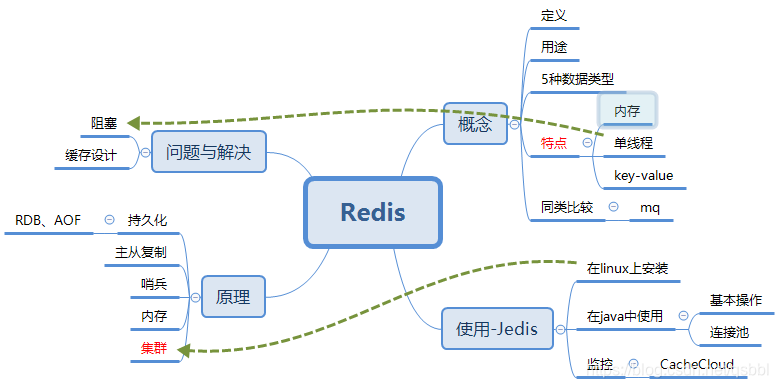
# 1.Redis入门
[说说NoSQL中的Redis](https://blog.csdn.net/qsbbl/article/details/82935416)
[【Redis】在java中的使用-存取string类型](https://blog.csdn.net/qsbbl/article/details/83651514)
[【Redis】基础问题答疑](https://blog.csdn.net/qsbbl/article/details/83652009)
[【Redis】连接池的使用](https://blog.csdn.net/qsbbl/article/details/83688327)
------
# 2.Redis的特点
## 1)5种数据结构
redis支持多种数据结构:string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)等。其中常用的是string、list。今天我们说说list的常用命令。列表类型是有序的,是可重复的,我们可以通过访问下标来获取某个元素。对其的操作和对list集合的操作的思想是一致的。
```java
// 在右边插入元素,结果为(person,a b c)
rpush person a b c
// 删除指定元素b,1代表从左到右,最多删除1个元素,此处可取的值为:
// 正数(从左到右)、负数(从右到左)、0(删除所有)
lrem person 1 b
// 获取指定元素b
lindex person 1
// 修改指定元素b为p
lset person 1 p
```
## 2)基于内存
我们知道,像mysql这些关系型数据库是将数据存储在磁盘上的,速度慢,但是稳定。
像redis这些非关系型数据库是将数据存储在内存上的,速度快,但是不稳定,服务器一宕机,内存里的数据就没了。
还好redis配置了可持久化,可将内存中的数据定期存放到磁盘上去。
因为redis是基于内存的,所以其速度快,1s可进行10万次读写。
## 3) 单线程
redis使用了单线程架构,预防了多线程可能产生的竞争问题。但也正是因为使用了单线程,其一旦发生阻塞,就将是致命的。
redis为什么选择使用单线程?redis的主要特点就是快,使用单线程能避免上下文切换等损耗。
## 4)key-value
和map集合一样,redis集合的组织方式也是key-value型的。

------
# 3.持久化
Redis是内存数据库,如果不将内存的数据库状态保存到磁盘,那么一旦服务器进程退出,数据库状态也会消失。redis提供了2种持久化的方式:RDB和AOF。持久化就是将内存里的数据同步到磁盘里,进行“持久”保存。
## RDB
RDB持久化是把当前线程数据生成快照保存到磁盘的过程。

```
优点:
1、适合大规模的数据恢复;
2、对数据完整性不高,则可以使用
缺点:
1、需要一定的实践间隔进程操作,如果redis意外宕机,最后一次修改的数据可能就没有了;
2、fork进程的时候,会占用一定的内存空间。
适用场景:
一般用于数据冷备和复制传输。
啥叫数据冷热备?热备指为了保证服务正常运行,用两台服务器作为服务机器,一台用于实际数据库操作应用,另一台用于从前者获取数据以保持数据一致。如果当前服务器宕机,有另一台继续提供服务。
冷备是指在数据库关闭后,进行备份。
```
## AOF

AOF持久化是以独立日志的方式记录每次写命令,重启时再重新执行一遍此命令,从而恢复数据。其工作流程如下:

