Shaders and Pipelines
Shaders and Pipelines
Shaders是设备中的基本的执行模块。vulkan shaders都由SPIR-V来表示——一种二进制表示的中间代码。SPIR-V可以通过离线编译,或嵌入到你的程序当中,又或者运行时以高级语言的形式传递给库。原始的shade是由GLSL语言编写的,这是与OPENGL相同的着色语言经过修改的加强的版本。然而,vulkan自己并不知道任何GLSL语言,也不关心SPIR-V的shaders从哪里而来的。
An Overview of GLSL
虽然不是vulkan标准的一部分,但vulkan与opengl还是有相当一部分是共享的。在opengl中,GLSL是官方支持的高级shading语言。因此,在设计SPIR-V时,相当一部分内容都保证至少一种高级语言可以生成SPIR-V shaders。为了与vulkan一起使用,GLSL做了一些小范围修改。有些添加的特性是为了让GLSL shader干净地与vulkan系统交互,有些vulkan不能利用的遗产特性则在vulkan配置中删除了。
经过瘦身的GLSL版本支持了vulkan的大多数功能,并且opengl和vulkan之间实现了高水平的可移植性。简而言之,如果你在OpenGL中坚持使用OpenGL的现代功能,那么你在shader中编写的大部分内容都可以直接编译成SPIR-V。
GL_KHR_vulkan_glsl扩展记录了关于GLSL的修改内容,使其能够产生适合vulkan使用的SPIR-V shader。
代码展示了最简单的GLSLshader。包含一个空函数,返回void,即不做任何事情。该shader都vulkan pipeline中任何一个阶段都是有效的,即使在某些阶段执行该shader会造成未定义行为。
#version 450 core
void main(void)
{
//Do Nothing!
}
所有的GLSL shaders都应该从#version开始,它直接让GLSL编译器了解我们当前正在使用的GLSL版本。这允许编译器使用合适错误检查以及允许引用最新的语言结构。
当把该shader编译成vulkan使用的SPIR-V格式,编译器应该自动将vulkan定义为正在使用的GL_KHR_vulkan_glsl扩展的版本,这样就可以在GLSL shader中使用#ifdef VULKAN或者#if VULKAN > {version}的宏来包装vulkan特定的结构或功能,以便使相同的shader可以用于vulkan或opengl。
GLSL是c-like语言,它的语法和许多语义都取自C或C++。如果你是一个C程序员,你在看到类似的语法结构会感到很熟悉。
GLSL中基本的数据类型分为有符号和无符号整形以及浮点型,表示为int,uint,float。GLSL支持双精度浮点类型,double。在GLSL中,没有位宽的概念,就像C一样。GLSL没有stdint的类似物,所以是不支持为各种类型定义尾款的,即使GLSL和SPIR-V规范确实为vulkan所使用数值的范围和精度提供了一些最低保证。然而,位宽和布局的定义是为了从内存中获取变量和写入内存所使用的。整数以双分量的形式存储在内存中,浮点变量则遵循IEEE规定,除了精度要求,在正负和非数字(NaN)值的处理有细微的差别。
除了基础的整数和浮点类型,GLSL还有最高有4分量的vector,最多4x4的矩阵的类型。向量和矩阵也是可以被声明的基础类型。比如vec2,vec3,vec4类型,是含有2个,3个和4个浮点分量的向量类型。整数向量通过i和u的前缀表示,代表符号和无符号整数。d前缀则用来表示double类型的分量。
矩阵类型通过matN或matNxM方式表示,代表NxN方阵或NxM矩阵。d前缀代表每一矩阵元素都是double类型。矩阵类型整数表示是不支持的。一个矩阵被认为是由一组向量构成的,每一向量代表矩阵的一列。
布尔类型也是GLSL类型之一,可以由向量表示。布尔变量由bool表示。向量的比较运算会产生一个布尔向量,每个分量代表各分量的比较结果。内置的函数any()和all()可用来产生单个布尔结果用来表示一个布尔向量中否含有任意true结果或者都为true结果。
由系统产生的数据通过内建变量传递给GLSL shaders。比如gl_FragCoord,gl_VertexIndex等。内建变量通常由特定的语义,更改这些变量可以更改shader的行为。
用户指定的数据通过内存传递给shader。变量可以绑定到一块,然后再被绑定到应用程序可写入的、设备可访问的内存上。这允许你将大量的数据传递给shaders。对于小而频繁的数据,有一类特殊的指定变量叫做push constants,我们之后会讲解到它。
GLSL支持大量的内置函数。然而与C相反,GLSL没有头文件,所以不需要使用#include任何东西。GLSL的东西由编译器提供。包含大量的数学函数,纹理采样函数,以及一些特殊的函数比如流控制函数可以控制shader在设备中的执行。
An Overview of SPIR-V
SPIR-V shaders被嵌入到模块(modules) 中。每个模块都包含一个或多个shaders。每个shader都有一个入口名称和一个shader类型,用来定义shaders运行的着色阶段。入口点是shader开始执行的函数。一个SPIR-V模块通过创建信息传递给vulkan,并且vulkan返回一个对象来代表这个模块。然后该模块可以用来构建管线,这是一个编译完全的shader版本。
Representation of SPIR-V
SPIR-V是vulkan官方唯一支持的着色语言。他在API层面接收并且最终被用于构建管线。
SPIR-V的设计是为了让工具和驱动易于使用。这提高了在各种实现之间的移植性。本地的SPIR-V模块是串32位的内存数据流。除非你是一个工具开发这或者打算自己生成SPIR-V,否则你不太可能需要了解SPIR-V的编码。
以上述shader为例,我们将其保存为文本文件并加上.comp后缀,告诉glslangvalidator该shader是一个compute shader。然后可以使用下述命令进行编译:
glslangvalidator simple.comp -o simple.spv
