

RNN、LSTM、GRU
一、什么是循环神经网络:
循环神经网络(Rerrent Neural Network, RNN),RNN是神经网络的一种,类似的还有深度神经网络DNN,卷积神经网络CNN,生成对抗网络GAN,等等。
RNN的特点,RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,利用了RNN的这种能力,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等NLP领域的问题时有所突破。
什么是序列特性,就是符合时间顺序,逻辑顺序,或者其他顺序就叫序列特性,举几个例子:
- 拿人类的某句话来说,也就是人类的自然语言,是不是符合某个逻辑或规则的字词拼凑排列起来的,这就是符合序列特性
- 语音,我们发出的声音,每一帧每一帧的衔接起来,才凑成了我们听到的话,这也具有序列特性
- 股票,随着时间的推移,会产生具有顺序的一系列数字,这些数字也是具有序列特性
- 再比如,用户网购某个商品,在下单前的一系列浏览、关注、架构等动作也是序列化的
1 传统的RNN
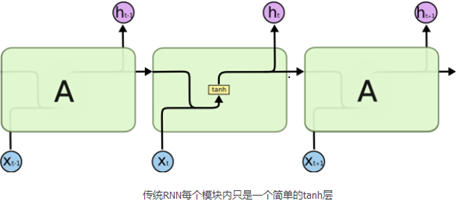
传统的RNN也即BasicRNNcell单元。内部的运算过程为,(t-1)时刻的隐层输出与w矩阵相乘,与t时刻的输入乘以u之后的值进行相加,然后经过一个非线性变化(tanh或Relu),然后以此方式传递给下一个时刻。
传统的RNN每一步的隐藏单元只是执行一个简单的tanh或者Relu操作。
在RNN里面,如果网络层次太深的话,此时会产生梯度消失或梯度下降问题。
为什么呢?首先想一个问题,RNN什么时候网络层次比较深呢?
RNN如果有多个时刻输入的时候,网络层次比较深,此时反向传播的路径比较长。反向传播是根据链式法则,如果开始的梯度小于1的话,则最后时刻的梯度几乎为0,则可理解为梯度消失;反之,若开始的梯度大于1的话,则最后时刻的梯度则非常大,可理解为梯度爆炸。这种情况下,开始应用Relu激活函数。
为什么应用Relu函数呢?
Relu函数在小于0时的梯度为0,大于0的时候梯度为1。使用Relu的好处:1 梯度容易求解;2 不会产生梯度消失或梯度爆炸。
2 LSTM(long short term memory)
优点:
可以在解决梯度消失和梯度爆炸的问题,还可以从语料中学习到长期依赖关系。
图中可以看出,t时刻有两个输出,上面代表长期输出,下面代表短期输出,用短期的输出与矩阵v运算得到t时刻的输出。
Tanh和sigmoid激活函数的优点?
首先tanh激活函数的范围是(-1,1),负的部分可以减一些信息,也即来控制忘记还是记忆信息,而sigmoid激活函数是用来表示记住多少的信息。
LSTM内部结构详解
LSTM中每个模块由4层结构。
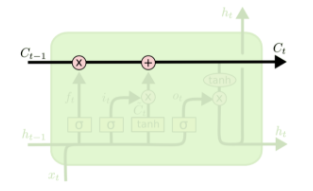
LSTM的关键是细胞状态 ,一条水平线贯穿于图形的上方,这条线上只有些少量的线性操作,信息在上面流传很容易保持。(该层是长时记忆传播)
第一层
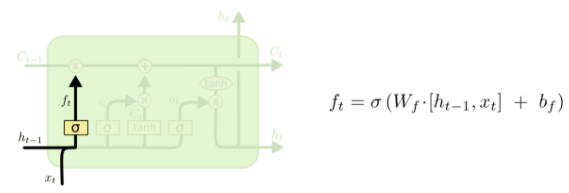
第一层是个忘记层,决定细胞状态中丢弃什么信息。把 和
拼接起来,传给一个sigmoid函数,该函数输出0到1之间的值,这个值乘到细胞状态
上去。sigmoid函数的输出值直接决定了状态信息保留多少。比如当我们要预测下一个词是什么时,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
第二层
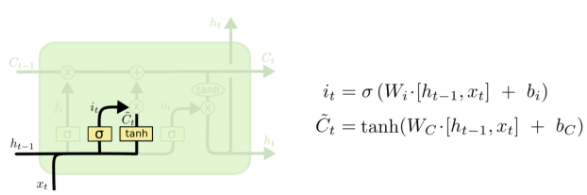
上一步的细胞状态 已经被忘记了一部分,接下来本步应该把哪些信息新加到细胞状态中呢?这里又包含2层:一个tanh层用来产生更新值的候选项
,tanh的输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱;还有一个sigmoid层(输入门层),它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的细胞状态不需要更新。在那个预测下一个词的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
第三层
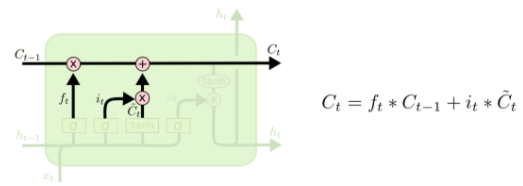
