Flink任务写hdfs文件卡在openforwrite状态
环境
flink-1.6.3
hadoop-2.5.0-cdh5.2.0
问题描述
2019/04/24 10:26 业务方反馈 hive某个表查询数据不全,疑似上游的Flink任务处理数据有丢失
经过定位发现上游的flink任务写 /data/BaseData/flinksql/TCFlyIntB2BTrade_flight_segment_info/2019/04/23/part-0-6 文件未被正常关闭,时隔1天后仍然处于openforwrite状态
从而影响到hive查询,导致查询结果缺失了部分数据
临时解决方案
使用hdfs recoverLease命令临时修复该文件状态
直接起因
Flink任务的JobManager所在的物理机(hadoop-080-037) 在2019/04/23 17:39:19 时间 发生4次Linux kernel 软中断。
内核日志如下:
Apr 23 17:39:19 hadoop-080-037 kernel: NMI watchdog: BUG: soft lockup - CPU#12 stuck for 22s! [java:1527146]
Apr 23 17:39:19 hadoop-080-037 kernel: Modules linked in: cfg80211 rfkill xt_nat veth ipt_MASQUERADE nf_nat_masquerade_ipv4 nf_conntrack_netlink nfnetlink iptable_nat nf_conntrack_ipv4 nf_defrag_ipv4 nf_nat_ipv4 xt_addrtype iptable_filter xt_conntrack nf_nat nf_conntrack libcrc32c overlay tcp_diag inet_diag bonding 8021q garp mrp binfmt_misc sb_edac edac_core x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel kvm irqbypass intel_cstate intel_rapl_perf iTCO_wdt iTCO_vendor_support sg hpwdt hpilo ipmi_si ipmi_devintf lpc_ich pcspkr i2c_i801 mfd_core ioatdma shpchp ipmi_msghandler pcc_cpufreq acpi_cpufreq acpi_power_meter nfsd auth_rpcgss nfs_acl lockd grace ip_tables ext4 jbd2 mbcache sd_mod crct10dif_pclmul crc32_pclmul mgag200 crc32c_intel drm_kms_helper syscopyarea sysfillrect ghash_clmulni_intel sysimgblt pcbc fb_sys_fops
Apr 23 17:39:19 hadoop-080-037 kernel: aesni_intel ttm crypto_simd glue_helper igb ixgbe cryptd serio_raw mdio dca ptp drm hpsa pps_core scsi_transport_sas i2c_algo_bit wmi sunrpc dm_mirror dm_region_hash dm_log dm_mod
Apr 23 17:39:19 hadoop-080-037 kernel: CPU: 12 PID: 1527146 Comm: java Tainted: G W 4.11.1-1.el7.elrepo.x86_64 #1
Apr 23 17:39:19 hadoop-080-037 kernel: Hardware name: HP ProLiant DL380 Gen9/ProLiant DL380 Gen9, BIOS P89 04/25/2017
Apr 23 17:39:19 hadoop-080-037 kernel: task: ffff88548b26ad00 task.stack: ffffc9005af68000
Apr 23 17:39:19 hadoop-080-037 kernel: RIP: 0010:native_queued_spin_lock_slowpath+0x17c/0x1a0
Apr 23 17:39:19 hadoop-080-037 kernel: RSP: 0000:ffff885efef03e58 EFLAGS: 00000202 ORIG_RAX: ffffffffffffff10
Apr 23 17:39:19 hadoop-080-037 kernel: RAX: 0000000000000101 RBX: ffff882ed9f59740 RCX: 0000000000000001
Apr 23 17:39:19 hadoop-080-037 kernel: RDX: 0000000000000101 RSI: 0000000000000001 RDI: ffff882ed9f597c8
Apr 23 17:39:19 hadoop-080-037 kernel: RBP: ffff885efef03e58 R08: 0000000000000101 R09: ffff885efef03ee8
Apr 23 17:39:19 hadoop-080-037 kernel: R10: 0000000000000013 R11: 0000000000000020 R12: ffff882ed9f597c8
Apr 23 17:39:19 hadoop-080-037 kernel: R13: 0000000000000100 R14: ffffffff816d44f0 R15: ffff882ed9f59740
Apr 23 17:39:19 hadoop-080-037 kernel: FS: 00007fce6f6aa700(0000) GS:ffff885efef00000(0000) knlGS:0000000000000000
Apr 23 17:39:19 hadoop-080-037 kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
Apr 23 17:39:19 hadoop-080-037 kernel: CR2: 00007fb1bcd0f140 CR3: 00000059b4e2a000 CR4: 00000000003406e0
Apr 23 17:39:19 hadoop-080-037 kernel: DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
Apr 23 17:39:19 hadoop-080-037 kernel: DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
Apr 23 17:39:19 hadoop-080-037 kernel: Call Trace:
Apr 23 17:39:19 hadoop-080-037 kernel: <IRQ>
Apr 23 17:39:19 hadoop-080-037 kernel: queued_spin_lock_slowpath+0xb/0xf
Apr 23 17:39:19 hadoop-080-037 kernel: _raw_spin_lock+0x20/0x30
Apr 23 17:39:19 hadoop-080-037 kernel: tcp_write_timer+0x1e/0x80