这产生一个SPIR-V二进制文件,叫做simple.spv。我们使用spirv-dis工具对其反汇编,将其转换为人类可读的形式。
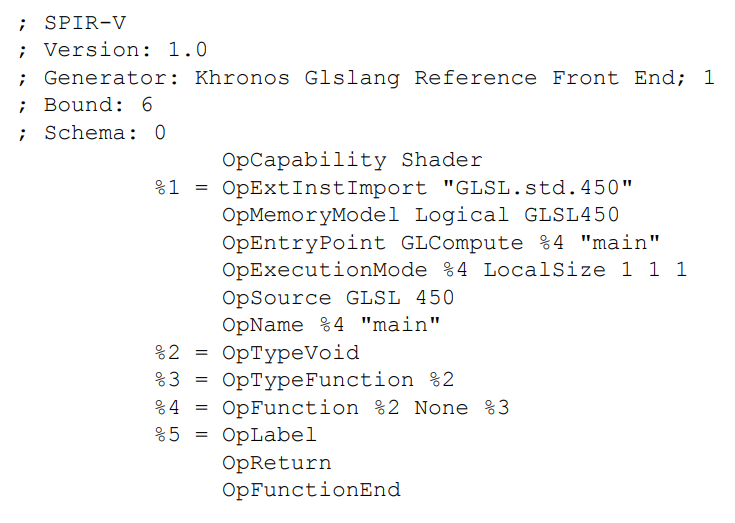
第一行,OpCapability Shader,请求了shader要启用的特性。SPIR-V的功能大致分为相关指令集和特性。在你的shader使用任何特性之前,必须声明使用该特性的能力。上述shader是一个图形shader,所以需要shader能力。这是最基础的能力。没有该能力,我们不能编译图形shaders。
接下来,我们遇见%1 = OpExtInstImport "GLSL.std.450"。这是将GLSL 450版本包含的额外指令的必要步骤,也是源shader所写的内容。主要到指令前面有%1 = , 这是给指令结果赋予ID的方式进行命名。OpExtInstImport的结果实际上是一个库,当我们想调用其中的库函数时,我们使用OpExtInst指令,该指令接收一个库(即该指令结果产生的库)和一个指令索引。这使得SPIR-V指令集可以被任意扩展。
接下来,我们看见一些额外的声明。OpMemoryModel指定了该模块的工作区内存模型,该例子中则是GLSL 450版本对应的logical memory model。这代表着所有的内存访问都是通过资源进行的,而不是不同指针访问的物理内存模型。
接下来的声明指定了模块的入口。OpEntryPoint GLCompute %4 "main"指令的意义是,该compute shader关联一个由ID 4导出的、函数名称为main的可获取的入口点。当我们把模块交给vulkan时,该名称引用入口点。
我们把该ID用在了接下来的指令当中,OpExecutionMode %4 LocalSize 1 1 1,定义了该shader的执行组大小为1x1x1的工作项目。如果local size的layout标识符没有不存在,这将是默认值。
接下里两个指令比较简单,OpSource GLSL 450表明该模块是从GLSL450版本编译而来,OpName 4 "main"给ID 4提供了一个名称。
接下来我们将看到该函数的真正功能。首先%2 = OpTypeVoid声明我们想用ID 2作为void类型。SPIR-V所有东西都由一个ID,即使是类型定义。大型的集合类型可以通过以此引用较小的,简单的类型建立起来。然而,我们需要一个起点,而给void类型一个ID就是我们的起点。
%3 = OpTypeFunction %2意思是我们定义了一个ID 3作为函数类型,包含void类型相关并没有任何参数。然后我们在下面的指令使用它,%4 = OpFunction %2 None %3,意思是我们声明的ID 4(即之前命名为“main”的ID)是一个函数ID 3 的实例(上一条命令声明的),它返回void(ID 2)并且没有特殊的解读。这是通过None表示的,可用于表示内联,变量是否为常数等。
最后,我们看到一个标签的声明(没有使用,只是编译器的一个副作用),它隐含返回语句和函数结尾。也是SPIR-V模块的结尾。
完成的二进制shader有192字节。SPIR-V有些冗长,因为192字节比源shader还要长一点。然后,SPIR-V将源着色语言一些隐含的信息显式的展示了出来。比如,给GLSL声明内存模型是不必要的,因为它只支持logical memory model。此外,在这里编译的SPIR-V模块有一些多余的东西。我们不关心主函数的名字,ID 5的标签从未被使用,shader导入了GLSL.std.450库,但是从未使用过。从一个模块中剥离这种不需要的指令是可能的。即使在这之后,由于SPIR-V编码相对较少,所产生的二进制文件也是易于压缩的,用专门的压缩库也会大大增加压缩量。
Handing SPIR-V to Vulkan
vulkan不太关心SPIR-V模块是从哪来的。一旦你有了一个SPIR-V模块,你需要用一个shader module 去管理它。调用vkCreateShaderModule
VkShaderModuleCreateInfo结构体中,codeSize表示模块的字节大小,pCode指向模块代码。
如果SPIR-V代码合法并且vulkan能够理解,那么调用vkCreateShaderModule会成功,并且将shader module返回给参数指针。
shader module使用完毕需要销毁,调用vkDestroyShaderModule。
Pipelines
在shader module能够使用之前,你需要创建管线。vulkan有两种管线:图形管和运算管线。图形管线是一种复杂的管线,包含许多不相关的shaders。运算管线概念上更简单而且几乎只包含shader code。
Compute Pipelines
在创建一个运算管线之前,我们需要了解一些compute shaders。shader和shader的执行是vulkan的核心。vulkan还提供访问各种功能的固定块来展现诸如复制数据和处理像素数据等功能。然而,shader是构成任何程序的核心。
compute shader提供对设备计算能力原始访问。设备可以看作一组对相关数据进行矢量处理的单元集合。一个compute shader被写成一个串行执行的单一执行轨道,但是许多迹象表明,许多这样的轨道可以并行。事实上,大多是vulkan设备都是这样的构造的。每个执行轨道被称作一个调用。
当一个compute shader被执行,许多调用同时发生。这些调用会被组成一组收进一个固定大小的本地工作组,然后在被称为什么全局工作组中,一个或多个这样的本地组被一起启动。逻辑上,本地和全局工作组都是三维,然后将维度的大小设置为1会降低组的维度。
工作组的大小在compute shader中设置。在GLSL中,这是通过布局限定符完成的,它会被翻译成OpExeCutionMode中的LocalSize。
#version 450 core
layout (local_size_x = 4, local_size_y = 5, local_size_z = 6) in;
void main(void)
{
//Do Nothing.
