【论文精读】模型驱动的遗留系统逆向工程综述
作为软件工程师,我们都曾有过这样的经历:面对一个庞大、陈旧且几乎没有任何文档的遗留代码库。它就像一座没有地图的迷宫,每一次修改都可能触发意想不到的连锁反应。在这个关键时刻,逆向工程(Reverse Engineering)——即从现有代码中提取设计和需求的过程——就成了我们唯一的指引。
H. A. Siala, K. Lano and H. Alfraihi, "Model-Driven Approaches for Reverse Engineering—A Systematic Literature Review," in IEEE Access, vol. 12, pp. 62558-62580, 2024, doi: 10.1109/ACCESS.2024.3394732.
keywords: {Reverse engineering;Unified modeling language;Software systems;Databases;Bibliographies;Systematics;Software;Application program;legacy system;model-driven reverse engineering (MDRE);model-driven re-engineering;software application},
背景
许多组织在满足新用户需求、支持新技术平台及提升质量的过程中,其软件系统会经历增长与复杂化。此时,原有的系统设计和架构已无法满足用户需求的新功能及技术创新。若未进行妥善维护与升级,这些系统可能沦为遗留系统。由于系统复杂性高、文档记录不全、对整体架构认知有限等诸多因素,遗留软件系统往往难以有效运维。因此,对任何组织而言,维护和升级这些系统都至关重要。当组织的软件系统无法满足需求时,需决定是通过升级延长其使用寿命,还是彻底重写或重构系统。通常而言,完全替换或重写遗留系统既耗时又费钱。此时,通过改进现有系统来满足新需求并延长其使用周期是更优选择。软件系统使用得越多,企业从中获得的收益就越多。
在着手维护和演进软件系统之前,必须先对其有深入理解。逆向工程通过提取反映软件系统结构与行为的不同模型和图表,在理解软件系统的各个方面中发挥着关键作用。重构工程旨在理解现有软件系统、提升其质量,并将其迁移至新技术或平台。
奇科夫斯基与克罗斯将重构工程定义为“对目标系统进行审视与改造,以重构其新形态并实施新形态”。重构工程包含三个阶段:逆向工程、重构和正向工程。逆向工程定义为:“通过分析目标系统来实现以下目标的过程:a)识别系统组件及其相互关系;b)以另一种形式或更高抽象层次创建系统表征”。在重构阶段,表征被映射到相同相对抽象层次的另一种表征形式。在此抽象层次上,软件系统的外部行为可能得以保留,同时改进内部结构(重构),或添加新功能。最后是正向工程阶段,其定义为:“从高层次抽象和逻辑独立于实现的设计转向系统物理实现的传统过程”。
下图清晰展示了逆向工程、正向工程与重构工程的核心概念。

尽管“逆向工程”与“重构工程”涉及不同技术手段,但在软件开发领域二者具有密切关联。逆向工程的核心目标是通过分析现有软件系统来理解其结构与功能,而重构工程则侧重于通过改变系统结构、行为或功能来实现改造,旨在提升系统性能、可维护性等特性。因此,在对系统进行任何改动前,逆向工程是重构工程的必要前提,它能帮助开发者透彻理解系统运作机制。
模型驱动工程(Model-driven engineering, MDE)是辅助逆向工程流程的一种方法。 MDE 提供高级抽象层,使设计者和开发人员能够通过模型来处理复杂的软件系统。这些模型对于不同的软件工程活动至关重要,包括正向工程、逆向工程和重构的三个阶段中,可以通过模型转换链来实现这些转换过程。
模型驱动的重构与模型驱动的逆向工程(Model-driven reverse engineering, MDRE)是 MDE 技术的主要应用场景,模型用于现有软件系统的表示、理解和文档化。
为通过模型集合表征软件系统,已开发出多种 MDRE 方法和工具,这些模型聚焦于软件系统的不同方面(结构与行为)。现有的 MDRE 方法可归纳为两大框架:通用与专用。通用方法可应用于不同目标的多种应用领域或技术,而专用方法则针对具有明确目标的特定领域或技术设计。
MDRE 方法可实现完全自动化,因此在逆向工程过程中无需人工干预。部分自动化 MDRE 方法中,可能需要在某个或多个步骤进行人工干预。 MDRE 技术还可分为静态、动态和混合三种类型。静态技术无需执行代码即可从源代码或二进制代码中提取信息,而动态技术则在运行时从系统中提取信息。混合技术则同时采用静态和动态技术。
讨论
模型驱动的逆向工程方法
RQ1:现有针对软件系统的模型驱动逆向工程方法有哪些?
模型驱动逆向工程方法的目标
SQ1.1:模型驱动的逆向工程方法的目标是什么?
