设的场景是:
新生入学,准备加入部门,部门积极准备纳新,各个部门都争相向选取更满足部门条件的部员,新生们也想通过自己的实际情况和部门的一些介绍来想加入对自己更有意义的部门
经过详细的考虑后,我们一致选择了部门优先的想法。
部门优先的情况下:我们一致的认为,兴趣是关键,为了让兴趣标签更加符合第一优先级的原则,我们设定每个部门的兴趣标签数量相同,以匹配部门的兴趣标签数为匹配度的第一考量,这样子可以保证不会出现,拥有更多兴趣标签的部门更具优势。
接下来,就是可以参与部门的活动时间,由于两个人参与部门的经历不同,汉森认为部门例会很重要,要保证有时间参与,文航认为参与部门的例会不是关键,那些不定期的部门活动才是加入部门的意义所在,所以综合考虑,时间就分成了两块,学生的每周固定时间和每周的不定期时间,以总的空闲时间作为第二考量,当学生匹配了一个部门后,因为例会的关系,总空闲时间有所下降,因此要更新该生对其他部门的匹配度,若是考虑到部门除了例会以外还有其他活动,会使得匹配算法过于复杂,因此总空闲时间的减少量为部门例会的时间。
至于绩点,个人认为及时是大二大三的学生,成绩与部门的影响比较小,兴趣标签已经足以表现这方面的情况。
还有其他的,如:给部门定一些属性的比例,如:不同兴趣标签之间还有优先级等,就算能实现,实际情况是:不存在属性的考量标准,我们思考的其他方面的东西,要么真实很难定量,要么想不出来,我们觉得匹配只是一个初步标准,其他东西需要面试才能体现
匹配细化成量的原则:

2.内部实现设计(类图)(1)
根据上述想法,在不考虑输入输出使用json的情况下,仅由C++完成整个过程设计的类图
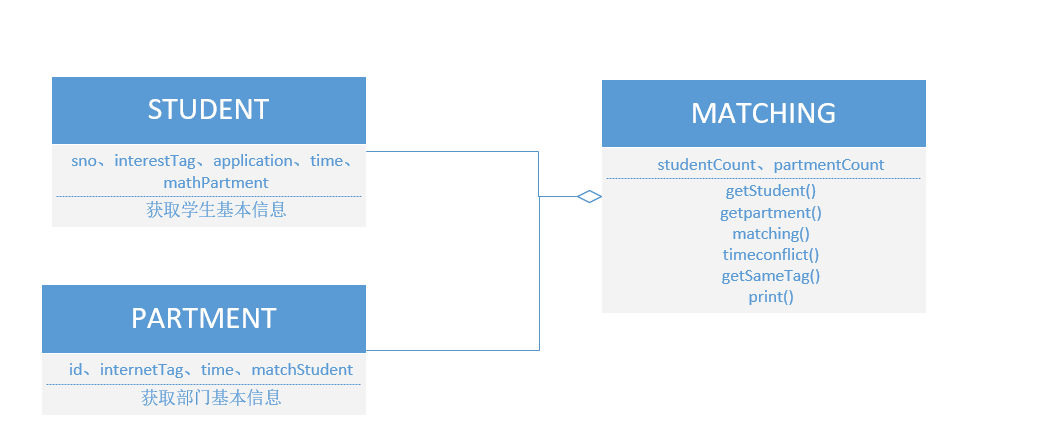
3.接口设计(API)
算法实现后,为了实现json的输入与输出,定下了相应的输入要求
(经过算法设计难度和json设计难度的考量,输入输出要求版本已经改进了3次)
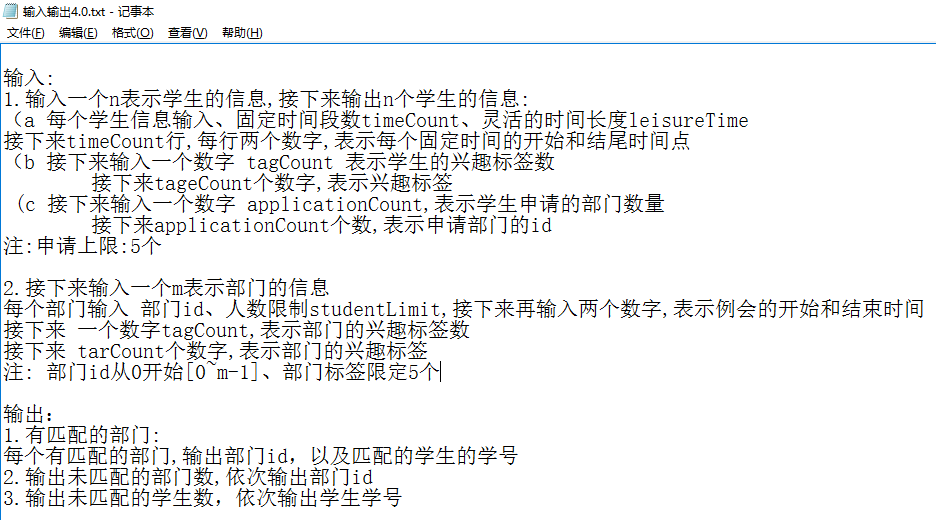
类READDATA:
- 构造函数:传入文件名
- getStudents() 返回vector
- getDepartment() 返回vector
