
[HDFS Manual] CH7 ViewFS Guide
ViewFS Guide
2. The Old World(Prior to Federation)
3 New World – Federation and ViewFS
3.2 使用ViewFs的每个cluster的Namespace
1 介绍
View File System(ViewFS)提供一个方法来管理hadoop文件系统namespaces。对于多个namnode的集群很有用。在HDFS Federation,ViewFS和client上面的Linux的mount table 类似。ViewFS可以用来创建个人的namespace。
Hadoop系统有多个clusters,每个cluster可能被联合到多个namespaces。也描述了如何在HDFS联合上使用ViewFS,可以让应用可以使用相似的方法,操作每个联合。
2. The Old World(Prior to Federation)
2.1单个Namenode Clusters
在以前HDFS联合,一个cluster有一个namenode提供了一个文件系统namespace。假设有多个cluster,每个cluster的文件系统namespace都是独立的。此外集群的存储也是相互不共享的。(datanode集群间是不共享的)。
Core-site.xml的每个配置属性设置namenode 的默认文件系统集群:
<property>
<name>fs.default.name</name>
<value>hdfs://namenodeOfClusterX:port</value>
</property>
比如这个配置允许使用相对路径来访问cluster namenode。比如使用上面的/foo/bar配置表示hdfs://namenodeOfClusterX:port/foo/bar。
这个配置属性需要配置在集群的每个gateway,也需要设置在关键的服务上,比如JobTracker和Oozie。
2.2 路径使用
配置了以上设置,通常的路径名:
1./foo/bar
这个配置等于hdfs://namenodeOfClusterX:port/foo/bar
2. hdfs://namenodeOfClusterX:port/foo/bar
是可用的路径,使用相对路径会更好,因为可以根据cluster的变化而变化。
3. hdfs://namenodeOfClusterY:port/foo/bar
指向另外一个集群的路径,可以使用以下命令复制:
distcp hdfs://namenodeClusterY:port/pathSrc
hdfs://namenodeClusterZ:port/pathDest
4.webhdfs://namenodeClusterX:http_port/foo/bar
URI用来访问WebHDFS文件系统。注意WebHDFS使用HTTP端口namenode,而不是使用PRC端口。
5.http://namenodeClusterX:http_port/webhdfs/v1/foo/bar 和http://proxyClusterX:http_port/foo/bar
通过WebHDFS RESET API和HDFS代理,HTTP URLs访问这些文件。
2.3 路径名的最佳实践
推荐使用上面类型1而不是类型2的。绝对URI类似于地址并且不允许应用程序转化数据。
3 New World – Federation and ViewFS
3.1 How The Clusters Look
假设有多个集群。每个集群有一个或者多个namenode。每个namenode都有自己的namespace。一个namenode只属于一个集群。同一个集群的namenode共享集群中的物理存储。Namespace关联的集群是独立的。
3.2 使用ViewFs的每个cluster的Namespace
为了提供和之前的兼容,ViewFS文件系统用来为每个集群创建独立的集群namespace view。和老的namespace类似。以下图片显示了mount table mount了4个namespace:
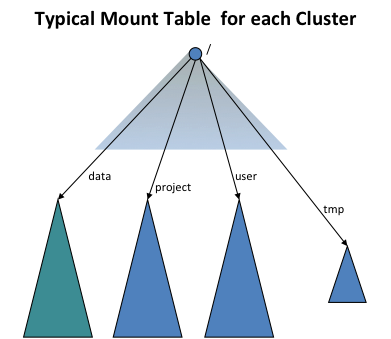
ViewFS实现了Hadoop file system结构和HDFS和本地文件系统类似。感觉就是一个细微的文件系统用来连接到其他文件系统。因为ViewFs实现了hadoop文件系统的借口,对hadoop tool透明。比如ViewFs的命令和hdfs和本地文件系统一样。
在hadoop配置文件可以配置mount表的mount点。在每个集群的配置,默认的文件系统被设置到mount table:
<property>
<name>fs.defaultFS</name>
<value>viewfs://clusterX</value>
</property>
头上在viewfs://之后是mount table名,推荐使用cluster name。然后hadoop系统查看在配置文件中的clusterx的mount table。操作覆盖所有gateway和服务来包含所有集群的mount table。对于每个cluster,默认文件系统会被创建为ViewFs mount table和上面描述的一样。
Mount table 的挂载点在hadoop 配置文件中设置。所有mount table使用fs.viewfs.mounttable配置。Mount point是使用link标签来链接其他文件系统。推荐mount point的名字和挂载目标的一样。对于所有的namespace没有配置在mount table中,我们可以使用linkFallback,fallback到默认文件系统。
在以下mount table配置,namespace /data链接到文件系统hdfs://nn1-clusterx.example.com:8020/data,/project链接到hdfs://nn2-clusterx.example.com:8020/project。所有的namespace没有被配置在mount table的比如/logs都会被链接到hdfs://nn5-clusterx.example.com:8020/home下。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./data</name>