Apr 23 17:39:19 hadoop-080-037 kernel: call_timer_fn+0x35/0x140
Flink影响过程
1. JobManager(hadoop-080-037)
因宿主机Linux软中断引起FlinkSQL任务的JobManager的zk session timed out
继而引起Flink任务重启(JM,TM进程不重启,仅重新注册恢复DAG)
JobManager日志如下 :
[WARN ] 2019-04-23 17:39:19,323(437903235) --> [main-SendThread(172.20.76.3:17711)] org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1108): Client session timed out, have not heard from server in 129565ms for sessionid 0x263b926efdd0815
[INFO ] 2019-04-23 17:39:19,323(437903235) --> [main-SendThread(172.20.76.3:17711)] org.apache.flink.shaded.zookeeper.org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1156): Client session timed out, have not heard from server in 129565ms for sessionid 0x263b926efdd0815, closing socket connection and attempting reconnect
[INFO ] 2019-04-23 17:39:19,345(437903257) --> [flink-akka.actor.default-dispatcher-18] org.apache.flink.runtime.executiongraph.Execution.transitionState(Execution.java:1318): Sink: BucketingTableSink(messageValue, turboMQ_queueOffset, consumertime) (1/1) (1570a617dc32235d243ed47e836165fc) switched from RUNNING to FAILED.
java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id container_1550743644028_2661_03_000008 timed out.
at org.apache.flink.runtime.jobmaster.JobMaster$TaskManagerHeartbeatListener.notifyHeartbeatTimeout(JobMaster.java:1608)
at org.apache.flink.runtime.heartbeat.HeartbeatManagerImpl$HeartbeatMonitor.run(HeartbeatManagerImpl.java:339)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.flink.runtime.concurrent.akka.ActorSystemScheduledExecutorAdapter$ScheduledFutureTask.run(ActorSystemScheduledExecutorAdapter.java:154)
at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:39)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:415)
at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
[INFO ] 2019-04-23 17:39:19,347(437903259) --> [flink-akka.actor.default-dispatcher-18] org.apache.flink.runtime.executiongraph.ExecutionGraph.transitionState(ExecutionGraph.java:1356): Job Flink Streaming Job (57f29a1a027d4572823bcc59008ad42b) switched from state RUNNING to FAILING.
java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id container_1550743644028_2661_03_000008 timed out.
at org.apache.flink.runtime.jobmaster.JobMaster$TaskManagerHeartbeatListener.notifyHeartbeatTimeout(JobMaster.java:1608)
at org.apache.flink.runtime.heartbeat.HeartbeatManagerImpl$HeartbeatMonitor.run(HeartbeatManagerImpl.java:339)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.flink.runtime.concurrent.akka.ActorSystemScheduledExecutorAdapter$ScheduledFutureTask.run(ActorSystemScheduledExecutorAdapter.java:154)
at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:39)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:415)
at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
[INFO ] 2019-04-23 17:39:19,751(437903663) --> [flink-akka.actor.default-dispatcher-19] org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:820): Closing TaskExecutor connection container_1550743644028_2661_03_000008 because: ResourceManager leader changed to new address null
[INFO ] 2019-04-23 17:39:19,752(437903664) --> [flink-akka.actor.default-dispatcher-18] org.apache.flink.runtime.executiongraph.Execution.transitionState(Execution.java:1316): Source: Custom Source -> Map -> select: (messageValue, turboMQ_queueOffset, LOCALTIMESTAMP() AS LOCALTIMESTAMP) -> to: Row (1/1) (9156996c65a4f26f7f0457cfd61588f6) switched from RUNNING to CANCELING.