struct student {
int id;
vector<times> times;
int actives;
vector<string> tags;
vector<int>applications;
};
struct department {
int id;
times meeting;
vector<string> tags;
int limit;
};
类MATCHING
- void getStudent(vector
&S) //初始化学生 - void getPartment(vector
&P)//初始化部门 - void matching()//匹配
- void Print()//输出到文件
4.内部实现设计(类图)(1)
完成了接口设计后,已经可以让代码正常运行了,类图也就完整了
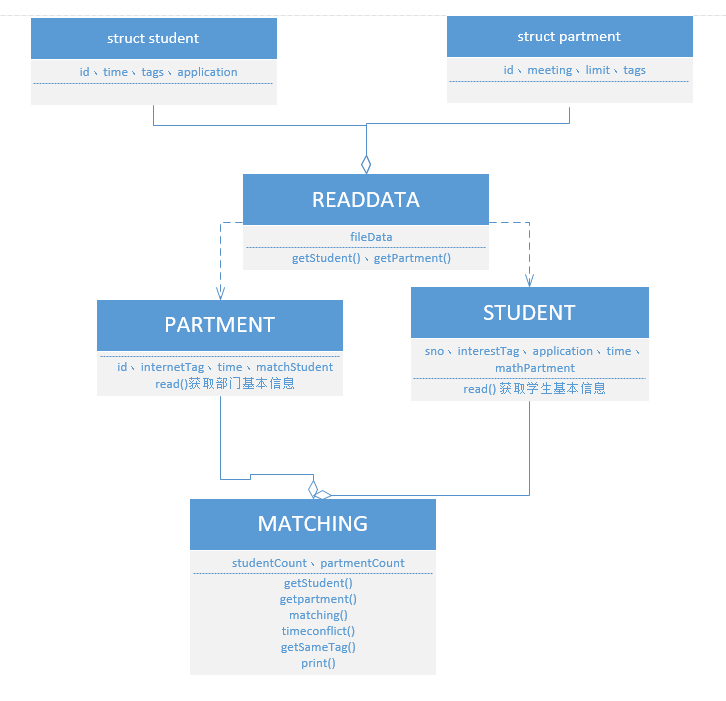
5.测试数据的实现
其实测试数据的实现基本上就是根据拟定的输入输出的要求来的,由汉森实现。
由go语言实现编码,然后利用的go语言自带导出json的功能,到处生成json。
(我都惊了,原来还有这种操作)
涨知识: 比较新的语言很多都有自动导出成其他语言的方法
这算不算歪门邪道,但是满足题目的要求
二、代码实现
1.代码规范
代码规范?不存在的
代码规范我们好像重视度不高...只是简单的进行了规范
规范要求:
1.缩进2个空格
2.变量命名:使用对应作用的英文单词,小驼峰式命名法
4.函数注释风格:
5.类名大写
唔...这点是做的不太好
2.核心代码
(a 匹配过程
struct P {
int sid; //学生ID
int pid; //部门ID
int sameTag; //部门与学生的相同兴趣标签数
int time; //学生的空闲时间
P(int _sid = 0,int _pid = 0,int _sameTage = 0,int _time = 0):sid(_sid),pid(_pid),sameTag(_sameTage),time(_time){
}
//重载运算符: 兴趣第一原则,时间第二原则
bool operator < (const P &t) const {