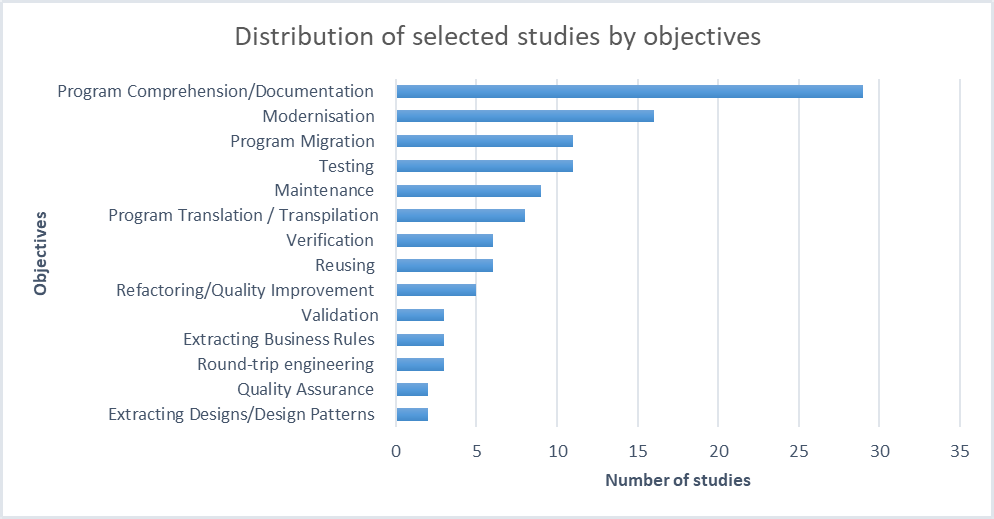
在探讨逆向工程的高级应用时,人们或许会认为软件系统现代化或平台迁移等复杂任务是其主要驱动力。然而,事实恰恰相反。在所有高级目标中,MDRE 方法最常见的首要目标是——“程序理解与文档化”(Program Comprehension/Documentation)。
数据显示,在被分析的 64 种不同的 MDRE 方法中,有高达 29 种方法将“理解与文档化”作为其核心目标。这使其成为最普遍的应用,远超软件系统现代化(16 种方法)、程序迁移(11 种方法)和程序转译(将程序从一种语言翻译成另一种语言)(8 种方法)等更复杂的任务。
这一发现与其说令人惊讶,不如说它揭示了一个根本性的真理:在对遗留系统进行任何重构、迁移或现代化改造之前,最基本、最关键的步骤是首先深入、准确地理解其现有的结构和行为。没有这一步,所有后续工作都如同建立在沙滩之上。这不仅仅是最普遍的目标,更是通往所有其他再工程项目成功的唯一入口。逆向工程的首要价值在于拨开历史代码的迷雾,为所有后续演进工作奠定坚实、不可动摇的基石。
软件测试与维护属于程序理解/文档目标之后的环节。在这些方法里,有 11 种专门用来做软件测试,还有 9 种更偏向于软件维护。其中 6 种方法的核心目标是验证软件系统;另外 6 种方则是为了实现软件系统的复用。5 种方法把重点放在了代码重构和质量优化上;只有 3 种方法的目的是对软件系统进行验证。
除此之外,有 3 种不同的方法专门用于往返工程;另外 3 种方法则聚焦在业务规则的提取上。还有 2 种方法是做设计模式提取的,另外 2 种方法以质量保证为核心目标。
这里要划个重点:在这些 MDRE 方法里,程序理解和文档编写是最核心、最重要的目标;相比之下,设计模式提取和质量保证这两项的重要性就要低一些了。
具体的统计数据如下图所示。
模型驱动逆向工程方法的特点
由于每种 MDRE 方法都具有独特的属性和特征,我们定义了一个本体论来解决次要问题 SQ1.2(模型驱动逆向工程方法的通用特征是什么?)。
该本体论基于 Cornelissen 等人建立的框架,并通过多种标准进行了细化,以全面分类所有 MDRE 方法。以下是关键分类标准:
- 来源(输入)