[INFO ] 2019-04-23 17:39:19,754(437903666) --> [flink-akka.actor.default-dispatcher-18] org.apache.flink.runtime.executiongraph.Execution.transitionState(Execution.java:1316): Source: Custom Source -> Map -> select: (messageValue, turboMQ_queueOffset, LOCALTIMESTAMP() AS LOCALTIMESTAMP) -> to: Row (1/1) (9156996c65a4f26f7f0457cfd61588f6) switched from CANCELING to CANCELED.
[INFO ] 2019-04-23 17:39:19,754(437903666) --> [flink-akka.actor.default-dispatcher-18] org.apache.flink.runtime.executiongraph.ExecutionGraph.tryRestartOrFail(ExecutionGraph.java:1479): Try to restart or fail the job Flink Streaming Job (57f29a1a027d4572823bcc59008ad42b) if no longer possible.
[INFO ] 2019-04-23 17:39:19,754(437903666) --> [flink-akka.actor.default-dispatcher-18] org.apache.flink.runtime.executiongraph.ExecutionGraph.transitionState(ExecutionGraph.java:1356): Job Flink Streaming Job (57f29a1a027d4572823bcc59008ad42b) switched from state FAILING to RESTARTING.
[INFO ] 2019-04-23 17:39:19,754(437903666) --> [flink-akka.actor.default-dispatcher-18] org.apache.flink.runtime.executiongraph.ExecutionGraph.tryRestartOrFail(ExecutionGraph.java:1487): Restarting the job Flink Streaming Job (57f29a1a027d4572823bcc59008ad42b).
[INFO ] 2019-04-23 17:39:19,755(437903667) --> [jobmanager-future-thread-20] org.apache.flink.runtime.executiongraph.ExecutionGraph.transitionState(ExecutionGraph.java:1356): Job Flink Streaming Job (57f29a1a027d4572823bcc59008ad42b) switched from state RESTARTING to CREATED.
[INFO ] 2019-04-23 17:39:19,756(437903668) --> [jobmanager-future-thread-20] org.apache.flink.runtime.checkpoint.ZooKeeperCompletedCheckpointStore.recover(ZooKeeperCompletedCheckpointStore.java:150): Recovering checkpoints from ZooKeeper.
[INFO ] 2019-04-23 17:39:19,857(437903769) --> [main-EventThread] org.apache.flink.shaded.curator.org.apache.curator.framework.state.ConnectionStateManager.postState(ConnectionStateManager.java:228): State change: SUSPENDED
[INFO ] 2019-04-23 17:39:19,857(437903769) --> [flink-akka.actor.default-dispatcher-2] org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1134): The heartbeat of TaskManager with id container_1550743644028_2661_03_000008 timed out.
2. TaskManager(hadoop-081-159)
上述步骤JM因内核软中断卡住后,导致TM在与JM RPC的过程中发现JM已经lost了
所以TM开始close 所有的operators。但是不幸运的是在关闭BucketingSink的时候,即调用BucketingSink内的close方法去关闭DFSOutputStream时候被Interrupted了。
TaskManager日志如下 :
[INFO ] 2019-04-23 17:38:05,586(437798687) --> [flink-akka.actor.default-dispatcher-2] org.apache.flink.runtime.taskmanager.Task.transitionState(Task.java:940): Sink: BucketingTableSink(messageValue, turboMQ_queueOffset, consumertime) (1/1) (1570a617dc32235d243ed47e836165fc) switched from RUNNING to FAILED.