}
你可以在VkPhysicalDeviceLimits中查看一组的包含最大值。一个本地组中最大的调用量由maxComputeWorkGroupInvocations指出。
Creating Pipelines
....
Specialization Constants
....
Accelerating Pipeline Creation
创建管线可能是程序中最昂贵的操作了。即便SPIR-V代码由vkCreateShaderModule加载,但是直到你调用vkCreateGraphicsPipelines或者vkCreateComputePipelinesvulkan才能看到所有shader阶段以及关联到该管线的其他阶段,这可能会影响到最终在设备执行的最终代码。基于此番原因,vulkan可能会尽量推迟创建可运行的管线对象。这包括shader的编译和代码生成,这些通常被认为是相当密集的操作。
因为多次运行的应用程序可能会重复使用相同的管线,vulkan提供了缓存 机制来存储跨应用的管线创建结果。这允许应用程序快速创建管线并且快速启动管线。管线缓存由接口vkCreatePipelineCache创建。
VkPipelineCacheCreateInfo结构体中,如果存在上一次应用程序运行产生的可用缓存数据,那么数据的地址通过pInitialData传递,数据的大小由initialDataSize指出。如果没有初始化数据可用,那么大小应设置为0,地址为nullptr。
如果缓存被创建,那么初始化数据就用来准备缓存。必要情况下,vulkan会复制一份数据,让pInitialData数据不会被修改。越多的管线被创建,缓存数据就可能越丰富。为了从缓存中获得数据,调用vkGetPipelineCacheData,原型为:
VkResult vkGetPipelineCacheData(
VkDevice device,
VkPipelineCache pipelineCache,
size_t* pDataSize,
void* pData);
如果pData不是nullptr,那么pData将指向一块获取缓存数据的内存,pDataSize的初始值是该内存区域的大小,然后该值将被实际写入到内存中的数据量所覆盖。
如果pData是nullptr,那么pDataSize的初始值将被忽略,该值会被实际需要的内存大小所覆盖。为了完整存储整个缓存数据,需要调用两侧vkGetPipelineCacheData。第一次获得所需要的内存大小,第二次来获得完整数据。
下面代码展示了如何将缓存数据保存到文件。
VkResult SaveCacheToFile(VkDevice device, VkPipelineCache cache, const char* fileName)
{
size_t cacheDataSize;
VkResult result = VK_SUCCESS;
//Determine the size of the cache data.
result = vkGetPipelineCacheData(device, cache, &cacheDataSize,nullptr);
if(result == VK_SUCCESS && cacheDataSize != 0)
{
FILE* pOutputFile;
void* pData;
//Allocate a temporary store for the cache data.
result = VK_ERROR_OUT_OF_HOST_MEMORY;
pData = malloc(cacheDataSize);
if(pData!=nullptr)
{
//Retrieve the actual data from the cache.
result = vkGetPipelineCacheData(device, cache, &cacheDataSize, pData);
if(result == VK_SUCCESS)
{
pOutputFile = fopen(fileName, "wb");
if(pOutputFile != nullptr)
{
fwrite(pData, 1, cacheDataSize, pOutpueFile);
fclose(pOutputFile);
}
free(pData);
}
}
}
return result;
}
一旦你获得了管线缓存数据,你就可以把他保存在磁盘或其他文档中,为未来程序启动做准备。缓存的内容没有数据结构定义,它与具体的实现方式有关。然而,缓存数据前几个字总是可以形成一个‘header’,用来验证一块数据是否有效以及哪个设备创建了它。
缓存头的布局差不多类似下面这样(注意,实际上没有该结构定义,只是为了方便理解)
typedef struct VkPipelineCacheHeader{
uint32_t length;
uint32_t version;
uint32_t vendorID;
uint32_t deviceID;
uint8_t uuid[16];
}VkPipelineCacheHeader;
虽然结构中的成员用uint32_t表示,但实际数据并不是uint32_t。缓存总是以小端模式存储,而忽略主机字节顺序是如何的。这意味着如果你想在大端模式的主机上解释这个结构,你需要颠倒这些字段的字节顺序。
length用字节数表示了头结构的长度。当前版本中,length应该是32。version字段是该结构的版本。唯一定义的版本号为1。vendorID和deviceID都和VkPhysicalDeviceProperties中的对应字段批评配。uuid是一串能够识别唯一设备的特征码。如果任一vendorID、deviceID或uuid与vulkan驱动期望的不匹配,系统可能拒绝缓存数据并将其清空 。驱动程序也可能在缓存中嵌入校验和、加密或其他数据来保证无效的缓存数据不会被加载进设备中。
如果你两个缓存对象并且想要合并他们,调用vkMergePipelineCaches,原型为:
VkResult vkMergePipelineCaches(
VkDevice device,
VkPipelineCache dstCache,
uint32_t srcCacheCount,
const VkPipelineCache* psrcCaches);
在执行之后,dstCache会包含所有源cache的条目。然后你可以通过调用vkGetPipelineCacheData来获得一个大的缓存数据,来代表所有缓存数据的条目。
这很有用,举个例子,如果在多线程中创建管线,即使访问缓存是线程安全的,但实现也可能在内部加锁,防止对多个缓存的并发写访问。如果你为每个线程都创建一个缓存对象,并在最初创建管线的时候使用他们,那么加在每个缓存对象上的锁都是无冲突的,加速对他们的访问。之后,当所有的管线创建完毕,你可将这些管线合并,保存到一个大的资源中。
当你创建完管线,并且不再需要缓存,就需要销毁他们,因为这些缓存对象还是挺大的。销毁一个缓存对象,调用vkDestroyPipelineCache
Binding Pipelines
在使用管线之前,必须将管线绑定到一个command buffer上来执行绘制或分发命令。当类似的命令被执行,当前管线(以及管线中所有的shaders)都用来处理该命令。调用vkCmdBindPipeline。
你可以想象command buffer上有许多“管线槽”,将管线绑定到对应的“槽”上可以影响对应的某些命令的行为。
Executing Work
....