现在可以让旧的细胞状态 与
(f是forget忘记门的意思)相乘来丢弃一部分信息,然后再加个需要更新的部分
(i是input输入门的意思),这就生成了新的细胞状态
。
第四层
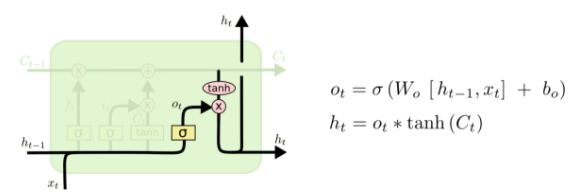
最后该决定输出什么了。输出值跟细胞状态有关,把 输给一个tanh函数得到输出值的候选项。候选项中的哪些部分最终会被输出由一个sigmoid层来决定。在那个预测下一个词的例子中,如果细胞状态告诉我们当前代词是第三人称,那我们就可以预测下一词可能是一个第三人称的动词。
3 GRU
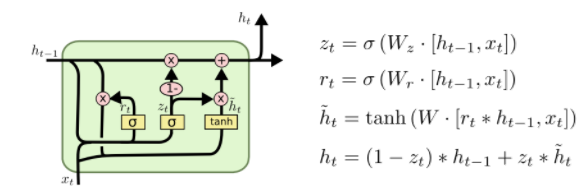
GRU(Gated Recurrent Unit)是LSTM最流行的一个变体,比LSTM模型要简单。
4 LSTM和GRU区别
1. 对memory 的控制
LSTM: 用output gate 控制,传输给下一个unit
GRU:直接传递给下一个unit,不做任何控制
2. input gate 和reset gate 作用位置不同
LSTM: 计算new memory c^(t)c^(t)时 不对上一时刻的信息做任何控制,而是用forget gate 独立的实现这一点
GRU: 计算new memory h^(t)h^(t) 时利用reset gate 对上一时刻的信息 进行控制。
3. 相似
最大的相似之处就是, 在从t 到 t-1 的更新时都引入了加法。
这个加法的好处在于能防止梯度弥散,因此LSTM和GRU都比一般的RNN效果更好。
2.RNN,LSTM,GRU的优缺点
2.1 为什么LSTM能解决RNN不能长期依赖的问题
(1)RNN的梯度消失问题导致不能“长期依赖”
RNN中的梯度消失不是指损失对参数的总梯度消失了,而是RNN中对较远时间步的梯度消失了。RNN中反向传播使用的是back propagation through time(BPTT)方法,损失loss对参数W的梯度等于loss在各时间步对w求导之和。用公式表示就是:
上式中 计算较复杂,根据复合函数求导方式连续求导。
是当前隐状态对上一隐状态求偏导。
假设某一时间步j距离t时间步相差了(t-j)时刻。则
如果t-j很大,也就是j距离t时间步很远,当 时,,会产生梯度爆炸问题,当
时,会产生梯度消失问题。而t-j很小时,也就是j是t的短期依赖,则不存在梯度消失/梯度爆炸的问题。一般会使用梯度裁剪解决梯度爆炸问题。所以主要分析梯度消失问题。
loss对时间步j的梯度值反映了时间步j对最终输出 的影响程度。就是j对最终输出
的影响程度越大,则loss对时间步j的梯度值也就越大。loss对时间步j的梯度值趋于0,就说明了j对最终输出
几乎没影响。
综上:距离时间步t较远的j的梯度会消失,说明j对最终输出 没影响。也就是说RNN中不能长期依赖。
(2)LSTM如何解决梯度消失
LSTM设计的初衷就是让当前记忆单元对上一记忆单元的偏导为常数。如在1997年最初版本的LSTM,记忆细胞更新公式为:
后来为了避免记忆细胞无线增长,引入了“遗忘门”。更新公式为:
此时连续偏导的值为:
虽然 是一个[0,1]区间的数值,不在满足当前记忆单元对上一记忆单元的偏导为常数。但通常会给遗忘门设置一个很大的偏置项,使得遗忘门在多数情况下是关闭的,只有在少数情况下开启。回顾下遗忘门的公式,这里我们加上了偏置b。
趋向于1时,遗忘门关闭,趋向于0,时,遗忘门打开。通过设置大的偏置项,使得大多数情况下遗忘门的值趋于1。也就缓解了由于小数连乘导致的梯度消失问题。
2.2 相较于LSTM,GRU的优势
GRU的参数量少,减少过拟合的风险
LSTM的参数量是Navie RNN的4倍(看公式),参数量过多就会存在过拟合的风险,GRU只使用两个门控开关,达到了和LSTM接近的结果。其参数量是Navie RNN的三倍
链接:https://zhuanlan.zhihu.com/p/149819433
链接:https://zhuanlan.zhihu.com/p/123211148
很好的讲解GRU和LSTM的文章:
GRU:https://zhuanlan.zhihu.com/p/32481747
LSTM:https://zhuanlan.zhihu.com/p/32085405

 浙公网安备 33010602011771号
浙公网安备 33010602011771号