<value>hdfs://nn1-clusterx.example.com:8020/data</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./project</name>
<value>hdfs://nn2-clusterx.example.com:8020/project</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./user</name>
<value>hdfs://nn3-clusterx.example.com:8020/user</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://nn4-clusterx.example.com:8020/tmp</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.linkFallback</name>
<value>hdfs://nn5-clusterx.example.com:8020/home</value>
</property>
</configuration>
替代方案,可以通过linkMergeSlash来合并mount table的root。在mount table配置,ClusterY的root使用hdfs://nn1-clustery.example.com:8020合并。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterY.linkMergeSlash</name>
<value>hdfs://nn1-clustery.example.com:8020/</value>
</property>
</configuration>
3.3 路径使用
配置了以上设置,通常的路径名:
1./foo/bar
这个配置等于hdfs://namenodeOfClusterX:port/foo/bar
2. hdfs://namenodeOfClusterX:port/foo/bar
是可用的路径,使用相对路径会更好,因为可以根据cluster的变化而变化。
3. hdfs://namenodeOfClusterY:port/foo/bar
指向另外一个集群的路径,可以使用以下命令复制:
distcp hdfs://namenodeClusterY:port/pathSrc
hdfs://namenodeClusterZ:port/pathDest
4.webhdfs://namenodeClusterX:http_port/foo/bar
URI用来访问WebHDFS文件系统。注意WebHDFS使用HTTP端口namenode,而不是使用PRC端口。
5.http://namenodeClusterX:http_port/webhdfs/v1/foo/bar 和http://proxyClusterX:http_port/foo/bar
通过WebHDFS RESET API和HDFS代理,HTTP URLs访问这些文件。
3.4 路径使用最佳实践
推荐使用上面类型1而不是类型2的。绝对URI类似于地址并且不允许应用程序转化数据。
3.5 通过namespace重命名路径名
在新的方式下,如果/user和/data在不同的namenode上,那么就不可以运行。
rename /user/joe/myStuff /data/foo/bar
3.7 FAQ
略
4 附录:Mount table配置例子
通常,用户不需要邓毅表或者core-site.xml来使用mount table。
Mount table可以在core-site.xml中描述,但是最好不要直接在core-site.xml上使用,而是通过一个独立的文件,比如mountTable.xml,在core-site.xml增加以下配置:
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="mountTable.xml" />
</configuration>
在mountTable.xml文件,定义了ClusterX的mount table,ClusterX是三个namespace:
1.nn1-clusterx.example.com:8020,
2.nn2-clusterx.example.com:8020,
3.nn3-clusterx.example.com:8020.
这里/home和/tmp由nn1-clusterx.example.com:8020 namenode管理,/foo和/bar在联合集群的其他namenode。Home的base目录被设置在/home,这样每个用户可以通过getHomeDirectory()访问各自的home目录,getHomeDirectory()定义可以查看FileSystem/FileContext.
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterX.homedir</name>
<value>/home</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./home</name>
<value>hdfs://nn1-clusterx.example.com:8020/home</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://nn1-clusterx.example.com:8020/tmp</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./projects/foo</name>
<value>hdfs://nn2-clusterx.example.com:8020/projects/foo</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./projects/bar</name>
<value>hdfs://nn3-clusterx.example.com:8020/projects/bar</value>
</property>
</configuration>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号