CPPCON2014:Essential of Modern C++ Style
CPPCON2014:Essential of Modern C++ Style
这是一个back to basic系列,CPPCON中这个系列是比较值得一看的。
这个演讲讲了一些modern c++中你应该做的,或是了解的一些行为。演讲者将这个行为称为“Default”行为,即除非你有什么更好的理由,否则最好按照该规则来写代码。
内容包括:
- range-for
- smart pointer
- auto
Range-for
第一条是关于range-for的。
你最好使用
for(auto& e:c){...use(e);...}
来代替
for(auto i=begin(c);i!=end(c);++i){...use(*i);...}
关于原因,演讲者似乎没有讲太多,不过提到了几点。
如果你想只是遍历整个容器,最好使用range-for with auto&,因为auto&保证无论你的容器是只读的还是可读可写的,auto&都能展现正确的行为。
目前range-for 还不是很好的支持break,即如果你想过早的break该循环,range-for还不是很好的选择。
也许你可能想到,我们可能需要auto&&,那稍后我们会再回到这个议题。
smart pointer
可以高效地使用智能指针,但是不要放弃使用原始指针(*)以及引用(&),他们还是很棒的!
不过还是需要注意几点:
Don’t use owning *,new,or delete
请看下面的code
//c++98
widget* factory();
void caller(){
widget* w = factory();
gadget* g = new gadget();
use(*w,*g);
delete g;
delete w;
}
这种写法在以前是允许的,但是现在这样的代码基本不能通过。你不能使用owning pointers,不能显式使用new,不要使用delete。除非你在底层需要很好的性能表现,将这些东西运用在低级的数据结构上。
那现代C++你需要使用智能指针来代替以上这些东西:
//modern c++
unique_ptr<widget> factory();
void caller(){
auto w = factory();
auto g = make_unique<gadget>();
use(*w,*g);
}
所以如果你想要像new一样申请内存,请使用make_unique或者make_shared,然后对于delete,不要做任何事情。
如果你不知道你申请的对象是否需要被shared,请使用unique,因为unique总是可以将对象移到一个shared pointer组中。
这条建议有一个很重要的前提——owning,不要使用任何owning pointer。
因为Non-owning pointers/references依然很好!
//c++98
void f(widget& w){
use(w);
}
void g(widget* w){
if(w) use(*w);
}
对于参数和返回值,他们并不真正owning原始数据,只是作为参数传递进来,作为non-owning的指针和引用,请继续使用他们。因为他们的生命周期只存在于自身的scope内,不影响外部数据。当函数return的时候,一切都会恢复正常。
//mordern c++ : same as c++98
void f(widget& w){
use(w);
}
void g(widget* w){
if(w) use(*w);
}
//call
auto upw = make_unique<widget>();
f(*upw);
auto spw = make_shared<widget>();
g(spw.get());
除非你想要转移对象的ownership,那传递智能指针是完全有效的。
那我们如何传递智能指针?
假设我们有一个factory(),他生产我们需要的对象。当我们不知道该对象会被外部如何使用时,总是返回一个unique_ptr,因为无论它将要被分享出去,或是即便返回值被忽略,甚至用于自定义的一些什么事情时。unique_ptr总是很好的表现,它可以移动到shared pointer组,返回值被忽略时则立即被销毁,如果人们想要用pointer的对象是,使用get()就可以把对象抛出去。
那么我们可以这样传递指针
unique_pir<T> factory();
void consume(unique_ptr<T>);
void reseat(unique_ptr<T>&);
你可以将参数设置为pass by value,然后再调用函数处使用std::move来将ownership移动过去。这意味对象的生命周期将交给参数进行控制,当consume函数结束时,对象会被释放。这就是为什么这类函数叫做consume。它消耗掉了对象。
你也可以将参数设置为pass by reference,它不会移动ownership但是注意,它有可能改变unique pointer指向的对象,导致原来的对象被释放,新的对象会返回到调用函数中。这种行为就像unique pointer找到了一个新的位置,所以这类函数叫做reseat。
举个例子:
void operator delete(void* p){
cout<<"delete"<<endl;
free(p);
}
unique_ptr<int> factory(int num){return make_unique<int>(num);}
void consume(unique_ptr<int> owner){owner = make_unique<int>(0);}
void reseat(unique_ptr<int>& owner){owner = make_unique<int>(1);}
void caller(){
auto in = factory(3);
reseat(in);
consume(move(in));
}
可以通过重载的delete追踪查看每一个对象的生命周期是多长,在哪里被释放。
shared_ptr同理。
接下来我们再看一份代码,看看其中有什么问题?