- 表示形式(输出)
- 范围(通用或特定)
- 自动化程度(自动化或半自动化)
- 技术类型(静态、动态或混合)
- 评估方式(通过案例研究、与其他方法对比或运行示例评估)
- 工具使用(自动生成工具、使用现有工具或两者兼用)
来源(输入)
下展示了 MDRE 方法的来源。
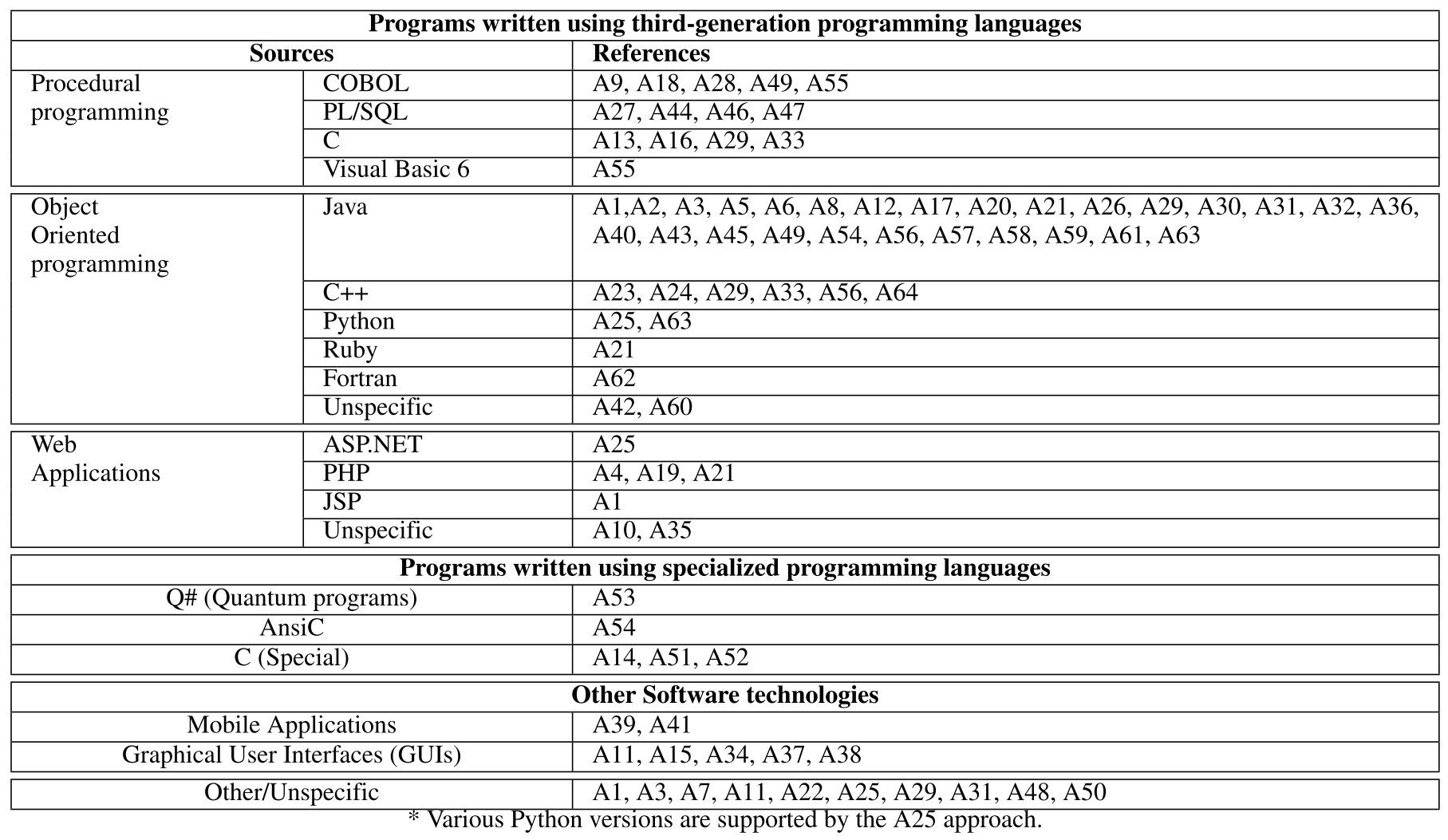
这些来源可分为三类:
- 使用第三代编程语言编写的代码(包括过程化编程语言和面向对象编程语言)以及网络应用程序
- 第二类是使用量子编程语言等专用编程语言编写的代码
- 移动应用程序和图形用户界面(GUI)则归入“其他软件技术”类别。所有不符合上述分类的来源均归为“其他”来源。
在选择逆向工程的目标语言时,学术研究显示出一种明显的偏好,揭示了“学术舒适区”与“工业主战场”之间的差异。分析发现,在所有面向对象的语言中,Java 是 MDRE 方法最青睐的目标,有多达 27 种方法明确支持对 Java 代码进行逆向工程。
相比之下,支持 C++ 的方法数量大约只有 Java 的五分之一。这种不成比例的关注度意义重大。正如该文献综述的作者所指出的:这与许多主流重构工程工作的重点——即面向过程的代码库——相反,这或许反映了模型驱动工程(MDE)研究普遍偏爱 Java 的倾向。
这一观察至关重要。虽然 Java 在现代企业应用中地位显赫,但许多最棘手、最需要逆向工程的遗留系统——那些真正困扰着企业的“硬骨头”——实际上是用COBOL、PL/SQL 等过程式语言编写的。这种学术研究重点与行业实际需求之间的潜在差距提醒我们,尽管现有工具和方法很强大,但它们可能并未完全对准那些最古老、最复杂的工业遗留问题。
表示形式(输出)
下表展示了 MDRE 方法的表示结果。
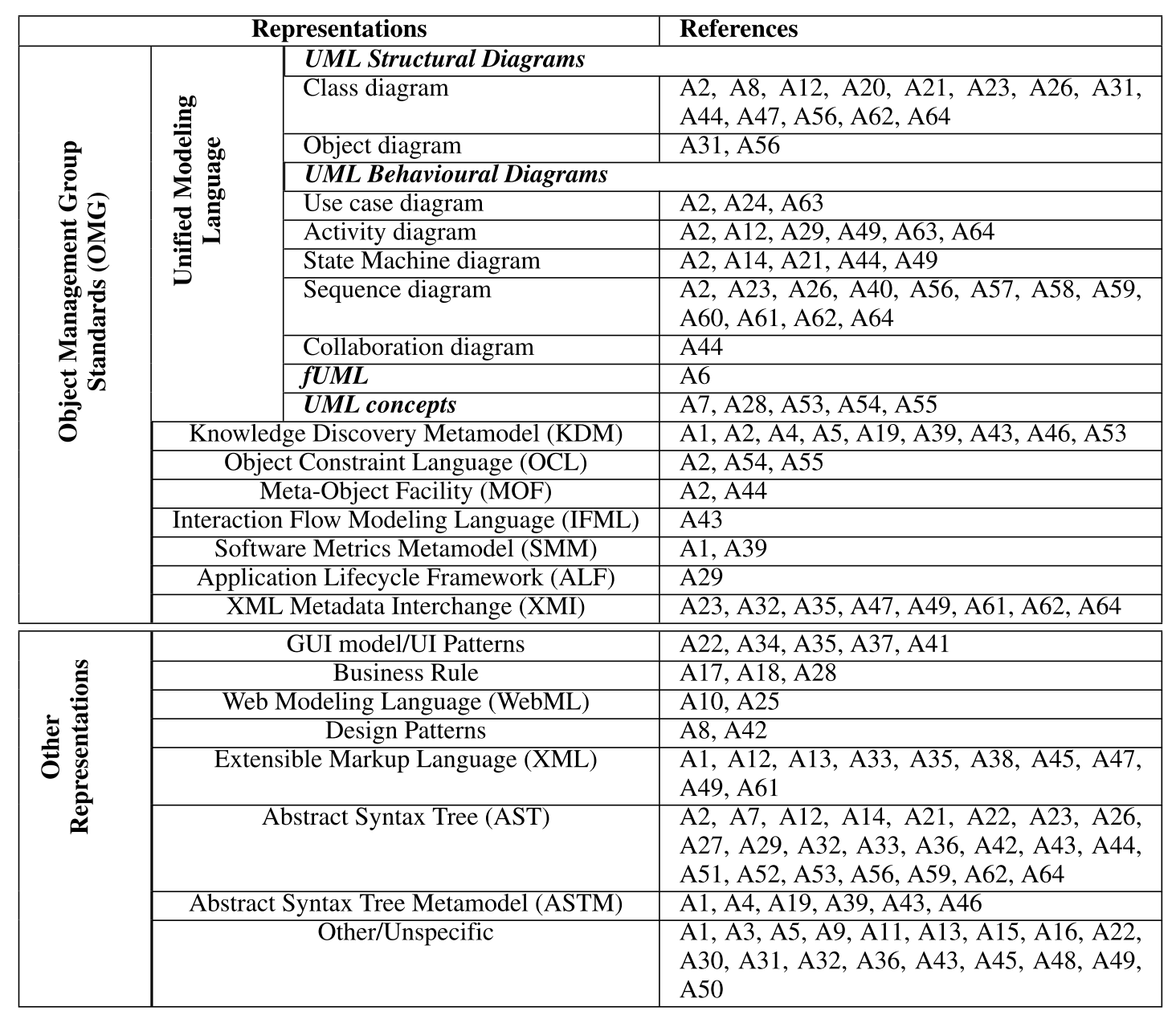
该表包含了 OMG 中的各种建模语言,以及归类于“其他/未指定”类别的其他表示方法。值得注意的是,目标表示方法中不包含元模型,但可扩展标记语言 (XML)、抽象语法树 (AST)、描述 AST 结构(元模型)的抽象语法树元模型 (ASTM) 以及 OMG 标准中的元模型除外。从 OMG 标准的角度来看,已使用了多种图表,其中 UML 是最流行的建模图,KDM 位居第二。UML 图主要分为结构图和行为图两大类。从逆向工程中提取不同类型 UML 图的方法数量差异很大。