Resource Access in Shaders
程序中shaders有两种方式去读取和产生数据。第一种是与固定功能硬件交互,第二种是直接从资源中读写。
我们已经了解过如何创建buffers和images。接下来我们介绍描述符集(descriptor sets)来表示shaders交互的一组资源。
Descriptor Sets
一个描述符集是绑定到管线上的一组资源。多个描述符集可以同时绑定到一个管线上。每个描述符集有一个布局,解释了集合内资源的排列顺序和类型。两个拥有同样布局的描述符集拥有兼容性并认为是可以互换的。描述符集的布局也有一个对象来表示,并且描述符集的创建也需要该布局对象。此外,那些管线能够访问的描述符集也被组合成另一个对象:管线布局。管线的创建也需要一个管线布局对象。
管线布局和描述符集布局两个对象的关系由下图表示:
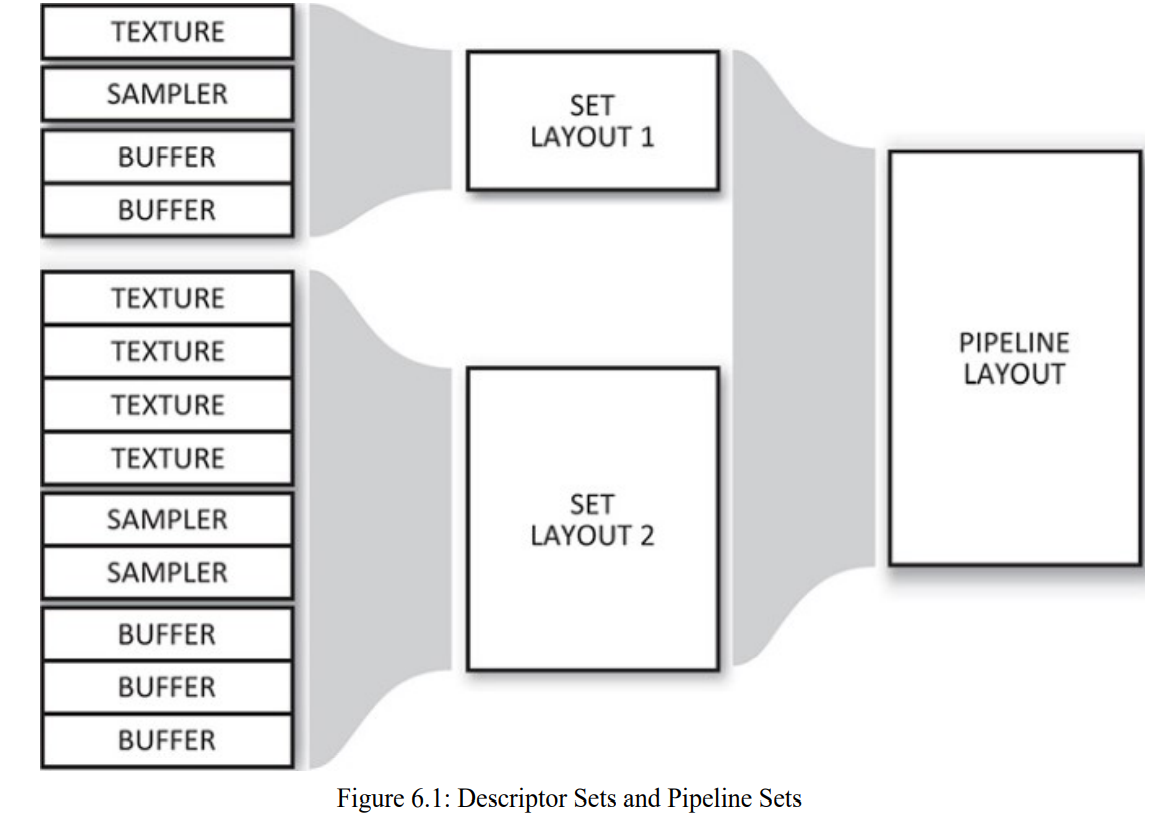
由图可知,两个描述符集都被定义好了,第一个描述符集含有一张纹理,一个采样器和两个缓存。第二个包含4张纹理,两个采样器和三个缓存。这些描述符集布局被聚合到一个管线布局对象中。一个管线就可以根据该管线布局创建出来,而每个描述符集也可以根据对应的描述符集布局进行创建。这些描述符集可以和兼容的管线一起绑定到command buffer中,允许管线访问其中的资源。
任何时候,你都可以将一个新的描述符集绑定到含有具有相同布局的管线的command buffer中。相同的描述符集布局可以用来创建多个管线。因此,如果你有一组共享相同资源的对象,但是每个对象需要一些独特的资源,那么你可以保留相同的资源,在渲染时替换那些独特的资源。
创建一个描述符集布局对象,调用vkCreateDescriptorSetLayout
VkDescriptorSetLayoutCreateInfo结构中,bindingCount和pBindings成员包含了描述符集内有多少个绑定点(可以理解为该描述符集包含多少个资源,不过每个资源都含有一个绑定点,这样shader可以根据绑定点找到该资源)以及绑定点对应的绑定资源信息。每个绑定物都有VkDescriptorSetLayoutBinding结构指出。
在VkDescriptorSetLayoutBinding中,绑定点由binding字段指出。绑定点虽然在描述符集中不一定是连续的,但是建议你不要创建稀疏的描述符集,这会造成资源浪费。
一个资源的类型由descriptorType指定,为VkDescriptorType枚举的成员:
VK_DESCRIPTOR_TYPE_SAMPLER:一个可以实现过滤和uv坐标变换的采样器。VK_DESCRIPTOR_TYPE_SAMPLED_IMAGE:一个可以和采样器结合的image资源,不可写。VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER:一个将image和采样器绑定到一起的资源对象,这会使采样操作更有效率。VK_DESCRIPTOR_TYPE_STORAGE_IMAGE:一个不能采样但是可写的image资源,与可采样image对立。VK_DESCRIPTOR_TYPE_UNIFORM_TEXEL_BUFFER:纹素buffer是一类某一个格式的数据填充的buffer,buffer不能由shader写入。buffer内容是常量可以让vulkan优化buffer资源访问。VK_DESCRIPTOR_TYPE_STORAGE_TEXEL_BUFFER:一个纹素存储buffer,拥有格式化数据但是可写。VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER&VK_DESCRIPOR_TYPE_STORAGE_BUFFER:与纹素buffer类似,但是数据没有格式,而是由shader中声明的结构赋予其意义。VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMIC&VK_DESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMIC:与buffer类似,但是包含由当描述符集绑定到管线时(而不是资源绑定到描述符集时)提供的偏移量和大小数据。这允许一个描述符集中的单个buffer进行高频更新。VK_DESCRIPTOR_TYPE_INPUT_ATTACHMENT:一个输入附件是一类特殊的图像类型,它的内容是由图形管线在同一张图像中经过前序操作生成的。
descriptorCount字段指定该binding下拥有几个资源。比如当shader出现某个结构的对象数组时,我们需要指定该字段。stageFlags指定该资源在哪一阶段的shader中使用。pImmutableSamplers是固定采样器,将采样器的地址赋值在这里时,该采样器便不能再绑定到其他描述符集中。
一个管线可以绑定多个描述符集布局。通过使用VkPipelineLayout可以将多个描述符集布局聚合到一个对象中。调用vkCreatePipelineLayout。
VkPipelineLayoutCreateInfo中 ,描述符集布局的数量由setLayoutCount指定,pSetLayout指向描述符集布局的数组。一次绑定描述符集的最大数量(也是一个管线布局中能包含的最多描述符集布局数量)至少是4。有些实现能有更高的限制。你可以通过查看VkPhysicalDeviceLimits中的maxBoundDescriptorSets查看支持的最大值。