if(sameTag ==t.sameTag) return time < t.time;
else return sameTag < t.sameTag;
}
};
//匹配算法的实现
void MATCHING::matching()
{
/*-------init-------*/
STUDENT *stu;
PARTMENT *par;
//用优先队列来贪心每次选取最大的匹配度
priority_queue<P>que;
P t;
//记录每个学生的空闲时间
int *leisureTime = new int[studentCount+10];
//初始化匹配度和空闲时间
//枚举学生
for (int i = 0; i < studentCount; ++i){
stu = Student + i;
leisureTime[i] = stu->leisureTime;
//枚举部门
for (int j = 0; j < stu->applicationCount; ++j){
int k = stu->application[j];
if (k >= partmentCount) continue;
par = Partment + k;
if (timeconflict(stu, par)) continue; //判断是否冲突
int sameTag = getSameTag(stu, par);
int time = stu->leisureTime;
t = P(stu->studentId, par->partmentId,sameTag,time);
que.push(t);
}
}
/*-------solve-------*/
while (!que.empty()){
t = que.top(); que.pop();
stu = Student + t.sid;
par = Partment + t.pid;
//--判断当前的 学生--部门 信息是否已经过时
if (leisureTime[t.sid] != t.time) continue;
if (stu->matchCount == stu->applicationCount) continue;