范围(通用或特定)
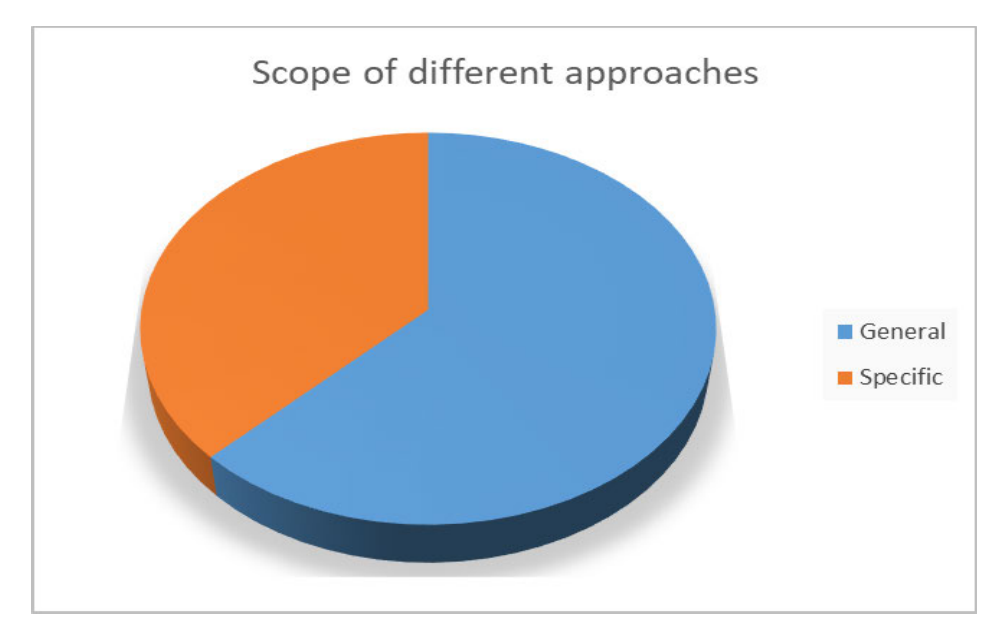
如下图所示,38% 的方案是为具有特定目标的特定系统开发的,而 62% 的方案是针对不同应用领域及不同目标开发的。
自动化程度(自动化或半自动化)
如下图所示,有超过 3/5 的方案为完全自动化,相比之下,不足 2/5 的方案需要人工干预。
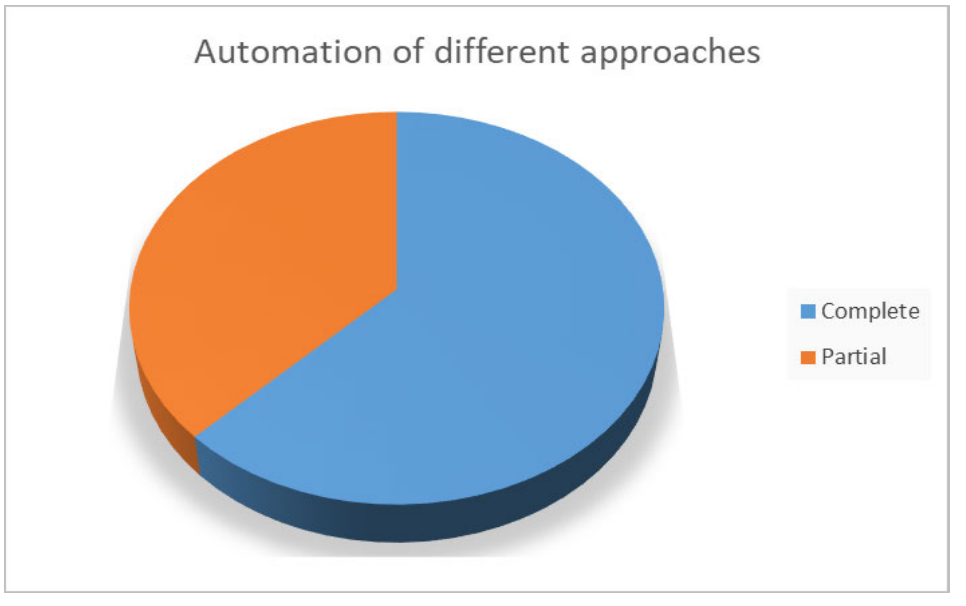
技术类型(静态、动态或混合)
逆向工程技术可以大致分为三类:
• 静态分析 (Static Analysis): 在不执行代码的情况下,通过分析源代码或二进制文件来提取信息。
• 动态分析 (Dynamic Analysis): 在系统运行时,通过监控其行为来收集信息。
• 混合分析 (Hybrid Analysis): 结合以上两种方法,取长补短。
如下图数据显示,静态分析在 MDRE 领域占据了绝对的主导地位。在 64 种方法中,有 45 种采用了静态分析技术。相比之下,只有 10 种方法采用动态分析,9 种采用混合方法。
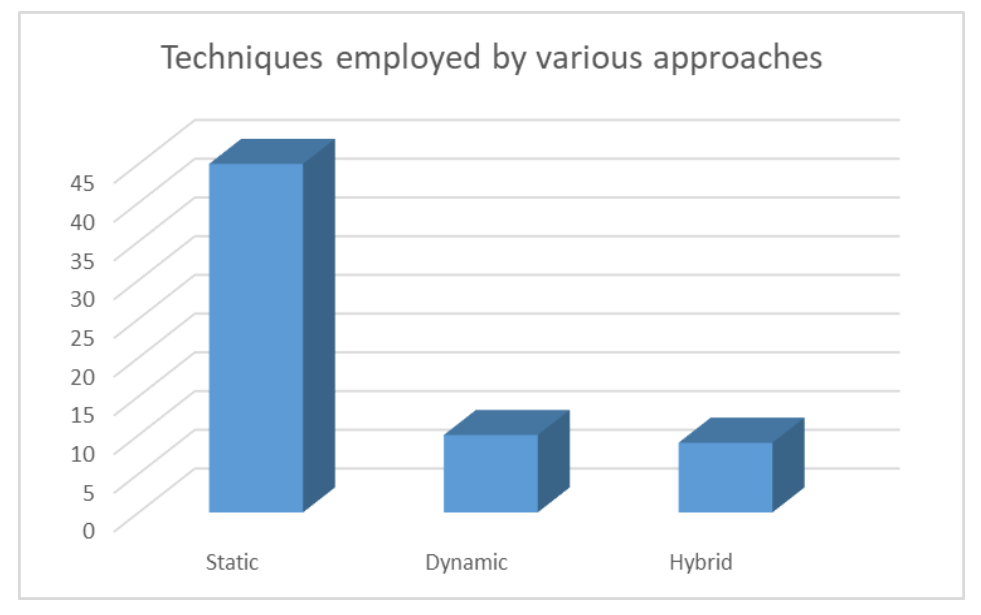
静态分析之所以如此普遍,是因为它更易于实现,并且能够提供对整个代码库的全面覆盖,而无需搭建复杂的运行环境。然而,它的局限性也正是其核心特征所决定的:它只能“猜测”程序的行为,因为它永远无法观察到代码的实际运行情况。对于正在评估逆向工程工具的工程师而言,这意味着你必须敏锐地意识到它“看不到”什么——那些往往隐藏着最复杂错误和性能瓶颈的运行时行为。这恰恰是动态分析的优势所在。
评估方式(通过案例研究、与其他方法对比或运行示例评估)
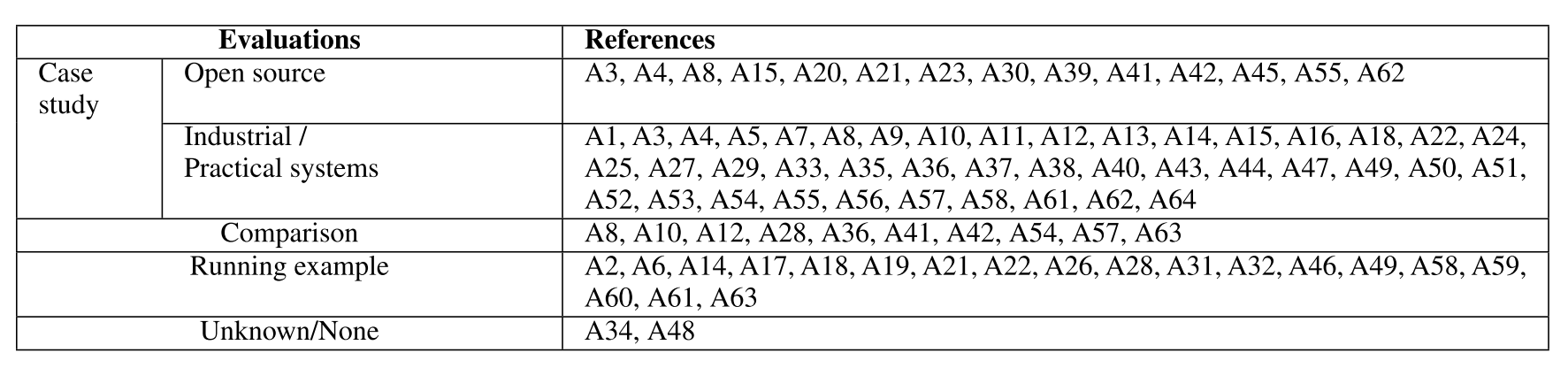
在模型驱动逆向工程(MDRE)的研究中,评估方法的透明度和多样性是衡量研究质量的重要标准。绝大多数方法都会明确说明其评估策略,主要通过三类方式验证有效性:案例研究、对比分析和运行示例。这些评估手段不仅帮助验证方法的可行性,还为不同场景下的应用提供了参考依据。