org.apache.flink.util.FlinkException: JobManager responsible for 57f29a1a027d4572823bcc59008ad42b lost the leadership.
at org.apache.flink.runtime.taskexecutor.TaskExecutor.closeJobManagerConnection(TaskExecutor.java:1167)
at org.apache.flink.runtime.taskexecutor.TaskExecutor.access$1200(TaskExecutor.java:136)
at org.apache.flink.runtime.taskexecutor.TaskExecutor$JobLeaderListenerImpl.lambda$jobManagerLostLeadership$1(TaskExecutor.java:1508)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:332)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:158)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:142)
at akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
at akka.actor.ActorCell.invoke(ActorCell.scala:495)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
at akka.dispatch.Mailbox.run(Mailbox.scala:224)
at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: java.lang.Exception: Job leader for job id 57f29a1a027d4572823bcc59008ad42b lost leadership.
... 16 more
[INFO ] 2019-04-23 17:38:05,588(437798689) --> [flink-akka.actor.default-dispatcher-2] org.apache.flink.runtime.taskmanager.Task.cancelOrFailAndCancelInvokable(Task.java:1066): Triggering cancellation of task code Sink: BucketingTableSink(messageValue, turboMQ_queueOffset, consumertime) (1/1) (1570a617dc32235d243ed47e836165fc).
[INFO ] 2019-04-23 17:38:05,590(437798691) --> [flink-akka.actor.default-dispatcher-2] org.apache.flink.runtime.taskmanager.Task.failExternally(Task.java:1016): Attempting to fail task externally Source: Custom Source -> Map -> select: (messageValue, turboMQ_queueOffset, LOCALTIMESTAMP() AS LOCALTIMESTAMP) -> to: Row (1/1) (9156996c65a4f26f7f0457cfd61588f6).
[INFO ] 2019-04-23 17:38:05,590(437798691) --> [flink-akka.actor.default-dispatcher-2] org.apache.flink.runtime.taskmanager.Task.transitionState(Task.java:940): Source: Custom Source -> Map -> select: (messageValue, turboMQ_queueOffset, LOCALTIMESTAMP() AS LOCALTIMESTAMP) -> to: Row (1/1) (9156996c65a4f26f7f0457cfd61588f6) switched from RUNNING to FAILED.
org.apache.flink.util.FlinkException: JobManager responsible for 57f29a1a027d4572823bcc59008ad42b lost the leadership.
at org.apache.flink.runtime.taskexecutor.TaskExecutor.closeJobManagerConnection(TaskExecutor.java:1167)
at org.apache.flink.runtime.taskexecutor.TaskExecutor.access$1200(TaskExecutor.java:136)
at org.apache.flink.runtime.taskexecutor.TaskExecutor$JobLeaderListenerImpl.lambda$jobManagerLostLeadership$1(TaskExecutor.java:1508)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:332)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:158)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:142)
at akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
at akka.actor.ActorCell.invoke(ActorCell.scala:495)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
at akka.dispatch.Mailbox.run(Mailbox.scala:224)
at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: java.lang.Exception: Job leader for job id 57f29a1a027d4572823bcc59008ad42b lost leadership.
... 16 more
[ERROR] 2019-04-23 17:38:05,591(437798692) --> [Sink: BucketingTableSink(messageValue, turboMQ_queueOffset, consumertime) (1/1)] org.apache.flink.streaming.runtime.tasks.StreamTask.disposeAllOperators(StreamTask.java:477): Error during disposal of stream operator.