//部门获取人数已经达到上限
if (par->matchCount == par->studentLimit) continue;
//匹配成功
par->matchCount++;
par->mathStudent.push_back(t.sid);
stu->matchCount++;
stu->matchPartment.push_back(t.pid);
t.time -= (par->regularTime.second - par->regularTime.first + 1);
leisureTime[t.sid] = t.time;
//更新 学生--部门 信息
for (int j = 0; j < stu->applicationCount; ++j){
int pid = stu->application[j],k;
if (pid >= partmentCount) continue;
par = Partment + pid;
if (timeconflict(stu, par)) continue;
//判断 当前部门是不是已经加入了,加入了就不用更新
for (k = 0; k < stu->matchCount; ++k){
if (pid == stu->matchPartment[k]) break;
}
if (k==stu->matchCount||k < stu->matchCount && pid == stu->matchPartment[k]) break;
int sameTag = getSameTag(stu, par);
int time = t.time;
que.push(P(stu->studentId, par->partmentId, sameTag, time));
}
}
}
(b 冲突判断条件
//判断学生与部门的冲关系
bool MATCHING::timeconflict(STUDENT * stu, PARTMENT * par1)
{
//判断是否已经加入了该部门
for (int i = 0; i < stu->matchCount; ++i)
{
int j = stu->matchPartment[i];
if (j == par1->partmentId) return true;
}
//判断学生加入的部门是否与该部门例会上时间冲突
PARTMENT *par2;
for (int i = 0; i < stu->matchCount; ++i)
{
int j = stu->matchPartment[i];
par2 = Partment + j;
int mx = max(par2->regularTime.first, par1->regularTime.first);
int mi = min(par2->regularTime.second, par1->regularTime.second);
if (mx <= mi) return true;
}
//判断学生的固定时间中是否包含了整个部门的例会时间
for (int i = 0; i < stu->timeCount; ++i)
{
if (stu->stableTime[i].first <= par1->regularTime.first
&&stu->stableTime[i].second <= par1->regularTime.second)
{
//stu->matchCount++;
return false;
}
}
return true;
}
三、算法评价
1.运行及测试结果展示
测试200位同学,20个部门的情况
测试500位同学,30个部门的情况】
测试1000位同学,50个部门的情况
测试5000位同学,100个部门的情况
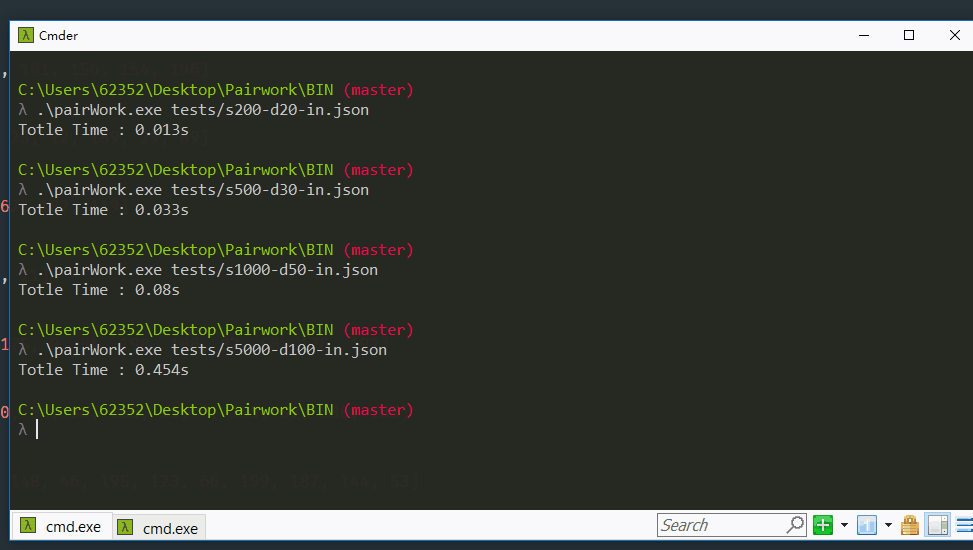
输出效果图
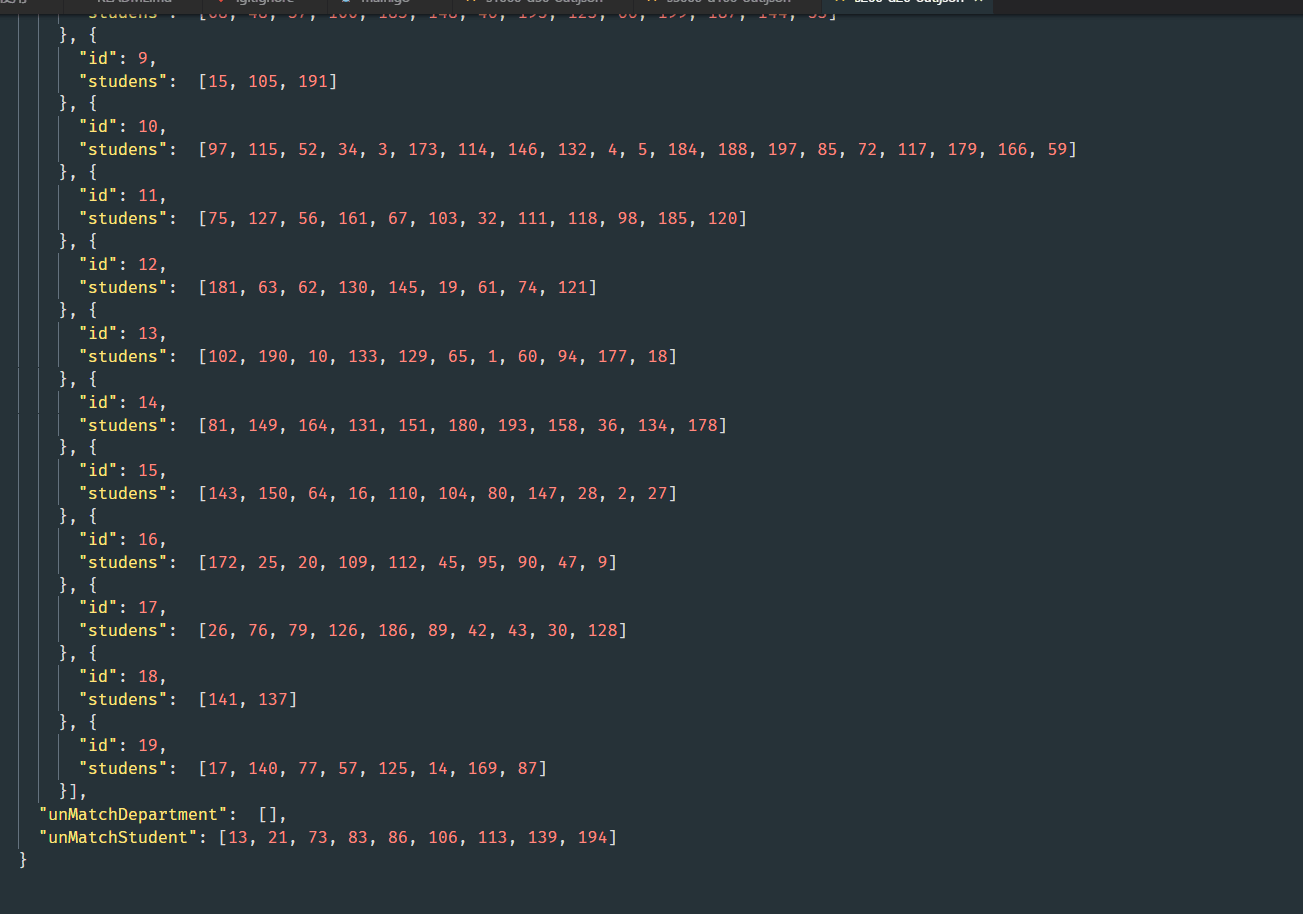
测试统计结果: 100%的部门都能匹配,70%~80%的学生能匹配
2.效能分析报告
直接测试5000student 和 100 department的性能
1.纯C++ 的输入输出
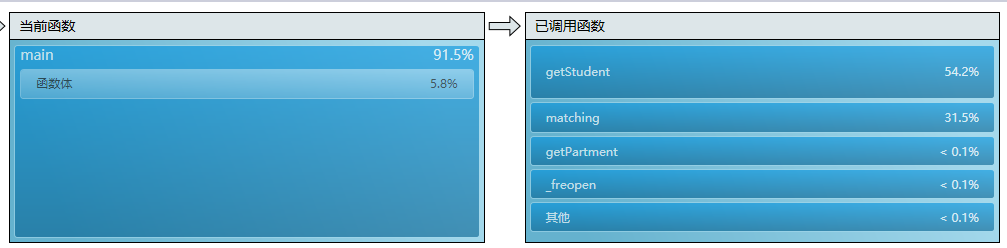
发现getSudent函数占了一半的时间?
