
数据采集实践第四次作业
一.作业①
(要求:使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息)
1.代码与运行
(1)代码展示:
import json
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 初始化数据库连接
db = pymysql.connect(
host="localhost",
user="root",
password="root",
database="hh",
charset="utf8mb4"
)
cursor = db.cursor()
# 配置Selenium
chrome_options = Options()
# chrome_options.add_argument("--headless") # 无界面模式
driver = webdriver.Chrome(options=chrome_options)
# API URLs
urls = {
"沪深A股": "http://75.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408402776409352335_1731396358714&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1731396358718",
"上证A股": "http://75.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408402776409352335_1731396358714&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1731396358729",
"深证A股": "http://75.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408402776409352335_1731396358714&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1731396358743"
}
# 从API获取数据
def fetch_data(url):
driver.get(url)
# 等待页面加载并确保数据已经渲染
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.TAG_NAME, "body"))
)
page_source = driver.page_source
# 提取出JSONP响应的JSON数据部分
json_str = page_source.split("(", 1)[1].rsplit(")", 1)[0]
data = json.loads(json_str)
return data["data"]["diff"]
# 数据存储到数据库
def save_to_database(data):
sql = """
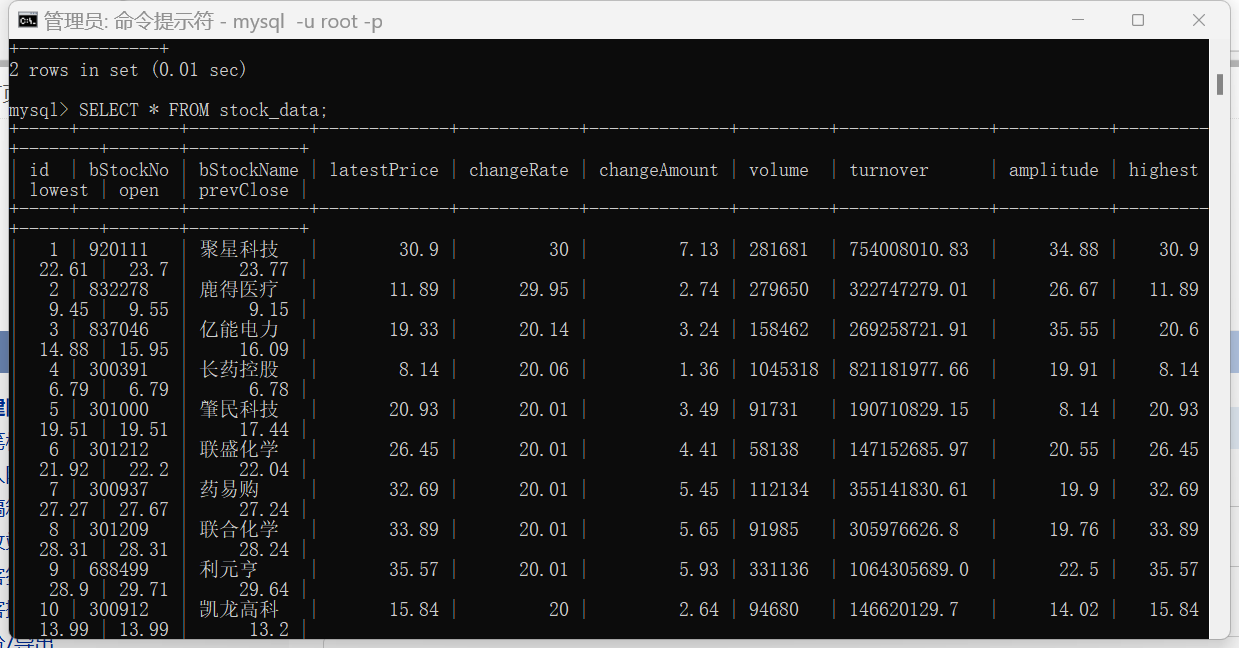
INSERT INTO stock_data (bStockNo, bStockName, latestPrice, changeRate, changeAmount,
volume, turnover, amplitude, highest, lowest, open, prevClose)
VALUES (%(bStockNo)s, %(bStockName)s, %(latestPrice)s, %(changeRate)s, %(changeAmount)s,
%(volume)s, %(turnover)s, %(amplitude)s, %(highest)s, %(lowest)s, %(open)s, %(prevClose)s)
"""
cursor.executemany(sql, data)
db.commit()
# 数据处理与清洗
def process_data(raw_data):
stock_data = []
for item in raw_data:
stock_info = {
"bStockNo": item["f12"],
"bStockName": item["f14"],
"latestPrice": float(item["f2"]),
"changeRate": float(item["f3"]),
"changeAmount": float(item["f4"]),
"volume": str(item["f5"]),
"turnover": str(item["f6"]),
"amplitude": float(item["f7"]),
"highest": float(item["f15"]),
"lowest": float(item["f16"]),
"open": float(item["f17"]),
"prevClose": float(item["f18"]),
}