java.io.InterruptedIOException: Interrupted while waiting for data to be acknowledged by pipeline
at org.apache.hadoop.hdfs.DFSOutputStream.waitForAckedSeqno(DFSOutputStream.java:2022)
at org.apache.hadoop.hdfs.DFSOutputStream.flushInternal(DFSOutputStream.java:2004)
at org.apache.hadoop.hdfs.DFSOutputStream.close(DFSOutputStream.java:2096)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:70)
at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:103)
at org.apache.flink.streaming.connectors.fs.StreamWriterBase.close(StreamWriterBase.java:99)
at org.apache.flink.streaming.connectors.fs.bucketing.BucketingSink.closeCurrentPartFile(BucketingSink.java:592)
at org.apache.flink.streaming.connectors.fs.bucketing.BucketingSink.close(BucketingSink.java:440)
at org.apache.flink.api.common.functions.util.FunctionUtils.closeFunction(FunctionUtils.java:43)
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.dispose(AbstractUdfStreamOperator.java:117)
at org.apache.flink.streaming.runtime.tasks.StreamTask.disposeAllOperators(StreamTask.java:473)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:374)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:712)
at java.lang.Thread.run(Thread.java:745)
[INFO ] 2019-04-23 17:38:05,591(437798692) --> [flink-akka.actor.default-dispatcher-2] org.apache.flink.runtime.taskmanager.Task.cancelOrFailAndCancelInvokable(Task.java:1066): Triggering cancellation of task code Source: Custom Source -> Map -> select: (messageValue, turboMQ_queueOffset, LOCALTIMESTAMP() AS LOCALTIMESTAMP) -> to: Row (1/1) (9156996c65a4f26f7f0457cfd61588f6).
3. Lease过程分析
因outputstream.close()时候被Interrupted导致close失败的细节:
close的时候最关键的是构造一个空的packet并将此最后一个packet在flushInternal()写到dataQueue里,并通过异步线程发送到DN,此时会线程会等待DN返回 last packet处理完成后的ack,收到ack后,客户端才真正的去关闭DataStreamer线程,并且通过RPC调用namenode.complete()方法,真正的将namenode中该文件从LeaseManager中移除,改变openforwrite状态。
当线程等待的时候被Interrupted 会导致之后complete()过程无法执行到,从而导致文件无法正常关闭,处于openforwrite状态
见下面代码:
/**
* Closes this output stream and releases any system
* resources associated with this stream.
*/
@Override
public synchronized void close() throws IOException {
if (closed) {
IOException e = lastException.getAndSet(null);
if (e == null)
return;
else
throw e;
}
try {
flushBuffer(); // flush from all upper layers
if (currentPacket != null) {
waitAndQueueCurrentPacket();
}
if (bytesCurBlock != 0) {
// send an empty packet to mark the end of the block
currentPacket = new Packet(0, 0, bytesCurBlock,
currentSeqno++, this.checksum.getChecksumSize());
currentPacket.lastPacketInBlock = true;
currentPacket.syncBlock = shouldSyncBlock;
}
flushInternal(); // flush all data to Datanodes
// get last block before destroying the streamer
ExtendedBlock lastBlock = streamer.getBlock();
closeThreads(false);
completeFile(lastBlock);
dfsClient.endFileLease(fileId);
} catch (ClosedChannelException e) {
} finally {
closed = true;
}
}
"DataStreamer for file /data/BaseData/flinksql/TCFlyIntB2BTrade_flight_segment_info/2019/04/23/tmp-part-0-6.in-progress" #107220 daemon prio=5 os_prio=0 tid=0x00007f1e7c450800 nid=0x28ab40 in Object.wait() [0x00007f1e3a4ba000]
java.lang.Thread.State: TIMED_WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:502)
- locked <0x000000073f9f2168> (a java.util.LinkedList)
前面阐述了part-0-6文件无法正常关闭,处于openforwrite状态的原因
那么NameNode的Lease Manager机制为什么没有在1小时 hard limit 之后将该文件租约recovery呢?原因是因为上次close失败导致 dfsClient.endFileLease(); 没有成功,
从而使得DFSclient中在filesBeingWritten里还保存着此文件(见如下截图),接着 LeaseRenewer线程 一直在将DFSClient的 clientName 发送给namenode 来为该文件的客户端续租。
LeaseRenewer核心逻辑见代码:
boolean renewLease() throws IOException {
if (clientRunning && !isFilesBeingWrittenEmpty()) {
try {
namenode.renewLease(clientName);
updateLastLeaseRenewal();
return true;
} catch (IOException e) {
// Abort if the lease has already expired.