shared_ptr<widget> g_p...
void f(widget& w){
g();
use(w);
}
void g(){
g_p = ...
}
这其中有什么问题?
如果我这样调用f(*g_p),那么再g()中,改变g_p有可能导致引用计数清零,widget对象被释放掉了。在接下来的use(w)中,我们使用了不存在的对象。
这一切的原因是,g_p掌控的对象的内存在堆上,不要解引用非本地的智能指针。
那我们怎么解决这个问题?答案是用本地指针就好了!
void my_call(){
auto local = g_p; //add new one
f(*local);
}
这样子,在我们的f()之前,增加一个变量对其引用计数+1,不论这个call tree有多深,它都不会出现问题。
所以,总结一下。
- 不要传递智能指针(不论是by value还是by reference),除非你想要使用该智能指针)
- 使用*或&,就想往常一样。
- 在整个call tree的顶端使用local的智能指针。
- 除非你想控制生命周期,你可以传递智能指针。
- 尽可能使用unique_ptr
- 如果你确定对象会被shared,使用shared_ptr
auto
使用auto感觉是遵守一种code style。
auto有一个重要的功能就是类型推导。
如果你想类型推导,使用auto。而即便你不需要类型推导,你也可以使用auto。
auto x = type{init};
使用auto有几个好处
-
正确性
也许你不确定一个函数的返回值,但是auto能保证正确性。
比如你可能认为
vector<int>::begin()的返回值是一个iterator? -
可维护性
比如
int i = f{1,2,3}*42;//ok int i = f{1,2,3}*42.0; //narrowing convertion当然,类似的例子往往出现在可隐式转换的类型上。
-
性能
类型推断保证没有隐式转换发生。
-
可用性(usability)
简单说,就是当你真的不知道一个变量是什么类型,比如在stl中非常复杂的类型名。使用auto
-
便利性
auto只有四个字母,很好。
所以,默认情况下,使用auto声明变量,但是当你需要时可以显式声明变量——但是你依然可以使用auto。
left-to-right auto style
请看下面auto形式:
auto s= "Hello";
auto w = get_widget();
auto e = employee{empid};
auto w = widget{12,34};
auto w = make_unique<widget>();
auto x = 12;
auto f = 12.f;
auto x = 42ul;
auto s = "42"s; //string
auto t = 42ns; //chrono::nanoseconds
auto f(double)->int;
using dict = set<string>;
template<typename T>
using myvec = vector<T>;
你能看到一些规律,一些c++的规律,c++似乎正在从左到右的把类型名放在右边。
当然,有一些类型不能使用“auto style”.
auto lock = lock_guard<mutex>(m); //error, not movable
auto ai = atomic<int>(); //error, not movable
auto a = array<int,20>(); //compiles, but needlessly expensive
参数传递
该议题是关于参数,我们究竟用什么方法传递参数。

列是关于你想对参数做什么操作,比如该参数是返回值(out),该参数即使输入又是输出,或是仅仅是输入,又或者不仅是输入你还想保存一个参数的副本。
行是该类型具有什么特征,它复制的开销很小或是根本不能复制,它移动的开销很小或者复制的开销处在中等水平,又或者移动的开销很大。
比如第一行。
对于参数是返回值的情况,复制的开销很小的类型推荐默认使用X f()的形式,而移动开销很大的类型推荐使用参数引用返回,或是在堆上申请内存然后再堆上返回,即f(X&)的形式。
对于即使输入还是输出的参数,我们只是用原始数据就好了,即f(X&)。
对于输入,开销小的便可以使用f(X),但对于开销较大的,使用原始数据,但是需要加上const,因为你不想编辑它。
如果你想对移动语义进行优化,完全可以。
图就变成了这个样子。

f(X&&)用于移动,推荐重载。
还有一种narrowly useful option(狭义的可用选择?)