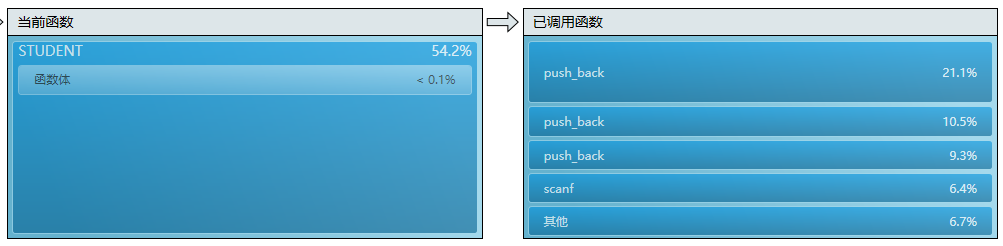
原来是vector的输入耗时很大,STL在没有开O2优化的情况,是很耗时的,然后vector是很好用的东西,直接5000个student的数组是acm行为,new的话指针太多不好处理,所以最后还是保留vector这种方式

getSameTag函数耗时也很多?由于兴趣标签很少,两重循环的方式不会耗时太多兴趣标签是字符串类型,存储方式是指针,排序然后用O(n)的方法也不会减少太多,反而增加代码的复杂度。所以没有想到什么优化的方法,唯一能做的就是限制一下每个人和部门标签数不要太多(这样也符合实际)
2.完整实现后的分析度

果然不出所料,getStudents()的耗时增加了,vector还是大头

算法评价:
(a 学生优先
匹配度当然高啦,没有匹配到的学生数量会比较少。
- 网络流思想
虽然网络流思想的算法先后被自己的acm队友和汉森给hack了,前者觉得网络流不适合解决这种灵活性比较大的题目,后者觉得网络流没有办法解决部门之间的冲突问题。
- 志愿优先级思想
这个应该算是实现简单,耗时也比较低的,学生匹配率效果也很好的一个算法。应该基本上能满足大部分同学的需求,应该很多同学都会选择这个思想的方法,应该能得到不错的时效和匹配率。
(b 部门优先
个人用vs最大的输入输出数据测试时间是在30s内能跑出结果(输出没有用json),但是交给汉森跑可以在0.5s内跑出来,这个结果在我最初的构想内是合理的,最坏情况下是n = 5000,m = 10,tagCount = 5,applicationCount = 5 5,优先队列内元素最坏情况是:nmappliaction常数(不知道怎么算,就设为40)log(nm*appliaction)约为 20000W, 1s 是 10000W-100000W左右,应该就是不到1s时间,但是实际上复杂度很玄学,算清楚比较麻烦,而且和数据有很大的关系。
关于匹配度,学生的匹配度70%~80%,不是特别高,个人认为是属于合理的情况:
1.匹配度由于数据是随机生成的,没有考虑申请部门与其兴趣之间的联系,所以会出现学生申请的部门都是没有什么兴趣的情况,这样子就会比较有劣势。
2.算法本身就不是以包分配为原则的匹配方式。
四、遇到的困难及解决方法
算法设计的输入和json输入不一致
- 困难描述:
把原先C++写的输入换成json的输入端口,一开始是迷茫的,不知道怎么样接到一起
- 做过哪些尝试
让C++的输入和json的输入变量名尽可能一样,开两个屏幕来修改 - 是否解决
解决 - 有何收获
这个问题之前是没有考虑过的,所以碰见的时候比较迷茫,下次的话会注意这个细节,而且发现了自己读代码能力的比较弱。
五、对队友的评价
有哪些好的地方值得学习
做事效率高,而且做事有始有终,虽然一直在叫麻烦麻烦,但是还是坚持到底
有哪些不好或者需要改进的地方
脾气有时候暴。
附件:
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | 610 | 550 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 90 |
| · Design Spec | · 生成设计文档 | 0 | 15 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 120 | 30 |
| · Coding | · 具体编码 | 180 | 120 |
| · Code Review | · 代码复审 | 120 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 210 | 340 |
| · Test Report | · 测试报告 | 180 | 300 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 825 | 900 |
ps:
觉得acm训练不适合放入进度条(耗时但是实际没有那么强的效果)中,因此接下来acm训练内容不加入,但是acm学习时间加入
学习进度条
| 第N周 | 新增代码 (行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 0 | 1000 | 1000 | 40 | 40 | acm训练、vs的使用,项目创建、性能分析等 |
| 1 | 800 | 1800 | 30 | 70 | acm训练,php基础知识学习 |
| 2 | 600 | 2400 | 10 | 80 | acm训练,wampserver的安装配置、php基础知识学习 |
| 3 | 400 | 2800 | 8 | 88 | CI框架学习 |
| 4 | 300 | 3100 | 12 | 100 | CI框架学习、acm学习 |
| 5 | 600 | 3700 | 14 | 114 | CI框架学习 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号