
分享一:关于mysql中避免重复插入记录方法
一: INSERT ON DUPLICATE KEY UPDATE
如果您指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则执行旧行UPDATE
注意:
1:如果行作为新记录被插入,则受影响行的值为1;如果原有的记录被更新,则受影响行的值为2。
2:如果该表中,由多个唯一索引,需要特别注意,出现重复时则该语句只能更新其中一行记录
如:原有数据表中有数据:
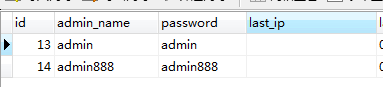
UNIQUE KEY `uk_admin_name` (`admin_name`) USING BTREE,
UNIQUE KEY `uk_password` (`password`) USING BTREE
执行:
insert into tab_admin(`admin_name`, `password`) value('admin', 'admin888') on duplicate key
update last_ip = '202.0.0.1';
结果:
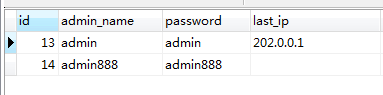
从上图可以看出:虽然admin,admin888和两行都匹配上了,但是只更新了一行数据,受影响的行: 2
至于为啥优先选择更新:admin_name这个唯一键? 原因:他会按照键的顺序来更新
结论:
1:
如果有多个唯一建存在,则这样的插入相当于:(其中a,b都是唯一键)
UPDATE table SET c=c+1 WHERE a=1 OR b=2 LIMIT 1;
如果a=1 OR b=2与多个行向匹配,则只有一个行被更新。通常,您应该尽量避免对带有多个唯一关键字的表使用ON DUPLICATE KEY子句。
2:DUPLICATE 插入多行数据
您可以在UPDATE子句中使用VALUES(col_name)函数从INSERT…UPDATE语句的INSERT部分引用列值。换句话说,如果没有发生重复关键字冲突,则UPDATE子句中的VALUES(col_name)可以引用被插入的col_name的值。本函数特别适用于多行插入。VALUES()函数只在INSERT…UPDATE语句中有意义,其它时候会返回NULL。
INSERT INTO `table` (`a`, `b`, `c`) VALUES (1, 2, 3), (4, 5, 6) ON DUPLICATE KEY UPDATE `c`=VALUES(`a`)+VALUES(`b`);
本语句与以下两个语句作用相同:
INSERT INTO `table` (`a`, `b`, `c`) VALUES (1, 2, 3) ON DUPLICATE KEY UPDATE `c`=3;
INSERT INTO `table` (`a`, `b`, `c`) VALUES (4, 5, 6) ON DUPLICATE KEY UPDATE c=9;
注释:当您使用ON DUPLICATE KEY UPDATE时,DELAYED选项被忽略。
例子:
举个例子,字段a被定义为UNIQUE,并且原数据库表table中已存在记录(2,2,9)和(3,2,1),如果插入记录的a值与原有记录重复,则更新原有记录,否则插入新行:
INSERT INTO TABLE (a,b,c) VALUES
(2,5,7),
(3,3,6),
(4,8,2)
ON DUPLICATE KEY UPDATE b=VALUES(b);

更新值的时候,像这种create_time根据数据库时间变动的,不会自动更新时间,还是最初插入的时间,需要构造数据的时候,把create_time自己加上。
变更前时间:
变更后时间:

二: REPLACE INTO
原理:插入数据时,如果发现了重复记录,则系统自动先调用了DELETE删除这条记录,然后再用INSERT来插入这条记录,影响的行数为2行,如果没有发现,则直接插入,影响的行数是1行
注意:
REPLACE和INSERT ON DUPLICATE的区别,在于REPLACE会影响多条结果。比如在表中有超过一个的唯一索引。在这种情况下,REPLACE将考虑每一个唯一索引,并对每一个索引对应的重复记录都删除,然后插入这条新记录。假设有一个table1表,有3个字段a, b, c。它们都有一个唯一索引。
CREATE TABLE table1(a INT NOT NULL UNIQUE,b INT NOT NULL UNIQUE,c INT NOT NULL UNIQUE);
假设table1中已经有了3条记录
a b c
1 1 1
2 2 2
3 3 3
下面我们使用REPLACE语句向table1中插入一条记录。
REPLACE INTO table1(a, b, c) VALUES(1,2,3);
返回的结果如下
Query OK, 4 rows affected (0.00 sec)
在table1中的记录如下
a b c
1 2 3
我们可以看到,REPLACE将原先的3条记录都删除了,然后将(1, 2, 3)插入。
三:使用ignore关键字
原理:如果是用主键primary或者唯一索引unique区分了记录的唯一性,避免重复插入记录可以使用:
INSERT IGNORE INTO `table_name` (`email`, `phone`, `user_id`) VALUES ('test9@163.com', '99999', '9999');
这样当有重复记录就会忽略,执行后返回受影响的行数为0
又如复制表:
INSERT IGNORE INTO `table_1` (`name`) SELECT `name` FROM `table_2`;
注意:ignore只提供不插入重复的记录,但是不会更新记录,replace和duplicate可以实现更新记录。
关于唯一建的注意:
1:在MYSQL中UNIQUE索引将会对null字段失效,也就是说(a字段上建立唯一索引):
INSERT INTO `test` (`a`) VALUES (NULL);
是可以重复插入的(联合唯一索引也一样)
2:
二:INSERT IGNORE
1> insert ignore into table(name) select name from table2
如:INSERT IGNORE into tab_baidu_label(uid) select `name` from tab_salary;
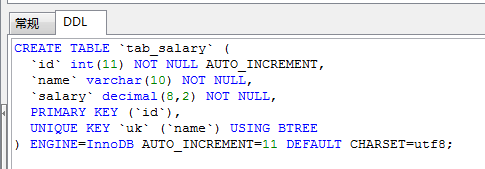
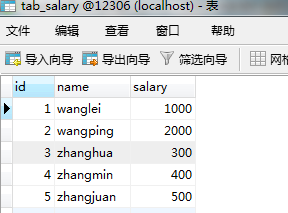
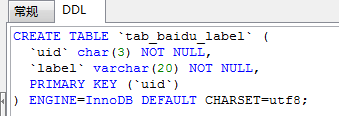
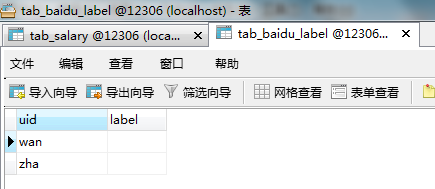
注意:如果插入表的字段长度不满足select中查询的字段长度,则字段会被截取(但是不会报错)
2> insert … select … where not exist
根据select的条件判断是否插入,可以不光通过primary 和unique来判断,也可通过其它条件。例如:
INSERT INTO books (name) SELECT 'MySQL Manual' FROM dual WHERE NOT EXISTS (SELECT id FROM books WHERE id = 1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号