(1)所有的写命令会追加到aof缓冲区。
(2)aof缓冲区根据对应的策略向磁盘做同步操作。
(3)随着aof文件越来越大,需要定期对aof文件进行重写,以达到压缩的目的。
(4)当redis服务器重启时,可以加载aof文件进行数据恢复。
```
优点:
1、每一次修改都同步,文件的完整会更加好;
2、每秒同步一次,可能会丢失一秒的数据;
3、从不同步,效率最高的
缺点:
1、相对于数据文件来说,aof远远大于rdb,修复速度也比rdb慢;
2、aof运行效率也比rdb慢
```
------
# 4. 阻塞
因为redis是单线程架构,所有的读写操作都是在一条主线程中完成的,所以一旦出现阻塞,将是致命的。
## 内在原因
(1)API或数据结构使用不合理
```
// 获取最近的10条慢查询
slowlog get 10
```
(2)CPU饱和
(3)持久化相关的阻塞:fork阻塞、aof刷盘阻塞、hugepage写操作阻塞
## 外在原因
(1)CPU竞争
(2)内存交换
(3)网络问题:连接拒绝、网络延迟、网卡软中断
## 解决措施
(1)在应用方加入异常监控,并要定位到具体的出问题的结点
(2)Redis的监控
------
# 5.缓存相关
## 更新策略
redis中的数据通常都是有生命周期的,需要在特定时间后被删除或更新,这样可以保证缓存空间在一个可控的范围。有3种缓存更新策略。
(1)LRU/LFU/FIFO算法剔除
当缓存使用量超过了预设的最大值时,会启动策略对数据进行清除。
```
LRU:最近最久未使用
LFU:最近最少使用
FIFO:先进先出
```
(2)超时剔除
在将数据放入缓存时,已经设置了过期时间,当到时间后,自动将其删除。使用命令expire来实现。
(3)主动更新
对数据进行“增删改”操作后,立即清除redis中的相关数据
## 缓存穿透
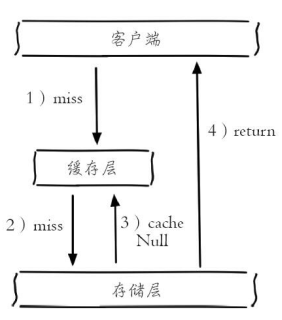
### 1、概念
缓存穿透是指查询一个数据库不存在的数据,每次都去查询数据库,而每次查询都是空,每次又都不会进行缓存。假如有大量请求进来,可能会压垮数据库。
### 2、产生的原因
(1)自身业务代码或者数据出现问题
(2)一些恶意攻击,爬虫等造成大量空命中
### 3、解决措施
(1)缓存空对象
当数据库不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据,将会从缓存中获取,这样就保护了后端数据源。
```java
String get(String key){
//从缓存中获取数据
String cacheValue=cache.get(key);
//缓存为空
if(StringUtils.isBlank(cacheValue)){
//从存储中获取
String storageValue=storage.get(key);
cache.set(key,storageValue);
//如果存储数据为空,需要设置一个过期时间(300秒)
if(storageValue==null){
cache.expire(key,60*5);
}
return storageValue;
}else{
//缓存非空
return cacheValue;
}
}
```
此解决办法的使用场景为:数据命中不高且数据频繁变化实时性高。
(2)布隆过滤器拦截
将存在的key放入布隆过滤器中。当一个查询请求过来时,先经过此过滤器,如果此过滤器认为该数据不存在,就直接丢弃,不再继续访问缓存层和存储层。
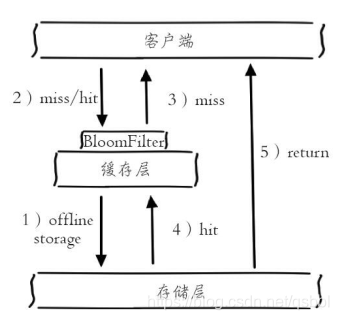
此解决办法的适用场景为:数据命中不高,数据相对固定、实时性低
## 无底洞
### 1、概念
为了满足业务需求,大量添加redis集群的节点,但是性能没提升反而下降。
### 2、产生的原因
在单机操作中,如果想批量获取多个key,只需一次网络操作即可,在集群中,节点越多,涉及的网络IO就越多,性能就可以能会下降。
### 3、解决办法
(1)串行命令
(2)串行IO
(3)并行IO
(4)hash_tag实现
## 缓存雪崩
### 1、概念
缓存雪崩是指在设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,导致所有的查询都落在数据库上,造成了缓存雪崩。
### 2、解决办法
(1)不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
(2)如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
(3)设置热点数据永远不过期。
(4)做二级缓存。
(5)在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号