pushConstantRangeCount和pPushConstantRanges是用来描述管线中的推送常量(push constants)的。推送常量是一类特殊的资源,能够shader直接以常量的形式使用。推送常量的更新速度极快,同时不需要同步。
当VkDescriptorSetLayout对象被创建后,所有该集合内的资源都聚合到管线布局内部并且必须符合设备限制。实际上,单个管道能够访问的资源数量和类型都有一个上限。
此外,有些设备可能不支持所有shader同时访问管线上的资源,因此,每个shader可访问资源数量有一个上限。
每个限制都可以通过VkPhysicalDeviceLimits查看,下表可查。

如果shaders或者管线需要比上图右侧保证的最小值还有多的资源,那你最好检查一下实际限制最大值是多少,并做好失败的准备。如果你的资源需求正好落再保证最小值的里面,就不需要做任何检查了。
如果两个管线的布局是兼容的,那么他们就可以使用相同的描述符集。两个兼容的管线布局有两个需求:
- 使用相同的推送常数范围。
- 使用同样顺序并且相同的描述符集布局。
如果两个管线前几个描述符集布局相同后面的不同,那么可以认为两个管线布局是部分兼容的。因此,在相同描述符集布局部分,两个管线是兼容的。
当管线绑定到command buffer,它可以使用任何在管线布局中与集合绑定兼容的描述符集。因此,两个(部分)兼容的管线在共享布局部分之间进行切换时,不需要进行重新绑定。如果你有一组全局共享的资源,比如一块每帧的常量数据,或者每个shader都可用的纹理,请把他们放在开头的描述符集中。高频更新的资源可以放在后面。
当不需要管线布局后,需要销毁。调用vkDestroyPipelineLayout。
当管线布局对象被销毁时,就不应该再次使用了。然而任何用该布局对象创建的管线依旧合法,知道管线被销毁。因此,仅仅只是为了创建管线,我们不需要一直保留布局对象。
销毁一个描述符集布局对象,调用vkDestroyDescriptorSetLayout。
描述符集布局对象被销毁,便不能再使用了。但是,任何引用该对象来创建的对象,比如描述符集,管线布局等,依旧合法。
Binding Resources to Descriptor Sets
资源用描述符(descriptors) 来指代,将他门绑定到管线上经过两个步骤,首先将他们绑定到描述符集,然后将描述符集绑定到管线上。这允许使用少量的时间就能绑定大量的资源,因为一个特定的绘图命令所使用的具体的资源可以提前指定,并预先创建持有他们的描述符集。
描述符由描述符池(descriptor pools)分配而来。因为不同类型的描述符可能拥有相似的数据结构,所以采用池分配可以让驱动程序高效利用内存。使用vkCreateDescriptorPool创建描述符池。
VkDescriptorPoolCreateInfo中,flags字段用来传递有关分配策略的额外信息,唯一的值为VK_DESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SET_BIT,表明应用程序可能释放池中分配的描述符,所以分配器应该做好准备。如果你不打算将描述符返还给池,设置为0。
maxSets字段指定了池可能分配的描述符的最大数量。pooSizeCount和pPoolSize指定了描述符集中可能含有的每种描述符数量。pPoolSize指向VkDescriptorPoolSize结构,每个结构指定了特定类型在池中可能分配的描述符数量。
在VkDescriptorPoolSize中,type字段指定了资源类型,descriptorCount指定了池中存储的该类型的描述符数量。如果pPoolSize中没有元素指定资源类型,那么便不能从池中分配没有指定资源类型的描述符。如果某种类型在数组中出现两次,那么池中能分配的数量为二者之和。池中资源的总数被分配给描述符集。
成功创建池后,使用vkAllocateDescriptorSets创建新描述符集。
在VkDescriptorSetAllocateInfo中,descriptorPool指向分配用的描述符池。descriptorSetCount指定分配的描述符集数量。每个描述符集的布局通过字段pSetLayouts传递。
接口调用成功后,会从池中消耗掉描述符集和描述符资源数量。每个描述符集消耗掉的描述符资源数量由布局决定。
如果池设定了VK_DESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SET_BIT,那么描述符集消耗的资源可能通过释放返回给池。调用vkFreeDescriptorSets。
即使没有设定,资源回收也是可以的。只要重置池就好了,调用vkResetDescriptorPool。
无论你怎么释放资源,需要注意的是你要确保释放掉的描述符集不会被引用。尤其是是任何command buffer包含的命令中可能使用即将被释放的描述符集,这类命令要么在释放之前执行完毕,要么就被丢弃而不提交。
调用vkDestroyDescriptorPool释放所有资源。当池被销毁,任何分配来的资源都会释放。
要将资源绑定到描述符集上,我们可以直接想描述符集中写入或者从其他描述符集中复制绑定资源。调用vkUpdateDescriptorSets。
接口参数中包含有关直接写入的参数和复制操作的参数。
在写入参数中,VkWriteDescriptorSet结构需要一个被写入的描述符集,由dstSet指定。资源绑定到的绑定点由dstBinding指定。如果绑定点需要一个资源数组,那么dstArrayElement指定写入的起始索引,descriptorCount指定多少连续的资源会被更新。不是数组则设置为0,descriptorCount设为1。被写入的资源类型由descriptorType指定,该字段的值将会影响接口决定下一个参数是什么。如果该字段是一个图像资源,那么pImageInfo指向一个VkDescriptorImageInfo,如果是一个buffer资源,则为VkDescriptorBufferInfo,或者是一个buffer view资源,为VkBufferView。