final long elapsed = Time.now() - getLastLeaseRenewal();
if (elapsed > HdfsConstants.LEASE_HARDLIMIT_PERIOD) {
LOG.warn("Failed to renew lease for " + clientName + " for "
+ (elapsed/1000) + " seconds (>= hard-limit ="
+ (HdfsConstants.LEASE_HARDLIMIT_PERIOD/1000) + " seconds.) "
+ "Closing all files being written ...", e);
closeAllFilesBeingWritten(true);
} else {
// Let the lease renewer handle it and retry.
throw e;
}
}
}
return false;
}
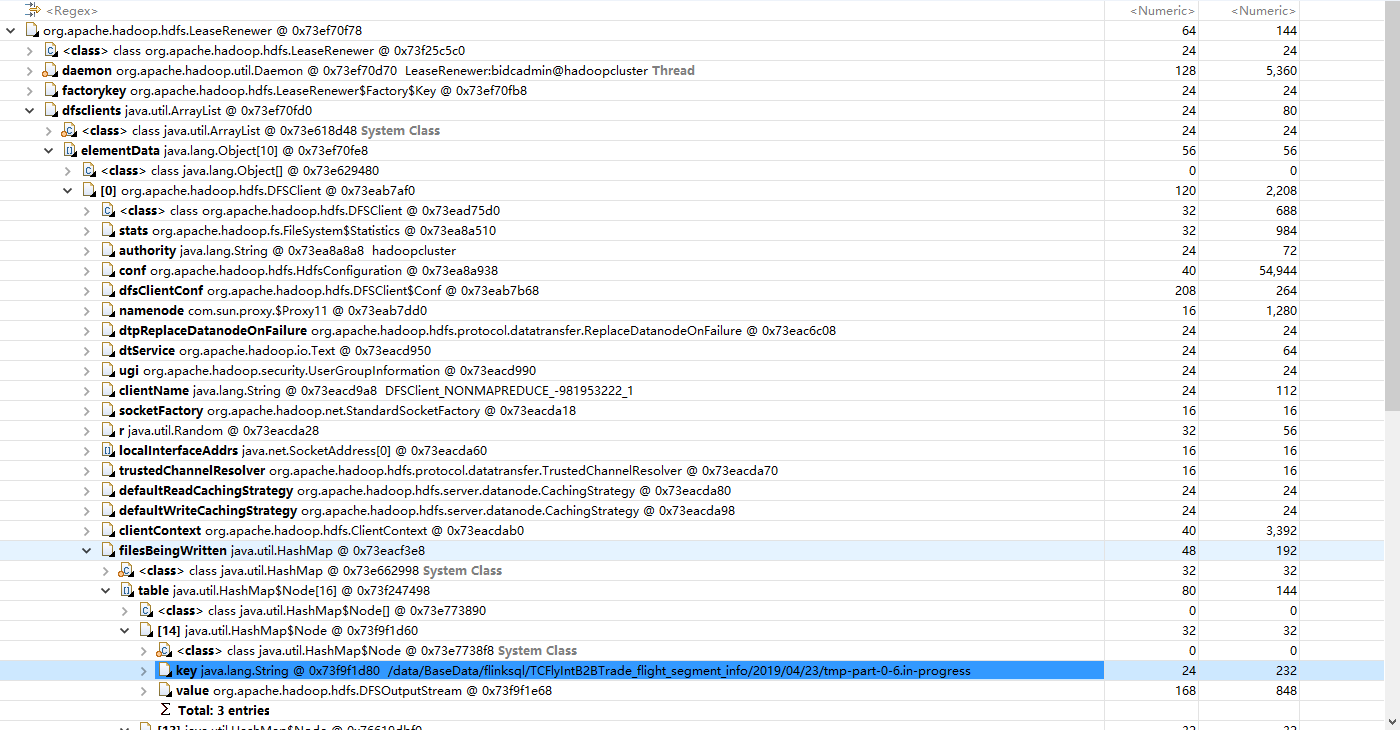
NameNode接收到client发送过来的 client名称作为holder 来续租的核心逻辑如下,如果Client能查询到Lease,则更新Lease里的lastUpdate时间,完成续租,如查询不到,直接结束。
synchronized void renewLease(String holder) {
renewLease(getLease(holder));
}
synchronized void renewLease(Lease lease) {
if (lease != null) {
sortedLeases.remove(lease);
lease.renew();
sortedLeases.add(lease);
}
}
Lease是一对多的关系,一个client name作为holder可以对应多个文件
class Lease implements Comparable<Lease> {
private final String holder;
private long lastUpdate;
private final Collection<String> paths = new TreeSet<String>();
...
