关于C++项目中的vector大量删除操作效率低的简单处理方法
前言
std::vector简单易用,随机访问效率高,在实际C++项目中的应用十分广泛,在数据量较少时,插入和删除的效率还可以被开发者接受。但随着时间发展,不可预料的复杂业务变多,开发人员的水平难以保证,项目会逐渐变得庞大甚至臃肿。这时vector中的数据量或许会上升到百万级别,大量插入和删除的时间会急剧上升,大幅降低软件的使用体验,让用户感到难以接受。
重构是一种解决方案,可以将vector完全替换为其他容器,从根本上解决效率问题。但需要十分熟悉业务的人花费大量时间梳理所有涉及到vector的业务逻辑,以保证功能的正确性,这一步的时间成本会非常高,甚至完全无法接受。因此需要一种低成本的优化方案,能够在短时间内提高vector大量插入删除效率。本文会以vector的大量删除为例,从效率低的原因出发,对vector的大量删除效率进行简单优化。
实际项目场景
一些项目最开始时的数据量并不大,因此vector的大量删除效率并无瓶颈。随着业务规模扩大,业务复杂性逐渐提高,vector中存储的数据也会逐渐增多,vector大量删除元素的效率瓶颈会越来越明显,直到无法被用户接受。
常见删除的代码如下:
// 存在难以替换的成员std::vector<DataClass*> m_dataList
// 下面是一个典型的大量删除函数
void DataClass::Remove(const std::vector<DataClass*>& removedDataList)
{
for (DataClass* removedData : removedDataList)
{
auto resultIter = std::find(m_dataList.begin(), m_dataList.end(), removedData);
if (resultIter != m_dataList.end())
{
m_dataList.erase(resultIter);
delete removedData;
}
}
}
效率分析
(这部分内容参考了《STL源码解析》)
find()函数
std::vector的find()函数源码如下所示。
template <class InputIterator, class T>
InputIterator find(InputIterator first, InputIterator last, const T& value)
{
while (first != last && *first != value)
++first;
return first;
}从源码中可以看出,find()函数会在first和last之间遍历一次,从中找到与value相同的元素并返回对应迭代器。
这个操作的时间复杂度是O(n)。
erase()函数
std::vector的erase函数的源码如下所示。
iterator erase(iterator position)
{
if (position + 1 != end()))
copy(position + 1, finish, position);
--finish;
destroy(finish);
return position;
}(注:finish就是end()函数所返回的迭代器)
从代码中可以看到以下两个关键点:
- 如果要删除的元素是vector的最后一个元素,会直接删除,时间复杂度是O(1)
- 如果要删除的元素不是最后一个,会先将这个元素之后的所有元素复制到前一个位置,再删除最后一个元素
由此可知,erase一个中间元素的效率取决于copy函数的效率。
copy()函数
copy函数可以说把效率提升到了极致,实现比较复杂,在这里先不展开。
简而言之,copy函数主要做了两件事:
- 如果要复制的数据是内置类型(int, short, double等等),会直接调用memmove()来完成任务,时间复杂度是O(1)
- 如果要复制的数据是用户自定义类型,就一个一个复制,时间复杂度是O(n)
也就是说,使用了自定义的类型的情况下,大量erase效率较差( O(n^2) ),需要考虑优化;如果vector使用的是内置类型,虽然erase()函数效率高,但考虑find()函数的效率,总的时间复杂度依然是O(n^2),同样需要考虑优化。
优化方案简述
大量删除效率低的原因来自两个方面:
- 多次调用find()函数
- 每次删除都需要移动大量元素O(n)
这就给了一个优化思路——用空间换时间的方法,加快find()效率,减少删除后调整元素所花费的时间。
以下从不考虑vector排列顺序和考虑vector排列顺序两方面来给出优化方案。
不考虑原vector排列顺序
在大量删除数据时,set的find()操作和erase操作需要的调整时间(O(log n))远小于vector,在不考虑vector元素顺序的情况下,可以使用set来重写删除函数。
注:使用unordered_set理论上也可以,这里以set为例进行测试。
// 存在难以替换的成员std::vector<DataClass*> m_dataList
// 下面是一个优化后函数,不用考虑m_dataList的顺序
void DataClass::Remove(const std::vector<DataClass*>& removedDataList)
{
std::set<DataClass*> tempSet(m_dataList.begin(), m_dataList.end());
for (DataClass* removedData : removedDataList)
{
tempSet.erase(removedData);
delete removedData;
}
std::vector<DataClass*> tempVector(tempSet.begin(), tempSet.end());
m_dataList.swap(tempVector);
}考虑原vector排列顺序
在大量删除数据并且需要考虑原有元素顺序时,情况会复杂一些。需要用到两个map,一个记录原有顺序信息,另一个用来优化删除操作。
同上,使用unordered_map理论上也可以,这里以map为例进行测试。
// 存在难以替换的成员std::vector<DataClass*> m_dataList
// 下面是一个优化后函数,需要考虑m_dataList的顺序,保证删除后原顺序不变
void DataClass::Remove(const std::vector<DataClass*>& removedDataList)
{
std::map<DataClass*, int> dataToIdMap;
std::map<int, DataClass*> idToDataMap;
for (int i = 0; i < m_dataList.size(); ++i)
{
dataToIdMap.emplace(m_dataList[i], i);
idToDataMap.emplace(i, m_dataList[i]);
}
for (DataClass* removedData : removedDataList)
{
auto findIter = dataToIdMap.find(removedData);
if (findIter != dataToIdMap.end())
{
idToDataMap.erase(findIter->second);
delete removedData;
}
}
std::vector<DataClass*> tempVector;
for (auto& iter : idToDataMap)
{
tempVector.emplace_back(iter.second);
}
m_dataList.swap(tempVector);
}
优化方案测试
有了优化方案后,还是按是否考虑顺序分成两组,分别进行测试,验证优化效果。
(模拟环境:vector中总数据量为100万,需要删除的数据量为10万)
不考虑原vector排列顺序
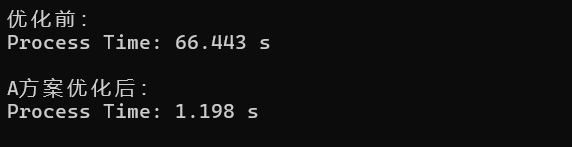
考虑原vector排列顺序

总结
从测试结果来看,无论是基础类型数据类型还是自定义数据类型,大量删除操作的效率都有了非常大的提升,并且效率提升的幅度会随着数据量的增大而增大。
因此,如果项目中存在数据量很大的vector,并且难以替换为其他删除效率更高的数据结构,那么可以参考上述优化方案,从查找流程和删除流程来入手,以较低的优化成本换取可观的效率提升。
本文仅是对这一主题的简单探讨,受限于个人经验与知识水平,难免存在疏漏或不足之处。
若读者发现任何问题,或对文中观点有不同见解,欢迎不吝指正。技术之路永无止境,愿与各位同行共同学习、进步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号