stock_data.append(stock_info)
return stock_data
# 获取数据并存入数据库
for name, url in urls.items():
raw_data = fetch_data(url)
cleaned_data = process_data(raw_data)
save_to_database(cleaned_data)
# 关闭数据库连接
cursor.close()
db.close()
driver.quit()
(2)运行展示:
三.作业②
(要求:使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介))
1.代码与运行
(1)代码展示:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import random
import pymysql
# 配置Chrome浏览器选项
def configure_chrome_options():
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("excludeSwitches", ['enable-automation'])
chrome_options.add_argument("--start-maximized")
chrome_options.add_argument('--disable-gpu')
return chrome_options
# 初始化WebDriver
def initialize_web_driver(chrome_options):
return webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
# 创建数据库连接
def create_database_connection():
return pymysql.connect(
host='127.0.0.1',
user='root',
password='root',
database='scrapy',
charset='utf8mb4'
)
# 创建存储课程信息的表
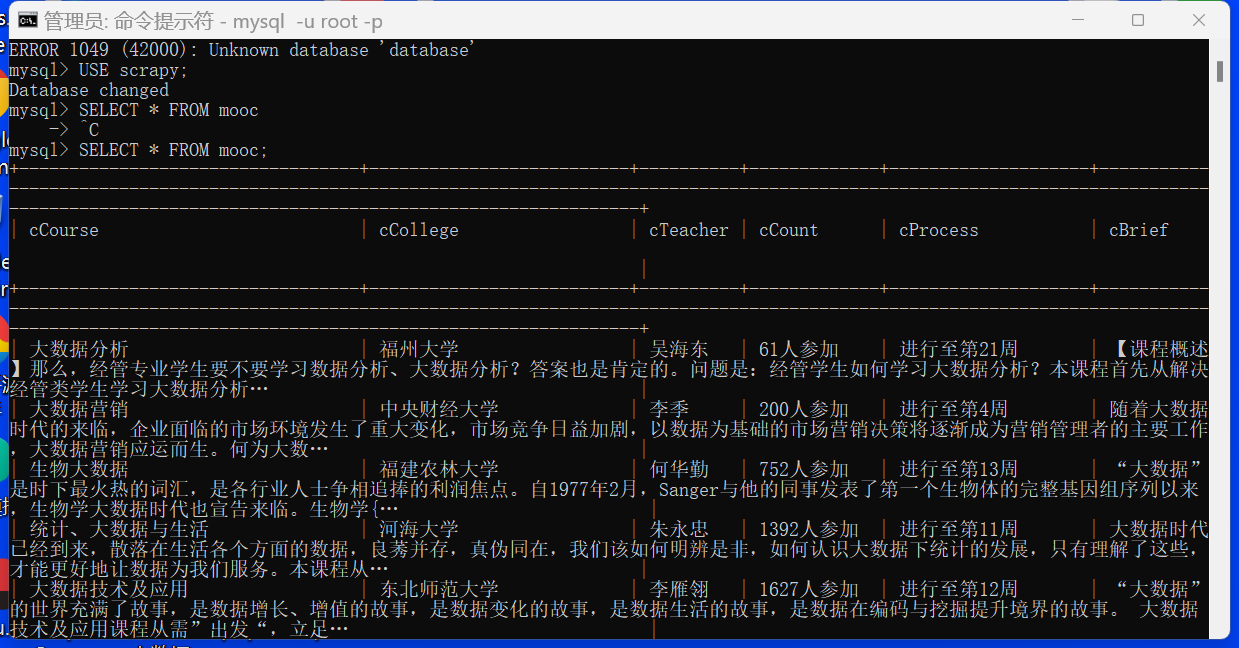
def create_course_table(cursor):
cursor.execute('''
CREATE TABLE IF NOT EXISTS course_info (
`course_name` varchar(255) DEFAULT NULL,