}
另外,为什么出问题时候文件名称已经改变为part-0-6 而上述过程中文件名称依然为tmp-part-0-6.in-progress?
因为,TM重新恢复任务的时候使用checkpoint恢复任务(见截图),而checkpoint恢复任务的时候有一个逻辑是把重启前TM正在写的文件名称等信息保存在state中,在state restore的时候会将重启的时候正在写入的文件重命名,去掉前后缀,并且另外生成valid-length文件(这样做的目的是为了后续在读取数据文件时需要先读取这个记录了该文件有效长度的文件以确保数据的有效性,否则可能读取到重复的数据,通过这种方式在sink来保证exactly-once语义)
private void handlePendingInProgressFile(String file, long validLength) {
if (file != null) {
// We were writing to a file when the last checkpoint occurred. This file can either
// be still in-progress or became a pending file at some point after the checkpoint.
// Either way, we have to truncate it back to a valid state (or write a .valid-length
// file that specifies up to which length it is valid) and rename it to the final name
// before starting a new bucket file.
Path partPath = new Path(file);
try {
Path partPendingPath = getPendingPathFor(partPath);
Path partInProgressPath = getInProgressPathFor(partPath);
if (fs.exists(partPendingPath)) {
LOG.debug("In-progress file {} has been moved to pending after checkpoint, moving to final location.", partPath);
// has been moved to pending in the mean time, rename to final location
fs.rename(partPendingPath, partPath);
} else if (fs.exists(partInProgressPath)) {
LOG.debug("In-progress file {} is still in-progress, moving to final location.", partPath);
// it was still in progress, rename to final path
fs.rename(partInProgressPath, partPath);
} else if (fs.exists(partPath)) {
LOG.debug("In-Progress file {} was already moved to final location {}.", file, partPath);
} else {
LOG.debug("In-Progress file {} was neither moved to pending nor is still in progress. Possibly, " +
"it was moved to final location by a previous snapshot restore", file);
}
重命名不会改变将租约释放吗?
重命名不会影响租约,不会释放租约。
这里来对文件做rename的只会重命名 namenode端记录的文件名称,并且会将leaseManager 里记录的文件映射同时从tmp-part-0-6.in-progress 改变为 part-0-6,改变本地的Client中缓存的文件名没有意义,因为client向namenode续租的时候只会根据clientName来续租。
// rename was successful. If any part of the renamed subtree had
// files that were being written to, update with new filename.
void unprotectedChangeLease(String src, String dst) {
assert hasWriteLock();
leaseManager.changeLease(src, dst);
}
结论
对于本次Flink任务写HDFS文件openforwrite问题
起因:是由于物理机内核软中断
主要原因:继而导致Flink JM TM 重启,但是Flink TM重启关闭资源时存在异常,导致文件关闭失败,客户端一直存在
另外:NameNode的Lease Manager工作是正常的,但是客户端一直续租,所以认为该文件不需要释放租约从而使得文件一直卡在openforwrite
解决方案
最保险的方式是Flink TM在BucketingSink close失败的时候catch InterruptedIOException,然后JVM直接退出
这样客户端肯定不存在,就无法续租,从而让NameNode一个小时后自动 Lease Recovery ,这种比较粗暴。
或者close失败的时候catch InterruptedIOException的时候用hdfs client 相应api主动释放租约,这种方式比较和谐。
后续
其实hdfs client版本是>2.8 就根本没有这个问题,因为高版本的hdfs client close文件的策略是不一样的
mailing-list
Flink邮件列表里两个关于close失败的讨论,但是没有下文了
http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Exception-in-BucketingSink-when-cancelling-Flink-job-td15856.html
http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Changing-timeout-for-cancel-command-td12601.html
想要的都拥有,得不到的都释怀。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号