在VkDescriptorImageInfo中,imageView指向会被绑定到该描述符集上的图像视图。如果资源是VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,还需要在sampler处指定采样器。图像使用的图像布局由imageLayout指定。
在VkDescriptorBufferInfo中,buffer指定绑定的buffer,offset和range都是VkDeviceSize对象,指定被绑定部分的偏移量和大小。绑定范围必须包含在整个buffer中。
如果绑定的buffer是一个uniform buffer binding, range就一定要小于等于设备的maxUniformBufferRange的限制。而且,offset参数也必须是设备的uniform buffer对齐需求的整数倍,可以查看minUniformBufferOffsetAlignment。同样,如果buffer是一个storage buffer,range就必须小于等于maxStorageBufferRange,offset必须是minStorageBufferOffsetAlignment的整数倍。
除了直接向描述符集中写入的方法,还可以从一个描述符集中复制,或者在同一描述符集中的binding之间复制。参数通过VkCopyDescriptorSet结构传递。
....
Binding Descriptor Sets
如果管线一样,为了访问描述符集中的资源,需要将描述符集绑定到会执行访问到该资源命令的command buffer上。command buffer上有两个绑定点——运算和图形,对应着访问该资源的管线类型。
调用vkCmdBindDescriptorSets。
原型为:
void vkCmdBindDescriptorSets(
VkCommandBuffer commandBuffer,
VkPipelineBindPoint pipelineBindPoint,
VkPipelineLayout layout,
uint32_t firstSet,
uint32_t descriptorSetCount,
const VkDescriptorSets* pDescriptorSets,
uint32_t dynamicOffsetCount,
const uint32_t* pDynamicOffsets);
layout参数就是访问该资源的管线的管线布局。该布局需要和任何访问该资源的管线兼容,并且允许vulkan在将一个管线绑定到该command buffer前正确配置bindings。这意味绑定管线和绑定描述符集的顺序并不重要,只要在绘制或分发命令执行时,布局相匹配即可。
如果想绑定一组描述符集的子集,使用firstSet和descriptorSetCount,他们会指定起始下标和数量。
接口还负责为任何dynamic uniform或者shader storage bindings设置偏移量。dynamicOffsetCount指定需要设置的偏移量的数量,pDynamicOffsets之指向一个32位元素大小的数组。对于描述符集中需要绑定的每一个dynamic uniform或shader storage buffer, 都应该由一个偏移量数据在pDynamicOffsets中。这允许uniform和shader storage blocks重新绑定到一块大的buffer中,而不需要每次更新偏移量数据时都创建一个新的buffer view。有些实现可能需要添加一些额外的信息给shader来考虑这个偏移量,但一般来说,他仍然比创建buffer view要快。
Uniform,Texel,and Storage Buffers
shaders可以直接访问三种buffer资源:
- uniform blocks:能够快速访问常量(只读)数据。他们就像在着色器中的结构一样,使用一个buffer对象连接到内存并绑定到某个描述符集中。
- shader storage blocks:能够提供读写数据。它们与uniform blocks类似但是可写。并且提供原子操作。
- Texel buffers:能够访问长的线性的格式化数据。它们是只读的并且texel buffer在shader读取的时候会在底层进行格式转换,变为浮点表示。
究竟使用哪种资源类型取决于你想要如何访问它们。uniform block的大小通常有最大限制,所以访问它们速度很快。另一方面,shader storag block的大小要很大,但是有些实现中访问速度要慢一点,尤其是写操作。如果访问大的并且具有某种格式的数据,使用Texel buffer。
Uniform and Shader Storage Blocks
在GLSL中声明一个uniform block,使用uniform关键字。shader storage block的声明也类似,不过使用buffer关键字。
layout(set = 0, binding = 1) uniform my_uniform_buffer_t
{
float foo;
vec4 bar;
int baz[42];
} my_uniform_buffer;
layout(set = 0, binding = 2) buffer my_storage_buffer_t