`college_name` varchar(255) DEFAULT NULL,
`teacher_name` varchar(255) DEFAULT NULL,
`student_count` varchar(255) DEFAULT NULL,
`course_progress` varchar(255) DEFAULT NULL,
`course_brief` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
''')
# 执行登录操作
def perform_login(driver):
try:
login_button = driver.find_element(By.XPATH, '//*[@id="j-topnav"]/div')
login_button.click()
time.sleep(3)
iframe = driver.find_element(By.XPATH,
'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(iframe)
account_input = driver.find_element(By.XPATH, '//*[@id="phoneipt"]')
password_input = driver.find_element(By.XPATH,
'//*[@id="login-form"]/div/div[4]/div[2]/input[2]')
account_input.send_keys("")#此处需要填入账号
password_input.send_keys("")#此处需要填入密码
password_input.send_keys(Keys.RETURN)
time.sleep(1)
WebDriverWait(driver, 60).until(EC.url_changes(driver.current_url))
driver.switch_to.default_content()
time.sleep(2)
except Exception as e:
print("登录失败:", e)
# 在页面中搜索指定课程
def search_course(driver, course_name):
try:
time.sleep(10)
search_box = WebDriverWait(driver, 10, 0.5).until(
EC.element_to_be_clickable((By.XPATH, '//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[1]/div/div[1]/div[1]/span/input'))
)
except TimeoutException:
print("搜索框在预期时间内未出现")
search_box.send_keys(course_name)
search_box.send_keys(Keys.RETURN)
time.sleep(5)
# 模拟滚动页面以加载更多内容
def simulate_page_scroll(driver):
page_height = driver.execute_script("return document.body.scrollHeight")
scroll_step = 5
scroll_delay = 5
current_position = 0
while current_position < page_height:
next_position = current_position + scroll_step
driver.execute_script(f"window.scrollTo(0, {next_position});")
driver.implicitly_wait(scroll_delay)
current_position = next_position
# 爬取课程信息并存储到数据库
def fetch_course_info(driver, cursor, page_count):
driver.implicitly_wait(5)
simulate_page_scroll(driver)
time.sleep(random.randint(3, 5))
course_elements = driver.find_elements(By.XPATH,
'/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[1]/div/div/div')
print(len(course_elements))
for course_element in course_elements:
course_name = get_text_from_element(course_element, './div[2]/div/div/div[1]/a[1]/span')
college_name = get_text_from_element(course_element, './div[2]/div/div/div[2]/a[1]')