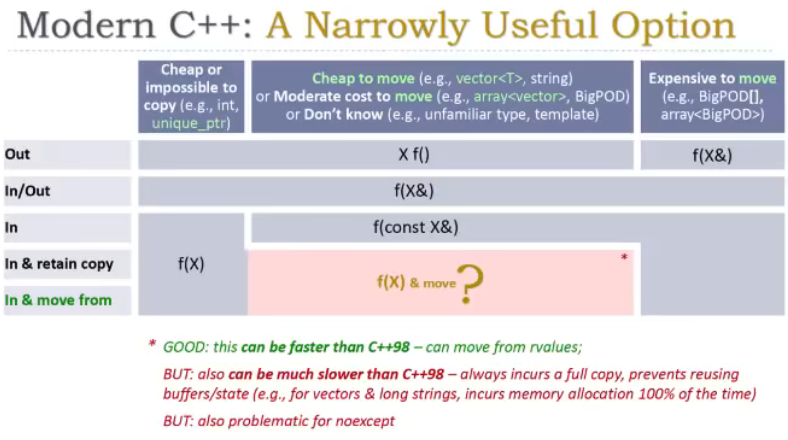
f(X)&move意思是参数pass by value但是在内部使用move。
可以看到,该情况占据了in&retain copy和in&move from两种情况,因为如果我传递了一个左值,程序会无条件地进行复制,所以内部依然保存着一个副本。如果我传递了一个右值,相当于我连续做了两次move操作,但是没关系,编译器会优化。
但是
f(X)&move也有它的缺点。
请看下面的代码
class test{
public:
void set_data(/*.....*/) {data = ...}
private:
std::string data;
};
set_data()函数的参数我们应该怎么写?
默认情况,也是推荐的情况使用const &
void set_data(const std::string& str){data = str;}
这很好,只需要一次复制就可以,如果想对右值优化,则可以重载&&
void set_data(std::string&& str){data = std::move(str);
如果我们用第三种也就是f(X)&move的形式,那么:
class test{
public:
void set_data(std::string str) {data = std::move(str);}
private:
std::string data;
};
因为参数在这会进行无条件的复制,它会导致两个问题。
- 异常:在给参数分配的内存的时候可能会抛出异常,但是因为代码内部只有一个move,理论上这个函数又是“安全的”。这个问题可难查了。
- 性能:无条件的复制会导致性能问题,比如说test对象内部的data字符串可能已经分配了足够的空间,那么对于
const&来说,虽然operator=是复制操作,但是如果是小字符串进行复制,函数不会申请新的空间。对于f(x)&move,每次进行set都会无条件新构造一个参数,这有可能导致性能问题。
所以,尽量在初始化阶段使用f(X)&move的形式,简而言之——构造函数。
class test{
public:
test(std::string str):data(std::move(str)){}
void set_data(const std::string& str){data = str;}
void set_data(std::string&& str){data = std::move(str);}
private:
std::string data;
};
因为构造函数肯定需要给成员分配空间,这几种方式没有什么差别。
还有第四个选项——完美转发。
但是一个完美的转发函数需要模板并且该函数不能是虚函数,而且非常难以理解(演讲说:Unteachable)。作为高阶的编程手段——呃,如果你真的想这么做的话——
template<class String, class = std::enable_if<!std::is_same<std::decay_t<String>,std::string>::value>>
void set_name(String&& str) noexcept(std::is_nothrow_assignalbe<std::string&,String>::value)
{
data = std::forward<String>(str);
}
Multiple returns
你可以使用tuple来让函数返回多个值。
以上,为全部内容(可能)。
不过提醒一点,该演讲是提供suggests,并不是rules,并不是非要遵守的东西。只是建议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号