如下表所示,案例研究是最常用的评估方式,有 42 种方法用了工业级系统做案例研究,只有 14 种用的是开源系统,能够真实反映方法在复杂环境中的表现;对比分析则通过与现有工具或技术的横向比较,凸显创新点和优势,有 10 种方法用的是对比分析法;运行示例则侧重于通过简化场景展示方法的核心流程,有19 种方法用“跑示例”的方式评估。
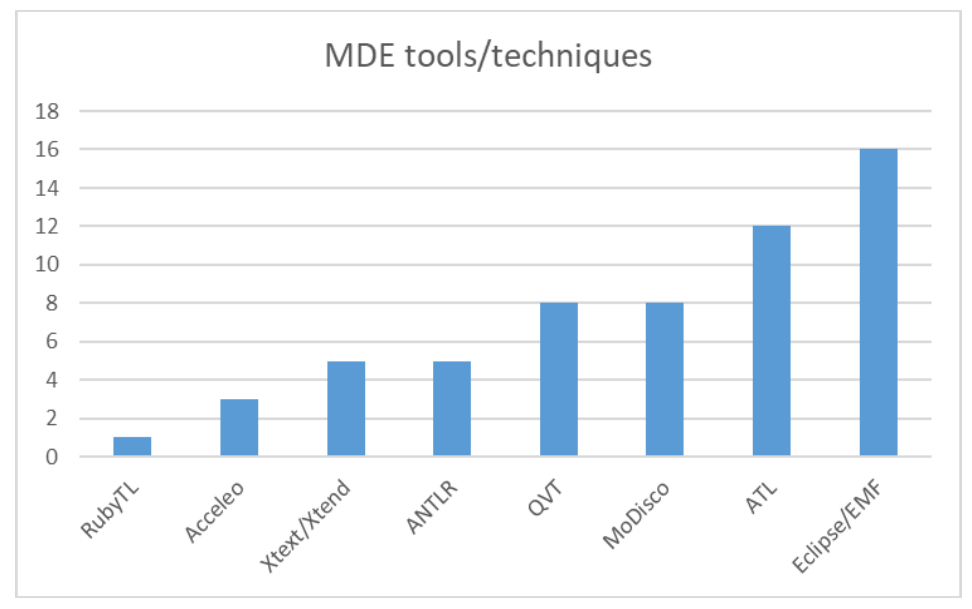
工具使用(自动生成工具、使用现有工具或两者兼用)
计算机辅助软件工程(CASE)工具对这类研究的成功特别关键。现在有不少商业 MDA 工具,这些工具能做正向工程,也能提供一些有限的逆向工程功能,比如 Eclipse Modeling Framework(EMF)、Modisco、ATL 这些都是常用的商业 MDA 工具:EMF 用来建模型、生成 Java 代码,Modisco 针对遗留系统做 MDRE,ATL 是基于 Eclipse 的模型转换语言。
如下图所示,具体到收集的 64 种方法里,工具使用分两种情况:42 种方法自己开发了工具来实现研究思路,8 种方法直接用了现有的 MDRE 工具(主要是 MoDisco)。从工具使用频率来看,EMF 用得最多,有 16 种方法在用;其次是 ATL,12 种方法使用;QVT 有 8 种方法在用;ANTLR 和 Xtext/Xtend 各有 5 种方法使用。
基于模型的软件系统重构方法
RQ2:当前有哪些基于模型的软件系统重构方法?
作者重点选取了程序迁移和程序翻译两项,两项活动相较于其他重构任务,它们不仅应用更广泛、定义更明确,还对其他重构活动具有基础性支撑作用。
程序翻译可归类为程序迁移的一个子集,但作者选择将其单独处理。程序迁移侧重于改变系统的平台和技术基础,例如从桌面应用程序转向以网络服务形式组织的系统;而程序翻译则专门涉及不同编程语言(如 Python 和 Java)之间的代码转换。
程序迁移
为深入理解程序迁移的各类方法,作者根据目标迁移平台对相关研究进行了分类。虽然基于网络的应用程序同时属于程序迁移和程序翻译范畴,但鉴于后续章节将重点讨论程序翻译,作者选择将其归类为程序迁移。如下表所示,从检索到的 64 种方法中,共识别出 10 种程序迁移方法。