teacher_name = get_text_from_element(course_element, './div[2]/div/div/div[2]/a[2]')
student_count = get_text_from_element(course_element, './div[2]/div/div/div[3]/span[2]')
course_progress = get_text_from_element(course_element, './div[2]/div/div/div[3]/div/span[2]')
course_brief = get_text_from_element(course_element, './div[2]/div/div/a/span')
print(course_name, college_name, teacher_name, student_count, course_progress, course_brief)
cursor.execute(
'INSERT INTO course_info (course_name, college_name, teacher_name, student_count, course_progress, course_brief) VALUES (%s, %s, %s, %s, %s, %s)',
(course_name, college_name, teacher_name, student_count, course_progress, course_brief)
)
for i in range(page_count - 1):
try:
next_page_button = driver.find_element(By.XPATH,
'//*[@id="j-courseCardListBox"]/div[2]/ul/li[10]/a')
next_page_button.click()
driver.implicitly_wait(5)
simulate_page_scroll(driver)
time.sleep(random.randint(3, 5))
fetch_course_info(driver, cursor, 1)
except TimeoutException:
print("下一页按钮在预期时间内未出现")
break
# 从指定元素的XPath获取文本内容
def get_text_from_element(element, xpath):
elements = element.find_elements(By.XPATH, xpath)
return elements[0].text if elements else None
def main():
chrome_options = configure_chrome_options()
driver = initialize_web_driver(chrome_options)
driver.get("https://www.icourse163.org/")
connection = create_database_connection()
cursor = connection.cursor()
create_course_table(cursor)
perform_login(driver)
course_name = '大数据'
search_course(driver, course_name)
fetch_course_info(driver, cursor, 3)
time.sleep(3)
driver.quit()
cursor.close()
connection.close()
if __name__ == "__main__":
main()
(2)运行展示:
作业一,二心得体会
解决上次数据库无法连接,数据库连接插件从mysql.connector改为pymysql,避开插件和mysql版本不兼容的问题
更加熟悉了selenium编程以及webdriver和浏览器driver的工作流程,强化了对数据库基本存储的掌握
感受到了selenium相对于scrapy的区别以及使用的便捷
二.作业③
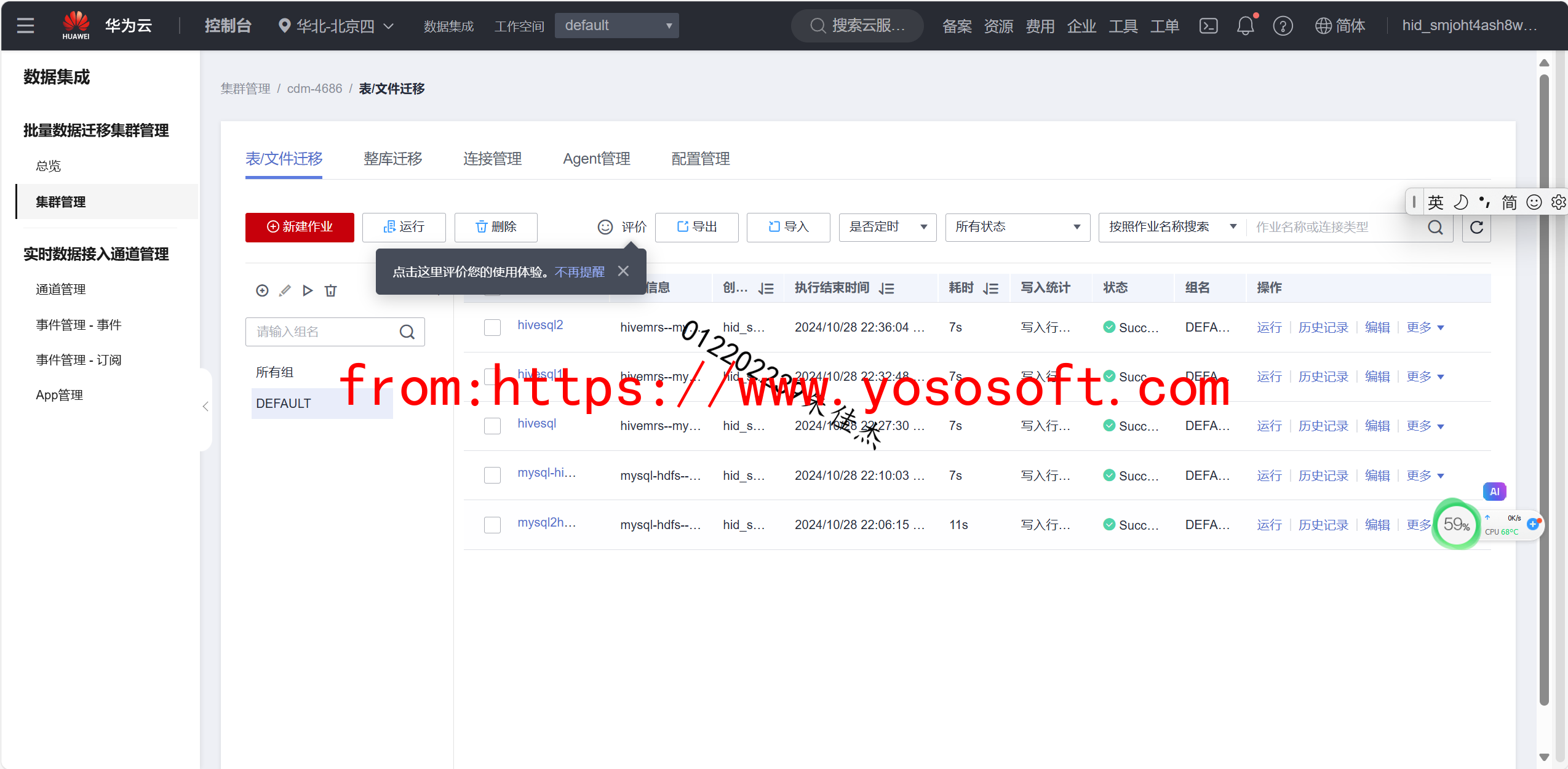
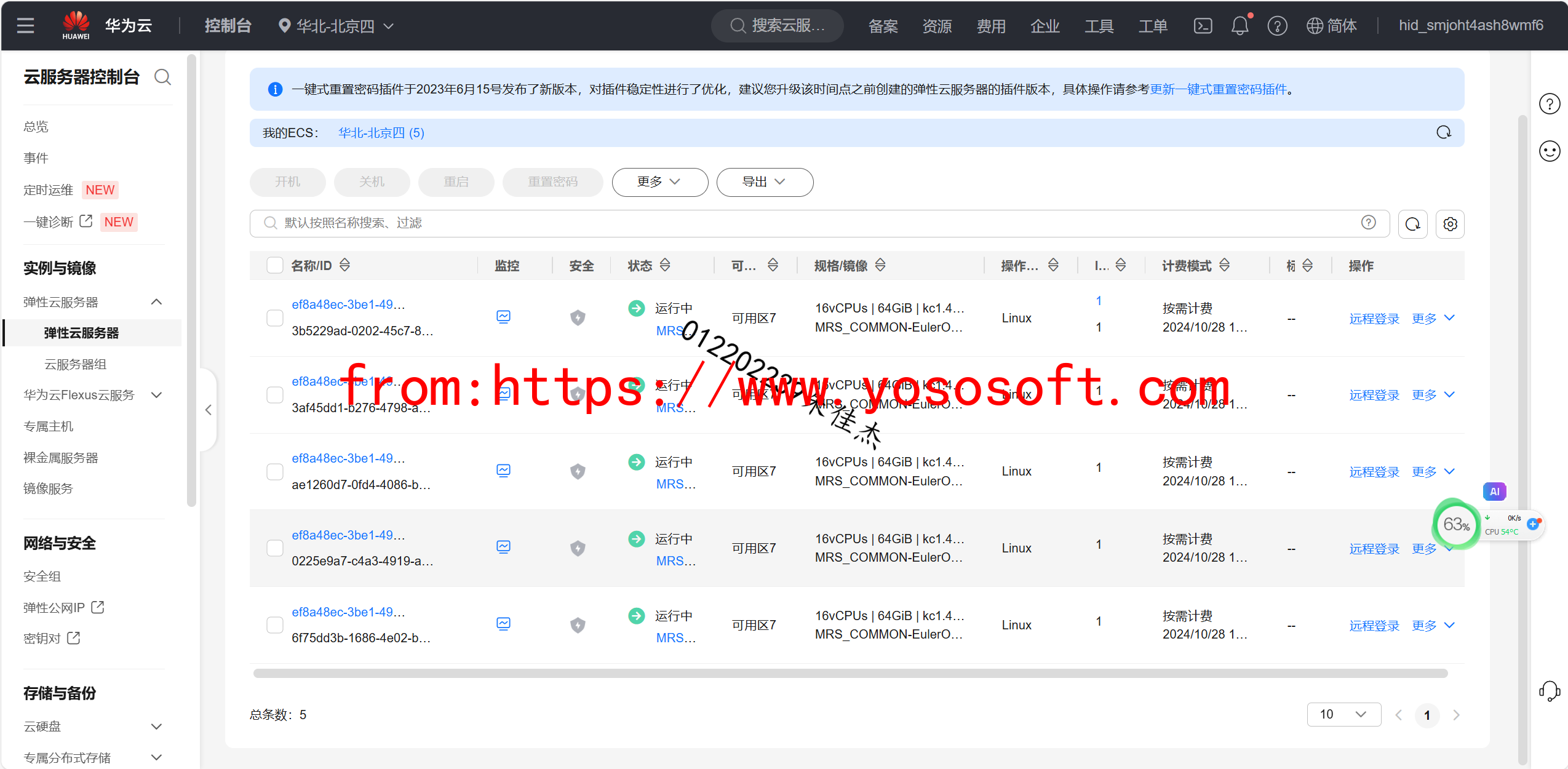
(要求:完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档)
实验关键结果截图:
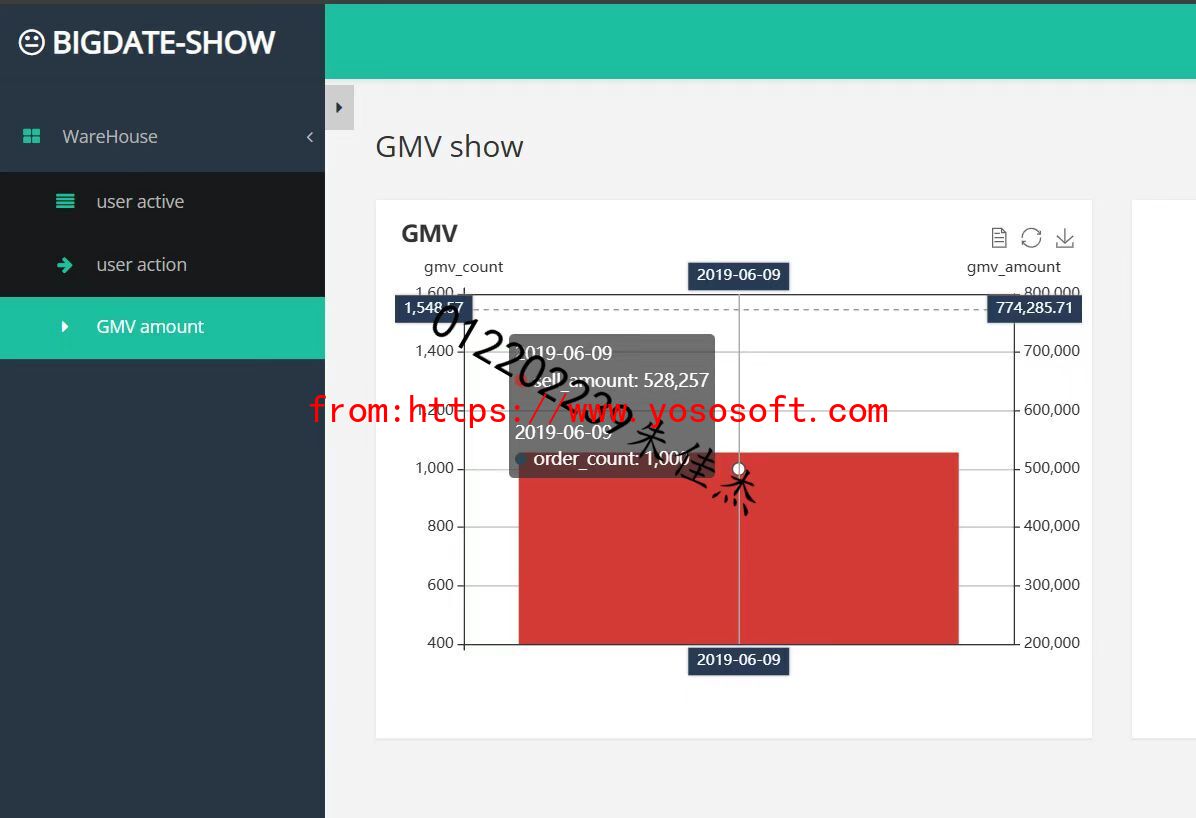
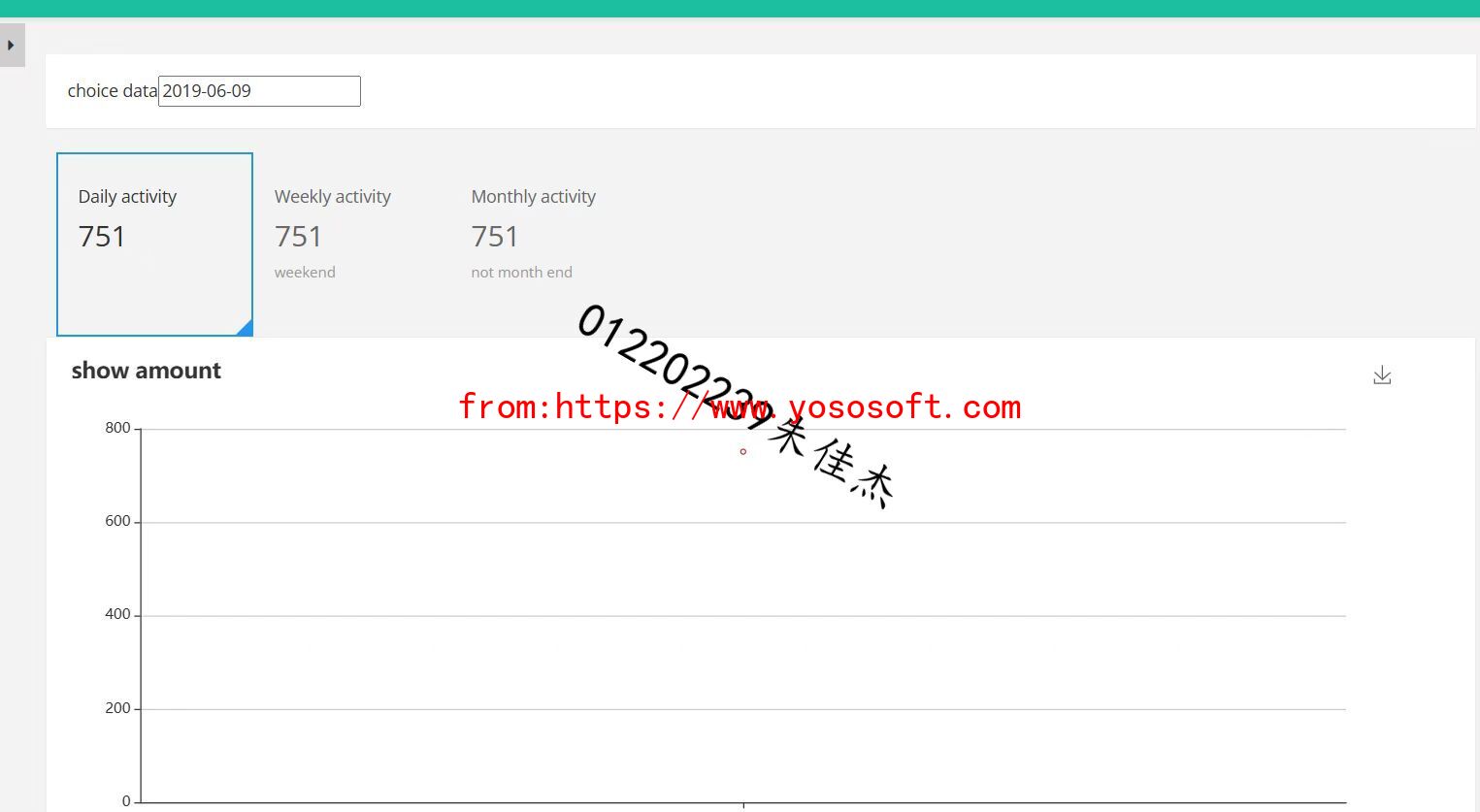
码云链接:
https://gitee.com/jia1666372886/data-collection-practice/tree/master/作业4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号