{
int peas;
float carrots;
vec3 potatoes[99];
} my_storage_buffer;
block内的变量布局规则也有规则限制,uniform blocks默认遵循std140,shader storage blocks遵循std430。这些规则以它们被引入的GLSL版本命名的。可以通过指定一个不同的布局来改变数据打包的规则。对于vulkan自身来说,却不会自动给blocks中的成员赋予偏移量。该工作是由产生SPIR-V文件的前端编译器负责的。
Texel Buffers
texel buffer是shader中一类特殊的资源,可以在数据读的时候实现格式转换。Texel buffer是只读的并且在GLSL中使用samplerBuffer声明。sampler buffers可能是浮点的,有符号整数或无符号整数。
layout(set = 0, binding = 3) uniform samplerBuffer my_float_texel_buffer;
layout(set = 0, binding = 4) uniform isamplerBuffer my_signed_texel_buffer;
layout(set = 0, binding = 5) uniform usamplerBuffer my_usigned_texel_buffer;
当采样器变量能读取单个texel时,接口texelFetch能够提取Texel buffer中的数据。samplerBuffer可以当作一个仅支持点采样的1D纹理。不过,Texel buffer的大小要比真正的1D纹理大得多。vulkan中Texel buffer最小要求上限是65535个纹素,而1D纹理是4096个。
Push Constants
推送常量是shader中一个uniform变量,它可以就像一个uniform block中成员变量一样使用,不过比起后者由实际内存表示,推送常量是属于vulkan并且由vulkan负责更新的。因此,这些常量的新值可以直接从command buffer中“推入”到管线中。
推送常量逻辑上被认为管线资源的一部分,因此需要在创建管线对象时和其他资源一起通过管线布局声明它们。在VkPipelineLayoutCreateInfo中,有两个字段定义了多少个推送常量存在在管线中。推送常量有一个范围,由VkPushConstantRange结构定义,其中管线创建结构体中的pushConstantRanges指明了推送常量范围结构信息的数量,pPushConstantRanges指向这些信息。
推送常量使用的空间被抽象成连续的内存区域,即使实际情况并非如此。在一些实现中,每个shader阶段都有属于自己的常量存储空间,于是向多个shader传递一个常数就需要进行广播并且需要消耗更多的资源。VkPushConstantRange中,stageFlags指出哪些shader能够使用推送常量,offset和size指出这些shader能够使用的推送常量空间大小。
为了能够在管线内使用推送常量,需要在shader中声明它们。在GLSL,类似的声明可以通过layout加上push_constant声明一个uniform block。
layout(push_constant) uniform my_push_constants_t
{
int bourbon;
int scotch;
int beer;
} my_push_constants;
当推送常量包含进管线中,可能会消耗一些vulkan用来跟踪管道或描述符绑定的资源,所以你应该将推送常量视为相对珍贵的资源。
更新多个推送常量的内容,调用vkCmdPushConstants,原型为:
void vkCmdPushConstants(
VkCommandBuffer commandBuffer,
VkPipelineLayout layout,
VkShaderStageFlags stageFlags,
uint32_t offset,
uint32_t size,
const void* pValues);
layout定义推送常量位置的layout。该layout必须与随后绑定的管道兼容。能够看到该次更新结果的shader由stageFlags指定。即使每个管线只有一个推送常量块可用,在某些实现中,推送常量被实现为一个每shader-stage的资源。如果stageFlags被准确设置,vulkan可能不会更新那些没有包括在内shader stage,这回带来性能提升。不过要注意:在那些不支持stages之间广播的没有花销的实现中,这些stageFlags可能会被忽略,你的shaders可能无论如何都能看到该次更新。
由于推送常量逻辑上表示为具有std430规则的布局内存,每个推送常量的内容的偏移量便都可以用std430规则计算。第一个更新的偏移量由offset表示,更新大小由size表示。
pValues指向一个uint32_t或float变量数组。offset和size二者都是必须是4的倍数以此来为这类数据类型进行正确对齐。当命令执行后,数组内容就会直接复制到std430块中。
你可以在调用vkCmdPushConstants后直接替换或释放数组中的内容。数组中内容会立刻被命令获得,并且指针内的数值不会再保留。因此,将pValues执行一个本地变量是完全可以的。
一个管线能够可用的推送常量总共的空间由VkPhysicalDeviceLimits的maxPushConstantSize决定。保证至少为128字节。大的数据结构使用uniform block,对于更新频率很高并且单个整数数据使用推送常量。