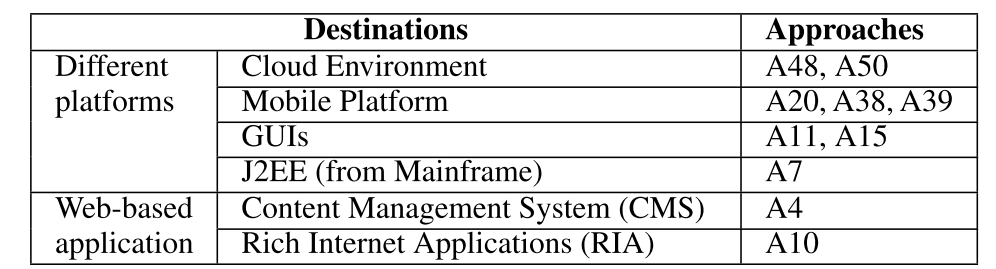
程序翻译
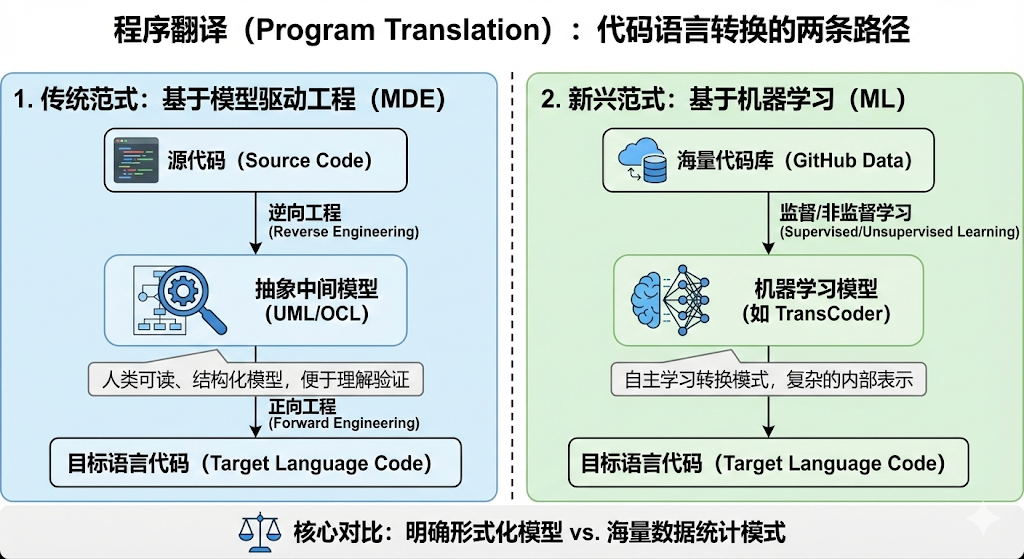
程序翻译(Program Translation)是将代码从一种编程语言转换为另一种的过程,这通常是更广泛的系统迁移或现代化工作的一部分。研究揭示了实现这一目标的两种截然不同的技术范式。
第一条路径是基于模型驱动工程(MDE)的传统方法。这类方法遵循一个经典流程:首先,将源代码逆向工程为抽象的、与具体语言无关的模型(例如 UML 类图和 OCL 约束规范);然后,再从这些中间模型正向生成目标语言的代码。这种方法的核心优势在于它会产出一个人类可读的、结构化的中间模型,这有助于工程师理解和验证转换逻辑。
第二条路径是基于机器学习(ML)的新兴方法。这类方法,如 Meta 开发的 TransCoder 模型,另辟蹊径。它们不依赖于明确的 UML 图,而是通过在海量代码库(例如来自 GitHub 的数百万个项目)上进行监督或非监督学习,让模型自主学习语言之间的转换模式。翻译结果依赖于模型内部学到的、复杂的中间表示,而非人类可读的图表。
这两种方法代表了解决同一问题的不同哲学:一种依赖于明确的形式化模型和规则,另一种则依赖于从海量数据中学习到的统计模式。
基于模型驱动工程(MDE)的传统方法
为全面理解并客观评估各类非机器学习程序翻译方法,我们首先明确了各方法支持的编程语言互译范围。这使我们能够判断该方法是支持多语言互译,还是仅限于特定语言间的转换。据此,程序翻译方法可分为“一对一”和“一对多”两大类。在检索到的文献中,有四种方法可归入“一对一”类别。这些方法均采用将特定语言编写的程序转换为另一种语言的处理方式。另一方面,仅发现三种方法不局限于特定编程语言,能够将一种语言编写的程序翻译成多种其他语言。
具体这些方法是怎么做的,可以去阅读一下原文,在这里就不赘述了。
基于机器学习(ML)的新兴方法
机器学习在软件工程中已被广泛应用于部署、测试和维护等任务,在程序翻译领域也得到广泛应用。目前已有多种技术通过监督或无监督机器学习实现编程语言间的程序翻译,包括:
- 罗齐埃等人提出的 TransCoder,这是一个高精度的无监督机器翻译模型,可自动实现 Python、C++ 和 Java 之间的函数转换。该模型基于 GitHub 海量源代码进行训练,采用序列到序列架构并配备注意力机制,其性能优于现有规则翻译技术,且无需人工监督即可运行。
- M. Zhu 等人开发了名为 CoST 的新数据集,包含七种编程语言(C++、C#、Java、JavaScript、PHP、Python 和 C)在代码片段和程序层面的平行数据。通过多语言代码片段翻译预训练和多语言代码片段去噪自动编码技术,研究者提出了一种创新的程序翻译模型。对所提模型的评估表明,其在代码片段级和程序级翻译任务中的表现均优于基线模型。
- Ahmad 等人提出了一种无监督方法,通过代码摘要生成作为传统回译技术的替代,以确保源语言与目标语言之间的准确性。在代码摘要生成中,模型通过代码片段训练生成自然语言(NL)摘要;而在代码生成中,模型则学习从 NL 摘要生成代码。
- Rithy 等人引入了 XTest 代码翻译平行多语言语料库,该语料库包含九种编程语言(Ruby、Go、Java、C++、C#、JavaScript、PHP、Python 和 C)的平行程序,以及英文测试用例和问题陈述。基于 XTest 数据集,开发了 30 个支持多语言代码翻译的系统。
- Chen 等人提出了一种树到树神经网络,该网络结合树编码器和树解码器实现源树到目标树的翻译。研究发现,该方法在使用注意力机制时表现优于其他神经翻译模型。
与非机器学习程序翻译方法不同,上述信息表明,大多数现有的机器学习程序翻译方法都能处理多种编程语言编写的程序。但这些方法在翻译过程中并不会生成流程图。相反,翻译结果依赖于机器学习模型中从数据集中源代码和目标代码共同学习到的中间表示。
面临的问题与挑战
在应用研究方法时,相关研究遇到了诸多困难。主要挑战具体表现为:
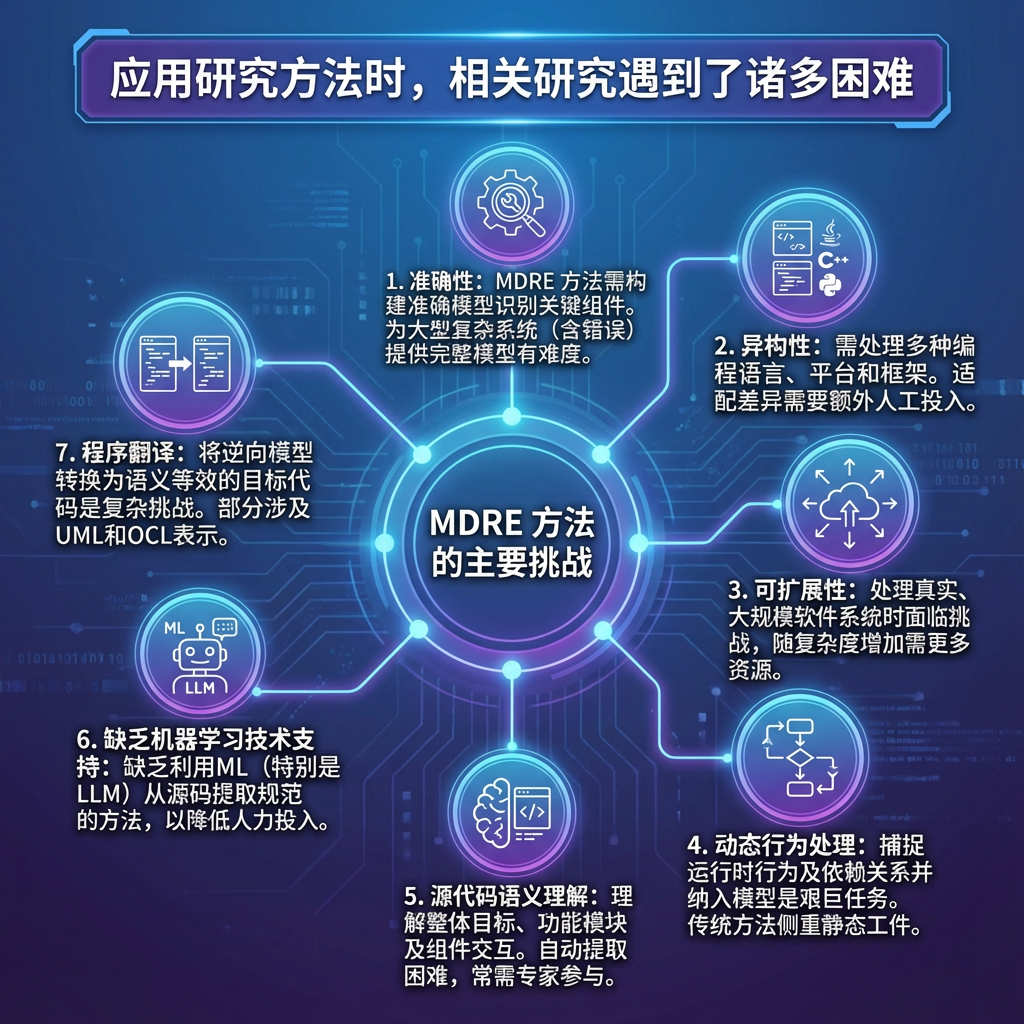
- 准确性:MDRE 方法需要构建能够识别软件系统关键组件并剔除冗余细节的模型。为大型复杂软件系统(存在错误或不一致性)提供完整准确的模型存在难度。
- 异构性:MDRE 方法在处理多种编程语言时面临诸多挑战,每种语言都具有独特特性。此外, MDRE 方法需适配不同软件平台、框架、架构和技术。要准确分析软件系统,必须考虑这些语言和平台差异,但这需要额外的人工投入来构建或配置 MDRE 工具。