Sampled Images
当shader从图像中读取,由两种方法。其一为原始加载,即直接从图像的特殊位置读取格式化或没有格式的数据,其二为使用采样器采样图像。采样操作包括图像坐标的基础变换或再将数据返回给shader时进行平滑过滤。
一个采样器由一个采样器对象表示,与buffer和image一样需要绑定到描述符集。调用vkCreateSampler创建采样器。
一个设备能够创建的采样器具有上限,取决于实现。不过至少为4000个。不过你也可以检查maxSamplerAllocationCount。
Image Filtering
在VkSamplerCreateInfo中,magFilter和minFilter字段指定了当图像放大或缩小是采取的采样模式。一个图象是放大还是缩小取决于比较被着色的临近像素的采样坐标。如果采样坐标的斜率大于1,则缩小,否则放大。magFilter和minFilter都是VkFilter枚举之一:
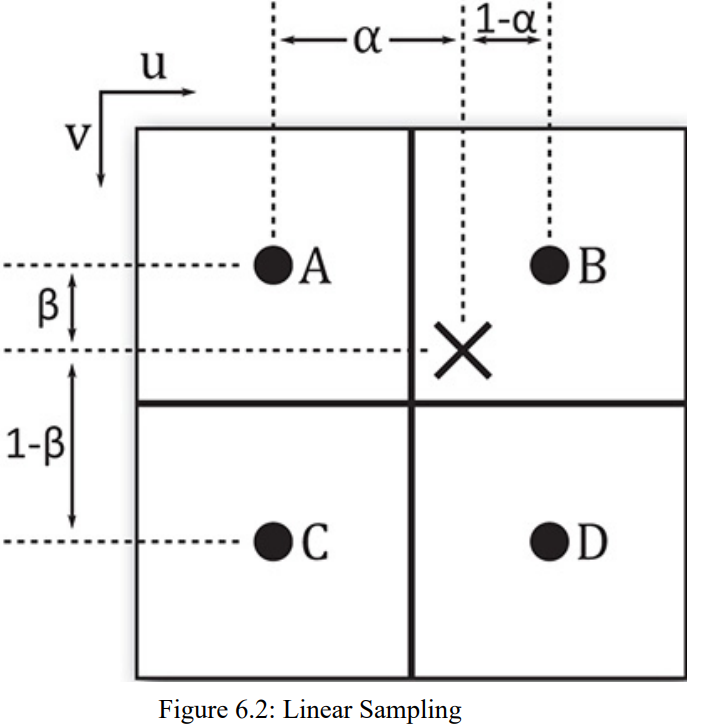
VK_FILTER_NEAREST:采样时,直接取距离最近的像素。VK_FILTER_LINEAR:平均2x2的纹素,将平均后的结果返回给shader。
VK_FILTER_NEAREST可能导致图像发生块状或失真,VK_FILTER_LINEAR则告诉vulkan使用线性过滤。线性过滤会根据采样点距离周围4个纹素的中心距离产生权重,依据该权重进行混合操作。如下图所示:
Mipmapping
结构体中mipmapMode字段指出当采样mipmap图像时使用什么采样模式。这是一个VkSamplerMipmapMode成员:
VK_SAMPLER_MIPMAP_MODE_NEAREST:整数会被向下取,然后依据该整数选择mipmap level。如果在基础level采样,将会使用magFilter指定的采样模式进行采样。否则,使用minFilter。VK_SAMPLER_MIPMAP_MODE_LINEAR:整数会在上下两层的mipmap上进行采样,采样模式使用minFilter,然后进行混合。
接下来的三个字段,addressModeU,addressModeV和addressModeW是用来选择当采样点超出纹理范围时应用到纹理坐标上的变换操作。
VK_SAMPLER_ADDRESS_MODE_REPEAT:像求余操作一样在坐标内循环。图像会无限平铺下去。VK_SAMPLER_ADDRESS_MODE_MIRRORED_REPEAT:坐标会像钟摆一样在0和1之间摆动,呈现镜像状态。VK_SAMPLER_ADDRESS_MODE_CLAMP_TO_EDGE:超出部分会直接采样到边缘。VK_SAMPLER_ADDRESS_MODE_CLAMP_TO_BORDER:超过部分会返回一个由borderColor指定的固定颜色。VK_SAMPLER_ADDRESS_MODE_MIRROR_CLAMP_TO_EDGE:这时一个混合模式,超过部分会采样到图像镜像后的边缘。
当过滤模式为VK_FILTER_LINEAR时,该模式会应用到每个生成2x2的纹理上,然后再变换到边缘。
如果过滤模式为VK_SAMPLER_ADDRESS_MODE_CLAMP_TO_BORDER,采样结果会被替换而不是从image中读取数据。结果颜色由borderColor指定,可选:
VK_BORDER_COLOR_FLOAT_TRANSPARENT_BLACK:所有通道设为浮点0。VK_BORDER_COLOR_INT_TRANSPARENT_BLACK:所有通道设为整数0.VK_BORDER_COLOR_FLOAT_OPAQUE_BLACK:RGB通道设为浮点0,A通道设为1。VK_BORDER_COLOR_INT_OPAQUE_BLACK:RGB通道设为整数0,A通道设为1。VK_BORDER_COLOR_FLOAT_OPAQUE_WHITE:所有通道设为浮点1.VK_BORDER_COLOR_INT_OPAQUE_WHITE:所有通道设为整数1。
如果你使用各向异性过滤,设置anisotropyEnable为VK_TRUE。
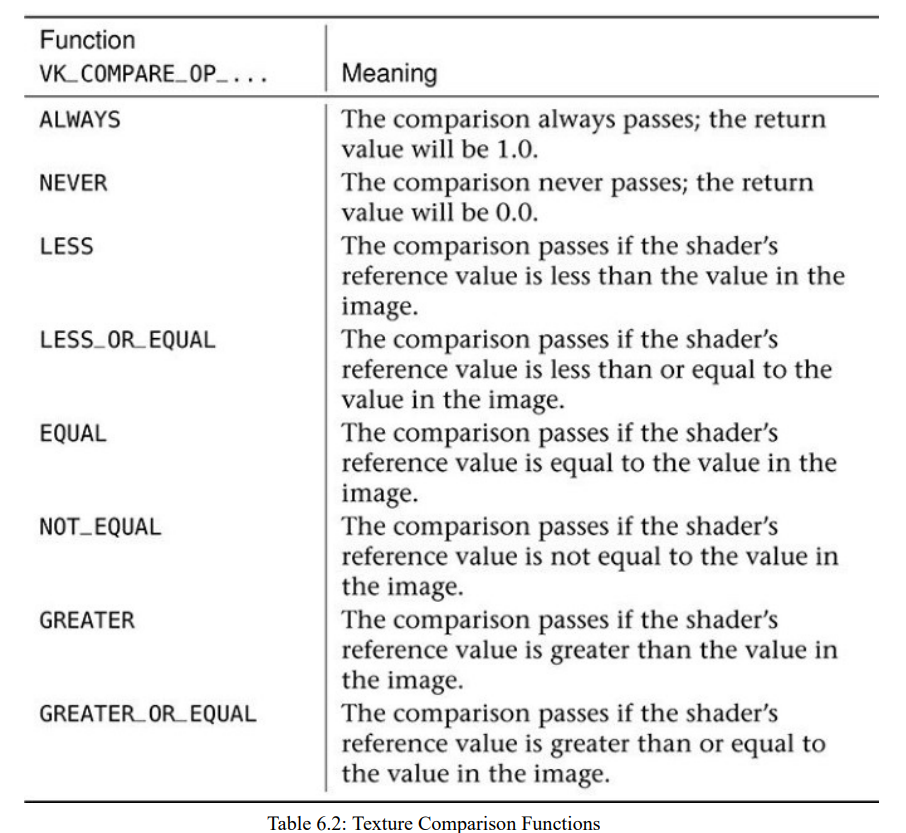
如果采样器采样的是深度图,就需要能够配置比较操作以及返回比较操作的结果。当启动这种模式后,每次采样都会进行比较操作,并且将通过测试的值写入到深度图中。该实现采用一种叫做PCF(percentage closer filtering)的技术。compareEnable设置为VK_TRUE来启用这种模式,比较操作设置在compareOp中。
采样器可以在某个mipmap的子集中。采样的mipmap范围由minLod和maxLod指定,为最低(最高分辨率)和最高(最低分辨率)的两层mipmap。如果采样整个mipmap,将minLod设置为0,maxLod需要设置到足够高,这样计算结果才不会产生clamp操作。
最后,unnormalizedCoordinates设置VK_TRUE,意为用来采样的坐标由原始像素为单位,而不是0和1。这允许显式的从image中提取纹素。然而,该模式有一些限制。当启用该字段时,magFilter和minFilter必须一致,mipmapMode必须是VK_SAMPLER_MIPMAP_MODE_NEAREST,并且anisotropyEnable和compareOp必须是VK_FALSE。
调用vkDestroySampler销毁一个采样器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号