- 可扩展性:MDRE 方法在处理真实软件系统时面临重大挑战,需要从源代码中提取所需信息。这是因为这些系统可能具有复杂架构,或采用多种编程语言开发。此外,随着软件系统规模和复杂度的增加,需要投入更多时间与资源。
- 动态行为处理:对于 MDRE 方法而言,捕捉运行时行为及软件组件间的依赖关系并将其纳入不同模型是一项艰巨任务。传统逆向工程方法往往侧重于静态工件(如源代码),这使得提取行为图(如 UML 序列图和通信图)变得极其困难。
- 源代码语义理解:MDRE 方法需要具备理解源代码语义的能力。这包括理解软件系统的整体目标、各功能模块的实现目标,以及源代码中各组件间的交互关系。从源代码中自动提取这些信息可能非常困难,尤其对于大型复杂软件系统而言。通常需要借助系统专家参与的交互式(半自动化)技术。
- 缺乏机器学习技术支持:MDRE 目前缺乏利用机器学习从源代码中提取规范的 MDRE 方法。这似乎存在研究空白,表明需要探索多种机器学习技术。这些技术通过识别源代码中的相关信息、理解其语义,并处理多种编程语言和框架,为 MDRE 方法提供支持。机器学习技术,尤其是大型语言模型(LLMs),能够有效降低大型复杂软件系统逆向工程所需的人力投入和资源消耗。
- 程序翻译:将逆向工程模型转换为与源代码语义等效的目标代码(特别是在涉及多种目标编程语言时),是一项复杂的挑战。部分解决方案通过先从源代码中提取精确的 UML 和 OCL 表示,再利用 AgileUML 等 MDE 工具将程序转换为目标语言来解决该问题。
总结
这篇综述通过对 83 篇学术论文的系统性回顾,让我们得以一窥软件逆向工程领域的真实面貌。这些发现共同描绘了一幅复杂的图景:这是一个以理解为基石、以实用主义为主导的领域,但其学术焦点却与最棘手的工业难题存在偏差,并且正处在两种不同范式和人工智能新机遇所驱动的深刻变革前夜。
核心思想依然明确:在软件系统日益复杂的今天,理解并演进遗留系统是一个永恒的挑战,而模型驱动的方法为此提供了结构化、系统化的解决方案。同时,AI 的崛起预示着一个激动人心的未来,它有望从根本上改变我们与陈旧代码互动的方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号